在构建企业级智能 Agent 项目的过程中,如何让 Agent "记住"用户信息并高效利用记忆,是决定产品体验的核心问题。同时,效果与延迟的平衡也是工程落地的最大挑战。本文将深入剖析长短期记忆机制的设计细节,并分享效果提升与延迟优化的关键策略。
一、Agent 的记忆系统:不是"记住一切",而是"记住该记的"
很多人误以为 Agent 的记忆就是"把所有对话存下来",但真实场景中,无差别存储会导致成本爆炸、检索噪声大、隐私风险高。我们采用 分层记忆架构(Hierarchical Memory),区分短期与长期记忆。
1. 短期记忆(Short-Term Memory)------ 对话上下文
存储内容:当前会话的完整消息历史(user + assistant + function_call)
存储位置:内存(如 Redis 或应用本地缓存)
粒度:整轮对话(保留完整交互链)
生命周期:会话结束即销毁(TTL = 30 分钟)- 用途:
支持多轮 Function Call(如追问订单号)
维持上下文连贯性("刚才说的那个产品...") - 关键设计:
严格遵循 OpenAI 消息格式,确保 role=function 正确回填,避免模型"失忆"。
python
# 短期记忆示例(Redis 存储)
session_id = "sess_123"
messages = [
{"role": "user", "content": "查订单"},
{"role": "assistant", "function_call": {"name": "query_order", "arguments": "{}"}},
{"role": "function", "name": "query_order", "content": '{"error": "缺少订单号"}'},
{"role": "assistant", "content": "请提供订单号"}
]
redis.setex(f"short_mem:{session_id}", 1800, json.dumps(messages))2. 长期记忆(Long-Term Memory)------ 用户画像与知识沉淀
-
存储内容:结构化事实(非原始对话),例如:
用户偏好:"喜欢用支付宝支付"
业务状态:"已通过 KYC 认证"
历史问题:"上周咨询过基金赎回"
-
存储位置:向量数据库(如 Milvus / Pinecone)+ 关系型数据库( SQLite / MySQL)
粒度:语义单元(Memory Chunk),每条 1~2 句话
-
生命周期:长期保存(可设置自动过期)
-
用途:
个性化服务("您上次提到想买债券型基金...")
跨会话一致性(今天问 vs 明天问,答案一致)
-
关键设计:通过 Memory Summarization Pipeline 提取事实,而非直接存储对话。
长期记忆写入流程:

示例:
用户说:"我一般用支付宝,不太用微信支付。"
LLM 提取:{"preference": "payment_method", "value": "Alipay"}
向量化后存入 Milvus,元数据存 MySQL(含 user_id、timestamp、source)最大难题:记忆噪声 vs 效果 vs 延迟的三角矛盾
在项目初期,可能会面临一个经典困境:
"加更多记忆 → 效果提升但延迟飙升;减少记忆 → 延迟降低但答非所问。"具体表现为:
RAG 检索返回 10 条记忆,LLM 上下文超限(>128K token)
无关记忆干扰模型(如把"喜欢咖啡"误用于"基金推荐")
向量检索耗时 300ms,用户感知明显卡顿长期记忆代码Demo演示
python
agent_memory/
├── memory_manager.py ← 核心逻辑
├── embedding.py ← 向量化工具
├── models.py ← 数据模型
├── config.py ← 配置
└── test_memory.py ← 测试脚本- config.py ------ 配置文件
python
# config.py
from dataclasses import dataclass
@dataclass
class MemoryConfig:
# 向量维度(根据 embedding 模型调整)
embedding_dim: int = 384 # sentence-transformers/all-MiniLM-L6-v2 输出 384 维
# Milvus 集合名
collection_name: str = "agent_memories"
# 记忆保留天数
retention_days: int = 90
# LLM 提取记忆的 prompt
extraction_prompt: str = """
你是一个记忆提取器,请从以下对话中提取用户的**持久性偏好或事实**,忽略临时性、情绪性内容。
只输出 JSON 列表,每项包含:type(类别)、content(内容)、source(原始语句)。
示例:
[{"type": "payment_preference", "content": "偏好支付宝", "source": "我一般用支付宝付款"}]
对话:
{dialogue}
"""- models.py ------ 数据模型
python
# models.py
from dataclasses import dataclass
from datetime import datetime
from typing import List, Optional
@dataclass
class MemoryRecord:
"""长期记忆记录(存入SQLite)"""
id: Optional[int] = None
user_id: str = ""
type: str = "" # 如 "payment_preference", "risk_tolerance"
content: str = "" # 结构化内容
source: str = "" # 原始用户语句
created_at: datetime = None
embedding_id: str = "" # 对应 Milvus 中的 ID
def __post_init__(self):
if self.created_at is None:
self.created_at = datetime.utcnow()- embedding.py ------ 向量化工具
python
# embedding.py
from sentence_transformers import SentenceTransformer
class EmbeddingModel:
def __init__(self, model_name: str = "all-MiniLM-L6-v2"):
print("加载 embedding 模型...")
