
2022 ICLR
1.摘要
background
多模态感知的重要性: 语音感知本质上是多模态的(听觉+视觉),视觉线索(如唇动)在嘈杂环境中有助于理解语音 。
数据匮乏与标注昂贵: 现有的唇读(Visual Speech Recognition)模型严重依赖大量的文本标注数据才能达到可接受的精度(例如之前的SOTA模型使用了3.1万小时的转录视频) 。
自监督学习的缺失: 现有的自监督语音表示学习(如wav2vec 2.0, HuBERT)主要集中在音频模态,尚未充分利用视频中音频和唇动之间的紧密耦合关系 。
innovation
AV-HuBERT****框架: 提出了一种音频-视觉隐藏单元BERT模型。通过掩码预测(Masked Prediction)任务,预测由聚类生成的离散隐藏单元 。
跨模态知识蒸馏: 利用音频流(MFCC或中间特征)生成目标聚类中心,指导视觉特征的学习。因为音频与音素的相关性比原始视觉信号更强,这种方式能有效引导视觉表征的学习 。
低资源下的卓越性能: 在仅使用30小时标注数据的情况下,性能超过了之前使用3.1万小时数据的SOTA模型 。
- 方法 Method
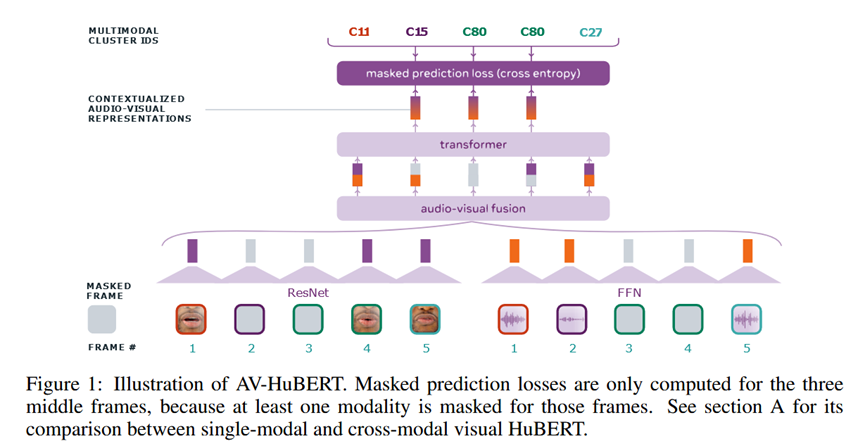
该方法是一个迭代式的自监督学习框架。核心Pipeline是"特征聚类 (Feature Clustering)"与"掩码预测 (Masked Prediction)"交替进行。输入是带有掩码的音频和视频帧,输出是目标聚类ID的概率分布。
具体细节:
- 输入与网络架构 (Input & Architecture):
视觉编码器: 使用修改后的 ResNet-18 处理唇部ROI序列 11。
音频编码器: 使用简单的线性投影层处理对齐的 Log Filterbank 特征 12。
融合与主干: 音频和视觉特征在通道维度拼接(Concatenation)后,输入到 Transformer 编码器中。
- 核心机制 (Core Mechanisms):
模态 Dropout (Modality Dropout): 为了防止模型过度依赖音频(音频包含更丰富的语音信息),训练时以一定概率丢弃某一模态的全部输入(通常是把音频置零,迫使模型仅靠视频预测目标),这缩小了预训练(多模态)和下游微调(仅视频)之间的差异。
目标生成 (Target Generation):
第一次迭代: 对音频的 MFCC 特征进行 K-means 聚类生成离散标签。
后续迭代: 使用上一轮训练好的 AV-HuBERT 模型提取的中间层特征进行聚类,生成更高质量的多模态目标 16。
掩码策略 (Masking by Substitution): 对于视频流,不是简单地用零填充,而是用同一视频中随机抽取的其他片段进行替换。这迫使模型识别"伪造"帧并推断原始内容,增加了任务难度和特征的语义性。
- 输出与损失 (Output & Loss):
模型预测被掩码位置所属的聚类中心 ID(Cluster ID)。
损失函数为 Cross-Entropy Loss,主要计算掩码区域的预测损失 18。
- 实验 Experimental Results
数据集:
LRS3 (英语): 433小时标注视频,用于微调和部分预训练 。
VoxCeleb2 (多语言): 2442小时无标注视频(筛选出1326小时英语内容),用于大规模预训练 。
主要实验结论:
低资源唇读 SOTA: 使用 1759小时无标注数据预训练,仅用 30小时 标注数据微调,AV-HuBERT (Large) 达到 32.5% WER,优于之前使用 31,000小时数据的模型 (33.6%) 。
高资源上限突破: 使用全部 433小时标注数据,WER 降至 28.6%。结合 Self-training 进一步降至 26.9%,创造新纪录 。
ASR 性能提升: AV-HuBERT 生成的聚类中心用于预训练音频模型,在 ASR 任务上也超越了纯音频的 HuBERT 。
多语言预训练收益: 在英语标注数据极少时,混入非英语的预训练数据能显著降低 WER,证明了唇动与发音关联的语言通用性 。
训练细节:
模型规格:
BASE: 12层 Transformer, 103M 参数 。
LARGE: 24层 Transformer, 325M 参数 。
训练时长/硬件: LARGE 模型在 64块 V100 GPU 上训练。使用 1759小时数据时,每次迭代约需 3.6天,共进行 5次迭代 。
创新点(简洁版): 首次证明了通过音频驱动的聚类和多模态掩码预测,可以在极少标注数据下实现高精度唇读。
- 总结 Conclusion
音频信号与唇部运动不仅高度相关,而且音频包含更清晰的语音结构。AV-HuBERT 通过"听音"来生成高质量的监督信号(聚类中心),并通过 Modality Dropout 迫使视觉编码器"学会看唇",从而彻底改变了依赖大量文本标注的唇读训练范式 。