在上一篇文章中,我们讨论了fork()函数的返回值、写时复制机制以及进程创建过程,了解到内核通过task_struct(PCB)这个'档案袋'来管理进程的所有信息。但这仅仅相当于看到了档案袋的封面。今天,我们将打开这个档案袋,深入探究:内核如何组织进程信息,调度器如何管理这个'生命体',进程状态如何转换,以及它如何与系统进行交互。
-
核心问题提炼:
-
高效组织机制:内核如何通过精巧的链表设计来管理海量task_struct结构?(引出进程链表管理)
-
调度决策机制:内核如何基于优先级等调度参数,实现快速进程切换?(引出调度算法设计)
-
资源管理机制:进程在阻塞时如何保存状态?内核如何维护其内存、文件等资源视图?(引出资源管理体系)
-
-
本文将深入探讨Linux内核进程管理的核心机制,不仅分析接口实现,更着重解析底层数据结构和算法设计原理。
task_struct如何被组织
由前文知,task_struct是进程在内核中的完整描述符,储存一个进程的所有信息,那么它是被怎样组织管理的呢?
进程状态
内核中有成千上万个task_struct,它们并不是随机的散落在各处,而是被精心组织在一个动态的网络中。这个网络的结构直接决定了内核管理进程的效率。要将task_struct放到这个网络中,首先就要把它们归类;进程可以被分为很多种,已经在运行的,等待调度的,还在磁盘中还没有创建PCB的。这时候就产生了进程状态这个概念,对进程分类后,对它们进行管理就方便多了。
进程的状态有很多种,在这里我们主要讨论运行,阻塞和挂起三种状态,及状态之间的切换。
进程状态切换图
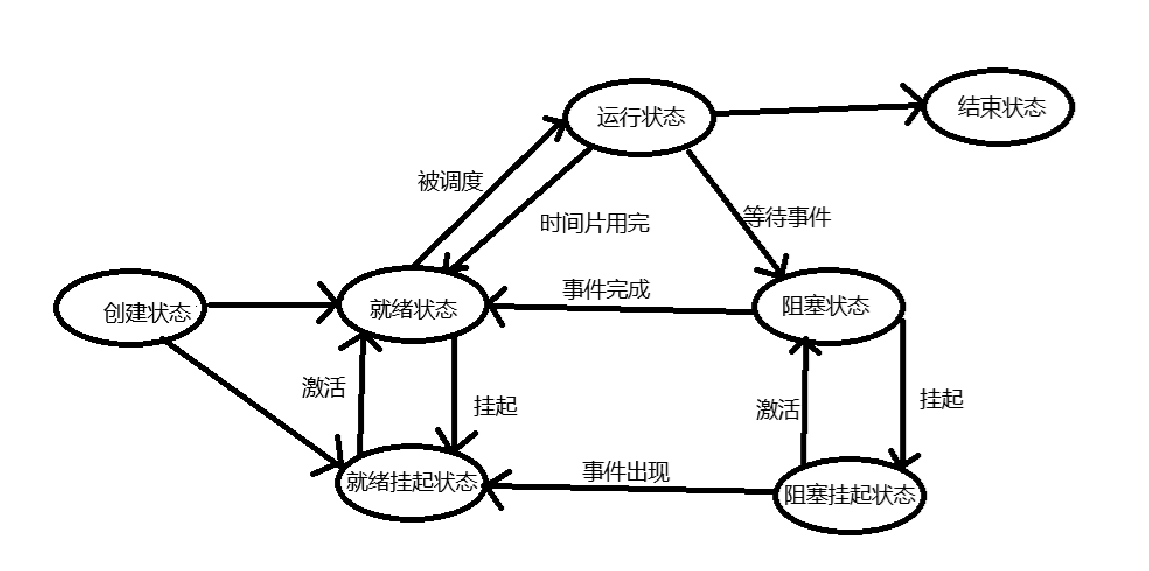 运行状态
运行状态
一个CPU会维护一个运行队列,多核CPU会有多个运行队列。资源准备就绪的进程的PCB会被链入runqueue,在运行队列中的进程的状态为running
运行队列图示:
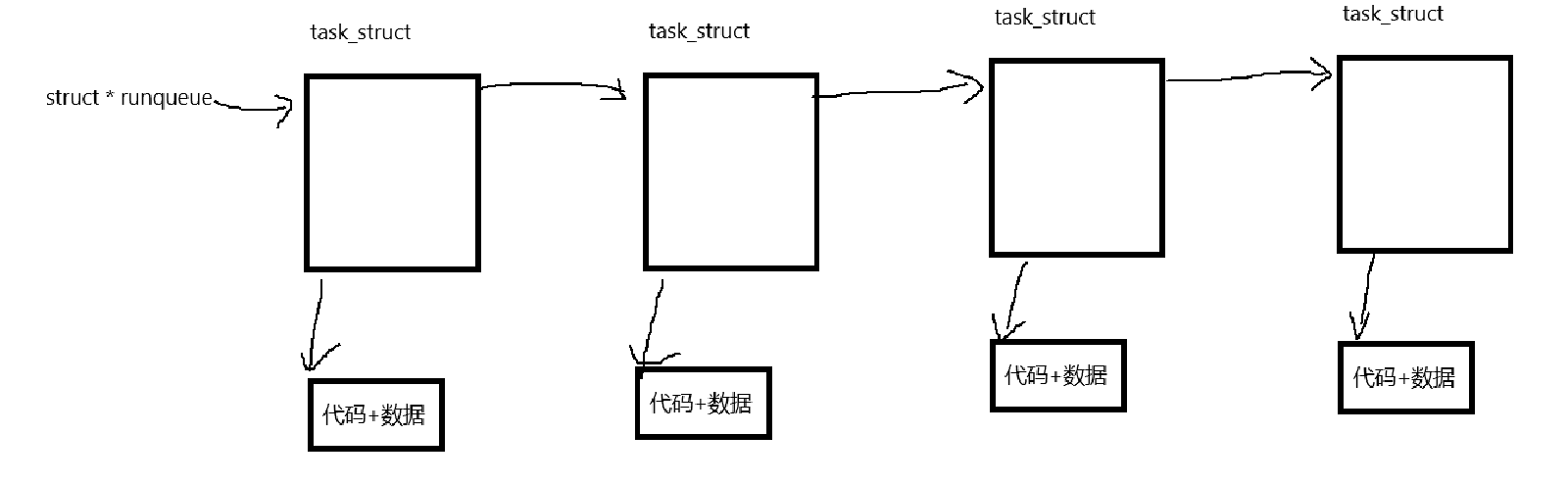
cpp
#include <linux/sched.h>
