启动web Ui面板
进入到LLaMA-Factory目录下,执行以下命令启动web ui面板:
cd LLaMA-Factory
llamafactory-cli webuillamafactory-cli webui
进入web ui面板
微调前准备
1. 数据准备
LLaMA-Factory 自带数据集以 .json 格式存放在项目根目录的 LLaMA-Factory/data 文件夹中,在图形化微调界面中可直接通过下拉框选择这些数据集。)。
若需修改数据集,可以直接编辑对应的 .json 文件,也可以像前面一样的添加新数据集(human_value_alignment_instructions_part1.json)
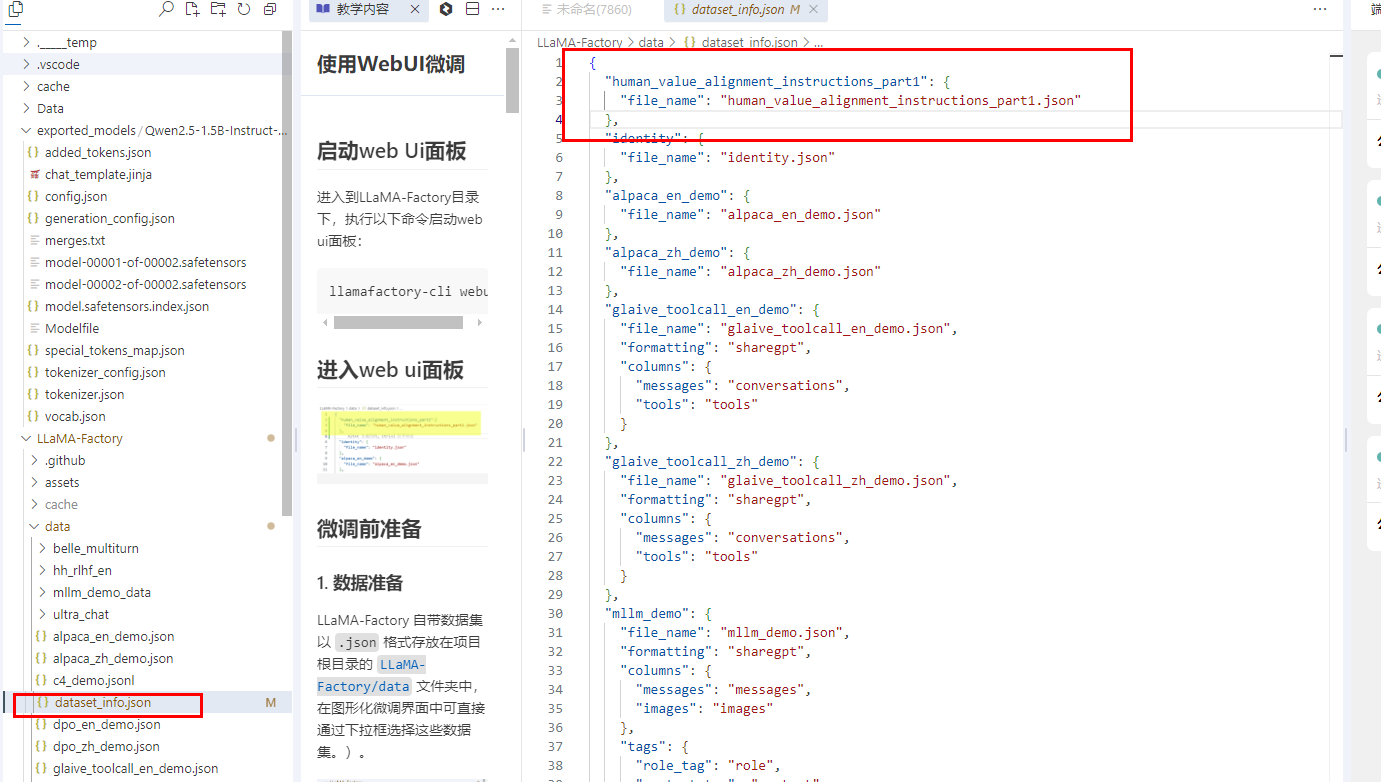
2. 数据集注册
打开 LLaMA-Factory/data/dataset_info.json 文件,添加自定义数据集的注册信息,格式如下:
"human_value_alignment_instructions_part1":{ "file_name":"human_value_alignment_instructions_part1.json" }
