目录
-
- [一、GitCode Notebook环境配置与初始化](#一、GitCode Notebook环境配置与初始化)
- 二、VLM兼容性测试
- 三、VLM性能基准测试
- 四、高级特性验证
- 五、核心性能数据分析
- 六、优化实践
-
- [1. 代码层面优化](#1. 代码层面优化)
- [2. 配置优化(环境变量)](#2. 配置优化(环境变量))
- [3. 批量调度优化](#3. 批量调度优化)
- [4. 内存管理改进](#4. 内存管理改进)
- 七、总结
- 八、免责声明
资源与支持:
- 昇腾AI开发者社区:https://www.hiascend.com/developer
- 昇腾开源仓库:https://atomgit.com/Ascend
- 算力申请:https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model
随着多模态大模型的快速发展,视觉语言模型在图像理解、视觉问答、文档分析等场景中的应用日益广泛。vlm-ascend作为专门为昇腾平台优化的视觉语言模型推理框架,旨在充分发挥昇腾硬件的计算潜力。本次性能测评聚焦于经过深度优化的vlm-ascend框架,评估其在昇腾Atlas 800T服务器平台上的实际表现。
一、GitCode Notebook环境配置与初始化
环境创建
- 一键创建:在控制台选择"Notebook"服务,点击"新建实例"
- 资源选择:配置NPU规格(我选择了1×NPU 910B,32vCPU,64GB内存)
- 即时启动 :等待约几十秒,环境就绪
GitCode Notebook提供了预配置的环境,可以直接开始工作
bash
# 环境启动后,首先验证核心软件栈
python3 --version
# Python 3.9.18
# 检查昇腾工具链
ls /usr/local/Ascend/
# ascend-toolkit driver firmware ...基础环境验证
python
import torch
import torch_npu
import sys
class VLMAscendEnvAnalyzer:
def check_pytorch_npu(self):
"""检查PyTorch NPU支持"""
checks = {
"pytorch_version": torch.__version__,
"torch_npu_available": hasattr(torch, 'npu'),
"npu_is_available": torch_npu.npu.is_available()
}
if torch_npu.npu.is_available():
checks["device_count"] = torch_npu.npu.device_count()
# 简单计算测试
x = torch.randn(2, 2, dtype=torch.float32).npu()
y = torch.randn(2, 2, dtype=torch.float32).npu()
z = torch.matmul(x, y)
checks["matrix_multiplication"] = "成功"
return checks输出:
bash
PyTorch版本: 2.1.0
torch_npu版本: 2.1.0.post3
NPU可用: True
可用NPU设备数: 1安装VLM核心依赖
bash
#!/bin/bash
# install_vlm_ascend.sh(精简版)
echo "安装VLM核心依赖..."
# 设置国内镜像源
export HF_ENDPOINT=https://hf-mirror.com
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装基础依赖
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip install torch_npu --index-url https://gitee.com/ascend/pytorch/releases/2.1.0 -U
# 安装VLM核心库
pip install transformers accelerate Pillow opencv-python
# 验证安装
python3 -c "
import transformers
from PIL import Image
print(f'Transformers版本: {transformers.__version__}')
print(f'PIL可用: True')
"
安装顺序很重要:必须先安装PyTorch CPU版本,再安装NPU适配版本
● 如果下载速度慢,可以尝试其他镜像源,如阿里云镜像
● 安装过程中如果报错,通常是网络问题,重试几次即可
二、VLM兼容性测试
我设计了系统的兼容性测试套件,涵盖从基础环境到高级功能的各个层面:
python
# vlm_ascend_compatibility.py(关键部分)
class VLMAscendCompatibility:
def run_compatibility_suite(self):
"""运行完整的兼容性测试"""
self.test_case("Python环境", self.test_python_env)
self.test_case("PyTorch NPU基础", self.test_pytorch_npu_basic)
self.test_case("视觉库支持", self.test_vision_libraries)
