一、创建MySql数据库
import pymysql
db = pymysql.connect(host='localhost',user='root',password='root',port=3306)
cursor = db.cursor()
cursor.execute('SELECT VERSION()')
data = cursor.fetchone()
print('Database version:',data)
cursor.execute("CREATE DATABASE spiders DEFAULT CHARACTER SET utf8mb4")
db.close()cursor = db.cursor() 是使用 pymysql 连接 MySQL 数据库后创建一个**游标对象(cursor)**的关键步骤。它的作用是:
通过游标来执行 SQL 语句,并获取查询结果。
🔍 详细解释
当你执行:
import pymysql
db = pymysql.connect(host='localhost', user='root', password='root', port=3306)
cursor = db.cursor()db是数据库连接对象,负责与 MySQL 服务器建立和维持连接。cursor()方法返回一个 游标对象,你可以把它理解为"SQL 命令的执行器"。
✅ 游标能做什么?
-
执行 SQL 语句
cursor.execute("SELECT VERSION()") cursor.execute("CREATE DATABASE spiders DEFAULT CHARACTER SET utf8mb4") cursor.execute("INSERT INTO users (name) VALUES ('Alice')") -
获取查询结果
-
fetchone():取一行 -
fetchall():取所有行 -
fetchmany(n):取 n 行cursor.execute("SELECT * FROM users")
row = cursor.fetchone()
print(row)
-
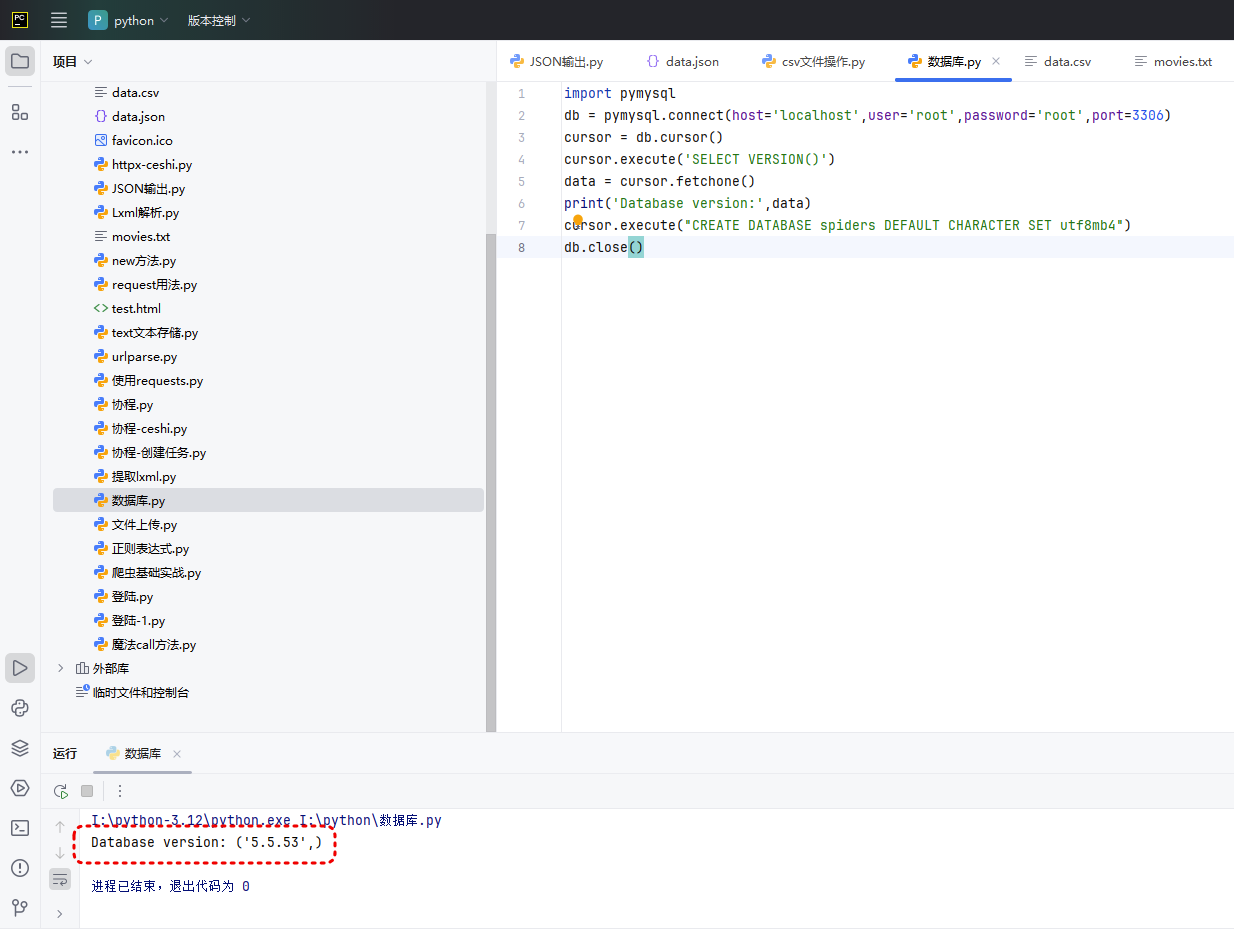
上述代码显示了数据库的版本号5.5.53
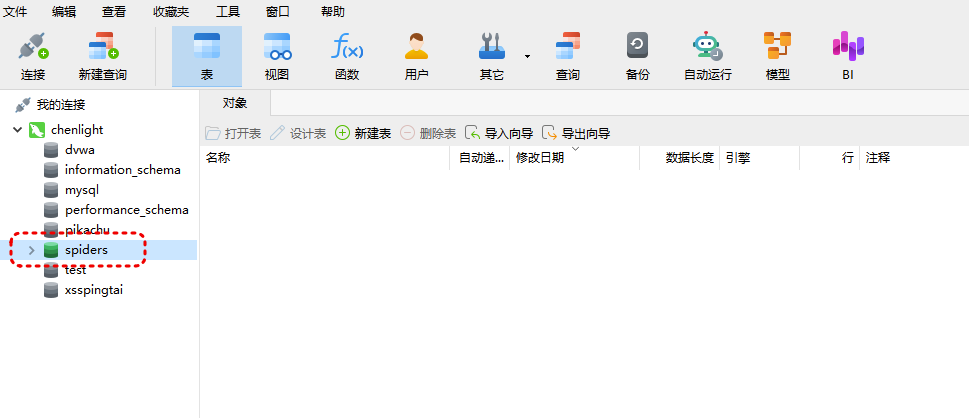
同时,也创建了spiders数据库
二、创建表
import pymysql
db = pymysql.connect(host='localhost',user='root',password='root',port=3306,db='spiders')
cursor = db.cursor()
sql = 'CREATE TABLE IF NOT EXISTS students (id VARCHAR(255) NOT NULL,name VARCHAR(255) NOT NULL,age INT NOT NULL,PRIMARY KEY (id))'
cursor.execute(sql)
db.close()运行结果:
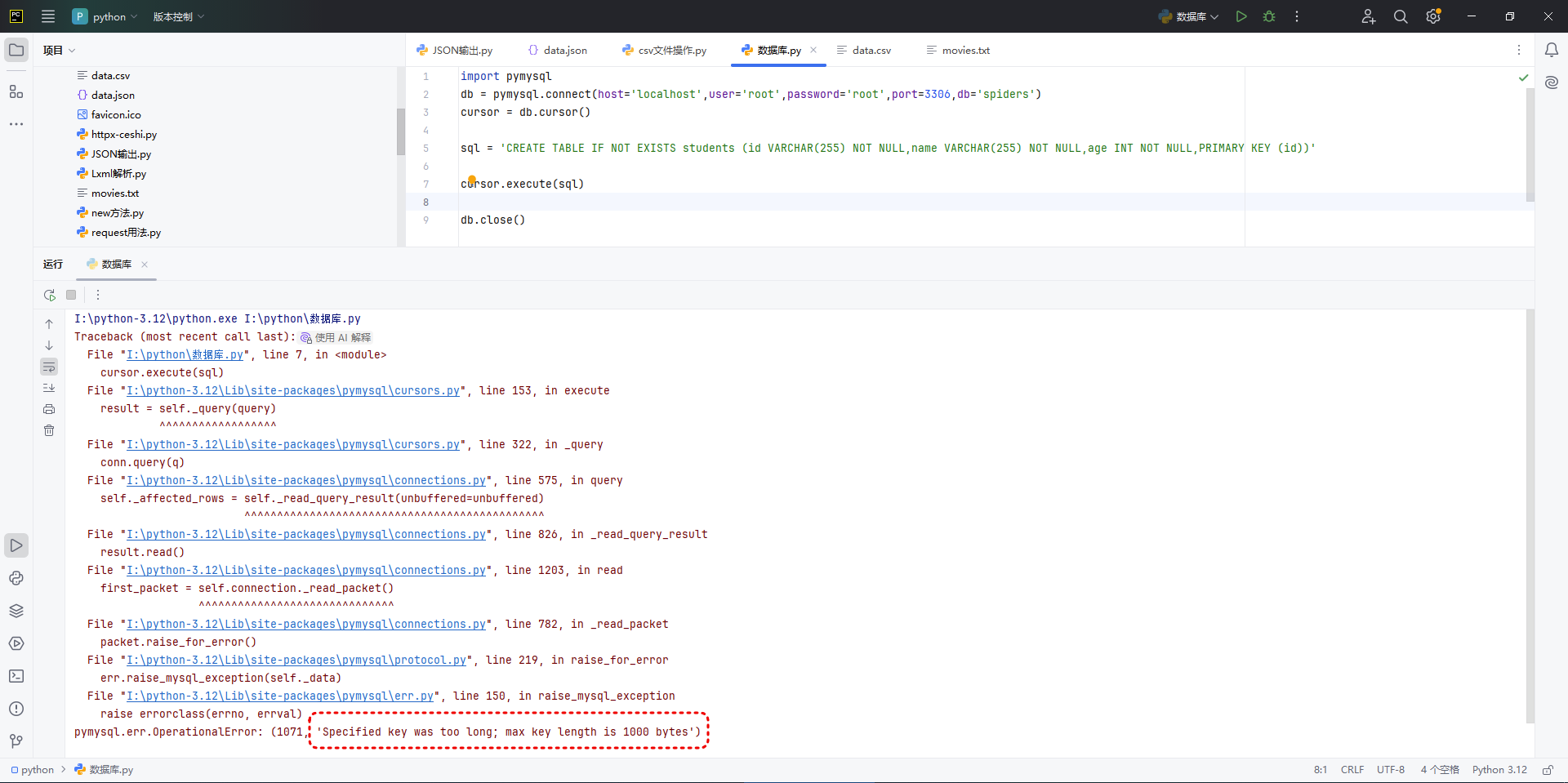
这个错误的意思是:你试图将一个长度超过 MySQL 允许最大索引长度(1000 字节)的字段设为主键(或索引)。
原因分析
在创建表时使用了:
id VARCHAR(255) NOT NULL,
PRIMARY KEY (id)VARCHAR(255)表示最多 255 个字符。- 如果你的数据库字符集是 utf8mb4 (这是现代 MySQL 的默认字符集,支持 emoji 等四字节字符),那么每个字符最多占 4 字节。
- 所以
VARCHAR(255)最多占用:255 × 4 = 1020 字节。 - 而 MySQL 的 MyISAM 或旧版本 InnoDB 引擎对索引长度限制为 1000 字节 (新版本 InnoDB 在启用
