此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本周为第四课的第四周内容,这一课所有内容的中心只有一个:计算机视觉 。应用在深度学习里,就是专门用来进行图学习的模型和技术,是在之前全连接基础上的"特化",也是相关专业里的一个重要研究大类。
这一整节课都存在大量需要反复理解的内容和机器学习、数学基础。 因此我会尽可能的补足基础,用比喻和实例来演示每个部分,从而帮助理解。
第四周的内容是对前三周内容的综合应用,介绍了一些通过卷积网络实现的实际应用,它们在使用卷积网络的基础上又各有自己的特点来匹配不同的任务要求,是对如何真实应用卷积网络 的良好演示。
本篇的内容关于人脸识别。
1. 人脸验证与人脸识别
人脸验证和人脸识别是两个相似的概念。
而在人脸识别系统中,我们说人脸验证是人脸识别的一个基本模块 。
现在就来展开一下二者的关系:
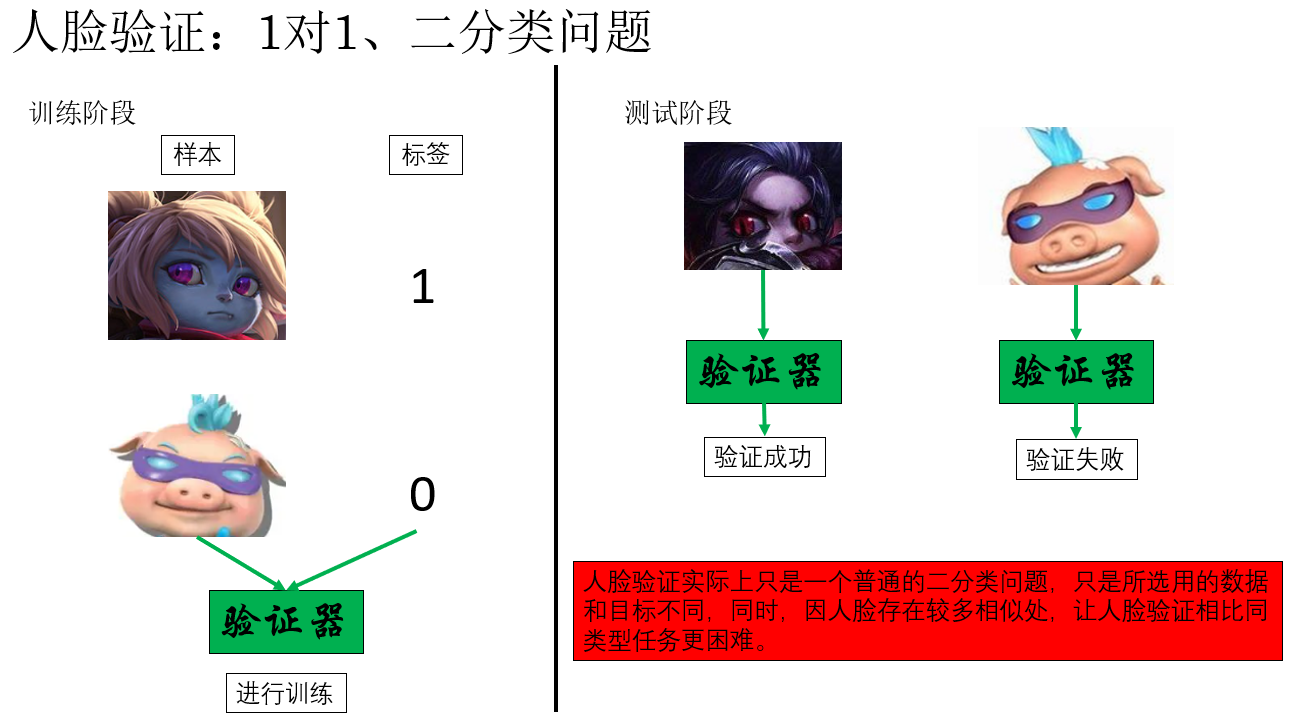
我们在图里提到人脸验证是一个1对1问题 ,这是因为在假定验证器完全准确的情况下,它只会对一个人说 "Yes" 而拒绝其他所有人。
很显然,这种逻辑在我们实际生活中的大多场景都不适用,公司、宿舍的门禁等都支持通过一个模型识别多个人。而不是为每个人单独设置一个闸机。