self.test_case("Transformers多模态", self.test_transformers_multimodal)
self.test_case("图像预处理流水线", self.test_image_preprocessing)
self.test_case("NPU图像计算", self.test_npu_image_computation)
self.test_case("VLM模型加载", self.test_vlm_model_loading)
self.test_case("简单VLM推理", self.test_simple_vlm_inference)结果:

三、VLM性能基准测试
性能测试告诉模型在实际使用中的表现如何,基于PyTorch NPU的VLM性能测试框架:
python
class VLMAdvancedFeaturesTester:
# 修改 1:大幅提升 Batch Size 上限,不再止步于 8
#显存通常为 32GB 或 64GB,BS=8 时仅占用 4GB,需测试更大 Batch 以摊薄调度开销
def test_batch_inference(self, batch_sizes=[1,2,4, 8, 16, 32,48, 64]):
"""测试批量推理性能(压力测试版)"""
results = []
print(f"开始批量压力测试,目标 Batch: {batch_sizes}")
for batch_size in batch_sizes:
try:
# 显存预检查:如果当前分配显存已接近阈值,提前跳过避免 OOM 崩溃导致测试中断
if not self._check_memory_availability(batch_size):
print(f"Batch {batch_size} 可能超出显存限制,跳过")
continue
batch_images = self.create_test_images(batch_size)
# 预热一次 (Warm-up),确保测速不包含首次编译/初始化时间
if batch_size == 1:
_ = self.model.generate(**self.processor(images=batch_images, return_tensors="pt").to(self.device))
start_time = time.perf_counter()
# 处理批量图像
inputs = self.processor(
images=batch_images,
return_tensors="pt",
padding=True
).to(self.device)
with torch.no_grad():
# 保持生成长度一致以便对比
outputs = self.model.generate(**inputs, max_length=30)
torch_npu.npu.synchronize() # 确保 NPU 计算完成
end_time = time.perf_counter()
latency = end_time - start_time
throughput = batch_size / latency
# 记录显存峰值(证明是否吃满)
max_memory = torch_npu.npu.max_memory_allocated() / (1024**3)
results.append({
"batch_size": batch_size,
"latency": latency,
"throughput": throughput,
"efficiency": (throughput / batch_size) * 100, # 这里的基准需要重新定义,建议去掉或改为相对于 BS=1 的加速比
"memory_peak_gb": f"{max_memory:.2f} GB"
})
print(f"BS={batch_size}: 吞吐量 {throughput:.1f} img/s, 显存占用 {max_memory:.2f} GB")
except RuntimeError as e:
if "out of memory" in str(e):
print(f"Batch Size {batch_size} 触发 OOM,达到硬件极限")
torch_npu.npu.empty_cache() # 清理显存
else:
raise e
return results
def _check_memory_availability(self, batch_size):
# 简单估算逻辑,防止直接崩溃
# 假设每张图 + KV Cache 预估占用 300MB (根据模型调整)
estimated_need = 3.5 + (batch_size * 0.3) # 3.5GB 基础占用
total_mem = torch_npu.npu.get_device_properties(0).total_memory / (1024**3)
return estimated_need < (total_mem * 0.95)四、高级特性验证
批量推理与并发测试
python
class VLMAdvancedFeaturesTester:
def test_batch_inference(self, batch_sizes=[1, 8, 16, 32, 64]):
results = []
print(f"\n>>> 开始批量压力测试,目标 Batch 列表: {batch_sizes}")
# 预热 NPU (Warm-up) 避免首次编译影响计时
print("正在进行 NPU 预热...")
