Ceph 分布式存储完整实践指南
一、Ceph 核心概述
1. 什么是 Ceph
Ceph 是一款开源、分布式、软件定义存储系统,旨在提供高可用性、无限扩展性和统一存储服务(对象、块、文件系统存储)。其核心设计理念是 "一切皆对象",所有数据最终以对象形式存储在底层 RADOS(Reliable Autonomic Distributed Object Store)系统中,摆脱传统存储的单点依赖。
核心特性:
- 架构去中心化,无网关或元数据服务器瓶颈
- 支持 x86/ARM 混合架构部署,兼容通用服务器硬件
- 自动数据平衡与故障恢复,无需人工干预
- 存储容量可从 TB 级扩展至 EB 级,性能随节点增加线性增长
- 支持数据强一致性,确保多副本数据同步可靠
- 与 Linux 内核、OpenStack、Kubernetes、CloudStack 等生态深度集成
2. 核心用户角色与应用场景
2.1 用户角色细分
| 角色 | 核心职责 | 适用场景 |
|---|---|---|
| 存储管理员 | 集群规划、安装配置、性能优化、灾难恢复方案设计、自动化集成、用户培训 | 企业级生产环境、大型云平台 |
| 存储操作员 | 日常监控(Dashboard/CLI)、警报响应、故障设备更换、日志分析 | 运维团队一线操作岗 |
| 应用开发人员 | 基于 librados/RBD/CephFS 开发应用,集成存储功能 | 云原生应用、大数据平台开发 |
| 云操作员 | 管理 OpenStack/OpenShift 等云平台与 Ceph 的集成 | 混合云 / 私有云环境 |
| 基础架构架构师 | 设计 Ceph 集群拓扑、资源规划、性能评估 | 集群建设初期规划阶段 |
| 数据中心操作员 | 底层硬件维护、存储资源供给 | 大型数据中心运维 |
2.2 典型应用场景
- 高性能计算(HPC):支撑大规模并行数据处理
- 虚拟化 / 云平台:为虚拟机、容器提供持久化存储(如 OpenStack Cinder、K8s PV)
- 内容存储与分发:图片、视频、日志等非结构化数据存储
- 大数据与人工智能:海量训练数据存储与访问
- 备份与灾难恢复:跨集群数据复制、异地容灾
- 智慧城市:物联网设备产生的海量时序数据存储
3. 版本演进与生命周期
3.1 版本命名与编号规则
- 版本格式:x.y.z(x = 发行周期,y = 发行类型,z = 发行号)
- x.0.z:开发版
- x.1.z:候选版
- x.2.z:稳定版 /bugfix 版
- 历史版本:从 Dumpling(0.67.x)开始支持 LTS,最新稳定版为 Squid(19.2.X)
- 发布周期:2017 年前每年 2 个稳定版,Nautilus(14.2.0)后每年 3 月发布 1 个 LTS 版本,支持周期 2 年
3.2 主流 LTS 版本生命周期
| 版本代号 | 版本号 | 发布日期 | 退役日期 | 核心改进 |
|---|---|---|---|---|
| Reef | 18.2.X | 2023-08-07 | 2025-08-01 | 优化性能监控、增强多站点复制 |
| Quincy | 17.2.X | 2022-04-19 | 2024-06-01 | 提升 RBD 镜像性能、改进 CephFS 稳定性 |
| Pacific | 16.2.X | 2021-03-31 | 2023-06-01 | 引入 CephFS Mirror、增强 RGW 多租户支持 |
| Nautilus | 14.2.X | 2019-03-01 | 2021-06-01 | 统一存储池管理、优化 OSD 性能 |
二、Ceph 架构深度解析
1. 核心组件详解
1.1 底层存储:RADOS
RADOS 是 Ceph 的核心存储引擎,由 OSD、MON、MGR 组成,提供:
- 分布式对象存储:所有数据以对象形式存储,每个对象包含数据、元数据和唯一标识符
- 自我修复:检测 OSD 故障,自动复制数据到健康 OSD
- 自我管理:自动数据平衡、负载均衡
- 无单点故障:多副本存储,MON 集群仲裁机制
1.2 核心守护进程
| 组件 | 核心功能 | 部署要求 | 关键配置 |
|---|---|---|---|
| 监视器(MON) | 维护集群映射(Cluster Map),包括 MON/OSD/MDS 状态、配置信息;通过 Paxos 算法达成集群状态共识 | 奇数个节点(推荐 3/5 个),确保仲裁 | 监听端口 6789(v1)、3300(v2);数据目录 /var/lib/ceph/fsi**d /mon.host |
| 对象存储设备(OSD) | 存储数据对象,处理数据复制、恢复、再平衡;通过 CRUSH 算法定位数据 | 每个物理磁盘对应 1 个 OSD 守护进程;推荐配置 SSD 作为 OSD 日志 | 端口范围 6800-7300;支持 XFS 文件系统;日志建议独立 SSD 部署 |
| 管理器(MGR) | 收集集群指标(CPU / 内存 / IO 等),提供 Web Dashboard 和 REST API;支持第三方监控集成(Zabbix/Prometheus) | 至少部署 2 个,跨故障域部署 | 默认端口 8443(Dashboard);需启用相关模块(dashboard、prometheus) |
| 元数据服务器(MDS) | 仅为 CephFS 提供元数据服务(文件权限、目录结构、时间戳等),加速 POSIX 命令执行 | 至少 1 个活跃节点 + 1 个备用节点 | 内存建议 4G+;元数据存储在 RADOS 池中 |
1.3 集群映射(Cluster Map)
集群映射是 Ceph 集群的 "拓扑地图",由 MON 维护,包含 5 类核心映射:
- 监视器映射(Monitor Map):集群 FSID、MON 节点地址与端口
- OSD 映射(OSD Map):OSD 列表、状态、池配置、副本数
- 放置组映射(PG Map):PG 状态、数据分布统计
- CRUSH 映射(CRUSH Map):存储设备层次结构、数据放置规则
- 元数据服务器映射(MDS Map):MDS 节点列表、状态
2. 数据存储原理
2.1 数据映射流程
- 客户端将数据封装为对象(包含对象 ID、数据、元数据)
- 通过公式
PG = hash(对象 ID) % PG 数量计算对象所属的放置组(PG) - CRUSH 算法根据 CRUSH Map 将 PG 映射到多个 OSD(主 OSD + 从 OSD)
- 客户端直接与主 OSD 通信,完成数据读写
2.2 数据读写流程
- 读取流程:客户端 → MON 获取集群映射 → 计算 PG 与主 OSD → 主 OSD 返回数据
- 写入流程:客户端 → MON 获取集群映射 → 计算 PG 与主 OSD → 主 OSD 写入数据并同步到从 OSD → 所有 OSD 确认后,主 OSD 向客户端返回成功
2.3 数据保护机制
- 复本池(Replicated Pool):默认 3 副本,数据复制到多个 OSD,故障时从副本恢复,读写性能好,存储开销高(3 副本开销 3 倍)
