项目简介
本项目基于YOLOv8深度学习算法,实现了行人和车辆的目标检测系统。系统采用PyQt5构建图形界面,支持单张图像、视频和摄像头实时检测,并提供历史记录查询和数据导出功能。
数据集信息
数据集概况
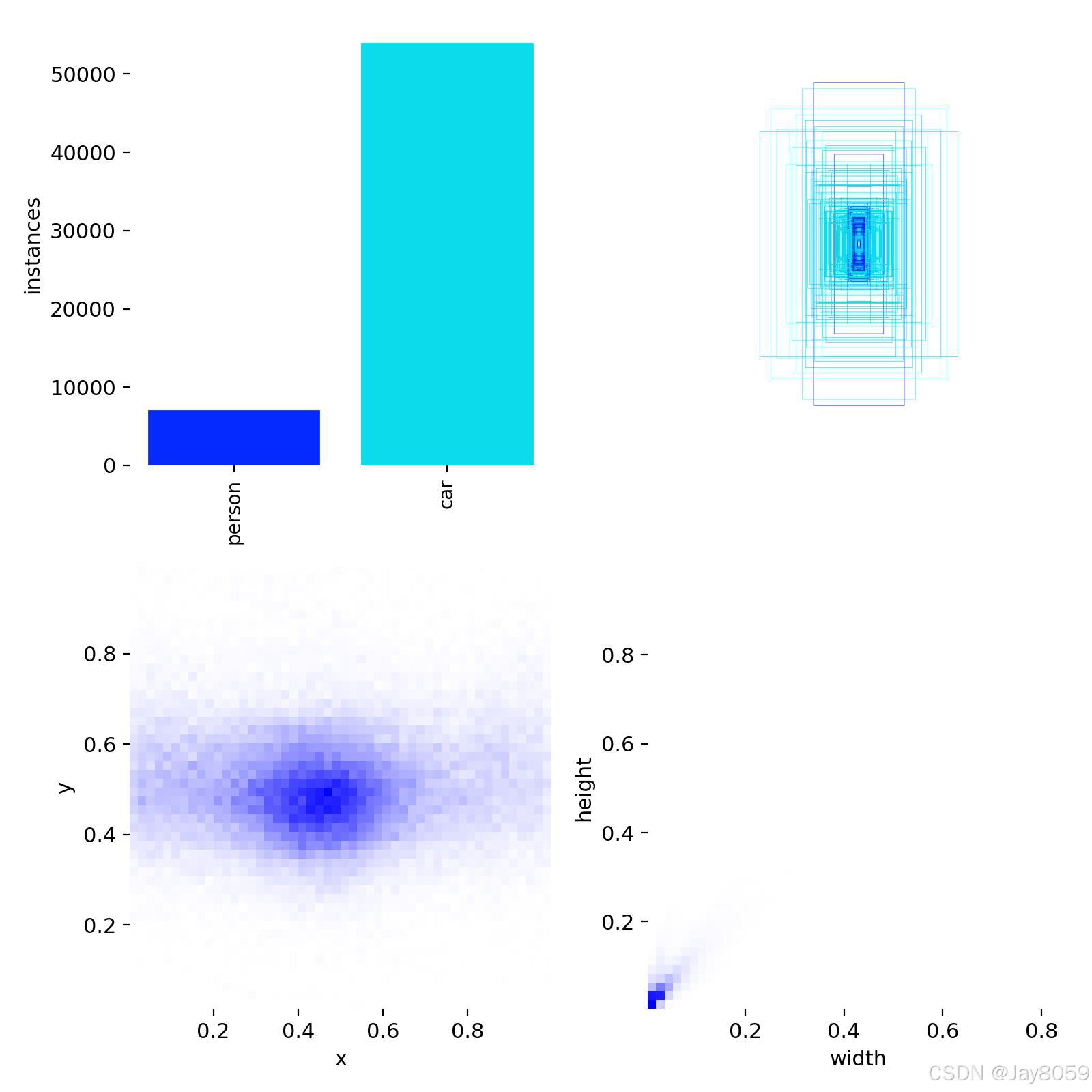
- 检测类别:2类(person-行人、car-车辆)
- 训练集图片数量:9,000张
- 验证集图片数量:1,500张
- 总图片数量:10,500张
- 总检测实例数:60,875个
- 数据格式:YOLO格式(图片+标注文件)
数据集结构
data/
├── images/
│ ├── train/ # 训练集图片(9,000张)
│ └── val/ # 验证集图片(1,500张)
└── labels/
