
2018.12
1.摘要
background
问题: 唇读(Lip Reading)即仅通过视觉信息识别说话内容,是一项极具挑战性的任务,主要因为存在"同音异义词"(homophones),即不同的字符可能产生相同的唇部动作 。
现状: 以前的工作主要集中在识别有限数量的单词或短语上。
目标: 本文旨在解决"开放世界"(open-world)的唇读问题,即识别自然语言句子,以及在自然场景视频(in the wild)中进行视听语音识别(Audio-Visual Speech Recognition, AVSR)。
innovation
模型对比: 比较了两种基于 Transformer 自注意力架构的模型:一种使用 CTC 损失,另一种使用序列到序列(Seq2Seq)损失 。
互补性研究: 研究了唇读在多大程度上可以作为音频语音识别的补充,特别是在音频信号嘈杂的情况下 。
新数据集: 发布了一个新的大规模视听数据集 LRS2-BBC,包含数千个来自英国电视的自然句子 。
- 方法 Method
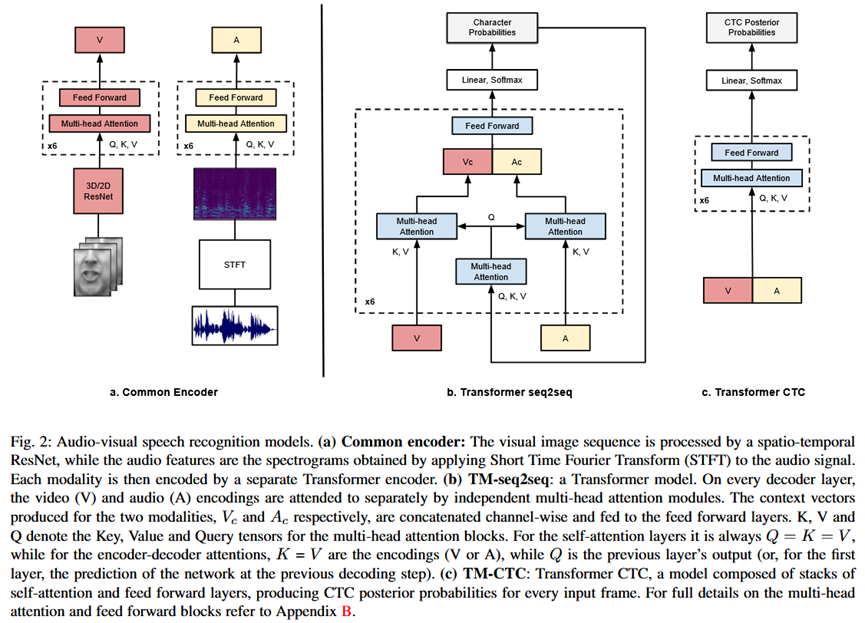
Pipeline (整体流程):
系统由两个模态的输入流(视频 V 和 音频 A)组成。每个模态首先通过各自的前端(Front-end)提取特征,然后通过编码器(Encoder),最后根据模型变体(CTC 或 Seq2Seq)进行融合和解码,输出字符序列 101010101010101010。
详细模块:
- 输入与特征提取:
视频输入 (V): 采样率为 25fps,裁剪嘴部区域 (112 \\times 112) 11。
视频前端 (Visual Module): 基于时空卷积(Spatio-temporal output)。使用 3D 卷积(滤波器宽度为5帧)处理序列,随后接 2D ResNet 逐渐减小空间维度。输出为每个视频帧对应一个 512维的特征向量 12121212。
音频输入 (A): 采样率为 16kHz。计算 Log-spectrograms(40ms 窗长,10ms 步长)。
音频特征: 将音频特征按 4 帧一组进行拼接,以匹配视频的帧率(40ms/帧),保持时间尺度一致 13131313。
- 通用编码器 (Common Encoder):
每个模态(V 和 A)分别有一个独立的 Transformer 编码器。
由多层多头自注意力(Multi-head Self-Attention)和前馈网络组成。使用正弦位置编码注入序列顺序信息 14141414。
- 模型变体 (Model Variants):
TM-seq2seq (Transformer Seq2Seq):
这是一个编码器-解码器结构。
融合方式: 解码器的每一层都有两个独立的注意力机制,分别关注视频编码和音频编码。产生的上下文向量 V_c 和 A_c 在通道维度拼接后输入前馈层 15。
Loss: Cross-Entropy Loss。
TM-CTC (Transformer CTC):
融合方式: 直接将视频和音频的编码输出在通道维度拼接,然后通过一堆自注意力块处理 16。
输出: 每一帧输出字符概率。
Loss: CTC Loss。
- 外部语言模型 (External LM):
使用一个字符级的 LSTM 语言模型(4层,每层1024个单元)。
在推理由波束搜索 (Beam Search) 结合 LM 分数进行解码(Shallow Fusion)17171717。
输入输出总结:
输入: 视频帧序列(嘴部图像) + 音频频谱图序列。
输出: 字符序列(Character level,包括26个字母、数字、空格等)18。
- 实验 Experimental Results
数据集: 主要使用 LRS2-BBC (新发布,来自BBC节目)和 LRS3-TED(来自TED演讲)。
主要实验结论:
- 纯唇读 (Lips only):
TM-seq2seq 表现最好。在 LRS2-BBC 测试集上达到 48.3% WER(词错误率),比之前的 SOTA(70.4%)提升了超过 20% 。
结论:Seq2Seq 模型在仅有视频输入时,能利用解码器的隐式语言模型能力,效果优于 CTC。
- 视听识别 (Audio-Visual):
在干净音频下,加入视觉信息能微弱提升性能(从 10.1% 降至 8.2%)。
在噪声环境下 (Noisy Audio): 视觉信息的加入至关重要。当音频信噪比低(0dB babble noise)时,纯音频模型崩溃,而视听模型依然稳健。
结论:TM-CTC 在视听任务中(特别是噪声下)表现略好于 Seq2Seq,且训练更稳定 。
- 非同步测试 (Out-of-sync):
TM-seq2seq 由于对音频和视频有独立的注意力机制,对音画不同步(人工偏移几帧)具有天然的抵抗力,微调后几乎不受影响 。
- 总结 Conclusion
Take home message: 在深度学习语音识别中,视觉模态(唇读)是音频的强大补充,尤其是在嘈杂环境中。对于开放世界的句子级唇读,基于 Transformer 的 Seq2Seq 架构是当时的最佳选择;而对于视听融合任务,基于 CTC 的 Transformer 架构则在抗噪性和效率上表现出色。