虚拟机:VmWare + Centos7
虚拟机准备工作
一、节点分配

hadoop001 master
hadoop002 node1
hadoop003 node2
关闭防火墙
systemctl stop firewalld #三台服务器都要执行
关闭开机自启
systemctl disable firewalld #三台服务器都要执行
修改文件内容
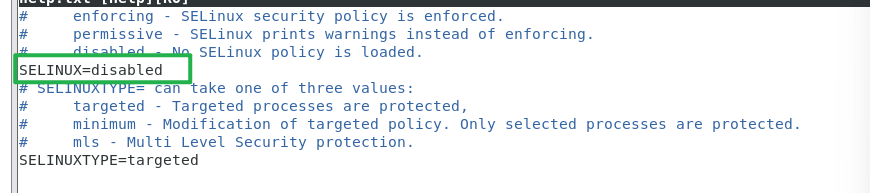
vim /etc/sysconfig/selinux
SELINUX=disabled #三台服务器都要执行
修改为disable,如果不能保存则切换至root用户
修改虚拟机名称
每台服务器都要执行
hostnamectl set-hostname master
hostnamectl set-hostname node1
hostnamectl set-hostname node2
reboot #重启服务器看下是否已经变成对应的名称
二、设置网络
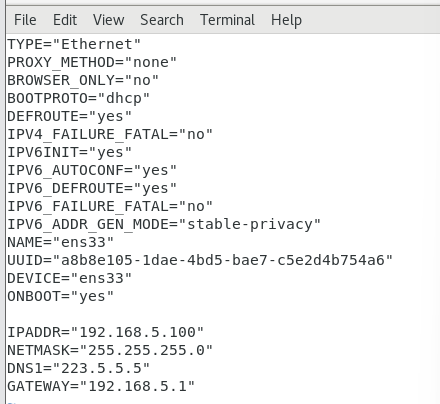
修改ens33 网卡的网络配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33 #修改BOOTPROTO为dhcp
#增加以下配置
IPADDR="192.168.**.100"
NETMASK="255.255.255.0"
DNS1="223.5.5.5"
GATEWAY="192.168.**.1"
#注意 每台主机的IPADDR不一样其他都一样
#主机的网段要和本地的ip在一个网段下
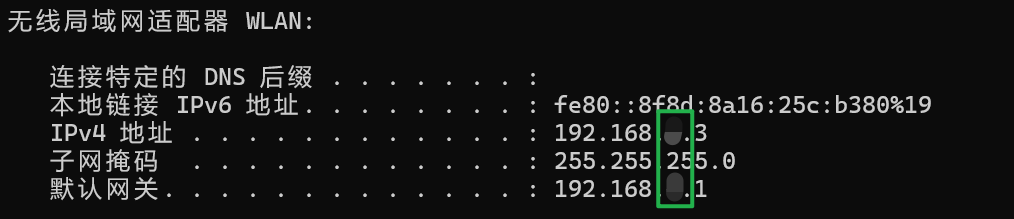
win+R 运行cmd,执行ipconfig命令查询本地ip
本文中的**由本地ip中的同位置数字代替
#但是要保证三台主机的IPADDR都在一个网段下
master:IPADDR="192.168.**.100"
node1: IPADDR="192.168.**.101"
node2: IPADDR="192.168.**.102"
重启网卡
systemctl restart network #每台服务器都运行
#查看网络连接是否正常
配置地址映射
vim /etc/hosts #每台服务器都运行
#添加以下内容
192.168.88.100 master
192.168.88.101 node1
192.168.88.102 node2
reboot #重启
三、设置虚拟机间的通信
每台主机都要操作
创建秘钥(rsa非对称加密)
ssh-keygen -t rsa -b 4096
root用户的免密登录
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