struct runqueue {
// 1. 队列锁:保护整个运行队列的并发访问
spinlock_t lock;
// 2. 绑定的CPU核心ID(关键:每个runqueue对应一个CPU)
unsigned int cpu;
// 3. 就绪进程队列:按优先级组织的链表(核心中的核心)
struct prio_array *active; // 活跃队列(时间片未用完的进程)
struct prio_array *expired; // 过期队列(时间片用完的进程)
struct prio_array arrays[2]; // 实际存储队列的数组(active/expired指向这里)
// 4. 当前在该CPU上运行的进程
struct task_struct *curr;
struct task_struct *idle; // 空闲进程(CPU无任务时运行)
// 5. 调度统计/状态
unsigned long nr_running; // 队列中就绪进程总数
unsigned long nr_switches; // 上下文切换次数
unsigned long load_weight; // CPU负载权重(用于负载均衡)
// 6. 负载均衡相关
struct migration_queue migration; // 进程迁移队列(核心间迁移任务)
int nr_migrate; // 待迁移进程数
};阻塞状态
阻塞即指进程因等待设备或资源就绪而被暂停执行的状态。操作系统通过结构化的方式(前文提到的先描述在组织)管理硬件设备:首先定义device结构体,为每个设备分配专属结构体实例,将设备相关信息存储其中,实现统一管理。
cpp
// 简化版device结构体 - 驱动开发中最常用的字段
struct device {
// 1. 设备树和层次结构
struct device *parent; // 父设备(必须设置!)
struct device_node *of_node; // 设备树节点(重要!)
