自动驾驶算法的演进史,本质上是从"人工规则"向"数据驱动",从**"模块化拆解"向"整体化协同"**进化的过程。
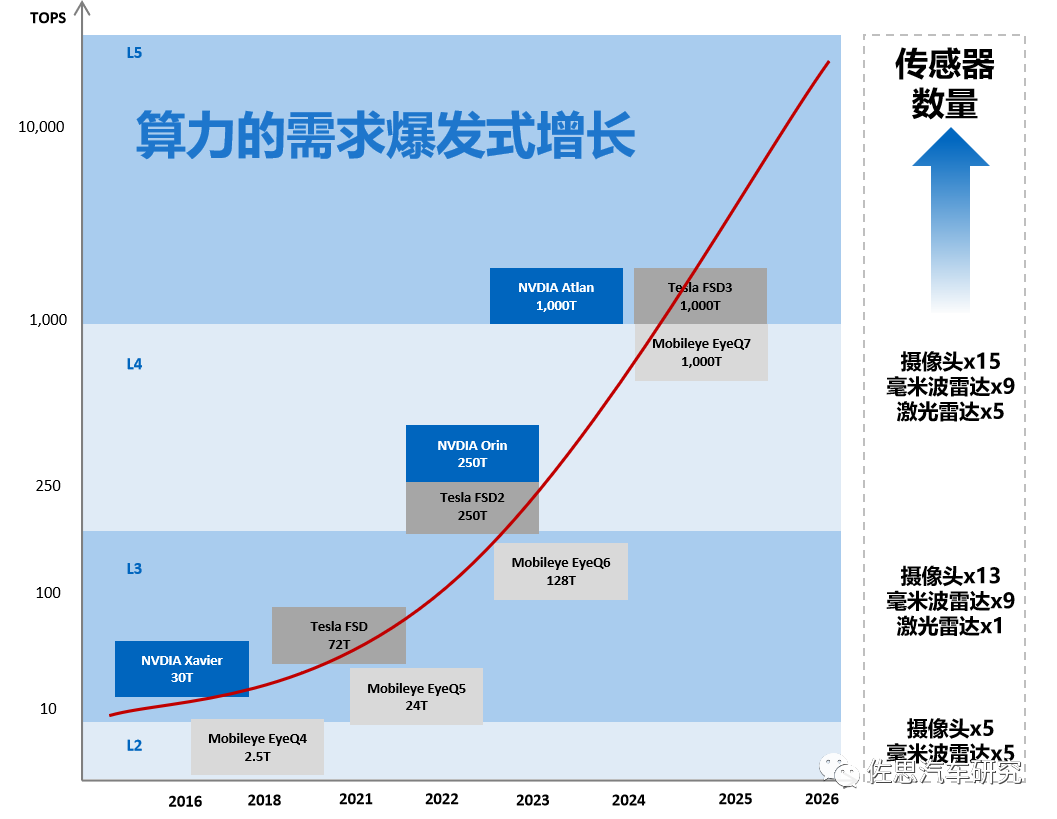
这一过程可以概括为四个主要阶段。以下是详细的技术演进路线图:
第一阶段:模块化规则算法 (Modular / Rule-Based)
这是自动驾驶最早期的形态(也是目前大多数传统 L2 辅助驾驶的实现方式)。
-
核心理念: 分而治之(Divide and Conquer)。将驾驶任务拆解为独立的子任务,每个子任务由专门的团队负责。
-
架构流程:
-
感知 (Perception): 识别车道线、车辆、红绿灯(输出:目标列表)。
-
定位 (Localization): 确定自己在地图上的位置。
-
预测 (Prediction): 预测其他车辆未来 3 秒怎么走。
-
决策规划 (Planning): 基于规则(有限状态机 FSM)决定本车轨迹。
-
控制 (Control): PID/MPC 控制方向盘和油门。
-
特征:
-
接口标准化: 模块之间传递的是非常抽象的、低维度的几何结果(如:障碍物框、车道线多项式、红绿灯状态)。
-
人为规则主导: 预测和规划模块大量使用规则(Rules)和优化算法(Optimization,如二次规划 QP)。
-
模块解耦: 感知团队只管画框准不准,规划团队只管轨迹平不平。
-
技术特点:
-
大量 C++ 代码: 充满 if-else 逻辑(例如:if 前车距离 < 30m then 减速)。
-
接口明确: 模块之间通过人为定义的接口(如 Object List)传递信息。
-
缺点:
-
信息有损传输: 感知模块把一个复杂的"正在招手的人"简化成一个"行人框",下游规划模块丢掉了"招手"这个语义信息。
-
累积误差 (Cascading Error): 感知错一点,预测偏一点,到了规划层误差就很大了。
-
长尾问题 (Long Tail): 工程师无法穷举所有路况写出对应的 if-else。
第二阶段:多任务联合感知架构 (Multi-Task Learning / HydraNet)
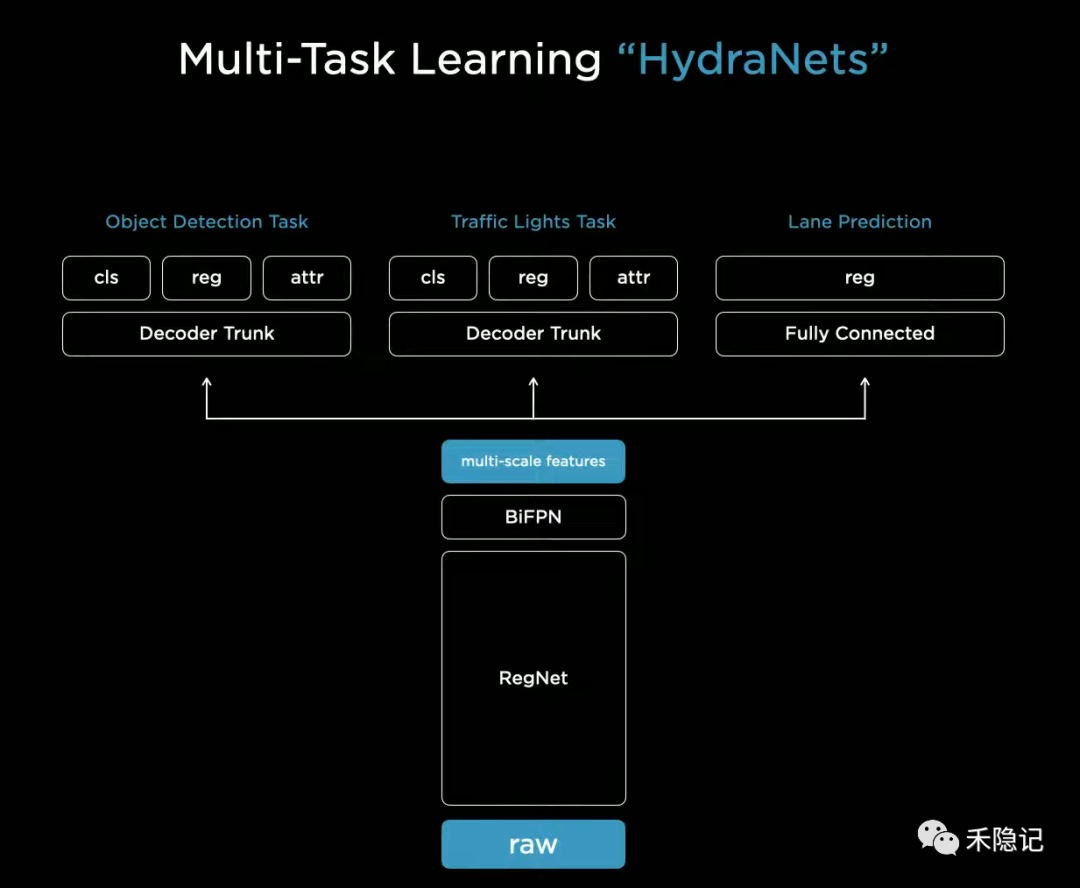
这是 Tesla 在 AI Day 2021 展示的架构(FSD V10 之前),也是国内新势力(小鹏、理想等)在 2022-2023 年的主流架构。
-
架构逻辑: 共享主干 (Shared Backbone) + 多头输出 (Multi-Head)。
-
演进点:
-
在感知内部打破了壁垒。不再是用单独的模型分别跑车道线和车辆,而是用一个巨大的 Backbone (如 RegNet/Swin Transformer) 提取特征。