#执行后会出现以下交互,全程回车使用默认配置即可,还需要输入yes确认
#无需设置密码短语,否则免密登录会需要输入短语

执行ssh,查看能否正常ssh到其他主机
ssh node1
ssh node2
hadoop用户免密登录
增加Hadoop用户
useradd hadoop
passwd hadoop #需要输入密码,用户的登陆密码
切换到hadoop用户后把上面的操作都再来一遍
su hadoop
ssh-keygen -t rsa -b 4096
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
四、jdk配置
我的镜像本来自带了jdk1.8,但是在后续的部署中发件无法执行jps
所以直接把重新安装的过程放在前面
替换国内第三方源
如阿里云的 CentOS 7 归档源
备份原有源文件:
sudo mkdir /etc/yum.repos.d/bak
sudo mv /etc/yum.repos.d/*.repo /etc/yum.repos.d/bak
#下载阿里云的 CentOS 7 归档源
sudo curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
#修改源文件中的$releasever为固定值7(因官方源已归档,变量无法解析)
sudo sed -i 's/$releasever/7/g' /etc/yum.repos.d/CentOS-Base.repo
清除缓存并更新源
sudo yum clean all
sudo yum makecache
重新安装 Java 1.8
sudo yum install -y java-1.8.0-openjdk-devel
需要变更环境变量,先找到正确的 JDK 根目录
通过which java跟踪路径
# 1. 找到java命令的路径
which java
# 示例输出:/usr/bin/java
# 2. 跟踪软链接,找到实际的java执行文件
ls -l /usr/bin/java
# 示例输出:/usr/bin/java -> /etc/alternatives/java
# 3. 继续跟踪,直到找到JDK的jre目录
ls -l /etc/alternatives/java
# 示例输出:/etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64/jre/bin/java
#从最终路径中,去掉/jre/bin/java,剩下的就是 JDK 根目录:
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64JAVA_HOME应配置为:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64
export PATH=JAVA_HOME/bin:PATH