├── train/ # 训练集标注文件(9,000个)
└── val/ # 验证集标注文件(1,500个)训练过程
训练参数
- 模型架构:YOLOv8s
- 训练轮数:50 epochs
- 批次大小:16
- 图像尺寸:640×640
- 学习率:初始学习率0.01,最终学习率0.01
- 优化器:自动选择(默认SGD)
- 动量:0.937
- 权重衰减:0.0005
- 预热轮数:3
- 数据增强:启用(包括翻转、缩放、HSV调整、Mosaic等)
- 训练设备:NVIDIA GeForce RTX 3060 Laptop GPU
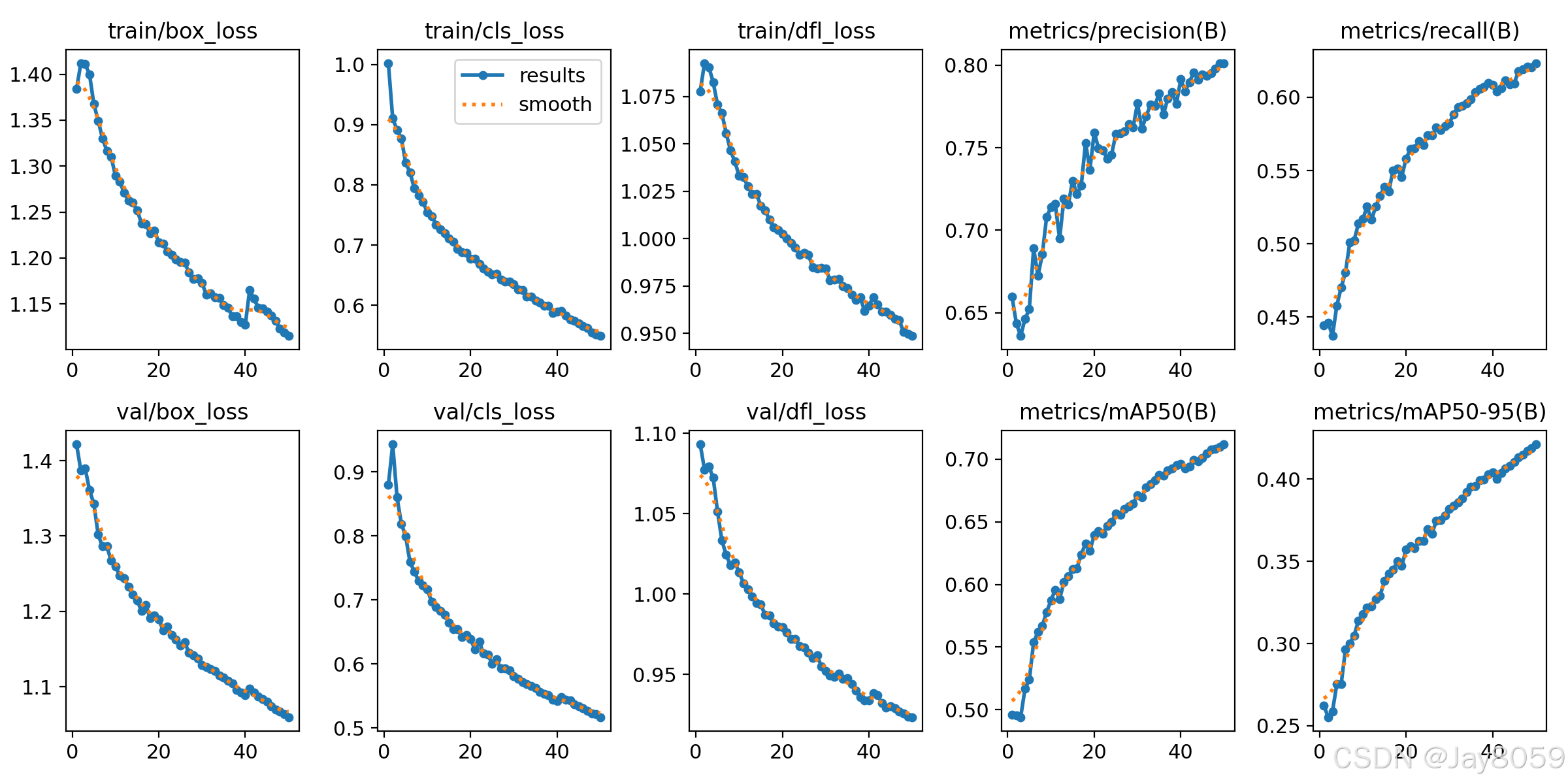
- 训练时间:2.840小时
训练结果
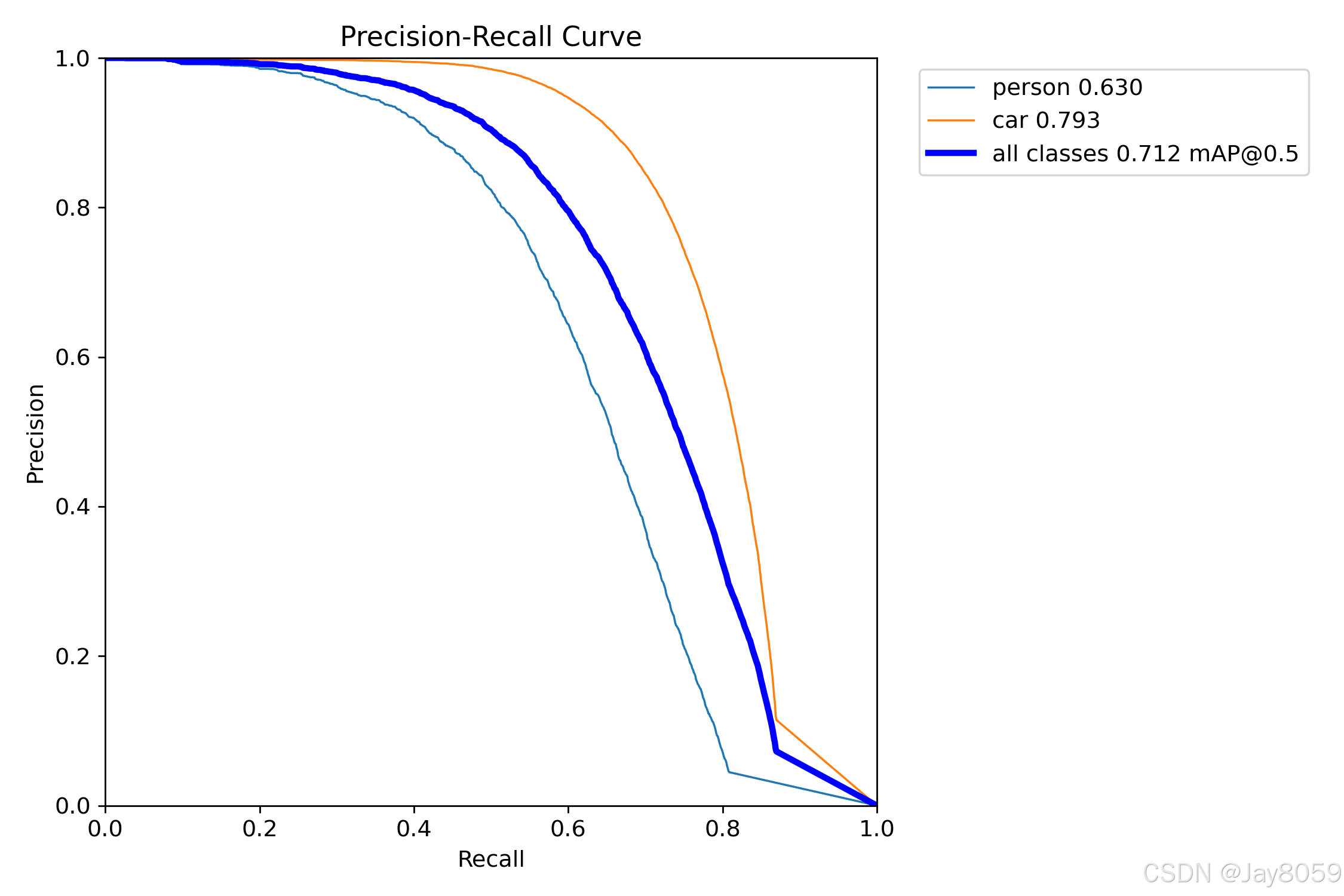
