作者:阿里通义实验室(Fun Team)
代码:https://github.com/FunAudioLLM/Fun-Audio-Chat
论文:https://github.com/FunAudioLLM/Fun-Audio-Chat/blob/main/Fun-Audio-Chat-Technical-Report.pdf
一句话总结:
- 一个像真人一样能听懂语气 、能插嘴 、反应快 ,而且训练还省钱的语音端到端大模型
痛点
-
Resolution Mismatch (节奏、 采样率 不匹配):
-
语音的采样率很高,但细节丰富
- 1秒~= 25 Token, 25Hz, 每40ms一个Token
-
文本的"采样率"很低,但语义密集
- 一秒钟 ~= 3~5 个字,即 3Hz~5Hz
-
LLM擅长处理文本的节奏,端到端模型适应语音的节奏会带来损失
-
-
Computational Costs (算力成本、效率)
- 带来额外的计算负担。本来只需要算3~5次,但音频需要算25次,同时影响训练和推理效率,导致落地问题
-
Catastrophic Forgetting (灾难性遗忘)
-
将文本LLM基座,转换为多模态大模型的过程(pretrain/posttrain),会影响文本LLM的基础能力
-
如果学习率高会加剧灾难性遗忘;如果学习率太低,训练又会收敛得很慢 。
-
核心创新
-
DRSR - Dual-Resolution Speech Representations (双 分辨率 架构)
-
总结:先降低++LLM++ ++部分++ 的音频采样率,再使用而外的++Decode Head++还原为高质量音频
-
LLM 部分
-
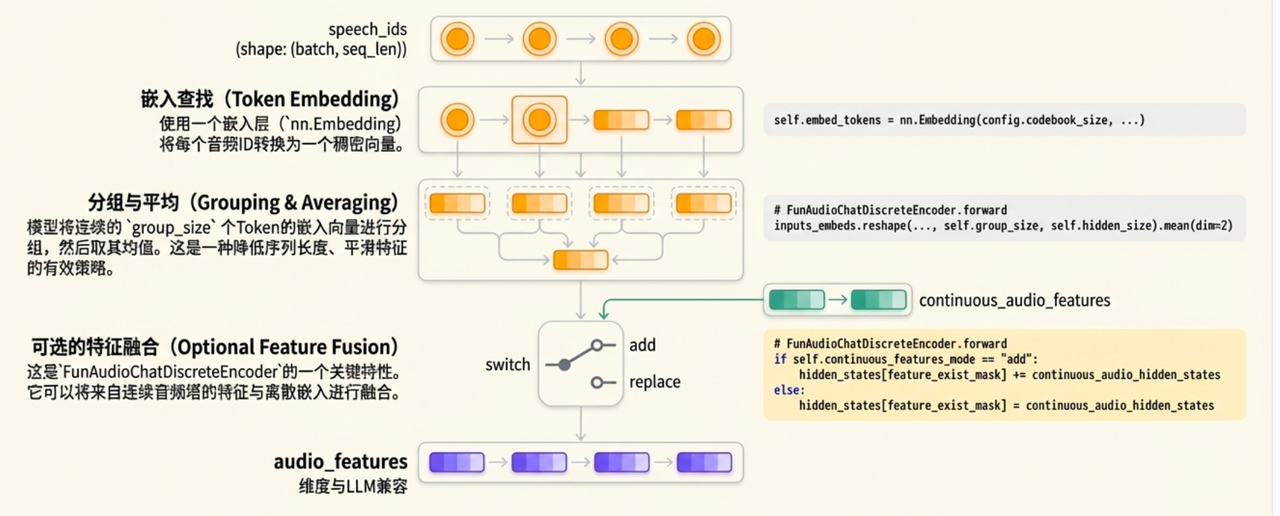
现状: 文本是 3~5Hz,语音 25Hz。
-
操作: 它把语音的每 5 个小碎片,打包成 1 个大碎片。
- 每5个speech token的 embedding 分组平均
-
结果:LLM看到的语音变成 5Hz,与文本接近
-
-
Decode Head
-
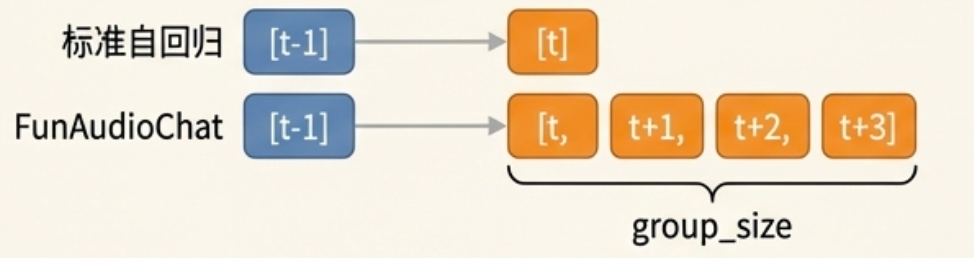
SRH - Speech Refined Head
LLM只管大概意思(5Hz),SRH负责精细发音(25Hz)
-
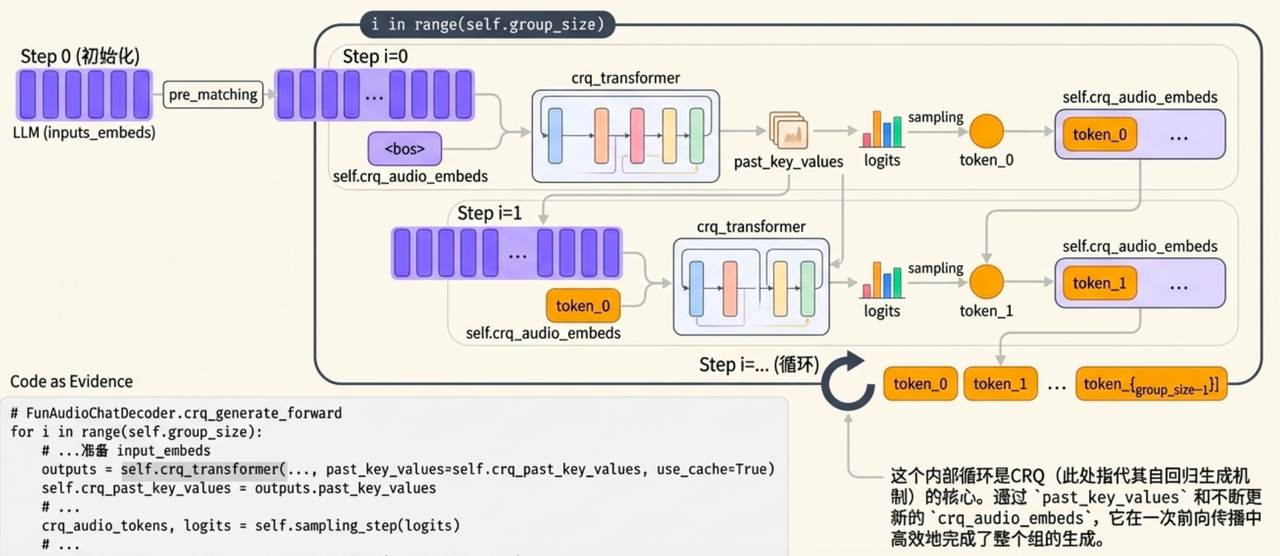
目标:将5Hz的压缩信号重新还原为25Hz的高质量语音
-
具体细节:
- CRQ Transformer模块,自回归迭代n次。 (n=Group size)
- CRQ Transformer模块,自回归迭代n次。 (n=Group size)
-
-
-
总结: 同时解决了
-
痛点1: Resolution Mismatch (节奏、 采样率 不匹配)
-
痛点2: Computational Costs (算力成本、效率)
-
既让LLM处理快,又让声音好听。
-
-
-
Core-Cocktail Training
-
痛点 3:
- 如果学习率高会加剧灾难性遗忘;如果学习率太低,训练又会收敛得很慢 。
-
解决:两阶段的训练策略:
-
阶段一: 用高学习率Fune-tuning,让模型快速学会听说。
-
模型融合 : 把阶段一的模型参数,和最原始的纯文本大模型参数按比例(1:1)混合。
-
阶段二:用低学习率再Fune-tuning混合后的模型,稳固效果。
-
-
进阶能力
-
Multi-Task DPO
-
Robustness:噪声、多样化语音输入(如不同口音、背景音)
-
Instruction-Following:情感、风格、韵律控制
-
Audio Understanding:语义识别、摘要、逻辑推理
-
Voice Empathy:情感识别、共情响应
-
-
Full-Duplex 全双工
-
双流并行 (parallel inference architecture):
"simultaneously handle user speech input and assistant speech output"
- 同时处理用户语音输入和助手语音输出
-
实时打断检测、轮流说话判定、语义一致性
-
通过一个构造的数据集,包含了各种打断、重叠、语气词(嗯、啊)和复杂的轮流说话逻辑,微调模型实现。
-
实验结果
-
Qwen3-8B
- 同量级 VoiceBench 和 OpenAudioBench 上,比 Kimi-Audio、GLM-4-Voice 要强
-
Qwen3-30B-A3B
- 在很多指标上能和闭源的 GPT-Audio 甚至 Gemini-2.5-Pro相当。
-
理解力与控制力
- 在语音理解(MMAU)、语音 函数调用(Function Calling)和情感控制(VStyle)上,表现都非常出色。
整体架构
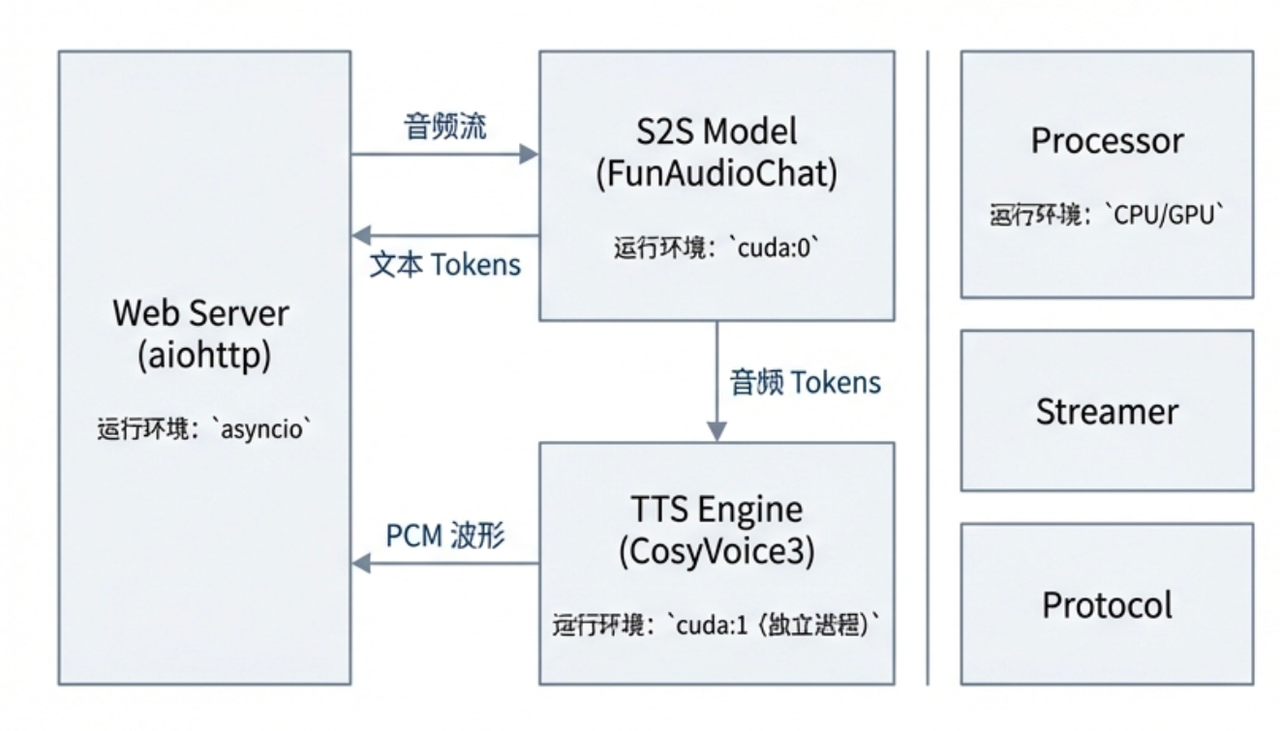
项目架构
-
语音VAD截断后,输入Fun-Audio-Chat
-
Fun-Audio-Chat流式生成文本Token和音频Tokens
