(以下内容全部出自上述课程)
目录
- 指令流水线的影响因素和分类
- 机器周期的设置
-
- [1. 影响因素](#1. 影响因素)
-
- [1.1 结构相关](#1.1 结构相关)
- [1.2 数据相关](#1.2 数据相关)
- [1.3 控制相关](#1.3 控制相关)
- [1.4 影响因素-小结](#1.4 影响因素-小结)
- [2. 分类(了解)](#2. 分类(了解))
- [3. 多发技术](#3. 多发技术)
-
- [3.1 超标量技术](#3.1 超标量技术)
- [3.2 超流水技术](#3.2 超流水技术)
- [3.3 超长指令字](#3.3 超长指令字)
- [4. 小结](#4. 小结)
- 五段式指令流水线
-
- [1. 介绍](#1. 介绍)
- [2. 执行过程](#2. 执行过程)
-
- [2.1 运算类指令](#2.1 运算类指令)
- [2.2 LOAD指令](#2.2 LOAD指令)
- [2.3 STORE指令](#2.3 STORE指令)
- [2.4 条件转移指令](#2.4 条件转移指令)
- [2.5 无条件转移指令](#2.5 无条件转移指令)
- [3. 例题](#3. 例题)
- 多处理器(概念)
-
- [1. 各种概念](#1. 各种概念)
-
- [1.1 SISD](#1.1 SISD)
- [1.2 SIMD](#1.2 SIMD)
- [1.3 MISD](#1.3 MISD)
- [1.4 MIMD](#1.4 MIMD)
- [1.5 概念-小结](#1.5 概念-小结)
- [2. 向量处理器](#2. 向量处理器)
- [3. 共享内存多处理器&多核处理器](#3. 共享内存多处理器&多核处理器)
- [4. 小结](#4. 小结)
- 硬件多线程(概念)
指令流水线的影响因素和分类
之前的指令流水线的内容,具体可见:指令流水线的基本概念和性能指标
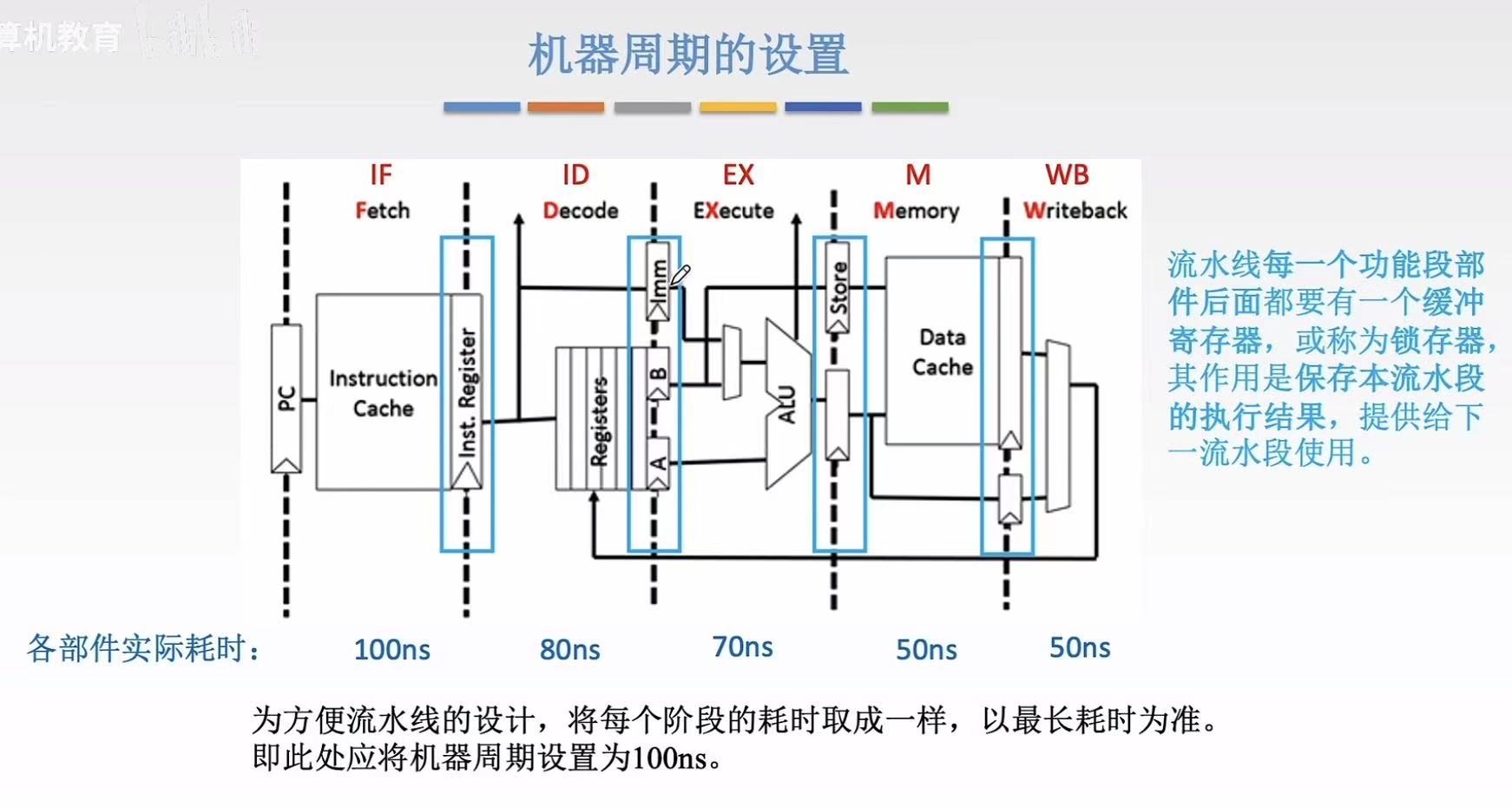
机器周期的设置
- IF :Instruction Fetch(取指)周期
PC(Program Counter):指向当前要取的指令地址
Instruction Cache(指令缓存):高速缓存,存放最近使用的指令
Instruction Register(Inst. Reg):暂存刚刚取出的指令 - ID :Instruction Decode(译码)周期
Registers(寄存器文件):存放通用寄存器(如 r1, r2)
A 和 B:两个输入端口,分别从寄存器读取操作数
Imm:存放立即数的存储器 - EX :Execute(执行)周期
ALU(Arithmetic Logic Unit):算术逻辑单元,执行加减乘除、移位等 - M :Memory(访存)周期
Data Cache(数据缓存):高速缓存,存放常用数据 - WB :WB:Writeback(写回)周期
Reg(寄存器):写回目标寄存器
注意 :为了方便流水线设计,所以就算每个周期用时不同,也会统一为最长的用时。
如图 :最大的时长是100ns。所以就会设计每个周期都是100ns。
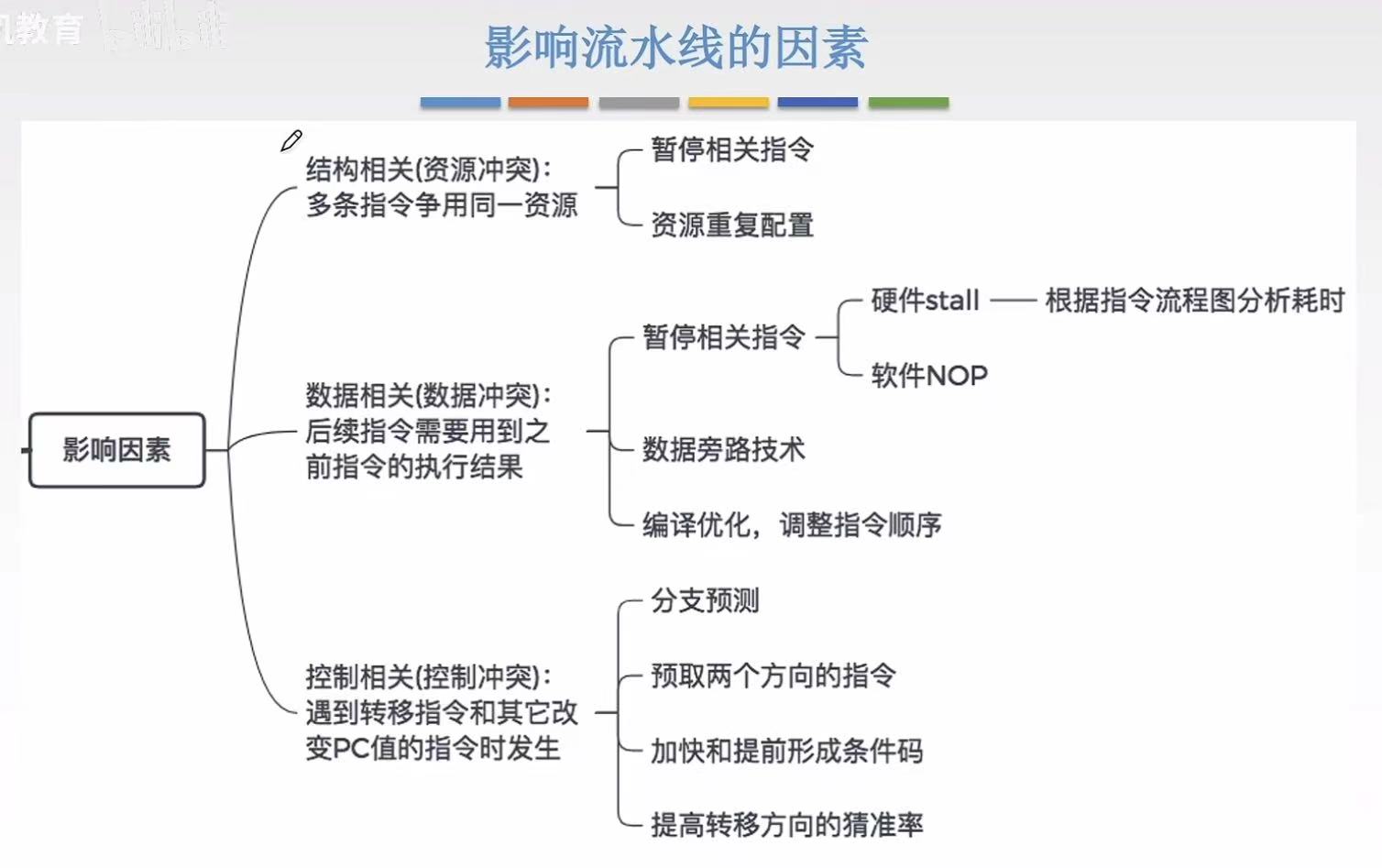
1. 影响因素

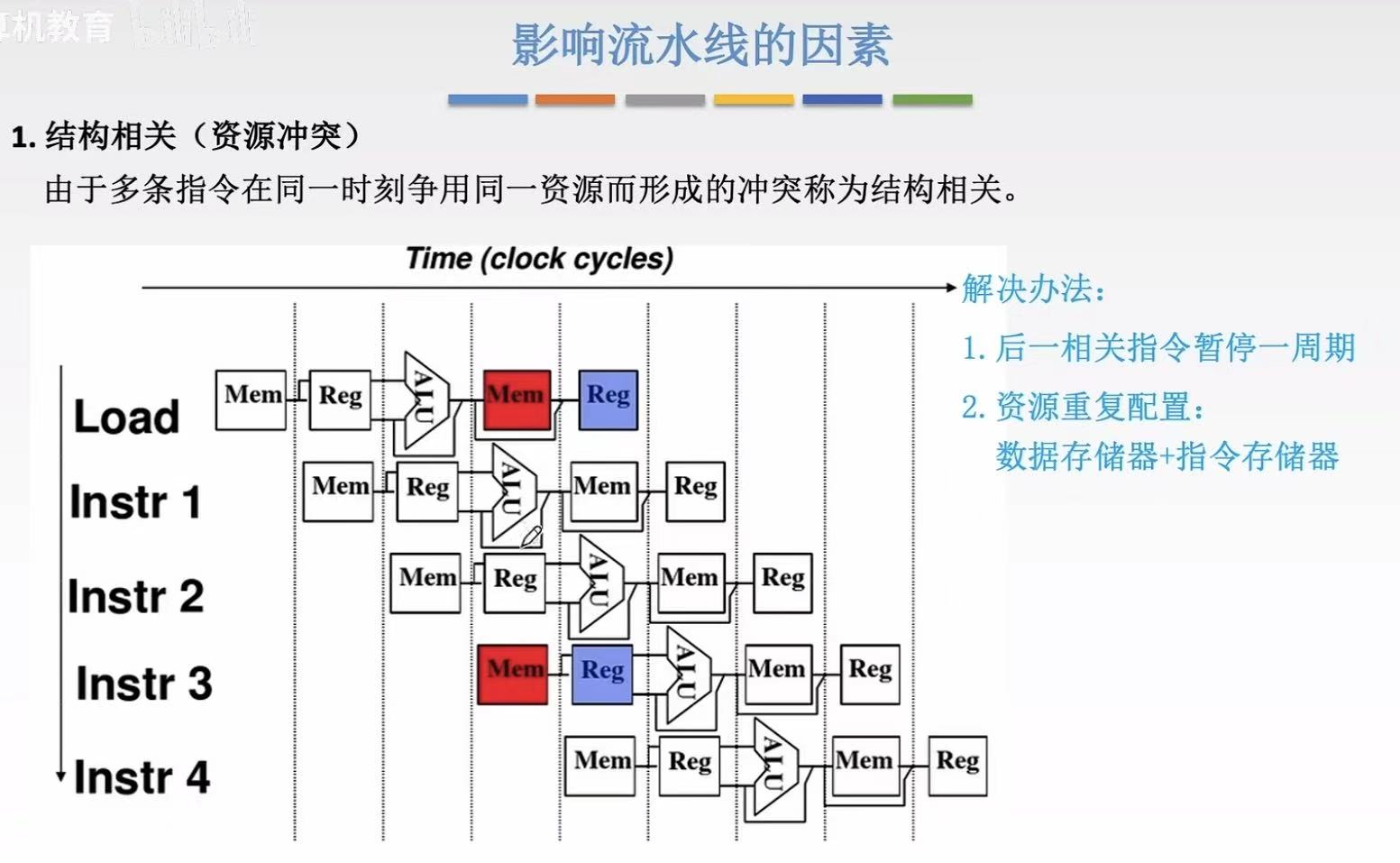
1.1 结构相关
类比-厨房:
- 只有一个炉灶(资源)
- 两个厨师(指令)都想同时用它炒菜 → 冲突!
- 解决办法:要么让其中一个等一下(暂停),要么增加一个炉灶(重复配置)
如图:
- Instr 1 正在 Memory 阶段(M):需要从内存读取数据(Load 指令)
- Instr 2 正在 Instruction Fetch(IF):需要从内存读取下一条指令(即取指)
- 两者都同时访问内存!
