一、配置前的前提准备
集群基础环境确认
- 已完成三台节点的免密登录(master能免密登录node1、node2,各节点间也可按需配置)。
- 已配置JAVA_HOME、HADOOP_HOME等环境变量,且三台节点一致。
- HDFS 集群已配置完成(core-site.xml、hdfs-site.xml)并能正常运行。
- 确保三台节点的时间同步(避免因时间差导致服务通信异常)
具体的hadoop集群部署过程和验证方式见同专栏下另一篇文章
确定 YARN 角色分配
推荐的角色分配方案:
|--------|-----------------------------|----------------------------|
| 节点 | YARN 角色 | 其他角色(HDFS) |
| master | ResourceManager、NodeManager | NameNode、SecondaryNameNode |
| node1 | NodeManager | DataNode |
| node2 | NodeManager | DataNode |
二、核心配置文件修改
所有配置文件均在 $HADOOP_HOME/etc/hadoop/目录下
先在master节点修改,再同步到node1、node2
1、配置yarn-site.xml(YARN 核心配置)
该文件定义 YARN 的服务地址、资源管理规则、辅助服务等核心参数,
cd $HADOOP_HOME/etc/hadoop/
vi yarn-site.xml
#将以下配置写入yarn-site.xml
<configuration>
<!-- 1. 指定ResourceManager的地址(master节点) -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<!-- ResourceManager的调度器地址(与address一致即可) -->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<!-- ResourceManager的资源跟踪地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<!-- 2. ResourceManager的Web UI地址(默认端口8088,可自定义) -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<!-- 3. NodeManager的辅助服务(必须配置为mapreduce_shuffle,否则MapReduce作业无法运行) -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 4. 配置NodeManager可用的资源(可选,根据节点硬件调整) -->
<!-- 每个NodeManager可用的内存大小(单位:MB,例如4G内存设为4096) -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<!-- 每个NodeManager可用的CPU核心数(例如4核设为4) -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<!-- 5. 开启日志聚合(作业日志统一存储到HDFS,方便查看) -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志聚合在HDFS的保留时间(单位:秒,例如1天=86400秒) -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 6. 指定NodeManager的本地目录和日志目录(避免权限问题) -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/yarn/log</value>
</property>
</configuration>注意这里的xml文件要在原来的configuration格式中添加,而不是增加一个configuration
这一点在hadoop部署的时候有提到过【第一站】本地虚拟机部署Hadoop分布式集群-CSDN博客
所有节点建目录
为避免 NodeManager 启动时因目录不存在或权限不足失败,在所有节点创建配置中指定的本地目录和日志目录,并赋予 Hadoop 运行用户权限(例如hadoop用户)
bash
# 所有节点执行
mkdir -p /data/data/yarn/local
mkdir -p /data/logs/yarn/log
chown -R hadoop:hadoop /data 2、配置mapred-site.xml(MapReduce 对接 YARN)
该文件用于指定 MapReduce 运行在 YARN 上,并配置作业历史服务器(可选)
bash
cd $HADOOP_HOME/etc/hadoop/
vi mapred-site.xml
#将以下配置写入mapred-site.xml
<configuration>
