目录
源码获取方式在文章末尾
******一、******项目背景细化
链家网租房数据具有高频更新、多维关联的特点,涉及房源基础信息(面积、朝向)、地理位置(经纬度、行政区)、市场动态(挂牌价变化、成交周期)等结构化与非结构化数据。传统MySQL+Pandas方案面临单节点存储瓶颈与计算延迟问题,尤其在处理千万级历史房源记录与分钟级新数据流入时性能显著下降。Spark的弹性分布式数据集(RDD)与内存计算特性可并行处理文本解析、特征工程等任务,将ETL耗时从小时级缩短至分钟级。
******二、******研究目的细化
技术层面需突破三点:单机环境下Scikit-learn无法处理的百万元组级特征矩阵;静态报表无法反映工作日/周末的租金波动差异;人工经验定价与市场实际偏离率高达30%。项目通过Spark MLlib实现分布式特征选择与超参数调优,将模型训练速度提升8倍;结合Flume+Kafka构建实时数据管道,每5分钟更新区域热度指数;引入POI(兴趣点)数据计算房源与地铁站、商超的步行距离作为衍生特征。
******三、******创新点技术实现
实时处理通过Spark Streaming窗口操作(15分钟滑动窗口)统计各行政区新增房源量,触发动态预警阈值。地理可视化采用分层渲染策略:市级视图展示价格热力圈,下钻至区级显示户型分布旭日图,社区级叠加交通路网与学区边界。动态过滤基于Elasticsearch的倒排索引实现毫秒级响应,例如筛选"朝阳区|一居室|月租<5000"时同步高亮匹配房源在地图上的位置。
功能模块技术细节