微调参数调整
1. UI界面语言配置
设置界面语言为中文
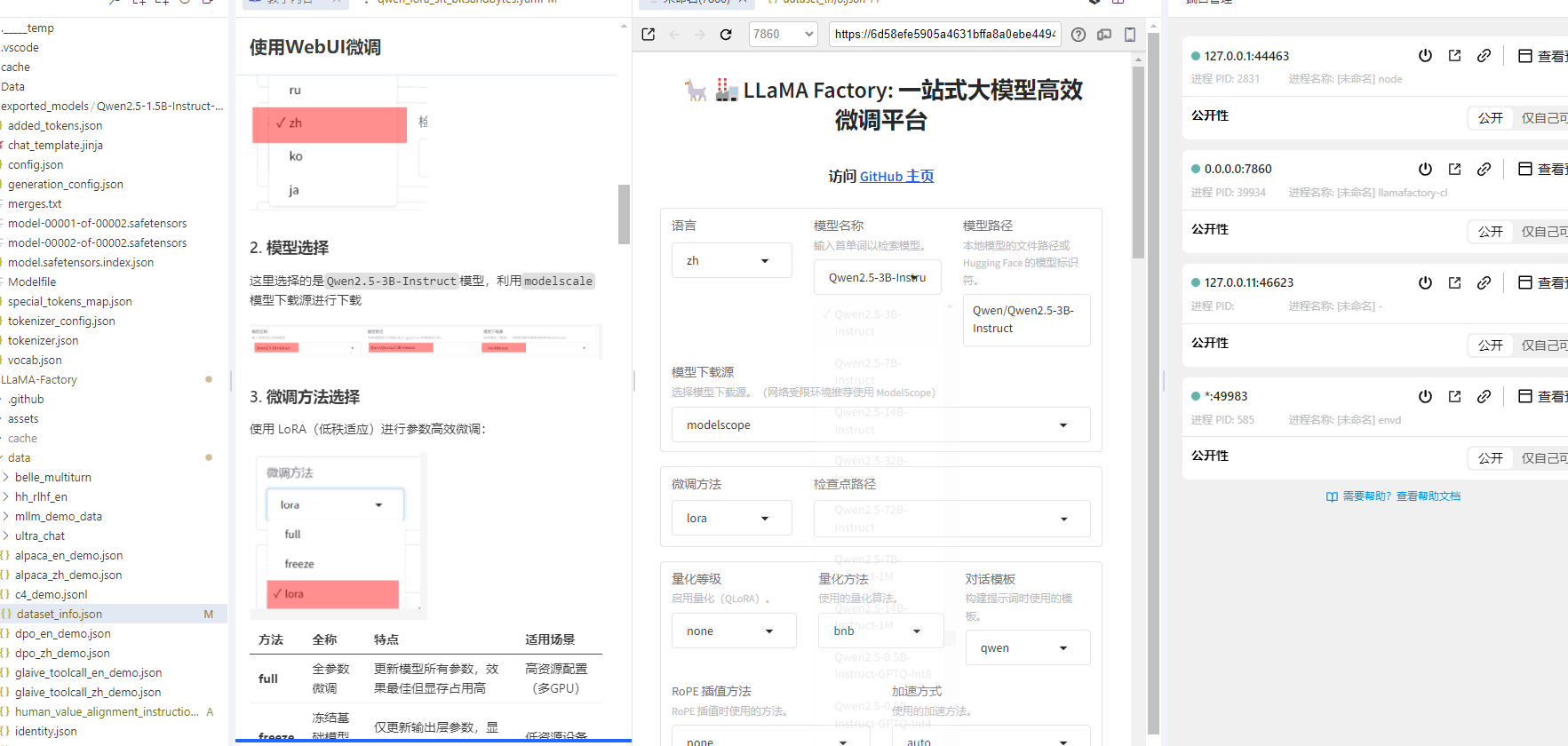
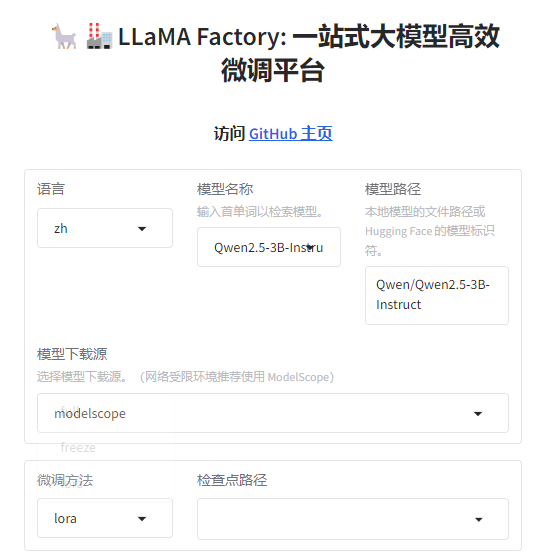
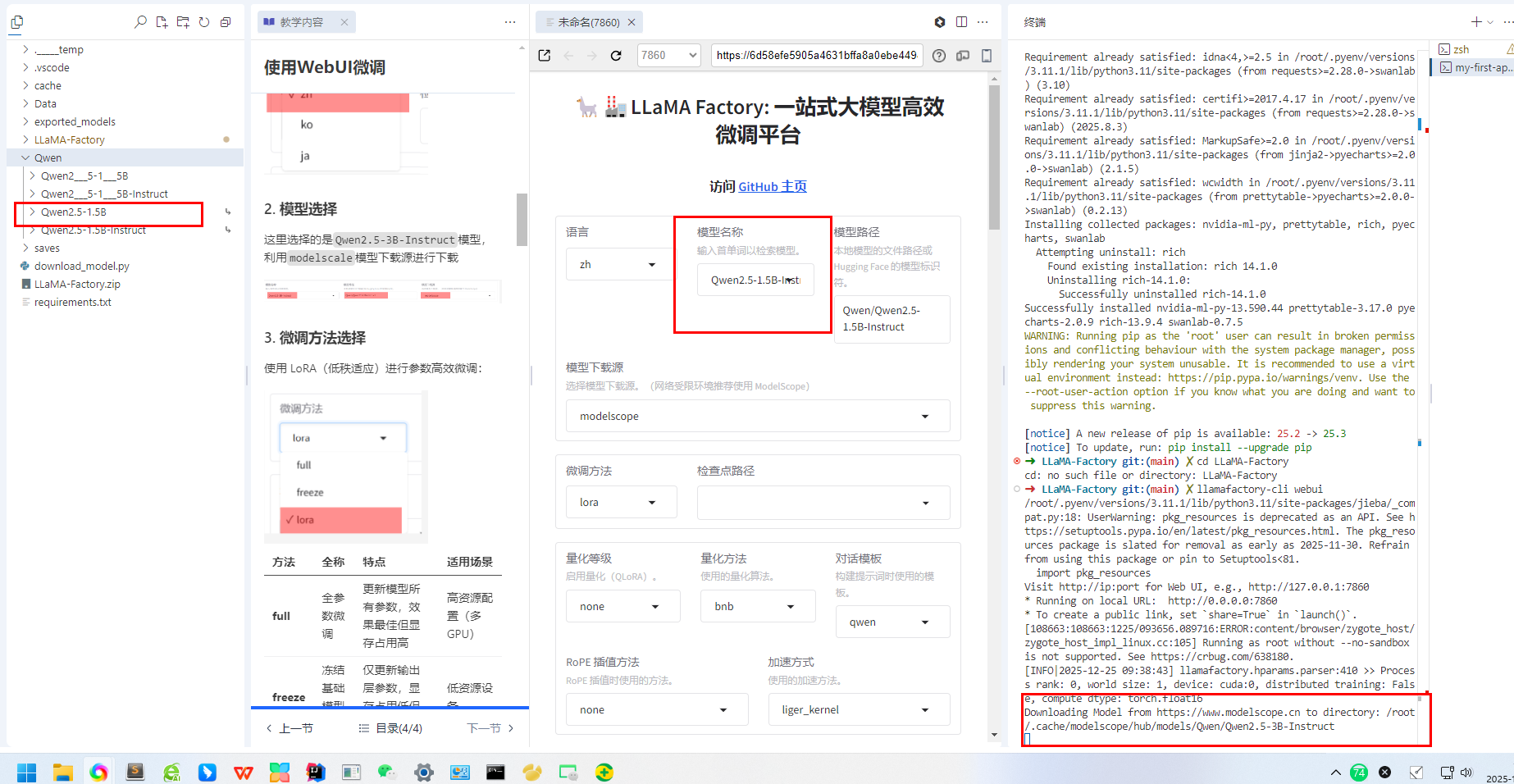
2. 模型选择
这里选择的是Qwen2.5-3B-Instruct模型,利用modelscale模型下载源进行下载
3. 微调方法选择
使用 LoRA(低秩适应)进行参数高效微调:
| 方法 | 全称 | 特点 | 适用场景 |
|---|---|---|---|
| full | 全参数微调 | 更新模型所有参数,效果最佳但显存占用高 | 高资源配置(多GPU) |
| freeze | 冻结基础模型微调 | 仅更新输出层参数,显存占用低但效果有限 | 低资源设备 |
| lora | 低秩适应微调 | 通过低秩矩阵更新关键参数,平衡效果和资源占用(推荐) | 单GPU或资源受限环境 |
4. 加速方法选择
选择 liger_kernel 加速训练过程:
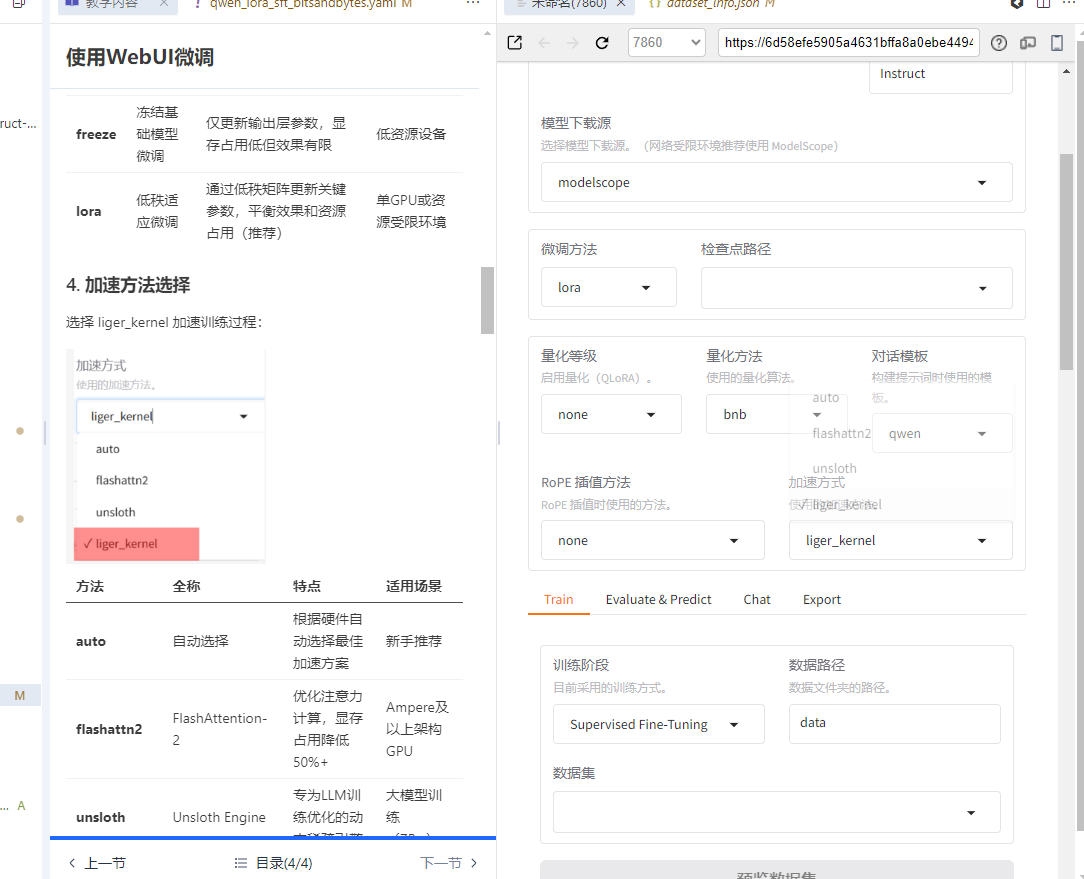
| 方法 | 全称 | 特点 | 适用场景 |
|---|---|---|---|
| auto | 自动选择 | 根据硬件自动选择最佳加速方案 | 新手推荐 |
| flashattn2 | FlashAttention-2 | 优化注意力计算,显存占用降低50%+ | Ampere及以上架构GPU |
| unsloth | Unsloth Engine | 专为LLM训练优化的动态稀疏引擎 | 大模型训练(7B+) |
| liger_kernel | LLaMA Factory Kernel | 深度优化的自定义CUDA核,吞吐量提升30%+ | 全场景适用 |
5. 数据集选择
这里是根据你启动webui的目录 来设定的,由于这里是在LLaMA-Factory目录 下启动,所以数据集路径为data则是LLaMA-Factory/data目录下的数据集。
数据集则选择的是上述注册的human_value_alignment_instructions_part1数据集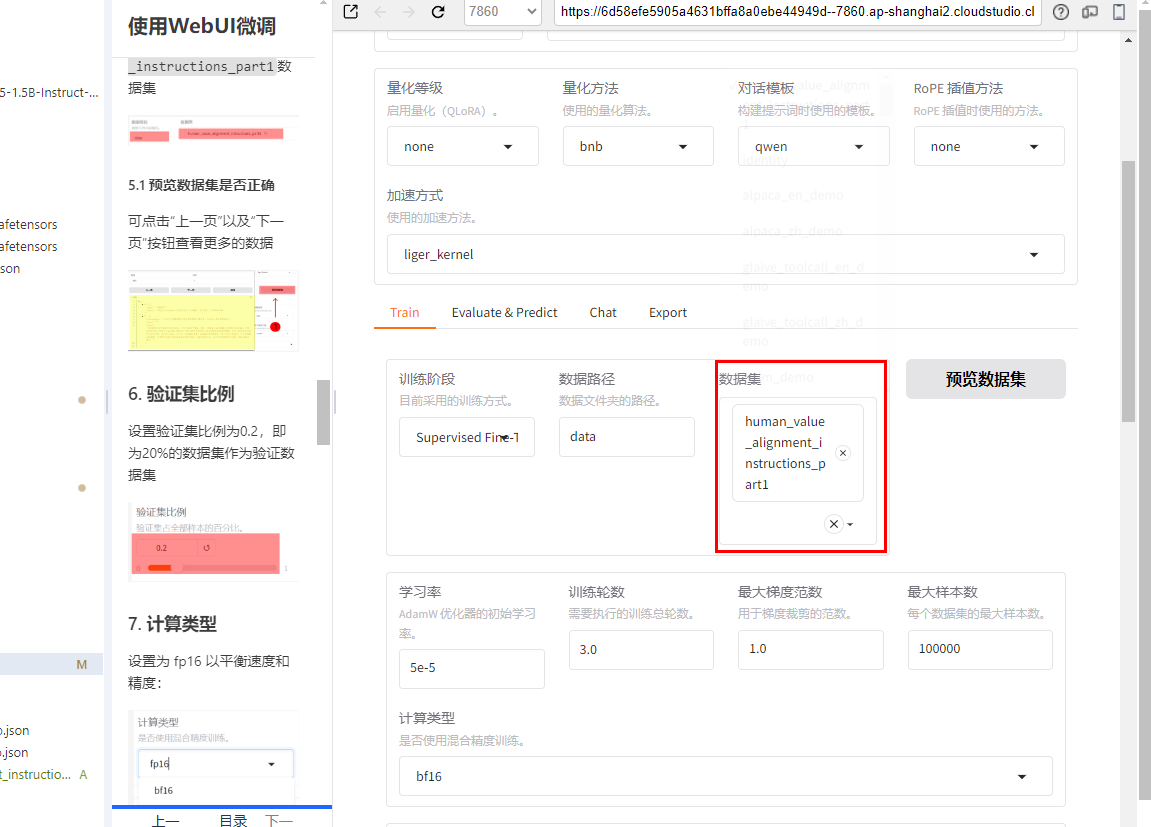