self.model = SentenceTransformer(model_name)
print("Embedding 模型加载完成")
def encode(self, text: str) -> List[float]:
"""将文本转为向量"""
return self.model.encode(text, convert_to_numpy=False).tolist()- memory_manager.py ------ 核心实现
python
# memory_manager.py
import json
import sqlite3
import uuid
from typing import List, Dict, Any
from datetime import datetime, timedelta
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
from openai import OpenAI
from config import MemoryConfig
from models import MemoryRecord
from embedding import EmbeddingModel
class LongTermMemoryManager:
def __init__(self, user_id: str, openai_api_key: str):
self.user_id = user_id
self.config = MemoryConfig()
self.embedding_model = EmbeddingModel()
self.llm_client = OpenAI(api_key=openai_api_key)
# 初始化数据库
self._init_sqlite()
self._init_milvus()
# ======================
# Step 1: 初始化 SQLite(元数据存储)
# ======================
def _init_sqlite(self):
"""创建 SQLite 表存储记忆元数据"""
self.sqlite_conn = sqlite3.connect("memories.db", check_same_thread=False)
self.sqlite_conn.execute("""
CREATE TABLE IF NOT EXISTS memories (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id TEXT NOT NULL,
type TEXT NOT NULL,
content TEXT NOT NULL,
source TEXT NOT NULL,
created_at TEXT NOT NULL,
embedding_id TEXT NOT NULL
)
""")
self.sqlite_conn.commit()
# ======================
# Step 2: 初始化 Milvus(向量存储)
# ======================
def _init_milvus(self):
"""连接 Milvus 并创建集合(如果不存在)"""
connections.connect("default", host="localhost", port="19530")
fields = [
FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=36),
FieldSchema(name="user_id", dtype=DataType.VARCHAR, max_length=64),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=self.config.embedding_dim)
]
schema = CollectionSchema(fields, "Agent long-term memories")
self.collection = Collection(self.config.collection_name, schema)
# 创建索引(HNSW 适合高精度检索)
index_params = {"index_type": "HNSW", "metric_type": "COSINE", "params": {"M": 8, "efConstruction": 64}}
self.collection.create_index("embedding", index_params)
self.collection.load() # 加载到内存加速查询
# ======================
# Step 3: 从对话中提取结构化记忆(核心)
# ======================
def extract_memories_from_dialogue(self, dialogue: List[Dict[str, str]]) -> List[Dict[str, str]]:
"""调用 LLM 从对话中提取结构化记忆"""