- mAP50:0.712
- mAP50-95:0.421
- 精确度(Precision):0.801
- 召回率(Recall):0.623
- F1分数:0.712
各类别性能
-
person(行人):
- 精确度:0.777
- 召回率:0.535
- mAP50:0.630
- mAP50-95:0.330
-
car(车辆):
- 精确度:0.826
- 召回率:0.712
- mAP50:0.793
- mAP50-95:0.513
可视化图含义
训练过程生成的可视化图表位于 runs/detect/person_car_detect/ 目录:
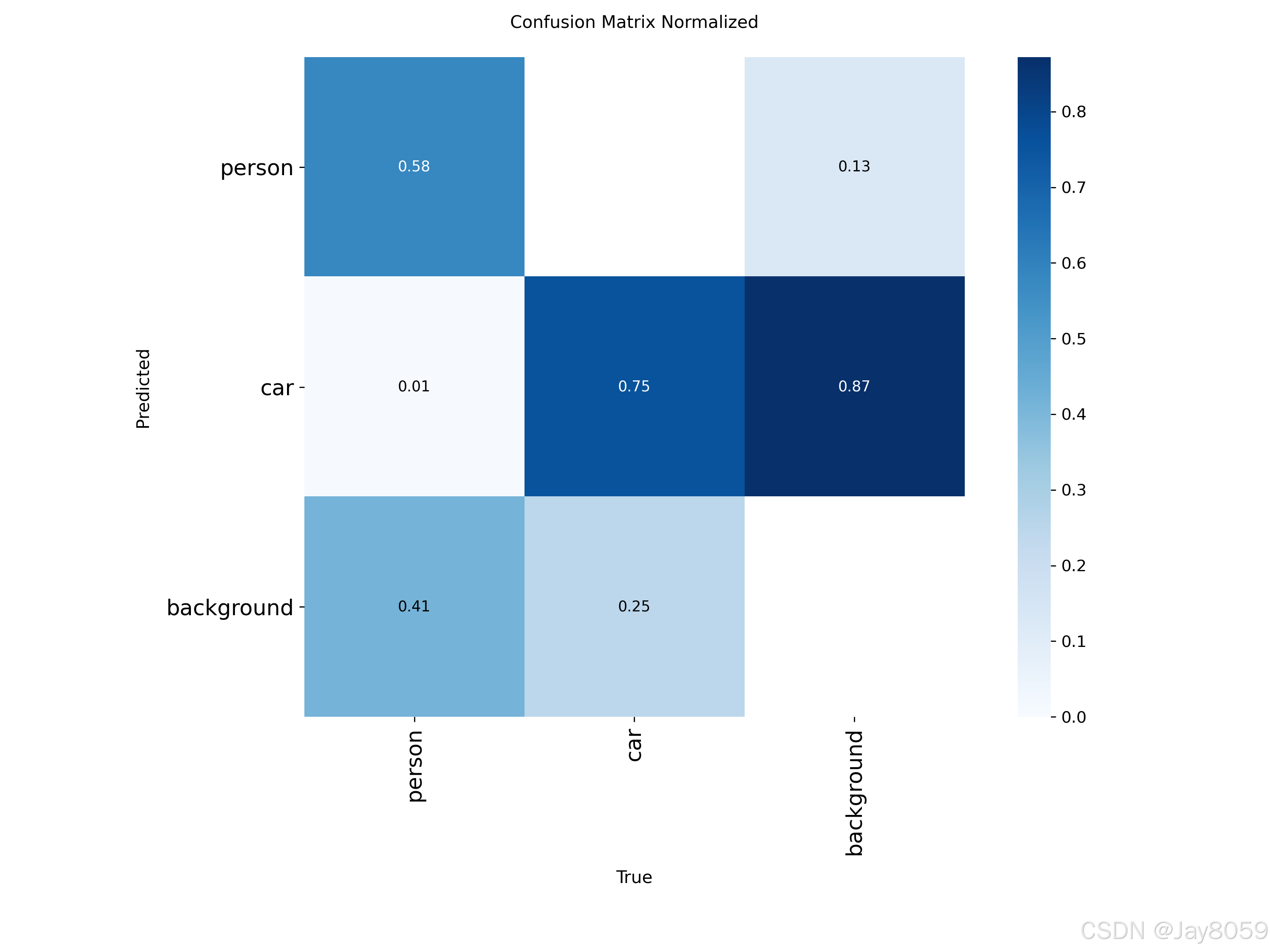