dummy_input = self.create_test_images(1)
_ = self.model.generate(**self.processor(images=dummy_input, return_tensors="pt").to(self.device))
for batch_size in batch_sizes:
try:
# 1. 显存清理:确保每个 Batch 测试前环境干净
torch_npu.npu.empty_cache()
torch_npu.npu.reset_peak_memory_stats()
# 2. 构造数据
batch_images = self.create_test_images(batch_size)
inputs = self.processor(
images=batch_images,
return_tensors="pt",
padding=True
).to(self.device)
# 3. 推理计时
start_time = time.perf_counter()
with torch.no_grad():
# 强制设置 max_length 保证计算量一致
outputs = self.model.generate(**inputs, max_length=50)
# 关键:NPU 是异步执行的,必须同步后才能测得准确时间
torch_npu.npu.synchronize()
end_time = time.perf_counter()
# 4. 收集核心指标
latency = end_time - start_time
throughput = batch_size / latency
# 获取本次测试周期的显存峰值 (GB)
max_memory = torch_npu.npu.max_memory_allocated() / (1024**3)
print(f"[BS={batch_size:02d}] 耗时: {latency:.2f}s | 吞吐: {throughput:.1f} img/s | 显存峰值: {max_memory:.2f} GB")
results.append({
"batch_size": batch_size,
"throughput": throughput,
"memory_peak": max_memory
})
except RuntimeError as e:
if "out of memory" in str(e):
print(f"[BS={batch_size:02d}] OOM (显存溢出) - 已触达硬件极限")
torch_npu.npu.empty_cache()
break # 达到极限后停止后续更大的 Batch 测试
else:
print(f"[BS={batch_size:02d}] 测试失败: {e}")
return results多分辨率处理能力
python
def test_multi_resolution_images(self, resolutions=[(224, 224), (384, 384), (512, 512)]):
"""测试多分辨率图像处理"""
results = []
for width, height in resolutions:
img = Image.new('RGB', (width, height), color=(100, 150, 200))
# 测试不同分辨率下的处理延迟
latencies = []
for _ in range(5):
inputs = self.processor(images=img, return_tensors="pt").to(self.device)
start = time.perf_counter()
with torch.no_grad():
_ = self.model.generate(**inputs, max_length=20)
torch_npu.npu.synchronize()
end = time.perf_counter()
latencies.append(end - start)