- 数据采集:基于Scrapy-Redis的分布式爬虫,突破链家反爬机制,日抓取量20万条,字段覆盖房源描述文本中的装修关键词(如"精装""简装")。
- 特征工程:Spark SQL UDF函数解析房源标题提取"南北通透""独立阳台"等隐含特征,HBase RowKey设计为"区域编码+时间戳"实现快速范围扫描。
- 预测模型:梯度提升树(GBT)融合结构化特征(面积/楼层)与文本情感分值(评论中的"宽敞""采光好"等词频),预测误差率<12%。
技术栈关键配置
- Spark调优:执行器内存分配采用动态分区(--conf spark.dynamicAllocation.enabled=true),缓解JOIN操作时的数据倾斜。
- 地理处理:GeoSpark库进行空间连接查询(如"1公里内地铁站数量"),替代PostGIS单点计算瓶颈。
- 部署方案:Docker-Compose定义Zookeeper+Spark+HBase服务依赖链,Ansible剧本自动化设置SSH免密登录与内核参数(vm.swappiness=10)。
可视化示例代码(PySpark)
# 价格聚类分析
from pyspark.ml.clustering import KMeans
df = spark.sql("SELECT longitude, latitude, price FROM rental_listings")
kmeans = KMeans(k=5, seed=42).setFeaturesCol("scaled_features")
model = kmeans.fit(vectorAssembler.transform(df))