- confusion_matrix.png:混淆矩阵,展示模型在各类别上的分类准确性
- confusion_matrix_normalized.png:归一化混淆矩阵,便于比较不同类别
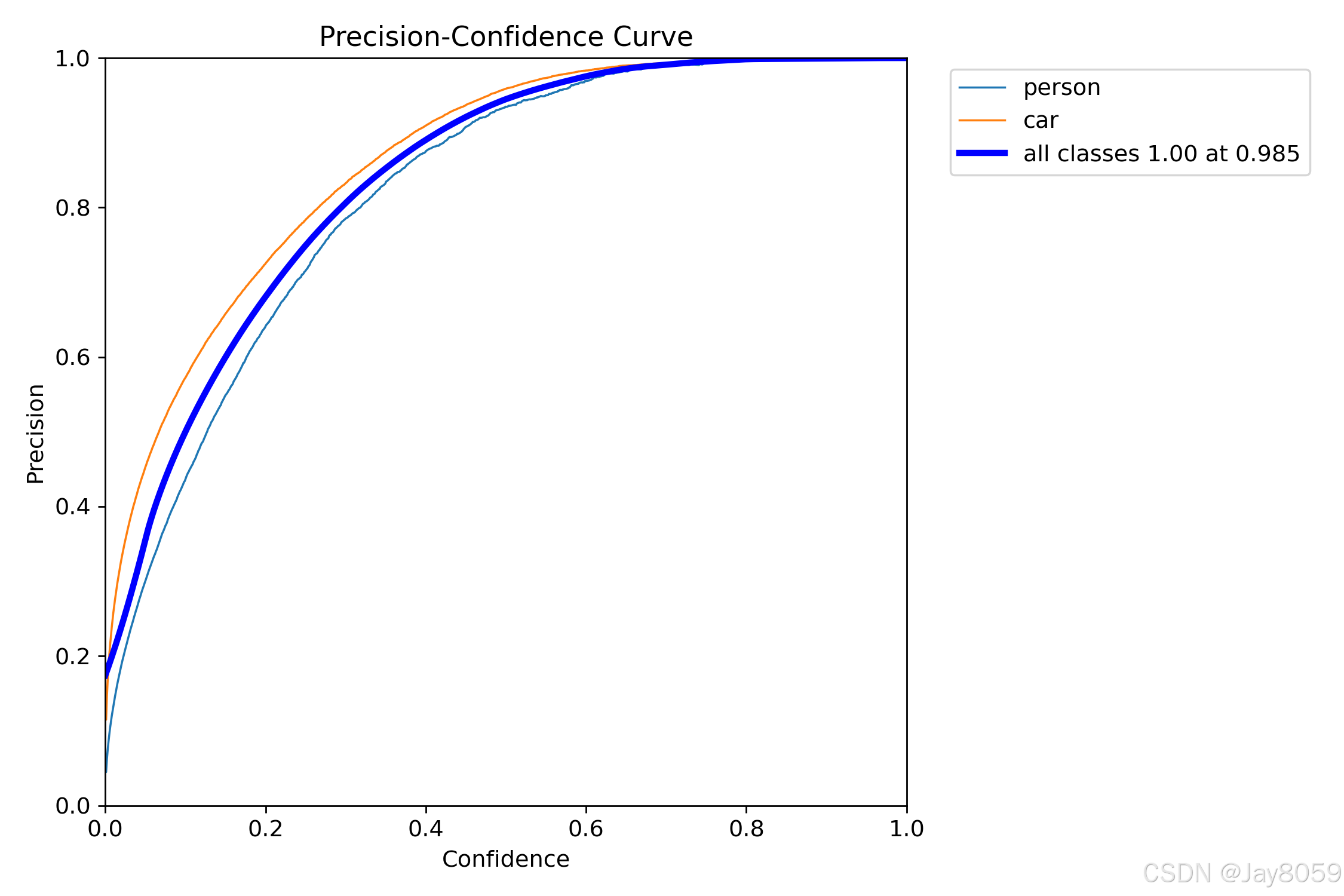
- F1_curve.png:F1分数曲线,展示不同置信度阈值下的F1分数变化
- P_curve.png:精确度曲线,展示不同置信度阈值下的精确度变化
- R_curve.png:召回率曲线,展示不同置信度阈值下的召回率变化
- PR_curve.png:精确度-召回率曲线,展示精确度和召回率的权衡关系
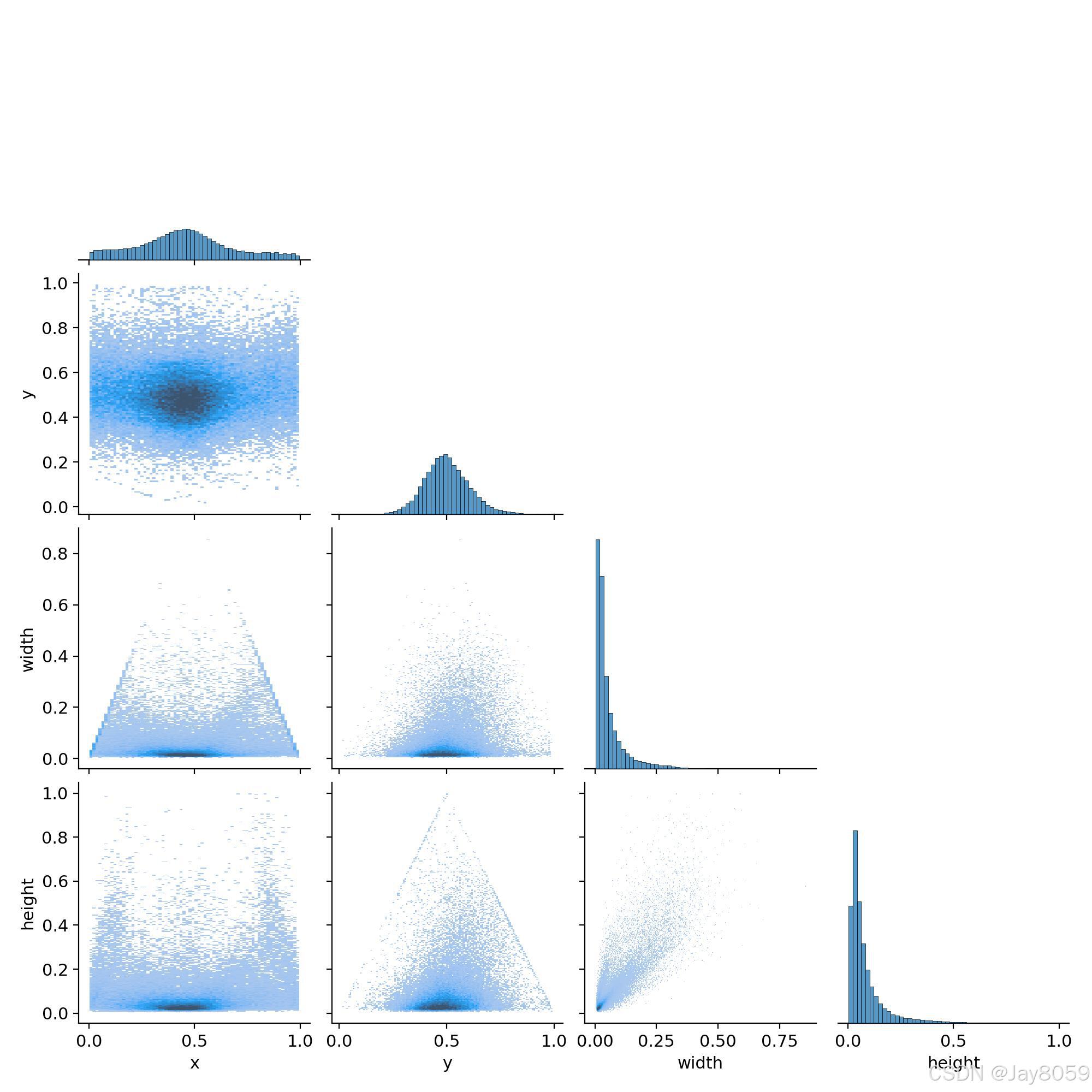
- results.png:训练结果汇总图,包含损失函数、mAP等指标随训练轮数的变化