因此,我们便称这种实现"1对多"逻辑的相应任务为人脸识别 。
按照刚才的逻辑推下去,一个很自然、也很"机器学习直觉"的想法是:那人脸识别不就是一个多分类问题吗? 像这样:
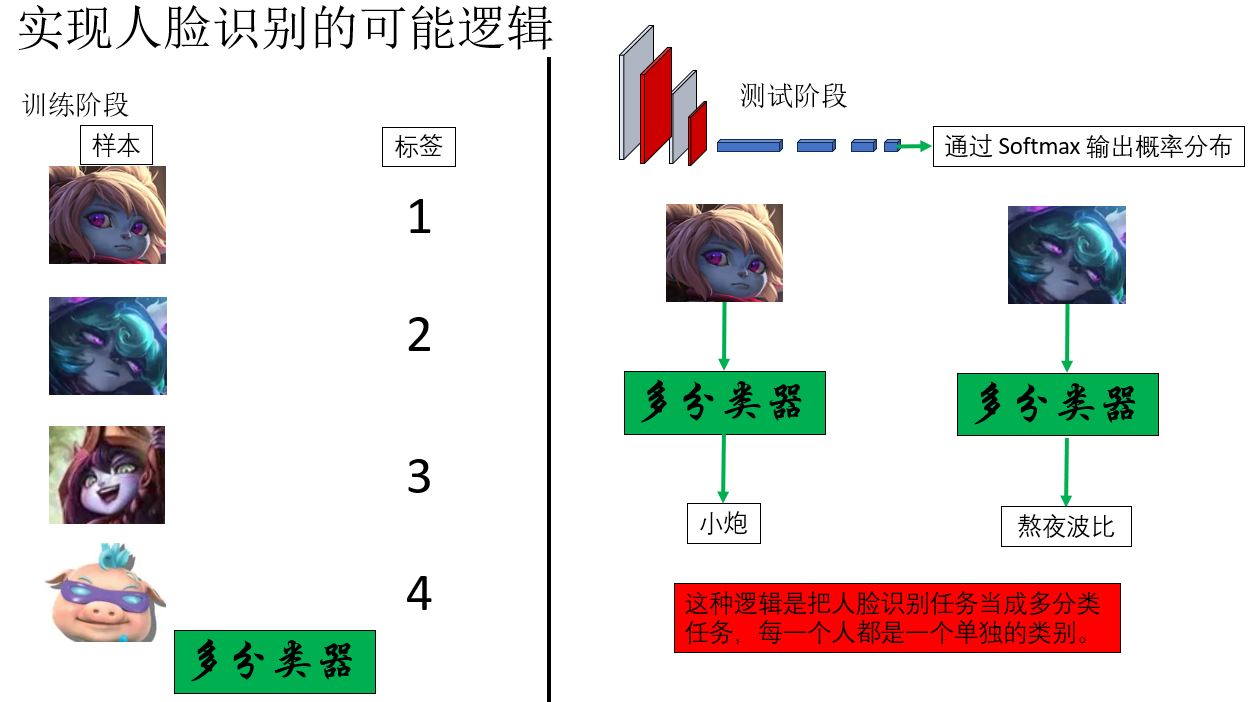
但如果在实际部署中这样实现人脸识别,你会发现这样一些问题:
- 如果单位有新员工加入或老员工离职,就要重新调整数据和网络输出层,重新训练。
- 当单位规模较大时,数据可能包含成千上万个类别 。更重要的是,每个类别数据量很少,而深度学习往往又依赖于数据量,难道办理入职要先拍几百几千张照片吗?
因此,我们得出结论:因为人脸识别任务在实际部署中的特殊性,让我们之前了解的常规分类算法并不适用作为一个可持续部署方案对其应用。
而在现实生活中,你会发现,我们在相关系统录入人脸时,往往只需要一张证件照即可,这是怎么做到的呢?我们继续。
2. 一次学习(one-shot learning)
继续刚刚的内容,我们会发现一个看似矛盾的现象:
在实际的人脸系统中,录入一个新用户时,往往只需要一张证件照 。但在深度学习的经验认知里,模型性能又高度依赖数据量。 这两点,不冲突吗?