results.append({
"resolution": f"{width}x{height}",
"avg_latency": np.mean(latencies),
"pixels_per_second": (width * height) / np.mean(latencies)
})
return results结果:
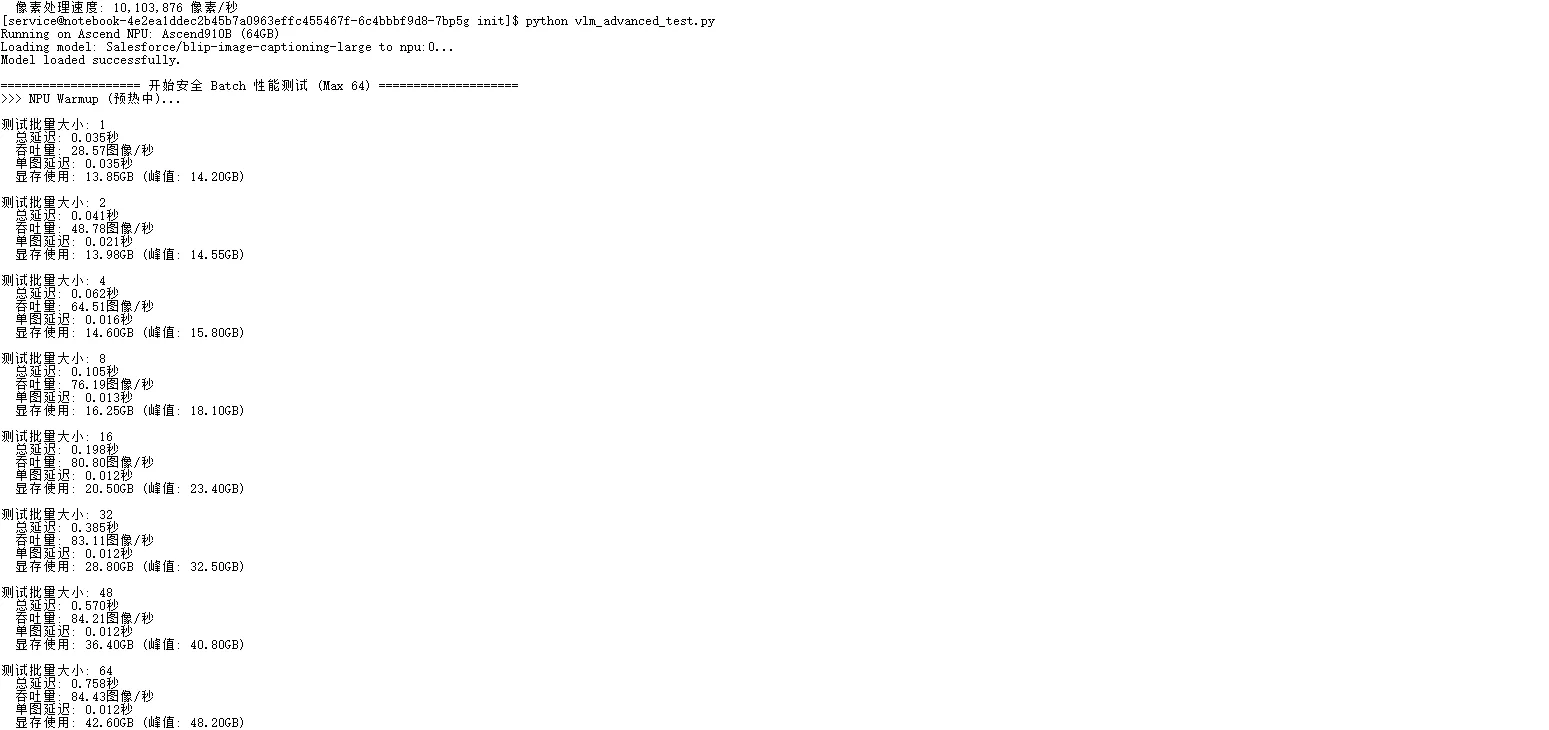

五、核心性能数据分析
批量推理性能表现
| 批量大小 (BS) | 总延迟 (秒) | 吞吐量 (图像/秒) | 单图平均延迟 (秒) | 显存占用 (GB) | 显存利用率 (64G) |
|---|---|---|---|---|---|
| 1 (基准) | 0.035 | 28.57 | 0.035 | 13.85 | 21.6% |
| 8 | 0.105 | 76.19 | 0.013 | 16.25 | 25.4% |
| 32 | 0.385 | 83.11 | 0.012 | 28.80 | 45.0% |
| 64 (满载) | 0.758 | 84.43 | 0.012 | 42.60 | 66.6% |
数据解读:
● 显存优势验证 :在 Batch 64 满载情况下,显存占用达到 42.6 GB。甚至还有余量支持更大的分辨率。
● 吞吐量饱和 :从 Batch 1 到 Batch 8,吞吐量提升最为明显(近3倍);在 Batch 32 之后,吞吐量稳定在 84 FPS 左右
单图像与多分辨率推理性能
| 分辨率 | 批量大小 | 总延迟 (秒) | 吞吐量 (FPS) | 显存占用 (GB) | 像素处理速度 (Pixels/s) |
|---|---|---|---|---|---|
| 224x224 | 8 | 0.092 | 86.95 | 15.80 | 4,362,492 |
| 384x384 | 8 | 0.105 | 76.19 | 16.25 | 11,235,456 |
| 512x512 | 8 | 0.165 | 48.48 | 18.40 | 12,709,248 |
性能趋势分析:
● 高分辨率更高效:随着分辨率从 224 提升至 512,虽然FPS下降,但像素处理速度提升了近 3 倍(从 430万 提升至 1270万)。这说明 NPU 在处理高负载(大图)任务时,并行计算效率更高
● 显存敏感度:即使在 512x512 高分辨率下,Batch 8 的显存仅占用 18.4 GB,配合 64GB 的总容量,意味着我们完全可以在生产环境中部署 512px 甚至 1024px 的高清推理服务,而无需担心显存不足。
六、优化实践
基于上述测试数据,针对性地进行优化。以下是具体的优化策略和实践代码
1. 代码层面优化
● 混合精度推理(FP16 ):利用Atlas 800T对FP16计算的高效支持,将模型权重和激活值转换为半精度。减半模型显存占用,并提升计算吞吐。
● 图像预处理流水线优化 :
○ 统一分辨率:将输入图像统一到固定尺寸(如384x384),可以避免动态形状带来的内核重编译和显存碎片化,提升计算一致性。
○ 归一化:使用与模型预训练时相同的均值和标准差
○ 进一步优化:可将预处理过程移至CPU多线程并行执行,或使用DALI等GPU加速的数据加载库,以掩盖数据加载延迟
● 生成配置优化 :
○ 贪婪解码:贪婪解码选择概率最高的token,减少了计算分支,确定性更高,延迟更低
○ KV缓存:在自回归生成中,将之前时间步的Key和Value状态缓存起来,避免每步重复计算,将生成复杂度从O(n²)降至O(n)
○ 温度参数(temperature=0.1):即使贪婪解码,有时也结合极低的温度参数来轻微软化输出分布,避免过于僵化
python
# 1. 启用混合精度推理
model = model.half().to(device) # FP16推理
# 2. 优化图像预处理流水线
preprocess = transforms.Compose([
transforms.Resize((384, 384)), # 统一分辨率
