整体项目架构采用单项目多模块的模式
(此模式的构建思路见单项目多模块的大数据项目框架构建-CSDN博客)
技术栈:scala+sparkRDD+sparkDataSet
主要使用RDD的目的在于了解学习底层RDD的实现逻辑和api使用
在企业级的结构化数据开发中一般使用sparksql或者sparkdataframe
gitee仓库地址:https://gitee.com/sawa0725/data-ware-house
一、工具类准备
1、环境准备
Spar环境初始化的工具类Env
放在父项目的Common模块下,因为spark环境很多项目都要用到,所以放在公共的模块下,一些只有这个项目用的环境可以放在本模块的Common下
Scala
//spark环境准备工具类,用来获取SparkContext和SparkSession
package com.dw.common.utils
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
trait Env {
def getSparkContext(appName: String = "AppName", master: String = "local[*]"): SparkContext = {
val conf: SparkConf = new SparkConf().setMaster(master).setAppName(appName)
new SparkContext(conf)
}
def getSparkSession(appName: String = "AppName", master: String = "local[*]"): SparkSession = {
SparkSession.builder().master(master).appName(appName).getOrCreate()
}
}局部线程封装EnvUtil类
构建EnvUtil类,这个EnvUtil对象是Spark 环境的工具类
核心作用是统一管理SparkContext和SparkSession的线程局部实例
避免多线程场景下的资源冲突,同时提供便捷的获取、设置、清理方法
目录位置同上
Scala
package com.dw.common.utils
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
object EnvUtil {
private val scLocal = new ThreadLocal[SparkContext]
private val sparkLocal = new ThreadLocal[SparkSession]
def getSc: SparkContext = {
scLocal.get()
}
def setSc(sc:SparkContext): Unit = {
scLocal.set(sc)
}
def clearSc(): Unit = {
scLocal.remove()
}
def clearSession(): Unit = {
sparkLocal.remove()
}
def getSession: SparkSession = {
sparkLocal.get()
}
def setSession(sc: SparkSession): Unit = {
sparkLocal.set(sc)
}
}这两步就可以完成我们spark环境的准备,只要在主方法中with Env就可以获取特质中的方法
实现代码样例:
Scala
private val sc: SparkContext = getSparkContext() //调用特质中的方法获取SparkContext
private val spark: SparkSession = getSparkSession() //调用特质中的方法获取SparkSession
EnvUtil.setSc(sc) //将获取到的SparkContext放到局部线程中去
EnvUtil.setSession(spark) //将获取到的SparkSession放到局部线程中去Dao层(业务数据访问)
这里主要是读取本地文件,其他项目可以增加hadoop文件读取等功能
Scala
//业务数据访问
package com.dw.maap.job.dao
import com.dw.common.utils.EnvUtil
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapreduce.InputSplit
import org.apache.hadoop.mapreduce.lib.input.{FileSplit, TextInputFormat}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.{NewHadoopRDD, RDD}
import org.apache.spark.sql.{DataFrame, SparkSession}
class Dao {
private val sc: SparkContext = EnvUtil.getSc