- 纠删码池(Erasure Code Pool):将数据分割为 k 个数据块 + m 个编码块,支持 k 个块故障时恢复,存储开销低(如 4+2 配置开销 1.5 倍),适合冷数据存储
3. 访问接口详解
3.1 原生 API:librados
- 支持 C/C++、Java、Python、Ruby 等多语言
- 直接操作 RADOS 对象,性能最优
- 适用于需要深度定制存储逻辑的场景
3.2 块存储:RBD(RADOS Block Device)
- 提供虚拟块设备,支持快照、克隆、镜像功能
- 支持 QEMU/KVM 直接挂载,集成 OpenStack Cinder、Kubernetes PV
- 核心特性:写时复制(COW)、读时复制(COR)、缓存优化(RBD Cache)
3.3 对象存储:RADOS Gateway(RGW)
- 兼容 Amazon S3 和 OpenStack Swift API
- 提供 RESTful 接口,支持 HTTP/HTTPS 访问
- 支持多租户、配额管理、数据加密、多站点复制
3.4 文件系统:CephFS
- 兼容 POSIX 标准,支持目录树结构、权限控制
- 适用于需要共享文件系统的场景(如大数据分析、容器共享存储)
- 依赖 MDS 服务管理元数据,支持快照、配额、ACL
三、Ceph 集群部署实战
1. 部署环境准备
1.1 硬件要求(生产环境)
| 组件 | 配置要求 | 备注 |
|---|---|---|
| 服务器 | 2U 机架式服务器 | 支持 12-24 块 SATA/SAS 硬盘 + 2-4 块 SSD |
| CPU | 8 核 16 线程以上 | 推荐 Intel Xeon 或 AMD EPYC 系列 |
| 内存 | 每 OSD 4-8G | 例如 12 个 OSD 节点建议 64G 内存 |
| 存储 | 数据盘:SATA/SAS 硬盘(4TB/8TB);缓存盘:SSD(400GB+) | OSD 日志建议单独 SSD 部署 |
| 网络 | 10Gbps 以太网 | 推荐双网卡绑定,分离 Public 网络和 Cluster 网络 |
1.2 系统环境配置
bash
# 1. 操作系统:CentOS Stream 8(最小化安装)
# 2. 关闭 SELinux
sed -ri 's/^SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
# 3. 关闭防火墙
systemctl disable firewalld --now
# 4. 配置 YUM 源(阿里云 Ceph 源)
cat > /etc/yum.repos.d/ceph.repo << 'EOF'
[Ceph]
name=Ceph
baseurl=https://mirrors.aliyun.com/centos-vault/8-stream/storage/x86_64/ceph-pacific
enabled=1
gpgcheck=0
EOF
# 5. 安装基础依赖
dnf install -y bash-completion vim lrzsz unzip rsync sshpass tar chrony
# 6. 时间同步
systemctl enable chronyd --now
chronyc sources
# 7. 配置主机名解析(所有节点)
cat >> /etc/hosts << EOF
192.168.108.11 ceph1.laogao.cloud ceph1
192.168.108.12 ceph2.laogao.cloud ceph2
192.168.108.13 ceph3.laogao.cloud ceph3
192.168.108.14 ceph4.laogao.cloud ceph4
192.168.108.15 ceph5.laogao.cloud ceph5
192.168.108.16 ceph6.laogao.cloud ceph6
192.168.108.10 client.laogao.cloud client
EOF
# 8. 配置免密登录(引导节点到其他节点)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
for node in ceph2 ceph3 ceph4 ceph5 ceph6; do
ssh-copy-id -o StrictHostKeyChecking=no root@$node
done2. 部署方式详解(Cephadm)
2.1 安装 Cephadm
bash
# 安装 cephadm(自动安装 podman 容器引擎)
dnf install -y cephadm
# 验证安装
cephadm --version
podman --version
# 提前拉取 Ceph 镜像(可选,加速部署)
podman pull quay.io/ceph/ceph:v16
podman pull quay.io/ceph/ceph-grafana:8.3.5
podman pull quay.io/prometheus/node-exporter:v1.3.12.2 引导集群
bash
cephadm bootstrap \
--mon-ip 192.168.108.11 \ # 引导节点 MON IP
--allow-fqdn-hostname \ # 允许使用长主机名
--initial-dashboard-user admin \ # Dashboard 管理员账户
--initial-dashboard-password laogao@123 \ # Dashboard 密码
--dashboard-password-noupdate # 不自动更新密码引导成功后输出关键信息:
- Dashboard 访问地址:https://ceph1.laogao.cloud:8443
- 管理员账户:admin
- 初始密码:laogao@123
- CLI 访问方式:
cephadm shell
2.3 扩展集群节点
bash
# 1. 获取集群公钥
ceph cephadm get-pub-key > ~/ceph.pub
# 2. 推送公钥到新增节点(以 ceph2 为例)
ssh-copy-id -f -i ~/ceph.pub root@ceph2.laogao.cloud
# 3. 添加节点到集群
ceph orch host add ceph2.laogao.cloud
ceph orch host add ceph3.laogao.cloud
ceph orch host add ceph4.laogao.cloud
# 4. 查看节点状态
ceph orch host ls2.4 部署核心服务
bash
# 1. 部署 MON 服务(指定 _admin 标签节点)
ceph orch host label add ceph2.laogao.cloud _admin
ceph orch host label add ceph3.laogao.cloud _admin