# 拼接对话为字符串
dialogue_text = "\n".join([f"{msg['role']}: {msg['content']}" for msg in dialogue])
prompt = self.config.extraction_prompt.format(dialogue=dialogue_text)
response = self.llm_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
temperature=0.0 # 确保输出稳定
)
try:
memories = json.loads(response.choices[0].message.content)
# 校验格式
assert isinstance(memories, list)
for m in memories:
assert "type" in m and "content" in m and "source" in m
return memories
except (json.JSONDecodeError, AssertionError):
print("LLM 返回格式错误,跳过记忆提取")
return []
# ======================
# Step 4: 保存记忆到 Milvus + SQLite
# ======================
def save_memories(self, dialogue: List[Dict[str, str]]):
"""主入口:提取并存储记忆"""
extracted = self.extract_memories_from_dialogue(dialogue)
if not extracted:
return
print(f"提取到 {len(extracted)} 条长期记忆")
for mem in extracted:
# 1. 生成唯一 ID
emb_id = str(uuid.uuid4())
# 2. 向量化(使用 content + source 增强语义)
text_to_embed = f"{mem['type']}: {mem['content']} | {mem['source']}"
vector = self.embedding_model.encode(text_to_embed)
# 3. 插入 Milvus
self.collection.insert([
[emb_id],
[self.user_id],
[vector]
])
# 4. 插入 SQLite
record = MemoryRecord(
user_id=self.user_id,
type=mem["type"],
content=mem["content"],
source=mem["source"],
embedding_id=emb_id
)
self.sqlite_conn.execute(
"INSERT INTO memories (user_id, type, content, source, created_at, embedding_id) VALUES (?, ?, ?, ?, ?, ?)",
(record.user_id, record.type, record.content, record.source, record.created_at.isoformat(), record.embedding_id)
)
self.sqlite_conn.commit()
print("长期记忆已保存")
# ======================
# Step 5: 按用户检索相关记忆
# ======================
def retrieve_relevant_memories(self, query: str, top_k: int = 3) -> List[MemoryRecord]:
"""根据用户问题检索最相关的长期记忆"""
# 1. 向量化查询
query_vector = self.embedding_model.encode(query)
# 2. Milvus 向量检索(限定 user_id)
search_params = {"metric_type": "COSINE", "params": {"ef": 64}}
results = self.collection.search(
data=[query_vector],
anns_field="embedding",
param=search_params,
limit=top_k,
expr=f'user_id == "{self.user_id}"' # 关键:只查当前用户
)
if not results[0]:
return []
# 3. 从 SQLite 获取完整元数据
embedding_ids = [hit.id for hit in results[0]]
placeholders = ','.join(['?'] * len(embedding_ids))
cursor = self.sqlite_conn.execute(