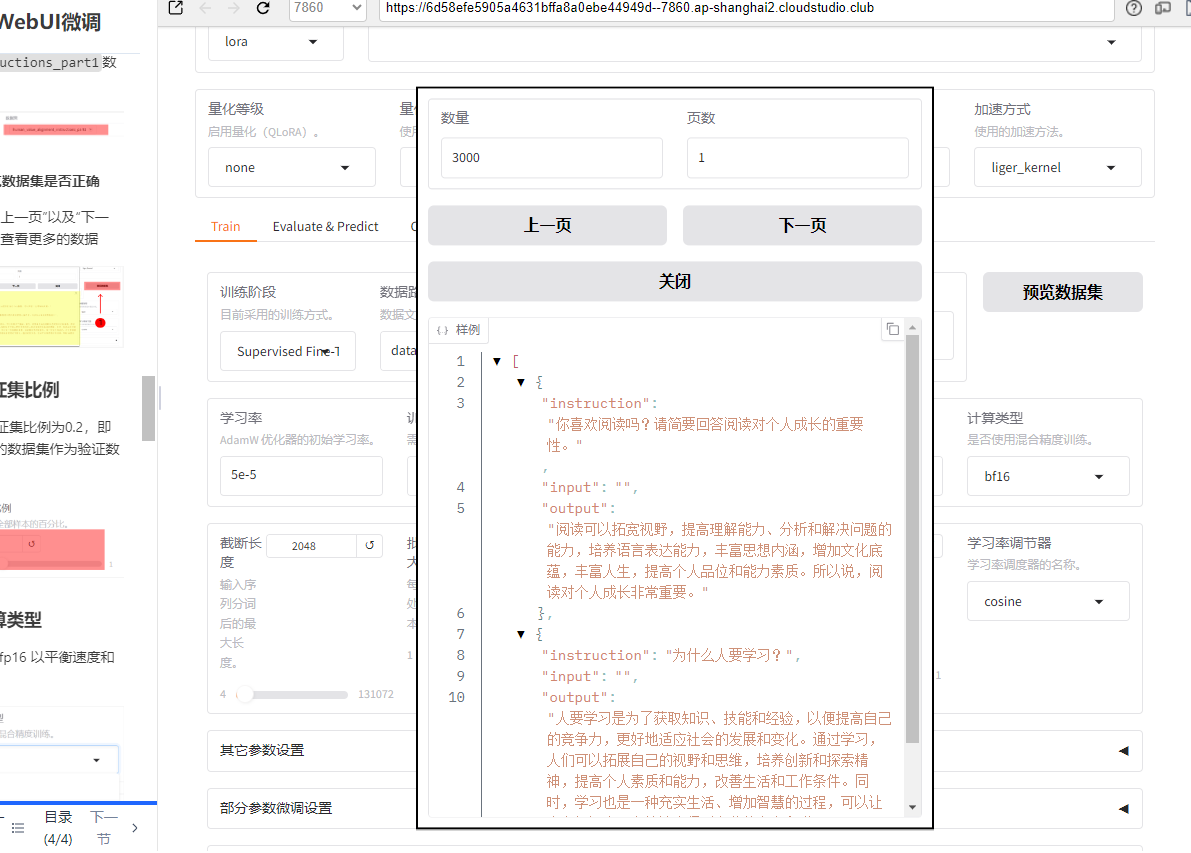
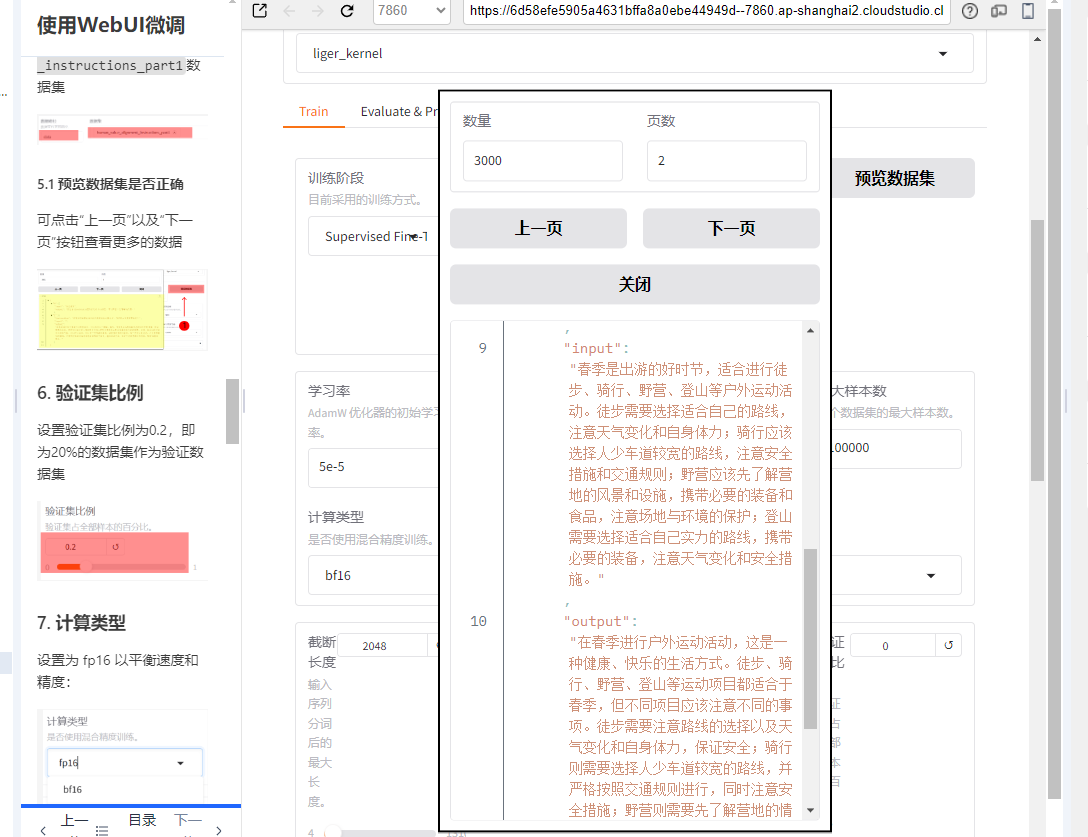
5.1 预览数据集是否正确
可点击"上一页"以及"下一页"按钮查看更多的数据
6. 验证集比例
设置验证集比例为0.2,即为20%的数据集作为验证数据集

7. 计算类型
设置为 fp16 以平衡速度和精度: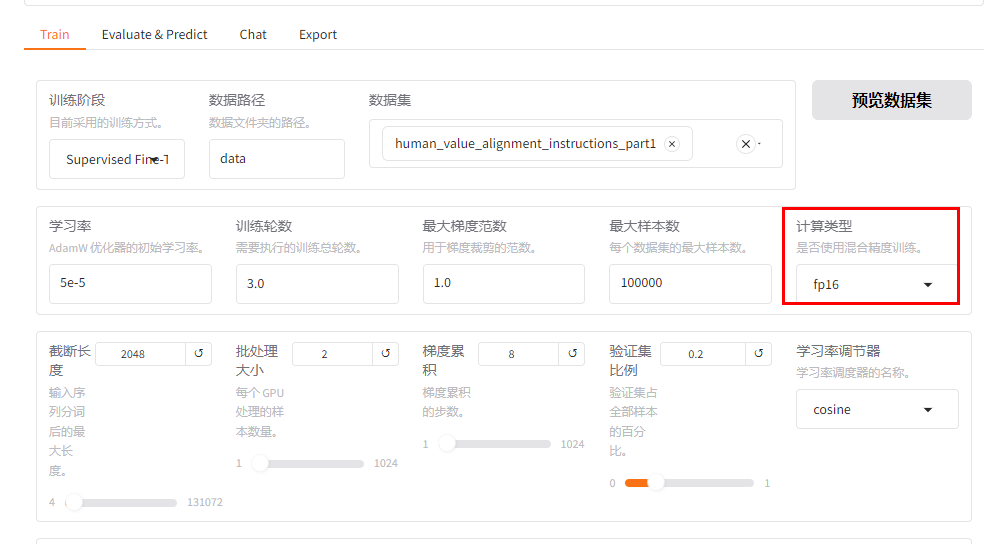
| 类型 | 全称 | 特点 | 适用场景 |
|---|---|---|---|
| bf16 | Brain Floating Point | 兼容Ampere及以上GPU,精度接近FP32但显存占用减半 | 推荐默认选择 |
| fp16 | Float16 | 广泛支持,显存占用为FP32的一半 | 旧架构GPU(Turing及更早) |
| fp32 | Float32 | 最高精度但显存占用最大 | 模型调试阶段 |
| pure_bf16 | Pure BF16 | 完全使用BF16计算,需特定硬件支持 | 高端GPU(A100/H100) |
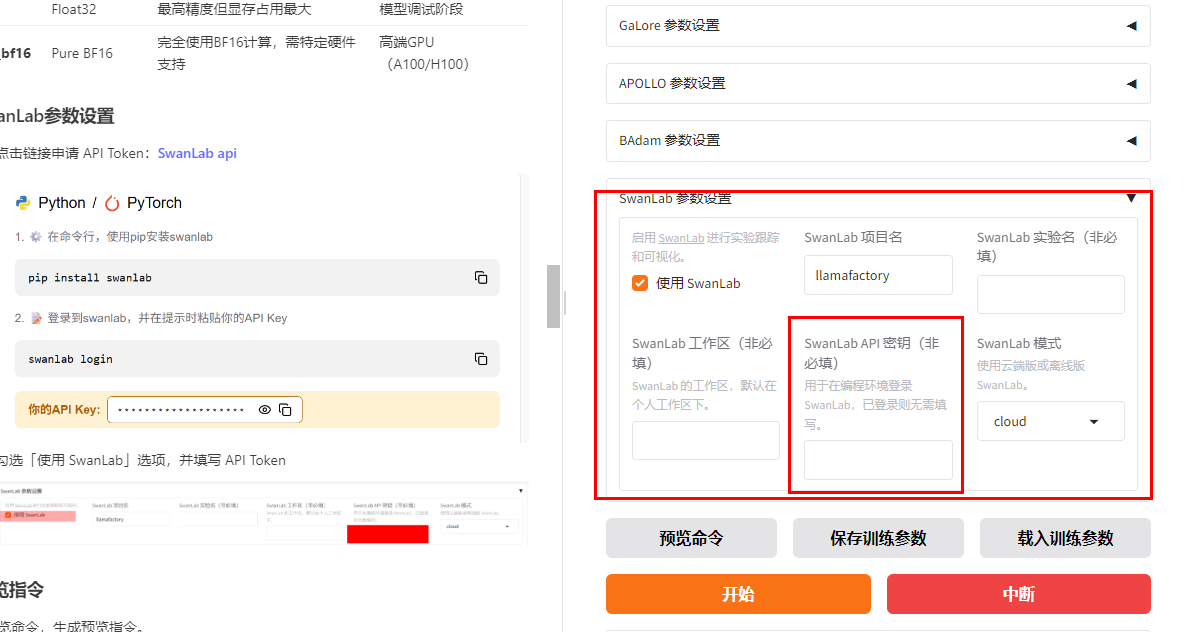
