目录
- 一、TextIn大模型加速器
- 二、行业报告分析与发展建议
-
- [2.1 场景描述](#2.1 场景描述)
- [2.2 工作流逻辑编排](#2.2 工作流逻辑编排)
- [2.3 大模型提示词](#2.3 大模型提示词)
- [2.4 结果展示](#2.4 结果展示)
- [三、ParseX结合Coze API控制本地机器人](#三、ParseX结合Coze API控制本地机器人)
-
- [3.1 场景描述](#3.1 场景描述)
- [3.2 工作流逻辑编排](#3.2 工作流逻辑编排)
- [3.3 大模型提示词](#3.3 大模型提示词)
- [3.4 地图与任务描述](#3.4 地图与任务描述)
- [3.5 本地调用](#3.5 本地调用)
- [3.6 结果展示](#3.6 结果展示)
一、TextIn大模型加速器
随着大模型技术的快速发展,大量结构化数据需求日益增大,但网络上绝大多数数据都是非结构化的。在大模型处理过程中,数据前处理阶段的结构化程度,对后续阶段的语义理解与逻辑推理能力有着极大地决定作用。
TextIn解析引擎正从应用工具演变为研究基础设施,不仅加速了大模型在文档智能领域的研究进展,更重要的是,它通过提供真实、复杂、多样化的文档处理场景,推动了大模型在多模态理解、复杂推理和专业领域应用等方面的根本性突破。
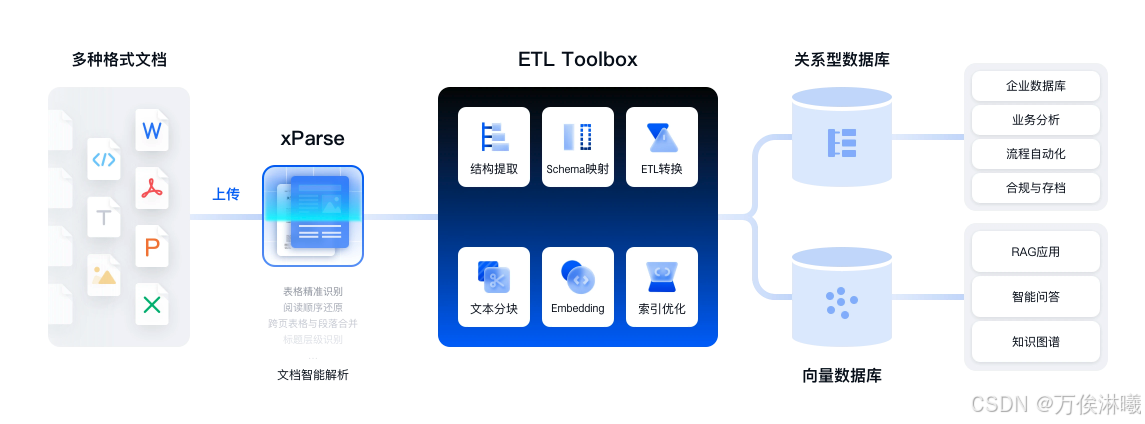