private val spark: SparkSession = EnvUtil.getSession
def hadoopFile(path: String): RDD[String] = {
val value: RDD[String] = sc.newAPIHadoopFile[LongWritable, Text, TextInputFormat](path)
.asInstanceOf[NewHadoopRDD[LongWritable, Text]]
.mapPartitionsWithInputSplit(
(inputSplit: InputSplit, iterator: Iterator[(LongWritable, Text)]) => {
val file = inputSplit.asInstanceOf[FileSplit]
val fileName = file.getPath.getName
iterator.map(line => {
line._2.toString + fileName
})
})
value
}
def rddRead(path: String): RDD[String] = {
sc.textFile(path)
}
def sessionRead(path: String): DataFrame = {
val frame: DataFrame = spark.read.load(path)
frame
}
def rddReadWhole(path: String): RDD[(String,String)] = {
sc.wholeTextFiles(path)
}
}重点解析这段代码
Scala
def hadoopFile(path: String): RDD[String] = {
//基于 Spark 的 Hadoop API 读取文件,并在每行数据后拼接文件名
//newAPIHadoopFile:Spark 调用 Hadoop 新 API 读取文件的核心方法,泛型参数说明:
//LongWritable:Hadoop 文件的行号(键类型);
//Text:Hadoop 文件的行内容(值类型,对应每行字符串);
//TextInputFormat:Hadoop 的文本文件输入格式(默认按行读取) ,此处未使用
val value: RDD[String] = sc.newAPIHadoopFile[LongWritable, Text, TextInputFormat](path)
.asInstanceOf[NewHadoopRDD[LongWritable, Text]] //类型转换为 NewHadoopRDD,普通RDD没有mapPartitionsWithInputSplit方法,必须强转为NewHadoopRDD才能获取InputSplit(文件分片信息),文件分片信息中有文件名
.mapPartitionsWithInputSplit(
(inputSplit: InputSplit, iterator: Iterator[(LongWritable, Text)]) => {
val file = inputSplit.asInstanceOf[FileSplit] //将通用分片转为FileSplit(文件分片),才能获取文件路径 / 名称
val fileName = file.getPath.getName
iterator.map(line => {
line._2.toString + fileName
})
})
value
}entity:业务实体类
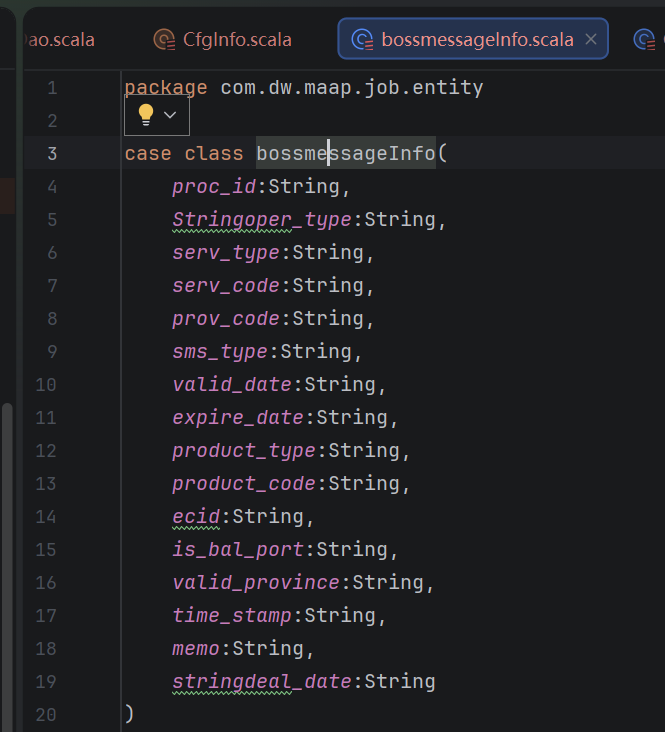
样例类(Case Class),封装业务数据结构(如MaapInfo)
用于 Dataset 类型安全操作,封装从文件中读取的rdd的值类型
这块的代码需要的可以从代码仓获取

二、业务流程
1、应用起点ApplicationAnalysis
只做拉起进程和环境配置
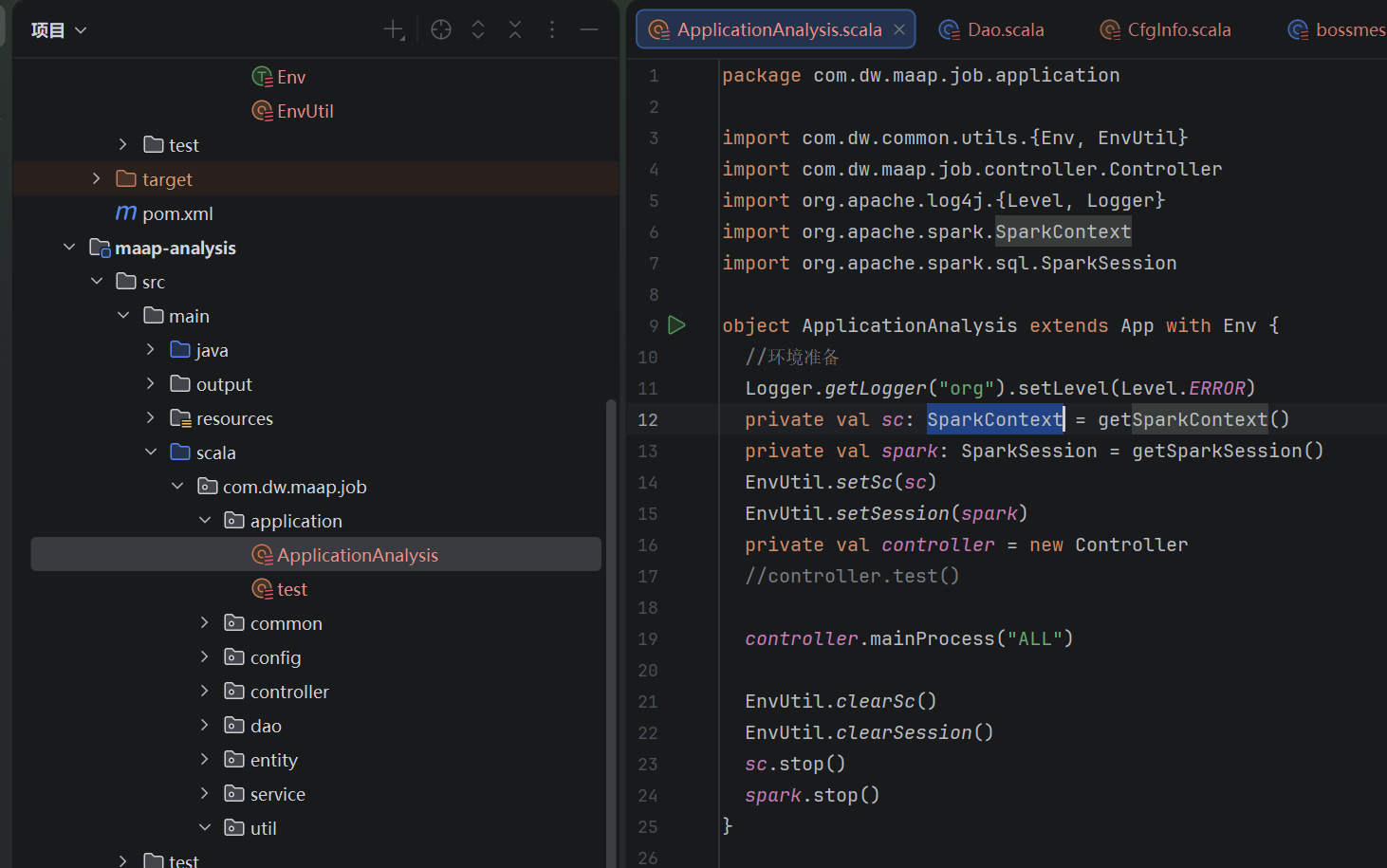
Scala
package com.dw.maap.job.application
import com.dw.common.utils.{Env, EnvUtil}
import com.dw.maap.job.controller.Controller
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
object ApplicationAnalysis extends App with Env {
//环境准备
Logger.getLogger("org").setLevel(Level.ERROR)
//核心作用是:将 org 包下所有类的日志输出级别设置为 ERROR,仅打印错误级别的日志,屏蔽 INFO/WARN/DEBUG 等低级别日志
private val sc: SparkContext = getSparkContext()
private val spark: SparkSession = getSparkSession()
EnvUtil.setSc(sc)
EnvUtil.setSession(spark)
