📚推荐阅读
面试官:为什么 Adam 在部分任务上会比 SGD 收敛更快,但泛化性更差?如何改进?
面试官:BatchNorm、LayerNorm、GroupNorm、InstanceNorm 有什么本质区别?
面试官:深层网络梯度消失的根本原因是什么?除了 ResNet,还有哪些架构能有效缓解?
面试官:大模型中的幻觉本质原因是什么?如何通过训练或推理手段抑制?
面试官:FlashAttention 的实现原理与内存优化方式?为什么能做到 O(N²) attention 的显存线性化?
面试官:KV Cache 了解吗?推理阶段 KV Cache 的复用原理?动态批处理如何提升吞吐?
面试官:Vision-Language 模型中,如何实现跨模态特征对齐?CLIP 与 BLIP 的主要区别?
面试官:多模态指令微调(Instruction Tuning)如何统一不同模态的输出空间?
面试官:说一下什么是量化,为什么将大语言模型从 FP16 量化到 int8 甚至 int4,性能仍然能保持得很好?
这道题表面上问量化,其实考察你对大模型权重分布特性、量化误差控制 以及 推理鲁棒性 的理解。
今天我们就一起来看看这个问题。
所有相关源码示例、流程图、面试八股、模型配置与知识库构建技巧,我也将持续更新在Github:AIHub,欢迎关注收藏!
一、为什么要量化?
在大语言模型(LLM)中,模型参数通常以 FP16 或 BF16 精度存储。
像一个 70B 参数的模型,用 FP16 存储就是:
这对单张 GPU 来说是天文数字,于是,量化(Quantization)就成为现实部署的"救命稻草"------用更低位的整数(int8 / int4)表示权重,大幅减少显存占用和带宽消耗,同时保持精度。
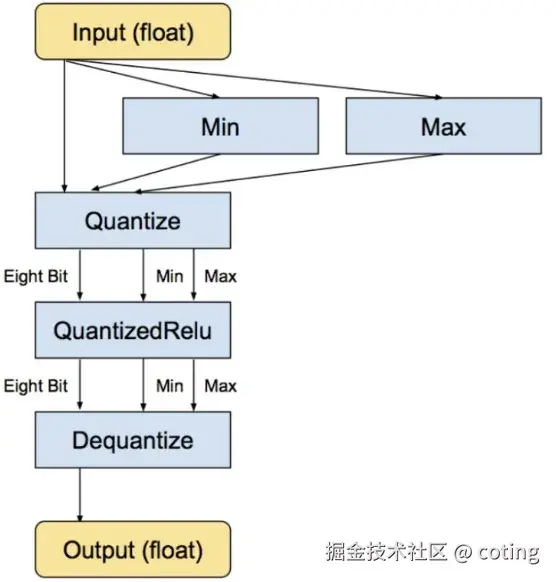
比如从 FP16 → int8,可以直接减半显存,从 int8 → int4 又能再减一半,而惊喜的是性能损失通常极小,甚至几乎没有。
常见方法包括PTQ(Post-Training Quantization)和QAT(Quantization-Aware Training)
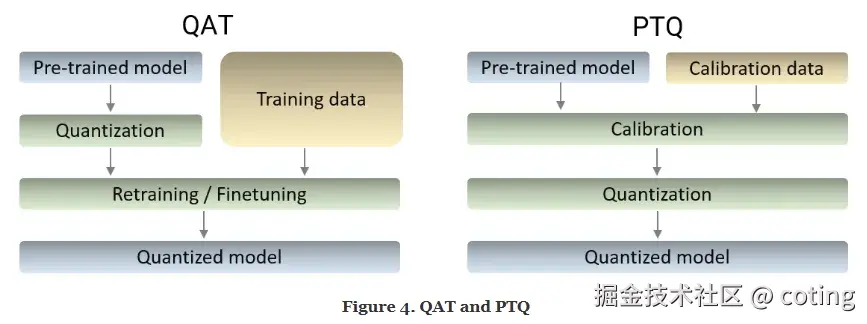
QAT训练过程中模拟量化效果, 能够实现较高的精度**。PTQ**训练后直接量化,无需重新训练,简单但精度下降可能较大。
二、为什么量化后模型还能记得住东西?