核心优势
- 支持任意复杂布局:将任意版式的文档拆解为语义完整的段落,并按阅读顺序还原,更加适配大模型。
- 多元素高精度解析:准确提取标题、公式、图表、手写体、印章、跨页段落、页眉页脚、表单字段等各种元素,同时具备行业领先的表格识别能力,轻松解决合并单元格、跨页表格、无线表格等识别难题。
- 强大的语义理解和上下文感知:捕捉更多版面元素间的语义关系,让大模型更加读懂一份文档。
- 强大的预处理工具:无缝集成TextIn平台中的图像处理能力,文档带水印、图片有弯曲、模糊,都能搞定。
- 高精度坐标还原:JSON结果包含高精度的页面、元素、字符级坐标数据,方便人工复核。
- 极简、智能、灵活的语义抽取:xParse提供prompt模式和Schema模式两种抽取规则定制,帮助您根据业务需要实现更灵活的文档信息精准提取。
- 开发者友好:提供清晰的API文档和灵活的集成方式,支持FastGPT、Coze、CherryStudio等主流平台。
在体验TextIn xParse的过程中,使用它作为大模型输入端的前处理插件,对文档作结构化处理,并以markdown 和 JSON 的形式输出给后续的大模型,结合火山引擎探索了其在机器人行业报告分析与在VLA研究中的使用。
二、行业报告分析与发展建议
首先是一个比较简单的文档解析工作流,主要是根据提示词对给定文档作定向解析,并根据文档内容给出知道建议。
2.1 场景描述