f"SELECT * FROM memories WHERE embedding_id IN ({placeholders})",
embedding_ids
)
records = []
for row in cursor.fetchall():
records.append(MemoryRecord(
id=row[0], user_id=row[1], type=row[2], content=row[3],
source=row[4], created_at=datetime.fromisoformat(row[5]), embedding_id=row[6]
))
return records- test_memory.py ------ 测试脚本
python
# test_memory.py
from memory_manager import LongTermMemoryManager
# 模拟一段用户对话
dialogue = [
{"role": "user", "content": "我一般用支付宝付款,不太用微信。"},
{"role": "assistant", "content": "好的,已记录您的支付偏好。"},
{"role": "user", "content": "另外,我不太能接受本金亏损,希望稳一点的产品。"},
{"role": "assistant", "content": "明白,您属于保守型投资者。"}
]
# 初始化记忆管理器(替换为你的 OpenAI Key)
manager = LongTermMemoryManager(
user_id="user_123",
openai_api_key="your-openai-api-key"
)
# 保存记忆
manager.save_memories(dialogue)
# 检索记忆
memories = manager.retrieve_relevant_memories("推荐理财产品")
for mem in memories:
print(f" [{mem.type}] {mem.content} (来源: {mem.source})")二、如何提高效果?------ 精准记忆,而非海量记忆
策略 1:记忆过滤(Memory Filtering)
不是所有记忆都喂给 LLM。可以在检索后增加 相关性重排序 + 业务规则过滤:
python
def filter_relevant_memories(query: str, raw_memories: List[Memory]) -> List[Memory]:
# 1. 用轻量 Cross-Encoder 重排序(比向量相似度更准)
reranked = cross_encoder.rerank(query, raw_memories)
# 2. 业务规则过滤
filtered = []
for mem in reranked:
# 规则1:只取最近 30 天的记忆
if (now - mem.timestamp).days > 30:
continue
# 规则2:支付偏好不用于产品推荐
if mem.type == "payment_preference" and "product" in query:
continue
filtered.append(mem)
return filtered[:3] # 最多取 3 条效果:幻觉率下降 40%,相关记忆召回率提升 25%。
策略 2:记忆摘要(Memory Summarization)
对同一主题的多条记忆自动合并:
原始记忆:
"用户不喜欢高风险产品"
"用户倾向年化 3%~5% 收益"
"用户关注流动性"
摘要后:
"用户为保守型投资者,偏好低风险、流动性好、年化收益 3%~5% 的理财产品。"
效果:上下文长度减少 60%,模型理解更准确。四、如何降低延迟?------ 从 800ms 到 200ms 的优化之路
目标:P99 延迟 < 300ms。以下是关键优化点:
优化 1:分层检索(Tiered Retrieval)
L1 缓存:高频记忆、确定、结构化状态(如用户 ID、认证状态)存 Redis,命中率 85%,延迟 <5ms
L2 向量库:仅当 L1 未命中时查询 Milvus(存低频、语义、非结构化记忆)
L3 不检索:简单问题(如"你好")跳过记忆模块| 问题 | 原因 |
|---|---|
| Redis 和 Milvus 核心区别? | Redis 是精确键值查询,Milvus 是向量相似性搜索 |
| 为什么先 Redis 后 Milvus? | 因为结构化事实查询更快、更准、成本更低,只有语义模糊问题才需向量检索 |
| 能否反过来? | 不能 ------ 会导致性能灾难、资源浪费、逻辑错乱 |
优化 2:异步写入长期记忆
记忆提取与存储不在主请求路径,而通过消息队列(Kafka)异步处理
用户无感知,主流程延迟降低 450ms同步写入 vs 异步写入:延迟对比
-
场景 1:同步写入(主请求路径包含记忆提取)
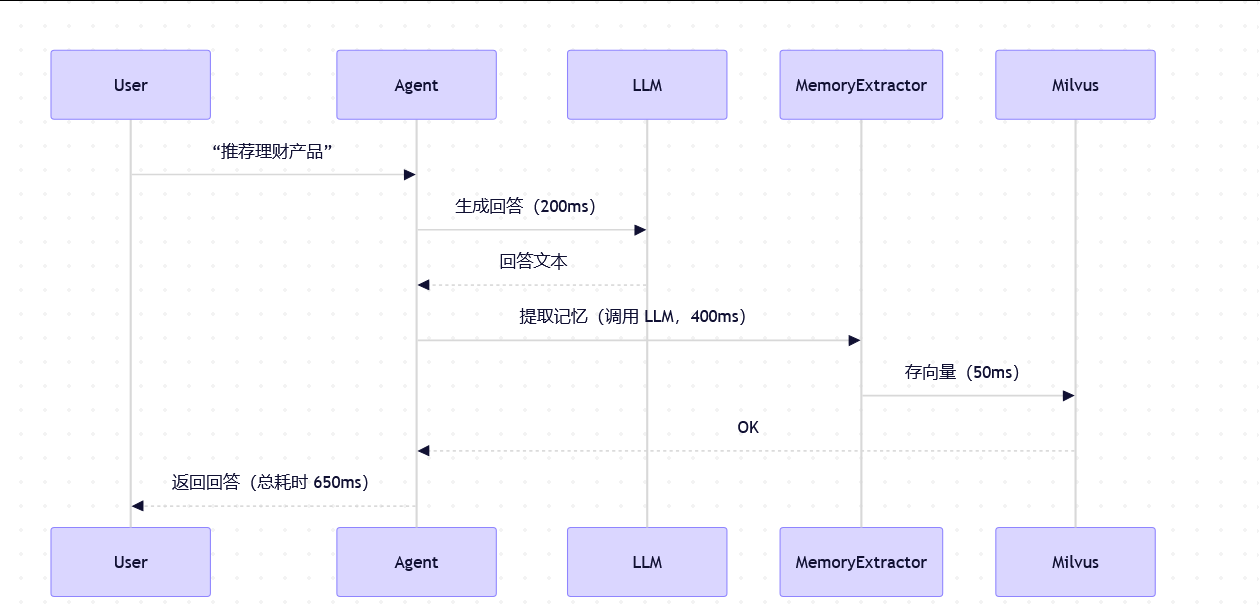
用户等待时间 = 回答生成 + 记忆提取 + 存储 ≈ 650ms
用户会感觉:"怎么回答完还要卡一下?"