private val controller = new Controller //
//controller.test()
controller.mainProcess("ALL")
EnvUtil.clearSc()
EnvUtil.clearSession()
sc.stop()
spark.stop()
}2、流程控制Controller
用来做大致的流程控制,只是将整体业务流程分为几个业务模块,然后按序进行
第一块整体流程控制包括判断参数是否正确等
第二块局数据加载,分号段H1H2H3局数据和bossmessage局数据
第三块逻辑处理,也分maap局数据和bsms局数据(这里会将加载的局数据作为入参输入)最后会将临时试图汇总为报表打印出来
Scala
一共四个函数
mainProcess
cfgDataLoad(两个业务调用同一个数据加载类的不同函数)
maapProcess
BsmsProcess流程控制代码
Scala
package com.dw.maap.job.controller
import com.dw.maap.job.config.CfgInfo.{bsmsTable, maapTable}
import com.dw.maap.job.entity.{BsmsInfo, H1H2H3, MaapInfo, bossmessageInfo}
import com.dw.maap.job.service.{BsmsAnalysisService, MaapAnalysisService, dataLoad, Statistics}
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
class Controller {
private val maapService = new MaapAnalysisService
private val loadService = new dataLoad
private val bsmsAnalysisService = new BsmsAnalysisService
private val statistics = new Statistics
var bossmessage: RDD[bossmessageInfo] = null
var H1H2H3: RDD[H1H2H3] = null
//主进程
def mainProcess(serviceType: String): Unit = {
if (List("BSMS", "MAAP", "ALL") contains serviceType.toUpperCase) {
cfgDataLoad() //加载局数据(配置数据)
//然后根据参数不同执行业务进程(参数类型:ALL、MAAP、BSMS)
if (serviceType.toUpperCase == "ALL") {
maapProcess()
BsmsProcess()
}
else if (serviceType.toUpperCase == "MAAP") maapProcess()
else if (serviceType.toUpperCase == "BSMS") BsmsProcess()
} else println("请输入正确的业务类型:ALL、MAAP、BSMS")
}
def cfgDataLoad(): Unit = {
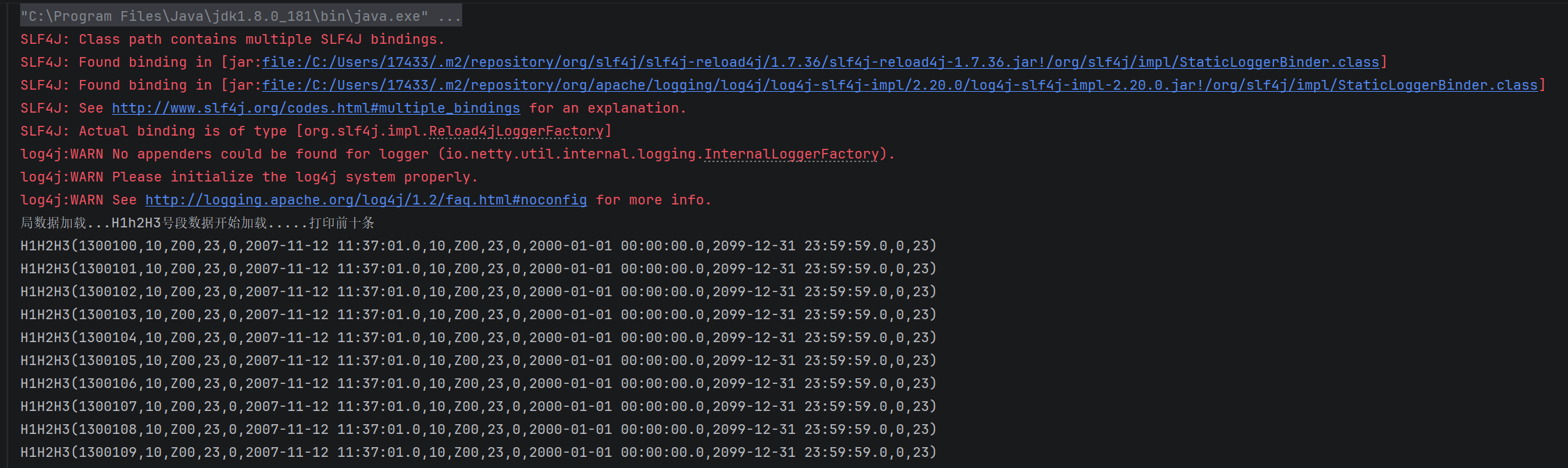
println("局数据加载...H1h2H3号段数据开始加载.....打印前十条")
H1H2H3 = loadService.H1H2H3Load().persist(StorageLevel.MEMORY_AND_DISK)
//persist 是 Scala/Spark 中核心的缓存 API
//主要用于持久化 RDD/DataFrame/Dataset 到内存 / 磁盘,避免重复计算,提升性能
H1H2H3.take(10).foreach(println)
println("局数据加载...bossmessage端口局数据开始加载.....打印前十条")
bossmessage = loadService.bossMessageLoad().persist(StorageLevel.MEMORY_AND_DISK)
bossmessage.take(10).foreach(println)
}
def maapProcess(): Unit = {
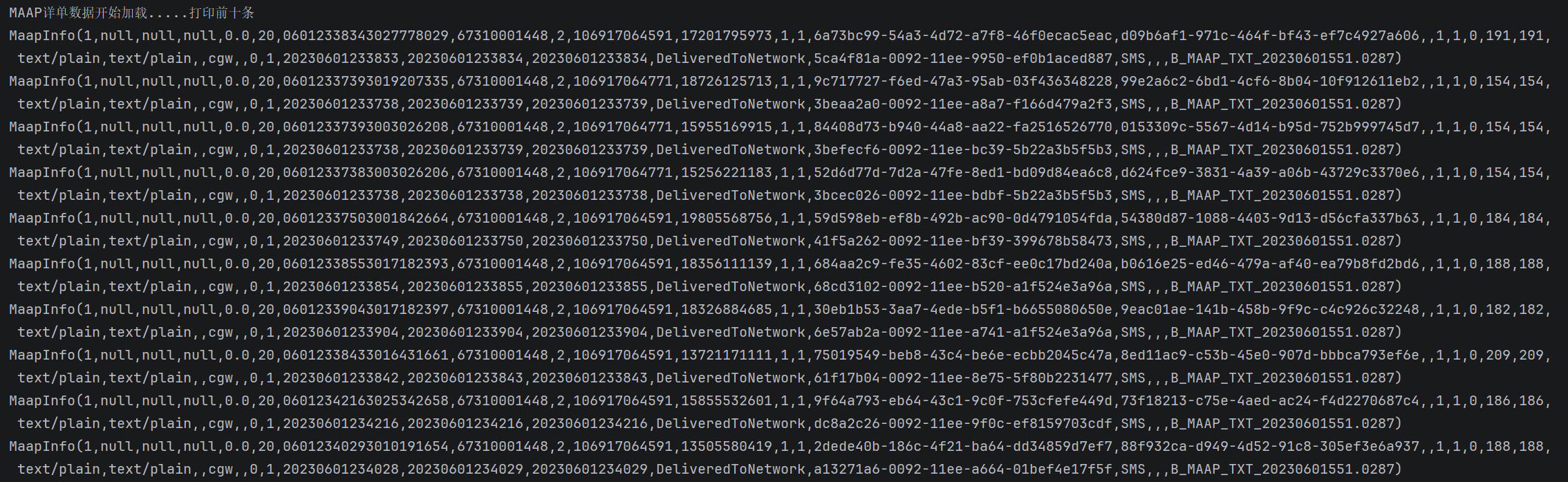
println("MAAP详单数据开始加载.....打印前十条")
val cdrRdd: RDD[MaapInfo] = loadService.maapCdrFileLoad()
cdrRdd.take(10).foreach(println)
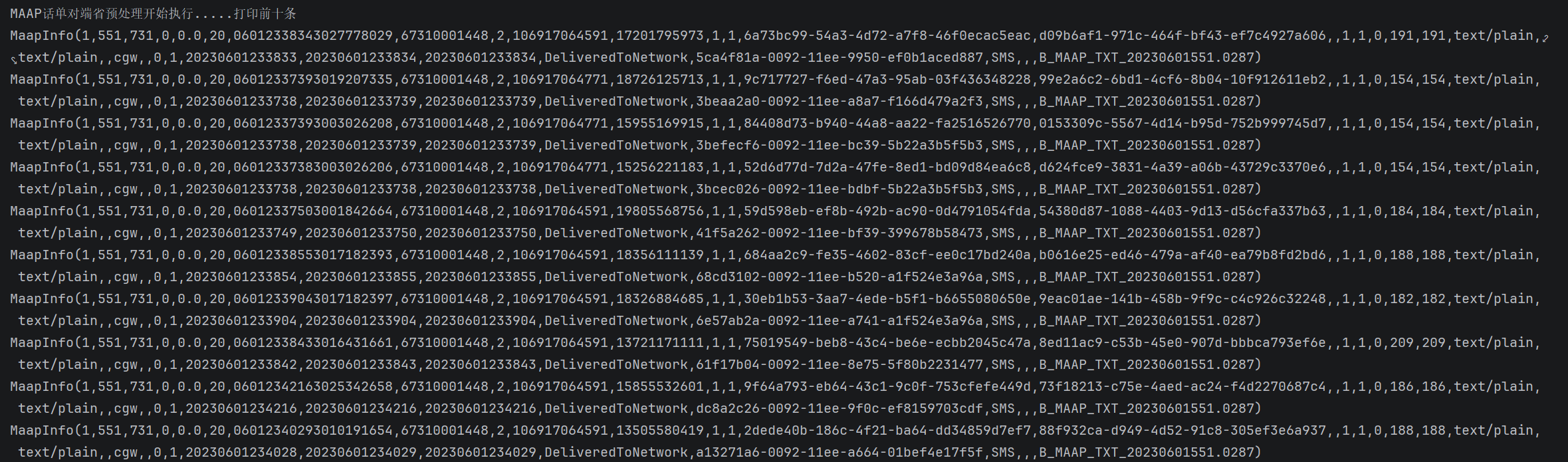
println("MAAP话单对端省预处理开始执行.....打印前十条")
val maapResult: RDD[MaapInfo] = maapService.maapCdrPreServerCode(bossmessage, cdrRdd)