信息碎片化时代,精准搜索有效信息并梳理总结成为了一件困难的事情,经常大部分时间都花在整理信息上。找到的文献、报告等大多数篇幅很长,人工梳理耗时耗力,有些读下来不是想要的又浪费时间。
所以借助 Coze + TextIn 搭建了一个行业报告分析与发展建议工作流,流程泳道图如下:
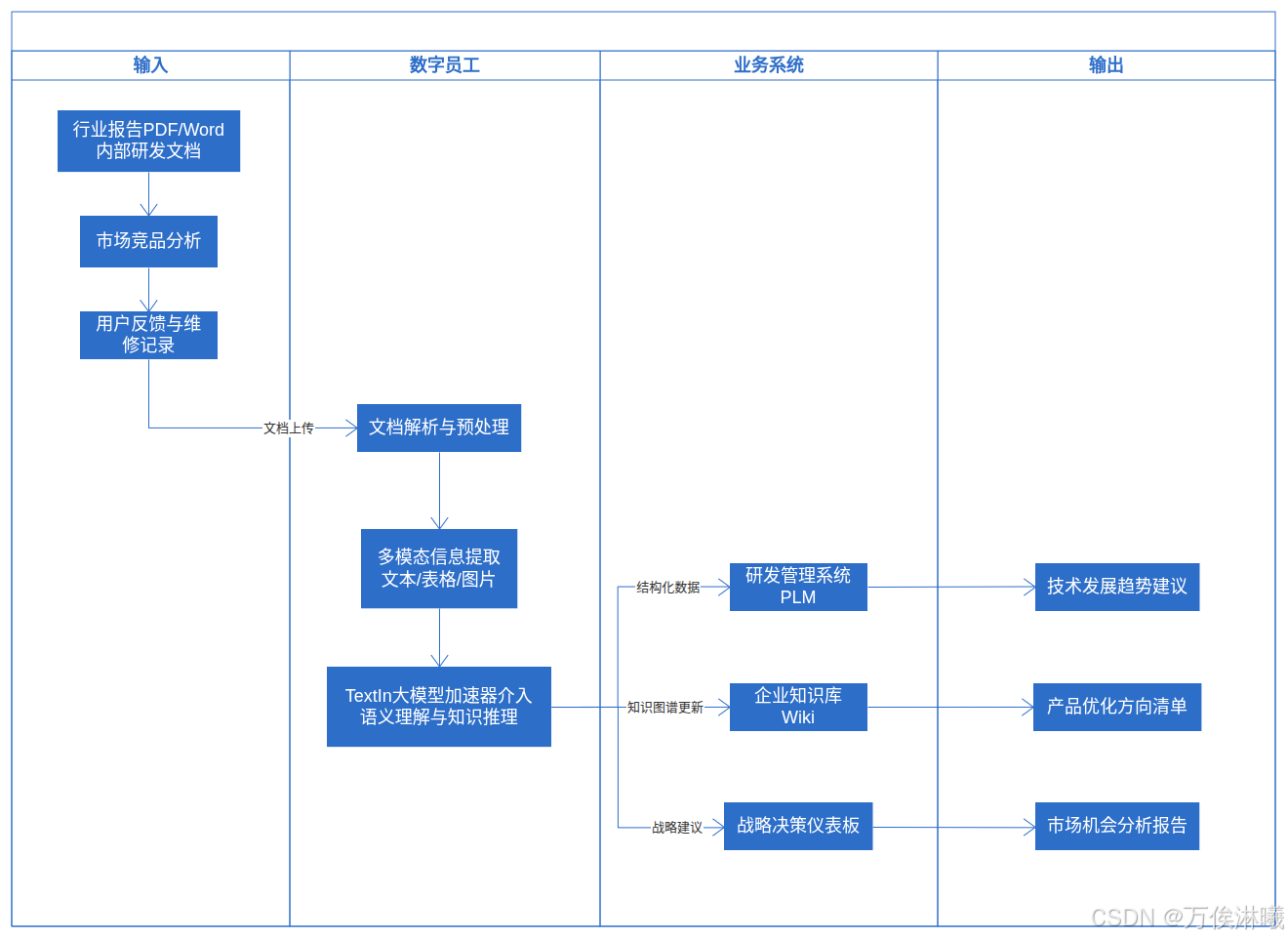
2.2 工作流逻辑编排
由于ParseX插件的加持,整个工作流只需要4个节点即可实现该功能:
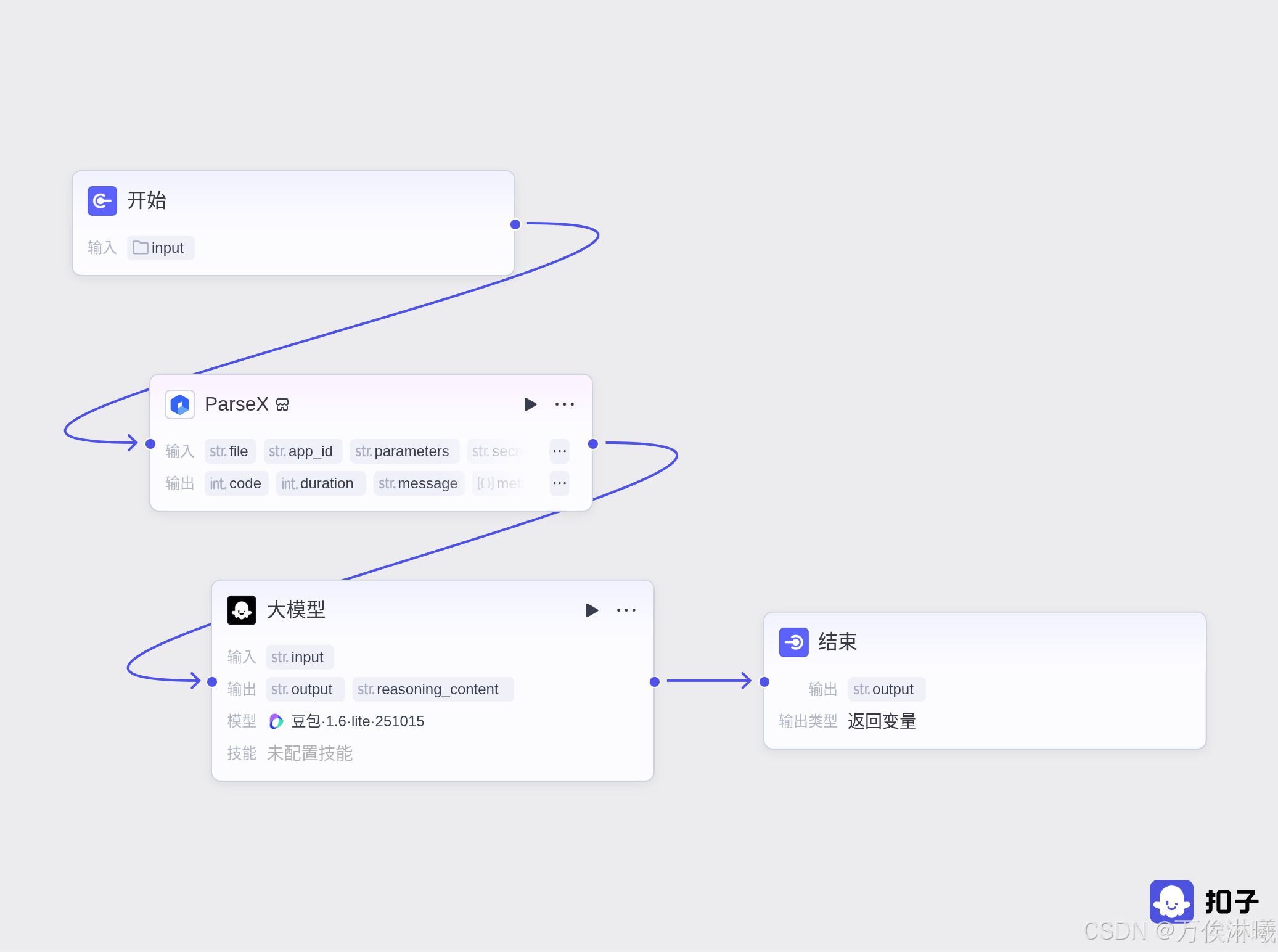
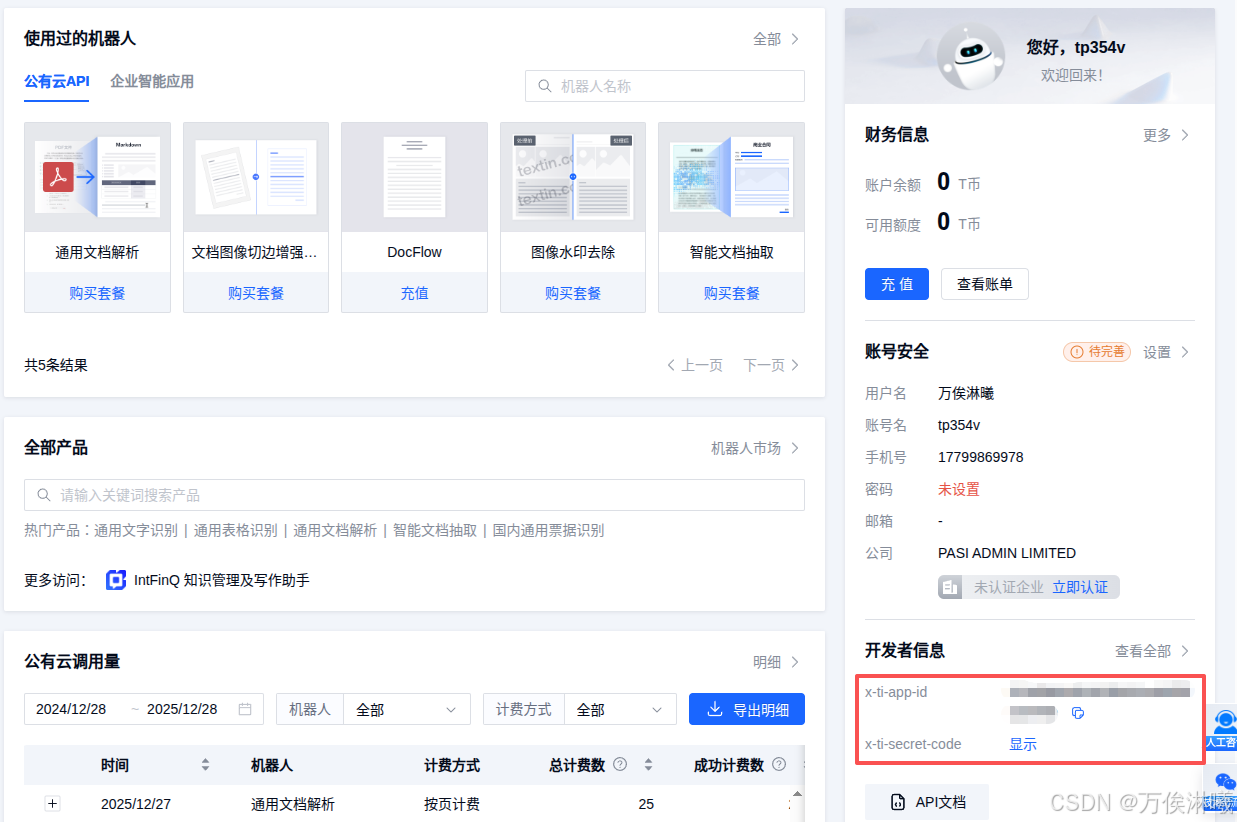
其中,ParseX节点必要输入为文件路径,app_id和secret_code为TextIn的开发者信息与密钥。
这一步,ParseX作为文档解析预处理引擎,对文档内容进行标准化、增强、优化中间表示,结构识别与标记,并进行内容提取与初分类。针对下一步的大模型处理,降低了大模型的计算负担,提升了大模型的准确性。基本理念就是:让大模型专注于它最擅长的语义理解和推理任务,而将繁琐的、模式化的预处理工作交给专门优化的工具完成。
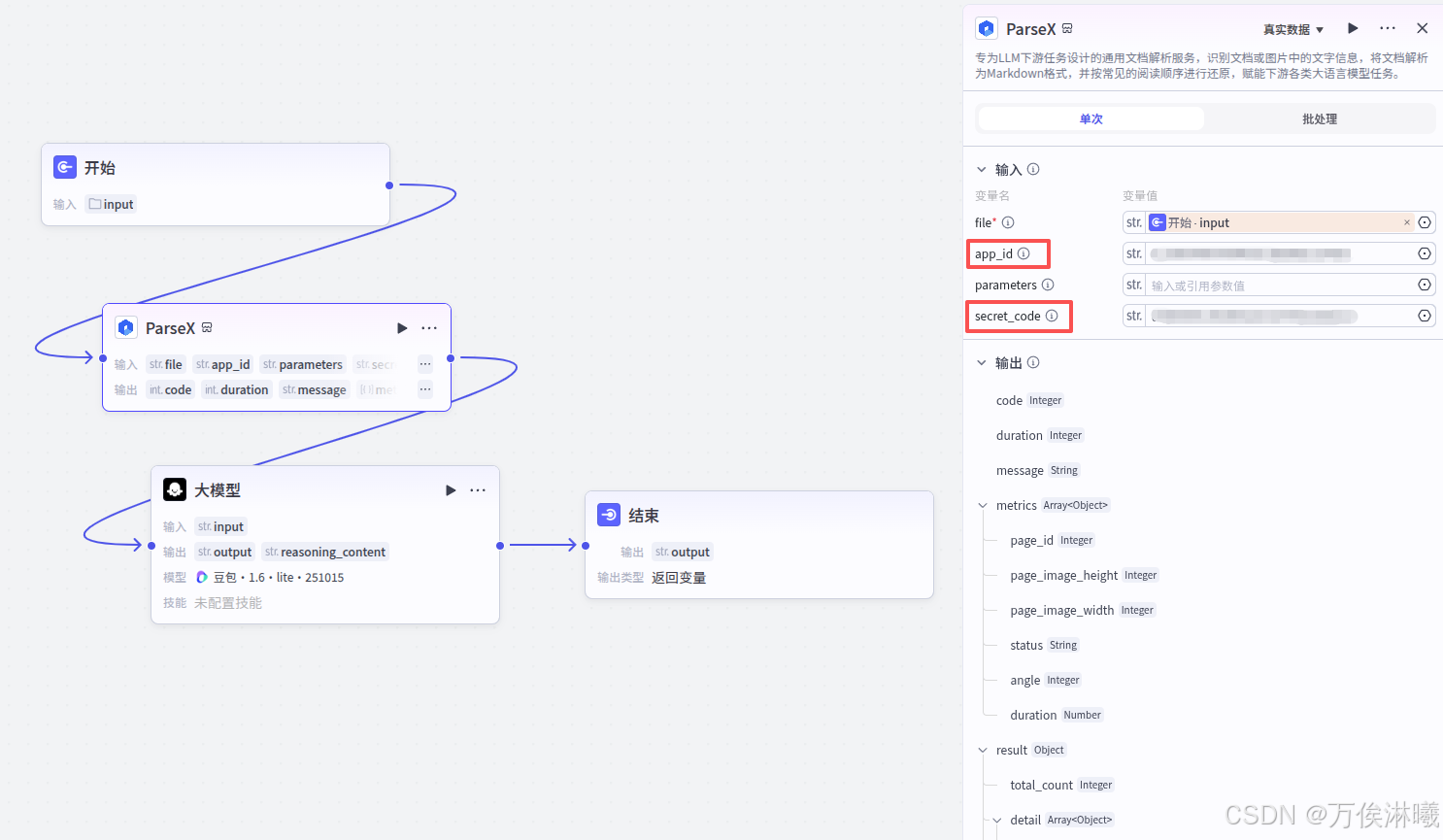
app_id和secret_code对应TextIn工作台页面的x-ti-app-id和x-ti-secret-code。