innodb_large_prefix且行格式为DYNAMIC或COMPRESSED时可支持到 3072 字节,但仍有条件限制)。
因此,主键 id VARCHAR(255) 超过了 1000 字节限制,导致建表失败。
解决方案
✅ 推荐做法:使用更短的 id 长度(最简单有效)
如果你的 id 实际上不需要 255 位(比如是学号、UUID 等),可以缩短长度:
- 如果是数字 ID:用
INT或BIGINT - 如果是 UUID(36字符):
VARCHAR(36) - 如果是自定义字符串 ID,评估最大长度,比如
VARCHAR(64)或VARCHAR(100)
例如:
sql = '''
CREATE TABLE IF NOT EXISTS students (
id VARCHAR(64) NOT NULL,
name VARCHAR(255) NOT NULL,
age INT NOT NULL,
PRIMARY KEY (id)
)
'''
64 × 4 = 256 字节,远低于 1000 字节限制,安全。
修改完善代码如下:
import pymysql
db = pymysql.connect(host='localhost',user='root',password='root',port=3306,db='spiders')
cursor = db.cursor()
sql = 'CREATE TABLE IF NOT EXISTS students (id VARCHAR(64) NOT NULL,name VARCHAR(255) NOT NULL,age INT NOT NULL,PRIMARY KEY (id))'
cursor.execute(sql)
db.close()再次运行结果如下:
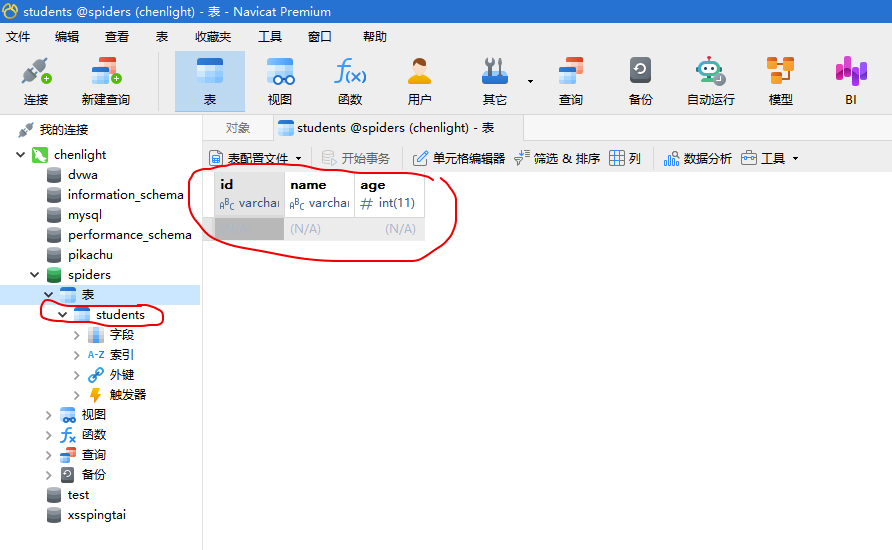
可以看到表创建成功了!