maapResult.take(10).foreach(println)
println("MAAP话单归属地预处理开始执行.....打印前十条")
val maapCdr: RDD[MaapInfo] = maapService.maapCdrPreH1H2H3(maapResult, H1H2H3).cache()
maapCdr.take(10).foreach(println)
println("##############################################")
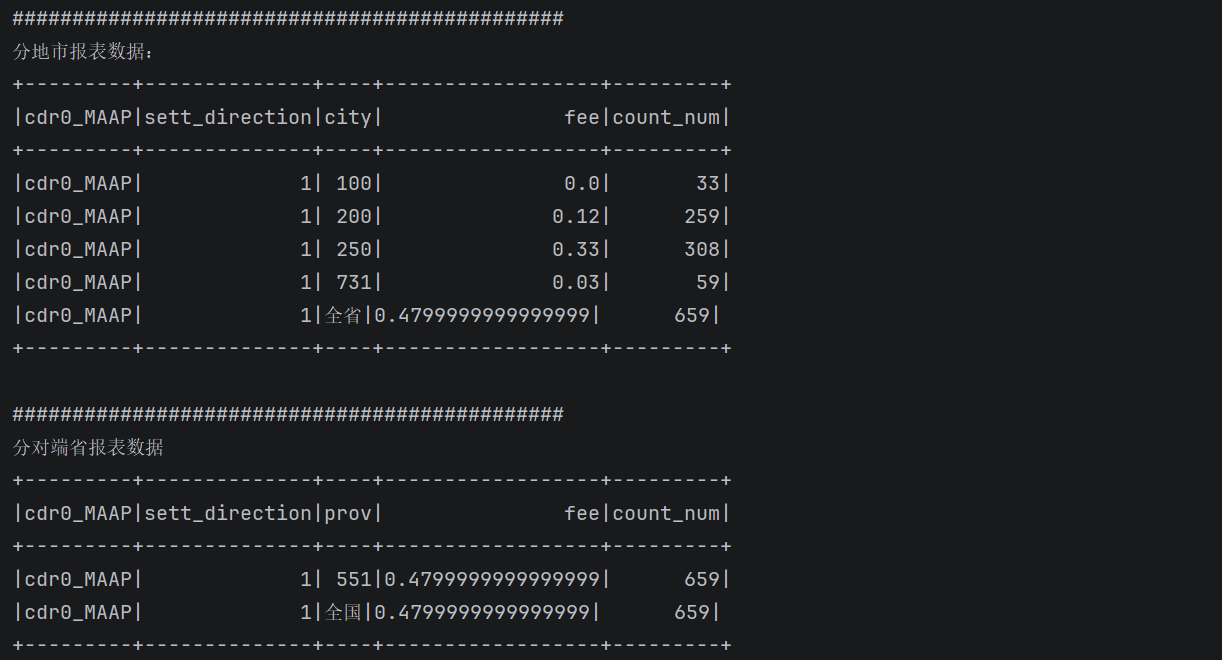
println("分地市报表数据:")
statistics.statisticsCity(maapTable)
println("##############################################")
println("分对端省报表数据")
statistics.statisticsProv(maapTable)
}
private def BsmsProcess(): Unit = {
println("BSMS详单数据开始加载.....打印前十条")
val cdrRdd: RDD[BsmsInfo] = loadService.bsmsCdrFileLoad().persist(StorageLevel.MEMORY_AND_DISK)
cdrRdd.take(10).foreach(println)
//需要先端口预处理打标端口是否生效标识
println("BSMS话单端口预处理开始执行.....打印前十条")
val bsmsResult: RDD[BsmsInfo] = bsmsAnalysisService.bsmsCdrPreServerCode(bossmessage, cdrRdd).persist(StorageLevel.MEMORY_AND_DISK)
bsmsResult.take(100).foreach(println)
println("BSMS话单手机号码预处理开始执行.....打印前十条")
val bsmsCdr: RDD[BsmsInfo] = bsmsAnalysisService.bsmsCdrPreH1H2H3(H1H2H3, bsmsResult).persist(StorageLevel.MEMORY_AND_DISK)
bsmsCdr.take(100).foreach(println)
println("##############################################")
println("分地市报表数据:")
statistics.statisticsCity(bsmsTable)
println("##############################################")
println("分对端省报表数据")
statistics.statisticsProv(bsmsTable)
}
}3、数据加载类dataLoad
功能:加载局数据和明细数据加载,在Controller中调用
(主要是将文件里的数据关联实体类,然后输出成DataSet的临时试图)
Scala
package com.dw.maap.job.service
import com.dw.common.utils.EnvUtil
import com.dw.maap.job.config.CfgInfo.{H1H2H3FileName, H1H2H3Path, bBsmsTxtFileName, bBsmsTxtPath, bMaapTxtFileName, bMaapTxtPath, bossmessageinfoFilename, bossmessageinfoPath, bsmsHead10String, bsmsTable, bsmsTail10String, bsmsTxtFileName, bsmsTxtPath, dd_bossmessageinfo, dd_h1h2h3_code_allocate, maapHead10String, maapTable, maapTail10String, maapTxtFileName, maapTxtPath}
import com.dw.maap.job.entity.{BsmsInfo, H1H2H3, MaapInfo, bossmessageInfo}
import com.dw.maap.job.dao.Dao
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Dataset, SparkSession}
class dataLoad {
private val spark: SparkSession = EnvUtil.getSession
private val sc: SparkContext = EnvUtil.getSc
private val dao = new Dao
import spark.implicits._
//导入SparkSession的隐式转换(包含toDS/toDF等方法),必须在SparkSession创建之后