ceph orch apply mon --placement="label:_admin"
# 2. 部署 MGR 服务(与 MON 同节点)
ceph orch apply mgr --placement="label:_admin"
# 3. 部署 OSD 服务(使用所有可用磁盘)
ceph orch apply osd --all-available-devices
# 4. 部署监控组件(Prometheus/Grafana)
ceph orch apply prometheus --placement="count:1"
ceph orch apply grafana --placement="count:1"
ceph orch apply alertmanager --placement="count:1"
# 5. 查看服务状态
ceph orch ls
ceph status访问 dashboard

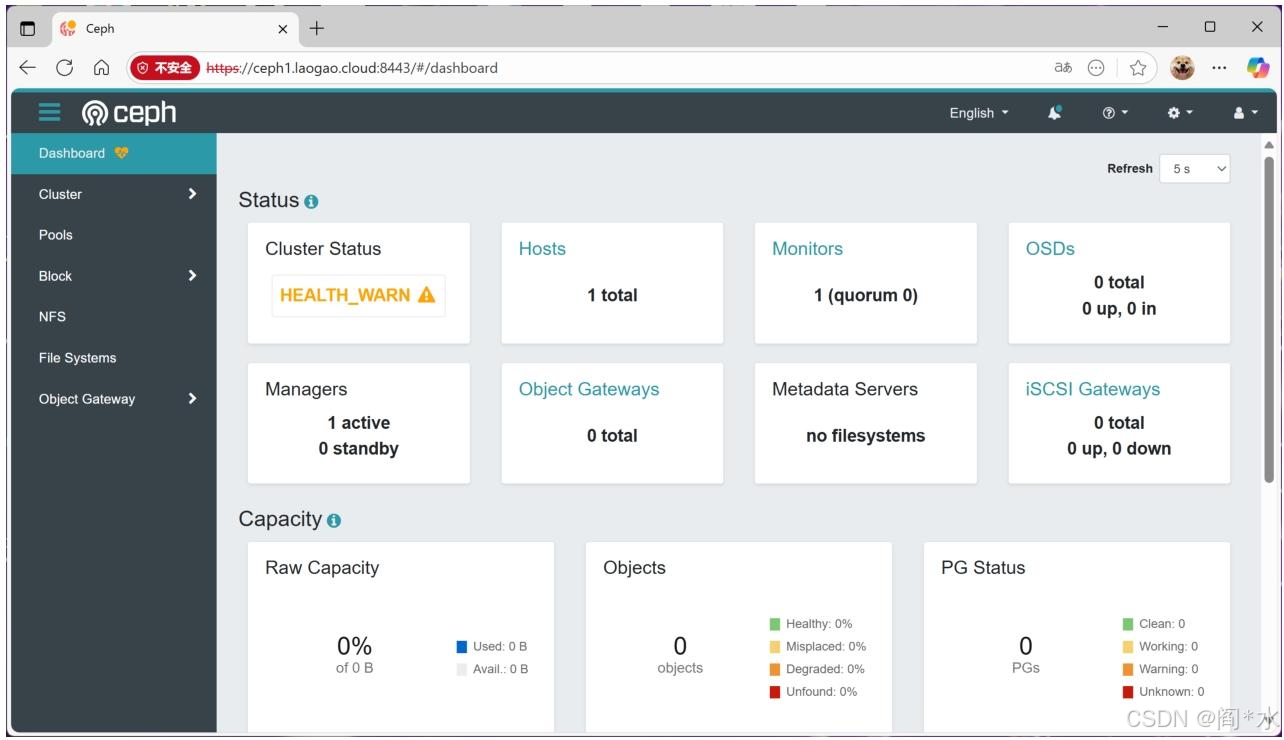
3. 集群验证与初始化
bash
# 1. 查看集群健康状态
ceph health # 正常状态为 HEALTH_OK
# 2. 查看 OSD 状态
ceph osd tree
# 3. 查看 MON 仲裁状态
ceph mon stat
ceph quorum_status -f json-pretty
# 4. 查看 Dashboard 状态
ceph mgr module enable dashboard
ceph dashboard status
# 5. 创建默认存储池(可选)
ceph osd pool create default_pool 128 128 replicated集群中运行的主要组件:
mgr,ceph 管理程序
monitor,ceph 监视器
osd,ceph 对象存储进程
rgw,ceph 对象存储网关
4. 其他部署方式对比
| 部署方式 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| Cephadm | 生产环境、独立集群 | 容器化部署、简化运维、支持 Dashboard | 仅支持 Octopus+ 版本 |
| Rook | Kubernetes 环境 | 与 K8s 深度集成、支持动态扩缩容 | 依赖 K8s 生态 |
| ceph-ansible | 复杂定制化部署 | 高度灵活、支持批量配置 | 配置复杂、学习成本高 |
| 手动部署 | 测试 / 研究环境 | 完全可控、适合学习 | 运维复杂、易出错 |
四、核心功能操作指南
1. 集群配置管理
1.1 配置源优先级
Ceph 配置生效顺序(从高到低):
- 命令行参数
- 运行时覆盖(ceph tell/daemon 命令)
- 本地配置文件(/etc/ceph/ceph.conf)
- 集中配置数据库(MON 管理)
- 编译默认值
1.2 配置文件管理
bash
# 配置文件路径(默认):/etc/ceph/ceph.conf
# 配置格式(INI 格式)
cat /etc/ceph/ceph.conf
[global]
fsid = 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
mon_host = 192.168.108.11,192.168.108.12,192.168.108.13
[mon]
public_network = 192.168.108.0/24
[osd]
osd_pool_default_size = 31.3 集中配置数据库操作
bash
# 查看所有配置项
ceph config ls
# 禁用mon服务自动扩展
[root@ceph1 ~]# ceph orch apply mon --unmanaged=true
# 启用 mon 服务自动扩展
[root@ceph1 ~]# ceph orch apply mon --unmanaged=false
# 查看服务中实例
[root@ceph1 ~]# ceph orch ps | grep crash
# 删除特定实例
[root@ceph1 ~]# ceph orch daemon rm crash.ceph1
Removed crash.ceph1 from host 'ceph1.laogao.cloud
# 删除crach服务(得先禁用服务和删除特定实例)
[root@ceph1 ~]# ceph orch rm crash
Removed service crash
# 查看特定配置项帮助
ceph config help public_network
# 查看当前配置
ceph config dump
# 设置全局配置
ceph config set global osd_pool_default_size 3
# 设置特定组件配置(如 MON)
ceph config set mon mon_allow_pool_delete true
# 运行时临时配置(重启失效)
ceph tell osd.* config set osd_memory_target 4294967296删除主机
从集群中删除主机流程:
- 禁用集群所有服务自动扩展
- 查看待删除主机上当前运行的服务
- 停止待删除主机上的所有服务
- 删除主机上的所有服务
- 删除osd在CRUSH中的映射
- 擦除osd盘中的数据
- 从集群中删除主机
bash
示例:删除 ceph2
首先,禁用集群中所有ceph服务自动扩展,进制自动部署osd。
[root@ceph1 ~]# for service in $(ceph orch ls |grep -v -e NAME -e osd| awk
'{print $1}');do ceph orch apply $service --unmanaged=true;done
[root@ceph1 ~]# ceph orch apply osd --all-available-devices --unmanaged=true
其次,删除主机上运行的服务。
# 查看ceph2上运行的daemon
[root@ceph1 ~]# ceph orch ps |grep ceph2 |awk '{print $1}'
crash.ceph2
mgr.ceph2.oetbal
mon.ceph2
node-exporter.ceph2
osd.2
osd.4
osd.7
# 删除相应 daemon
[root@ceph1 ~]# for daemon in $(ceph orch ps |grep ceph2 |awk '{print $1}');do
ceph orch daemon rm $daemon --force;done
# 手动清理crush信息
[root@ceph1 ~]# ceph osd crush rm osd.2
[root@ceph1 ~]# ceph osd crush rm osd.4