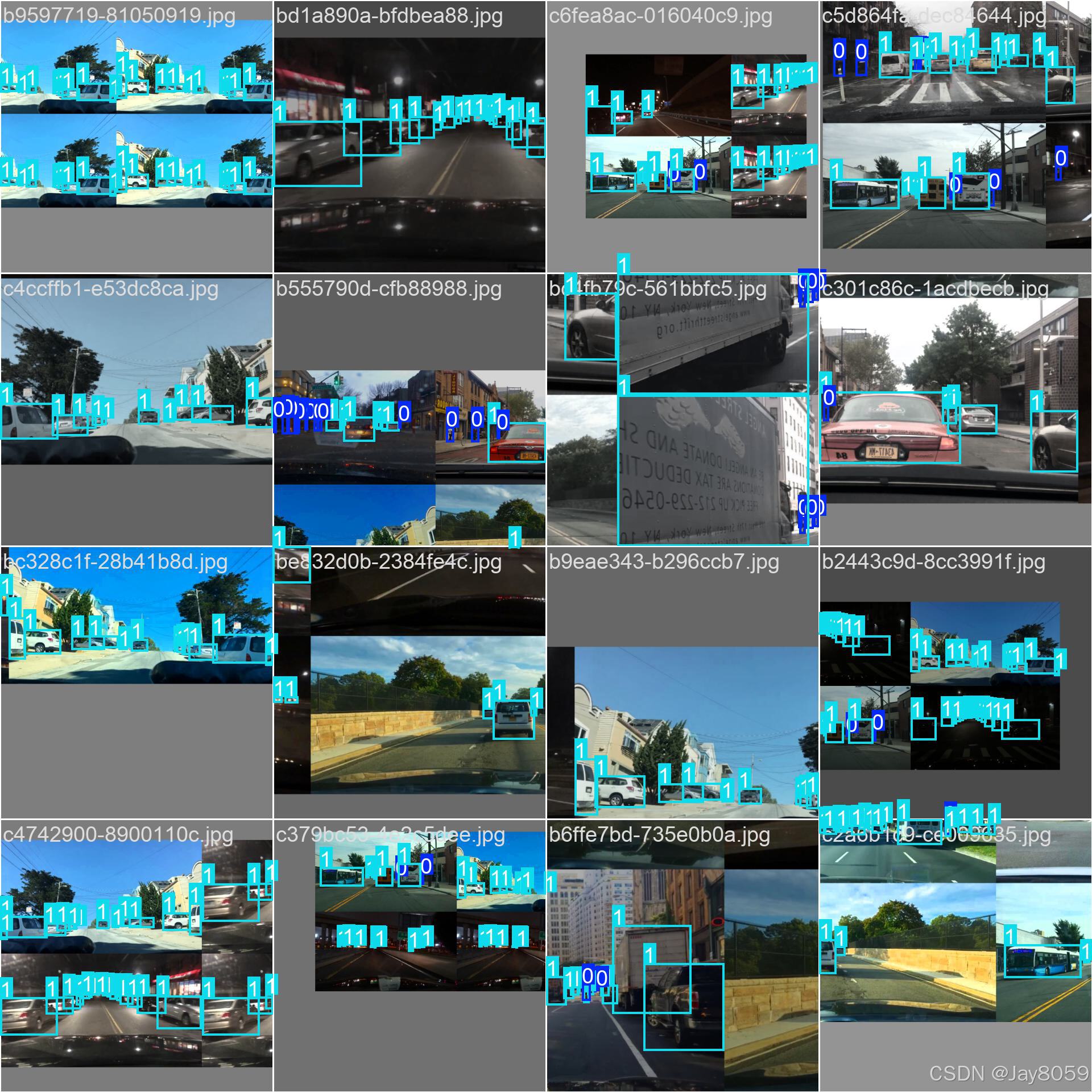
- train_batch.jpg*:训练批次可视化,展示训练过程中的数据增强效果
- val_batch_labels.jpg*:验证集标签可视化,展示真实标注框
- val_batch_pred.jpg*:验证集预测结果可视化,展示模型预测框
系统功能
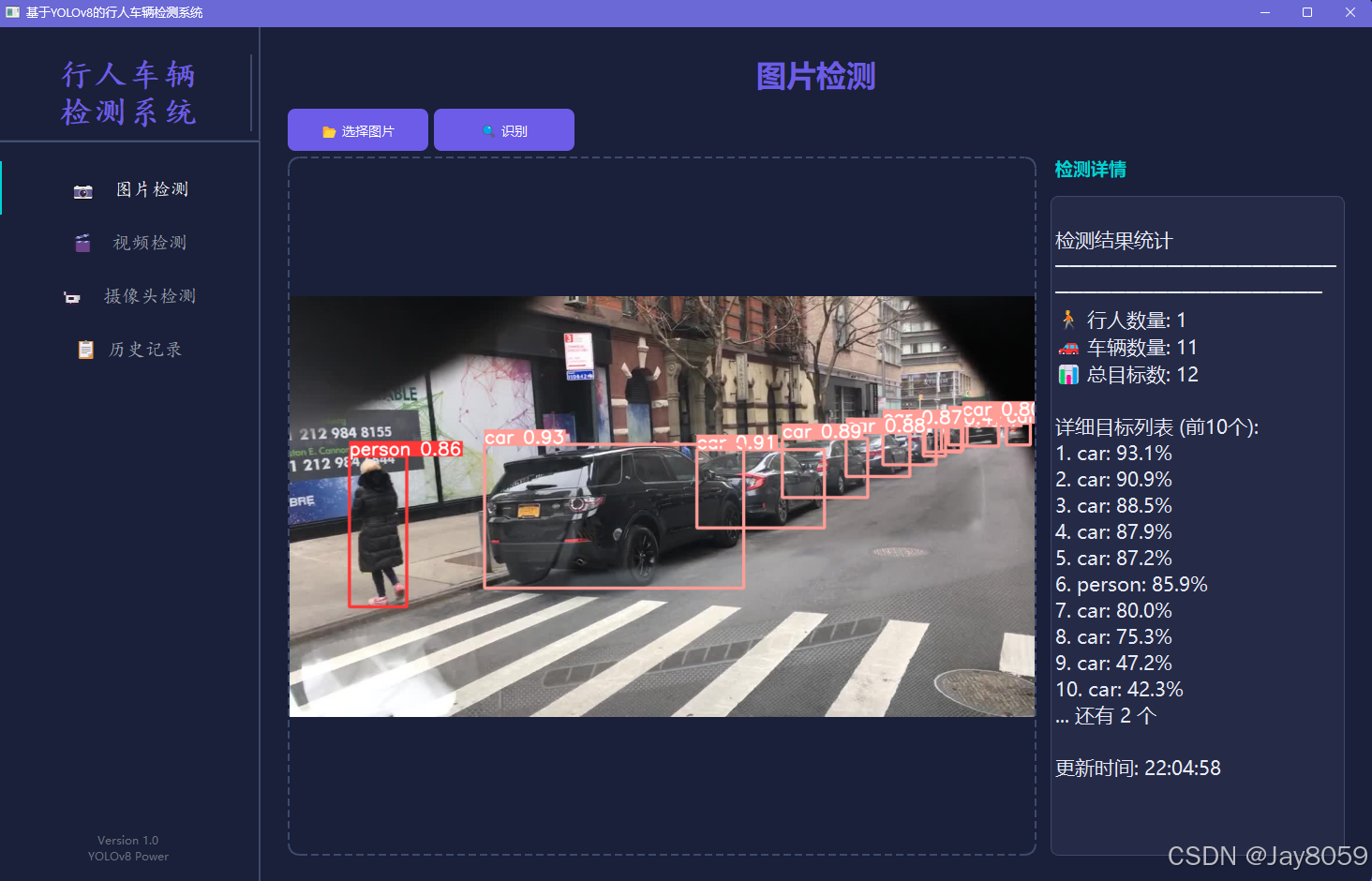
- 单张图像识别:上传单张图像进行行人和车辆检测,实时显示检测结果和统计信息
- 视频识别:支持视频文件导入,逐帧进行目标检测并实时显示
- 摄像头实时识别:支持调用摄像头进行实时检测,适用于实时监控场景
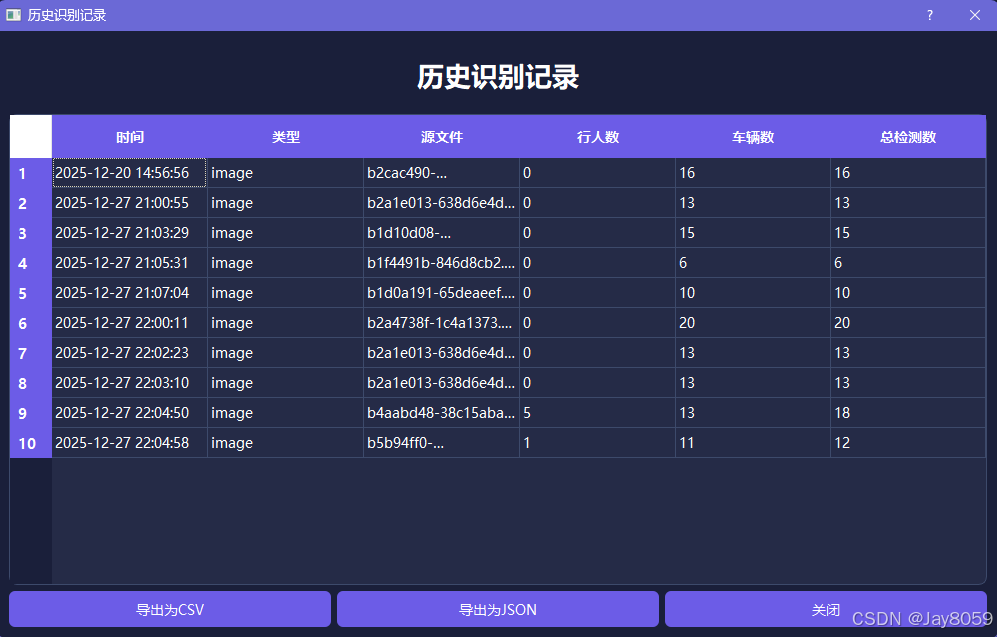