def bossMessageLoad(): RDD[bossmessageInfo] = {
val bossmessageRdd: RDD[bossmessageInfo] = dao.rddRead(bossmessageinfoPath + bossmessageinfoFilename)
.map(_.split("\\u0001"))
.map(data => {
bossmessageInfo(
data(0), data(1), data(2), data(3), data(4), data(5), data(6), data(7), data(8), data(9), data(10), data(11), data(12), data(13), data(14), data(15)
)
})
val bossmessageSet: Dataset[bossmessageInfo] = bossmessageRdd.toDS()
bossmessageSet.createOrReplaceTempView(dd_bossmessageinfo)
bossmessageRdd
}
def H1H2H3Load(): RDD[H1H2H3] = {
val H1H2H3Rdd: RDD[H1H2H3] = dao.rddRead(H1H2H3Path + H1H2H3FileName)
.map(_.split("\\u0001"))
.map(data => {
H1H2H3(
data(0).trim,
data(1).trim,
data(2).trim,
data(3).trim,
data(4).trim,
data(5).trim,
data(6).trim,
data(7).trim,
data(8).trim,
data(9).trim,
data(10).trim,
data(11).trim,
data(12).trim,
data(13).trim
)
})
val H1H2H3Set: Dataset[H1H2H3] = H1H2H3Rdd.toDS()
H1H2H3Set.createOrReplaceTempView(dd_h1h2h3_code_allocate)
H1H2H3Rdd
}
def maapCdrFileLoad(): RDD[MaapInfo] = {
val maapRdd: RDD[String] = dao.hadoopFile(bMaapTxtPath + bMaapTxtFileName + "*" + "," + maapTxtPath + maapTxtFileName + "*")
val filHead: RDD[String] = maapRdd.filter(_.substring(0, 10) != maapHead10String)
val filHeadTail: RDD[String] = filHead.filter(_.substring(0, 10) != maapTail10String)
val maapInfo: RDD[MaapInfo] = filHeadTail.map(data => {
MaapInfo(
if (data.substring(1174).startsWith(bMaapTxtFileName)) 1
else if (data.substring(1174).startsWith(maapTxtFileName)) 0
else {
-1
},
null,
null,
null,
0.00,
data.substring(0, 2).trim,
data.substring(2, 22).trim,
data.substring(22, 54).trim,
data.substring(54, 56).trim,
data.substring(56, 184).split(":")(1).split("@")(0),
data.substring(184, 312).split("\\+86")(1).trim,
data.substring(312, 314).trim,
data.substring(314, 316).trim,
data.substring(316, 352).trim,
data.substring(352, 388).trim,
data.substring(388, 424).trim,
data.substring(424, 426).trim,
data.substring(426, 428).trim,
data.substring(428, 429).trim,
data.substring(429, 443).trim,
data.substring(443, 457).trim,
data.substring(457, 521).trim,
data.substring(521, 585).trim,
data.substring(585, 649).trim,
data.substring(649, 777).trim,
data.substring(777, 905).trim,
data.substring(905, 907).trim,