但图中显示:
- 只有一个 Memory 模块(共享的存储器)
- 不能同时完成"取指令"和"读数据"
- 所以发生了 资源冲突
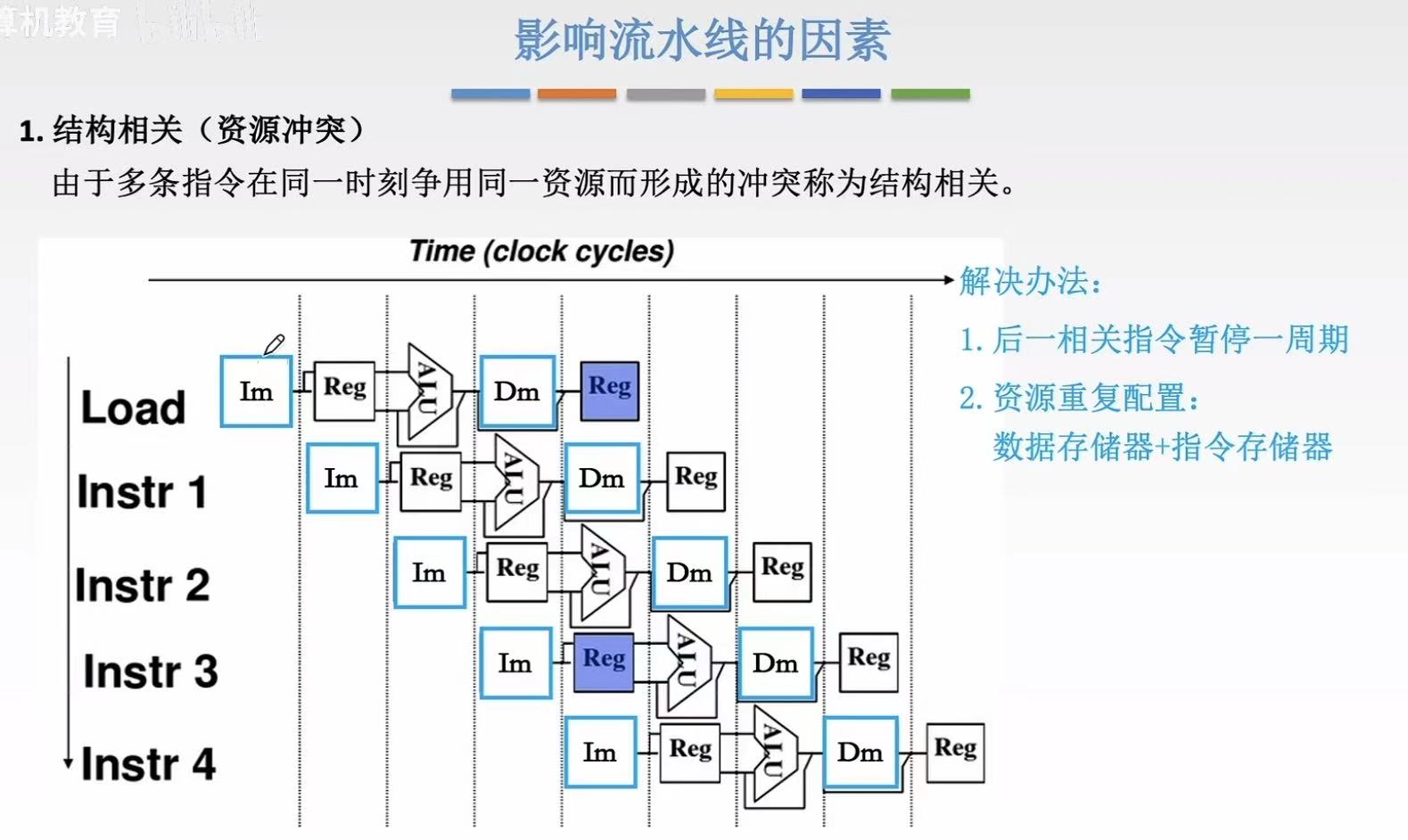
- 后一相关指令暂停一周期 (Stall)
让 Instr 2 的 IF 阶段延迟一个周期
即:Instr 2 跳过第 3 个周期,等到第 4 个周期再取指
这样就避免了与 Instr 1 同时访问内存 - 资源重复配置 (Resource Duplication)
将 指令存储器(图中Im) 和 数据存储器(图中Dm) 分开
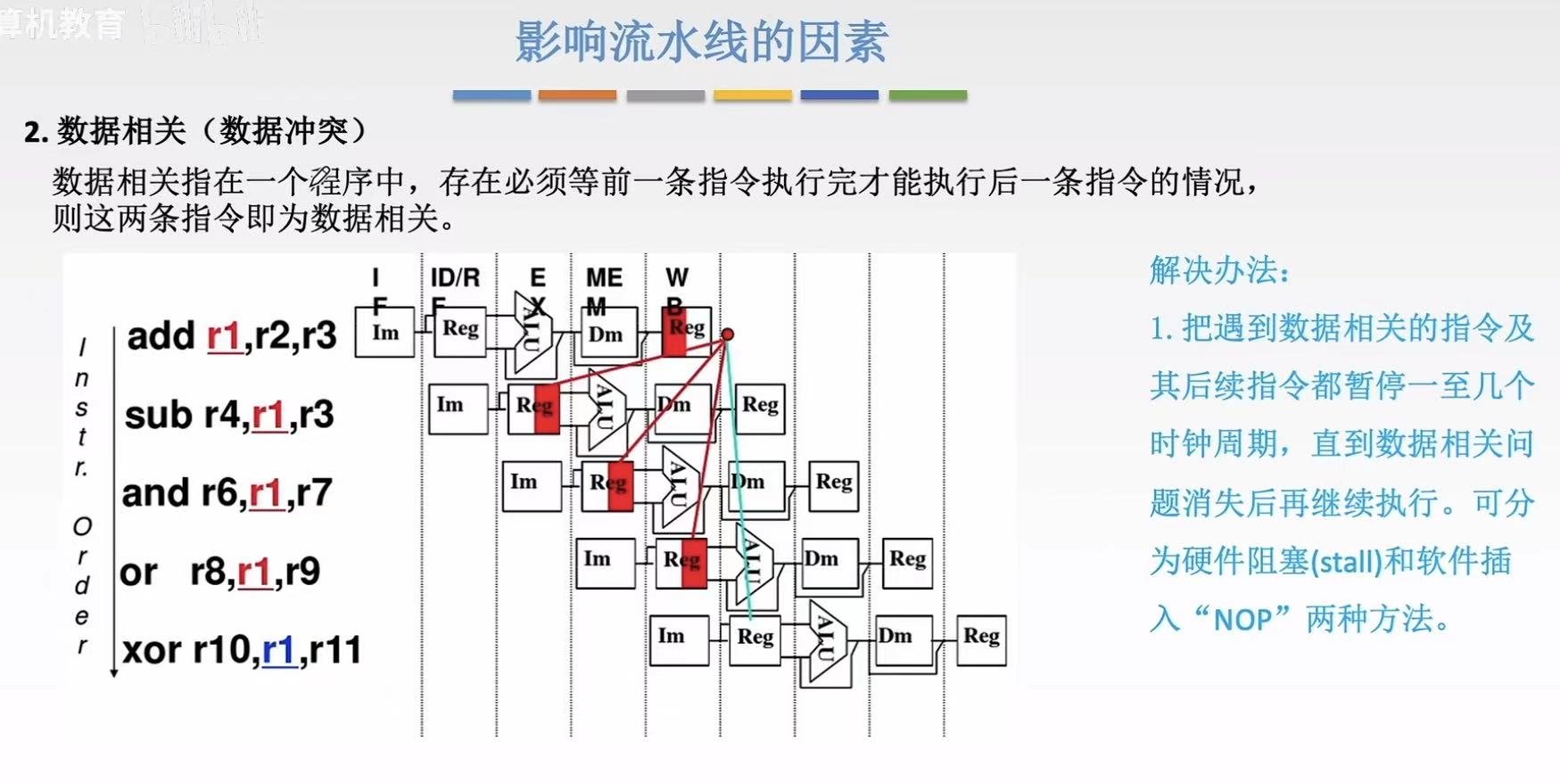
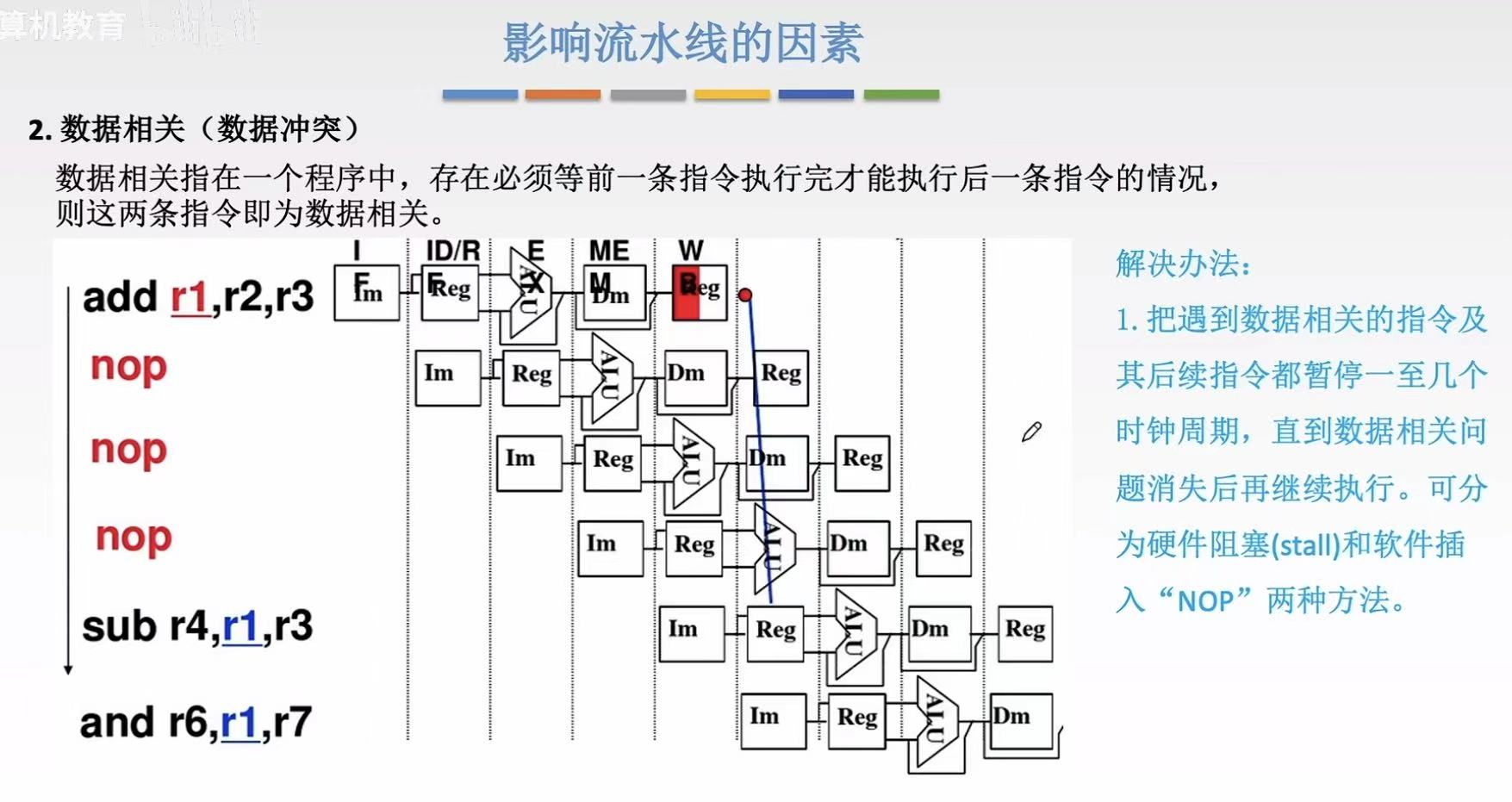
1.2 数据相关
数据冲突-比如图中:
- add的r1最后需要存入reg,如果sub和add同时执行,sub就要在add还没得到的结果的时候用add得到的结果
- 简单来说,就是提前预支了自己没有的东西
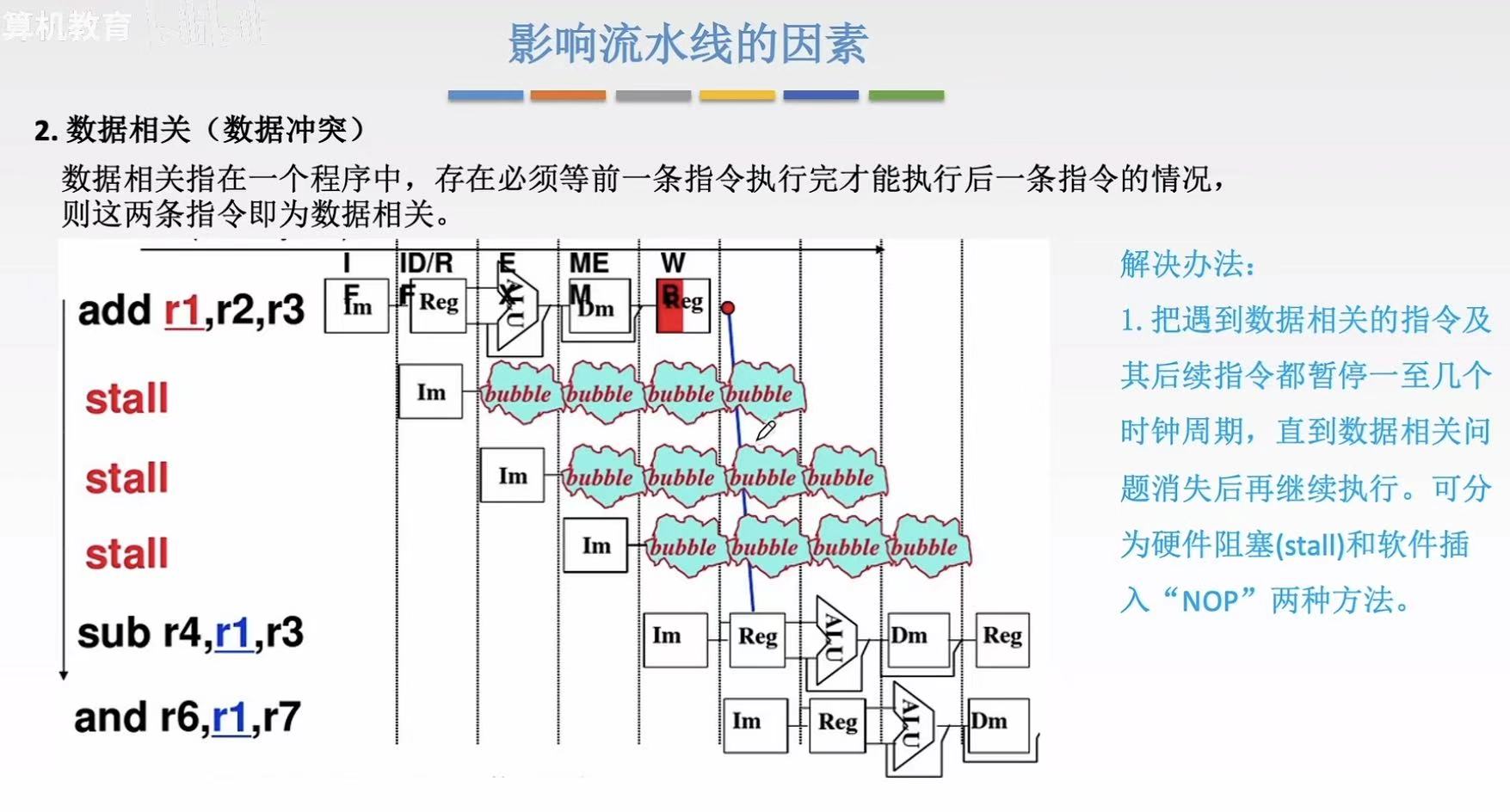
硬件阻塞: - 就是在上一步的结果没出来之前,通过插入 'bubble'(空操作)来填充因数据依赖而暂停的时钟周期,实现硬件阻塞(stall)
- 流程:第一步结果没出来之前-->bubble-->bubble...-->结果出来了-->下一步正好需要用到结果的周期
软件插入: - 和硬件差不多,不过是直接填充了空指令
- 等结果出来之后,再让下一条有实际意义的指令执行
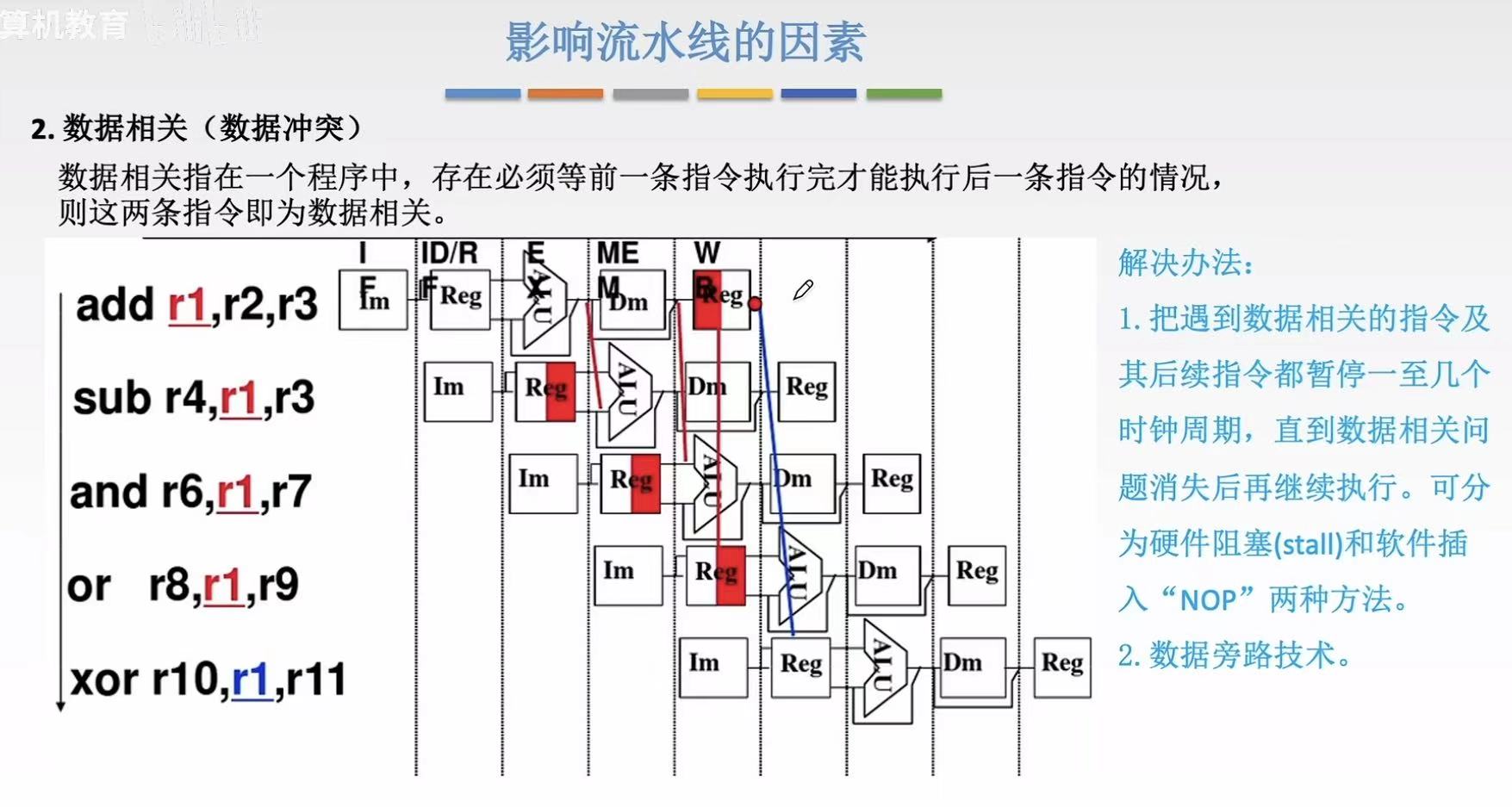
数据旁路技术: - 上一步得到的结果,因为下一步要用,就直接通过旁路传输给下一步要用的组件
- 比如图中:add算出来的r1直接从自己的ALU传递到sub的ALU上
- 图中连的线都可以看成旁路
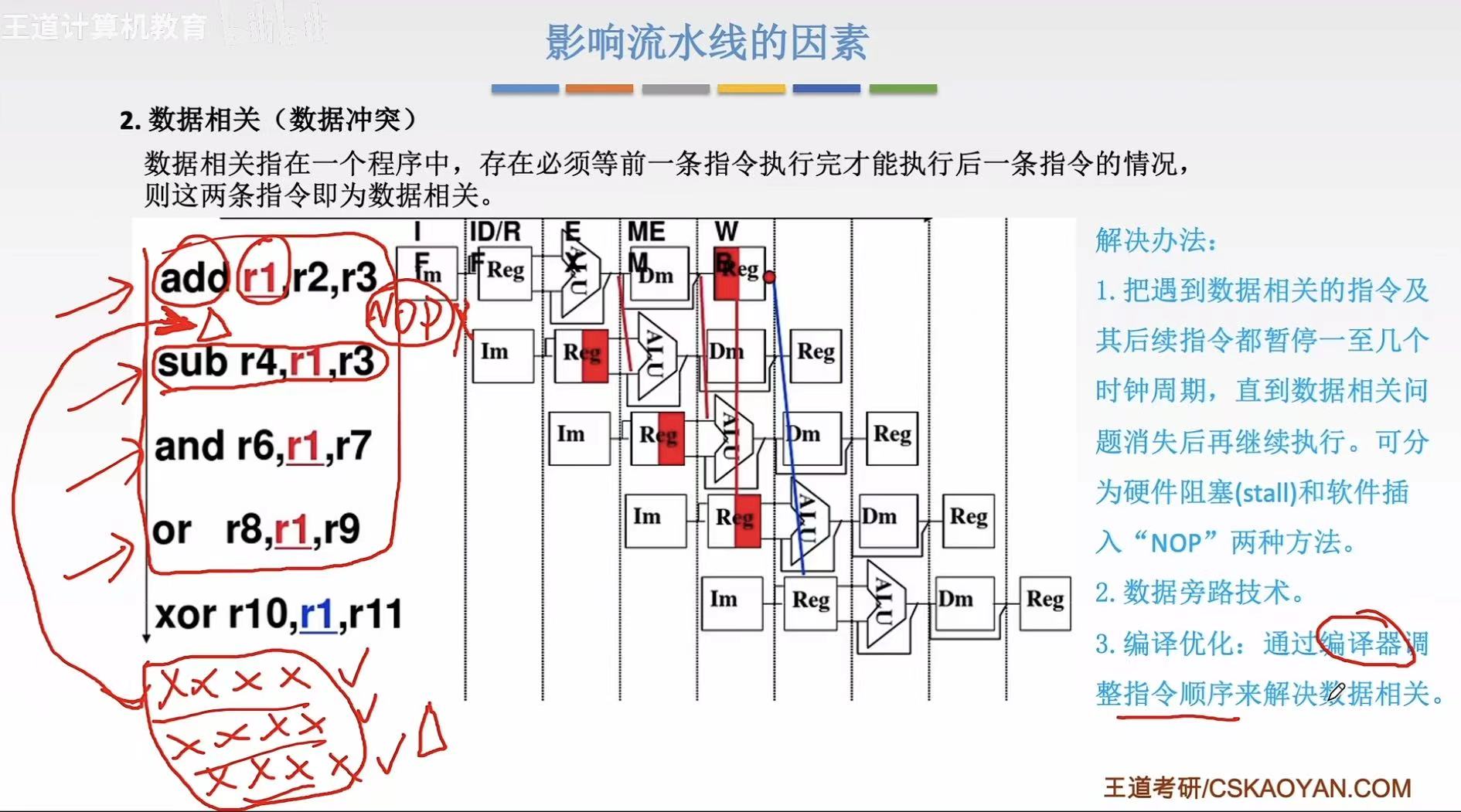
编译优化: - 可以将不被数据冲突影响的指令插在两条互相影响的指令中间
- 类似于:上面硬件阻塞的bubble 变成了 后续需要执行的与数据无关的指令