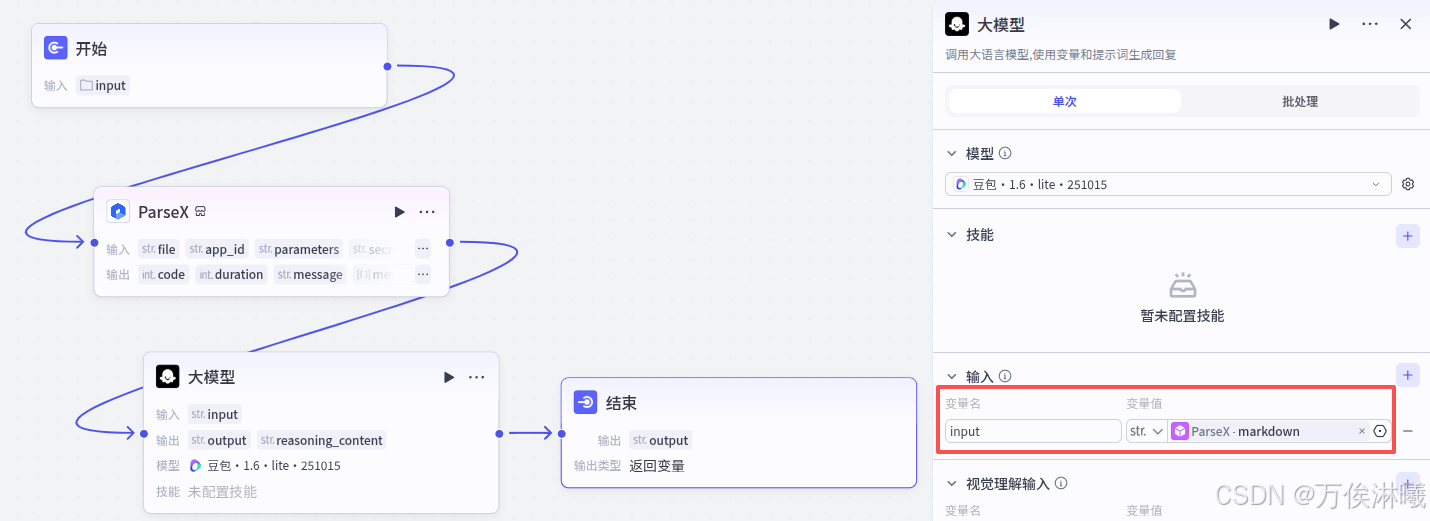
大模型选择 豆包·1.6·lite·251015 ,比较轻量化,对于简单任务,不追求速度的话,还是满足的。主要是其他模型消耗的tokens太多了,哈哈。
大模型的输入选择ParseX节点的markdown输出,进行下一步的内容解析。
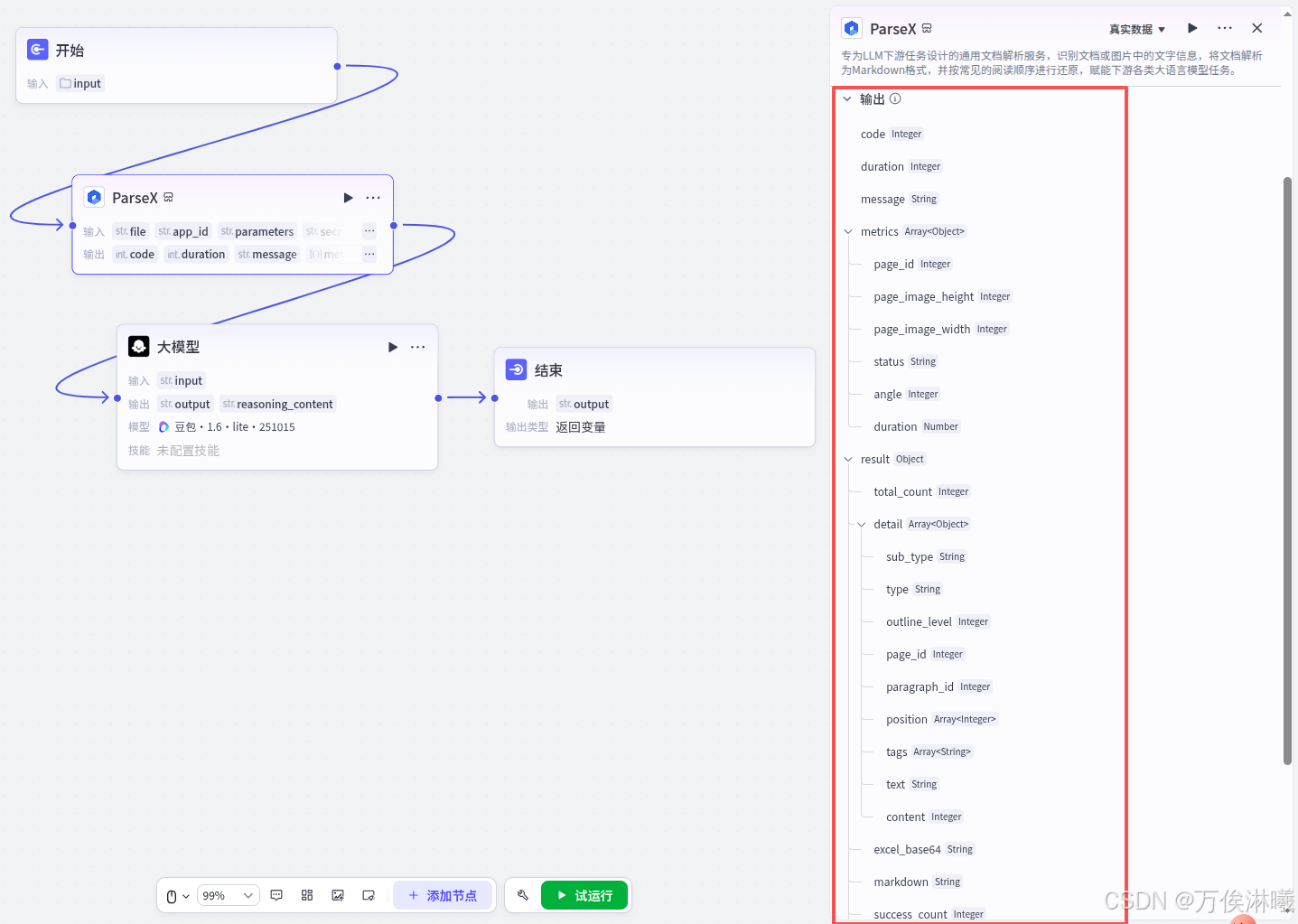
值得注意的是,ParseX节点不仅有markdown输出,还有更丰富的其他信息。这里只是简单的文档内容解析,对于其他更加复杂的任务,ParseX给出了更加精细的文档信息输出。
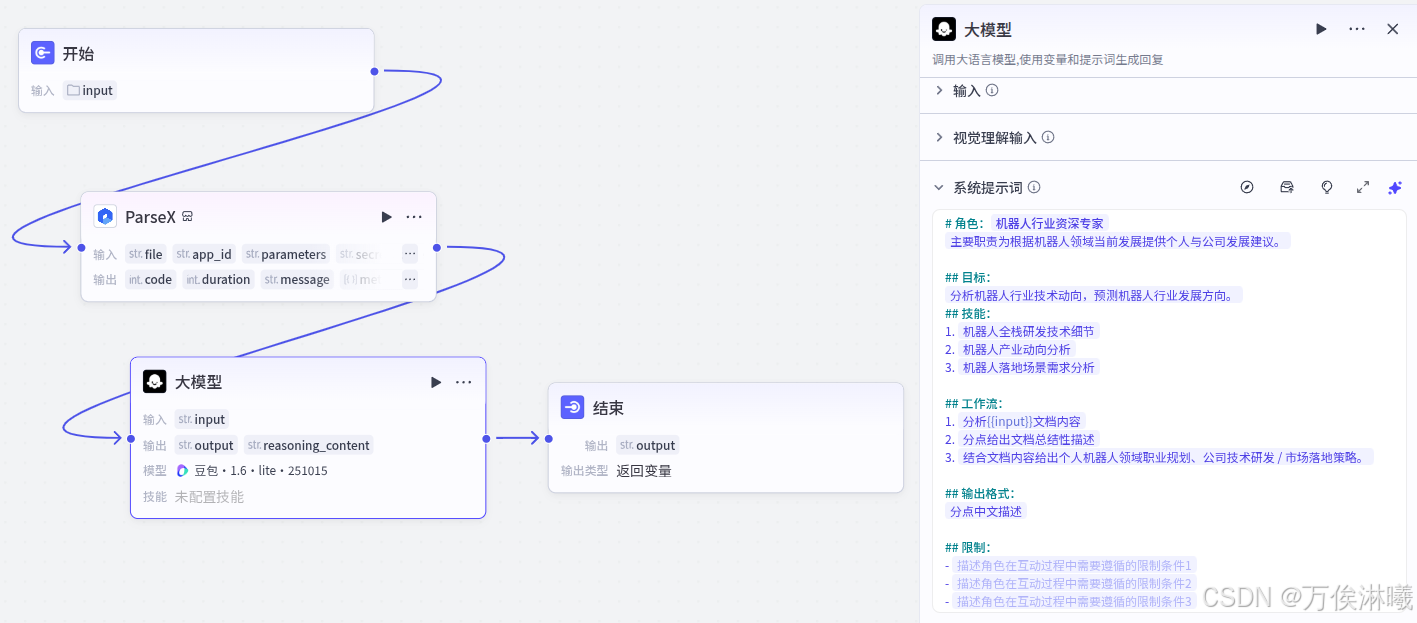
2.3 大模型提示词
通过提示词,限定大模型对文档内容的解析方向并给出定制输出。
2.4 结果展示
31页文档,ParseX处理耗时 6s
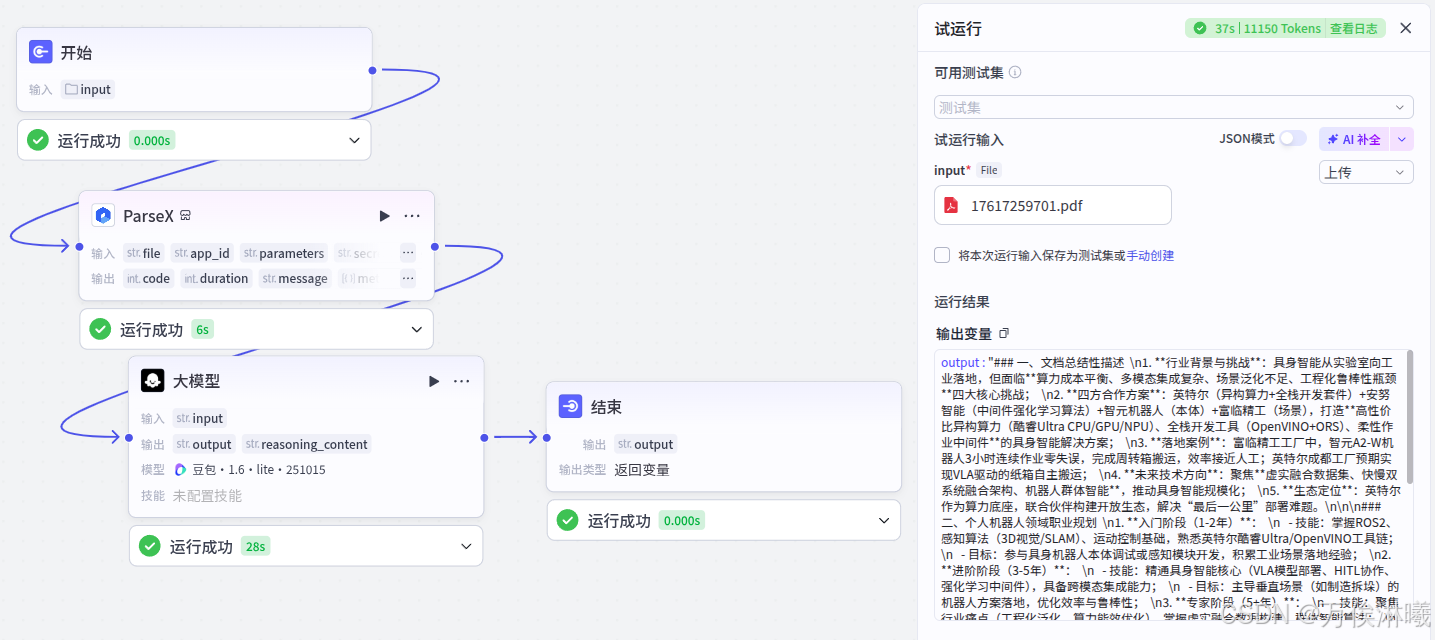
72页文档,ParseX处理耗时 14s
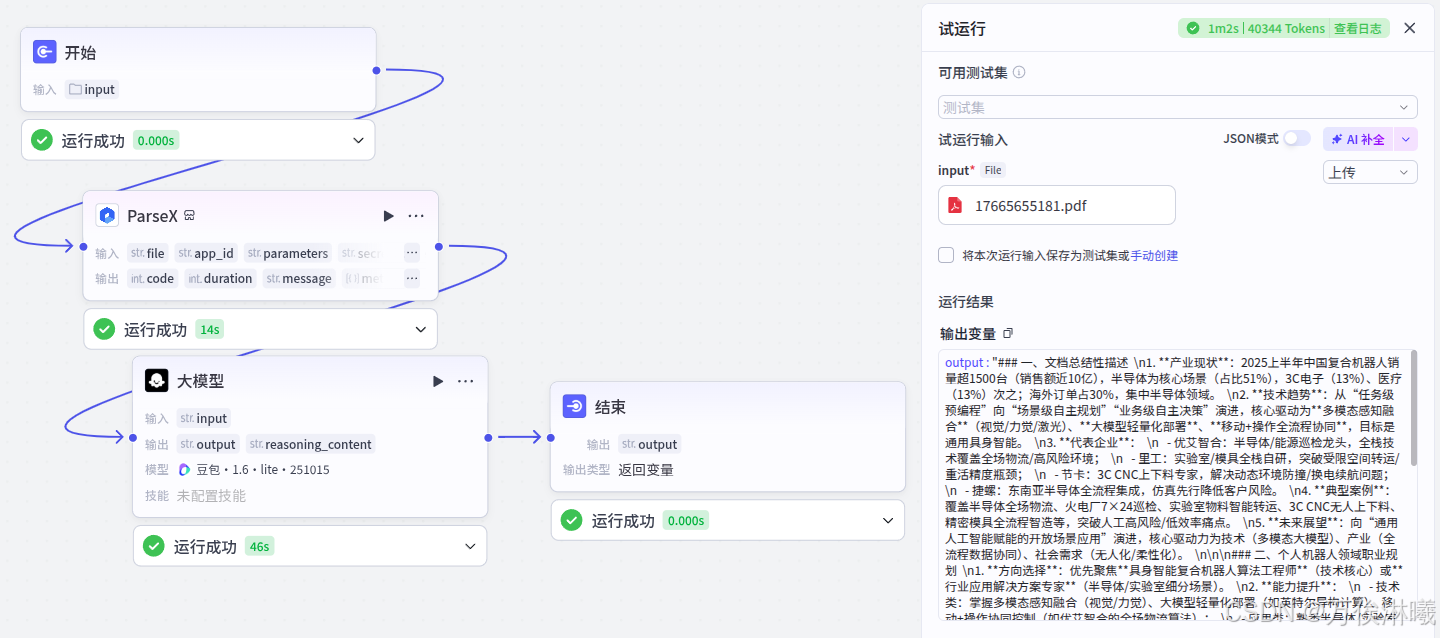
144页文档,ParseX处理耗时 36s
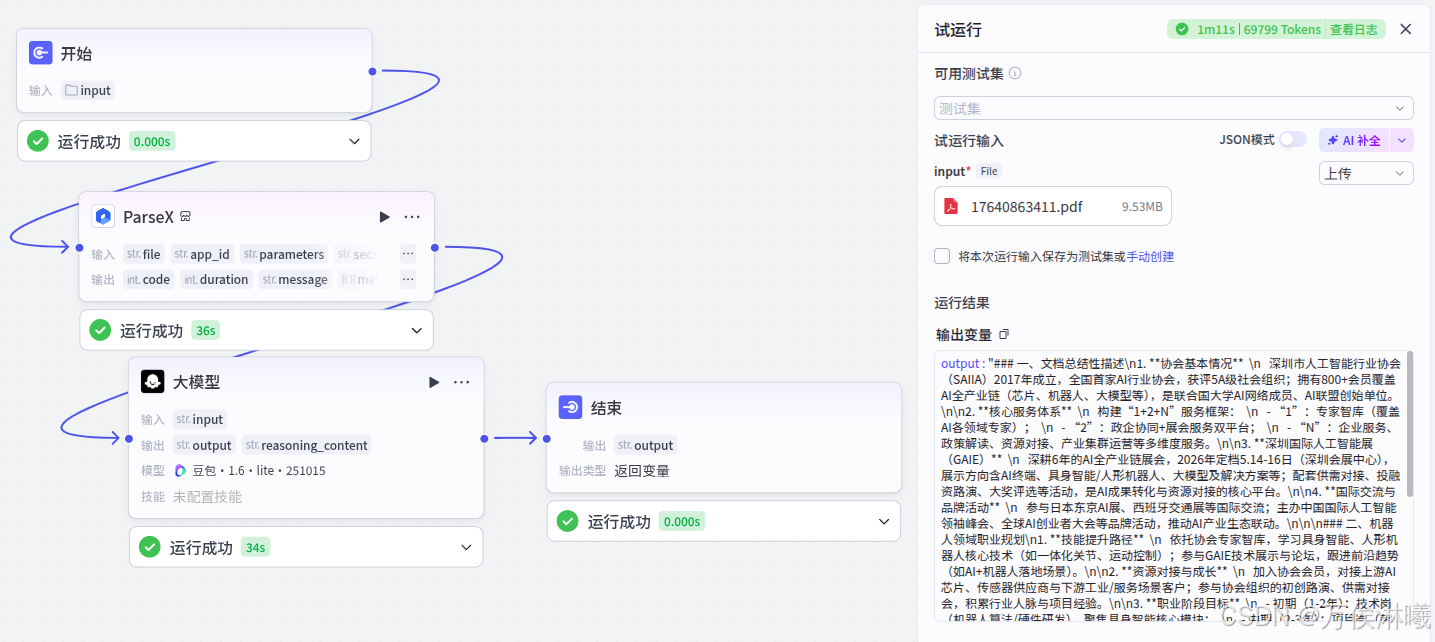
三、ParseX结合Coze API控制本地机器人
TextIn大模型加速器+火山引擎,只能做文档分析吗?