data.substring(907, 909).trim,
data.substring(909, 924).trim,
data.substring(924, 939).trim,
data.substring(939, 954).trim,
data.substring(954, 974).trim,
data.substring(974, 1034).trim,
data.substring(1034, 1054).trim,
data.substring(1054, 1114).trim,
data.substring(1114, 1174).trim,
data.substring(1174)
)
})
val maapSet: Dataset[MaapInfo] = {
maapInfo.toDS()
}
maapSet.createOrReplaceTempView(maapTable)
maapInfo
}
def bsmsCdrFileLoad(): RDD[BsmsInfo] ={
val bsmsRdd: RDD[String] = dao.hadoopFile(bBsmsTxtPath + bBsmsTxtFileName + "," + bsmsTxtPath + bsmsTxtFileName)
val filHead: RDD[String] = bsmsRdd.filter(_.substring(0, 10) != bsmsHead10String)
val filHeadTail: RDD[String] = filHead.filter(_.substring(0, 10) != bsmsTail10String)
val bsmsInfo: RDD[BsmsInfo] = filHeadTail.map(data => {
BsmsInfo(
if (data.substring(198).substring(12,15)=="551") 1
else if (data.substring(198).substring(16,19)=="551") 0
else -1,
null,
null,
null,
0.00,
data.substring(0, 2).trim,
data.substring(2, 22).trim,
data.substring(22, 24).trim,
data.substring(24, 25).trim,
data.substring(25, 40).trim,
data.substring(40, 58).trim,
data.substring(58, 70).trim,
data.substring(70, 85).trim,
data.substring(85, 106).trim,
data.substring(106, 116).trim,
data.substring(116, 123).trim,
data.substring(123, 124).trim,
data.substring(124, 127).trim,
data.substring(127, 133).trim,
data.substring(133, 139).trim,
data.substring(139, 150).trim,
data.substring(150, 164).trim,
data.substring(164, 178).trim,
data.substring(178, 198).trim,
data.substring(198)
)
})
val bsmsSet: Dataset[BsmsInfo] = bsmsInfo.toDS()
bsmsSet.createOrReplaceTempView(bsmsTable)
bsmsInfo
}
}三、业务逻辑开发
在Controller中调用,实现具体的业务逻辑
两个核心业务BSMS(BsmsProcess)和MAAP(maapProcess),核心逻辑类似
MAAP两个核心逻辑
maapCdrPreH1H2H3
maapCdrPreServerCode
BAMS两个核心逻辑
bsmsCdrPreH1H2H3
bsmsCdrPreServerCode
这里就重点拿MAAP进行详细解析
1、maapCdrPreH1H2H3
功能:
入参为maap话单和H1H2H3(号段局数据)
根据号段匹配H1H2H3号段分辨是哪个城市的号码
2、maapCdrPreServerCode
1>匹配局数据的端口号,找到归属的省份(最长匹配原则,明细数据中的端口号匹配局数据中的端口号,如果有一样长的就匹配一样长的,例如123匹配123,如果123在局数据中没有,就匹配1234,没有1234就匹配12345)
核心为先对号段长度进行排序,然后进行双重遍历的时候对第二层也就是端口的遍历增加一层breakable,这样在下面的遍历操作中优先匹配最短的号段,匹配到之后就跳出当前循环,跳出后,程序会回到外层messageInfos循环,继续处理下一个messageInfos元素;这样就实现了 匹配到serv_code后,处理完逻辑就跳过剩余的serverCodeInfo遍历的需求。
2>批价,根据短信类型以及对应的短信单价
Scala