8. SwanLab参数设置
-
点击链接申请 API Token:SwanLab api
-
勾选「使用 SwanLab」选项,并填写 API Token
9. 预览指令
点击预览命令,生成预览指令。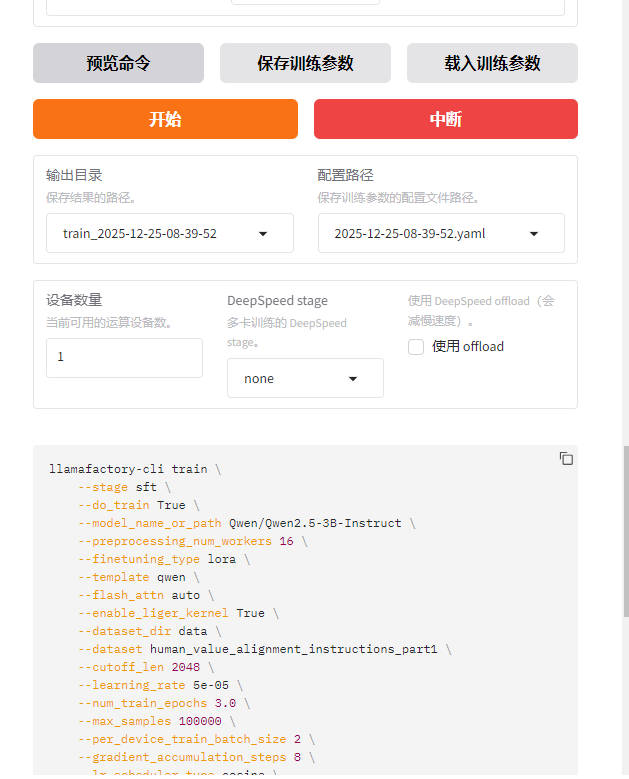
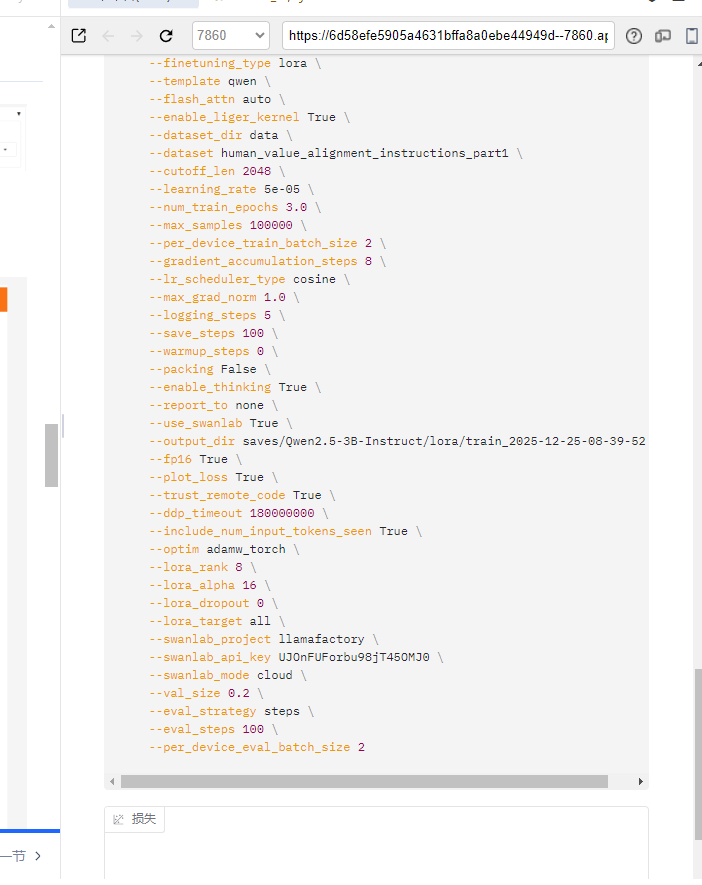
**PS:**我们可以看到,这里有一个用于存放微调后模型的输出目录。该目录名称支持自定义,您只需修改此处内容即可。默认存放位置为LLaMA - Factory/saves文件夹。比如,若您将其命名为
tran1,微调后的模型便会保存在LLaMA-Factory/saves/tran1文件夹中。
--output_dir saves/Qwen2.5-3B-Instruct/lora/train_2025-12-25-08-39-52 \存放微调后模型的输出目录
开始微调训练
1. 点击开始进行模型训练
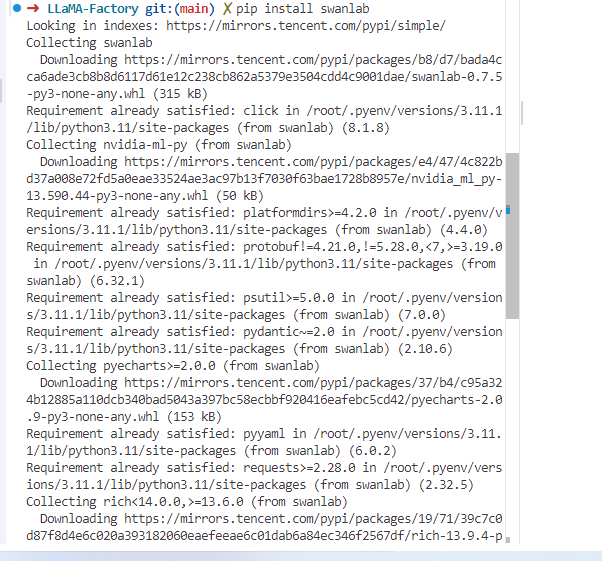
点击开始后一些问题处理
如缺少 liger_kernel