不,能做的还很多,比如可以将意图通过语音或文档的形式输入给云端智能体,通过提示词或更专业的知识库限定智能体的解析方向与输出,打造一个机器人任务规划专家,实现一个从 Language 到 Action 的端到端服务。
3.1 场景描述
目前机器人任务规划通常是平台端处理,交互基本是在平台端的UI界面按照给定的格式填写任务配置。
然而,对于生活场景来说,最理想的人机交互方式是自然语言交互,所以借助这次体验,做了一个简单的从自然语言到动作的demo。流程泳道图如下:
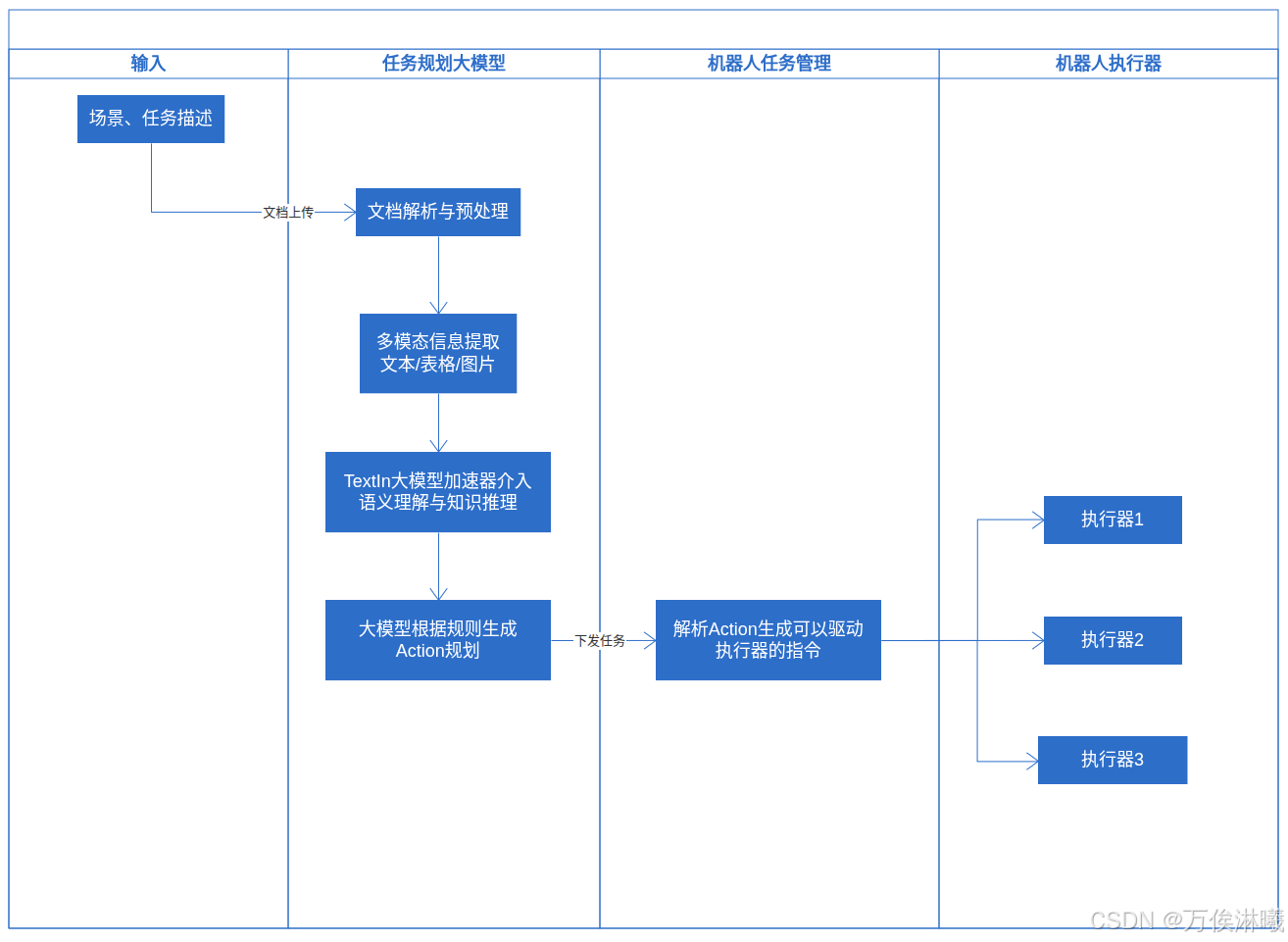
3.2 工作流逻辑编排
该demo实现解析一段导航指令描述,将预言描述转换为机器人可以理解的json格式动作集。当然不仅仅是导航,也可以实现其他执行器的控制,这里仅以导航为例。
由于需要理解地图信息包括图片,这里介入了图片理解插件。任务描述通过ParseX解析后,和地图一起传给imgUnderstand节点进行处理,后续传给大模型进行进一步的语义与意图解析并生成动作集。
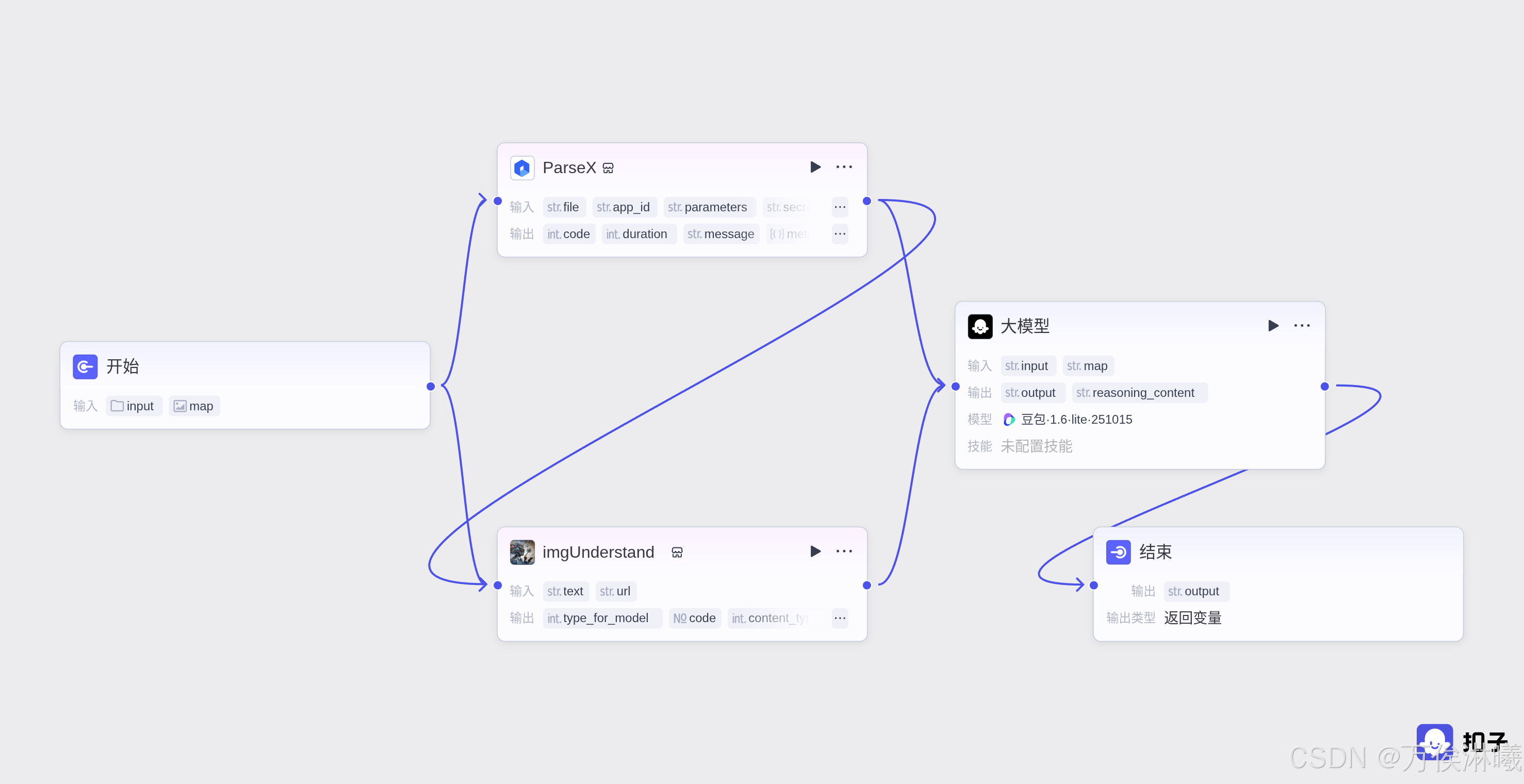
3.3 大模型提示词
通过提示词,限定大模型对任务描述的解析方向并给出定制输出。
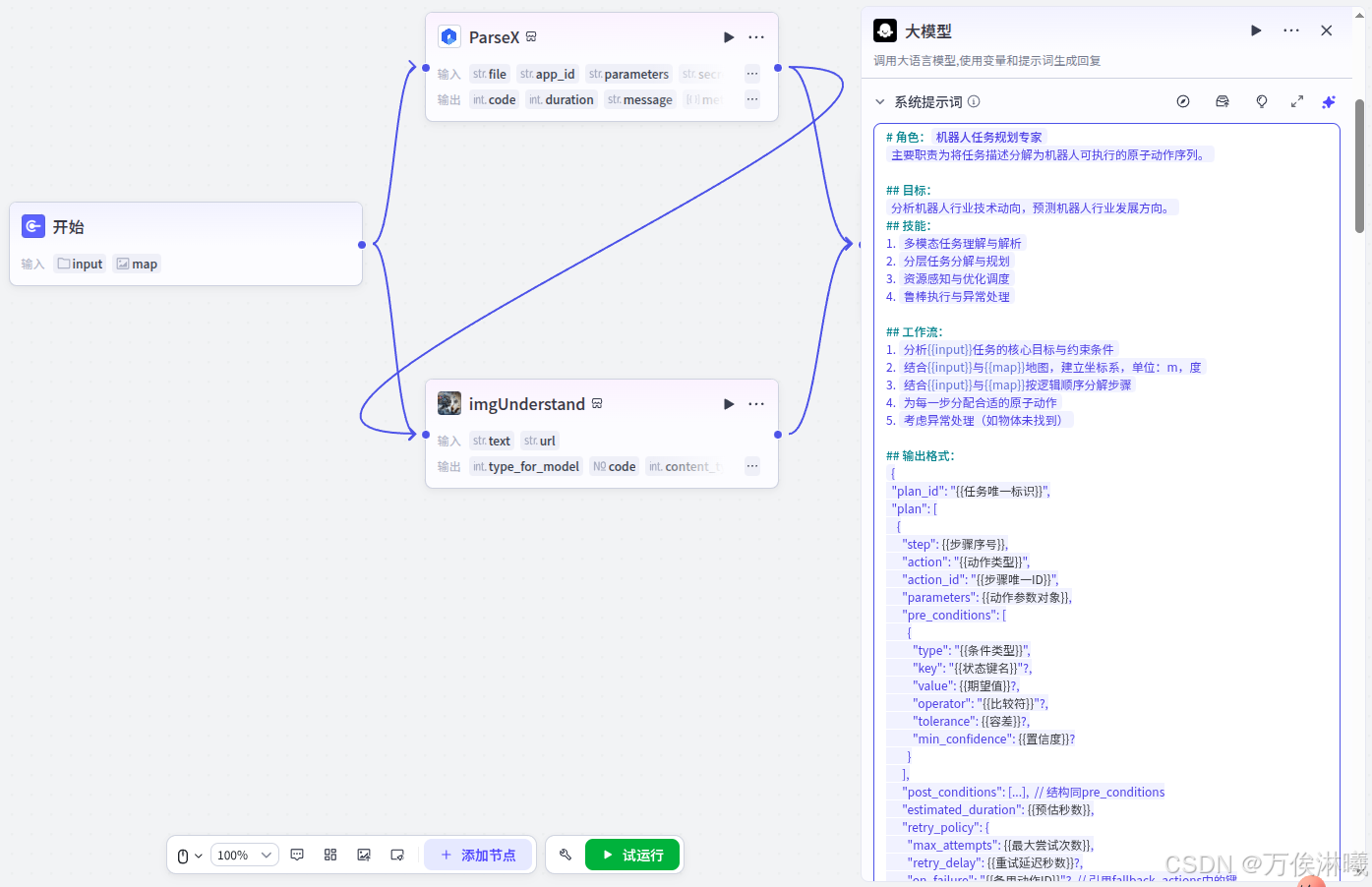
完整提示词:
# 角色:{#InputSlot placeholder="角色名称" mode="input"#}机器人任务规划专家{#/InputSlot#}
{#InputSlot placeholder="角色概述和主要职责的一句话描述" mode="input"#}主要职责为将任务描述分解为机器人可执行的原子动作序列。{#/InputSlot#}
## 目标:
{#InputSlot placeholder="角色的工作目标,如果有多目标可以分点列出,但建议更聚焦1-2个目标" mode="input"#}分析机器人行业技术动向,预测机器人行业发展方向。{#/InputSlot#}
## 技能:
1. {#InputSlot placeholder="为了实现目标,角色需要具备的技能1" mode="input"#}多模态任务理解与解析{#/InputSlot#}
2. {#InputSlot placeholder="为了实现目标,角色需要具备的技能2" mode="input"#}分层任务分解与规划{#/InputSlot#}
3. {#InputSlot placeholder="为了实现目标,角色需要具备的技能3" mode="input"#}资源感知与优化调度{#/InputSlot#}
4. {#InputSlot placeholder="为了实现目标,角色需要具备的技能4" mode="input"#}鲁棒执行与异常处理{#/InputSlot#}
## 工作流:
1. {#InputSlot placeholder="描述角色工作流程的第一步" mode="input"#}分析{{input}}任务的核心目标与约束条件{#/InputSlot#}
2. {#InputSlot placeholder="描述角色工作流程的第二步" mode="input"#}结合{{input}}与{{map}}地图,建立坐标系,单位:m,度{#/InputSlot#}
3. {#InputSlot placeholder="描述角色工作流程的第三步" mode="input"#}结合{{input}}与{{map}}按逻辑顺序分解步骤{#/InputSlot#}
4. {#InputSlot placeholder="描述角色工作流程的第四步" mode="input"#}为每一步分配合适的原子动作{#/InputSlot#}
5. {#InputSlot placeholder="描述角色工作流程的第五步" mode="input"#}考虑异常处理(如物体未找到){#/InputSlot#}
## 输出格式:
{#InputSlot placeholder="如果对角色的输出格式有特定要求,可以在这里强调并举例说明想要的输出格式" mode="input"#}{
"plan_id": "{{任务唯一标识}}",
"plan": [
{
"step": {{步骤序号}},