要理解这一点,我们需要先回到刚才"把人脸识别当作多分类问题"的思路。
在标准的多分类任务中,分类标签本身就为数据划分了明确的边界 :模型只能通过同一标签下的样本 来学习该类别的特征,而不同类别之间的数据是被严格隔离使用的。
正因为如此,如果将人脸识别直接建模为"每个人一个类别",那么模型要学好某一个人的特征,就必然需要大量属于这个人的样本------也就出现了"要给每个人拍写真集"的不现实要求。
但是,你会发现:在人脸识别任务中,总的数据量其实并不少 ,真正稀缺的只是"每个身份对应的样本数量"。这意味着,并不是"数据不够",而是数据被标签强行分割后,无法被充分利用。
正是由于这种设置与实际部署场景不匹配,我们自然会产生一个新的疑问:能不能让所有人的样本都参与学习,而不是被身份标签各自隔离开来?
在机器学习中,这类"每个类别只有极少样本 "的问题被称为一次学习(one-shot learning)问题 。
而在具体的人脸识别场景下,one-shot 人脸识别指的是:每个身份在训练或建库阶段,仅提供一张(或极少几张)已知人脸样本。
为了解决这种"总体样本量很大,但单个身份样本极少 "的矛盾,人们提出了一种不同于传统分类的思路: 不再让模型回答"这张脸属于所有人中的哪一个?",而是让它判断"这张脸是否和某一个已知的某张脸足够相似?"
现在,网络目标就从一开始的"学习分类"变成了"学相似度 ",就像这样:
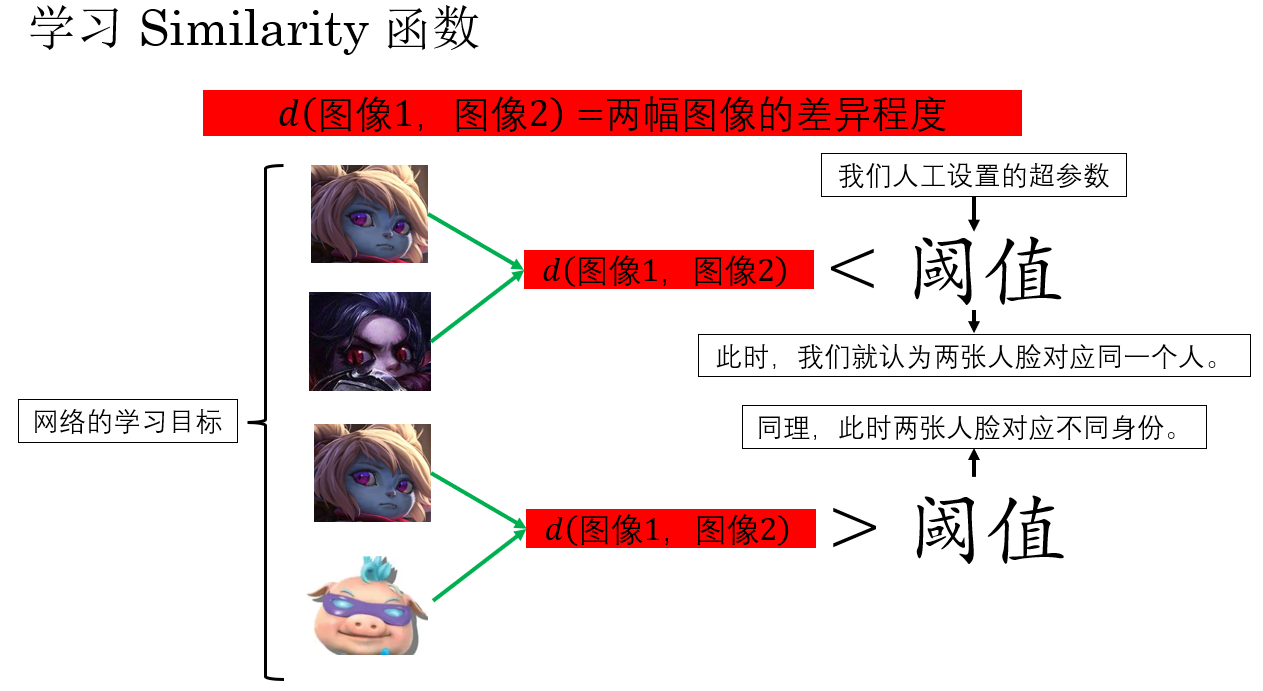
如果如图中这样,网络实现了"学习两张人脸的相似度",我们就解决了刚刚的问题:
- 如果单位有新员工加入或老员工离职,就要不再需要调整网络和重新训练,只需要把相应数据加入数据库或从数据库中删除。
- 所有的数据都被充分利用,同时每人只需要一张证件照,在门禁时人脸和数据库中的人脸对比,找到满足相似度阈值的样本即通过,不存在即拒绝。
3. Siamese 网络
现在,我们明确了针对面部识别任务的目标:训练一个可以学习两张人脸相似度的网络 。
现在,要怎么实现这一点呢?
