
定位并从场景级点云中检索物体是机器人技术和增强现实领域中一项具有广泛应用的挑战性问题。该任务通常被定义为开放词汇的三维实例分割。尽管现有方法表现出较强的性能,但它们严重依赖 SAM 和 CLIP 来生成和分类从点云所附图像中提取的三维实例掩码,导致巨大的计算开销和缓慢的处理速度,限制了其在实际应用中的部署。
《Retrieving Objects from 3D Scenes with Box-Guided Open-Vocabulary Instance Segmentation》提出了一个新想法,如何用"四两拨千斤"的巧思,让机器真正"看懂"这个复杂多变的三维世界。
**论文链接:**https://arxiv.org/abs/2512.19088v1

Open-YOLO 3D 通过使用实时二维检测器对预训练三维分割器直接从点云生成的类别无关掩码进行分类,缓解了该问题,消除了对 SAM 和 CLIP 的依赖,并显著减少了推理时间。然而,Open-YOLO 3D 通常难以泛化到三维训练数据中出现频率较低的物体类别。本文提出了一种方法,通过二维开放词汇检测器的引导,从 RGB 图像生成新物体的三维实例掩码。我们的方法继承了二维检测器识别新物体的能力,同时保持了高效的分类,实现了从开放文本查询中快速准确地检索罕见物体实例。
一、方法概述
我们的方法流程如图 1 所示。
**输入:**场景的三维点云 P(包含 N 个点),以及 Kf个 RGB 图像 I、多视角深度信息、相机内参矩阵 I和外参矩阵 E。
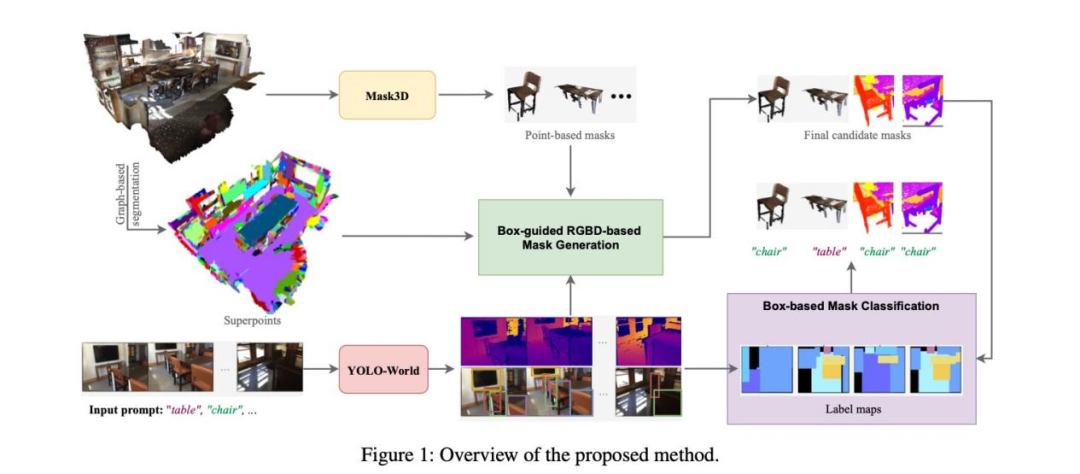
**任务:**通过生成相应的三维实例掩码,检索并定位三维点云中与给定文本查询匹配的物体。
主要步骤:
点云预处理与三维掩码生成:
-
使用基于图的分割方法将点云P分割成几何一致的区域(超点),作为形成新实例的基本单元。
-
使用预训练的三维实例分割器 Mask3D 从点云P中提取二值实例掩码(称为基于点的掩码)。
二维检测与边界框引导的三维掩码生成:
-
使用开放词汇二维物体检测器 YOLO-World 从每个 RGB 图像
-
Ii中生成相关物体的边界框及类别标签。
-
将二维边界框内的像素利用深度和相机参数反投影到三维空间,形成三维定向边界框。
-
过滤掉与现有基于点掩码重叠度过高的冗余三维框。
-
为每个剩余的三维框提取其内部的超点,形成粗糙掩码。
-
跨帧合并这些粗糙掩码,构建基于 RGB-D 的物体候选集,并将其转换为二值掩码。
掩码融合与过滤:
-
将基于 RGB-D 的掩码与基于点的掩码合并为最终的候选实例集。
-
进行额外过滤,移除与基于点掩码高度重叠的新物体掩码,优先保留几何质量更高的基于点掩码。
基于边界框的掩码分类:
-
利用二维检测器的结果(类别标签)构建每个 RGB 图像的标签图。
-
将每个三维候选掩码投影到可见的二维标签图上,聚合其在最可见的几帧中的类别分布。
-
将实例分配给出现概率最高的类别。
Coovally官网目前已支持多模态3D检测任务类型训练,并且可以直接调用已部署好的相关模型算法,当然你也可以直接上传并使用本篇论文中的模型算法,进行项目复现。
Coovally平台不仅提供模型资源,还可以帮助你提供AI解决方案,可以扫描二维码,我们来给你提供解决方案!!

