
2024.11
1.摘要
background
数据不平衡问题:音视听语音识别(AVSR)利用唇语视频来提高噪音环境下的识别性能,但高质量的视频数据(几千小时)远少于纯音频数据(数十万小时)。
现有方法的局限:目前的AVSR模型通常在有限的视频数据上从头训练,或者简单地微调,这导致文本解码器的能力不如那些在大规模音频数据上训练的模型(如Whisper)。
目标:利用在大规模数据上训练好的Whisper模型的强大解码能力,将其适配到视频输入上,以解决训练数据差异带来的问题 。
innovation
Whisper-Flamingo****架构 :受视觉-语言模型 Flamingo 的启发,提出了一种通过门控交叉注意力(Gated Cross Attention)将视觉特征注入到 Whisper 模型中的方法 。
高效适配 :保持 Whisper 的大部分参数冻结,只训练新插入的交叉注意力层,使其能够利用 AV-HuBERT 提取的视觉特征 。
多任务能力 :该模型不仅能做英语语音识别(ASR/AVSR),还能利用同一套参数进行英语到其他语言(En-X)的语音翻译,且在噪声环境下表现优异 。
- 方法 Method
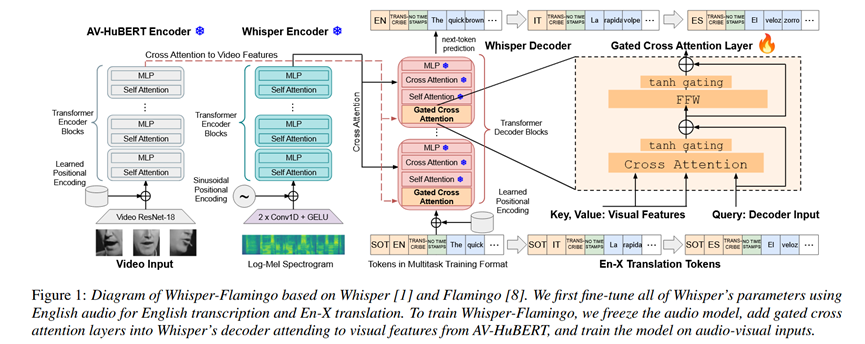
总体 Pipeline
Whisper-Flamingo 的构建分为两个阶段:
- 纯音频微调 (Audio-Only Fine-tuning):首先在目标域(如 LRS3)上微调纯音频的 Whisper 模型,以适应特定领域的声学特征和文本分布 11。
- 音视听适配 (Audio-Visual Adaptation):冻结微调后的 Whisper 音频编码器和解码器的大部分参数,在解码器层中插入新的"门控交叉注意力层"。同时使用预训练的 AV-HuBERT 作为视觉编码器(冻结参数),仅训练新插入的层 12。
具体模块与输入输出
输入 (Input):
音频:80-bin Log-Mel 频谱图(16kHz采样)13。
视频:嘴唇区域的灰度视频帧(25fps),经过预训练的 AV-HuBERT Large 提取视觉特征。
文本 Prompt:SOT(Start of Transcript)等控制 token。
视觉编码器 (Visual Encoder):使用 AV-HuBERT Large,并在训练中冻结其权重(但允许 dropout 和 BN 更新)16161616。
解码器融合机制 (Gated Cross Attention):
在 Whisper 解码器的每个 Block 的自注意力层(Self Attention)之前插入门控交叉注意力层 17。
公式:
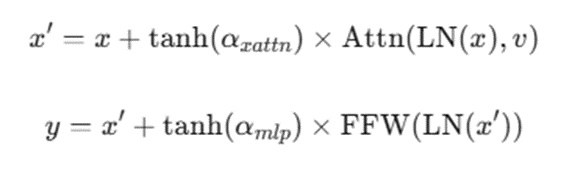
其中x是解码器输入,v 是视觉特征。
初始化策略:可学习参数 \\alpha 初始化为 0。由于 \\tanh(0)=0,初始状态下该层为恒等映射(Identity),保留了 Whisper 原有的纯音频能力,随着训练逐渐引入视觉信息 18。
输出 (Output):预测的文本 token 序列(英语转录或翻译文本)19。
- 实验 Experimental Results
数据集
训练集:LRS3 (433h), LRS3 + VoxCeleb2 (1759h) 。
评测集:LRS3 Test, LRS2 Test, MuAViC (用于翻译评测) 。
噪声设置:使用 MUSAN 和 LRS3 的 babble noise 进行 0-SNR 的加噪测试 。
实验结论
- LRS3 英语识别:
Whisper-Flamingo 达到了 SOTA 效果。Clean WER 为 0.68%,Noisy (0-SNR) WER 为 5.6%。相比纯音频 Whisper (Noisy WER 11.7%),性能大幅提升 。
相比其他 AVSR 模型(如 AV-HuBERT),在低信噪比下表现更好且参数利用率更高 。
- LRS2 英语识别:
达到了 SOTA AVSR WER (1.4%),优于 AutoAVSR 等之前的方法 。
- En-X 语音翻译 (MuAViC):
Whisper-Flamingo 能够用同一个模型处理转录和翻译。
在噪声环境下,翻译性能显著优于纯音频 Whisper(BLEU 从 18.6 提升至 20.5)。
- 消融实验:
对比 Early Fusion 和 Late Fusion,门控交叉注意力(Gated Cross Attention)在噪声环境下效果最好(WER 7.0% vs Early Fusion 10.0%)。
- 总结 Conclusion
通过借鉴视觉-语言模型(Flamingo)的架构,利用"门控交叉注意力"机制,可以有效地将预训练的视觉特征(AV-HuBERT)注入到冻结的强力语音模型(Whisper)中。这种方法既保留了 Whisper在大规模数据上学到的鲁棒解码能力,又以较低的训练成本实现了抗噪的音视听识别和翻译。