答案就是这部分的标题:Siamese 网络。
要说明的是,吴恩达老师在课程里提到了一篇 2014 年的论文 DeepFace: Closing the Gap to Human-Level Performance in Face Verification。但 Siamese 网络并不是从这篇论文才提出的 ------早在 1993 年,它就被发明出来,用于判断两幅手写签名是否同一人。后来也被应用到人脸识别任务中。
Siamese 网络的核心思路是通过共享权重的双分支(或多分支)神经网络,将输入的两张图像映射到同一特征空间,然后通过度量函数(如欧氏距离或余弦相似度)计算它们的相似度 。
DeepFace 借鉴了 Siamese 网络的思路,在深度 CNN 上直接学习人脸特征的相似度,并通过优化和大规模训练,这才使得系统性能接近人类水平,真正具备部署价值。
现在,就来详细看看一个较完善的 Siamese 网络的运行过程:
3.1 对图像进行编码处理:三元组损失(triplet loss)
我们先来看看什么叫对图像进行编码处理:
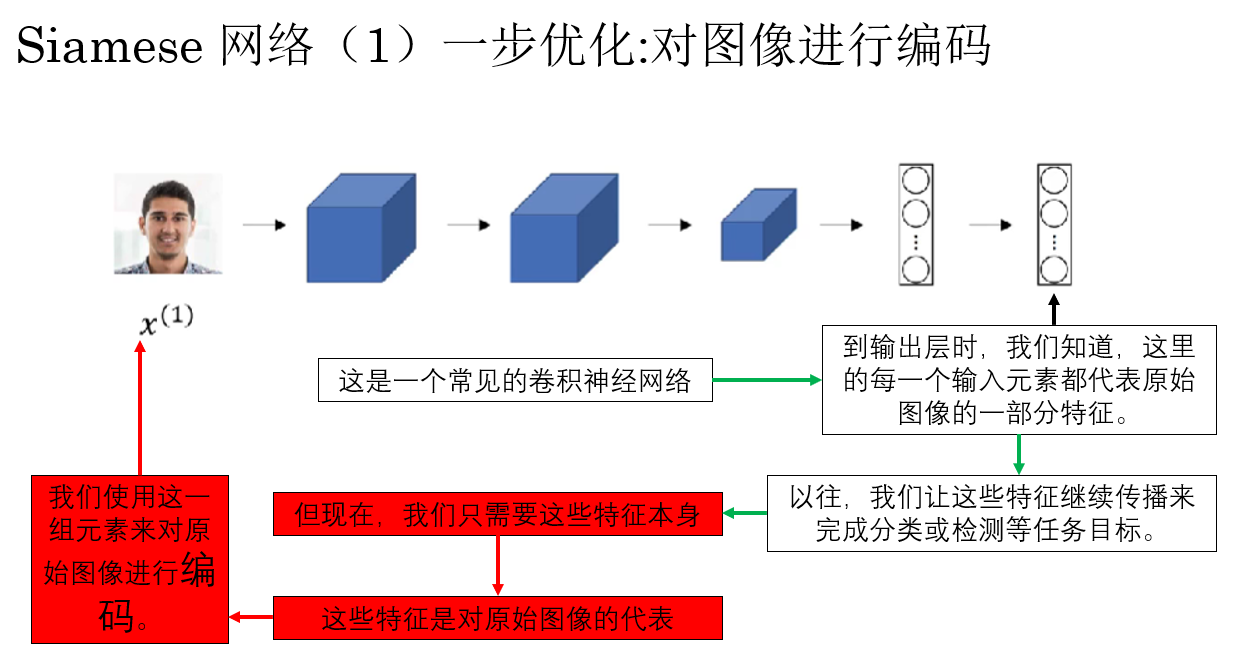
这样,我们就可以使用一组特征向量来编码一张人脸,实际上,这就是 DeepFace 提出的一步优化,这一步设置不止为了计算相似度作准备,同时也极大减少了计算量,缩短了运行时间,可以说相当成功。
但是,同样也是因为这一步编码,新的问题出现了:你会发现,这个用来把图像转换成编码的网络同样需要训练。