package com.dw.maap.job.service
// 导入SparkSession的隐式转换(包含toDS/toDF等方法)
import com.dw.common.utils.EnvUtil
import com.dw.maap.job.config.CfgInfo._
import com.dw.maap.job.dao.Dao
import com.dw.maap.job.entity.{H1H2H3, MaapInfo, bossmessageInfo}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import scala.util.control.Breaks.breakable
case class MaapAnalysisService() {
private val dao = new Dao
private val spark: SparkSession = EnvUtil.getSession
private val sc: SparkContext = EnvUtil.getSc
import spark.implicits._
//导入SparkSession的隐式转换(包含toDS/toDF等方法),必须在SparkSession创建之后
def maapCdrPreH1H2H3(maapInfo: RDD[MaapInfo], H1H2H3: RDD[H1H2H3]): RDD[MaapInfo] = {
val h1h2h3: RDD[(String, String)] = H1H2H3
.map(data =>
(data.h1h2h3h4, data.long_code)
)
val maap: RDD[(String, String)] = maapInfo.map(
data => (
data.reserveuser.substring(0, 7), ""
)
)
val h1h2h3Pre: Array[(String, String)] = h1h2h3.join(maap).map(data => {
(data._1, data._2._1)
}).collect()
val filRdd: RDD[MaapInfo] = maapInfo
.filter(_.is_bal_port != '0') //过滤发送端口失效的话单
val frame: DataFrame = filRdd.map(data => {
for (i <- h1h2h3Pre) {
if (data.sett_direction == 0 && data.reserveuser.substring(0, 7) == i._1) {
data.prov = i._2
data.city = "551"
}
}
data
}
).toDF()
frame.createOrReplaceTempView(maapTable)
val value: Dataset[MaapInfo] = frame.as[MaapInfo]
value.rdd
}
def maapCdrPreServerCode(bossmessage: RDD[bossmessageInfo], maap: RDD[MaapInfo]): RDD[MaapInfo] = {
//业务端口为10657586[开头]并且长度为8位或者12位的按0.045元/条进行结算
//批价
val messageInfo: Array[MaapInfo] = maap.map(data => {
if (data.input_file_name.contains("MAAP_TXT")) {
data.settle_fee = maapTxtPrice * (data.messagelength.toInt / 270) //MAAP_TXT业务,如果短信长度超过270那么费用为短信长度/270 * 短信单价
} else if (data.input_file_name.contains("MAAP_MMA")) {
data.settle_fee = maapMmaPrice
} else if (data.input_file_name.contains("MAAP_CSN")) {
data.settle_fee = maapCsnPrice
}
data
}).collect()
val serverCodeInfo: Array[bossmessageInfo] = bossmessage.sortBy(_.serv_code.length) //根据号段长度排序,优先取最短的号段进行匹配
.collect()
for (messageInfos <- messageInfo) {
breakable {
for (serverCodeInfos <- serverCodeInfo) {
if (messageInfos.senduser.indexOf(serverCodeInfos.serv_code) != -1) {
messageInfos.is_bal_port = serverCodeInfos.is_bal_port
if (messageInfos.sett_direction == 1) {