三、插入数据
import pymysql
id = '20251225'
user = 'Chen'
age = 41
db = pymysql.connect(host='localhost',user='root',password='root',port=3306,db='spiders')
cursor = db.cursor()
sql = 'INSERT INTO students(id,name,age) values(%s,%s,%s)'
try:
cursor.execute(sql,(id,user,age))
db.commit()
except:
db.rollback()
db.close()关键知识点:
1、原书中的%ss是错误的,在代码测试中输入%ss虽然没有报错,但是数据库始终无法写入数据;

应该将三个%ss全部更改为%s才可以,%s才是占位符。
2、commit和rollback
commit() 的作用
db.commit()- 将当前事务中所有未保存的更改永久写入数据库。
- 一旦执行
commit(),这些更改无法撤销(除非你有备份或日志)。 - 如果不调用
commit(),即使cursor.execute()成功执行了 INSERT/UPDATE/DELETE,数据也不会真正保存(因为默认启用了事务)。
✅ 使用场景 :
当你的 SQL 操作(如插入、更新)执行成功,且业务逻辑确认无误时,调用 commit() 提交。
rollback() 的作用
db.rollback()- 撤销当前事务中所有未提交的更改,恢复到事务开始前的状态。
- 常用于异常处理:当某一步操作失败,避免留下"半成品"数据。
✅ 使用场景 :
在 try...except 中,当捕获到数据库错误(如主键冲突、连接中断、语法错误等),调用 rollback() 回滚,保证数据一致性。
| 方法 | 作用 | 何时调用 |
|---|---|---|
commit() |
永久保存更改 | 所有操作成功后 |
rollback() |
撤销未提交的更改 | 发生错误时 |
✅ 黄金法则:
任何修改数据库的操作,都应放在
try...except中,并配合commit()/rollback()使用。
这样能确保你的程序 健壮、安全、数据一致。
四、插入数据(升级版)
import pymysql
db = pymysql.connect(host='localhost',user='root',password='root',port=3306,db='spiders')
cursor = db.cursor()
data = {
'id':'20251226',
'name':'Bob',
'age':42
}
table = 'students'
keys = ','.join(data.keys())
values = ','.join(['%s']*len(data))
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table = table,keys = keys,values = values)
try:
if cursor.execute(sql,tuple(data.values())):
print('Successful')
db.commit()
except:
print('Failed')
db.rollback()
db.close()关键知识点:
1、分析values = ','.join('%s'*len(data))
生成一个由 %s 组成的、用逗号分隔的字符串,数量等于字典 data 中键值对的个数。
例如:
data = {'id': '20251226', 'name': 'Bob', 'age': 42}
len(data) # → 3
['%s'] * 3 # → ['%s', '%s', '%s']
','.join(['%s', '%s', '%s']) # → '%s,%s,%s'所以最终 values = '%s,%s,%s'
2、分析.format()
.format() 是 Python 中用于字符串格式化 的一种强大且灵活的方法,广泛用于将变量插入到字符串模板中。它比早期的 % 格式化更清晰、功能更丰富。
✅ 基本语法
"模板字符串".format(参数)模板中使用 {} 作为占位符,.format() 中的参数按顺序或按名称填入。
🔹 2.1. 位置参数(按顺序)
name = "Alice"
age = 30
s = "Hello, {}! You are {} years old.".format(name, age)
print(s) # 输出: Hello, Alice! You are 30 years old.- 第一个
{}→name - 第二个
{}→age
注意:从左到右依次匹配。
🔹 2.2. 索引参数(指定位置)
s = "I have {1} apples and {0} oranges.".format(5, 3)
print(s) # 输出: I have 3 apples and 5 oranges.{0}表示.format()的第 0 个参数(5){1}表示第 1 个参数(3)
✅ 可重复使用:
s = "{0} loves {0}, but {1} hates {0}.".format("Python", "Java")
# 输出: Python loves Python, but Java hates Python.🔹 2.3. 关键字参数(推荐,可读性高)
s = "My name is {name}, and I'm {age} years old.".format(name="Bob", age=25)
print(s) # 输出: My name is Bob, and I'm 25 years old.也可以混合使用字典:
data = {'name': 'Charlie', 'age': 40}
s = "Name: {name}, Age: {age}".format(**data)
print(s) # 输出: Name: Charlie, Age: 40
**data将字典解包为关键字参数。
🔹 2.4. 格式化数字、对齐、精度等
.format() 支持丰富的格式控制,用冒号 : 指定格式:
📌 数字格式化
pi = 3.1415926
print("{:.2f}".format(pi)) # 3.14(保留两位小数)
print("{:0>5}".format(42)) # 00042(右对齐,用0填充到5位)
print("{:,}".format(1234567)) # 1,234,567(千位分隔符)
print("{:.2%}".format(0.85)) # 85.00%(百分比)📌 对齐方式
print("{:<10}".format("left")) # left (左对齐,总宽10)
print("{:>10}".format("right")) # right(右对齐)
print("{:^10}".format("center")) # center (居中)3、tuple(data.values())
将字典 data 中的所有值(values) 转换为一个元组(tuple)。
data = {'id': '20251226', 'name': 'Bob', 'age': 42}
result = tuple(data.values())
print(result) # 输出: ('20251226', 'Bob', 42)五、数据更新
import pymysql
db = pymysql.connect(host='localhost',user='root',password='root',port=3306,db='spiders')
cursor = db.cursor()
data = {
'id':'20251226',
'name':'Bob',
'age':22
}
table = 'students'
keys = ','.join(data.keys())
values = ','.join(['%s']*len(data))
sql = 'INSERT INTO {table}({keys}) VALUES ({values}) ON DUPLICATE KEY UPDATE '.format(table = table,keys = keys,values = values)
update = ','.join([f"{key} = %s".format(key=key) for key in data])
sql += update
try:
if cursor.execute(sql,tuple(data.values())*2):
print('Successful')
db.commit()
except:
print('Failed')
db.rollback()
db.close()关键知识点:
1、INSERT ... ON DUPLICATE KEY UPDATE 是 MySQL 中非常实用的语句
用于在执行插入操作时,如果遇到唯一键(主键或唯一索引)冲突,则转而执行更新操作,而非直接抛出错误。这一特性避免了先查询再判断后插入 / 更新的繁琐逻辑,提升了操作的原子性和效率。
基本语法如下:
INSERT INTO 表名 (列1, 列2, ...)
VALUES (值1, 值2, ...)
[ON DUPLICATE KEY UPDATE 列1 = 值1, 列2 = 列2 + 值2, ...];- 若插入的记录不存在唯一键冲突,执行普通插入;
- 若存在唯一键冲突,执行
UPDATE子句中指定的更新操作。
2、update = ','.join("{key} = %s".format(key=key) for key in data)
这段的意图是生成形如 "id = %s,name = %s,age = %s" 的字符串,用于 ON DUPLICATE KEY UPDATE 子句。
这行代码分为两个核心部分:列表推导式 和字符串拼接。
2.1. 列表推导式:["{key} = %s".format(key=key) for key in data]
- 遍历
data的键 :for key in data会依次取出data中的每个字段名(id、name、age)。 - 格式化字符串 :
"{key} = %s".format(key=key)会将{key}替换为当前遍历的字段名,生成形如"id = %s"、"name = %s"、"age = %s"的字符串。 - 生成列表 :最终得到列表
['id = %s', 'name = %s', 'age = %s']。
2.2. 字符串拼接:','.join(...)
','.join(列表)会将列表中的每个字符串用逗号连接,最终生成字符串:"id = %s,name = %s,age = %s"。- 这个字符串会被拼接到
ON DUPLICATE KEY UPDATE之后,成为 SQL 的更新子句。
最终拼接出的完整 SQL 如下(以students表为例):
INSERT INTO students(id,name,age) VALUES (%s,%s,%s) ON DUPLICATE KEY UPDATE id = %s,name = %s,age = %s- 当插入的数据主键 / 唯一键已存在时,MySQL 会执行
UPDATE后的逻辑,将对应字段更新为新值。 - 这里的
%s是占位符,后续会通过cursor.execute(sql, tuple(data.values())*2)传入插入值 和更新值 (因为插入和更新各需要一次值,所以乘以 2)。