[root@ceph1 ~]# ceph osd crush rm osd.7
[root@ceph1 ~]# ceph osd crush rm ceph2
[root@ceph1 ~]# ceph osd rm 2 4 7
# 清理磁盘数据
[root@ceph1 ~]# ceph orch device zap ceph2.laogao.cloud /dev/sdb --force
[root@ceph1 ~]# ceph orch device zap ceph2.laogao.cloud /dev/sdc --force
[root@ceph1 ~]# ceph orch device zap ceph2.laogao.cloud /dev/sdd --force
然后,删除主机。
[root@ceph1 ~]# ceph orch host rm ceph2
[root@ceph1 ~]# ceph orch host ls #查看现象ceph2被移除
HOST ADDR LABELS STATUS
ceph1.laogao.cloud 192.168.108.11 _admin
ceph3.laogao.cloud 192.168.108.13 _admin
2 hosts in cluster
最后,删除ceph2中相应ceph遗留文件。
[root@ceph2 ~]# rm -rf /var/lib/ceph
[root@ceph2 ~]# rm -rf /etc/ceph /etc/systemd/system/ceph*
[root@ceph2 ~]# rm -rf /var/log/ceph2. 存储池(Pool)管理
2.1 池创建与删除
bash
# 1. 创建复本池
ceph osd pool create <池名> <pg_num> <pgp_num> [replicated] [crush-rule-name]
# 示例:创建名为 rbd_pool 的复本池,PG 数 256
ceph osd pool create rbd_pool 256 256 replicated
# 2. 创建纠删码池
ceph osd pool create <池名> <pg_num> <pgp_num> erasure [erasure-code-profile]
# 示例:创建名为 ec_pool 的纠删码池,使用 default 配置文件
ceph osd pool create ec_pool 128 128 erasure default
# 3. 查看池列表
ceph osd pool ls
ceph osd pool ls detail
# 4. 删除池(需先开启删除权限)
ceph config set mon mon_allow_pool_delete true
ceph osd pool rm <池名> <池名> --yes-i-really-really-mean-it2.2 池配置调整
bash
# 1. 修改复本数
ceph osd pool set <池名> size <副本数>
ceph osd pool set rbd_pool size 3
# 2. 修改 PG 数(需与 PGP 数一致)
ceph osd pool set <池名> pg_num <新 PG 数>
ceph osd pool set <池名> pgp_num <新 PG 数>
ceph osd pool set rbd_pool pg_num 512
ceph osd pool set rbd_pool pgp_num 512
# 3. 设置配额(最大对象数/最大容量)
ceph osd pool set-quota <池名> max_objects <数量>
ceph osd pool set-quota <池名> max_bytes <容量> # 单位:字节(10G=10737418240)
# 4. 查看配额
ceph osd pool get-quota <池名>
# 5. 启用/禁用池自动扩展 PG
ceph osd pool set <池名> pg_autoscale_mode on/off/warn2.3 纠删码配置文件管理
bash
# 1. 查看现有纠删码配置文件
ceph osd erasure-code-profile ls
# 2. 查看配置文件详情
ceph osd erasure-code-profile get default
# 3. 创建自定义纠删码配置文件(k=4 数据块,m=2 编码块)
ceph osd erasure-code-profile set my_ec_profile k=4 m=2 plugin=jerasure technique=reed_sol_van
# 4. 删除纠删码配置文件
ceph osd erasure-code-profile rm my_ec_profile3. 块存储(RBD)深度操作
3.1 RBD 镜像管理
bash
# 1. 初始化 RBD 池
rbd pool init <池名>
rbd pool init rbd_pool
# 2. 创建 RBD 镜像(100G 大小)
rbd create <池名>/<镜像名> --size <大小> [--order <阶数>]
rbd create rbd_pool/webapp_disk --size 100G --order 22 # order=22 对应 4MB 对象大小
# 3. 查看镜像列表
rbd ls <池名>
rbd ls rbd_pool
# 4. 查看镜像详情
rbd info <池名>/<镜像名>
rbd info rbd_pool/webapp_disk
# 5. 调整镜像大小(扩展/缩减)
rbd resize <池名>/<镜像名> --size <新大小> # 扩展
rbd resize <池名>/<镜像名> --size <新大小> --allow-shrink # 缩减(需先卸载文件系统)
# 6. 删除镜像(需先删除快照)
rbd rm <池名>/<镜像名>3.2 快照与克隆
bash
# 1. 创建快照
rbd snap create <池名>/<镜像名>@<快照名>
rbd snap create rbd_pool/webapp_disk@snap_20250801
# 2. 查看快照列表
rbd snap ls <池名>/<镜像名>
# 3. 保护快照(防止删除,克隆前必须保护)
rbd snap protect <池名>/<镜像名>@<快照名>
# 4. 克隆快照(基于快照创建可写镜像)
rbd clone <池名>/<镜像名>@<快照名> <目标池名>/<目标镜像名>
rbd clone rbd_pool/webapp_disk@snap_20250801 rbd_pool/webapp_disk_clone
# 5. 扁平化克隆(脱离父快照独立)
rbd flatten <目标池名>/<目标镜像名>
# 6. 删除快照(需先解除保护)
rbd snap unprotect <池名>/<镜像名>@<快照名>
rbd snap rm <池名>/<镜像名>@<快照名>