-
BEV 引入: 引入 View Transformer(视角落投影),将 2D 图像特征转换到 3D BEV 空间,直接输出鸟瞰图下的感知结果。
-
特征:
-
感知变强了,不再需要复杂的后处理逻辑将 2D 拼成 3D。
-
但下游(预测、规划)依然是独立的、基于规则的模块。感知仅仅是为这些规则模块提供了更准的输入。
第三阶段:两段式 / 模块化端到端 (Modular End-to-End)
为了解决下游规则模块的僵化问题,业界开始尝试将预测和规划也纳入神经网络,这就诞生了 UniAD(Unified Autonomous Driving)类架构。
-
架构逻辑: 特征级交互 (Feature-Level Interaction)。
-
演进点:
-
Query 传递: 感知模块检出的 Target Query(目标向量)直接传递给预测模块,预测出的轨迹 Query 直接传递给规划模块。
-
全链路可导 (End-to-End Differentiable): 这是一个巨大的突破。意味着你可以用最终规划轨迹的误差,去反向优化感知的特征提取能力。
-
特征:
-
仍然保留了模块的"名分"(你有检测头、预测头、规划头),但它们在数学上已经融为一体。
-
解决了信息瓶颈,预测模块能"看到"感知模块提取的原始特征。
为了解决规则算法的瓶颈,行业开始引入深度学习来替代部分模块,但保留了模块化的结构以便于解释和调试。这通常被称为 UniAD (Unified Autonomous Driving) 风格或 Mid-to-Mid。
-
核心理念: 仍然有感知、预测、规划模块,但它们都在同一个大神经网络里,通过向量(Query/Feature)连接,而不是通过人工定义的接口。
-
技术特点:
-
可微分 (Differentiable): 整个网络可以从最终的轨迹误差反向传播梯度,更新感知层的权重。感知是为了规划服务的,而不只是为了画框准。
-
特征共享 (Shared Backbone): 感知和预测共享同一个 BEV 特征图。
-
代表作: UniAD(2023 CVPR Best Paper)。它通过 Query 将检测、跟踪、映射、预测、规划串联起来。
-
优势:
-
比纯黑盒有更好的可解释性(能看到中间过程)。
-
比规则算法有更强的泛化能力和全局优化能力。
第四阶段:一段式端到端 (One-Stage End-to-End)
这是目前最激进、最前沿的方向,彻底抛弃了中间模块的概念。
这是 Tesla FSD V12 和 Wayve 所代表的最新方向。
-
架构逻辑: 单一网络 (Single Network)。