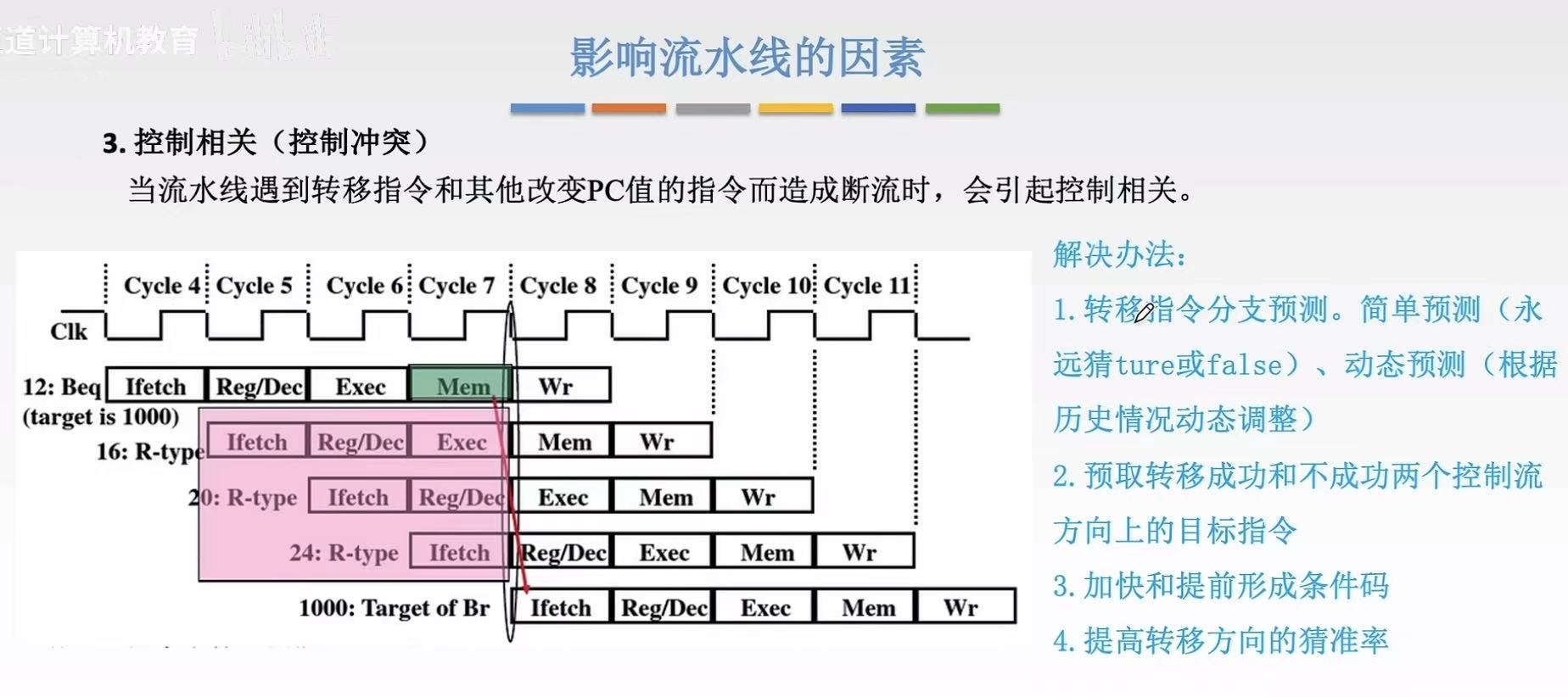
1.3 控制相关
控制冲突-如图:
- 12:Beq这行指令要求跳到序号为1000的指令
- 但是我们正常是需要12-->16-->20这个顺序来执行指令
- 因为序号12的指令要求跳到序号1000,就和我们本应执行的顺序冲突了
主要原因:转移指令or其他改变PC值的指令
1.4 影响因素-小结
2. 分类(了解)
-
部件功能级:把一个蛋糕分成4步做(打蛋、拌面糊、烤、冷却) 将复杂操作拆成多个子步骤
-
处理机级:整个蛋糕店有5个工位:取材→搅拌→烘烤→装饰→包装 一条指令被分解为多个阶段(IF/ID/EX/M/WB)
-
处理机间级:有多个小作坊:A做奶油蛋糕,B做巧克力蛋糕,C做水果蛋糕 不同处理器专门负责不同任务
-
单功能流水线:只能做"奶油蛋糕"的机器 专一高效,但不能做其他蛋糕
-
多功能流水线 :能切换模式:做奶油、巧克力、水果蛋糕 通过改变连接方式实现多种功能

-
静态流水线:工厂只允许按"奶油蛋糕"流程走 所有阶段只能以一种方式连接
-
动态流水线:工厂可以根据订单自动调整流程 某些阶段做加法,另一些阶段做乘法
-
线性流水线:从起点到终点只走一次,不能回头 每个功能段只允许经过一次
-
非线性流水线 :有环形轨道,可以反复跑 存在反馈回路,某些段可多次使用

3. 多发技术
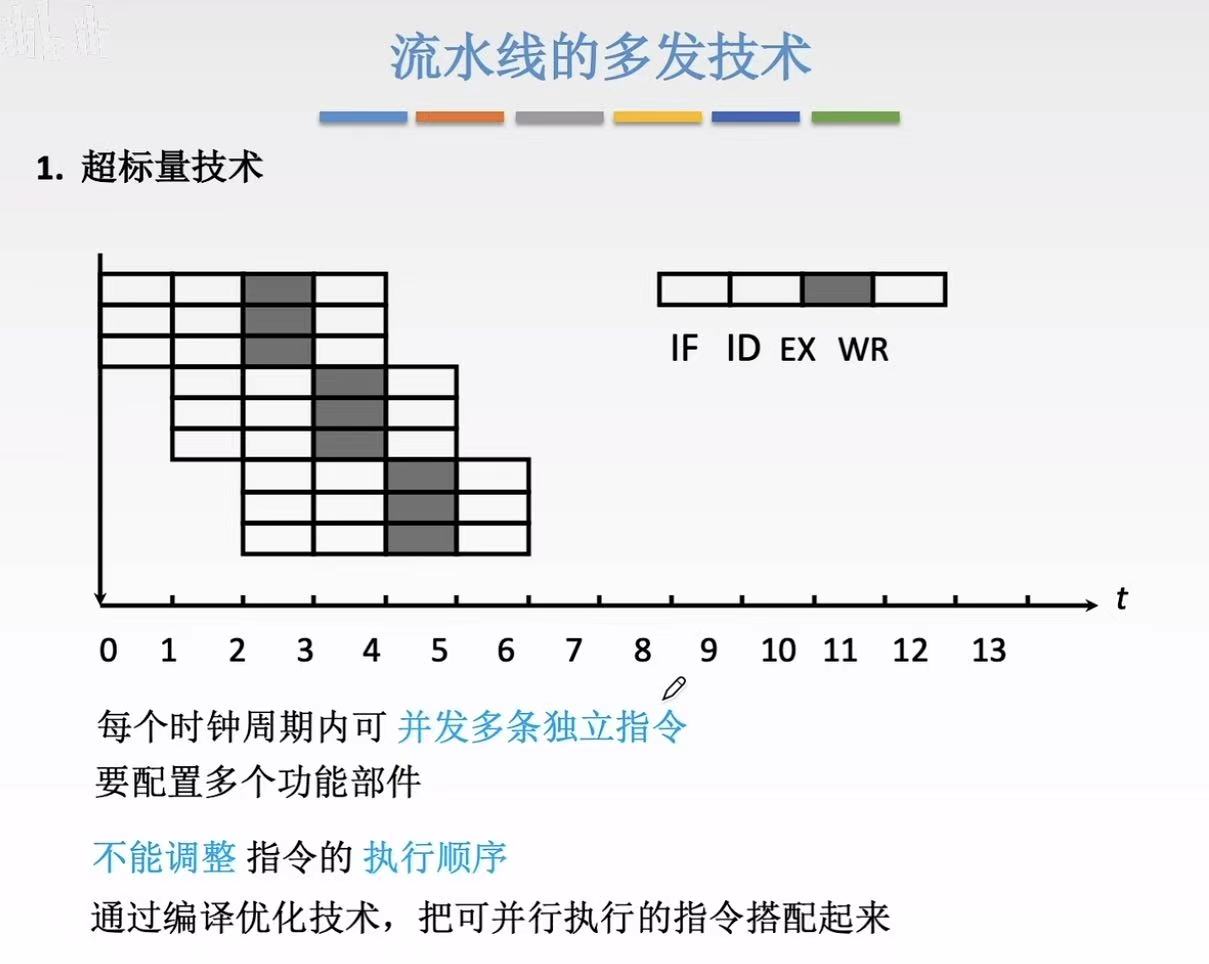
3.1 超标量技术
超标量(Superscalar)------ 多开几条并行流水线
- 做法:建 多条完全相同的分拣流水线,同时处理多个包裹。
- 特点:
每条线独立工作
控制器自动判断哪些包裹可以并行处理
硬件负责调度
类比:
- 仓库有 3 个分拣台,每个台都有自己的扫码机、打包机、传送带。
- 控制中心(硬件)看到 3 个不相关的包裹,就同时派给 3 个台处理。
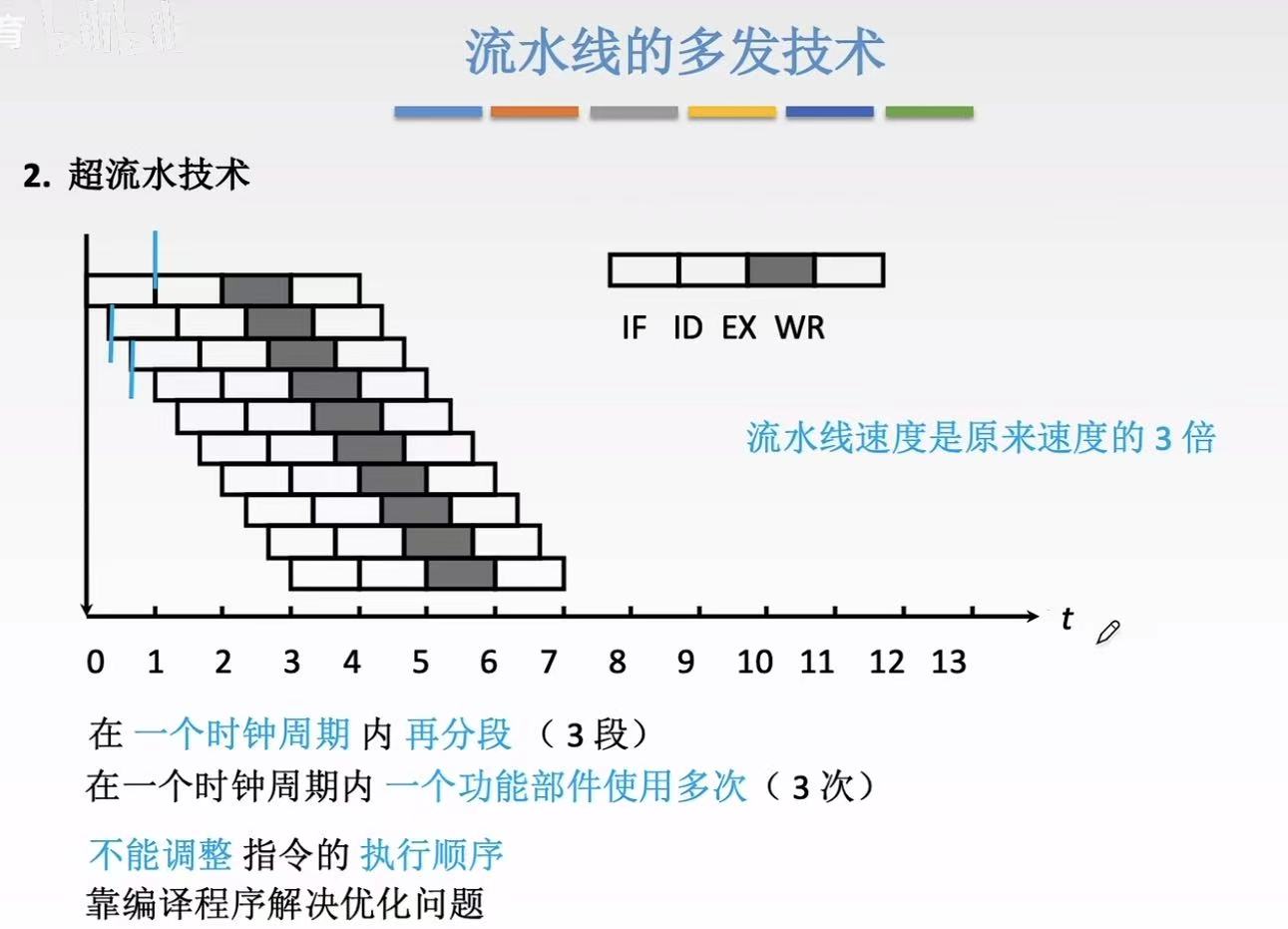
3.2 超流水技术
超流水(Superpipelining)------ 把一条流水线切得更细
- 做法:把原来的 5 级流水线切成 10 级、20 级......
