这篇介绍利用Transformer结构进行目标检测的工作,首先需要了解计算机视觉中Transformer结构的基础用法,可以看:深度学习基础-5 注意力机制和Transformer,目标检测相关介绍可以看:计算机视觉-目标检测,如果不了解卷积神经网络,可以看:深度学习基础-3 卷积神经网络。
利用Transformer进行目标检测,首先就要问几个问题,CNN处理目标检测任务已经很好了,为什么还需要Transformer架构的目标检测模型?Transformer架构的目标检测模型相比于以往CNN架构的目标检测模型究竟有什么优点,又有什么缺点?









一 DETR
原论文:《End-to-End Object Detection with Transformers》
DETR从"集合预测"的角度重新看待目标检测问题,以往基于CNN的目标检测模型,无论是两阶段的Faster RCNN系列,还是单阶段的YOLO系列,本质上是基于滑动窗口特征预测的方式,其目标检测流程是"这里好像有个目标物体,物体的类别是***" ,像一群盲人摸象,每个人只摸一小块,然后各自报告"我摸到的是腿/耳朵/尾巴",最后靠一个"裁判"(NMS)来合并不同人的说法,而DETR是基于集合匹配的思想,让Transformer模型直接输出输入图像具有的目标集合,省去传统CNN结构目标检测任务中的NMS等后处理步骤,其目标检测流程是"我这里有N个物体,你在图像中找找它们在哪里",像一位画家看一眼整幅画,直接说:"图中有 3 个物体:一个人、一辆车、一棵树",并指出它们的位置,不需要逐像素扫描,也不需要事后删重复。DETR整体流程如下:
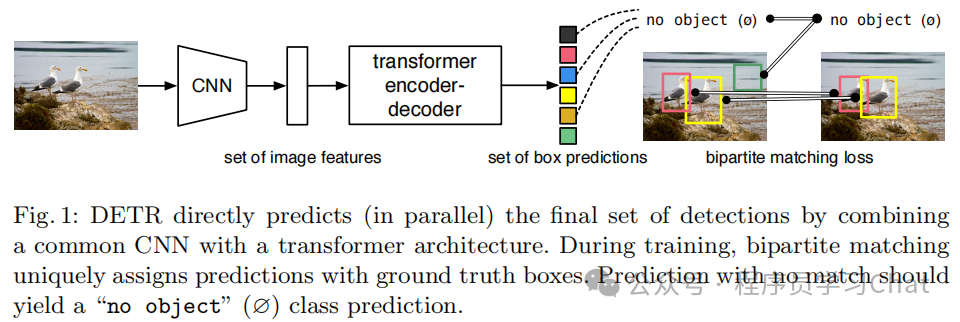
首先利用CNN对图像进行特征提取,将CNN得到的特征图作为序列元素,输入到Transofrmer的Encoder中进行特征编码,Decoder根据Encoder的特征编码结果直接解码出图像中具有哪些物体以及物体的位置,模型具体结构如下:
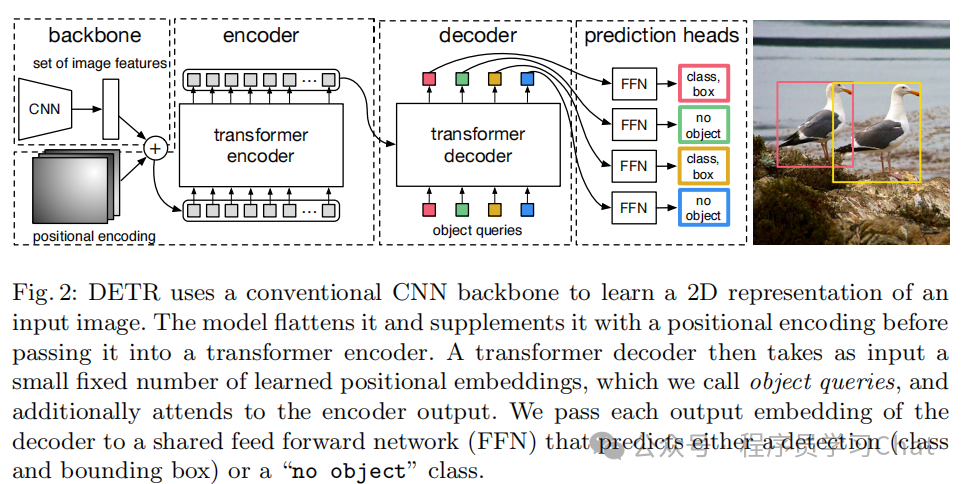
1.1 Encoder如何对特征编码
CNN输出的特征图维度是c,h,w,其中c是特征图通道数、h是特征图高度、w是特征图高度,而Transformer的Encoder要求输入是一个N,d-model的嵌入矩阵,N位序列长度、d-model是嵌入向量维度,如何进行转换?
DETR的做法是先利用1*1d 卷积对c,h,w特征图进行降维,变为d,h,w,然后将空间维度合并,变为d,h\*w,然后调换维度顺序变为h\*w,d,这样就满足Encoder的N,d-model的输入维度要求了,也就是现在序列长度N=h*w,嵌入维度d-model=d,注意这里有个细节问题,为什么序列长度是h*w,而不是d?这个问题一定要想明白。
CNN输出的特征图c,h,w,可以想象为是c张h*w大小的A4纸摞在一起,每张A4纸代表从某个角度对输入图像的特征表示,所以称为特征图,例如某个特征图可能是输入图像的纹理表示,如果想将这个c,h,w的特征图转换为序列元素输入到Transformer的Encoder中,一个最自然的想法是,将每个A4纸撕成纸条,拼成一个长的纸条,也是将h,w这个矩阵进行向量化,变成1,h\*w的向量,这样原先c,h,w的特征图,现在就变成c个h*w的向量,序列长度是c,向量嵌入维度是h*w,但是DETR没有这么做,DETR是将h*w作为序列长度,c作为向量嵌入维度,也就是DETR的做法不是撕纸条拼接,而是从上到下,挖取这摞c张h*w的A4,它是用一个长度为c的收纳容器,从上到下挖取h*w每个位置,每个位置产生一个1,c的序列元素,一定要理解这种每张A4纸"撕"和对这摞A4纸从上到下"挖"的区别,那么为什么要这么做呢