二、实验结果
我们在两个广泛使用的数据集上评估了我们的方法:
-
ScanNet200:包含 1201 个训练场景和 312 个验证场景的室内数据集,涵盖 198 个物体类别。
-
Replica:包含 8 个真实室内场景数字副本的合成数据集,涵盖 48 个物体类别。
主要结果:
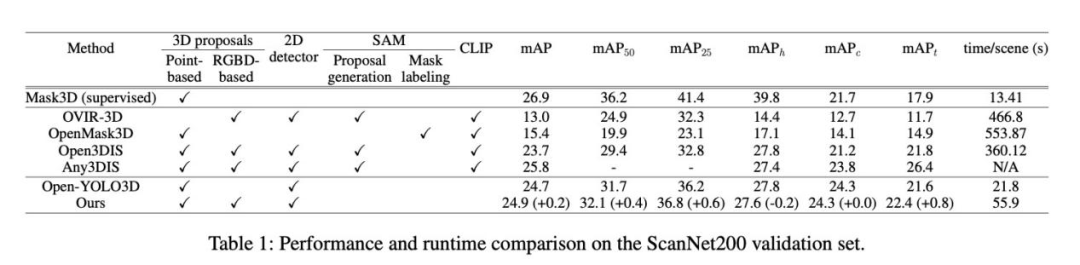
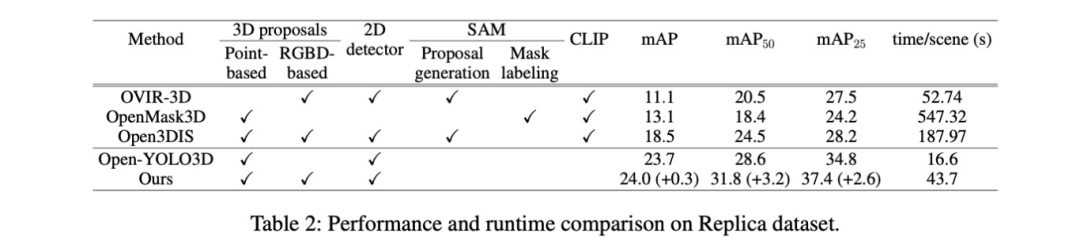
性能提升:如表 1 和表 2 所示,与 Open-YOLO 3D 相比,我们的方法在整体 mAP 上取得了提升,尤其是在尾类(罕见类别) 上表现更佳。这表明我们的框引导策略有效利用了二维检测器的知识来发现三维模型易忽略的罕见物体。
效率:我们的方法在每个场景的处理时间上(ScanNet200约56秒,Replica约44秒)远快于依赖 SAM 和 CLIP 的方法(通常需要数分钟),虽然比纯依赖三维分割的 Open-YOLO 3D(约22秒)稍慢,但仍在可接受的实时交互范围内,同时带来了显著的性能增益。
定性结果:如图 2 所示,我们的方法能够成功检索出像"日历"这样在三维训练数据中罕见的物体,而 Open-YOLO 3D 则无法检测到。

结论与展望
我们提出了一种新颖的、基于边界框引导的开放词汇三维实例分割方法,用于从语言查询中检索三维点云中的物体。核心在于利用开放世界二维检测器的预测,将三维超点合并为与输入查询相关的罕见物体的实例掩码。实验表明,我们的方法优于仅依赖点云的方法,尤其对于三维训练数据中代表性不足的物体类别。
局限性与未来工作:
-
计算效率:将二维预测提升到三维的过程是目前的主要瓶颈。未来可以开发更高效的 GPU 实现来加速。
-
掩码质量:基于超点组装的新物体掩码可能存在噪声。未来可以探索高效策略(如选择性使用 SAM)来优化最终候选掩码的精度。
-
分类器扩展:未来可以考虑集成开放世界的三维物体分类器,以进一步提升分类效率和能力。
