Secure Retrieval-Augmented Generation against Poisoning Attacks
https://arxiv.org/abs/2510.25025
IEEE BigData2025
RAGuard
整体而言,扩大检索范围+两阶段过滤策略
扩大检索范围不用额外阐述,就是PoisonedRAG防御方案里面的DTF
块状困惑度过滤
作者说计算整个文本的困惑度通过实验证明无效,因此作者采取的方案是把每一个扩大检索得到的文本分为两块,大致均匀的分割文本或者使用标点符号。
源于这个观察:有毒文本由于缺乏流畅性和连贯性,在不同部分往往表现出困惑度的仙湖波动,但是良性文本则保持更加一致的困惑度得分。所以作者引入了困惑度差异PD得分,衡量划分出来的两个快之间的困惑度差异,计算方法为前半部分的困惑度减去后半部分的困惑度。

【摒弃早期的阈值分界法,使用假设检验方案。两种方案同时确保有毒文本被检测出来:一个是把待检测文本划分前后两部分,分别计算困惑度,求差值;另一个是求最大困惑度值。如果两个方案中任意一个越过了分界,则认为是有毒文本。基于这样的假设:有毒文本往往前言不搭后语,而良性文本表达更连贯,划分两部分后每一部分的PPL都很小,并且PPL差异小】
文本相似度过滤

【有毒文本往往和目标查询的相似度异常的高,所以对相似度也进行假设检验】