同样因为Transformer是位置不敏感的,需要为特征图的序列表示h\*w,c添加一个位置编码


之后就是Encoder的标准流程进行特征编码。
1.2 Decoder如何解码出目标
最初Transformer的Decoder的输入是原始训练数据output的整体右移一位(不清楚可以看:深度学习基础-5 注意力机制和Transformer)+Encoder的特征编码信息,Decoder结合这些信息,预测下一个词语,所以Decoder的输入可以看做是一种查询要求,"上个词语是这个,帮我解码(查询)一下下个词语最可能是什么"。DETR也利用了这种查询的想法,"帮我查询一下,这个物体在图像中对应是什么类别、位置在哪里",DETR称这个查询为"object query",object query是一个可学习组件,预先是不知道每个object query具体数值的,具体数值是随着DETR整体在目标检测数据集上训练得到的,为什么要引入"object query"这个可学习组件





将Encoder的输出和object query输入到Decoder中,Decoder对于每个object query的解码结果,表示这是什么物体以及所处图像位置



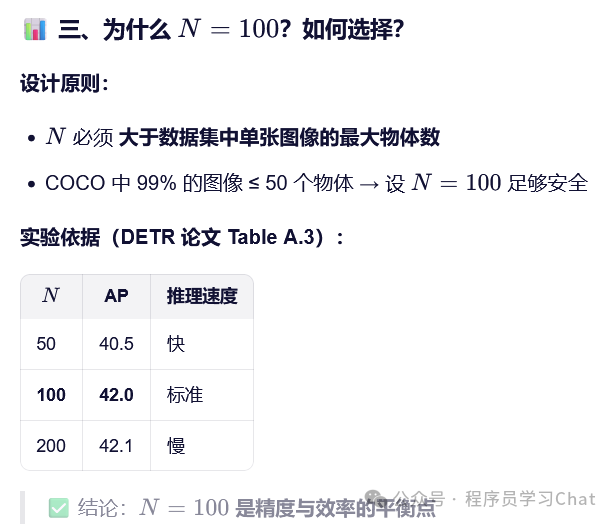

1.3 损失函数
Decoder根据输入的N个object query,在图像中寻找每个object query对应的物体类别和所在位置,N是固定的,大于一张图像中最多出现的目标物体个数就可以,在coco目标检测训练数据集上DETR设置N=100,那么就有一个问题,Decoder输出一直是100个预测,而真实输入图像上可能只有2个物体,怎么计算预测损失训练网络呢?DETR的做法是对预测结果和真实标记框进行一对一的匹配,因为真正只有两个物体,那就让100个里面预测到这两个物体的结果和真实标记框信息匹配上,然后可以计算分类损失和标记框损失,剩余的98个预测必须预测为"空",也就是没在图像上找到对应目标,这样才能计算损失训练网络。
使用的一对一匹配算法是"匈牙利算法",一种离散问题优化算法