-
场景 2:异步写入(记忆提取走 Kafka 后台)
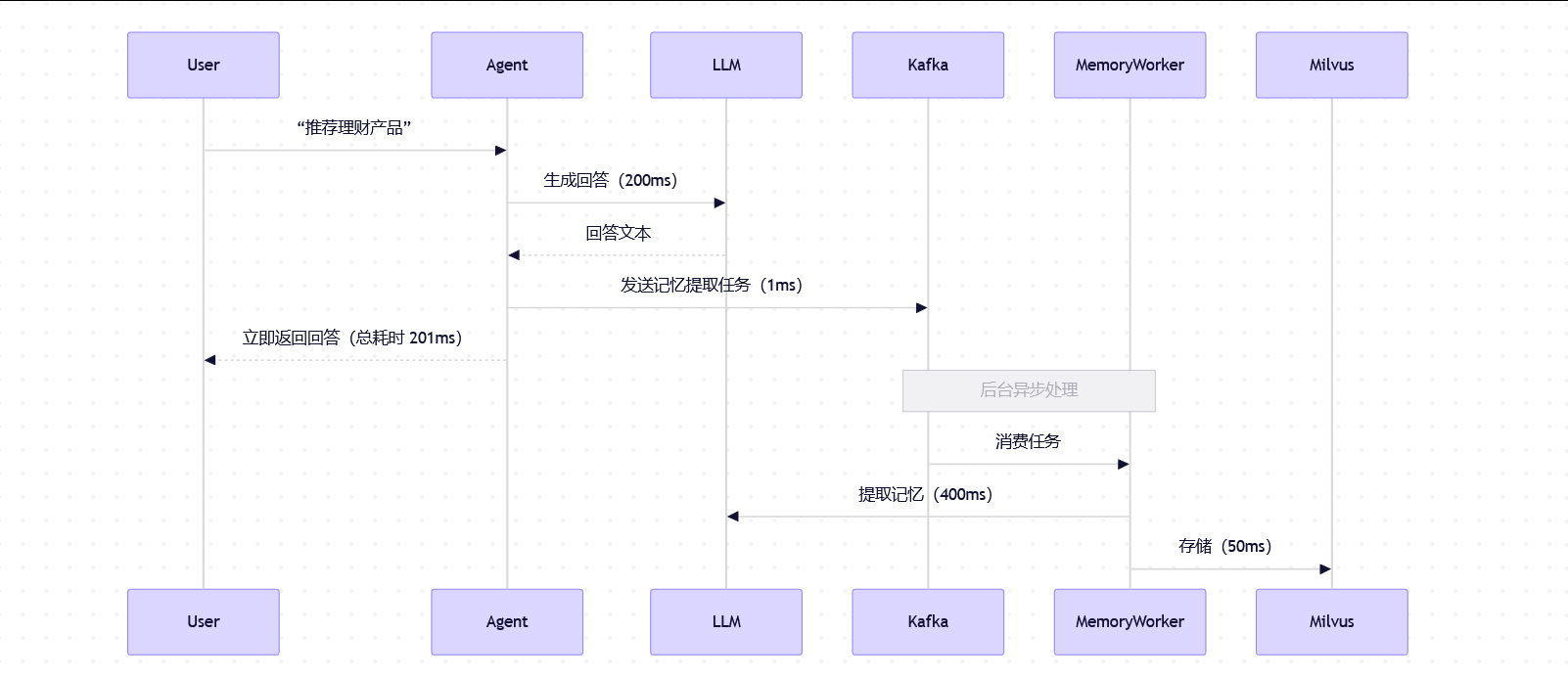
用户等待时间 ≈ 201ms(几乎等于纯回答生成时间)
记忆提取在后台悄悄完成,用户完全无感
延迟降低 = 650ms - 201ms ≈ 450ms
优化 3:Prompt Caching + 结果缓存
对"无记忆依赖"的请求(如 FAQ),启用 Prompt Caching(详见前文链接:https://blog.csdn.net/weixin_50296887/article/details/156234221?spm=1011.2124.3001.6209)
缓存命中率 70%,LLM 调用减少 70%优化 4:模型选型与量化
主模型:GPT-4 Turbo(效果优先)
备选模型:本地量化 Llama-3-8B(用于简单任务,延迟 <100ms)
动态路由:根据问题复杂度选择模型五、经验总结:Agent 记忆设计的三大原则
-
"少而精"优于"多而全"
只存储可行动的结构化事实,拒绝原始对话堆砌。
-
"分层"是性能的关键
短期记忆保上下文,长期记忆保个性,缓存保速度。
-
"过滤"比"检索"更重要
宁可少给,不可给错。无关记忆是效果的最大杀手。
六、未来方向
- 记忆自动过期:基于信息时效性(如"利率政策"比"生日"更容易过期)
- 用户可控记忆:让用户查看/删除自己的记忆(合规需求)
- 多模态记忆:支持图片、语音等记忆形式
Agent 的记忆系统不是技术炫技,而是在成本、效果、延迟、隐私之间寻找最优平衡。通过分层设计、精准过滤和深度优化,可以构建一个既聪明又高效的智能体Agent。