【检索N条相关文本,每一个都计算PD、PM和TS值,如果任何一个指标越界,那么就剔除。如果最后保留的条目大于K条,就使用前k】
数学证明


实验
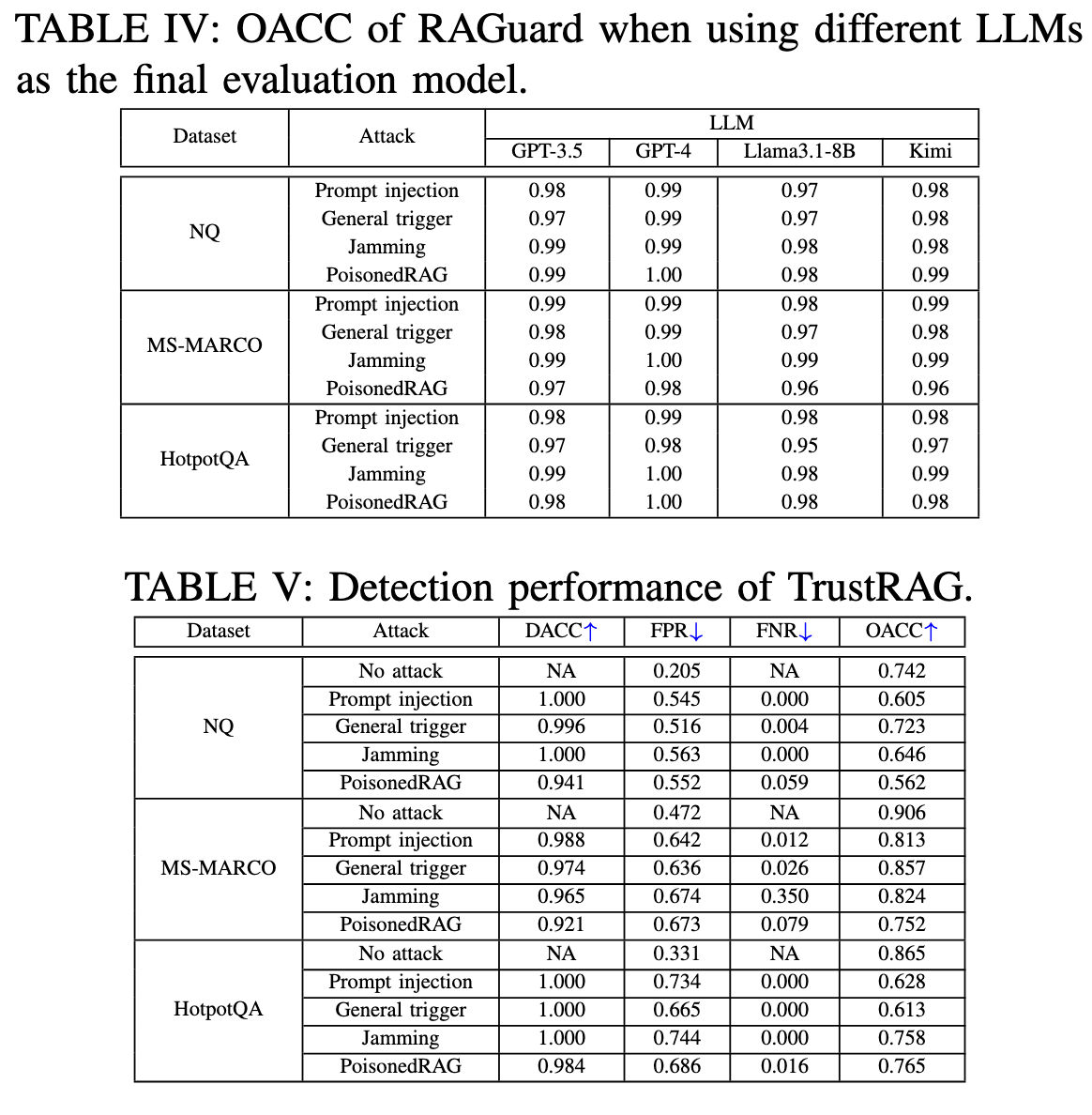
数据集:NQ,MS-MARCO,HotpotQA。使用LLM重写NQ和MS-MARCO,得到extended版本的ENQ和EMS_AMRCO
攻击方案:提示注入、通用触发器Phantom、干扰攻击JammingRAG和PoisonedRAG
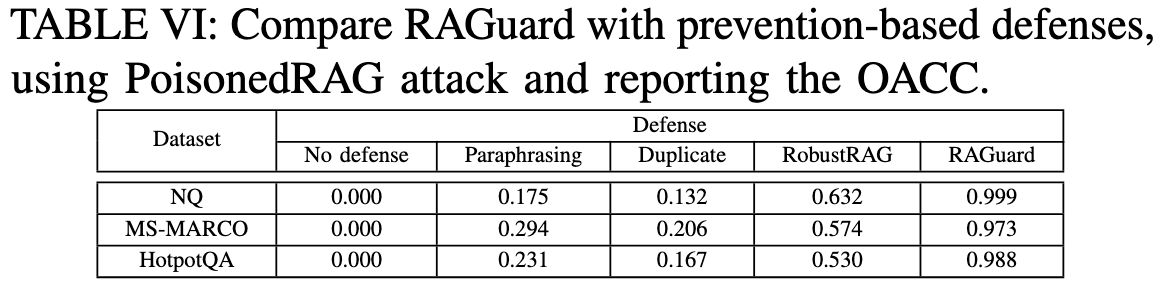
baseline:困惑度和困惑度窗口检测、TrustRAG、释义、重复文本过滤和RobustRAG