messageInfos.prov = "551"
messageInfos.city = serverCodeInfos.prov_code
}
}
breakable()
}
}
}
val value: RDD[MaapInfo] = sc.makeRDD(messageInfo)
value.toDS().createOrReplaceTempView(maapTable)
value
}
}四、结果输出
Statistics:功能,将统计后的数据分组求和输出报表打印并写入文件
Scala
package com.dw.maap.job.service
import com.dw.common.utils.EnvUtil
import org.apache.spark.sql.{Dataset, Row, SparkSession}
import java.time.format.DateTimeFormatter
import java.time.{LocalDate, LocalDateTime}
class Statistics {
private val spark: SparkSession = EnvUtil.getSession
val currentDate: LocalDate = LocalDate.now()
val currentDateTime: LocalDateTime = LocalDateTime.now()
val formatter: DateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd-HH-mm-ss")
val formattedDateTime: String = currentDateTime.format(formatter)
def statisticsCity(tableName:String): Unit = {
val value: Dataset[Row] = spark.sql(s"select '$tableName',sett_direction,city,sum(settle_fee) as fee,count(*) as count_num from $tableName group by sett_direction,city " +
"union " +
s"select '$tableName',sett_direction,'全省' as prov,sum(settle_fee) as fee,count(*) as count_num from $tableName group by sett_direction"
).orderBy("city")
value.coalesce(1).write.format("com.databricks.spark.csv").option("header", "true") save(s"maap-analysis/src/main/output/${currentDate}/${formattedDateTime}/{$tableName}_city.csv")
value.show()
}
def statisticsProv(tableName:String): Unit = {
val value: Dataset[Row] = spark.sql(s"select '$tableName',sett_direction,prov,sum(settle_fee) as fee ,count(*) as count_num from $tableName group by sett_direction,prov " +
"union " +
s"select '$tableName',sett_direction,'全国' as prov,sum(settle_fee) as fee,count(*) as count_num from $tableName group by sett_direction").orderBy("prov")
value.coalesce(1).write.format("com.databricks.spark.csv").option("header", "true") save(s"maap-analysis/src/main/output${currentDate}/${formattedDateTime}/{$tableName}_prov.csv")
value.show()
}
}注意,需要读取的数据文件在maap-analysis/src/main/resources中(本文件仅作学习使用,请勿用作他处)
运行结果:
日志后面有bsms短信的结果,模式一致,不进行展示,大家可以亲自动手尝试
五、项目拓展优化方向
当前已经在本地搭建好了hadoop、hive、spark集群,可以优化成从hadop读取文件,然后报表输出到hive表中,模拟企业级开发流程。后面有机会会对这个项目进行改造升级,当前准备从零开始设计一个规范的企业级流程的离线数仓项目,座椅就暂时搁置,后面有时间了再优化项目,可以持续关注~
(搭建全过程见专栏从零开始部署本地大数据集群_是阿威啊的博客-CSDN博客)