- 特点:
每级任务更简单 → 主频可以更高
但每条指令走的步骤更多
仍是一个周期只发射 1 条指令
类比:
- 原来 1 个工人负责"扫码+打包+贴单",现在拆成 3 个工人:
- 工人A只扫码,工人B只打包,工人C只贴单。
- 流水线变长了,但每个工位更快,整体速度提升。
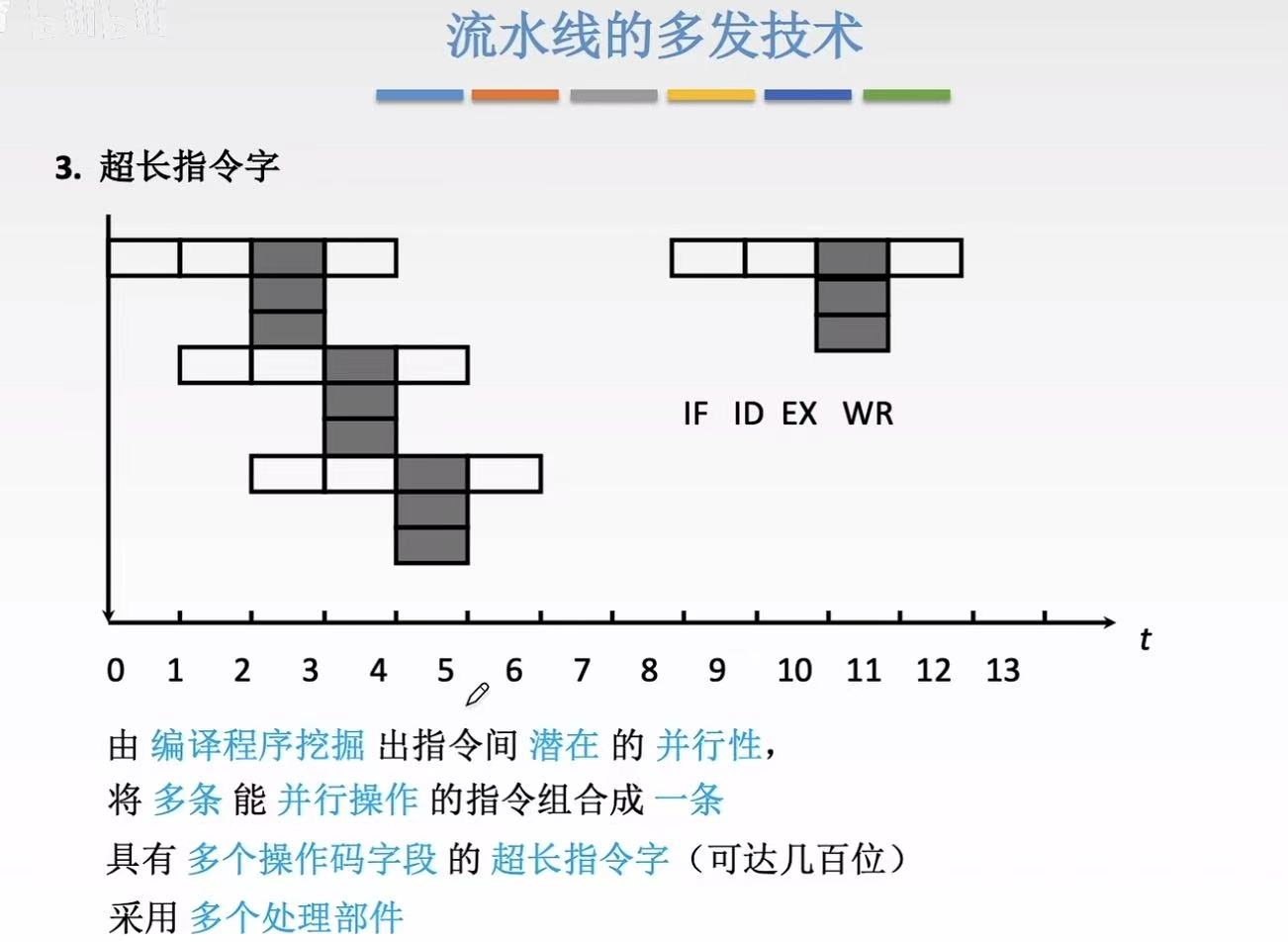
3.3 超长指令字
超长指令字(VLIW)------ 让程序员/编译器提前打包指令
- 做法:
编译器在编译时就把 多条能并行的指令打包成一条"超长指令",
CPU 直接按包执行,无需动态判断。 - 特点:
指令字很长(如 128 位、256 位)
包含多个操作(如:ALU1 + ALU2 + Load)
并行性由软件决定
类比:
- 快递公司要求客户自己把 3 个包裹绑在一起,写明:"这 3 个可同时处理"。
- 仓库收到后,直接交给 3 个工人同步操作,不用再判断是否冲突。
4. 小结
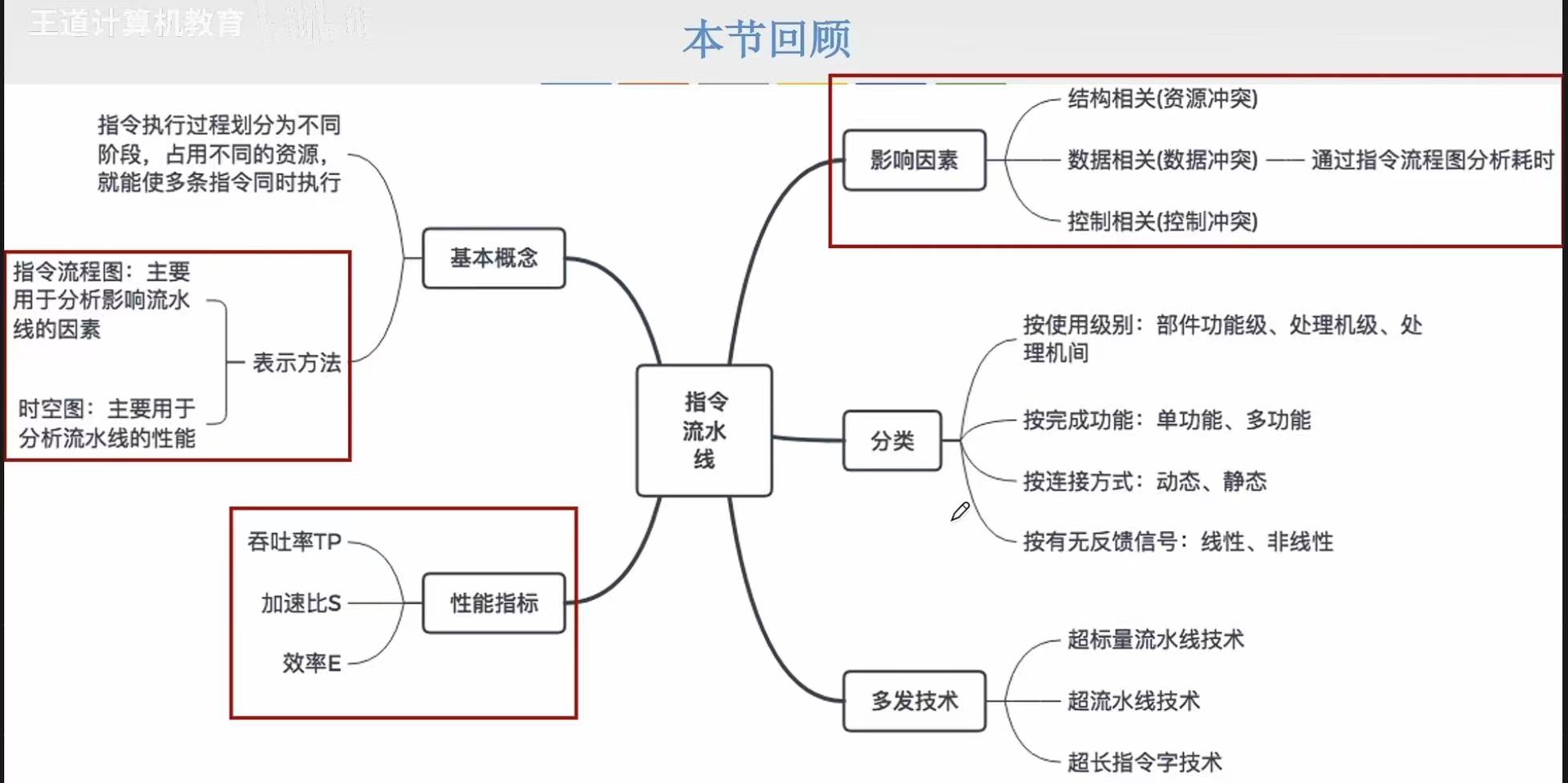
五段式指令流水线
1. 介绍
- IF :Instruction Fetch(取指)周期
PC(Program Counter):指向当前要取的指令地址
Instruction Cache(指令缓存):高速缓存,存放最近使用的指令
Instruction Register(Inst. Reg):暂存刚刚取出的指令 - ID :Instruction Decode(译码)周期
Registers(寄存器文件):存放通用寄存器(如 r1, r2)
A 和 B:两个输入端口,分别从寄存器读取操作数
MUX(多路选择器) 选择 A/B 的来源:寄存器或立即数
Imm:存放立即数的存储器 - EX :Execute(执行)周期
ALU(Arithmetic Logic Unit):算术逻辑单元,执行加减乘除、移位等
Store:见Store指令 - M :Memory(访存)周期
Data Cache(数据缓存):高速缓存,存放常用数据 - WB :WB:Writeback(写回)周期
Reg(寄存器):写回目标寄存器
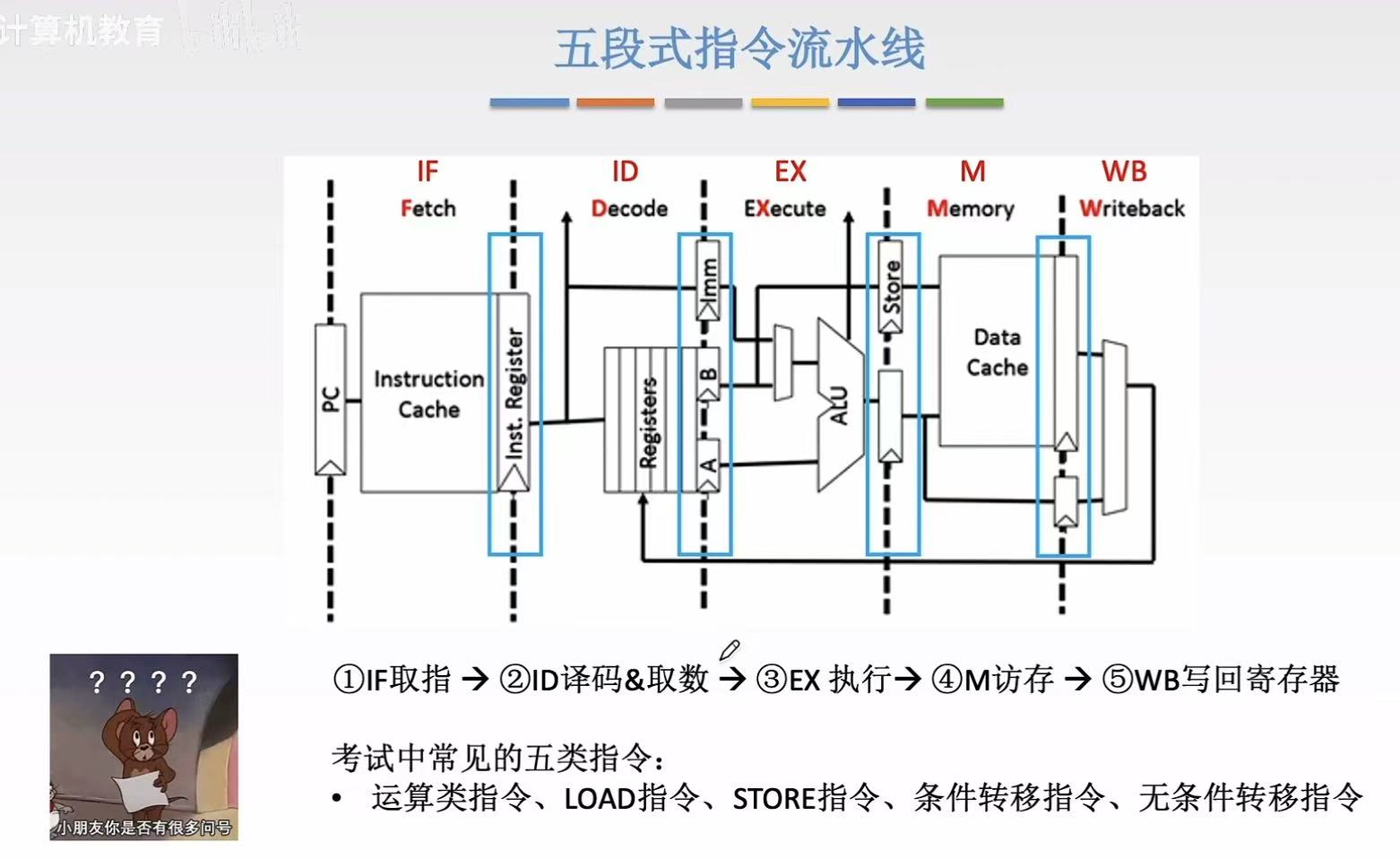