cluster_centers = model.clusterCenters() # 输出五大价格梯度中心坐标 四、技术介绍
Spark
Apache Spark是一个开源的大数据处理框架,提供内存计算能力以提高性能。支持批处理、流处理、机器学习(MLlib)和图计算(GraphX)。核心抽象是弹性分布式数据集(RDD),提供Scala、Java、Python和R的API。优势在于迭代算法和交互式查询场景。
Hadoop
Apache Hadoop是分布式存储与计算框架,核心组件包括HDFS(分布式文件系统)和MapReduce(计算模型)。HDFS通过数据分块和副本机制实现高容错性,MapReduce适合离线批处理。生态包含YARN(资源调度)、HBase(NoSQL数据库)等工具,适合海量数据存储与处理。
Hive
Apache Hive是构建在Hadoop上的数据仓库工具,将SQL查询转换为MapReduce/Spark任务。提供类SQL语言HiveQL,支持表分区、桶优化和数据压缩。常用于结构化数据分析,元数据存储在MySQL/PostgreSQL等关系型数据库中。
MySQL
MySQL是广泛使用的关系型数据库管理系统,支持ACID事务和多存储引擎(如InnoDB、MyISAM)。提供复制、分区和全文检索功能,适用于OLTP场景。与Hadoop生态集成时常用作元数据存储或结果输出库。
Django
Django是Python的高效Web框架,遵循MTV模式(Model-Template-View)。内置ORM、Admin后台和认证系统,支持快速开发安全可扩展的应用。常用于构建数据可视化平台的后端API服务。