// 2. 驱动模型绑定
struct bus_type *bus; // 所属总线(如pci_bus_type)
struct device_driver *driver;// 绑定的驱动
// 3. 识别信息
const char *init_name; // 设备名称
dev_t devt; // 设备号(主/次设备号)
// 4. 私有数据指针
void *platform_data; // 平台特定数据
void *driver_data; // 驱动私有数据
// 5. 设备类的kobject(sysfs基础)
struct kobject kobj;
// 6. 关键回调函数
void (*release)(struct device *dev); // 释放设备时调用
};同时在Linux中,每个设备通常会维护自己的等待队列(wait queue),用于管理等待该设备特定事件的进程。这个队列叫等待队列,在这个队列中的进程,状态为阻塞状态
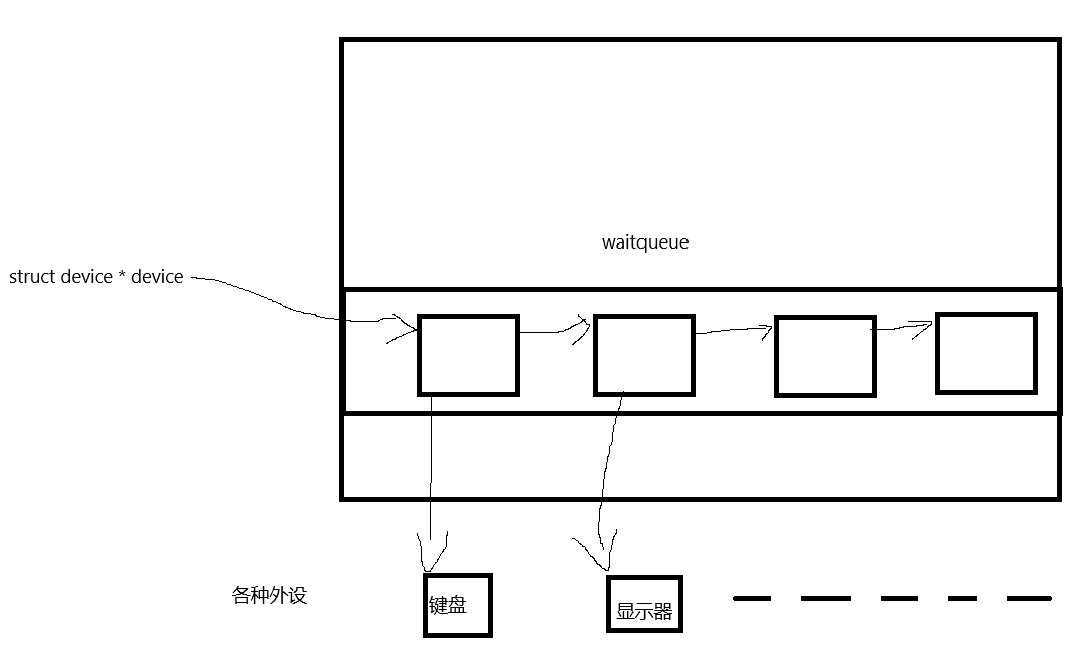
eg:一个进程中有scanf需要等待键盘输入,cpu不可能一直让这个进程干等着,空耗资源,这时OS会将这个进程从运行队列中移出,链入等待队列;OS是硬件的管理者,键盘有响应了,资源就绪了又会将此进程链入运行队列并执行。
具体步骤:
-
内核会将此进程加入键盘设备驱动的等待队列中
-
将进程状态设置为阻塞状态
-
从运行队列中移出
-
CPU可以调度其他进程执行
当键盘有输入时,键盘驱动会:
-
接收硬件中断
-
从键盘设备的等待队列中唤醒等待的进程
-
将进程状态改回就绪状态
-
重新加入运行队列等待调度
挂起状态
挂起状态一般出现在一些资源告急的情况,挂起状态分为运行挂起和阻塞挂起,我们先来谈阻塞挂起。
阻塞挂起
阻塞挂起,我初学听这个名词和运行挂起一下子就被吓到了,怕分不清。阻塞挂起,有一个前提是阻塞,当内存中资源告警时,等待队列在内存中,暂时可能用不是,OS作为管理者,会将暂时不那么紧急的进程移到磁盘(外设)中,方便其它急需内存资源的进程。这个将进程从等待队列中删除,保存到磁盘中的这个过程叫做唤出。被唤出到的这个磁盘区域叫swap交换分区(Swap Partition :交换分区是硬盘(磁盘)上专门划分出来的一块区域,用于扩展内存。当物理内存(RAM)不足时,操作系统会将暂时不用的内存数据移出(换出) 到交换分区,从而释放RAM给急需的进程使用)。当进程等待外设或资源就绪时,进程又会被链入到运行队列中执行。从swap交换区到运行队列的这个过程叫唤入。
运行挂起
理解了阻塞挂起,运行挂起手到擒来,当内存紧缺到极致时,在运行队列靠后的部分进程也会被唤出到swap交换区中。当进程等待外设或资源就绪时,进程又会被链入到运行队列中执行。
从上面内容基本可以看出:所谓的进程状态的切换就是进程PCB在不同队列中切换。
内核链表
之前我们讨论过运行队列和等待队列,这两个数据结构都以进程的PCB作为节点。那么PCB如何能够同时存在于多个数据结构中呢?这就要借助内核链表机制来实现。
内核链表的优势
当然不使用list_head我们也能在功能上实现,将PCB放进多个数据结构。
cpp
// 灾难版本:每个队列都需要独立实现
struct task_struct {
// 1. 运行队列需要的指针
struct task_struct *run_next;
struct task_struct *run_prev;
// 2. 等待队列需要的指针
struct task_struct *wait_next;
struct task_struct *wait_prev;
// 3. 所有进程链表需要的指针
struct task_struct *tasks_next;
struct task_struct *tasks_prev;
// 4. 进程组链表需要的指针
struct task_struct *pgrp_next;
struct task_struct *pgrp_prev;
// 进程实际数据
int pid;
// ... 还有几十个字段
};
// 每个队列都需要独立的操作函数!