2. 执行过程
ps:常用数据基本都可以从Cache中找到,所以下方大多数指令都可以从Instruction Cache(指令缓存)中取到。
2.1 运算类指令
- IF-指令:PC(计数器)-->Instruction Cache(指令缓存)-->Inst. Reg(暂存寄存器)
- ID-指令-操作数:译码-->得到操作码&寄存器编号-->Registers(找寄存器编号)-->得到操作数-->A&B
- EX-操作数:A&B-->ALU-->锁存器
- M:无需访存
- WB-运算结果 :EX(ALU 结果) → M(bypass) → M/WB 锁存器 → WB → Registers
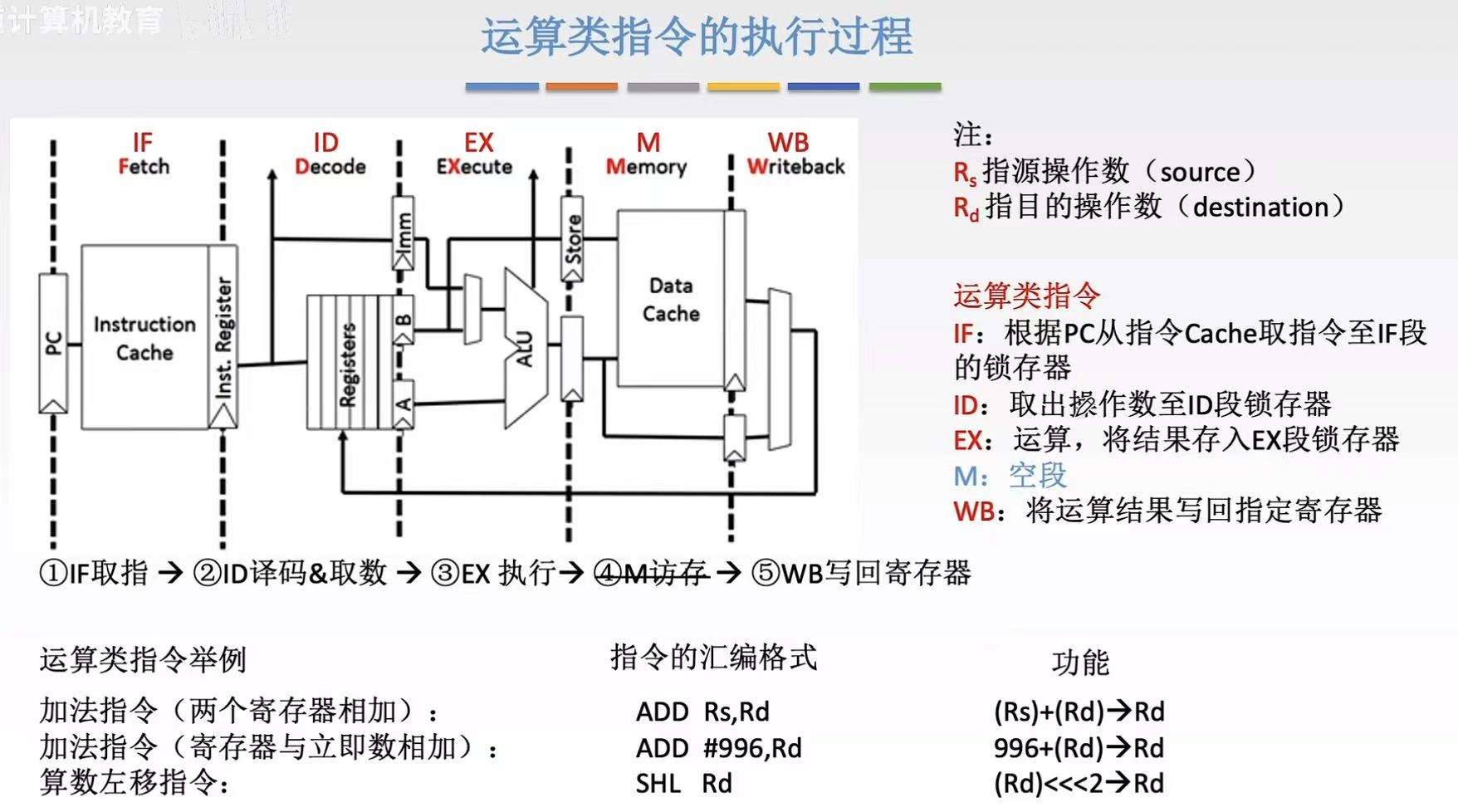
2.2 LOAD指令
LOAD 指令:用寄存器和偏移量算出内存地址,从该地址取出数据(这才是操作数),最后把数据写入目标寄存器。
- IF-指令:PC(计数器)→ Instruction Cache(指令缓存)→ Inst. Reg(暂存寄存器)
- ID-指令-地址值:译码 → 得到操作码 & 寄存器编号(Rs, Rd)& 偏移量 →从 Registers 读取 Rs 的值 →基址存 A,偏移量存 Imm
- EX-最终地址:A & Imm → ALU → 锁存器
- M(Memory):根据EX计算出来的最终地址,再在Data Cache中找到想要的值
- WB-找到的值 :M/WB 锁存器 → WB → Registers
2.3 STORE指令
STORE指令:将某个寄存器中的数据(值)存储(写入)到内存的指定地址中。
- IF-指令:PC(计数器)→ Instruction Cache(指令缓存)→ Inst. Reg(暂存寄存器)
- ID-指令-地址与数据准备:译码 → 获取操作码、Rs(基址寄存器)、Rt(源数据寄存器)、offset →从 Registers 读取 Rs 的值(基址) 和 Rt 的值(要存的数据) →将 Rs 送入 A,将 offset 送入 Imm(作为 B)→同时将 Rt 的值暂存为 StoreData
- EX-有效地址:A(Rs) + Imm(offset) → ALU → 计算出有效地址 →与 StoreData(Rt 的值)一起存入 EX/M 锁存器