匈牙利算法目的是寻找一个预测框和真实框之间的一个最优排列

















二 Deformable DETR
原论文:《DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION》
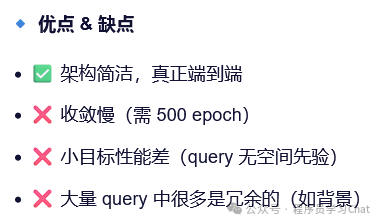
DETR:
1)训练慢
2)对于小目标预测效果较差
训练缓慢是因为注意力机制本身的复杂度和序列长度平方成正比,小目标预测效果差是因为只使用了最后一个尺度特征图进行Encoder编码。
Deformable DETR针对这两个问题做出了改进,利用可分离注意力机制代替以往的注意力机制,解决计算缓慢的问题,利用多尺度可分离注意力解决小目标检测效果差的问题。
2.1 可分离注意力
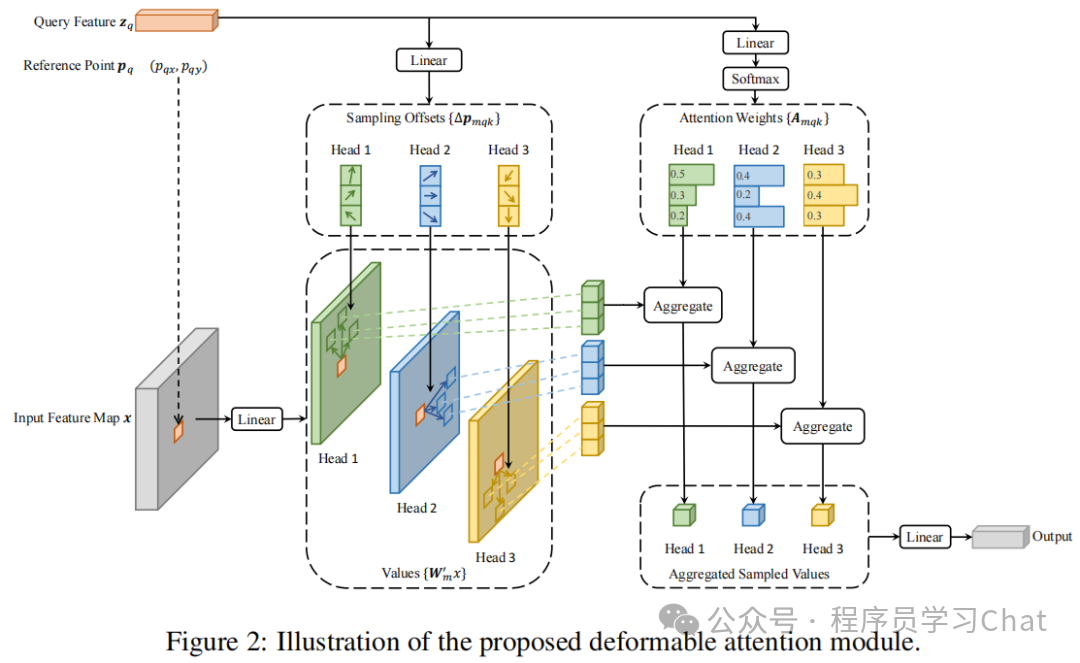
这部分如果只看论文里的公式介绍很晦涩

下面逐步说可分离注意力到底在做什么
传统注意力机制对于输入的特征图c,h,w,会将其变为h\*w,c的序列元素,然后这个矩阵线性投影变为Q、K、V进行多头注意力计算,计算复杂度和h*w的平方成正比。
可分离注意力将h\*w,c中每个元素作为q,q不和其它(h*w-1)个元素都进行注意力计算,而是将q输入到一个FFN中,FFN预测出q的采样点位置,q只和这些采样点位置处的元素进行注意力计算,但是这种注意力计算不是以往通过内积的方式,而是通过FFN直接预测出对应的注意力权重,所以整体流程是取特征图h\*w,c某个位置处1,c维度的q,将其输入到一个FFN中,预测出对应的采样点位置、和采样权重,取出采样点位置的元素,用对应的采样权重对这些元素进行加权求和,作为最终的可分离注意力计算结果,再放回原q的位置处,替换原先的1,c向量,所有h*w个位置处的q都这样替换,就得到这个特征图h\*w,c的可分离注意力计算结果。