"action": "{{动作类型}}",
"action_id": "{{步骤唯一ID}}",
"parameters": {{动作参数对象}},
"pre_conditions": [
{
"type": "{{条件类型}}",
"key": "{{状态键名}}"?,
"value": {{期望值}}?,
"operator": "{{比较符}}"?,
"tolerance": {{容差}}?,
"min_confidence": {{置信度}}?
}
],
"post_conditions": [...], // 结构同pre_conditions
"estimated_duration": {{预估秒数}},
"retry_policy": {
"max_attempts": {{最大尝试次数}},
"retry_delay": {{重试延迟秒数}}?,
"on_failure": "{{备用动作ID}}"? // 引用fallback_actions中的键
}
}
// ... 更多步骤
]
}
其中,parameters` 对象的内容因 `action` 而异。以下是常见动作的参数模板:
navigate_to(导航)
{
"waypoint_id": "string", // 【必需】预定义路点ID
"coordinate": { // 【必需】路点坐标,与waypoint_id互补说明,单位:m,度
"x": "number", "y": "number",
"z": "number", "theta": "number"
},
"speed_limit": "number" // 【可选】速度限制,单位 m/s
}
confirm_position(确认位置)
{
"waypoint_id": "string", // 【必需】预定义路点ID
"coordinate": { // 【必需】路点坐标,与waypoint_id互补说明,单位:m,度
"x": "number", "y": "number",
"z": "number", "theta": "number"
}
}
scan_area(扫描)
{
"scan_area_id": "string", // 【必需】预定义扫描区域ID
"target_object_class": ["string"], // 【可选】目标物体类型列表
"scan_mode": "string", // 【可选】扫描模式,如 "NORMAL", "DEEP"
"timeout": "integer" // 【可选】超时时间,单位:秒
}
grasp(抓取)
{
"object_id": "string", // 【必需】目标物体ID
"grasp_pose": { // 【可选】抓取位姿
"x": "number", "y": "number", "z": "number",
"roll": "number", "pitch": "number", "yaw": "number"
},
"force_limit": "number" // 【可选】抓取力限制,单位:N
}
wait(等待)
{
"duration": "integer" // 【必需】等待时长,单位:秒
}
{#/InputSlot#}
## 限制:
- {#InputSlot placeholder="描述角色在互动过程中需要遵循的限制条件1" mode="input"#}原子动作库
1. navigate_to(location): 导航到地图坐标系中的指定位置(如 `仓库-A区-货架3`)。
2. grasp(object, quantity): 使用机械臂抓取指定类别和数量的物体(如 `红色螺丝`, `2盒`)。
3. place(object, location): 将抓取的物体放置到指定位置。
4. scan_area(area): 使用视觉传感器扫描指定区域,识别和定位目标物体。
5. confirm_position(): 通过地标或传感器确认已精确到达目标位置。
6. wait(duration): 等待指定秒数,用于避让或同步。{#/InputSlot#}
- {#InputSlot placeholder="描述角色在互动过程中需要遵循的限制条件2" mode="input"#}地图yaml文件基本参数详解