- M-存数:根据EX计算出来的有效地址,写入Data Cache
- WB :无用
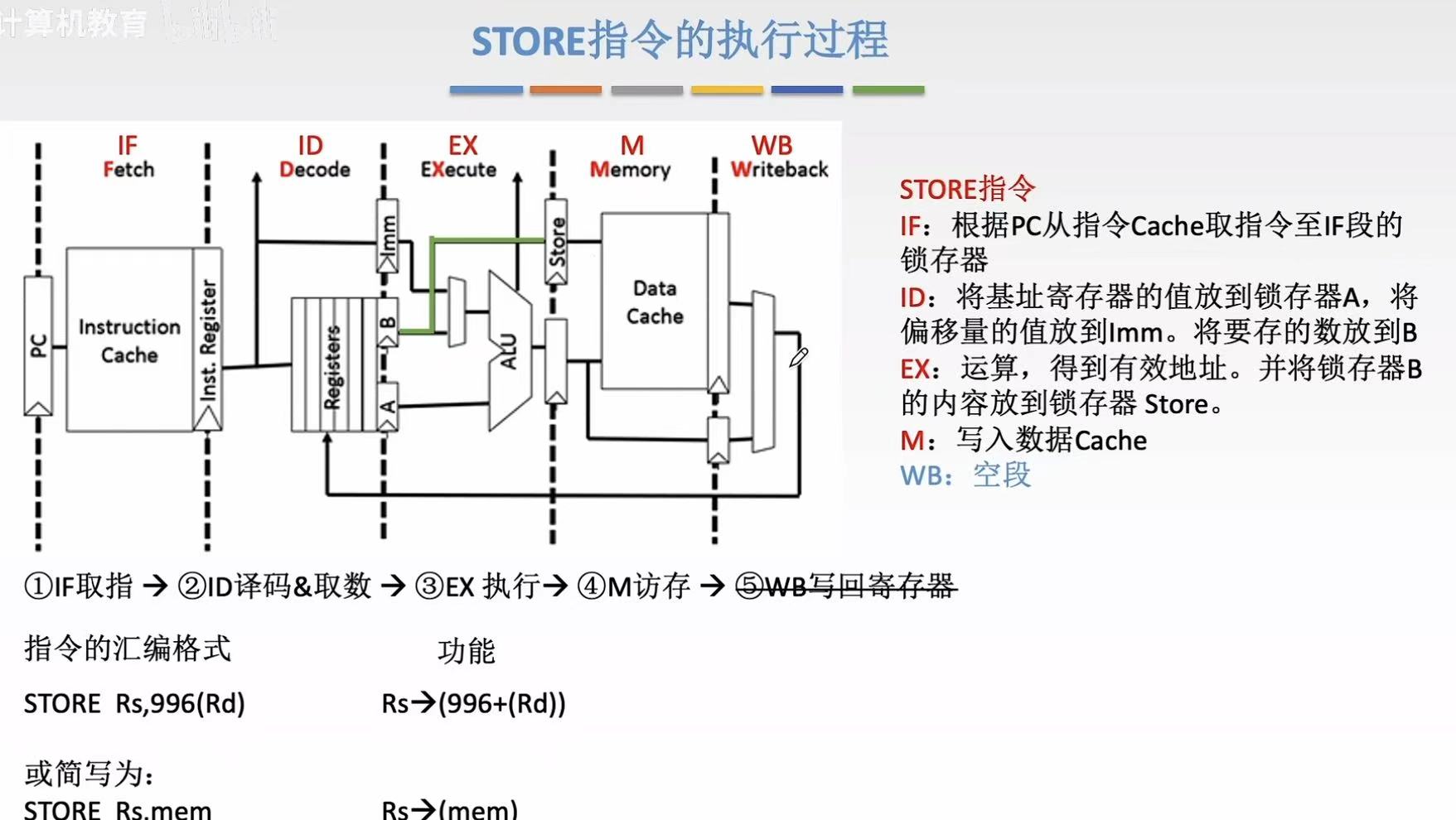
2.4 条件转移指令
条件转移本质:根据条件改变PC的值
- IF:公共操作,每次都一样
- ID:译码阶段,有啥值取啥值
- EX:运算,比较就进行比较运算,地址就按地址算,普通运算就按普通运算算
- M :运行时间短的话可以和写回PC功能融合在一起
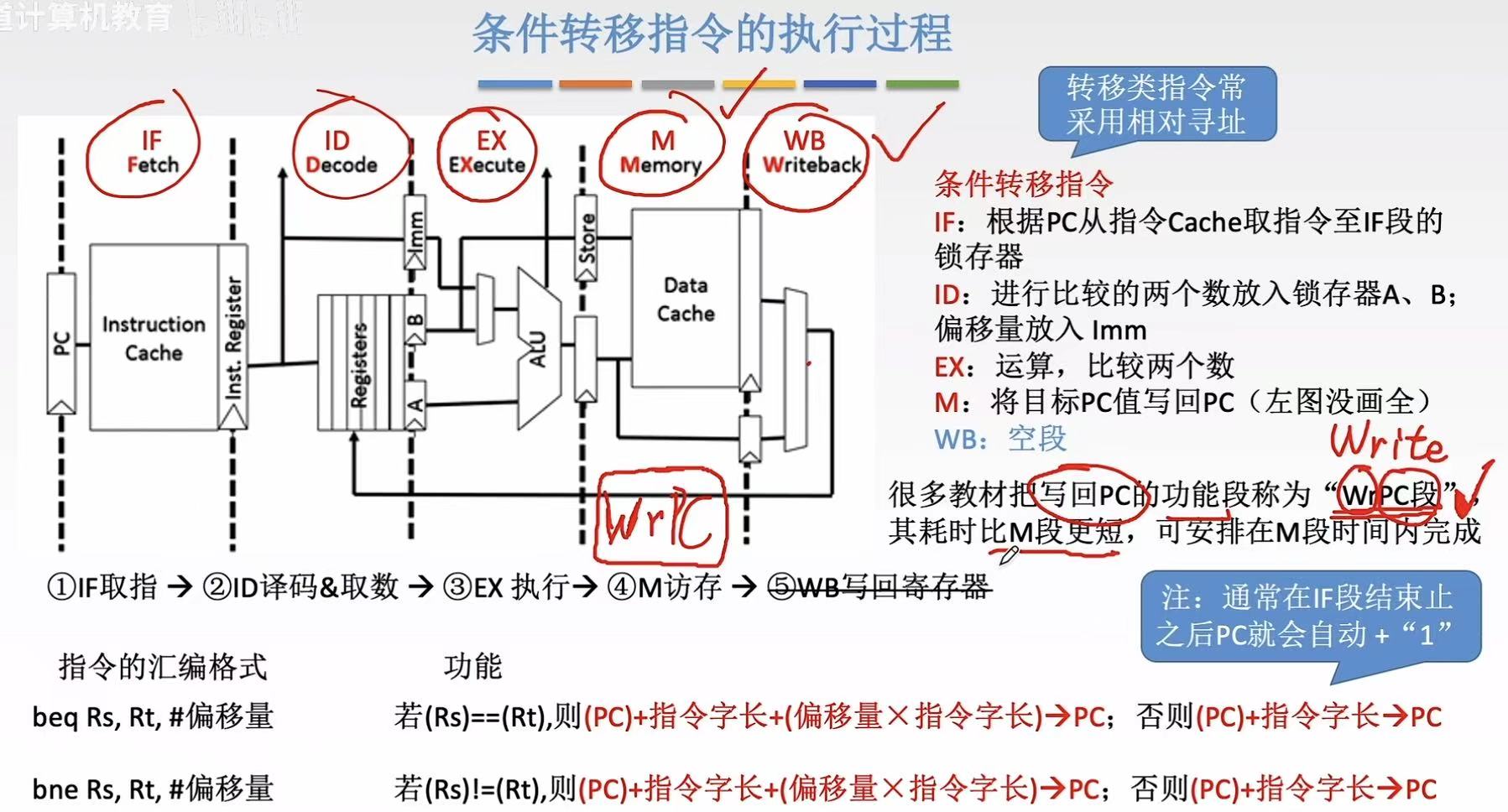
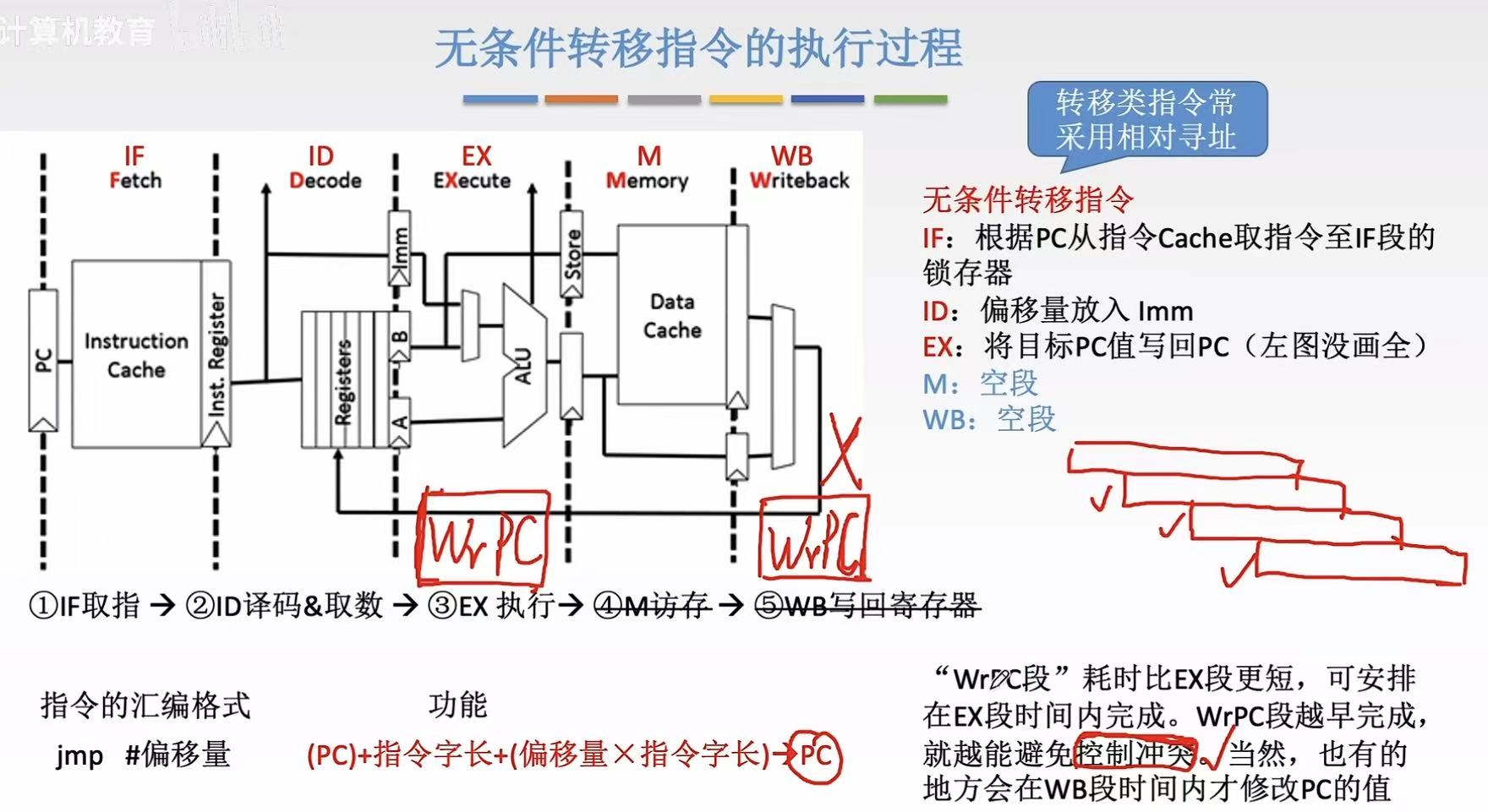
2.5 无条件转移指令
无条件转移指令:就是改变PC值
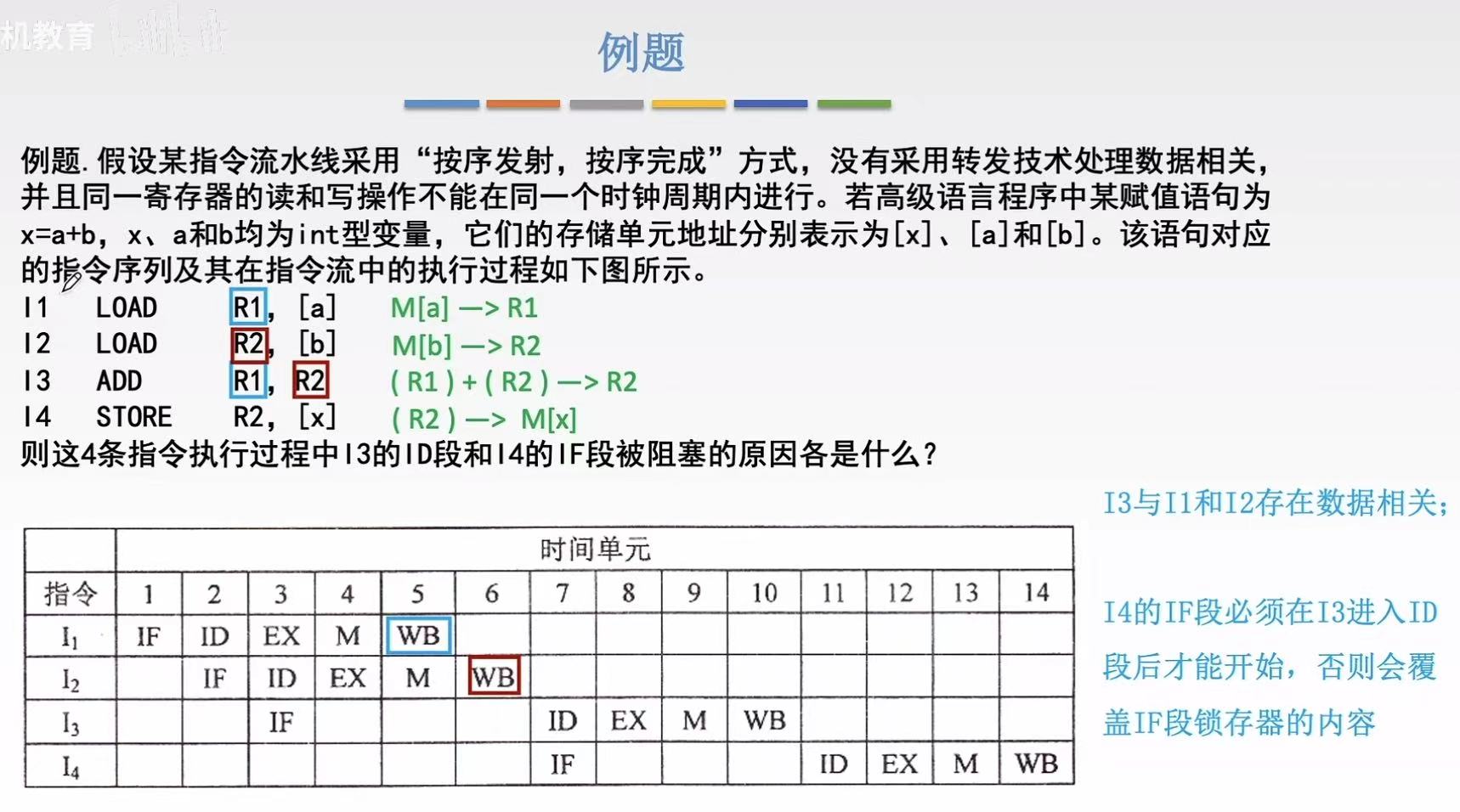
3. 例题
多处理器(概念)
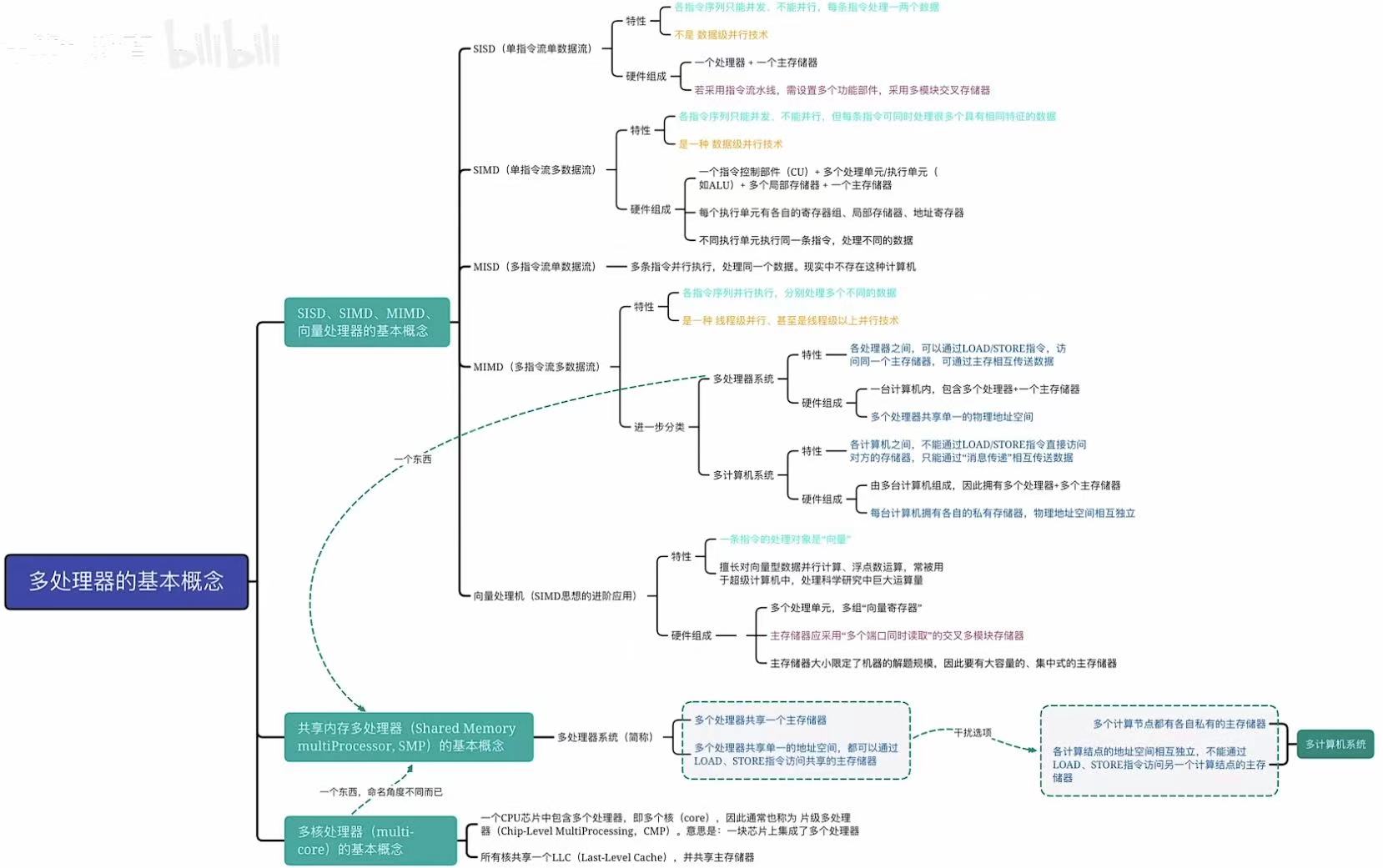
1. 各种概念
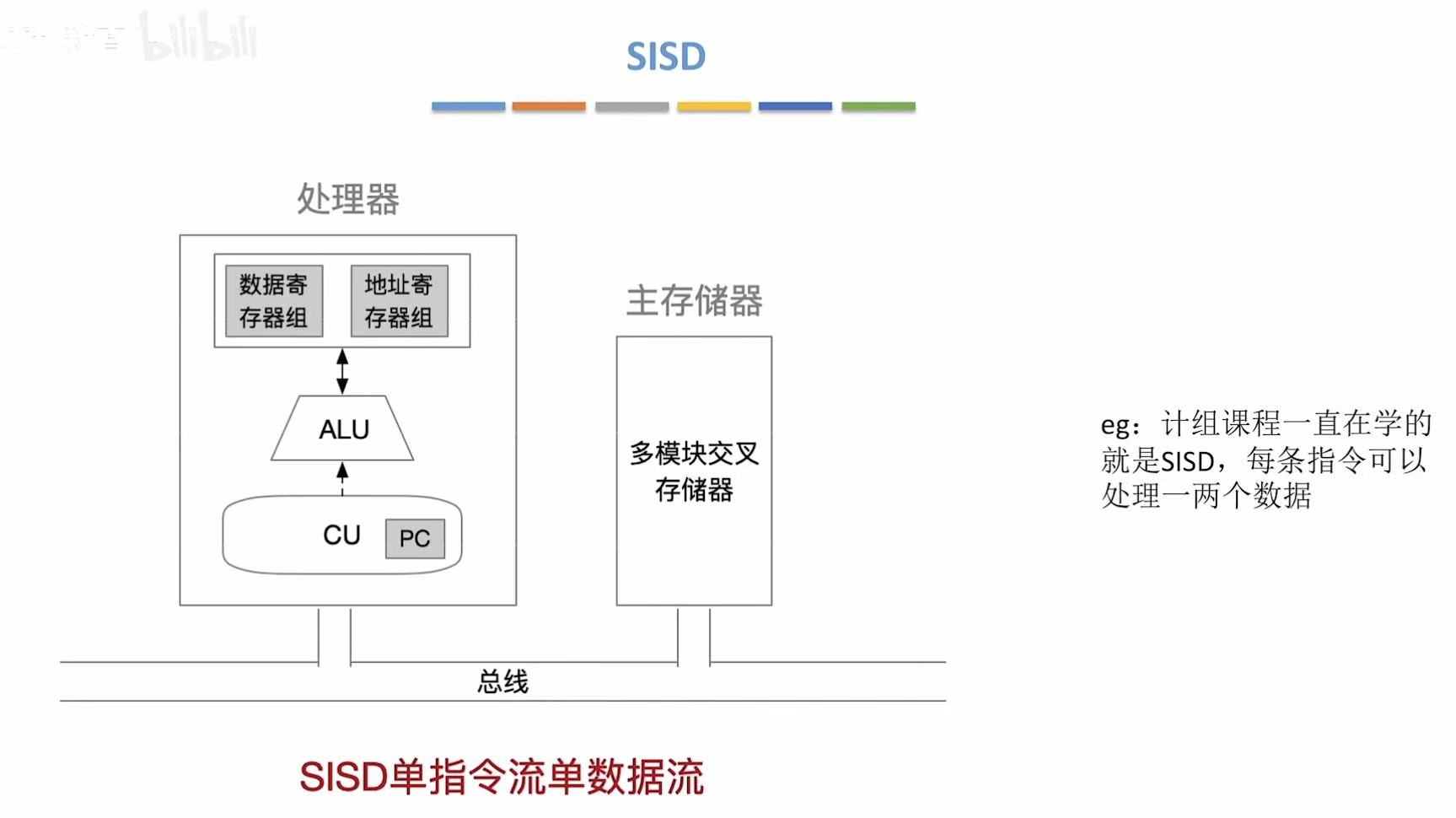
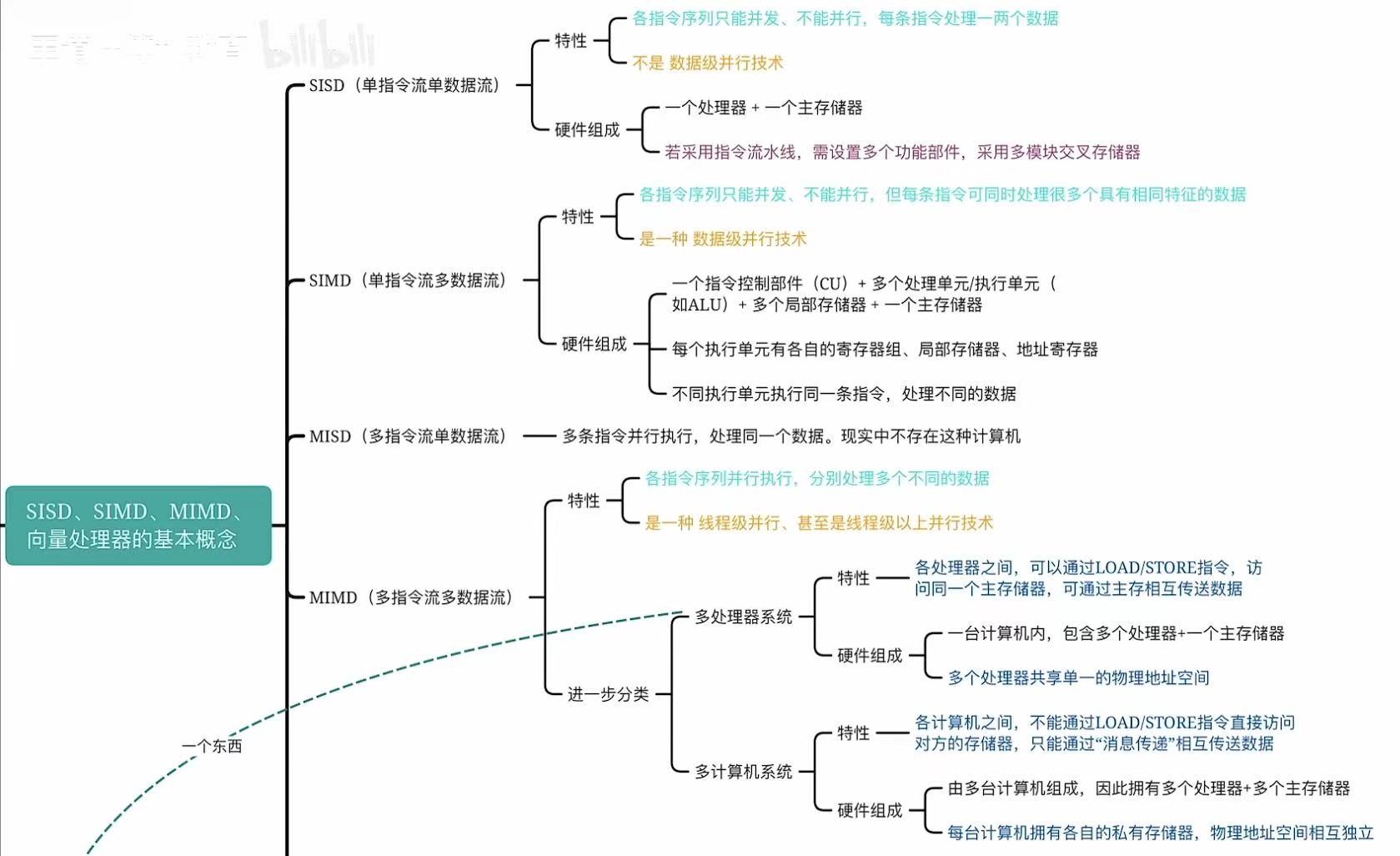
1.1 SISD
- 类比 :一个厨师做一道菜
只有一个灶台(ALU)
每次只处理一个食材(数据)
按菜谱一步步做(顺序执行) - 特点 :
无并行(但可有流水线)
所有传统单核处理器(如早期 Intel 8086) - 现实意义 :现代 CPU 虽多核,但每个核内部对单线程仍是 SISD 行为。

1.2 SIMD
- 类比 :一个指挥家指挥合唱团
指挥喊"唱 C 音!" → 所有人同时唱 C
一条指令,多个数据同时执行相同操作 - 技术实现 :
向量寄存器(如 AVX-512:512 位,可存 16 个 float)
GPU 的 warp 执行(32 线程同指令) - 典型应用 :
图像处理(每个像素做相同滤镜)
科学计算(向量加法:Ai + Bi)
AI 推理(矩阵乘法)

1.3 MISD
- 类比 :一份病历被多个医生独立诊断
同一个病人(数据)
医生 A 开药方,医生 B 做手术,医生 C 做理疗(不同指令) - 现实系统?