-
演进点:
-
彻底取消了"检测"、"跟踪"、"预测"、"规划"这些人定义的中间任务接口。
-
Input: 视频流 + 导航指令 + IMU。
-
Output: 轨迹点 (Trajectory) 或 控制指令 (Steering/Throttle)。
-
核心技术栈变化:
-
从 CNN/Transformer 转向 World Model (世界模型) 和 Generative Model (生成式模型)。
-
它预测的不是"这里有辆车",而是"下一帧画面长什么样"以及"我应该在那个画面里处于什么位置"。
-
特征:
-
数据驱动: 代码量极少,性能完全取决于训练数据的质量和规模。
-
模糊性: 网络内部没有清晰的模块边界,它是一种通过模仿人类行为习得的直觉反应。
-
核心理念: Photon in, Control out(光子进,控制出)。输入是原始传感器数据(视频流),输出直接是方向盘转角或轨迹点。
-
架构流程:
-
Sensor Data (Video/LiDAR) -> Huge Neural Network -> Trajectory / Control Command.
-
技术特点:
-
黑盒模型: 网络内部不再强制输出"目标框"或"车道线"(除非作为辅助监督),它自己学习如何看路。
-
模仿学习 (Imitation Learning): 让 AI 观看数百万小时的人类老司机驾驶视频,学习人类的行为模式。
-
数据飞轮: 极其依赖高质量的数据规模,代码量极少,参数量极大。
-
优势:
-
无损信息: 网络可以利用图像中的微小细节(如前车司机的眼神、路边的积水反光)来做决策。
-
拟人化: 开车风格更像人,而不是生硬的机器。
第五阶段:VLA 模型 (Vision-Language-Action)
这是大语言模型(LLM)爆发后,自动驾驶的"终极形态"探索。
这是学术界和 L4 公司正在探索的未来架构。
-
架构逻辑: 大语言模型 (LLM) 赋能。
-
演进点:
-
将驾驶视为一种通用的推理任务,而不仅仅是几何计算任务。
-
引入 LLM 的推理能力来处理长尾场景(Corner Cases)。
-
特征:
-
System 1 + System 2:
-
System 1 (直觉): 用端到端小模型处理 99% 的日常驾驶(如车道保持、跟车),反应快。
-
System 2 (逻辑): 当遇到复杂情况(如交警手势、事故现场)时,激活 VLA 大模型进行慢思考推理,输出高层决策。
-
核心理念: 将 World Model(世界模型) 和 LLM(大语言模型) 引入驾驶。不仅要"会开",还要"理解世界"。
-
解决了什么问题?