// 运行队列操作
void run_queue_add(struct task_struct *new, struct task_struct *head) {
// 专门操作run_next/run_prev
new->run_next = head->run_next;
new->run_prev = head;
head->run_next->run_prev = new;
head->run_next = new;
}
// 等待队列操作(几乎相同的代码!)
void wait_queue_add(struct task_struct *new, struct task_struct *head) {
// 专门操作wait_next/wait_prev
new->wait_next = head->wait_next;
new->wait_prev = head;
head->wait_next->wait_prev = new;
head->wait_next = new;
}
// 重复 × N 次!这样有什么问题?
代码行数:每个队列一套代码 × N个队列
维护成本:修改链表算法要改N个地方
内存浪费:每个指针8字节 × 8个指针 = 64字节
容易出错:操作run队列时误用wait指针。(容易记混指针的名字)
我们的知道这样的代码在行业中是无法忍受的,是没有水平的,我们要遵循高内聚,低耦合的设计原则。很多PCB需要在多个数据结构中被串起来,我们将这个粘合PCB的功能独立为一个模块,这个模块就是list_head。
cpp
// 通用链表节点(包含在数据结构中)
struct list_head {
struct list_head *next, *prev;
};
// 内嵌在具体结构中
struct task_struct {
// ... 进程数据
struct list_head tasks; // 所有进程链表
struct list_head children; // 子进程链表