要理解这一点,先得看清两个事实:
1.模型权重不是均匀分布的
在预训练后的大模型中,权重往往呈 近似正态分布。
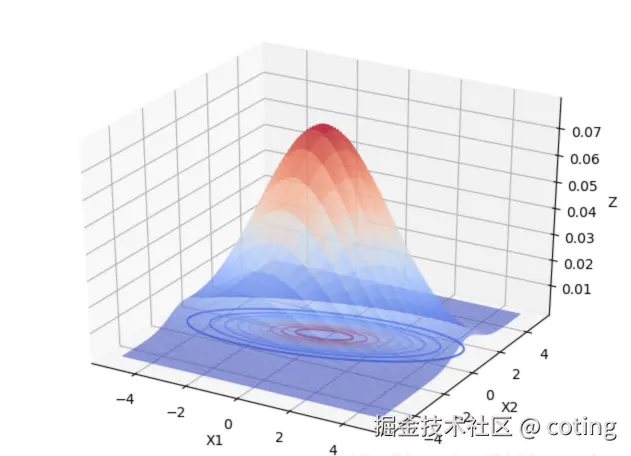
绝大多数权重集中在一个较小范围,真正极大或极小的值非常少,这意味着用高精度去表示这些小范围波动其实有些浪费。
2.模型输出对小数值扰动不敏感
Transformer 层叠结构具备强大的冗余与自稳性,它不像传统算法那样对精度极度敏感。
也就是说模型其实不在乎每个权重精确到小数点后 6 位,只要方向(sign)和大致比例(scale)对了,就能正常工作。
这就是量化的理论基础:低比特整数近似不会破坏关键的表示结构。
三、量化的核心机制
量化的本质是把连续值映射到有限的离散值集合 ,并且量化分为对称量化和非对称量化,这两者的具体区别可以去看我之前写的文章模型的量化了解吗?解释一下非对称量化与对称量化。
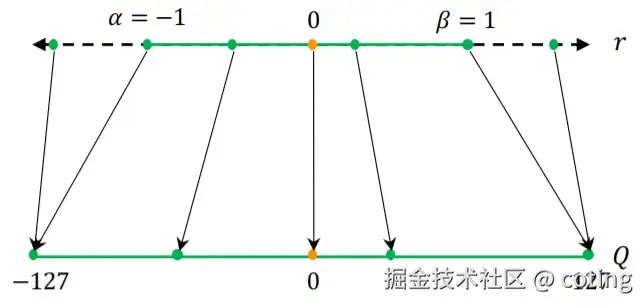
以 int8 为例,范围是 (-128, 127),我们通过一个缩放因子(scale)实现近似:

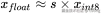
其中 s 就是"缩放因子",表示单位整数代表的真实值大小。