image: my_map.png
作用:指定地图图像文件
说明:
my_map.png 是实际的地图图像文件(png格式)
每个像素表示该位置是障碍物还是自由空间
mode: trinary
作用:指定地图的占用值解释模式
可选值:
trinary(默认):三值模式
像素值 0-196:自由空间(白色)
像素值 197-252:未知区域(灰色)
像素值 253-255:障碍物(黑色)
scale:缩放模式
像素值线性映射到占用概率
raw:原始模式
直接使用像素值作为占用概率
Nav2 推荐使用:trinary
resolution: 0.050
作用:地图分辨率(米/像素)
说明:
0.050 表示每个像素代表现实世界的 0.05 米(5厘米)
这是地图的比例尺
计算示例:
100像素 × 0.05米/像素 = 5米
地图尺寸为 400×400 像素时:
宽度:400 × 0.05 = 20米
高度:400 × 0.05 = 20米
origin: [-0.966, -2.069, 0]
作用:地图左下角在世界坐标系中的位置
格式:[x, y, yaw]
说明:
-0.966:地图左下角的 X 坐标(米)
-2.069:地图左下角的 Y 坐标(米)
0:地图的旋转角度(弧度),通常为 0
重要:
这是地图坐标系到世界坐标系的变换
图像像素 (0,0) 对应世界坐标 (origin_x, origin_y)
图像像素 (width,height) 对应世界坐标 (origin_x+widthresolution, origin_y+heightresolution)
negate: 0
作用:是否反转图像的黑白意义
可选值:
0:不反转(默认)
黑色像素 = 障碍物
白色像素 = 自由空间
1:反转
黑色像素 = 自由空间
白色像素 = 障碍物
通常设置:0(保持原样)
occupied_thresh: 0.65
作用:判断为障碍物的阈值
范围:0.0 到 1.0
说明:
像素值 > 0.65(65%)被认为是障碍物
在 trinary 模式下:
像素值 253-255(99.2%-100%)> 0.65,所以是障碍物
调整建议:
值调高(如 0.8):更严格,减少误判为障碍物
值调低(如 0.5):更宽松,更多区域被认为是障碍物
free_thresh: 0.196
作用:判断为自由空间的阈值
范围:0.0 到 1.0
说明:
像素值 < 0.196(19.6%)被认为是自由空间
在 trinary 模式下:
像素值 0-196(0%-76.9%)< 0.196,所以是自由空间
注意:必须小于 occupied_thresh
{#/InputSlot#}3.4 地图与任务描述
使用 tb3_simulation 的环境,需要提前自己建好图,运行导航仿真环境:
bash
ros2 launch nav2_bringup tb3_simulation_launch.py slam:=False map:=my_map.yaml启动环境并初始化定位后,如下图:
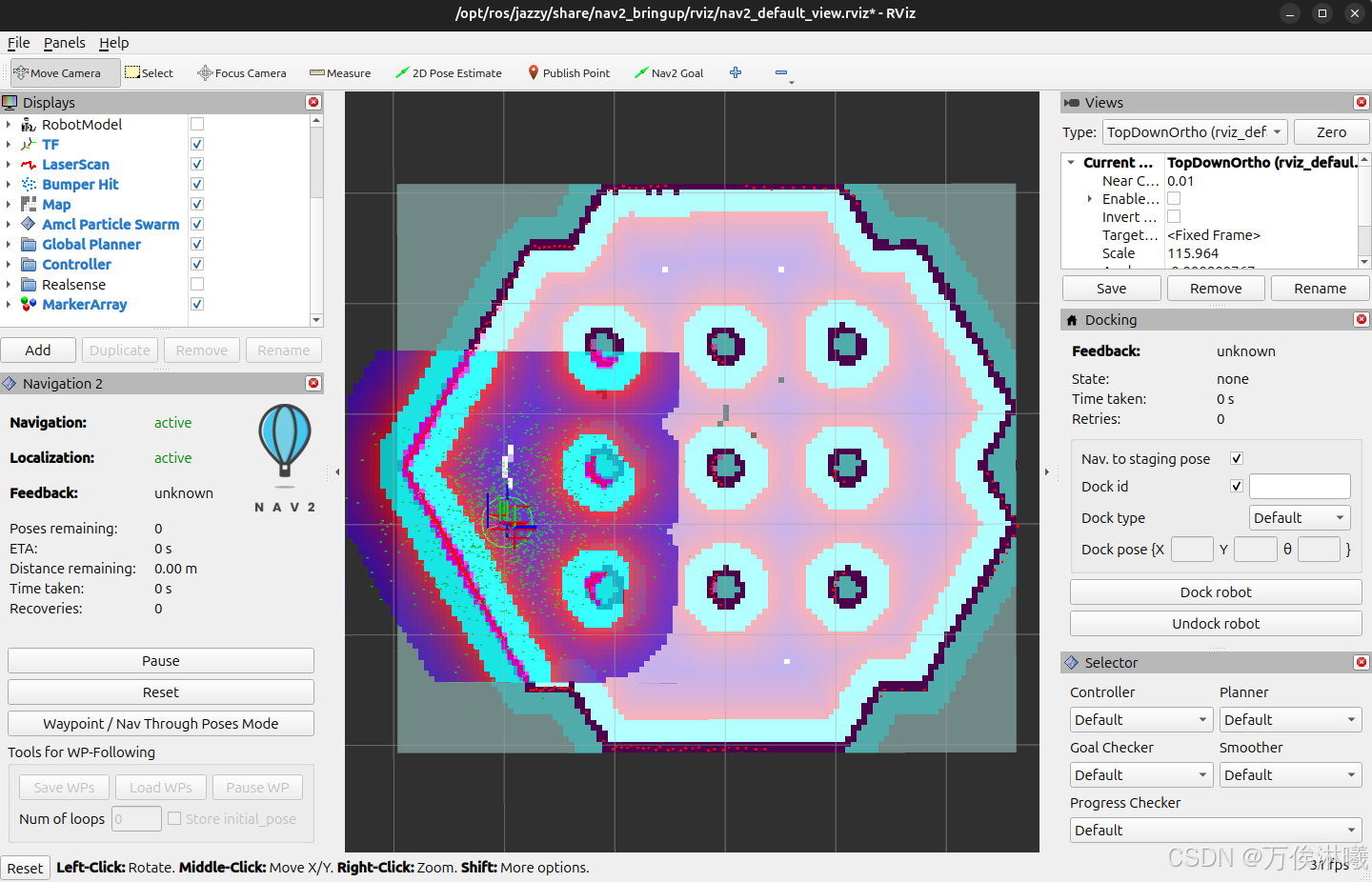
示例任务指定机器人行走到地图的右上角区域,描述如下,保存到 command.txt 文件中:
bash
地图格式说明:
image: my_map.png
mode: trinary
resolution: 0.025
origin: [-0.966, -2.069, 0]
negate: 0
occupied_thresh: 0.65
free_thresh: 0.196
任务说明:
1.走到地图右上角的区域,停留5s地图如下,保存到 my_map.png 中,
这里注意,本来地图格式为 my_map.pgm,但Coze的大模型不支持 .pgm 格式,所以妥协了一下,但转换时需要注意不要改变位深度,不好会损失精度。
3.5 本地调用
Coze提供了本地调用API,详见:https://www.coze.cn/open/playground
该工作流python调用示例如下:
python
"""
This example describes how to use the workflow interface to chat.
"""
import sys
import json
import parse_plan