struct list_head sibling; // 兄弟链表
// 一个结构可以有多个链表!
};
struct inode {
// ... inode数据
struct list_head i_list; // inode链表
struct list_head i_sb_list; // 超级块链表
};区分内核链表和普通链表
cpp
struct Node
{
int data;
struct Node* next;
struct Node* prev;
};平时我们使用的双链表是这样的,这样不论prev还是next都指向的是一个节点开头的地址。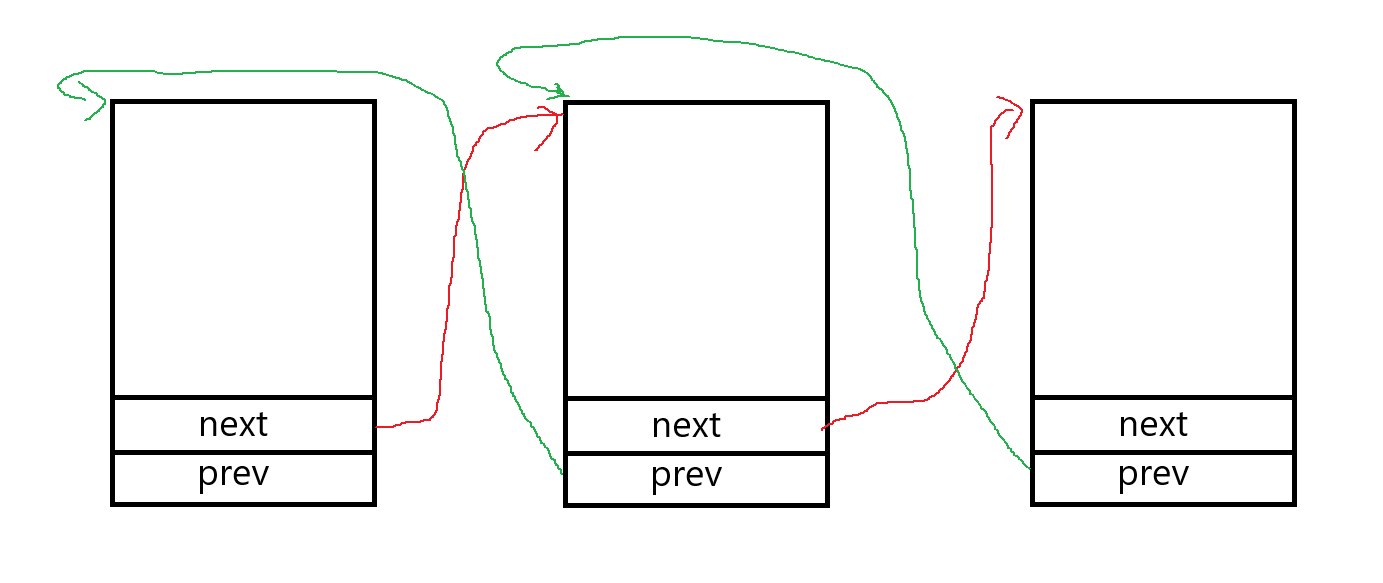
list_head的实现却和它们有所不同,每一个内核链表的next直接指向下一个节点的next,prev指向下一个节点的prev。
cpp
struct list_head
{
struct list_head* next, *prev;
};
struct task_struct
{
int x;
int y;
list_head links;
};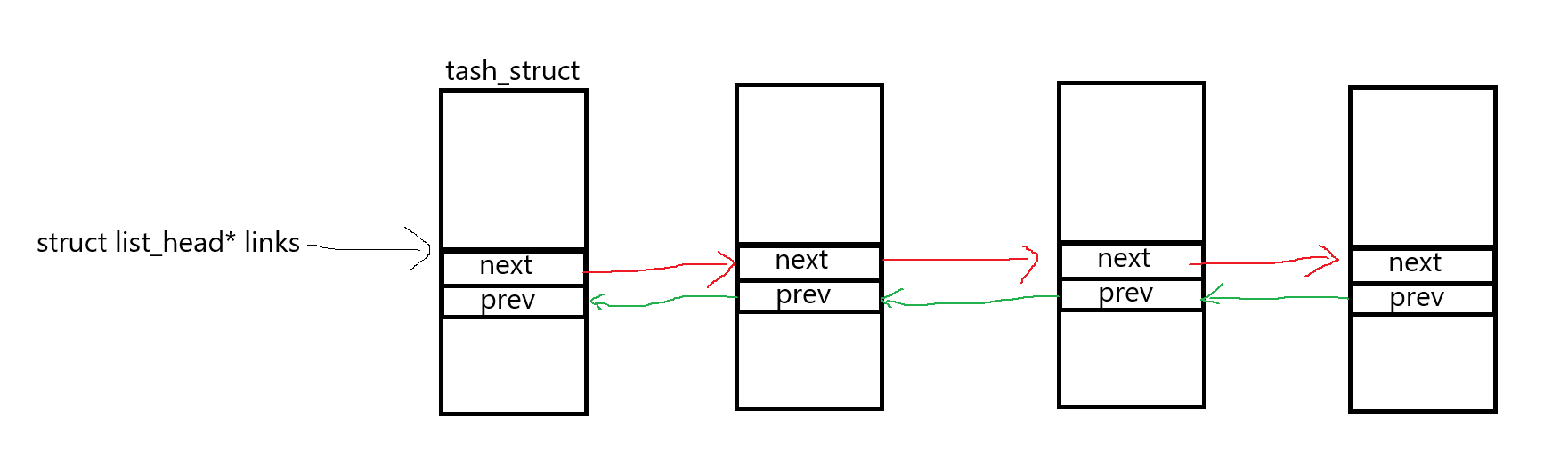
此时我们需要思考:既然使用指针的最终目的是解引用访问指向的资源,那么在内核链表设计中,指针指向的是结构体成员而非整个结构体,如何通过这个成员指针访问task_struct中的其他资源呢?
偏移量
父结构地址 = 成员地址 - 成员偏移量
&((struct task_struct*)0->links)假设结构体地址从零开始,这一样就可以求出links这个成员相对0的偏移量,在取next指针的减去偏移量,就是节点开头的地址。通过偏移量就可以在不同队列直接切换。
用数学公式表示:
设:
A = struct task_struct 的地址(我们想求的)
M = &a.links(已知的成员地址)
offset = offsetof(struct task_struct, links)
则:
A = M - offset