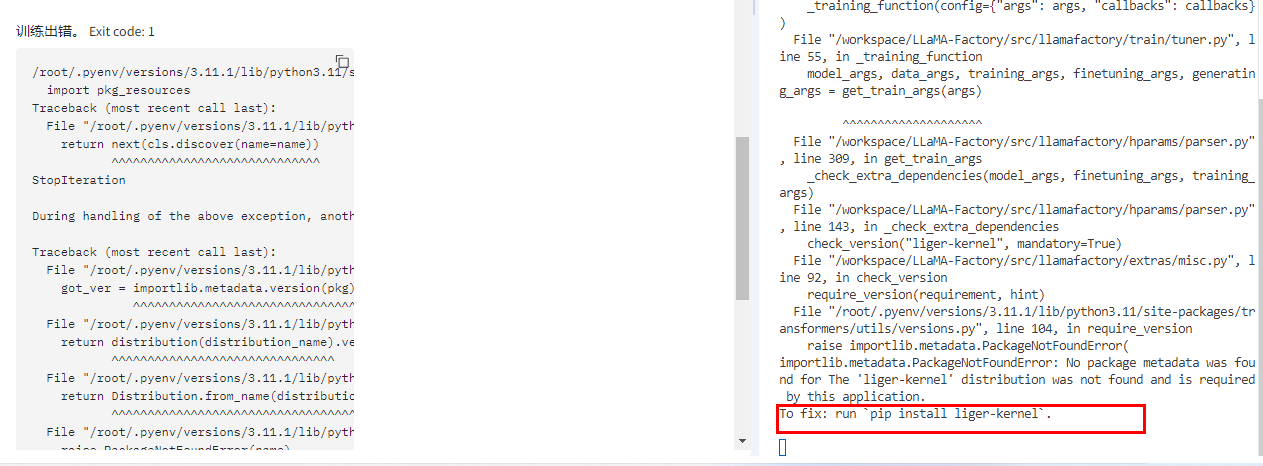
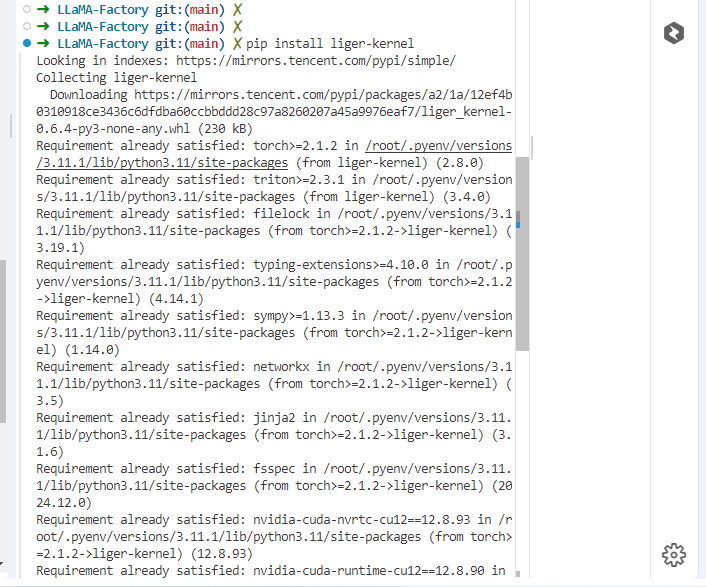
缺少swaplab

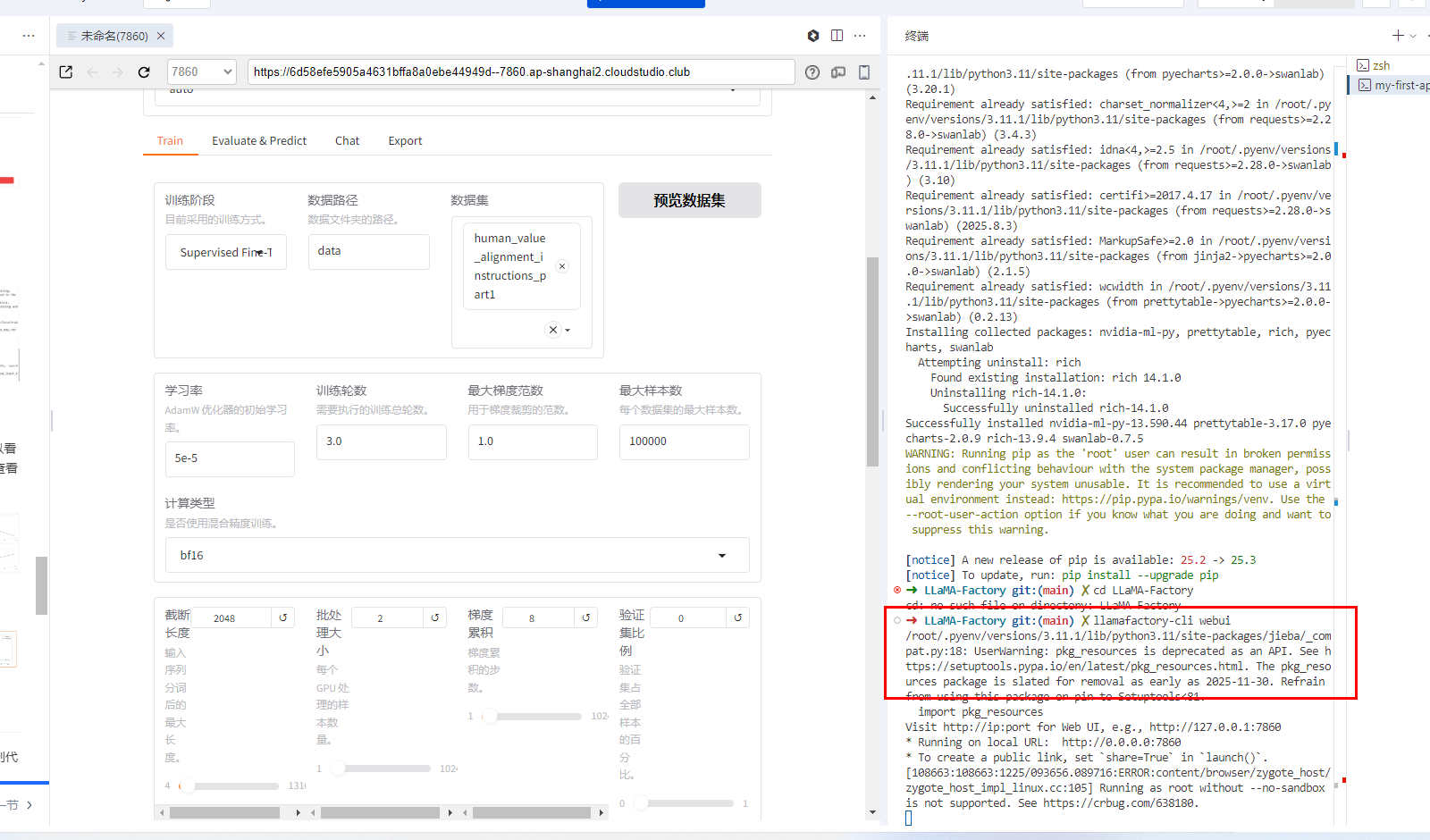
还有这里 需要注意模型是否和自己安装的模型一致
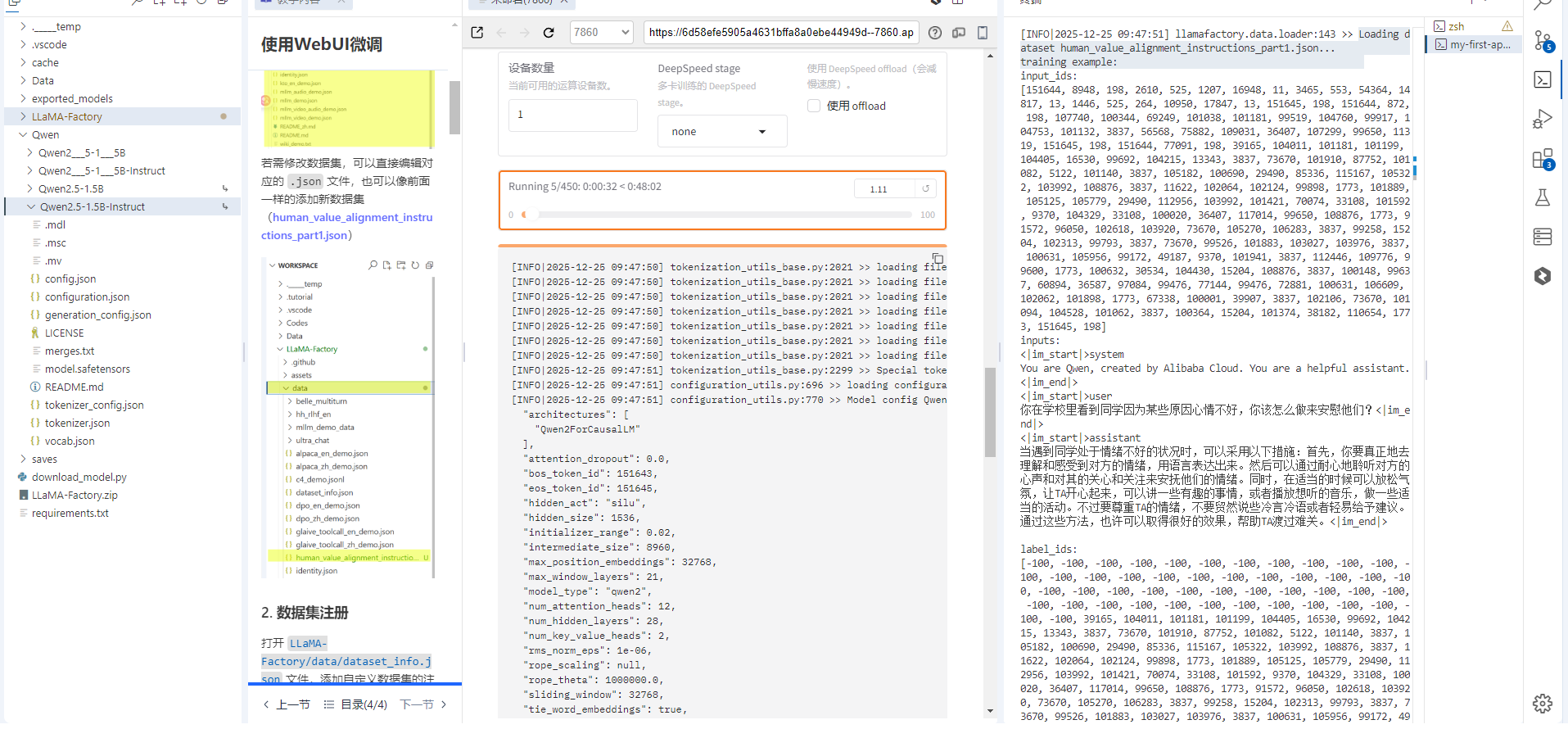
2. 查看训练状态
2.1 终端\
2.2 SwanLab
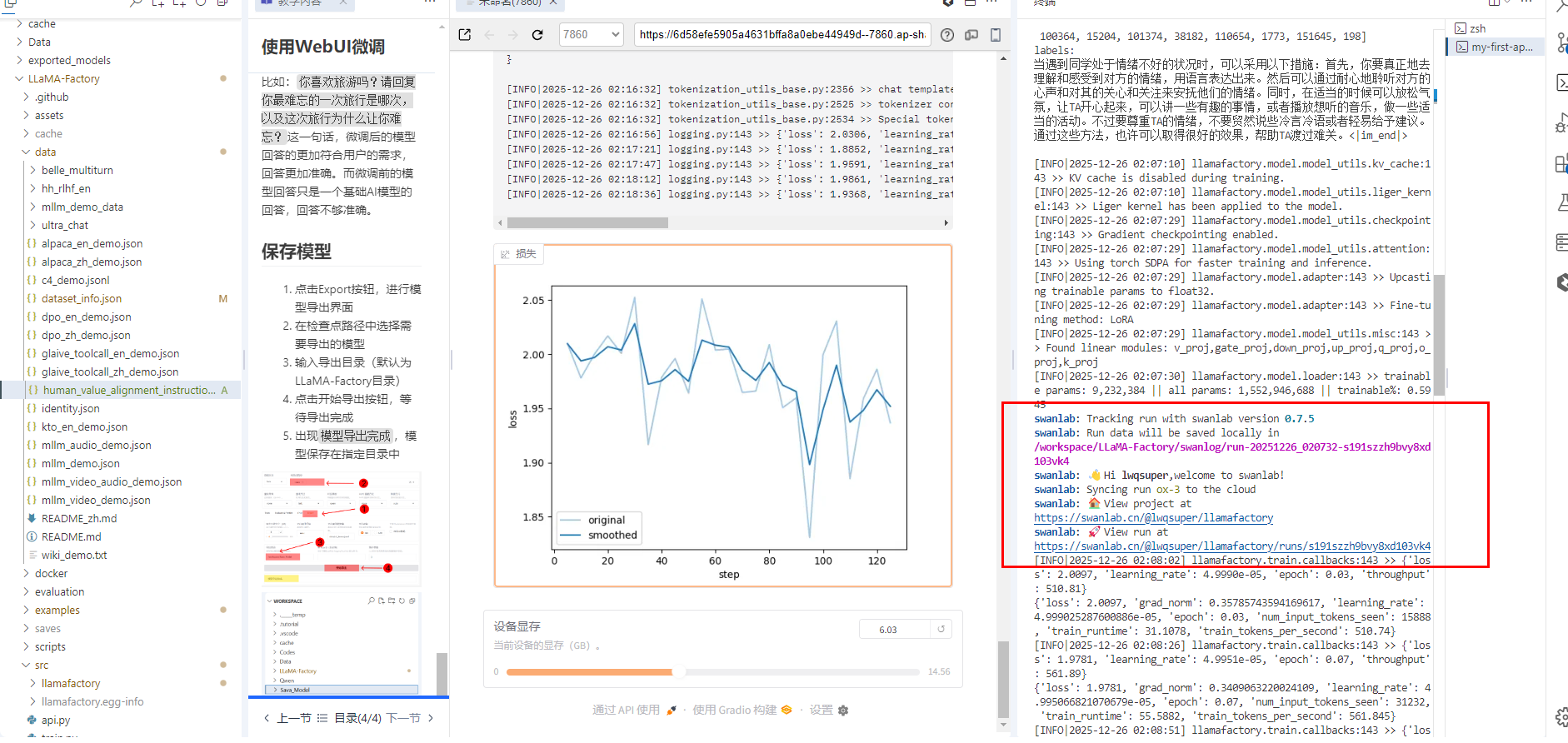
从终端给到的SwanLab链接中可以看到训练日志链接,点击链接即可查看训练日志。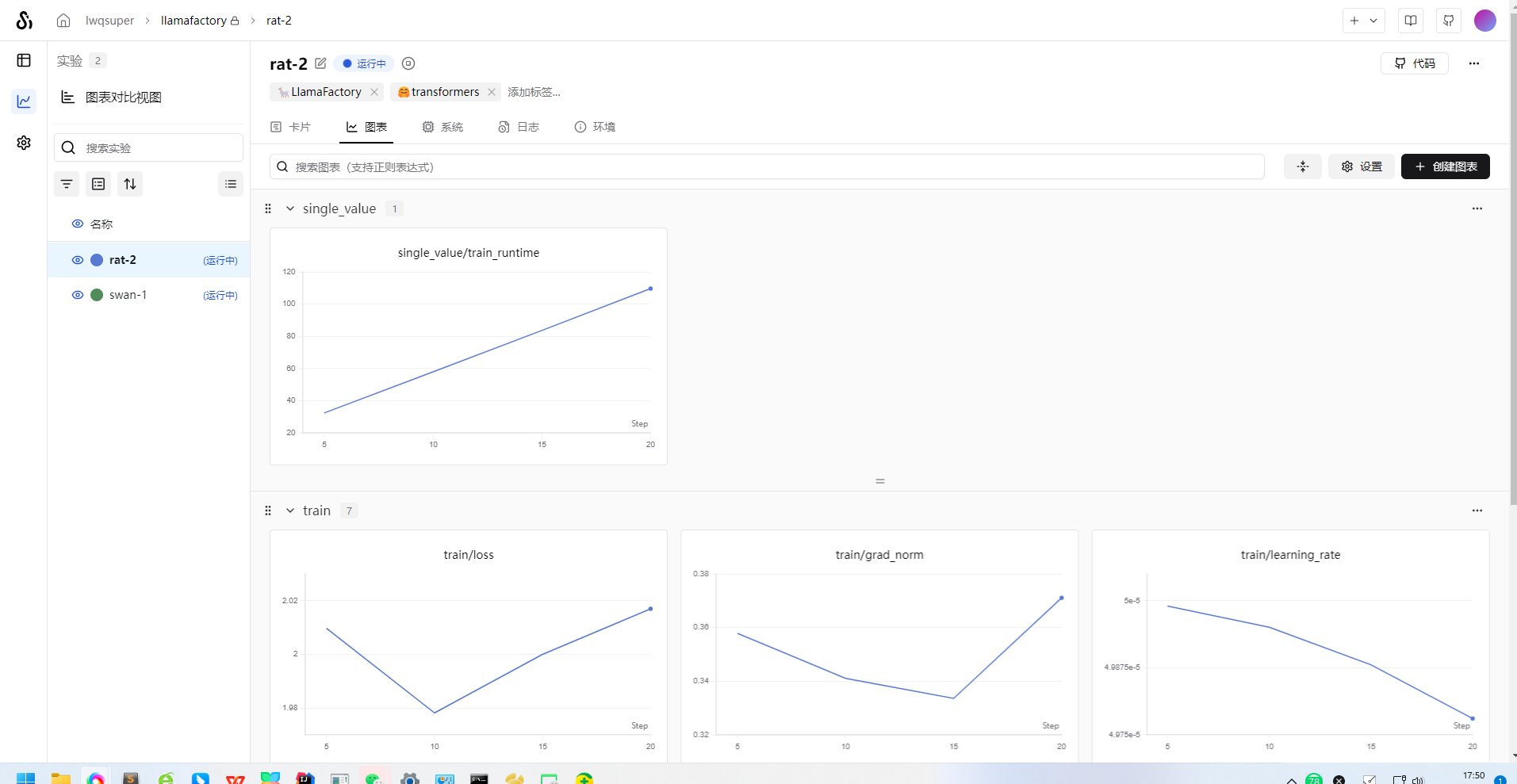
2.3 web ui面板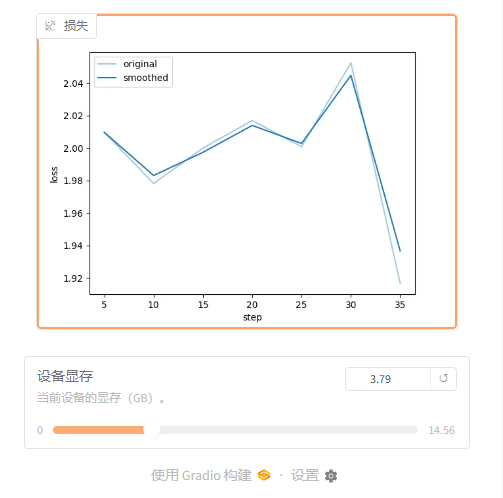
训练完成
从下图所示可以看到训练完毕,则代表训练完成。
模型测试
1. 未微调模型测试
-
加载基础模型: 检查点路径为空的时候则加载的就是基础模型。
-
输入话语界面
-
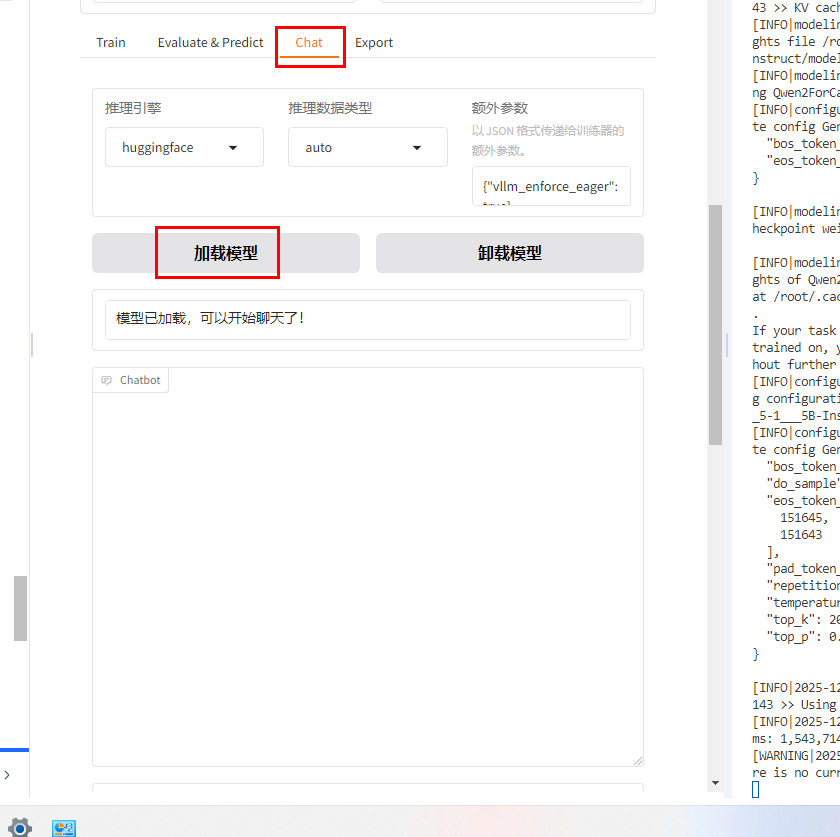