# 7. 删除所有快照
rbd snap purge <池名>/<镜像名>3.3 镜像映射与挂载
bash
# 1. 映射 RBD 镜像到本地
rbd map <池名>/<镜像名>
rbd map rbd_pool/webapp_disk
# 2. 查看映射状态
rbd showmapped
lsblk | grep rbd
# 3. 格式化镜像(XFS 文件系统)
mkfs.xfs /dev/rbd0
# 4. 挂载镜像
mkdir -p /mnt/webapp
mount /dev/rbd0 /mnt/webapp
# 5. 永久挂载(/etc/fstab)
echo "/dev/rbd/<池名>/<镜像名> /mnt/webapp xfs _netdev 0 0" >> /etc/fstab
mount -a
# 6. 卸载与解除映射
umount /mnt/webapp
rbd unmap /dev/rbd03.4 RBD 缓存优化
bash
# 1. 查看缓存配置
ceph config get client rbd_cache
ceph config get client rbd_cache_policy
# 2. 设置缓存模式(writethrough/writeback/writearound)
ceph config set client rbd_cache_policy writethrough
# 3. 调整缓存大小(默认 32MB)
ceph config set client rbd_cache_size 67108864 # 64MB
# 4. 调整最大脏缓存(默认 24MB)
ceph config set client rbd_cache_max_dirty 41943040 # 40MB4. 对象存储(RGW)实战
4.1 RGW 部署与配置
bash
# 1. 创建 RGW 域、区域组、区域
radosgw-admin realm create --rgw-realm=myrealm --default
radosgw-admin zonegroup create --rgw-realm=myrealm --rgw-zonegroup=myzonegroup --master --default
radosgw-admin zone create --rgw-realm=myrealm --rgw-zonegroup=myzonegroup --rgw-zone=myzone --master --default
radosgw-admin period update --rgw-realm=myrealm --commit
# 2. 部署 RGW 服务(3 个实例)
ceph orch apply rgw myrgw --placement="3 ceph1 ceph2 ceph3" --realm=myrealm --zone=myzone --port=8080
# 3. 验证 RGW 服务
ceph orch ls rgw
curl http://ceph1.laogao.cloud:8080 # 应返回 XML 格式的桶列表4.2 RGW 用户管理
bash
# 1. 创建 S3 风格用户
radosgw-admin user create \
--uid="s3user" \
--display-name="S3 User" \
--email="s3user@example.com" \
--access-key="AKIAEXAMPLE" \
--secret-key="secretkeyexample"
# 2. 查看用户信息
radosgw-admin user info --uid=s3user
# 3. 生成/修改密钥
radosgw-admin key create --uid=s3user --gen-access-key
radosgw-admin key rm --uid=s3user --access-key="旧 AK"
# 4. 临时禁用/启用用户
radosgw-admin user suspend --uid=s3user
radosgw-admin user enable --uid=s3user
# 5. 删除用户(--purge-data 同时删除用户数据)
radosgw-admin user rm --uid=s3user --purge-data4.3 S3 客户端操作(AWS CLI)
bash
# 1. 安装 AWS CLI
pip3 install awscli
# 2. 配置用户凭据
aws configure
# 输入 Access Key、Secret Key、区域(默认空)、输出格式(默认空)
# 3. 创建 S3 桶
aws --endpoint=http://ceph1.laogao.cloud:8080 s3 mb s3://mybucket
# 4. 上传文件到桶
aws --endpoint=http://ceph1.laogao.cloud:8080 s3 cp /etc/hosts s3://mybucket/
# 5. 查看桶内文件
aws --endpoint=http://ceph1.laogao.cloud:8080 s3 ls s3://mybucket
# 6. 下载文件
aws --endpoint=http://ceph1.laogao.cloud:8080 s3 cp s3://mybucket/hosts /tmp/
# 7. 设置文件访问权限(公开可读)
aws --endpoint=http://ceph1.laogao.cloud:8080 s3api put-object-acl --bucket mybucket --key hosts --acl public-read
# 8. 删除文件/桶
aws --endpoint=http://ceph1.laogao.cloud:8080 s3 rm s3://mybucket/hosts
aws --endpoint=http://ceph1.laogao.cloud:8080 s3 rb s3://mybucket # 桶必须为空4.4 配额管理
bash
运行
bash
# 1. 用户级配额(最大对象数 1000)
radosgw-admin quota enable --quota-scope=user --uid=s3user
radosgw-admin quota set --quota-scope=user --uid=s3user --max-objects=1000
# 2. 桶级配额(最大容量 10G)
radosgw-admin quota enable --quota-scope=bucket --bucket=mybucket
radosgw-admin quota set --quota-scope=bucket --bucket=mybucket --max-size=10G
# 3. 查看配额使用情况
radosgw-admin user stats --uid=s3user