-
常识推理 (Common Sense): 端到端能学会"红灯停",但 VLA 能理解"前方有警车拦路,虽然是绿灯但由于交通管制必须停"。
-
长尾场景: 比如路上出现了一只从未见过的怪兽气球,端到端可能会不知所措,VLA 可以根据语义理解这是"气球",是可以撞过去或绕行的。
-
技术方案:
-
利用多模态大模型(如 GPT-4V 类的车端版),输入视频,输出驾驶决策解释和动作。
-
代表企业:Wayve (英国自动驾驶独角兽), 清华 DriveVLM。
总结对比
| 阶段 | 核心驱动 | 架构特点 | 优点 | 缺点 | 代表方案 |
|---|---|---|---|---|---|
| 规则算法 | 工程师写代码 | 感知-预测-规划 串行 | 逻辑可解释,易调试 | 累积误差,无法处理长尾 | Mobileye早期,传统L2 |
| 两段式端到端 | 深度学习+先验结构 | 特征共享,可微分模块 | 兼顾性能与解释性 | 仍有结构限制 | UniAD, HydraNet |
| 一段式端到端 | 视频数据 | Sensor IN -> Control OUT | 上限极高,拟人化 | 黑盒,训练极其昂贵 | Tesla FSD V12, comma.ai |
| VLA | 通用人工智能 (AGI) | 视觉+语言+动作 | 具备常识推理能力 | 实时性挑战,算力巨大 | Wayve, DriveVLM |
| 演进阶段 | 核心特征 | 数据流形式 | 下游规划 | 局限性 |
|---|---|---|---|---|
| 1. 模块化 | 人工拆解,串行 | 几何目标列表 (Object List) | Rules / Optimization | 信息丢失,累积误差 |
| 2. BEV/多任务 | 共享感知 Backbone | 3D 空间特征 + 几何结果 | Rules / Optimization | 感知强,规划弱(木桶效应) |
| 3. UniAD/一体化 | 模块间 Query 交互 | 稀疏向量 / 特征流 | Neural Planner | 训练复杂,推理延迟高 |
| 4. 端到端 | 单一黑盒网络 | 原始视频 -> 控制信号 | Implicit (隐式学习) | 不可解释,依赖海量数据 |
| 5. VLA | 引入语言/常识 | 视频 + 文本提示 | LLM Reasoning | 算力昂贵,实时性差 |
Tesla 的技术演进方案
特斯拉是端到端技术的集大成者和坚定推动者,其演进路线极具代表性。
- Software 1.0 时代 (Mobileye & Early Autopilot)
-
特征: 传统的 2D 图像识别 + C++ 规则控制。
-
局限: 无法处理复杂的 3D 空间和路口,严重依赖高精地图(虽然特斯拉声称不用,但早期其实有依赖)。
- Software 2.0 - HydraNet (FSD Beta V9-V11)
-
HydraNet (九头蛇网络): 引入巨大的 RegNet 主干网络,共享视觉特征,然后分出不同的"头"负责车道线、车辆、红绿灯检测。
-
BEV + Transformer: 2021年引入,将 8 个摄像头的图像拼接到 3D 鸟瞰空间(Vector Space)。
-
Occupancy Network (占用网络): 2022年引入,不识别物体是什么,只识别体积和运动,解决了通用障碍物问题。
-
局限: 虽然感知已经非常强(全是神经网络),但规划控制(Planner)仍然是 30 万行 C++ 代码写死的规则。这导致车开起来像个机器人,生硬且处理不了复杂博弈。
- FSD V12 (端到端大爆发)
-
核心变革: 删除了 30 万行 C++ 控制代码,替换为一个单一的神经网络。
-
技术原理:
-
输入: 8 个摄像头的视频流。
-
输出: 直接输出车辆控制指令(方向盘转角、踏板深度)。
-
训练: 使用数千万个优质的人类驾驶片段(Video Clips)进行视频预训练 (Video Pre-training)。
-
本质: 它不再通过写代码来告诉车怎么开,而是通过喂视频数据,让神经网络自己提取特征、自己学会规划。
-
效果: 所谓的"上帝之手"。车辆学会了礼让行人、在泥坑前减速、丝滑变道,表现出极强的拟人特性。