为什么在计算的过程中需要双线性插值获取对应采样点处的元素值

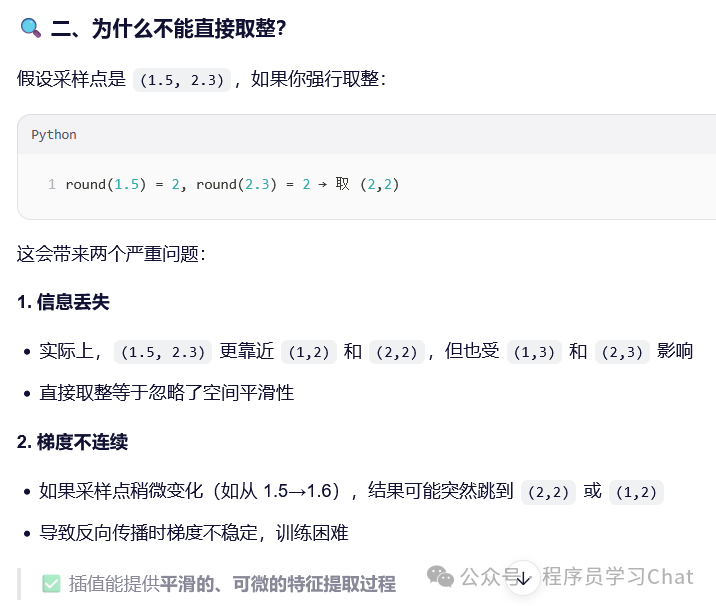



2.2 多尺度可分离注意力
可分离注意力解决了以往注意力机制计算低效的问题,多尺度可分离注意力解决小目标检测效果不好的问题
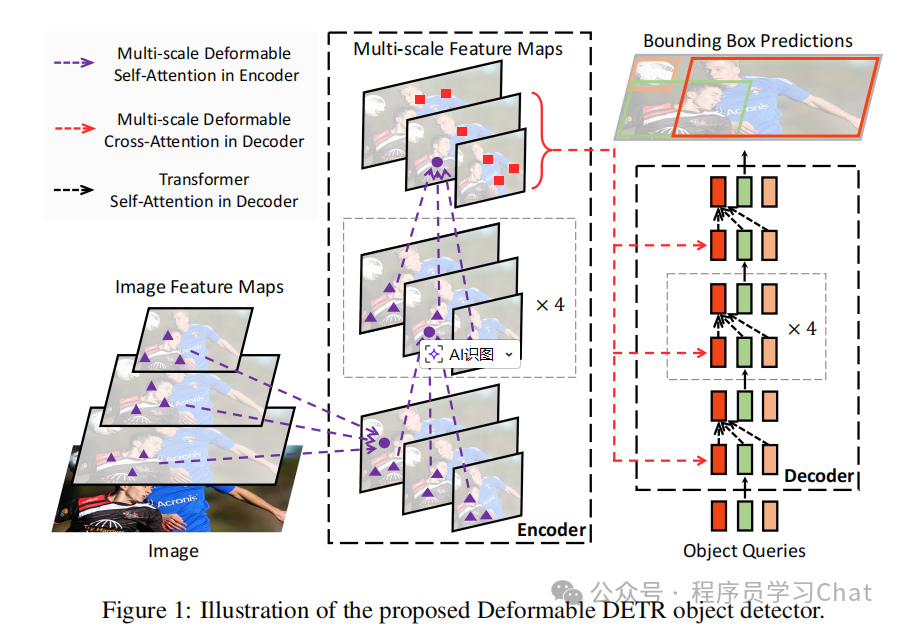