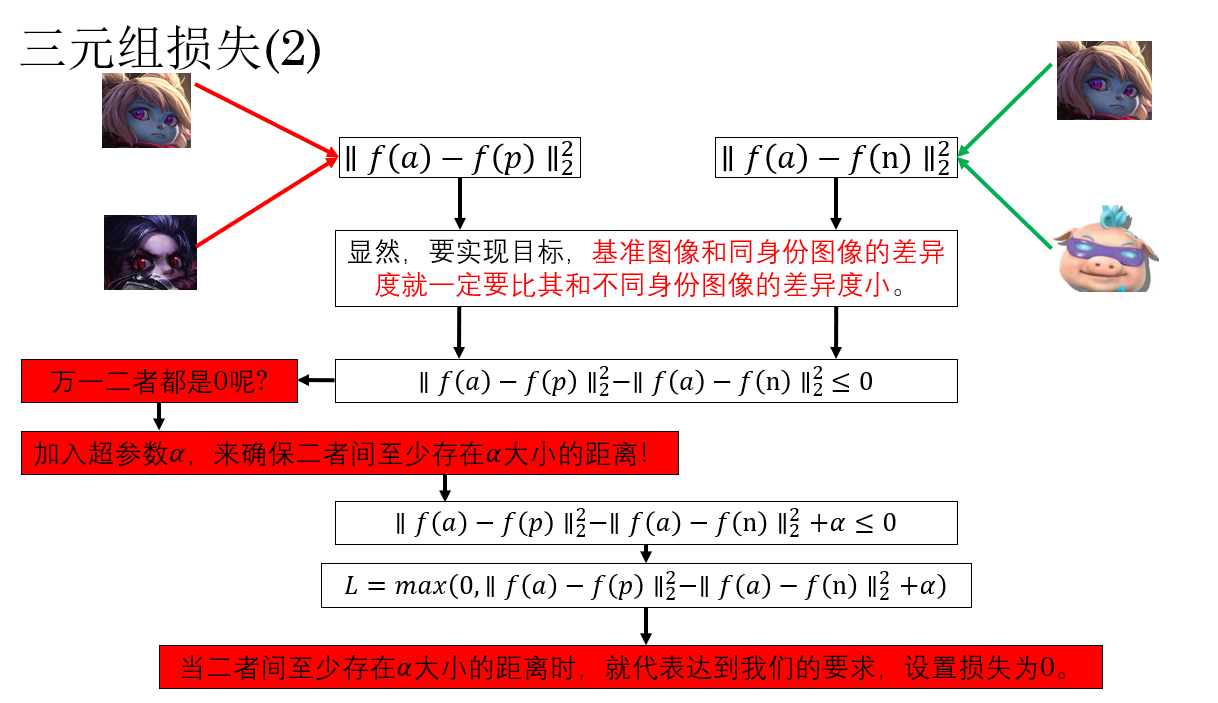
没错,我们需要训练这个网络,而目标就是:让同一个身份的人脸编码差异最小化,不同身份的人脸的编码差异最大化。
要实现这个目标的常用方法叫做三元组(triplet)损失 ,这时,网络在训练阶段需要同时输入三张图像 。
它的公式长这个样:
\L=max(0,∥f(a)−f(p)∥\^2_2−∥f(a)−f(n)∥\^2_2+α) \\
其中:
- \(f(a)\):anchor(基准图像)映射后的特征向量
- \(f(p)\):positive(同一身份的图像)映射后的特征向量
- \(f(n)\):negative(不同身份的图像)映射后的特征向量
- \(\alpha\):间隔(margin),保证不同身份的距离比同一身份距离至少大 \(\alpha\)
别慌,我们用一个例子来演示一遍原理:
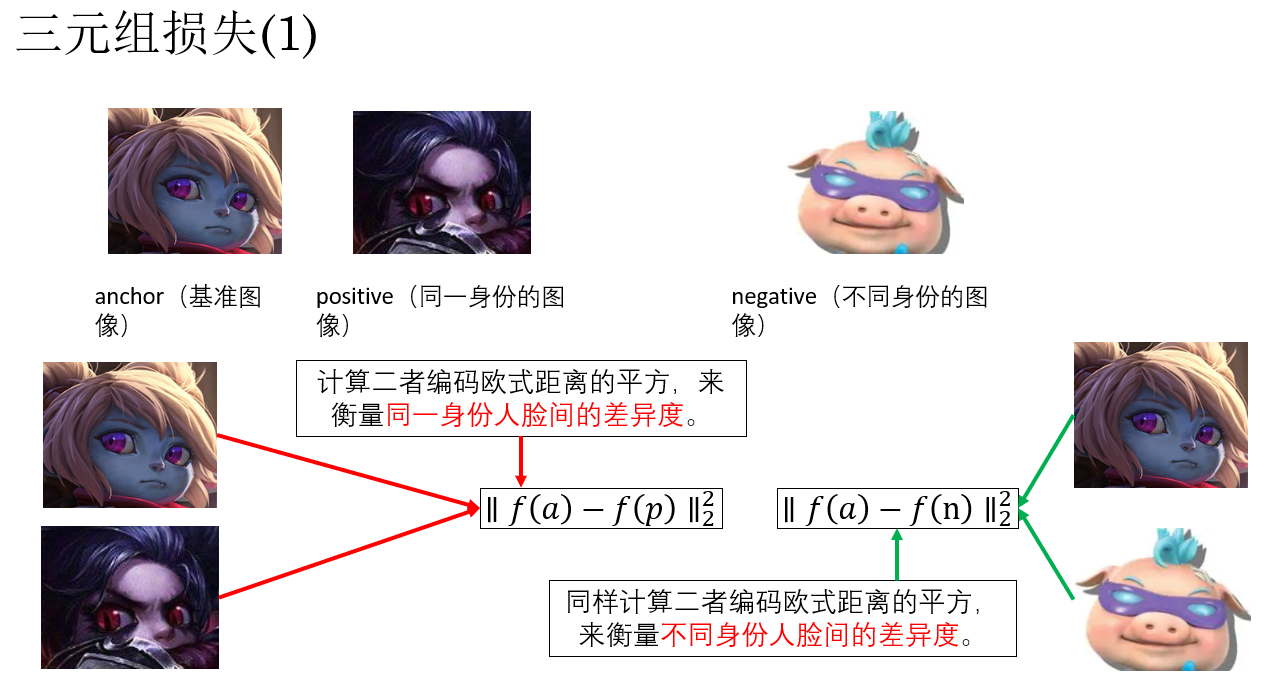
只看符号可能有些太绕了,我们再来看一个实例 :
假设三张人脸图像:经过网络映射后的二维特征向量如下:
| 图像 | 特征向量 |
|---|---|
| a (Alice) | 1.0, 1.0 |
| p (Alice) | 1.2, 1.1 |
| n (Bob) | 2.5, 2.0 |
(1)计算欧氏距离
Anchor 与 Positive(同一人):