配置完成后
source /etc/profile
#查看java版本,在node1和node2上分别验证
java -version
五、同步时间
date # 查看系统时间
timedatectl # 查看时区、同步状态 .
设置为中国时区(Asia/Shanghai)
运行 sudo timedatectl set-timezone Asia/Shanghai
六、设置共享文件夹
Vmware开启共享文件夹
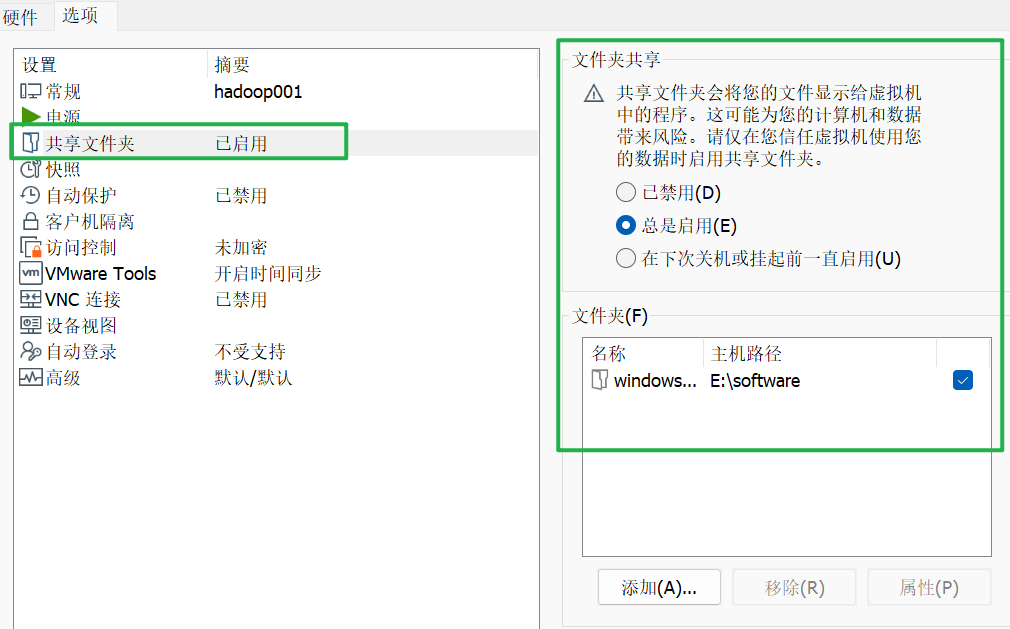
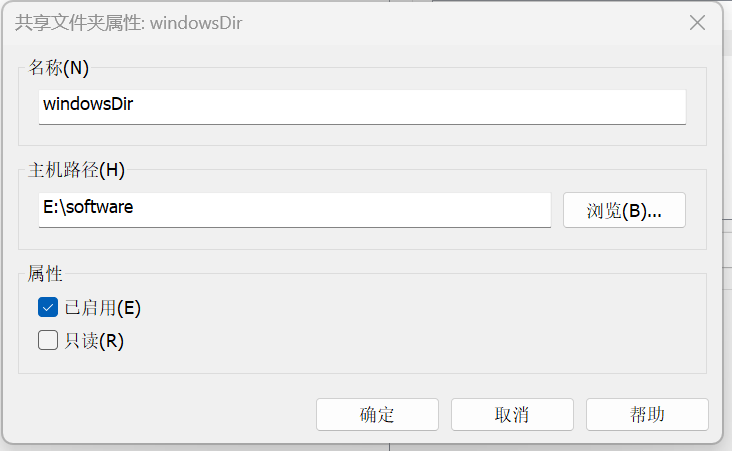
挂载共享文件夹
bash
mkdir /windowsDir
#创建共享文件夹,并将挂载设置为总是启用
echo ".host:/windowsDir /windowsDir fuse.vmhgfs-fuse allow_other,uid=1000,gid=1000 0 0" | sudo tee -a /etc/fstab
sudo mount -a # 测试挂载
reboot #重启host后面的是挂载的共享文件夹的名称,fuse前面的是主机上的文件夹名称
正式部署hadoop集群
一、集群部署-master节点部署
安装hadoop
创建工作目录
mkdir /software
进入目录
cd /software
本地下载好Hadoop3.3.6的tar包之后放到共享文件夹下面
根据上面的配置我这里是:E盘下的software
然后在主机上把windowsDir下面的安装包复制到本机software目录下
解压缩
tar -zxvf hadoop-3.3.6.tar.gz -C /software
修改workers
这个文件会指定节点的分布,比如DataNode有哪些
到hadoop的安装目录下
cd /software/hadoop-3.3.6/etc/hadoop
vi workers
#添加以下节点
master
node1
node2
配置hadoop相关的环境变量
cd /software/hadoop-3.3.6/etc/hadoop
#设置java和hadoop的环境变量,java的和上文的保持一致
export JAVA_HOME=/home/jdk/jdk1.8.0_151
export HAD00P_HOME=/software/hadoop-3.3.6
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
hadoop的全局核心配置文件1
core-site.xml是 Hadoop 分布式文件系统(HDFS)中的核心配置文件,属于 Hadoop 的配置文件集合,主要用于配置 Hadoop 的核心服务(包括 HDFS 和 YARN 的基础配置),文件存放在 Hadoop 的配置目录下,通常是$HADOOP_HOME/etc/hadoop/。