依旧很晦涩,可能这种可分离注意力数学描述起来就是不怎么友好。
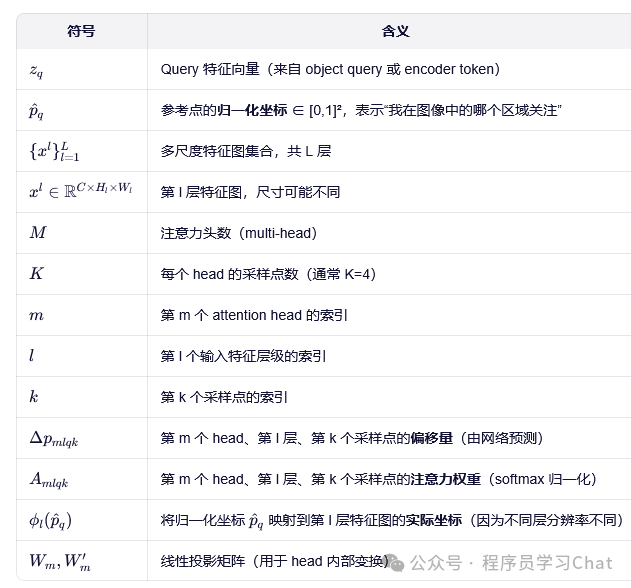
可分离注意力是针对单一特征图h\*w,c中的q进行计算,多尺度可分离注意力和可分离注意力的区别是,q的采样点是在多个尺度的特征图上同时获取的,也就是可分离注意力是只在h\*w,c的对应采样点位置处获取元素,而多尺度可分离注意力会获取不同尺度特征图对应采样点位置处的元素和q进行注意力计算,同样这种注意力计算的注意力权重还是通过网络直接预测出来的,而不是通过内积计算的方式获取到的。
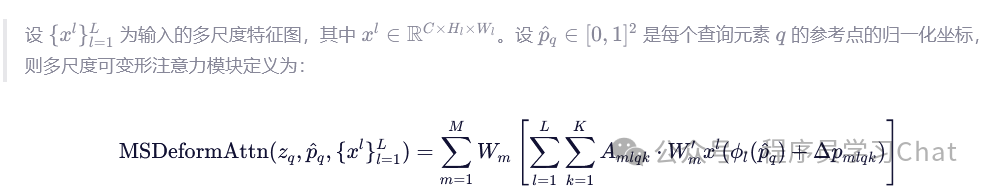
三 RT-DETR
原论文:《DETRs Beat YOLOs on Real-time Object Detection》
RT-DETR可以类比为DETR中的YOLO,使得DETR检测速度可以更准更快。
了解RT-DETR之前先说一下DETR中的one-stage和two-stage






RT-DETR就属于tow-stage DETR,它的object query是从Encoder中筛选出来的,而不是像传统DETR是一个固定个数的向量。



RT-DETR只对多尺度特征图最高层的特征图进行注意力计算,从而加速计算,通过多尺度融合提升小目标检测效果,整体结构如下:
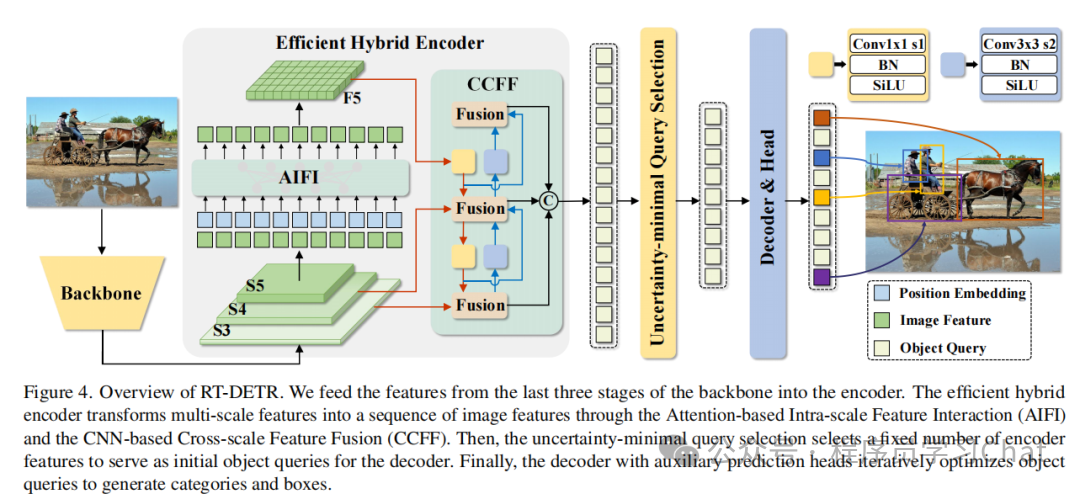
为什么只在最后一个特征图上进行注意力计算



通过多尺度特征融合模块,融合不同尺度的特征,结构如下:
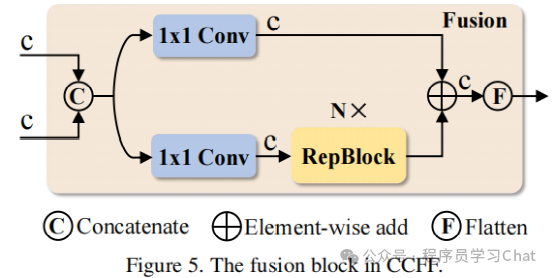


为什么需要特征融合呢

对于Encoder输出的特征编码,以往的query选择方法是选择分类概率最大的作为Decoder的Object query,但是这种方式可能导致选择到分类准确但是位置定位异常的query,从而影响整体检测性能

RT-DETR重新定义了query选择衡量的准则-不确定性

那么如何根据Encoder的特征编码得到这些类别分布和bbox分布呢