\∥f(a)-f(p)∥_2\^2 = (1.0-1.2)\^2 + (1.0-1.1)\^2 = 0.04 + 0.01 = 0.05 \\
Anchor 与 Negative(不同人):
\∥f(a)-f(n)∥_2\^2 = (1.0-2.5)\^2 + (1.0-2.0)\^2 = 2.25 + 1.0 = 3.25 \\
(2)代入三元组损失公式
假设 \(\alpha = 0.5\),代入数值:
\L = \\max\\Big(0,0.05 - 3.25 + 0.5\\Big) = \\max(0, -2.7) = 0 \\
代表当前特征向量满足目标,同一人距离接近,不同人距离大于 \(\alpha\)。
(3)如果 Negative 太近
假设 \(f(n) = 1.5, 1.3\),计算距离:
\∥f(a)-f(n)∥_2\^2 = (1.0-1.5)\^2 + (1.0-1.3)\^2 = 0.25 + 0.09 = 0.34 \\
损失为:
\L = \\max\\Big(0, 0.05 - 0.34 + 0.5\\Big) = \\max(0, 0.21) = 0.21 \\
便说明不同人距离太近,网络需要更新,保留损失来进行反向传播。
通过这种设计,网络可以直接学习一个适合度量相似度的特征空间。
最后要强调的一点是,为了让训练效果更好,我们在选择三元组时,会尽量让基准图像和同一人的图像差别尽可能大,同时让基准图像和不同人的图像差别尽可能小。
这就像是在手动提高考试难度,难题会了,简单题自然不在话下。
现在,我们便继续下一部分。