- 文件的作用 这个文件主要用来定义 Hadoop 集群的全局核心配置,会被 Hadoop 的所有守护进程和客户端读取,主要配置的内容包括:
- HDFS 的命名节点(NameNode)的地址
- Hadoop 的临时文件存储目录
- HDFS 的默认文件系统的地址
- 分布式文件系统的基础参数
cd /software/hadoop-3.3.6/etc/hadoop
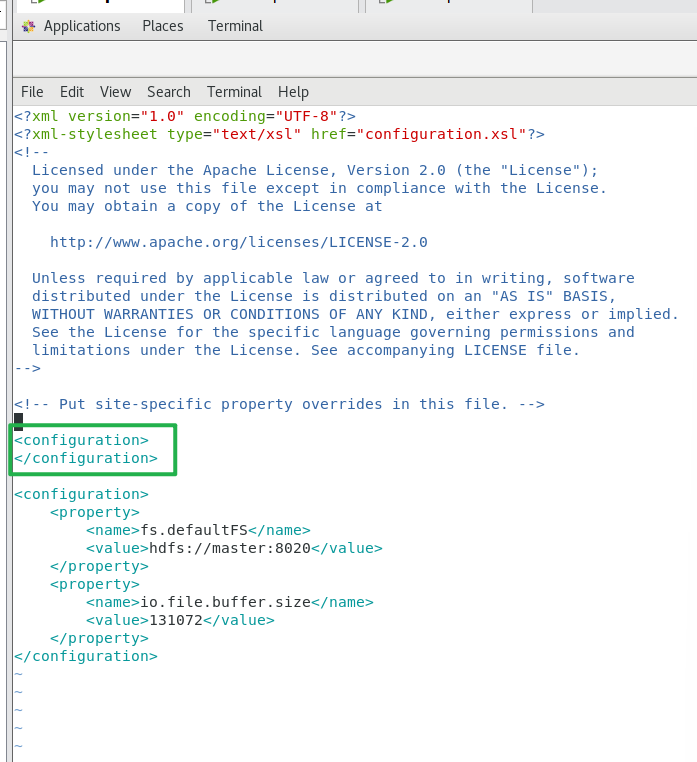
vi core-site.xml
添加以下信息
XML
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>正确的core-site.xml结构示例(单根节点,所有属性嵌套在中)绿色框中的要删掉
hadoop的全局核心配置文件2
hdfs-site.xml是Hadoop 分布式文件系统(HDFS) 的核心配置文件之一,与core-site.xml配合使用,专门用于配置 HDFS 的具体运行参数和集群行为,而非 Hadoop 的全局核心配置。该文件同样存放在 Hadoop 的配置目录$HADOOP_HOME/etc/hadoop/下,会被 HDFS 的守护进程(NameNode、DataNode、SecondaryNameNode 等)和客户端读取。
文件的核心作用
它主要聚焦于 HDFS 的个性化配置,补充core-site.xml中未定义的 HDFS 专属参数,涵盖集群的存储策略、副本机制、守护进程的运行参数、容错机制等,是调优 HDFS 性能和功能的关键文件。
cd /software/hadoop-3.3.6/etc/hadoop
vi /hdfs-site.xml
格式问题和上面同理
XML
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>master,node1,node2</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/dn</value>
</property>
</configuration>#需要创建上述文件夹
#在master上执行下述命令
mkdir -p /data/dn
mkdir /data/nn
#在node1和node2上执行下述命令
mkdir -p /data/dn
二、node节点部署
将hadoop-3.3.6及其所有子文件复制到其他两个节点(node1和node2)的/software文件夹下
使用scp工具(依赖主机间的通信)
scp -r /software/hadoop-3.3.6 node1:'/software/hadoop-3.3.6'/
scp -r /software/hadoop-3.3.6 node2:'/software/hadoop-3.3.6'/