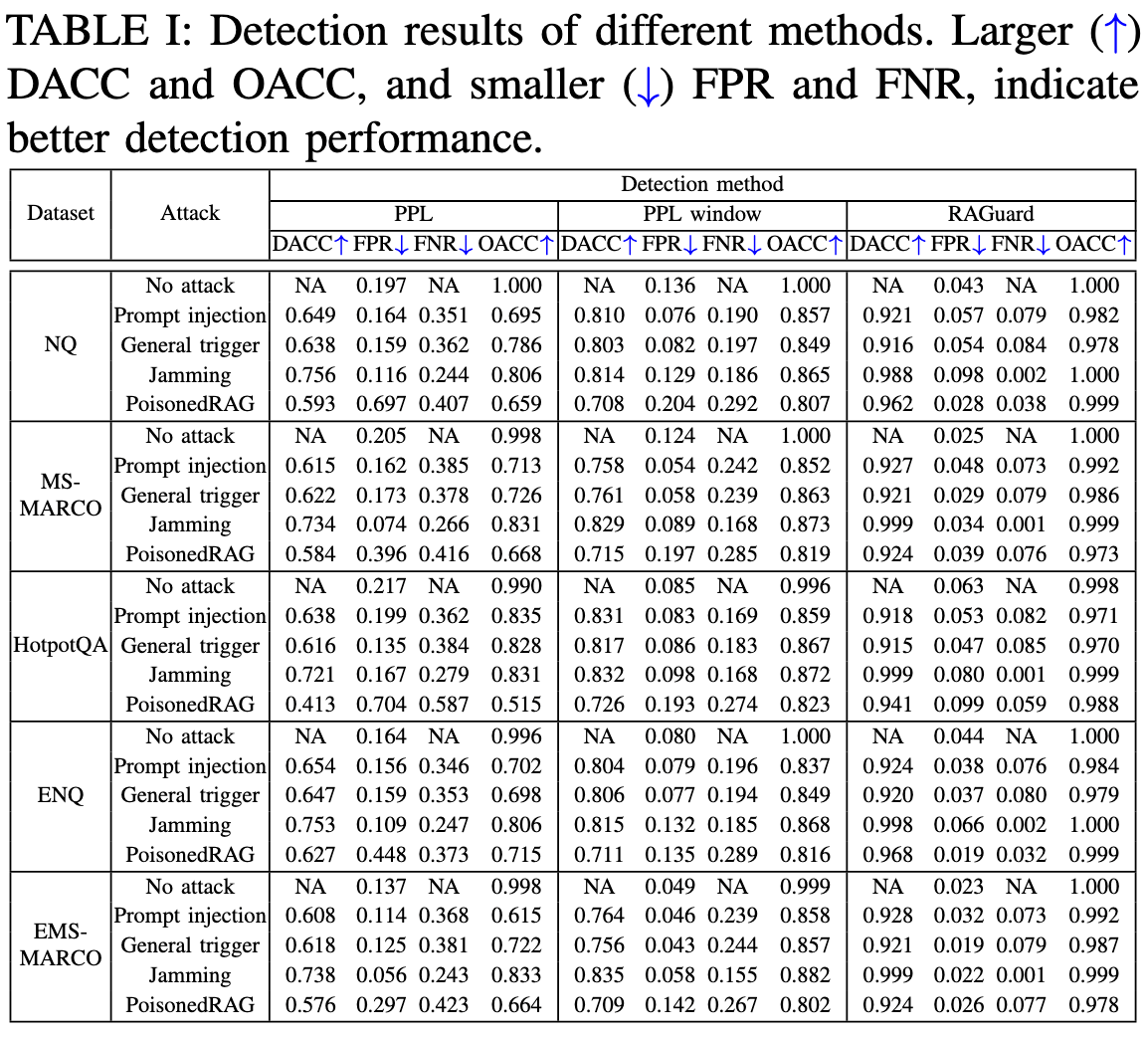
评估指标:检测准确率DACC(正确分类的样本包括正面和负面站总样本数的比例);误报率FPR(干净/良性文本被错误分类为重度文本的比例);漏报率FNR(未能监测到有毒文本的比例);输出准确率OACC(LLM生成正确答案的目标查询的比例)
参考PoisonedRAG,为每个数据集使用相同的100个封闭的目标查询和答案
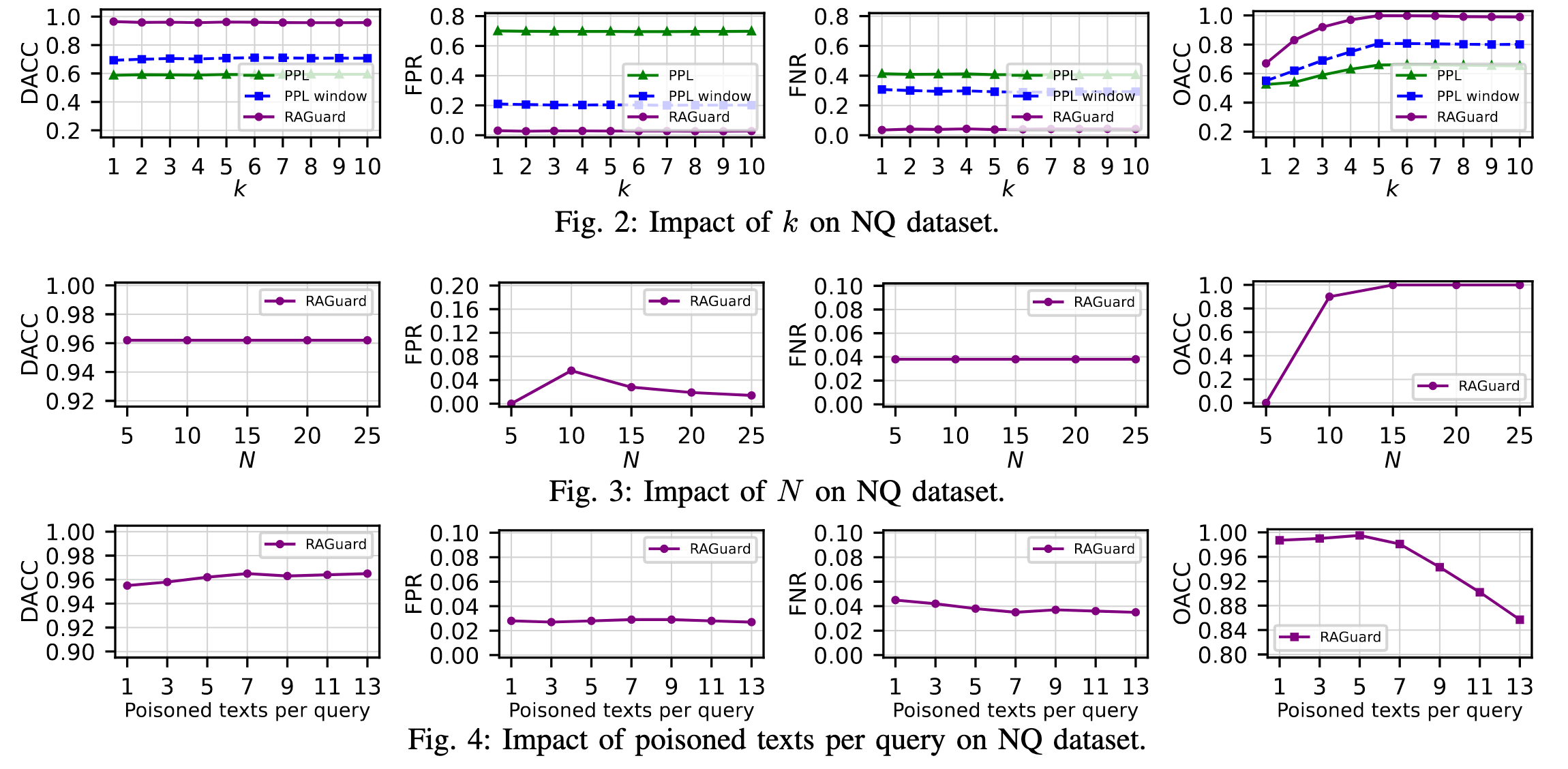
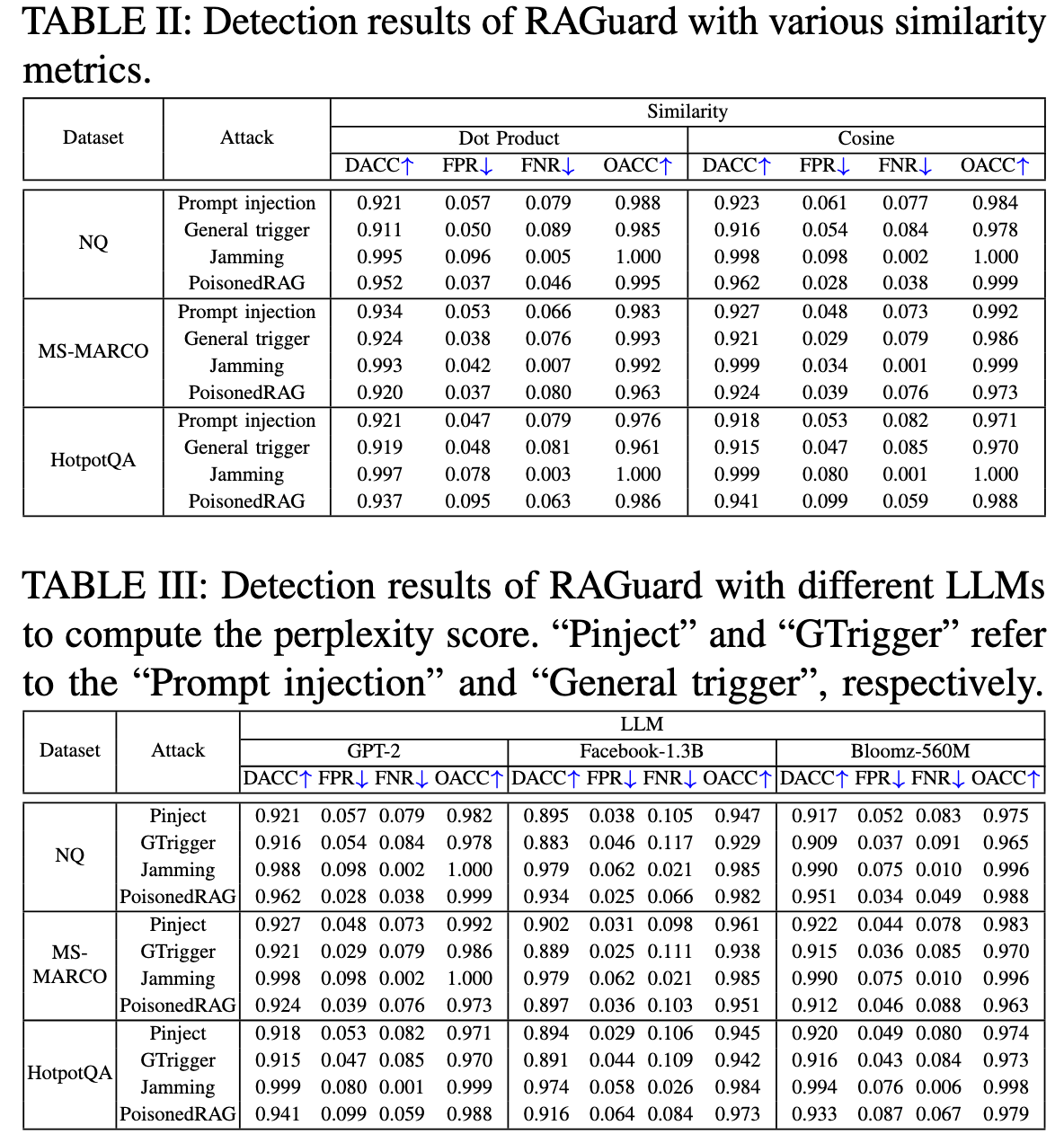