几乎没有纯 MISD 系统
容错系统可能接近:同一数据经多条路径处理以校验结果
流水线有时被误认为 MISD,但其实不是(同一指令流分阶段) - 结论 :主要是理论模型,工程中罕见

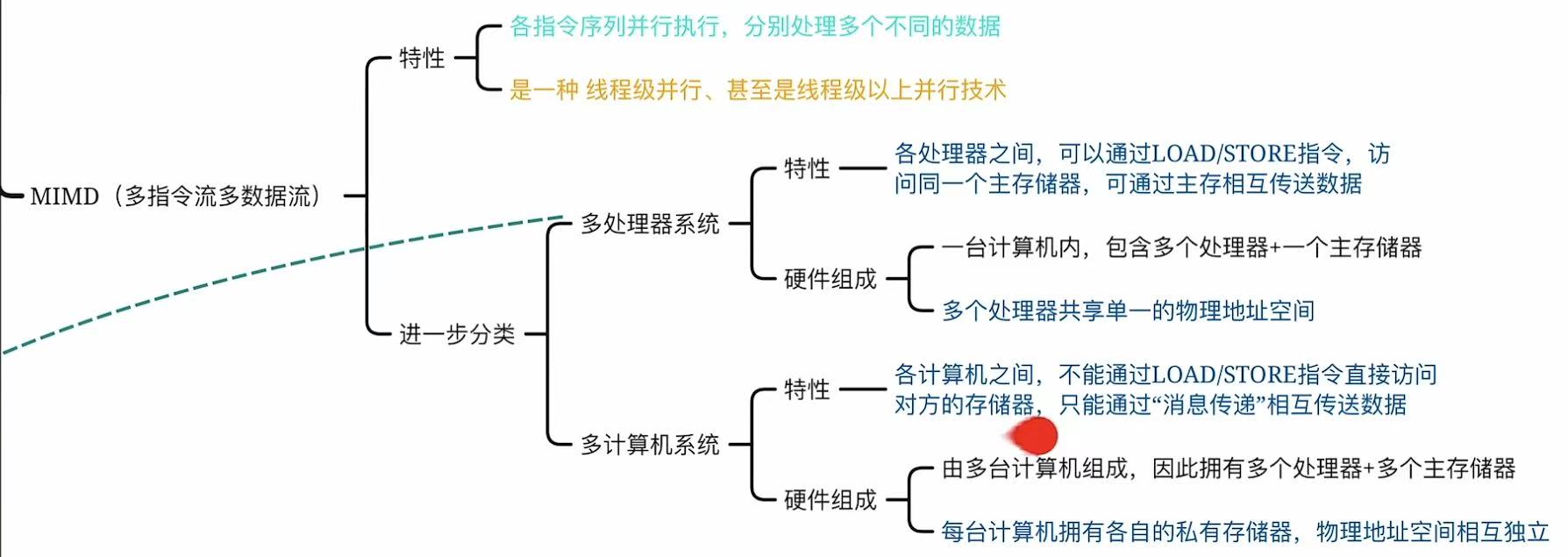
1.4 MIMD
- 类比 :一家餐厅有多个厨师,各自做不同菜
厨师 A 做牛排,厨师 B 做沙拉(不同指令)
用不同食材(不同数据) - 特点 :
完全异步、独立
可运行不同程序 - 子类型 :
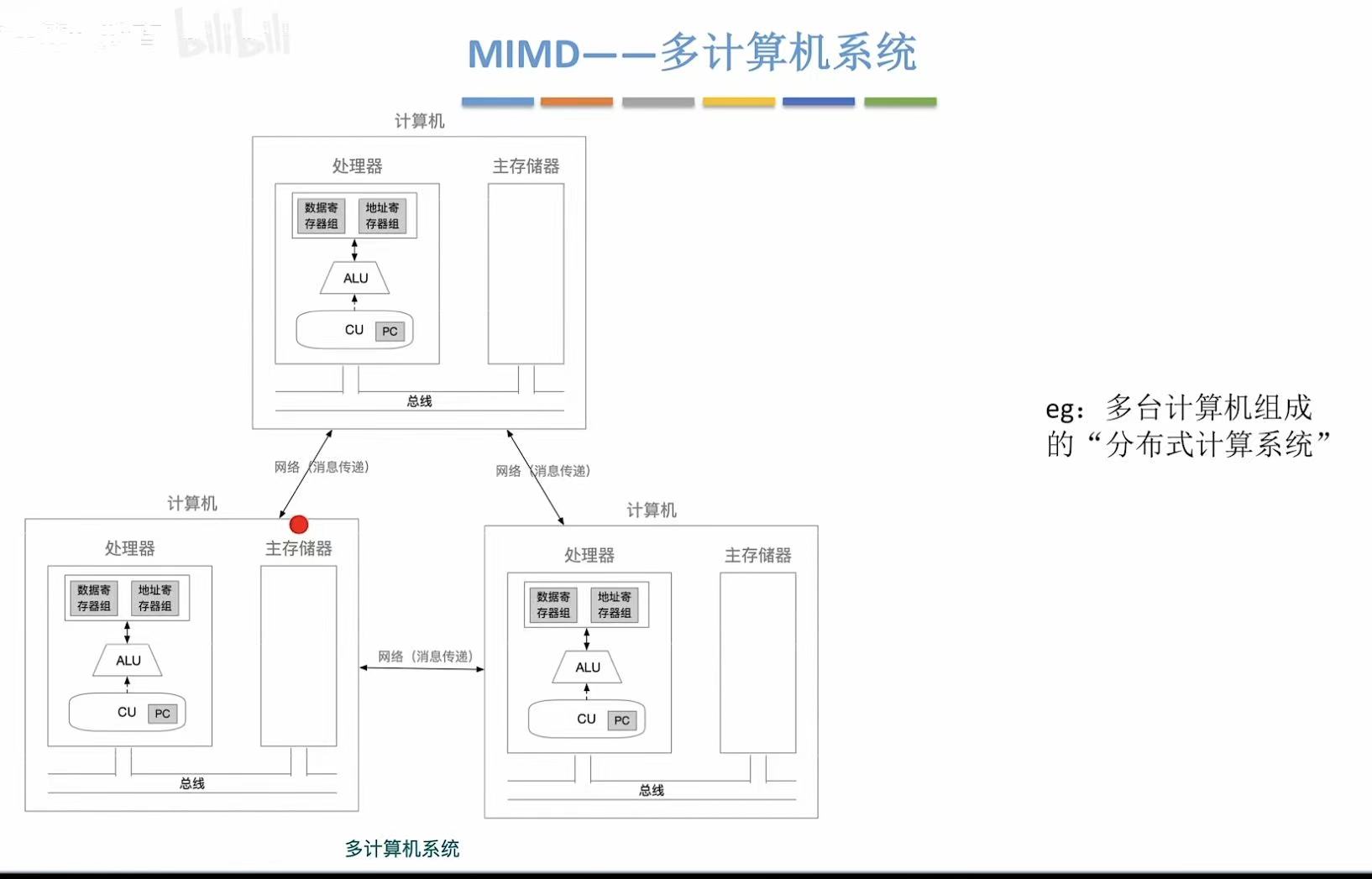
共享内存 MIMD:所有 CPU 访问同一内存(如多核 CPU)
分布式内存 MIMD:每个 CPU 有私有内存(如集群)
1.5 概念-小结
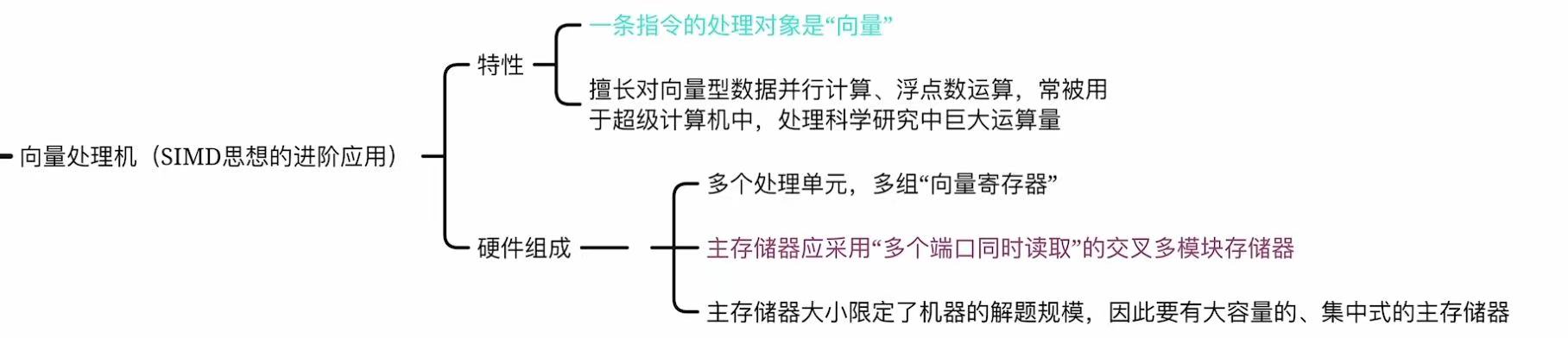
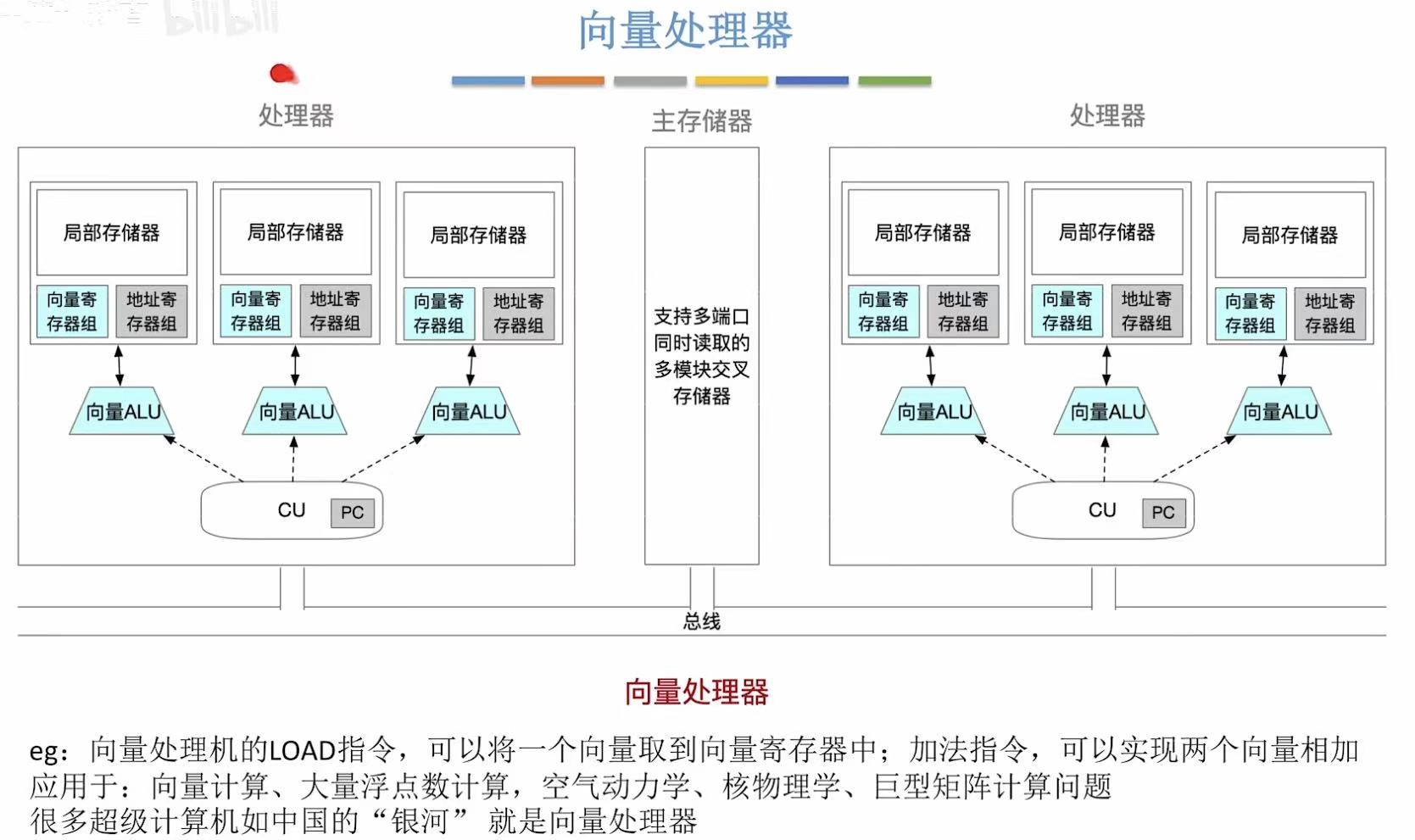
2. 向量处理器
SIMD 的专用硬件
- 本质:高性能 SIMD 实现
- 类比 :工厂流水线专做"批量相同操作"
一次处理 64 个浮点数 - 代表 :
Cray-1(1970s 超级计算机)
现代 GPU 的 SIMT(Single Instruction, Multiple Thread)是其变种 - vs 普通 SIMD :向量机有更深的流水线、专用向量寄存器、支持向量长度可变
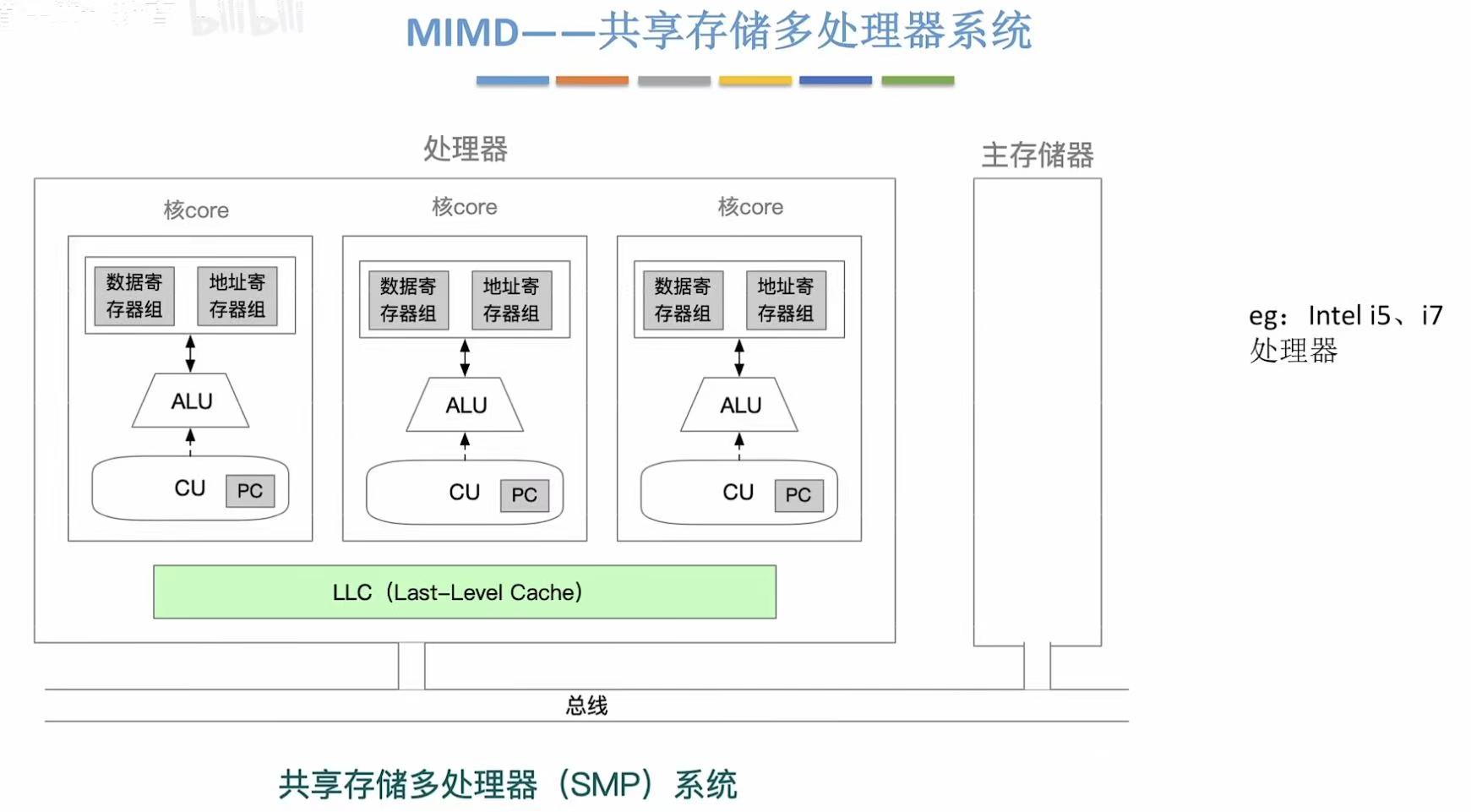
3. 共享内存多处理器&多核处理器
共享内存多处理机(SMP)------ MIMD 的一种
- 架构:
多个 CPU 核心
共享同一物理内存(通过总线或互连网络)
每个核可运行不同程序 - 类比:办公室多人共用一个文件柜(内存)
多核处理机(Multicore Processor)------ 现代主流 MIMD
- 本质:将多个 CPU 核集成在一个芯片上
- 内存模型 :
通常采用 共享内存 MIMD