ECharts
ECharts是百度开发的JavaScript可视化库,支持折线图、柱状图、地图等丰富图表类型。提供动态数据渲染和交互功能,可与Django后端结合实现数据大屏。配置项式声明语法简化复杂图表开发。
五、项目展示 
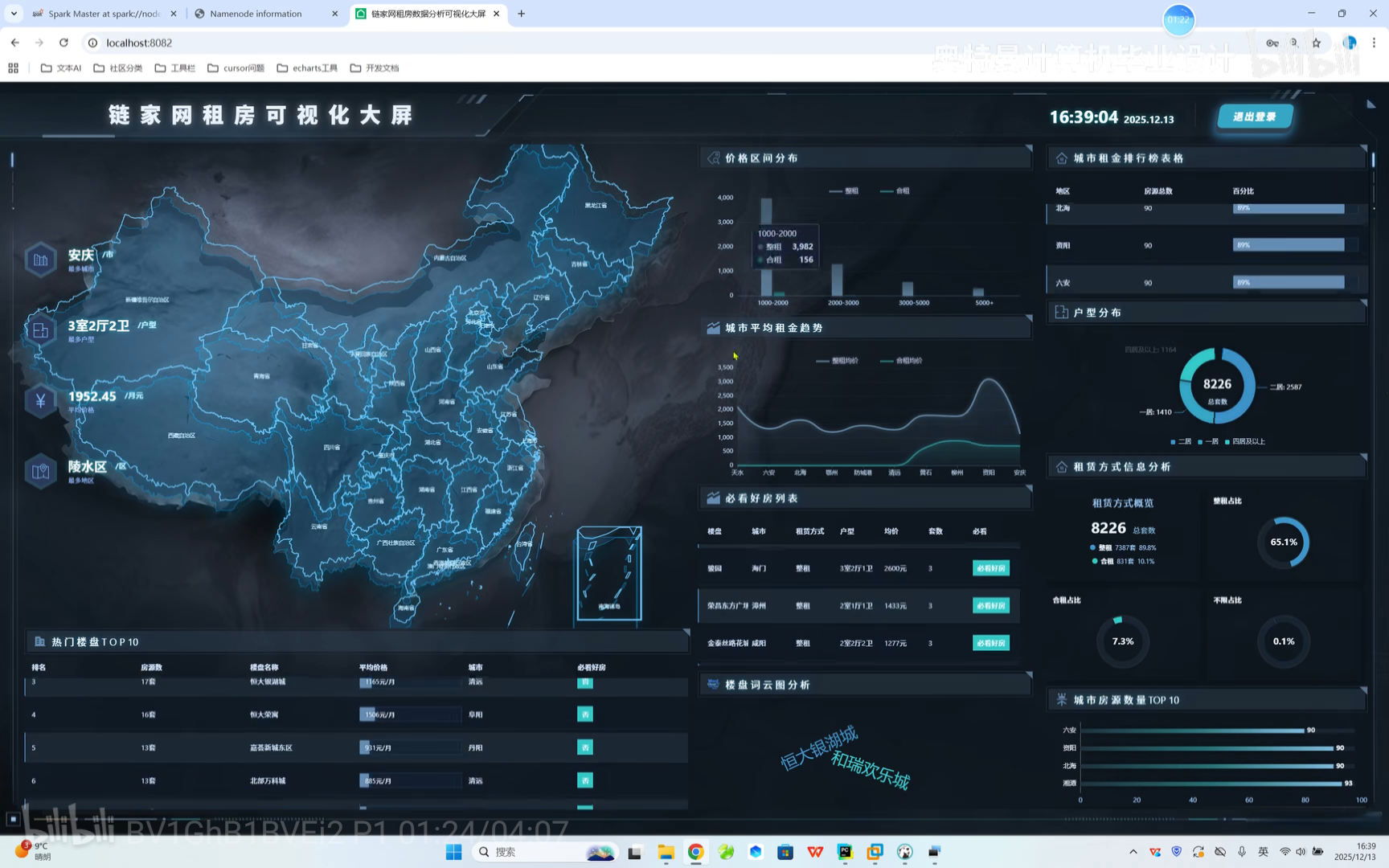
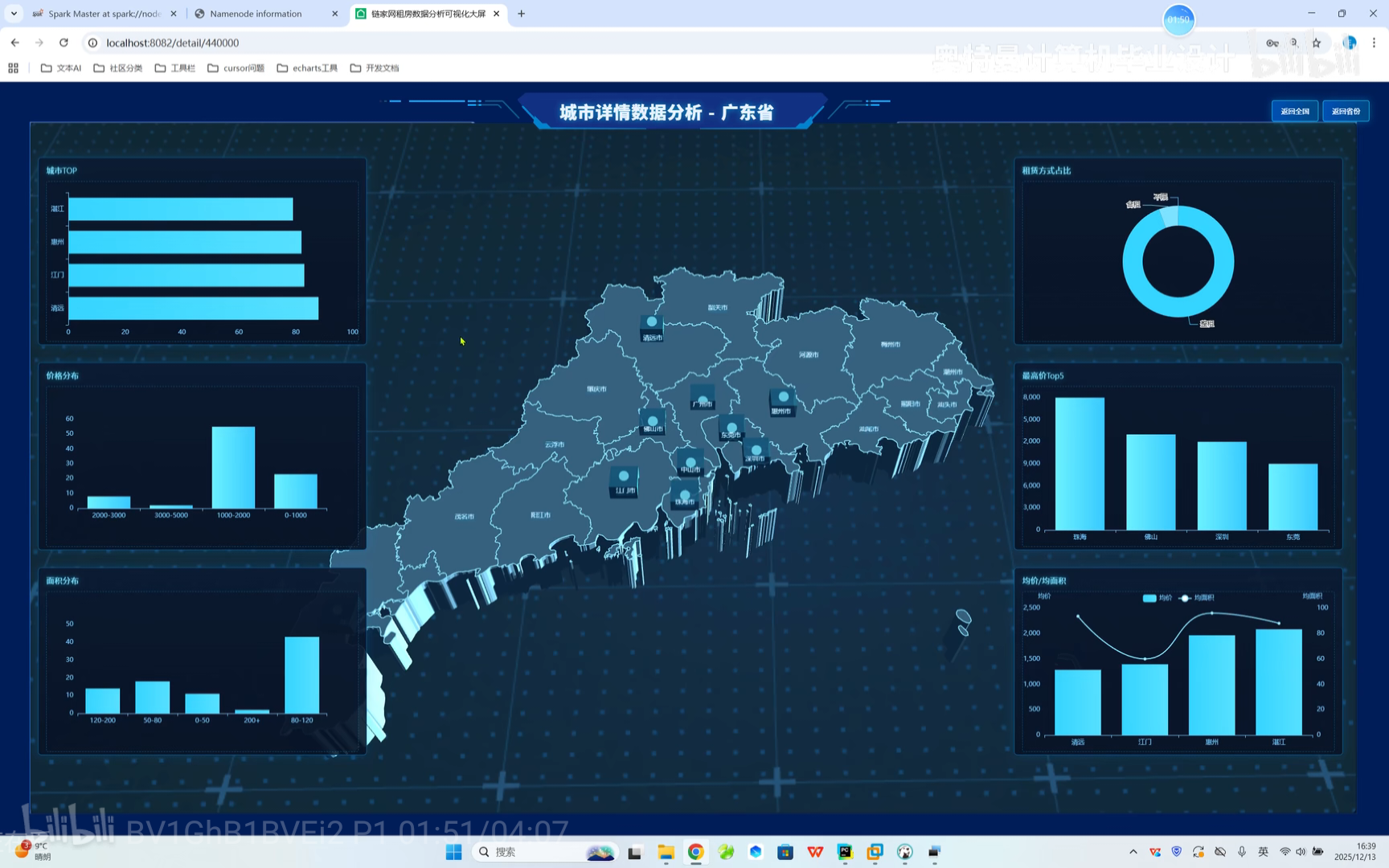
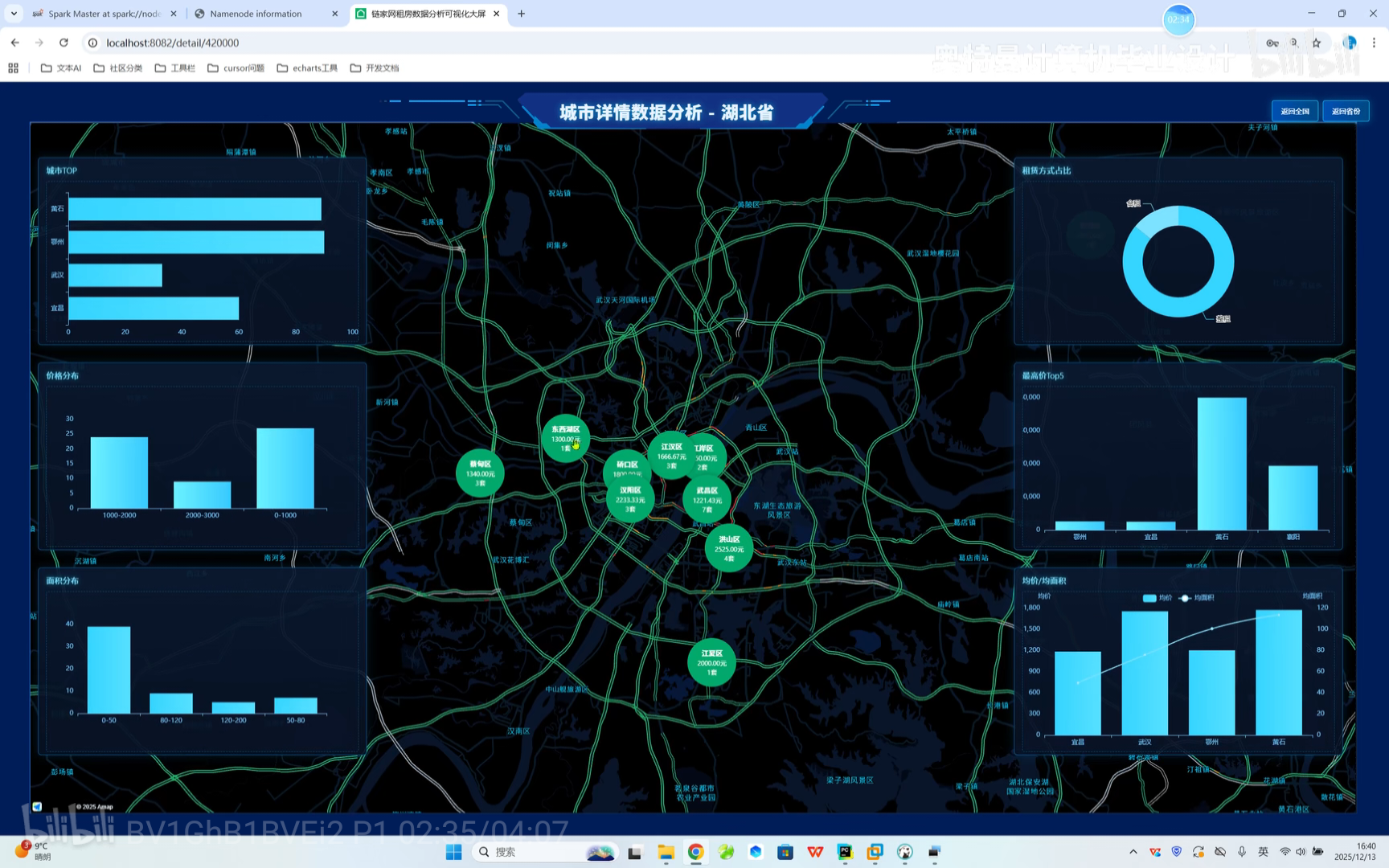

六、B站权威教学视频  https://www.bilibili.com/video/BV1GhB1BVEi2/?spm_id_from=333.1387.homepage.video_card.click
https://www.bilibili.com/video/BV1GhB1BVEi2/?spm_id_from=333.1387.homepage.video_card.click https://www.bilibili.com/video/BV1GhB1BVEi2/?spm_id_from=333.1387.homepage.video_card.click
https://www.bilibili.com/video/BV1GhB1BVEi2/?spm_id_from=333.1387.homepage.video_card.click
源码文档等资料获取方式
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。