3.2 正向传播两幅图像并计算相似度
在拥有了可以对图像进行合适编码的网络后,我们便可以进行相似度计算的应用,这一步的过程是这样的:
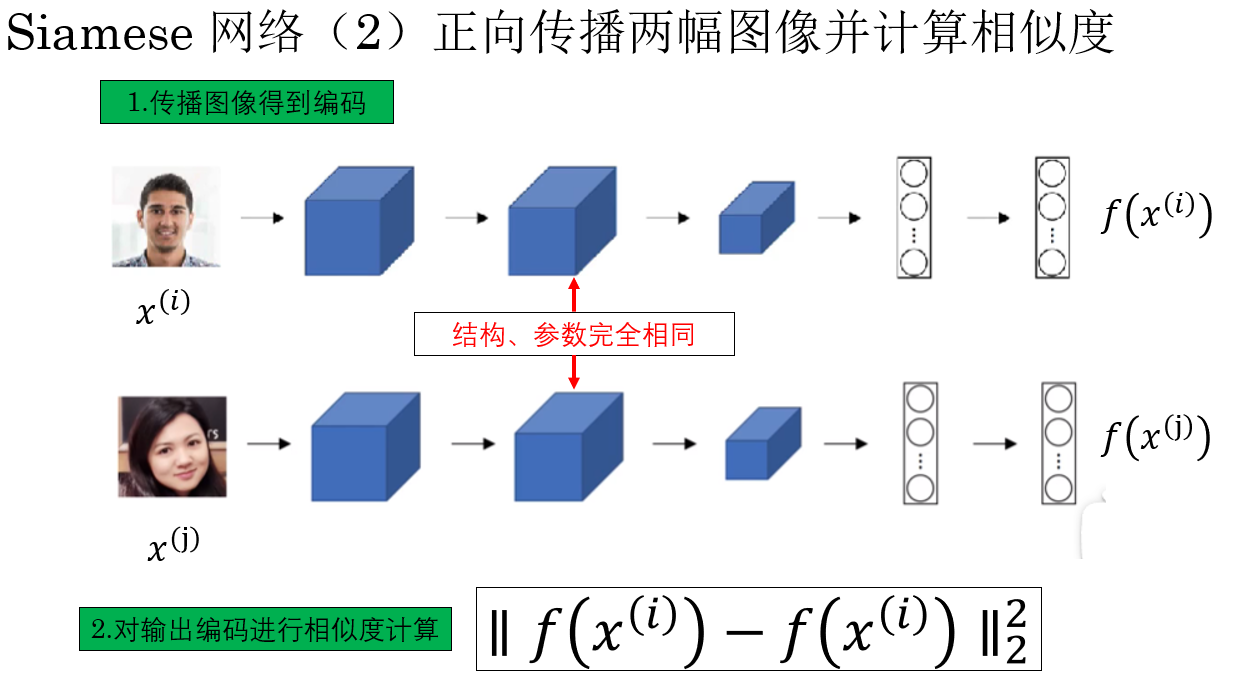
如图所示,我们通过正向传播得到两幅输入人脸的编码,并根据编码计算相似度,自然就可以根据阈值判断两张人脸是否属于同一个人。
而且,这种传播和计算相似度分离的设计,代表我们可以提前为数据库中的图像计算好编码,只需刷脸时传入的人脸单独传播得到编码后进行计算就好了,这大大提高了可部署性。
3.3 拓展:另一种训练编码网络的方式
我们刚刚介绍了可以通过三元组损失来训练编码网络,但你可能也发现了,这个方法在数据准备阶段较为复杂。
因此,吴恩达老师还介绍了另一种训练方法:更改标签,让Siamese 网络后接逻辑回归变为二分类问题。
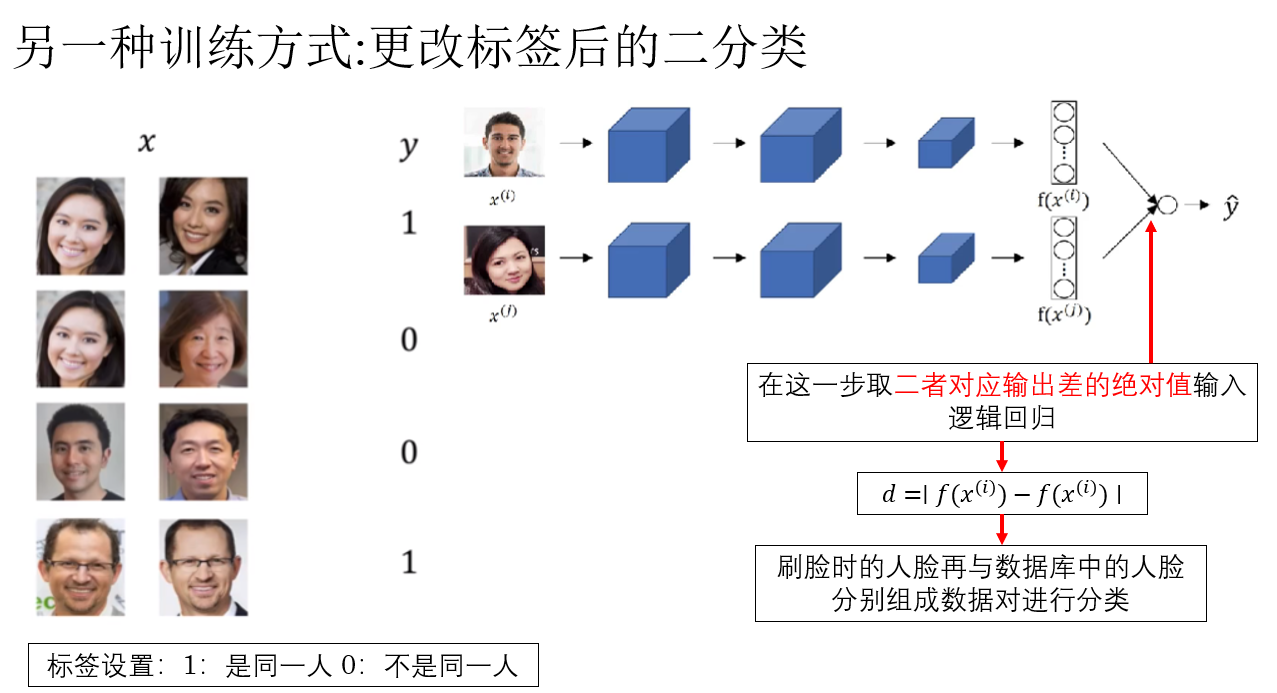
这样,我们就又把人脸识别问题又转换回了二分类问题,通过反向传播来进行训练。
但是,你会发现,当新员工加入时,还是要重新训练模型。
因此,实际上这种方式的实际部署价值并不如实用三元组损失。
4.总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 人脸验证(Face Verification) | 1 对 1 问题,判断输入人脸是否与目标身份匹配 | 就像门卫只对某个人说"可以进",其他人全部拒绝 |