#查看node1、node2复制过去的文件夹是否正常
#把master配置好的环境变量文件复制过去,要保证三个节点的java、hadoop部署位置一致
scp -r /etc/profile node1:/etc/profile
scp -r /etc/profile node2:/etc/profile
#加载配置文件,在node1和node2上分别执行
source /etc/profile
#查看java版本,在node1和node2上分别验证
java -version
#给hadoop用户授权(三个节点都要赋权)
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /software/hadoop-3.3.6
启动集群
一、集群启动相关命令
bash
start-dfs.sh 启动hdfs服务
然后jps查看进程,正常应该是这样
# 通过jps验证启动的程序,正常情况下,master应该启动如下进程:
6576 Jps
86147 DataNode
86522 SecondaryNameNode
85741 NameNode
# node1和node2应该启动的进程包括:
8729 Jps
112543 DataNode但是发现DataNode没有启动然后进行核查
表现为jps下没有DataNode进程
二、异常处理
原因分析
最常见原因:DataNode 与 NameNode 的 clusterID 不一致
这是 DataNode 无法启动的首要原因:
原因:NameNode 格式化后生成的clusterID被存储在其数据目录中,若多次格式化 NameNode,新的clusterID会与 DataNode 本地存储的旧clusterID不匹配,导致 DataNode 拒绝启动。
异常修复方案
停止所有 HDFS 服务:
删除 DataNode 的存储目录(所有从节点执行)
DataNode 的存储目录是/data/dn,删除该目录下的所有数据:(参考自己的目录,我这里是单独给data新建的)
rm -rf /data/dn/*
重新启动 HDFS 服务
也可以通过查看日志发现问题
tail -100f $HADOOP_HOME/logs/hadoop-hadoop-datanode-master.log
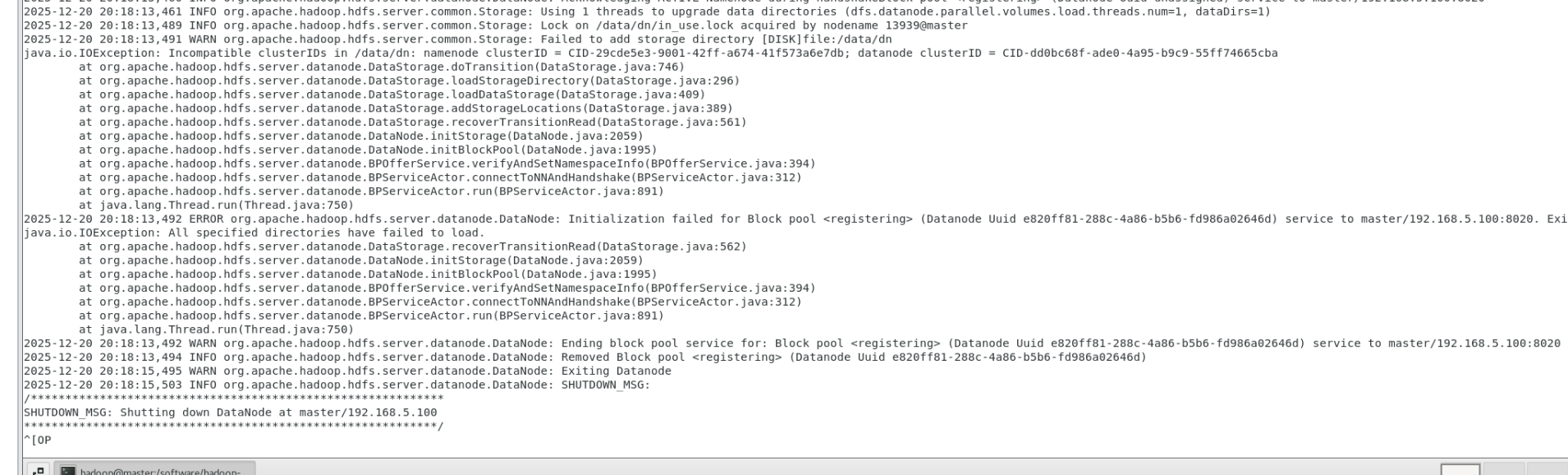
这个错误的核心是DataNode 与 NameNode 的 clusterID 不匹配(日志中明确显示Incompatible clusterIDs),这是 DataNode 无法启动的典型原因 ------NameNode 格式化后生成了新的 clusterID,而 DataNode 本地存储的还是旧的 clusterID。
参考来源:
豆包