radosgw-admin bucket stats --bucket=mybucket4.5 多站点复制(主从模式)
bash
# 前提:两个 Ceph 集群(主集群 A,从集群 B)
# 1. 主集群创建同步用户
radosgw-admin user create --uid=syncuser --display-name="Sync User" --system --access-key="syncAK" --secret-key="syncSK"
# 2. 主集群配置区域端点
radosgw-admin zone modify --rgw-zone=myzone --endpoints="http://ceph1:8080,http://ceph2:8080" --access-key="syncAK" --secret-key="syncSK"
# 3. 从集群拉取主集群配置
radosgw-admin realm pull --url=http://ceph1:8080 --access-key="syncAK" --secret-key="syncSK"
radosgw-admin period pull --url=http://ceph1:8080 --access-key="syncAK" --secret-key="syncSK"
# 4. 从集群创建区域
radosgw-admin zone create --rgw-zonegroup=myzonegroup --rgw-zone=myzone_slave --endpoints="http://ceph4:8080" --access-key="syncAK" --secret-key="syncSK"
# 5. 从集群部署 RGW 服务
ceph orch apply rgw myrgw_slave --placement="3 ceph4 ceph5 ceph6" --realm=myrealm --zone=myzone_slave --port=8080
# 6. 验证同步状态
radosgw-admin sync status5. 文件系统(CephFS)操作
5.1 CephFS 部署(手动方式)
bash
# 1. 创建元数据池和数据池
ceph osd pool create cephfs_meta 128 128 replicated
ceph osd pool create cephfs_data 512 512 replicated
# 2. 设置元数据池副本数(推荐 3)
ceph osd pool set cephfs_meta size 3
# 3. 创建 CephFS 文件系统
ceph fs new mycephfs cephfs_meta cephfs_data
# 4. 部署 MDS 服务(3 个节点,1 活跃 + 2 备用)
ceph orch apply mds mycephfs --placement="3 ceph1 ceph2 ceph3"
# 5. 查看 CephFS 状态
ceph fs ls
ceph fs status mycephfs
ceph mds stat5.2 CephFS 挂载(Kernel 方式)
bash
# 1. 创建挂载点
mkdir -p /mnt/cephfs
# 2. 挂载(使用 admin 用户)
mount.ceph ceph1:6789,ceph2:6789,ceph3:6789:/ /mnt/cephfs -o name=admin,fs=mycephfs
# 3. 验证挂载
df -h /mnt/cephfs
touch /mnt/cephfs/testfile
# 4. 永久挂载(/etc/fstab)
echo "ceph1:6789,ceph2:6789,ceph3:6789:/ /mnt/cephfs ceph name=admin,fs=mycephfs,_netdev 0 0" >> /etc/fstab
mount -a5.3 CephFS 挂载(FUSE 方式)
bash
# 1. 安装 ceph-fuse
dnf install -y ceph-fuse
# 2. 挂载(指定用户和文件系统)
ceph-fuse -n client.admin -m ceph1:6789,ceph2:6789,ceph3:6789 /mnt/cephfs_fuse --client_fs=mycephfs
# 3. 挂载特定子目录
ceph-fuse -n client.admin -m ceph1:6789 -r /data /mnt/cephfs_data --client_fs=mycephfs
# 4. 卸载
umount /mnt/cephfs_fuse5.4 快照与配额管理
bash
# 1. 启用/禁用快照功能
ceph fs set mycephfs allow_new_snaps true/false
# 2. 创建快照(通过 .snap 隐藏目录)
mkdir /mnt/cephfs/.snap/snap_20250801
# 3. 访问快照文件
ls /mnt/cephfs/.snap/snap_20250801
cp /mnt/cephfs/.snap/snap_20250801/testfile /tmp/
# 4. 删除快照
rmdir /mnt/cephfs/.snap/snap_20250801
# 5. 设置目录配额(最大 100G,最大文件数 10000)
setfattr -n ceph.quota.max_bytes -v 107374182400 /mnt/cephfs/data
setfattr -n ceph.quota.max_files -v 10000 /mnt/cephfs/data
# 6. 查看配额
getfattr -n ceph.quota.max_bytes /mnt/cephfs/data
getfattr -n ceph.quota.max_files /mnt/cephfs/data5.5 CephFS Mirror(跨集群复制)
bash
# 前提:主集群(A)和从集群(B)均部署 CephFS
# 1. 主集群部署 mirror 守护进程
ceph orch apply cephfs-mirror --placement="ceph1"
# 2. 从集群创建同步用户
ceph fs authorize mycephfs client.cephfs-mirror / rwps
# 3. 从集群生成引导令牌
radosgw-admin fs snapshot mirror peer_bootstrap create mycephfs client.cephfs-mirror slave_site
# 4. 主集群导入令牌
ceph fs snapshot mirror peer_bootstrap import mycephfs <令牌字符串>
# 5. 主集群添加同步目录
ceph fs snapshot mirror add mycephfs /data