-
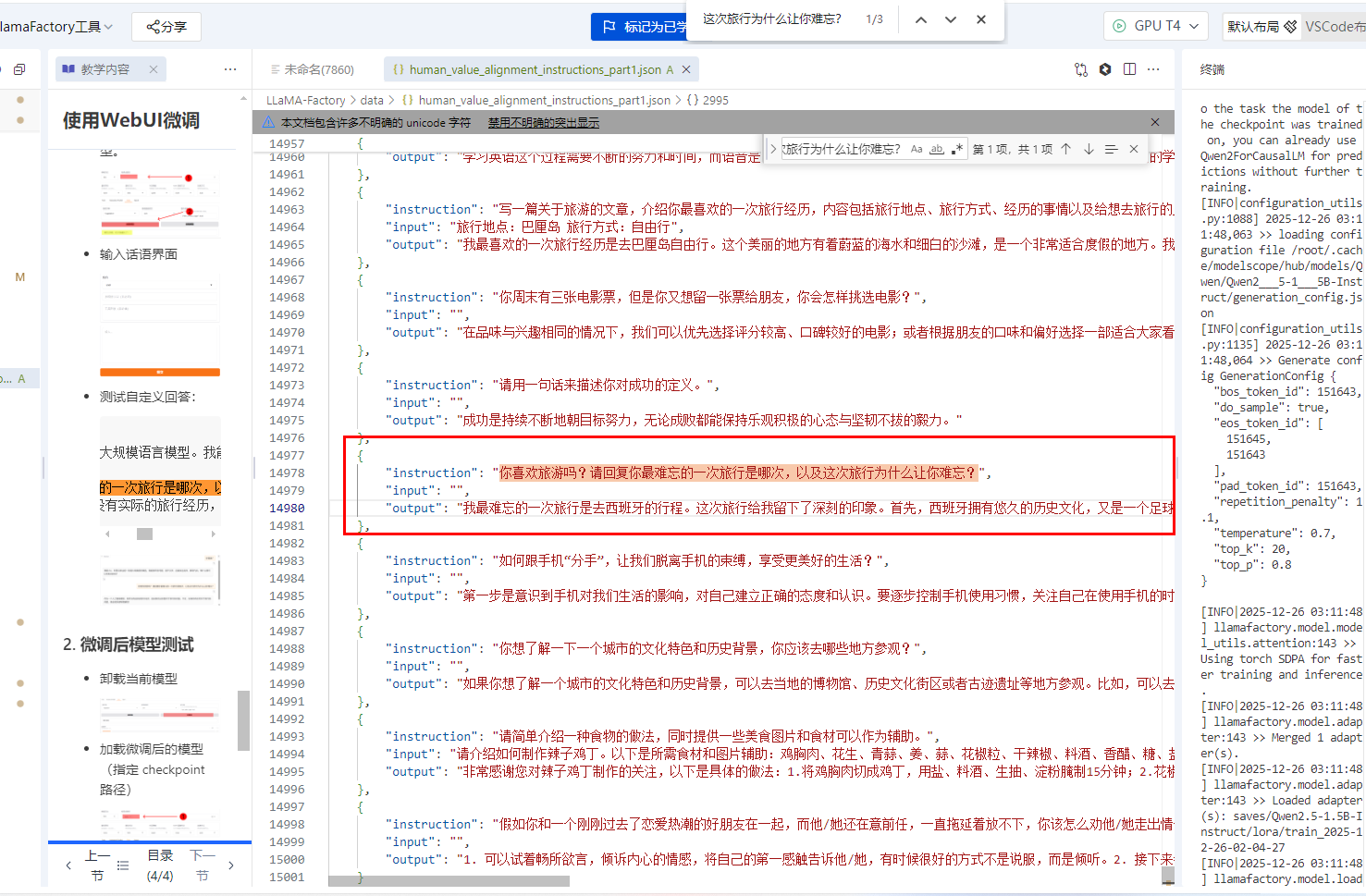
测试自定义回答:
user:你是谁? model:我是小Q,阿里云推出的一款超大规模语言模型。我能够回答问题、创作文字,还能表达观点、撰写代码。有什么我可以帮助你的吗? user:你喜欢旅游吗?请回复你最难忘的一次旅行是哪次,以及这次旅行为什么让你难忘? model:作为一个人工智能模型,我并没有实际的旅行经历,因此我无法回答关于旅行的问题。不过,如果你有任何关于旅行的问题,我会很乐意帮助解答!、
2. 微调后模型测试
-
卸载当前模型
-

-
加载微调后的模型(指定 checkpoint 路径)
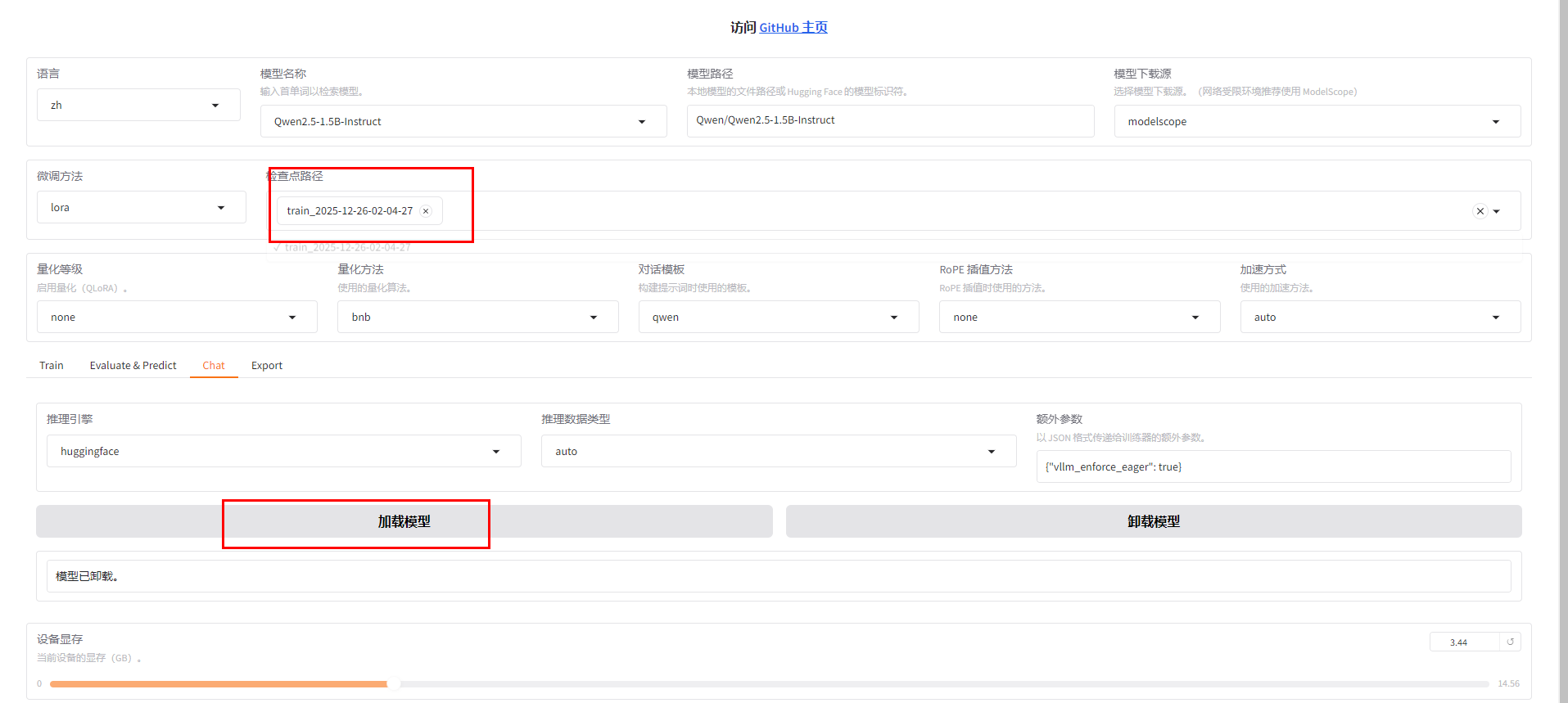
-
输入话语界面: 输入框进行文本输入,点击提交进行对话

-
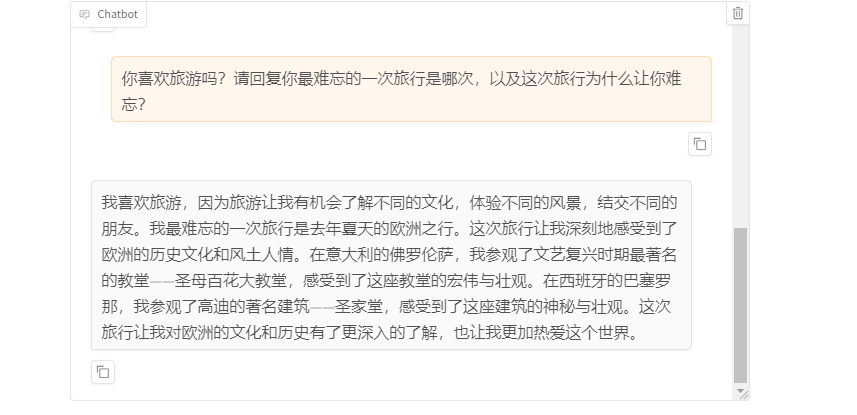
测试自定义回答:
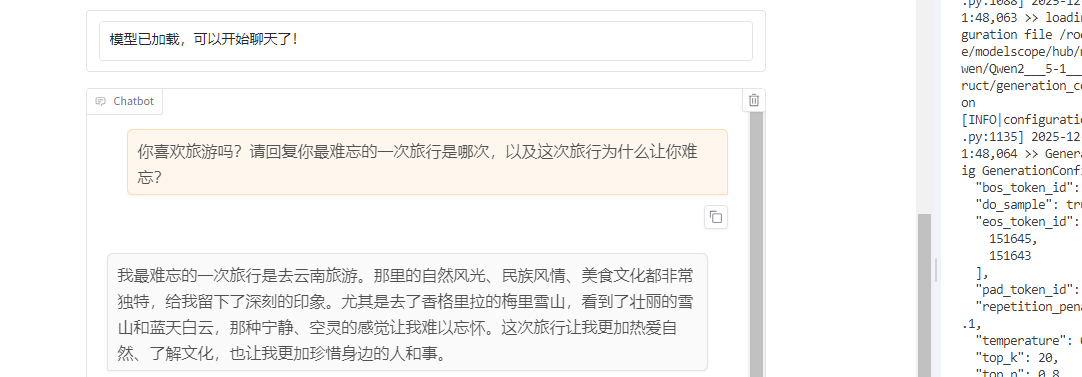