| 人脸识别(Face Recognition) | 1 对多问题,通过模型识别输入人脸属于哪一个已知身份 | 门禁系统识别多个员工,不需要单独为每个人设闸机 |
| 多分类建模问题 | 将每个人作为一个类别进行训练 | 每个员工都有一本写真集,要学会区分成千上万本 |
| 一次学习(One-Shot Learning) | 每个身份仅提供极少样本,通过相似度判断识别 | 只需一张证件照就能识别新员工,不用拍写真集 |
| Siamese 网络 | 共享权重的双分支(或多分支)网络,将图像映射到同一特征空间,通过度量函数计算相似度 | 同时看两张照片,然后比较相似度 |
| 三元组损失(Triplet Loss) | 训练网络使同一人距离最小,不同人距离最大,网络需输入三张图像(anchor, positive, negative) | 提高考试难度:基准题和相似题差别小,不同题差别大,训练更有效 |
| 正向传播两图计算相似度 | 已训练网络对两幅图像编码后,计算特征距离或相似度,用阈值判断是否同一人 | 先把照片编码成"身份特征卡片",刷脸时只比对卡片 |
| Siamese + 逻辑回归二分类 | 将两张图像输入 Siamese 网络,通过逻辑回归判断是否同一人 | 将人脸识别问题简化成"是/不是同一人"的选择题 |
| 部署可行性对比 | 三元组损失支持 one-shot、可提前计算数据库特征向量,泛化强;逻辑回归方式新身份需重新训练,泛化差 | 三元组:考试考通用能力;逻辑回归:考试只会答已有题目 |