关键点在于如何选择 s,如果全层共享一个 scale(per-tensor),误差大;如果为每个通道或每个组独立设置 scale(per-channel / per-group),则量化误差能大幅降低。
这也是现代量化方案能在 int4 精度下仍然保持性能的关键。
四、现代 LLM 的量化技巧
光靠线性量化是不够的,现代 LLM 量化之所以表现好,是因为结合了几种关键技巧👇
1.分组量化
将矩阵按列或按块分组,每组独立计算缩放因子。
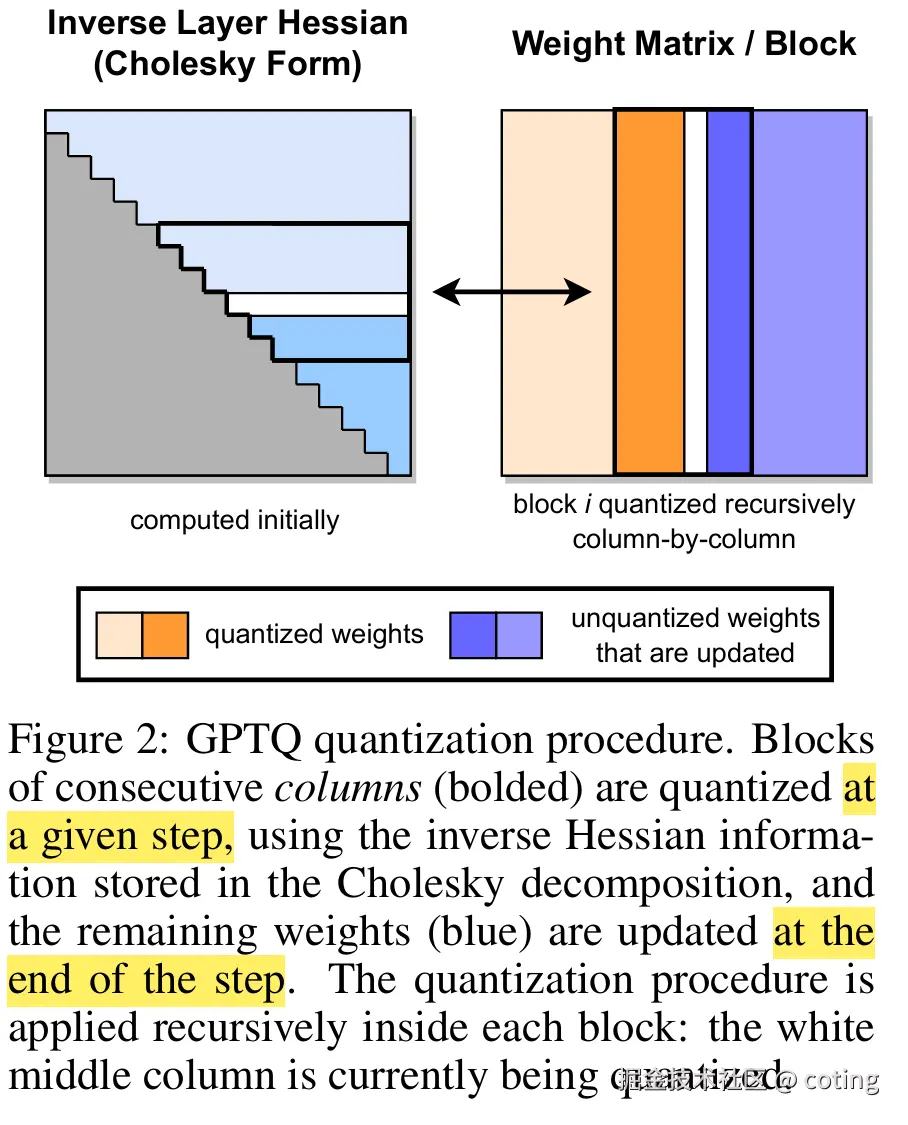
这样能自适应每组分布差异,大幅降低信息丢失。
常见方案包括GPTQ、AWQ、SmoothQuant。
2.激活重标定
量化不仅影响权重,还影响激活值(中间输出)。
现代方法通过线性变换在量化前重新平衡激活范围,减少大数值主导效应。
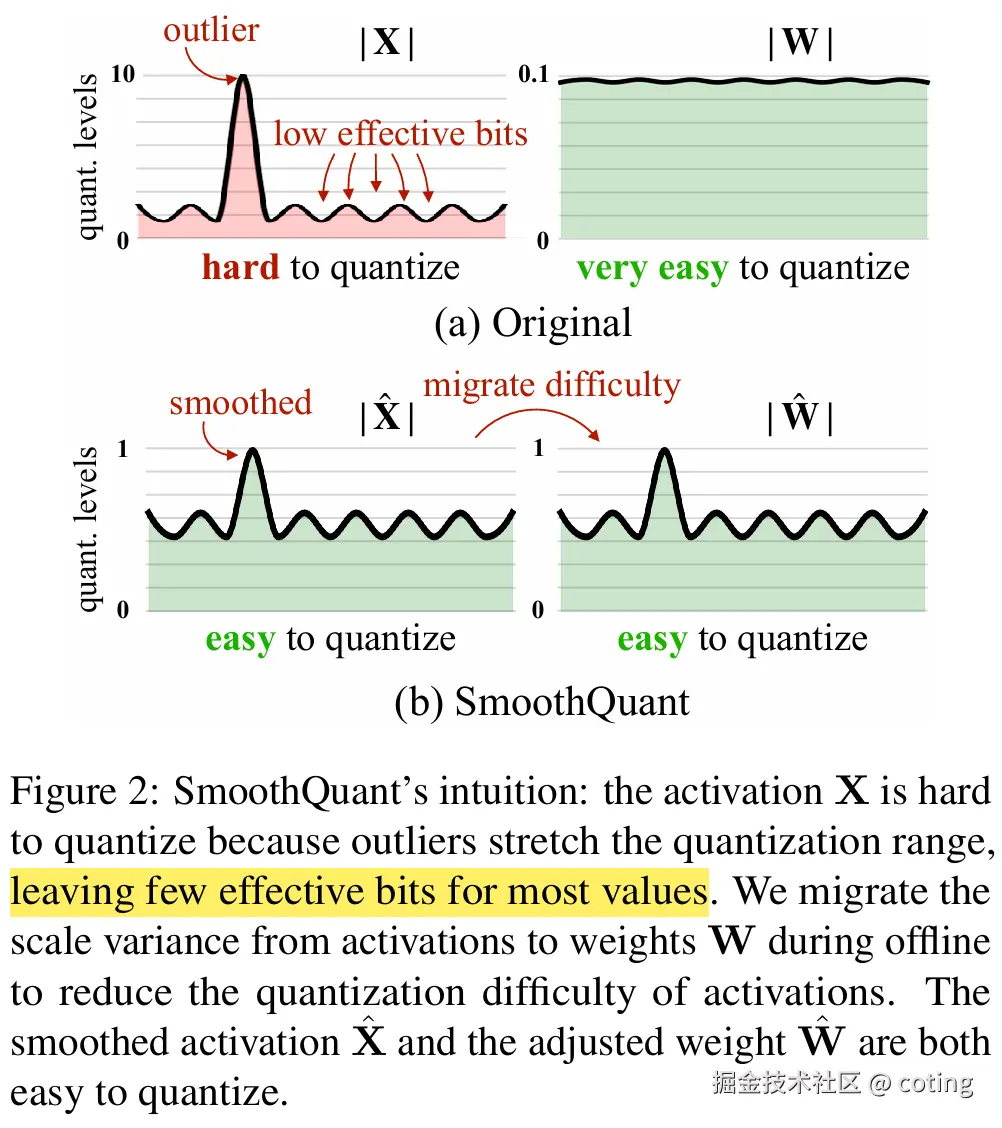
比如 SmoothQuant:
保证乘积保持稳定。
3.量化感知微调
有时会在低比特量化后进行短暂再训练,让模型重新适应离散权重分布。
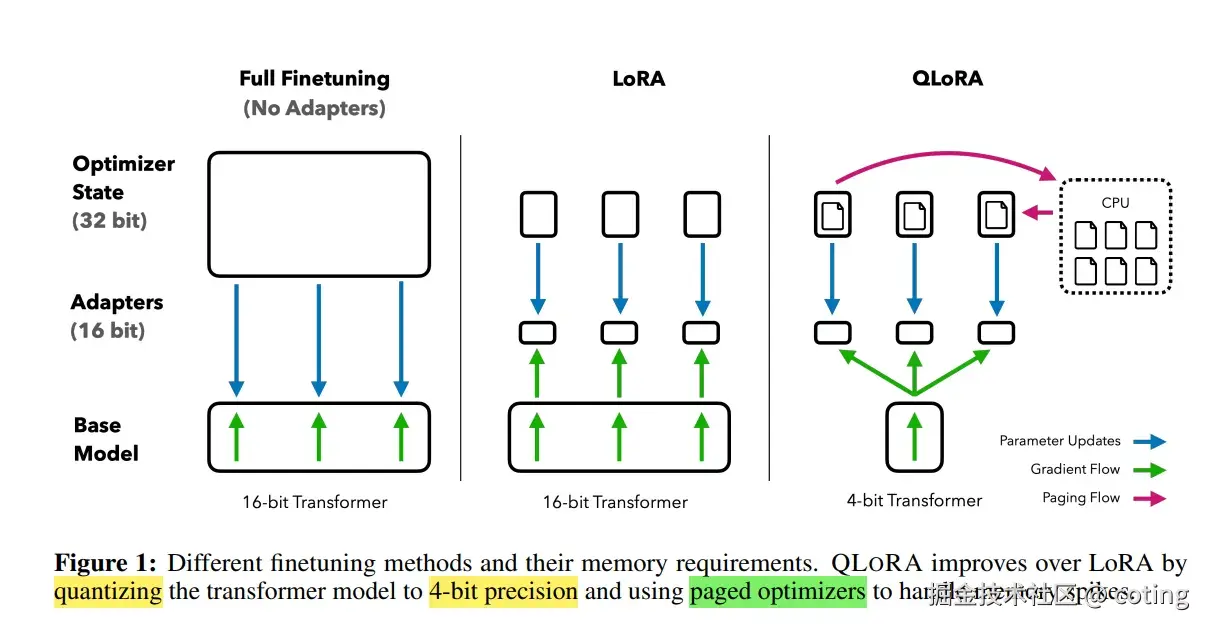
这类轻量微调(几小时即可)能显著恢复性能,像 LLM.int8()、QLoRA 都采用了这种策略。
4.保留高敏感部分
并不是所有层都需要量化。
通常:
- 前馈层(FFN)权重可量化到 int4;
- 归一化层、embedding 层保持 FP16;
- 输出头(lm head)也保持高精度。
这类混合精度量化保证性能几乎不降。
五、Int4/Int8 仍能保持性能的核心原因
总结下来,其实有四个关键点:
- 权重分布集中:大部分参数幅度小,可被低比特整数准确近似;
- 模型冗余高:Transformer 层具备容错性,对微小误差不敏感;
- 量化分组细粒度化:per-channel / per-group 设计减少误差传播;
- 训练后自适应修正:通过 rescale 或微调补偿量化噪声。
也就是说模型本身过强,量化带来的精度损失不足以动摇它的语义能力。
这就是为什么我们能看到int8 几乎无损,int4 也只略微下降 1~2% 的结果。
对于面试官的这个问题,可以按下面的方法进行回答:
大模型权重分布集中且冗余度高,模型对微小数值扰动不敏感。
现代量化方法采用 per-channel 分组量化与激活重标定,有效控制量化误差;
同时通过微调或混合精度保持关键层高精度,使得 int4 / int8 量化后在计算效率和性能之间取得平衡,几乎无损精度。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号 aicoting!