<!-- 核心:指定MapReduce框架运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置MapReduce作业历史服务器地址(master节点) -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 作业历史服务器的Web UI地址(默认端口19888) -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<!-- 作业历史日志的保留时间(单位:秒) -->
<property>
<name>mapreduce.jobhistory.retain.hours</name>
<value>3600</value>
</property>
</configuration>3、配置workers文件(Hadoop 3.x替代原 slaves)
该文件列出所有运行DataNode和NodeManager的节点,在master节点编辑
这一项在部署hadoop的时候已经改好了
bash
vi $HADOOP_HOME/etc/hadoop/workers
master
node1
node24、同步配置文件到所有节点
在master节点执行scp命令,将修改后的配置文件同步到node1、node2,确保集群配置一致
bash
# 同步yarn-site.xml
scp $HADOOP_HOME/etc/hadoop/yarn-site.xml node1:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/yarn-site.xml node2:$HADOOP_HOME/etc/hadoop/
# 同步mapred-site.xml
scp $HADOOP_HOME/etc/hadoop/mapred-site.xml node1:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/mapred-site.xml node2:$HADOOP_HOME/etc/hadoop/三、开放相关端口
1、master开放端口
bash
# 开放HDFS端口
firewall-cmd --add-port=9870/tcp --permanent
firewall-cmd --add-port=9000/tcp --permanent
firewall-cmd --add-port=50090/tcp --permanent
# 开放YARN端口
firewall-cmd --add-port=8088/tcp --permanent
firewall-cmd --add-port=8032/tcp --permanent
firewall-cmd --add-port=8030/tcp --permanent
firewall-cmd --add-port=8031/tcp --permanentfirewall 是linux防火墙、端口操作工具
2、node1、node2开放端口
bash
firewall-cmd --add-port=9864/tcp --permanent
firewall-cmd --add-port=9866/tcp --permanent
firewall-cmd --add-port=9867/tcp --permanent
# 开放NodeManager端口
firewall-cmd --add-port=8042/tcp --permanent
firewall-cmd --add-port=8040/tcp --permanent
firewall-cmd --add-port=8041/tcp --permanent
# 重载防火墙配置
firewall-cmd --reload四、验证配置并启动 YARN
先启动 HDFS,再启动 YARN
启动 HDFS
在master节点执行 start-dfs.sh
启动yarn
在master节点执行(一键启动ResourceManager和所有NodeManager)
启动作业历史服务器(可选)
mr-jobhistory-daemon.sh start historyserver
验证 YARN 启动状态
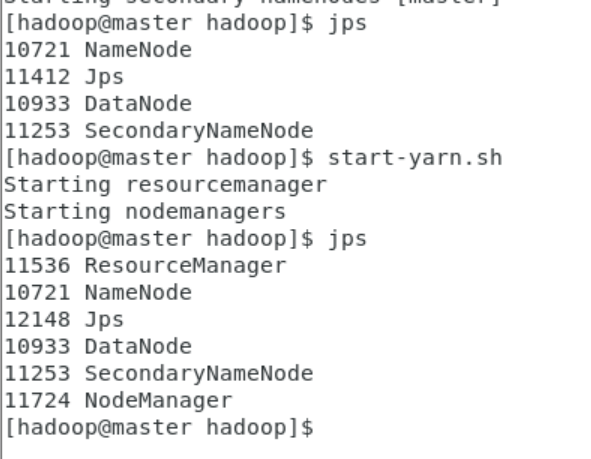
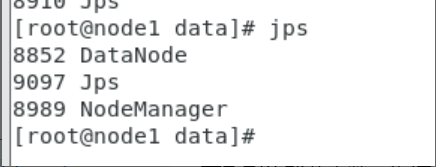
查看进程:在各节点执行 jps:
master:ResourceManager、NodeManager、JobHistoryServer(可选)
node1/node2:NodeManager
master:
node1\node2
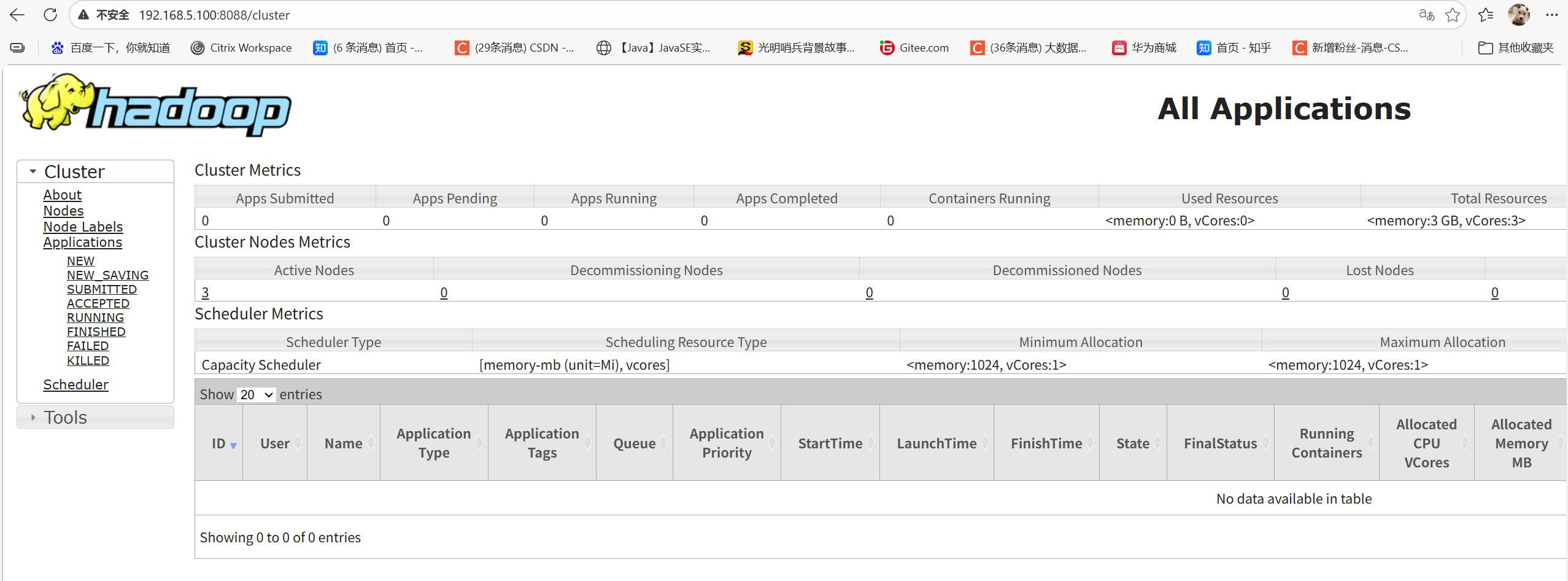
访问 Web UI
浏览器输入http://master:8088,可看到集群节点数、资源使用情况
本地如果没有配置host映射的话就把master换成你的主节点ip
命令行验证
yarn node -list # 列出所有活跃的NodeManager节点
yarn top # 实时查看YARN资源使用