- 历史记录查询:自动保存每次检测记录,支持查看历史检测数据
- 数据导出:识别结果可导出为CSV或JSON格式,便于后续分析和处理
- 检测结果可视化:实时显示检测框、类别标签和置信度,直观展示检测效果
技术栈
- 前端框架:PyQt5
- 深度学习框架:PyTorch
- 目标检测算法:YOLOv8(Ultralytics)
- 图像处理:OpenCV
- 数据处理:NumPy、JSON、CSV
系统运行流程
- 启动系统 :运行主程序
detection_ui.py,加载训练好的YOLOv8模型权重 - 选择检测模式:用户通过左侧导航栏选择检测模式(图片识别/视频识别/摄像头识别)
- 输入检测源 :
- 图片模式:选择单张图片文件
- 视频模式:选择视频文件
- 摄像头模式:选择摄像头设备编号
- 执行检测:系统调用YOLOv8模型对输入进行检测,实时显示检测结果
- 结果展示:显示检测框、类别、置信度以及统计信息(行人数、车辆数、总检测数)
- 保存记录:图片检测完成后自动保存到历史记录
- 查询导出:用户可查看历史记录,并导出为CSV或JSON格式
系统目录结构
code/
├── detection_ui.py # 主程序入口,GUI界面
├── detection_history.json # 检测历史记录数据
├── log.txt # 训练日志
├── data/ # 数据集目录
│ ├── data.yaml # 数据集配置文件
│ ├── images/ # 图片目录
│ │ ├── train/ # 训练集图片
│ │ └── val/ # 验证集图片
│ └── labels/ # 标注文件目录
│ ├── train/ # 训练集标注
│ └── val/ # 验证集标注
├── runs/ # 训练输出目录
│ └── detect/
│ └── person_car_detect/ # 训练结果
│ ├── weights/ # 模型权重文件
│ │ ├── best.pt # 最佳模型权重
│ │ └── last.pt # 最后一轮权重
│ ├── *.png # 训练可视化图表
│ └── *.jpg # 训练批次可视化
├── vis_output/ # 可视化输出目录
├── yolo11m.pt # YOLO模型文件
├── yolo11n.pt # YOLO模型文件
├── yolov8s-cls.pt # YOLO分类模型
└── yolov8s.pt # YOLO检测模型系统部分截图