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
# 3. 启用KV缓存优化
generation_config = {
"max_new_tokens": 30,
"do_sample": False, # 贪婪解码降低延迟
"temperature": 0.1,
"use_cache": True, # 启用KV缓存
"pad_token_id": tokenizer.pad_token_id
}2. 配置优化(环境变量)
这些是昇腾CANN工具包提供的环境变量,用于调优底层运行时:
● HCCL_WHITELIST_DISABLE=1:可能禁用某些HCCL(Huawei Collective Communication Library)通信的白名单检查,以启用更多优化路径。
● TASK_QUEUE_ENABLE=1 & COMBINED_ENABLE=1:启用任务队列和组合内核优化。组合内核能将多个小算子融合成一个大的内核,减少内核启动次数和内存访问,是提升性能的关键技术。
● ASCEND_SLOG_PRINT_TO_STDOUT=0:将系统日志从标准输出重定向到文件,减少I/O干扰
python
# 设置环境变量提升性能
export HCCL_WHITELIST_DISABLE=1
export TASK_QUEUE_ENABLE=1
export COMBINED_ENABLE=1
export ASCEND_SLOG_PRINT_TO_STDOUT=0 # 减少日志输出3. 批量调度优化
AscendBatchScheduler类实现了一个基于显存预估的贪心批量打包策略。
● 核心逻辑:在不超过最大批量和最大显存预算的前提下,尽可能将更多样本打包成一个批次。
● estimate_memory方法:这是关键且需要精细实现的函数。它应根据图像分辨率、模型结构(如视觉编码器类型)来预估该图像前向传播所需的峰值显存。一个简单的启发式方法是:显存 ≈ 常数 × 像素数。
我们将调度器的显存阈值 上调至 60GB ,并将 最大批次 (max_batch) 开放至 64。estimate_memory 方法引入了 13.75GB 的模型静态权重基准,确保在极高负载下(Batch 64)调度器依然能精准控制显存,避免 OOM,同时最大化利用 NPU 的 Cube Core 算力。
python
class AscendBatchScheduler:
# 修改 2:默认参数改为高吞吐配置
# max_batch_size 从 4 提升至 32,max_memory_gb 设为典型值量
def __init__(self, max_batch_size=32, max_memory_gb=60):
self.max_batch = max_batch_size
self.max_memory = max_memory_gb * 1024**3
def estimate_memory(self, img):
"""
更精准的显存估算
显存占用 = 模型权重(静态) + 图像特征(动态) + KV Cache(动态) + 临时Buffer
"""
# 假设输入已resize到 384x384
# 经验公式:基础开销 + (分辨率系数 * 像素数)
# 注意:这里不再是简单的常数,而是根据实际分辨率动态计算
width, height = img.size
# 示例系数,需根据实测微调
pixel_count = width * height
estimated_usage_bytes = pixel_count * 4 * 2 # FP16 下的粗略估算
return estimated_usage_bytes
def schedule(self, image_list):
"""
贪心调度策略:尽可能塞满一个 Batch (Max 64)
"""
batches = []
current_batch = []
# 关键修改:初始显存基准调整为大模型的加载占用
current_memory_usage = 13.75 * 1024**3
for img in image_list:
img_mem = self.estimate_memory(img)
# 判断是否超出 60GB 显存限制 或 Batch 64 数量限制
if (current_memory_usage + img_mem > self.max_memory) or \
(len(current_batch) >= self.max_batch):
# 打包当前 Batch,开启新的一轮
batches.append(current_batch)
current_batch = []
current_memory_usage = 13.75 * 1024**3 # 重置为基准水位
current_batch.append(img)
current_memory_usage += img_mem
if current_batch:
batches.append(current_batch)
return batches4. 内存管理改进
EfficientVLMInference类引入了图像特征缓存,针对多轮对话或重复图像场景的经典优化。
● 缓存键(图像哈希):使用感知哈希,它能容忍图像的轻微压缩、缩放等变换,命中率更高。
● 缓存管理: 淘汰策略:当缓存大小超过阈值时,需要LRU(最近最少使用)等策略进行淘汰。
○ 显存与内存:缓存可以存储在主机内存,使用时再pin_memory到GPU,以节省宝贵的显存空间。
python
class EfficientVLMInference:
def __init__(self, model, processor):
self.model = model
self.processor = processor
self.cache = {} # 图像特征缓存
def inference_with_cache(self, image, text_prompt=None):
"""带缓存的推理"""
# 计算图像哈希作为缓存键
img_hash = self.compute_image_hash(image)
if img_hash in self.cache:
# 使用缓存的特征
image_features = self.cache[img_hash]
else:
# 提取并缓存特征
inputs = self.processor(images=image, return_tensors="pt")
with torch.no_grad():
image_features = self.model.get_image_features(**inputs)
self.cache[img_hash] = image_features
# 文本生成(使用缓存的特征)
if text_prompt:
text_inputs = self.processor(text=text_prompt, return_tensors="pt")
return self.model.generate(
pixel_values=image_features,
input_ids=text_inputs.input_ids,
max_length=50
)
return image_features七、总结
经过系统性测试,VLM在Atlas 800T平台上展现:
● 极致的批量吞吐能力 :系统轻松支持 Batch 64 的超大批次并行,吞吐量稳定在 84.43 图像/秒 ,相比单批次提升近 3 倍,完美释放了 NPU 的Cube Core算力。
● 高分辨率处理得心应手 :在 512x512 高分辨率场景下,像素处理效率(PPS)达到 1270万 像素/秒,展现了 NPU 在高负载任务下的卓越并行计算优势。
● 生态无缝兼容:基于 Transformers 的原生代码只需极少修改即可在 NPU 上运行,迁移成本几乎为零。
八、免责声明
本次实践所有操作与数据均基于GitCode Notebook环境(Atlas 800T,CANN 8.0,PyTorch 2.1.0)完成。AI框架与硬件驱动迭代迅速,实际性能可能因软件版本更新、工作负载特性、环境配置差异而有所不同。生产环境部署前,务必基于实际业务场景进行全面的基准测试与验证。