# 6. 查看同步状态
ceph fs snapshot mirror peer_list mycephfs
ceph fs snapshot mirror status mycephfs6. 认证与授权管理
6.1 Cephx 认证机制
Ceph 默认启用 Cephx 协议,通过共享密钥进行身份验证,涉及三类密钥环:
- 集群密钥环:/etc/ceph/ceph.client.admin.keyring(管理员密钥)
- 守护进程密钥环:/var/lib/ceph/fsi**d/daemon_type.$host/keyring
- 用户密钥环:/etc/ceph/ceph.client.<用户名>.keyring
6.2 用户管理命令
bash
# 1. 创建用户(指定权限)
ceph auth add client.<用户名> \
mon 'allow r' \ # 允许读取 MON 信息
osd 'allow rw pool=<池名>' \ # 允许读写指定池
mds 'allow rw path=/<目录>' # 允许读写 CephFS 目录
# 示例:创建只读用户
ceph auth add client.reader mon 'allow r' osd 'allow r pool=rbd_pool'
# 2. 查看用户列表
ceph auth ls
# 3. 查看用户详情
ceph auth get client.<用户名>
# 4. 导出用户密钥环
ceph auth get client.<用户名> -o /etc/ceph/ceph.client.<用户名>.keyring
# 5. 导入用户密钥环
ceph auth import -i /etc/ceph/ceph.client.<用户名>.keyring
# 6. 修改用户权限
ceph auth caps client.<用户名> \
mon 'allow r' \
osd 'allow rw pool=rbd_pool, allow r pool=ec_pool'
# 7. 删除用户
ceph auth rm client.<用户名>6.3 客户端认证配置
bash
# 1. 复制密钥环到客户端
scp /etc/ceph/ceph.client.reader.keyring root@client:/etc/ceph/
# 2. 复制配置文件到客户端
scp /etc/ceph/ceph.conf root@client:/etc/ceph/
# 3. 客户端测试访问
ceph --id reader osd pool ls
rbd --id reader ls rbd_pool五、集群运维与监控
1. 日常运维命令
bash
# 1. 集群状态查看
ceph status # 简写 ceph -s
ceph health detail # 详细健康信息
ceph df # 存储容量统计
# 2. 组件状态查看
ceph osd stat # OSD 状态摘要
ceph mon stat # MON 状态摘要
ceph mgr stat # MGR 状态摘要
ceph mds stat # MDS 状态摘要
# 3. 服务管理
ceph orch daemon start <服务名> # 启动服务
ceph orch daemon stop <服务名> # 停止服务
ceph orch daemon restart <服务名> # 重启服务
ceph orch daemon rm <服务名> # 删除服务
# 4. OSD 管理
ceph osd in <osd-id> # 激活 OSD
ceph osd out <osd-id> # 下线 OSD
ceph osd crush rm <osd-id> # 从 CRUSH 地图移除 OSD
ceph osd rm <osd-id> # 删除 OSD
ceph orch device zap <节点名> <磁盘名> --force # 清理磁盘
# 5. 日志查看
ceph orch logs <服务名> # 查看服务日志
ceph log last 100 # 查看最近 100 条集群日志2. 监控与告警
2.1 Dashboard 监控
- 访问地址:https://<MON 节点 IP>:8443
- 核心监控面板:
- Cluster Status:集群健康状态、组件状态
- Capacity:存储容量使用情况
- Performance:IOPS、吞吐量、延迟
- Hosts:节点资源使用情况
- OSDs:OSD 状态、性能指标
2.2 Prometheus + Grafana 监控
- Grafana 访问地址:http://<Grafana 节点 IP>:3000(默认账户 admin/admin)
- 导入 Ceph 官方仪表盘(ID:917)
- 核心监控指标:
- 集群健康状态(ceph_cluster_health_status)
- OSD 状态(ceph_osd_up、ceph_osd_in)
- 存储容量(ceph_cluster_total_bytes、ceph_cluster_used_bytes)
- IO 性能(ceph_osd_op_perf_latency_ms、ceph_osd_op_perf_throughput_bytes)
2.3 告警配置
bash
# 1. 启用 Prometheus 告警模块
ceph mgr module enable prometheus
# 2. 配置告警规则(Grafana 中设置)
# 示例告警规则:
# - OSD 下线超过 5 分钟
# - 集群使用率超过 85%
# - PG 处于 degraded 状态超过 10 分钟
# 3. 配置邮件告警(修改 Prometheus Alertmanager 配置)
vim /etc/ceph/alertmanager.yml3. 集群扩容与缩容
3.1 节点扩容
bash
# 1. 新增节点环境准备(参考前文系统配置)
# 2. 推送公钥到新增节点
ssh-copy-id -i ~/ceph.pub root@new-node
# 3. 添加节点到集群
ceph orch host add new-node.laogao.cloud
# 4. 部署服务到新增节点(如 OSD)
ceph orch apply osd --all-available-devices3.2 节点缩容
bash
# 1. 下线节点上的 OSD
for osd_id in $(ceph osd tree | grep new-node | awk '{print $1}'); do
ceph osd out $osd_id
ceph orch daemon rm osd.$osd_id --force
done
# 2. 移除节点上的其他服务(MON/MGR/MDS)
ceph orch daemon rm mon.new-node --force
ceph orch daemon rm mgr.new-node --force