-
音频Tokens流式传输到Cosyvoice3的Detokenizer (flow matching + hifigan)得到PCM wave
-
并行的流式生成
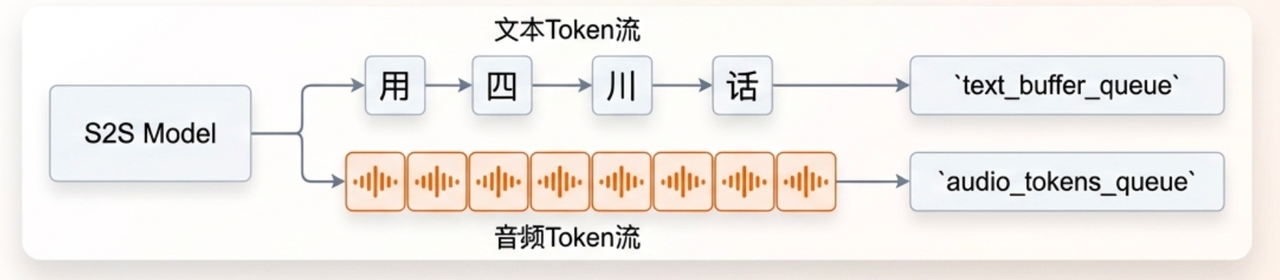
同步生成:
-
模型在一次前向传播中,同时预测下一个最可能的文本 token 和一组对应的音频token。
-
具体来说:模型每一步解码,同时产生1个文本token和5个音频token (group_size=5)
模型架构
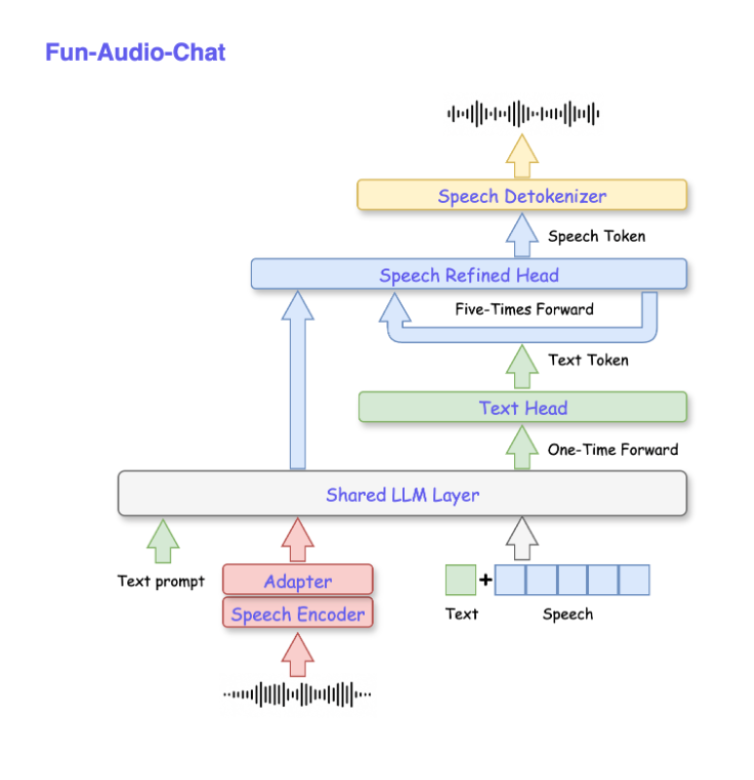
音频处理
-
多模态输入,同qwen-audio、qwen-omni系列(whisper encoder)
-
音频部分,提取fbank特征,通过whisper encoder编码为dense表示
-
文本部分,通过tokenizer、embedding loop up转换为dense表示
-
LLM
-
音频和文本拼接(通过<audio>占位符)得到LLM的输入表示
-
LLM给出
-
hidden_states用于音频token的自回归生成
-
logits用于文本token
-