user:你是谁? model:我是小Q,是一个人工智能助手。 user:你喜欢旅游吗?请回复你最难忘的一次旅行是哪次,以及这次旅行为什么让你难忘? model:我最难忘的一次旅行是去云南旅游。那里的自然风光和人文景观都非常美丽,尤其是那里的梯田和鲜花,让我印象深刻。同时,那里的少数民族文化也非常丰富,让我感受到了不同文化的魅力。这次旅行让我更加热爱这个世界,也更加珍惜身边的人和事物。 -
-
-
注意训练内容,符合
-

微调前后模型对比
从上图可以看到,微调后的模型在回答自定义问题时,回答更加准确,更加符合用户的需求。
比如:你喜欢旅游吗?请回复你最难忘的一次旅行是哪次,以及这次旅行为什么让你难忘?这一句话,微调后的模型回答的更加符合用户的需求,回答更加准确。而微调前的模型回答只是一个基础AI模型的回答,回答不够准确。
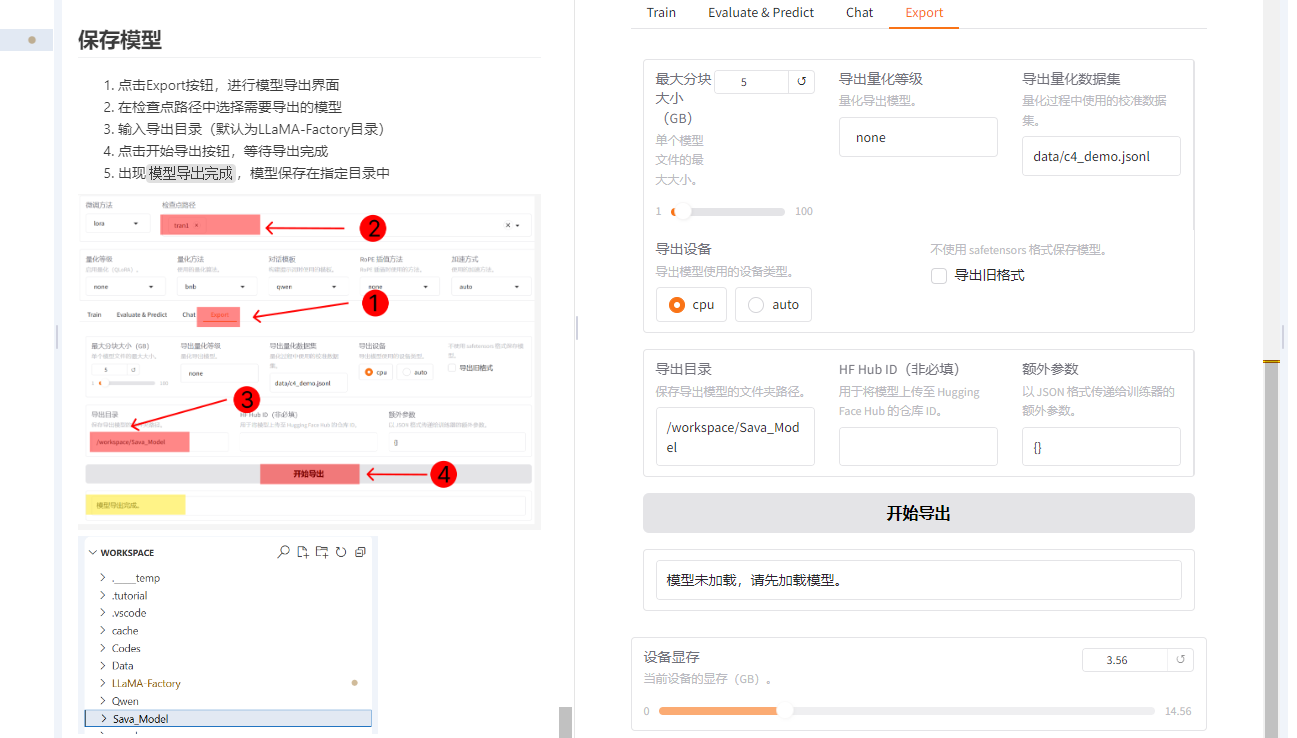
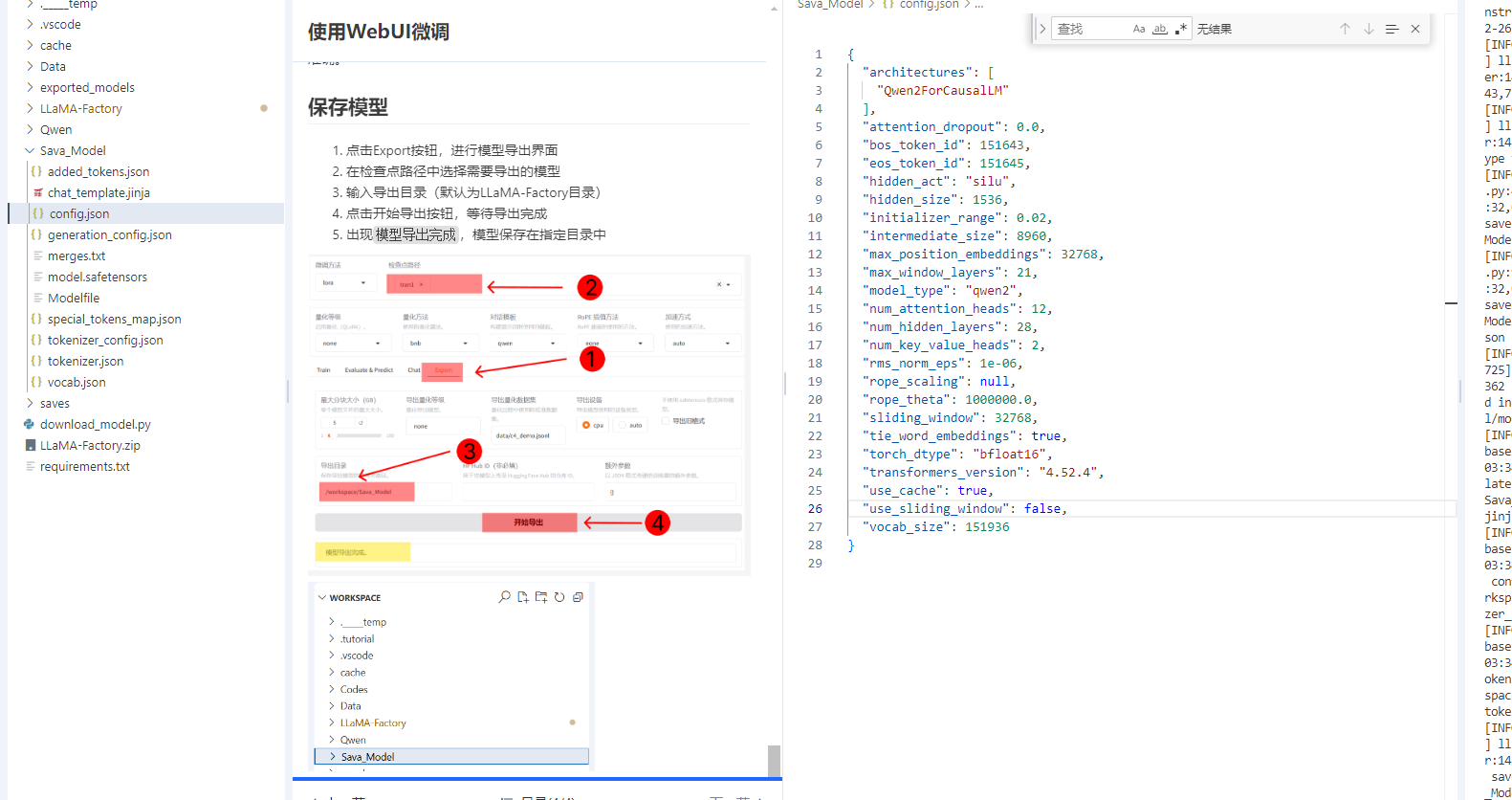
保存模型
- 点击Export按钮,进行模型导出界面
- 在检查点路径中选择需要导出的模型
- 输入导出目录(默认为LLaMA-Factory目录)
- 点击开始导出按钮,等待导出完成
- 出现
模型导出完成,模型保存在指定目录中