# 3. 从集群移除节点
ceph orch host rm new-node.laogao.cloud
# 4. 清理节点残留文件
ssh root@new-node "rm -rf /var/lib/ceph /etc/ceph /var/log/ceph"4. 数据备份与恢复
4.1 备份策略
- 定期创建 RBD 快照:适合块存储数据
- 定期导出 RBD 镜像:
rbd export <池名>/<镜像名> /备份路径/镜像名.img - CephFS 快照:适合文件系统数据
- 跨集群复制:RGW 多站点复制、CephFS Mirror
4.2 恢复示例(RBD 镜像)
bash
# 1. 导入备份的 RBD 镜像
rbd import /备份路径/镜像名.img <池名>/<镜像名>
# 2. 基于快照恢复
rbd snap rollback <池名>/<镜像名>@<快照名>
# 3. 克隆快照恢复数据
rbd clone <池名>/<镜像名>@<快照名> <池名>/<恢复镜像名>
rbd map <池名>/<恢复镜像名>
mount /dev/rbd0 /mnt/restore六、常见问题排查
1. 集群健康状态异常
1.1 HEALTH_WARN 排查
bash
# 查看详细告警信息
ceph health detail
# 常见告警处理
# 1. PG 未激活(PG_NOT_ACTIVE)
ceph pg repair <pg-id> # 修复 PG
ceph osd tree # 检查 OSD 状态
# 2. 存储容量不足(LOW_SPACE)
ceph df # 查看容量使用
# 解决方案:扩容 OSD、清理无用数据、调整池配额
# 3. MON 仲裁警告(MON_QUORUM_WARN)
ceph mon stat # 检查 MON 状态
# 解决方案:确保奇数个 MON 运行,添加/修复 MON 节点1.2 HEALTH_ERR 排查
bash
# 1. OSD 故障(OSD_DOWN)
ceph osd tree # 确认故障 OSD
ceph osd out <osd-id> # 下线故障 OSD
# 解决方案:更换故障磁盘,重新部署 OSD
# 2. PG 不一致(PG_INCONSISTENT)
ceph pg scrub <pg-id> # scrub PG
ceph pg repair <pg-id> # 修复 PG
# 3. CRUSH 地图错误(CRUSH_INCOMPATIBLE)
ceph osd crush dump # 查看 CRUSH 地图
ceph osd crush reweight-all # 重新平衡 CRUSH 权重2. 访问故障排查
2.1 客户端无法连接集群
bash
# 1. 检查网络连通性(MON 端口 6789/3300)
telnet ceph1 6789
nc -zv ceph1 3300
# 2. 检查密钥环权限
ls -l /etc/ceph/ceph.client.*.keyring # 确保权限为 600
# 3. 检查配置文件
cat /etc/ceph/ceph.conf # 确认 mon_host 配置正确
# 4. 测试认证
ceph --id <用户名> health # 验证用户权限2.2 RBD 镜像无法映射
bash
# 1. 检查镜像状态
rbd info <池名>/<镜像名>
# 2. 检查内核模块
lsmod | grep rbd # 确保 rbd 模块加载
modprobe rbd # 加载模块
# 3. 检查权限
ceph auth get client.<用户名> # 确保有 rbd 访问权限
# 4. 查看日志
dmesg | grep rbd # 查看内核日志3. 性能问题排查
3.1 存储性能低下
bash
# 1. 查看 IO 性能指标
ceph osd perf # OSD IO 性能
rbd perf image <池名>/<镜像名> # RBD 镜像性能
# 2. 检查网络带宽
iftop -i <网卡名> # 监控网络流量
ceph osd netstat # OSD 网络统计
# 3. 检查磁盘 IO
iostat -x 1 # 磁盘 IO 统计
iotop # 进程 IO 监控
# 4. 优化建议
# - 确保网络带宽充足(推荐 10Gbps)
# - OSD 日志使用 SSD
# - 调整 PG 数,避免单个 OSD 负载过高
# - 优化 CRUSH 规则,避免数据集中在少数节点七、总结与扩展
1. 核心优势与适用场景
- 优势:高可用、无限扩展、统一存储、开源免费、生态完善
- 适用场景:云平台存储、大数据存储、备份归档、高性能计算、内容分发
3. CRUSH 地图错误(CRUSH_INCOMPATIBLE)
ceph osd crush dump # 查看 CRUSH 地图
ceph osd crush reweight-all # 重新平衡 CRUSH 权重
### 2. 访问故障排查
#### 2.1 客户端无法连接集群
```bash
# 1. 检查网络连通性(MON 端口 6789/3300)
telnet ceph1 6789
nc -zv ceph1 3300
# 2. 检查密钥环权限
ls -l /etc/ceph/ceph.client.*.keyring # 确保权限为 600
# 3. 检查配置文件
cat /etc/ceph/ceph.conf # 确认 mon_host 配置正确
# 4. 测试认证
ceph --id <用户名> health # 验证用户权限2.2 RBD 镜像无法映射
bash
# 1. 检查镜像状态
rbd info <池名>/<镜像名>
# 2. 检查内核模块
lsmod | grep rbd # 确保 rbd 模块加载
modprobe rbd # 加载模块
# 3. 检查权限
ceph auth get client.<用户名> # 确保有 rbd 访问权限
# 4. 查看日志
dmesg | grep rbd # 查看内核日志3. 性能问题排查
3.1 存储性能低下
bash
# 1. 查看 IO 性能指标
ceph osd perf # OSD IO 性能
rbd perf image <池名>/<镜像名> # RBD 镜像性能
# 2. 检查网络带宽
iftop -i <网卡名> # 监控网络流量
ceph osd netstat # OSD 网络统计
# 3. 检查磁盘 IO
iostat -x 1 # 磁盘 IO 统计
iotop # 进程 IO 监控
# 4. 优化建议
# - 确保网络带宽充足(推荐 10Gbps)
# - OSD 日志使用 SSD
# - 调整 PG 数,避免单个 OSD 负载过高
# - 优化 CRUSH 规则,避免数据集中在少数节点七、总结与扩展
1. 核心优势与适用场景
- 优势:高可用、无限扩展、统一存储、开源免费、生态完善
- 适用场景:云平台存储、大数据存储、备份归档、高性能计算、内容分发
- 不适用场景:对延迟要求极高的核心业务(如金融交易)、小规模存储(建议 < 10 节点不采用)