Audio token Generation
- CRQ transformer 自回归从llm的last hidden states解码group size个speech token
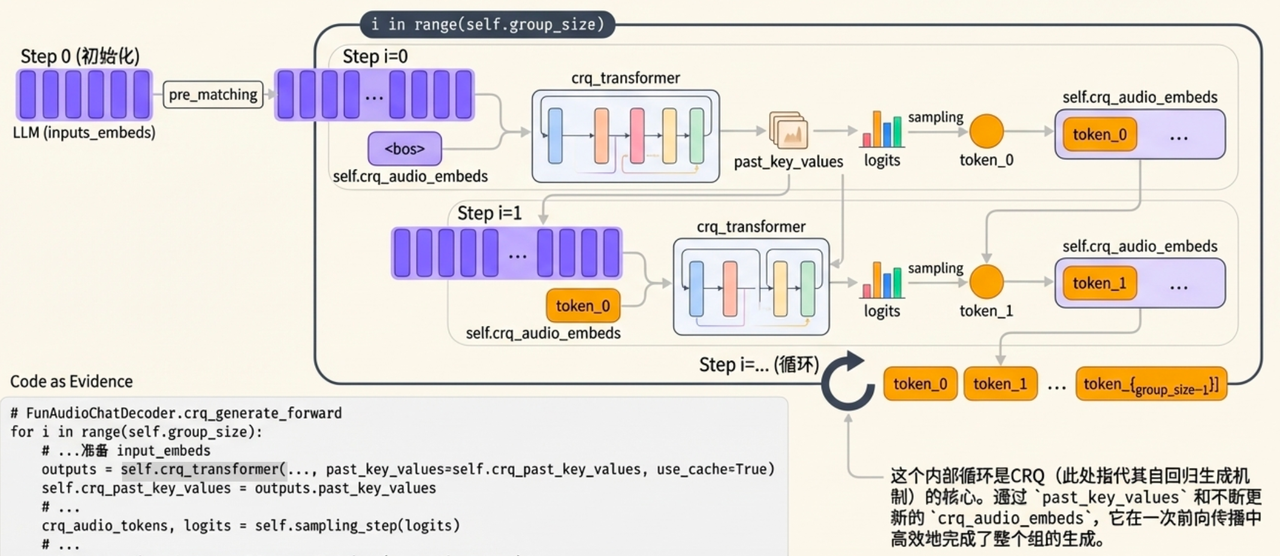
Next Step
-
Speech tokens merge
- 每group size个speech token,在编码表示上融合(mean)
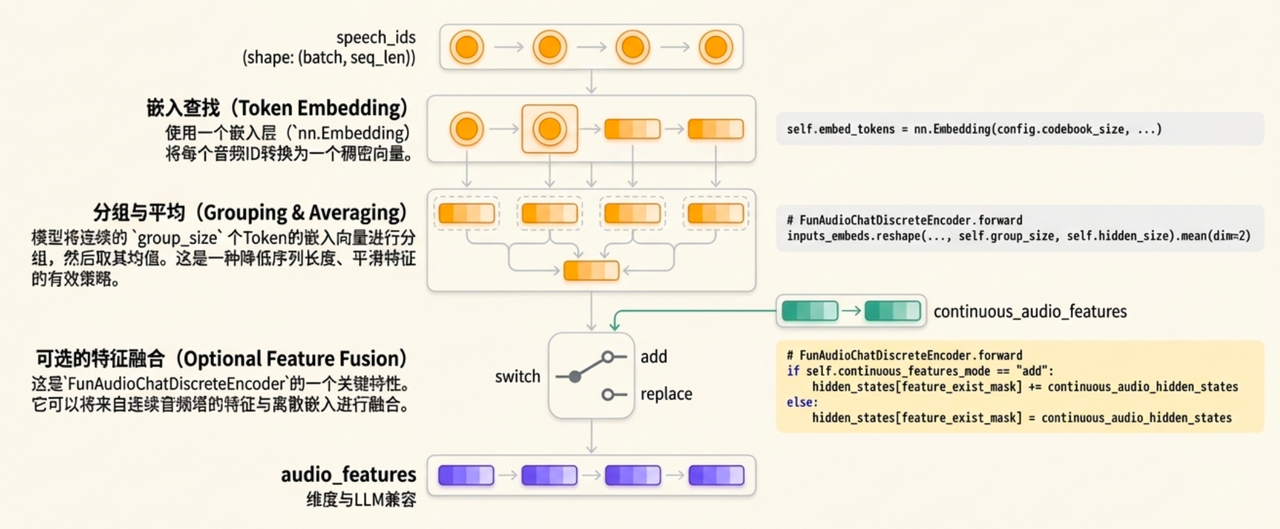
-
Multimodal merge
- 每个生成的文本token的embedding 和 融合后的音频表示 融合(mean)
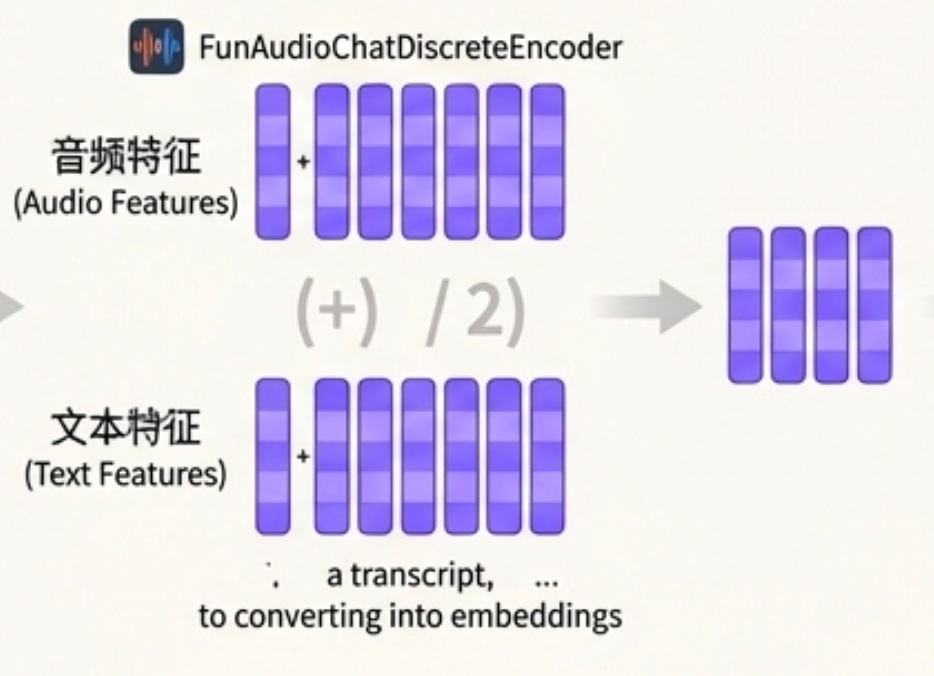
优劣
-
优势
-
开源比较彻底,全面可训练的语音端到端大模型
-
对语音函数调用、语音指令遵循、语音共情响应都做了特殊优化
-
-
劣势
-
语音函数调用只训练了S2T、T2T。也就是说,我们在S2S场景下使用Function call可能受限
-
8B size的模型可能智商需要优化
-
LLM部分没有speaker id信息,只靠cosyvoice3的token2wav实现,可能不够还原
-