每个核有私有 L1/L2 缓存,共享 L3 和主存 - 类比 :一栋楼里多个独立厨房,共用食材仓库

4. 小结
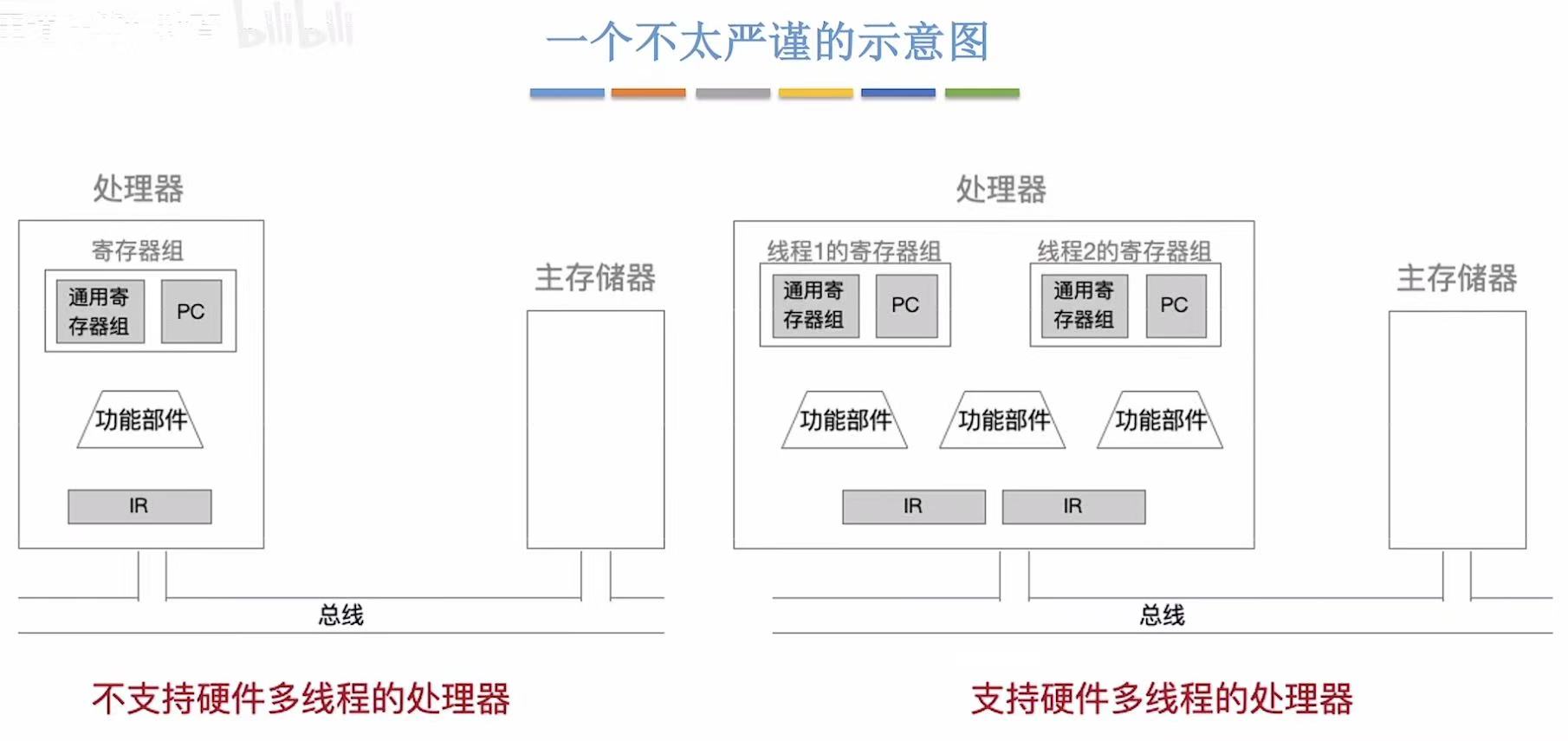
硬件多线程(概念)
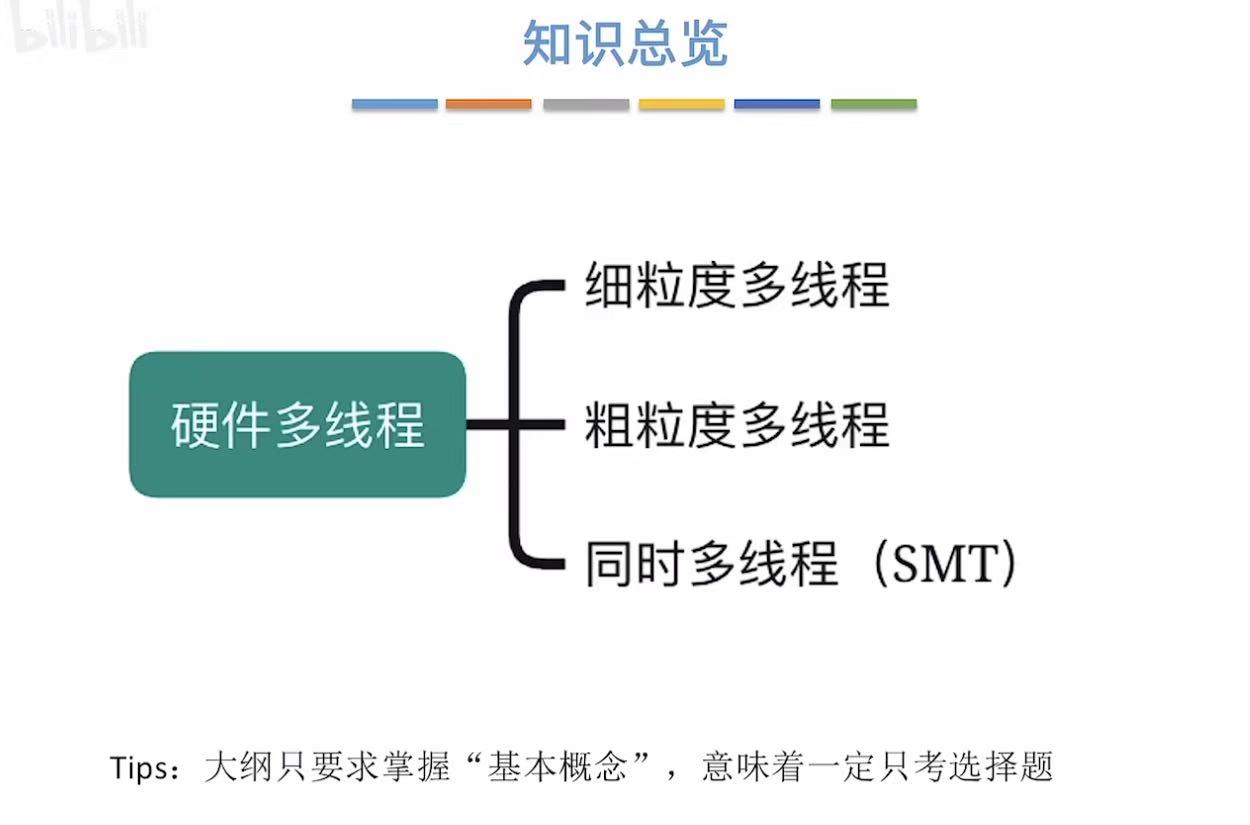
-
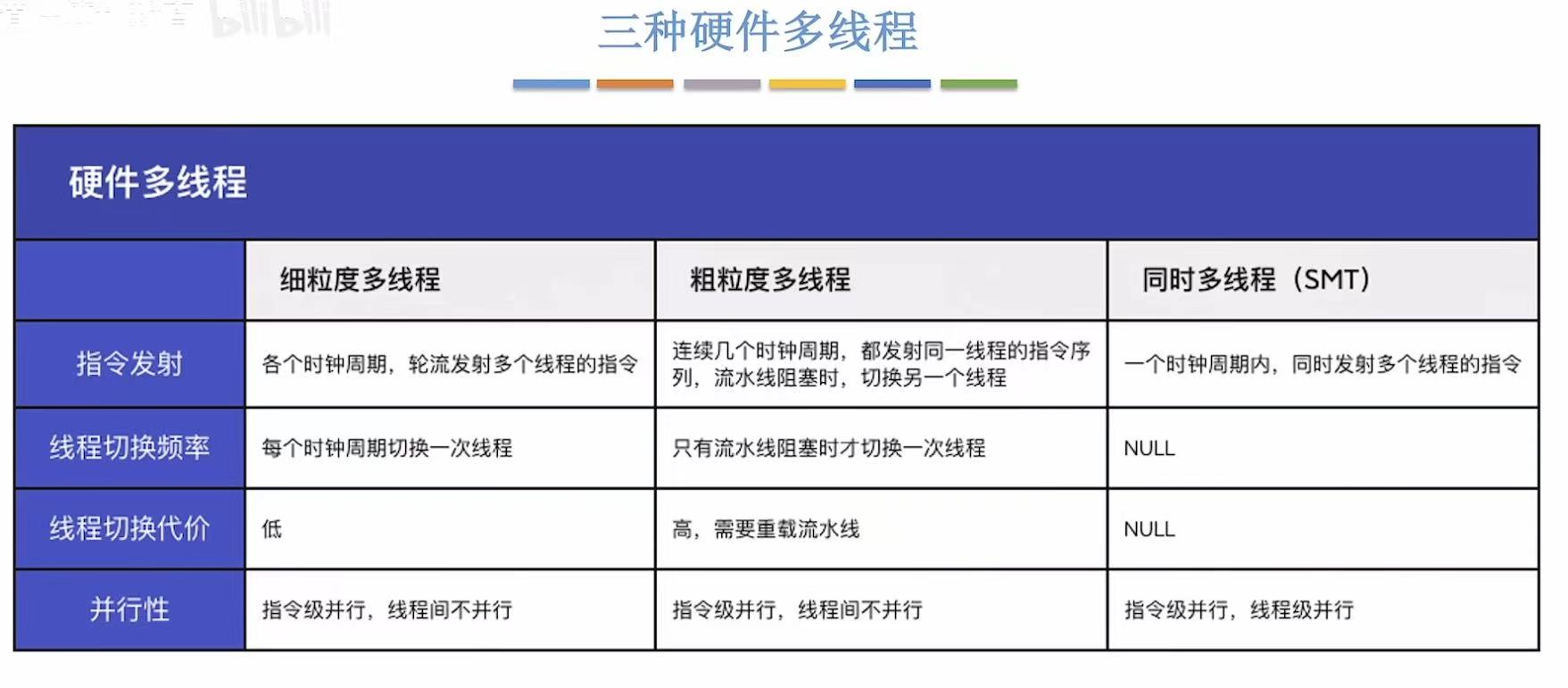
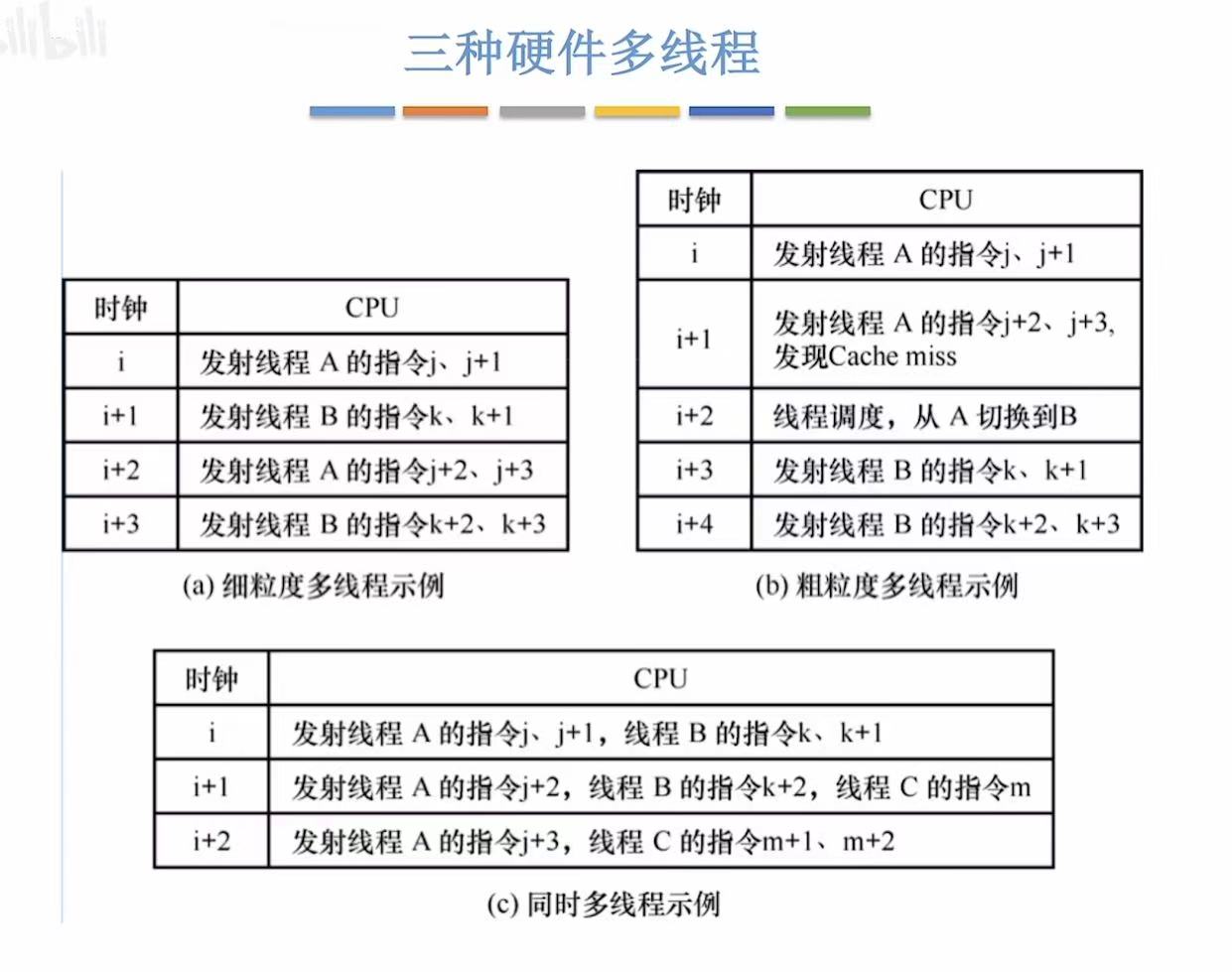
细粒度多线程 (Fine-Grained Multithreading)
🔹 类比 :餐厅里的"快速换桌"服务
想象一个厨师正在炒菜(A 线程)
但需要等油烧热 → 这段时间空闲
此时服务员立刻把另一个顾客的菜(B 线程)端过来,让厨师炒
油热了,再切回 A 线程
切换频率高,每次只切几秒
✅ 特点 :
频繁切换(每条指令后或每个周期)
上下文切换开销小(只需保存少量状态)
依赖流水线停顿触发切换
可以隐藏长延迟(如内存访问)
⚠️ 缺点 :
调度复杂
可能造成资源争抢(如 ALU、寄存器)
实际中较少单独使用
-
粗粒度多线程 (Coarse-Grained Multithreading)
🔹 类比 :电影放映厅换片
电影 A 放到一半卡住了(比如加载下一场景)
放映员不等它,直接换上电影 B 开始播放
等电影 A 加载好了,再切回来
切换间隔大(可能几十秒甚至几分钟)
✅ 特点 :
切换频率低,通常在遇到长延迟(如 cache miss)时才切换
上下文切换开销大,但可以容忍
更适合处理突发性阻塞任务
⚠️ 缺点 :
如果线程很快完成,会浪费机会
不能有效利用短暂停顿
-
同时多线程 (SMT, Simultaneous Multithreading)
🔹 类比 :双人厨房并行工作
厨师 A 和 B 同时在一个厨房里做饭
一个负责切菜(读数据),一个负责炒菜(执行)
他们共享炉灶、刀具、调料
同一时间,两个线程都在运行,互不干扰
✅ 特点 :
真正意义上的并发:多个线程在同一周期内并行执行