每个目标问题注入5个恶意文本,使用gpt3.5作为最终评估的模型,使用GPT2计算困惑度,使用点积计算相似度,使用Contriever检索器,检索top5个文本。RAGuard中N设置为3k,随机抽取1000个文本以构成集合S,显著性水平设置为α =2.5%
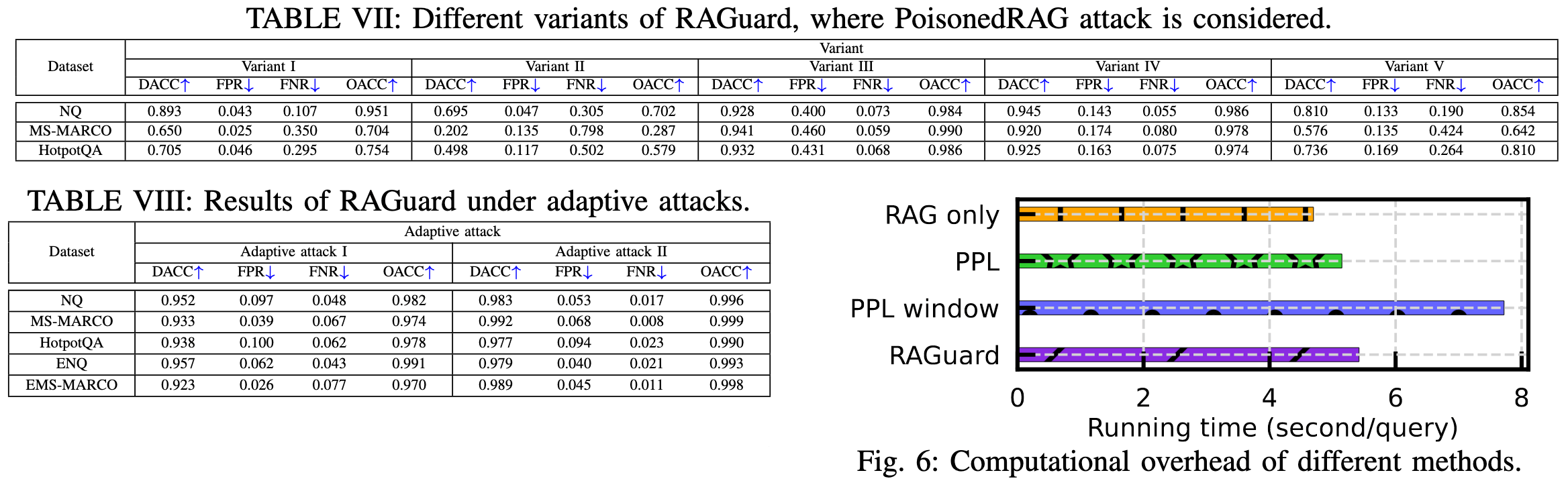
自适应攻击 I: 此攻击使用 GPT-4 自动释义中毒文本。 生成的输出在语义上是恶意的,但在句法上经过精心设计,使其看起来像良性样本。 用于生成这些中毒文本的具体提示如下:

自适应攻击 II: 在此攻击中,中毒文本由人工标注员手动重写。 目的是重构和改写原始内容,使其在风格和语言特征上都难以与干净文本区分开来。