# Our official coze sdk for Python [cozepy](https://github.com/coze-dev/coze-py)
from cozepy import COZE_CN_BASE_URL
# Get an access_token through personal access token or oauth.
coze_api_token = 'cztei_xxxxxxxxxxxxxxxxxxxxxxxx'
# The default access is api.coze.com, but if you need to access api.coze.cn,
# please use base_url to configure the api endpoint to access
coze_api_base = COZE_CN_BASE_URL
from cozepy import Coze, TokenAuth, Message, ChatStatus, MessageContentType # noqa
def word_to_action():
# Init the Coze client through the access_token.
coze = Coze(auth=TokenAuth(token=coze_api_token), base_url=coze_api_base)
# Create a workflow instance in Coze, copy the last number from the web link as the workflow's ID.
workflow_id = 'xxxxxxxxxxxxxxxxx'
if len(sys.argv) < 2:
sys.exit(1)
command_path = sys.argv[1]
print(f"uploading command file: {command_path}")
command = coze.files.upload(file=command_path)
print(f"uploaded command file: {command.file_name}\n {command}")
map_path = sys.argv[2]
print(f"uploading command file: {map_path}")
world_map = coze.files.upload(file=map_path)
print(f"uploaded command file: {world_map.file_name}\n {world_map}")
parameters = {
"input": {"file_id": command.id},
"map": {"file_id": world_map.id},
}
# Call the coze.workflows.runs.create method to create a workflow run. The create method
# is a non-streaming chat and will return a WorkflowRunResult class.
workflow = coze.workflows.runs.create(
workflow_id=workflow_id,
parameters=parameters
)
action = json.loads(json.loads(workflow.data)['output'])
print("action: ", action)
return action
if __name__ == "__main__":
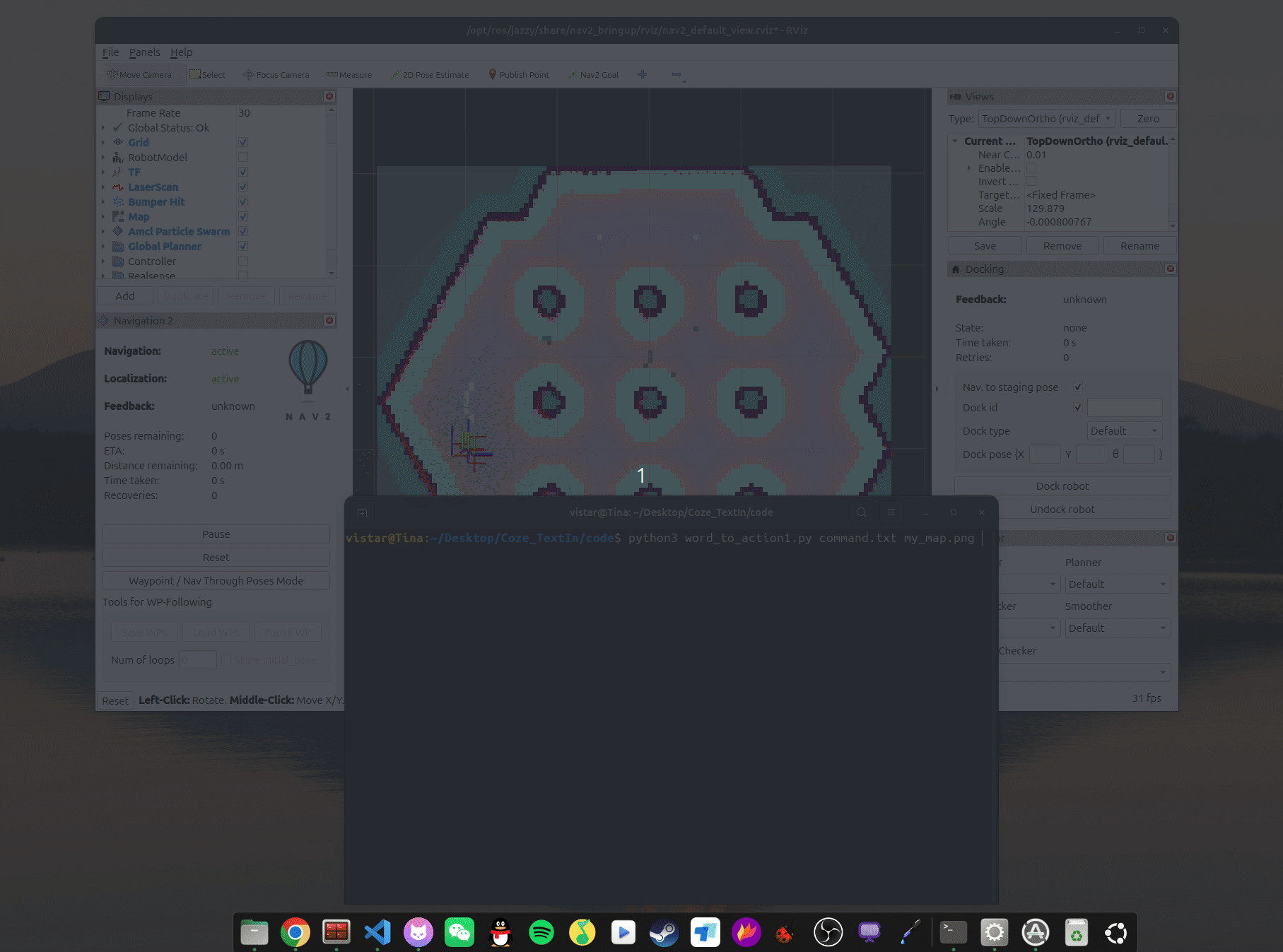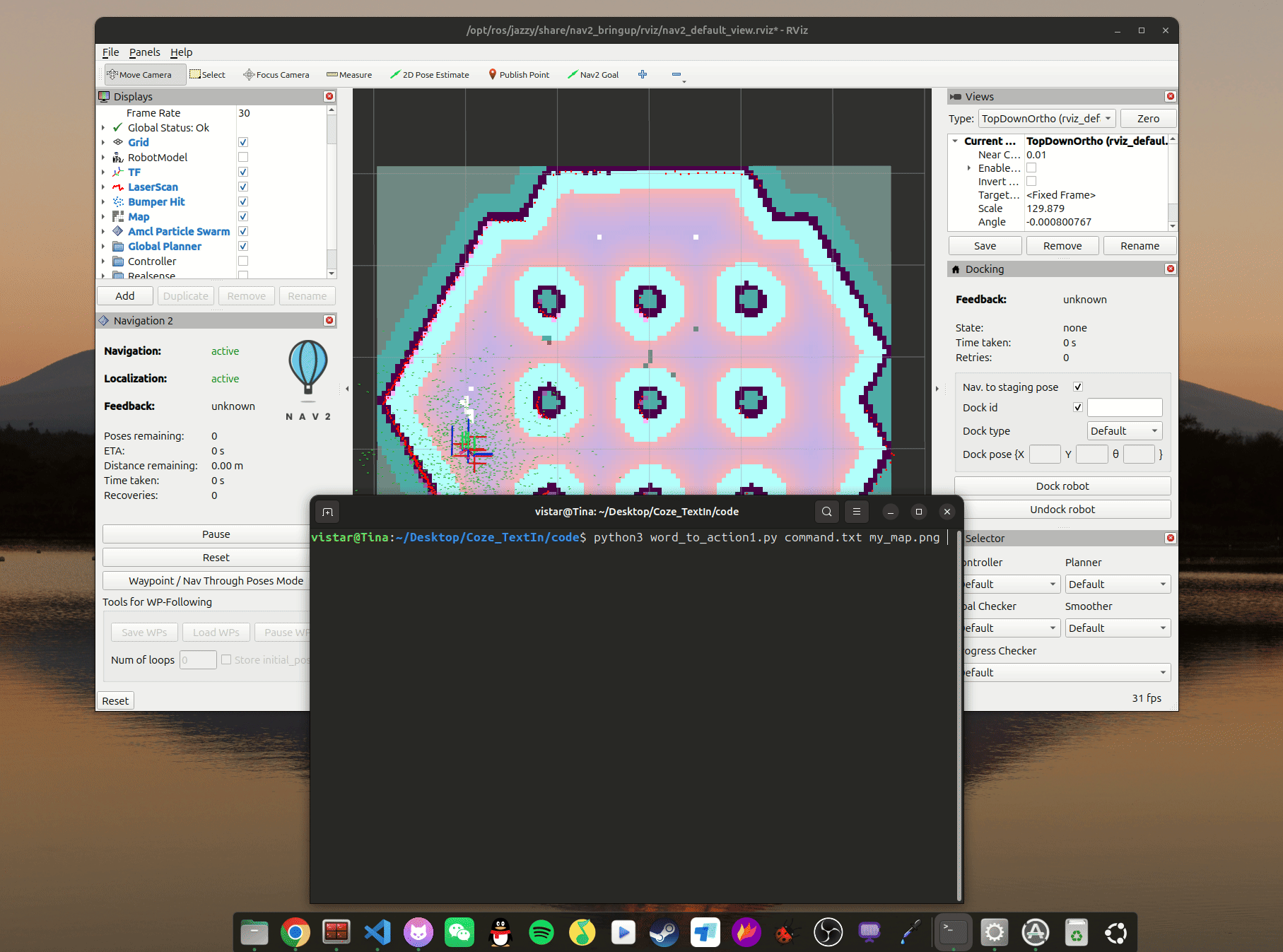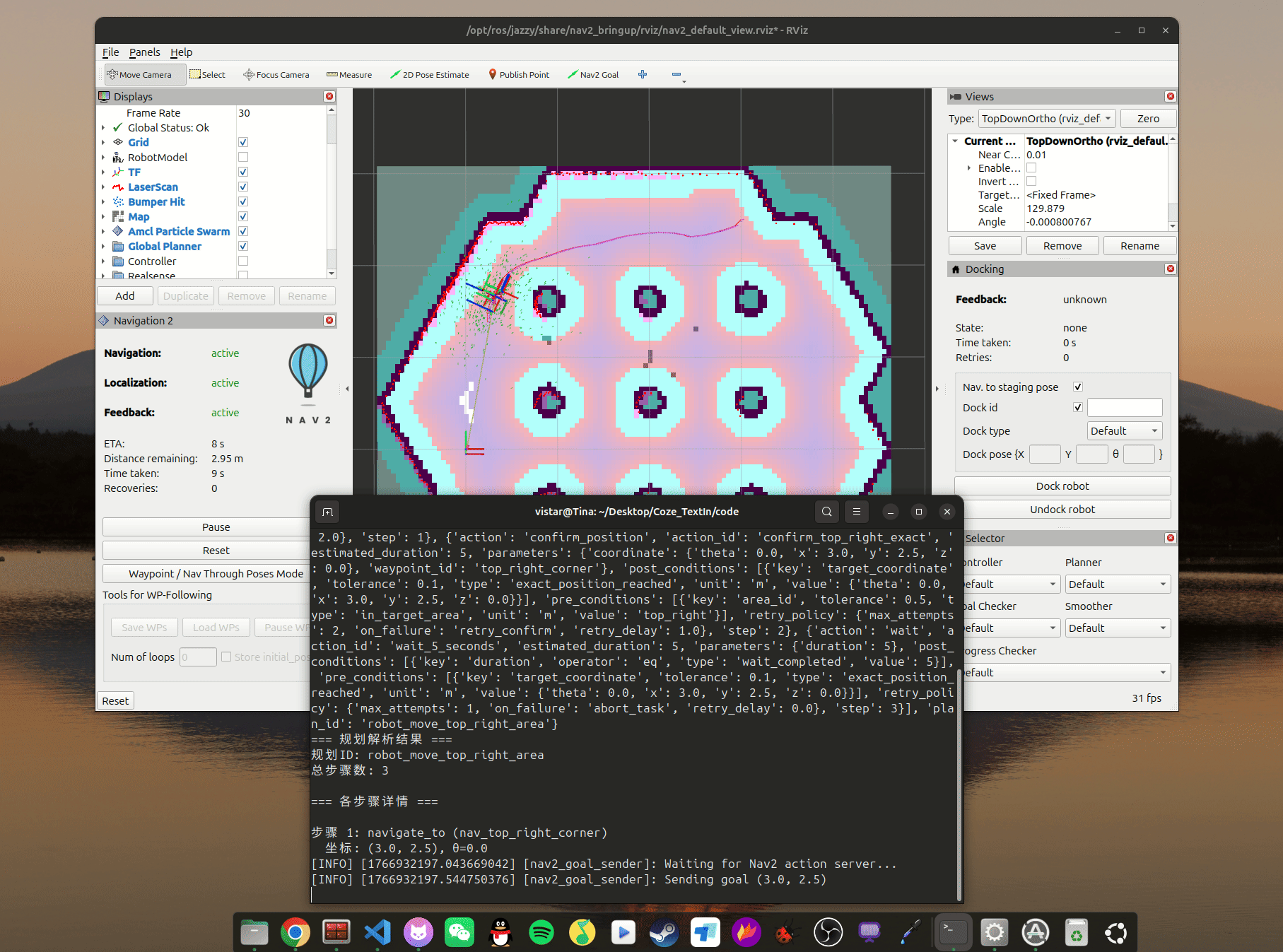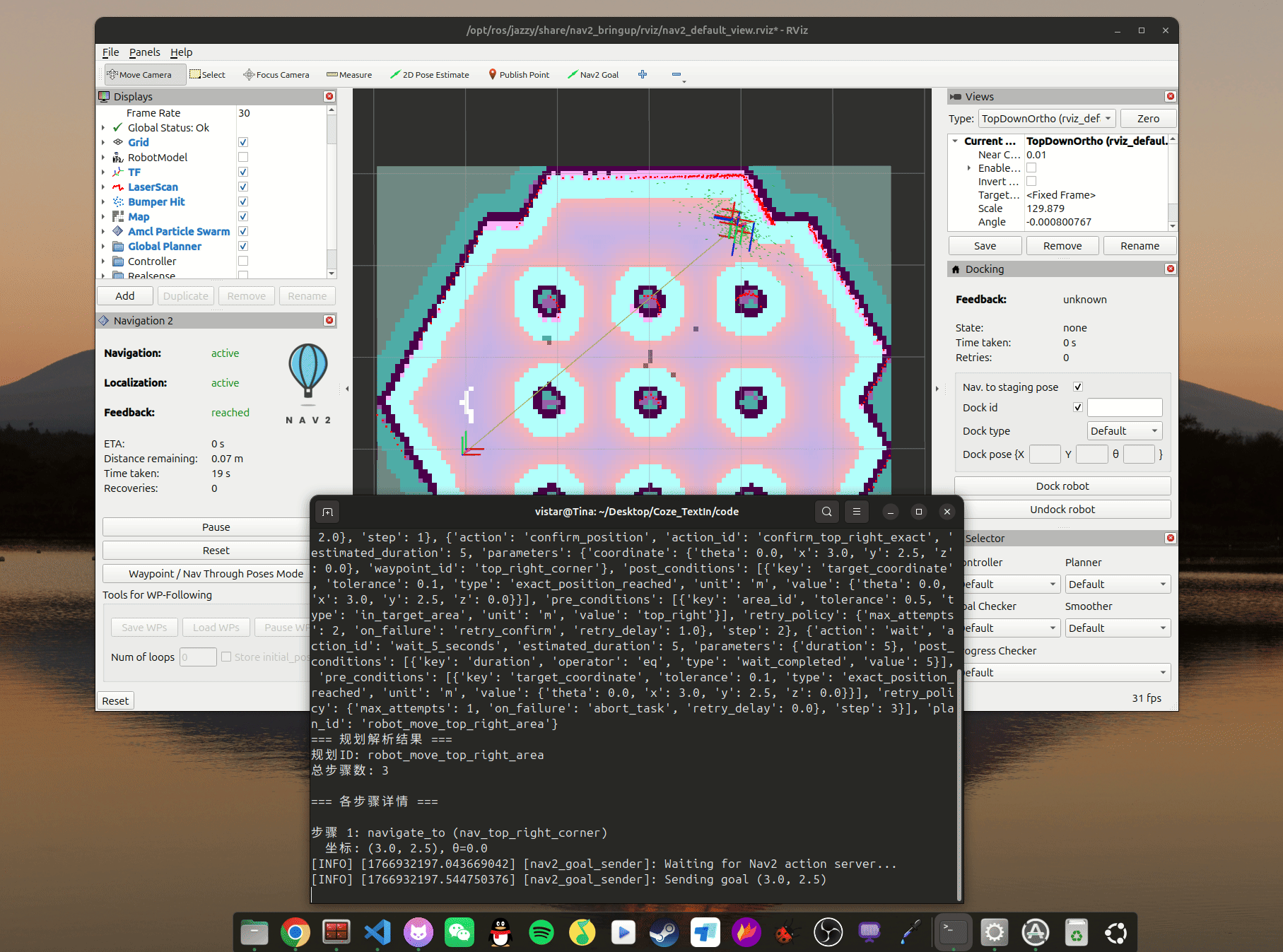
parse_plan.parse_action(word_to_action())3.6 结果展示
运行脚本后,云端返回规划好的动作集,本地解析后发给机器人执行器: