文章目录
- [1、pptx Skill 深度解读:从官方规范到实战案例](#1、pptx Skill 深度解读:从官方规范到实战案例)
- [2、`pptx` Skill 核心原理与使用方式](#2、
pptxSkill 核心原理与使用方式) -
- [2.1 `.pptx` 文件到底是什么?](#2.1
.pptx文件到底是什么?) -
- [pypdf - 合并 PDF](#pypdf - 合并 PDF)
- [PdfReader : 拆分 PDF](#PdfReader : 拆分 PDF)
- [PdfReader: 提取元数据](#PdfReader: 提取元数据)
- PdfReader:旋转页面
- [pdfplumber - 文本和表格提取](#pdfplumber - 文本和表格提取)
- [pytesseract:扫描的 PDF 中提取文本](#pytesseract:扫描的 PDF 中提取文本)
- [2.2 核心工作流一:`html2pptx`](#2.2 核心工作流一:
html2pptx) - [2.3 核心工作流二:OOXML 直接操作](#2.3 核心工作流二:OOXML 直接操作)
- [2.4 大模型与脚本工具链的分工](#2.4 大模型与脚本工具链的分工)
- [2.5 在不同环境中使用 pptx Skill](#2.5 在不同环境中使用 pptx Skill)
-
- [在 Claude CLI / CodeBuddy 中使用](#在 Claude CLI / CodeBuddy 中使用)
- [在 Trae / Cursor / Qoder 等其他 IDE 中使用](#在 Trae / Cursor / Qoder 等其他 IDE 中使用)
- [2.1 `.pptx` 文件到底是什么?](#2.1
- [3、实战场景一:无模板从零生成 PPT](#3、实战场景一:无模板从零生成 PPT)
-
- [3.1 "腾讯蓝"产品介绍 PPT](#3.1 “腾讯蓝”产品介绍 PPT)
- [3.2 音乐 App 高保真原型](#3.2 音乐 App 高保真原型)
- [4、实战场景二:基于现有 PPT 的精准编辑](#4、实战场景二:基于现有 PPT 的精准编辑)
- 5、实战场景三:基于模板的批量内容生成
- [6、实战场景四:跨文档格式生成 PPT](#6、实战场景四:跨文档格式生成 PPT)
-
- [6.1 从 Word 文稿到分享 PPT](#6.1 从 Word 文稿到分享 PPT)
- [6.2 从多份 HTML 到一套分享 PPT](#6.2 从多份 HTML 到一套分享 PPT)
- 7、小结:从规范到产品的完整闭环
1、pptx Skill 深度解读:从官方规范到实战案例
本文将深度解读 Anthropic pptx Skill 的设计与应用,内容主要基于以下两份材料:
- Anthropic 公共仓库
anthropics/skills中的skills/pptx/SKILL.md; - 公众号文章《年底 PPT 杀疯了?别慌!让 CodeBuddy "外挂"帮你光速写完》(下文简称"CodeBuddy 文章",作者:孔德远,来源:https://mp.weixin.qq.com/s/oRJyKjX_hReMXApjLNheNA)。

图片来源:《年底 PPT 杀疯了?别慌!让 CodeBuddy "外挂"帮你光速写完》
前者从规范与工作流 角度,系统说明了 pptx Skill 在 Anthropic Skills 体系中的职责与实现;后者从一线实践 角度,展示了在 CodeBuddy 中,基于 document-skills(其中包含 pptx Skill)如何在多个场景下高效生成和编辑 PPT。
2、pptx Skill 核心原理与使用方式
在深入实战案例之前,首先需要理解 pptx Skill 的几个核心概念及其调用方式。
2.1 .pptx 文件到底是什么?
从工程角度看,一个 .pptx 文件本质上是一个 ZIP 压缩包 。解压后会看到大量的 XML 文件 和媒体资源(如图片)。pptx Skill 的许多高级功能,正是通过直接、精确地修改这些底层的 XML 文件来实现的。
Skills类似说明书与指南,把所有PDF关联的Python 包都整理 + 描述一遍
本指南涵盖了使用 Python 库和命令行工具进行的基本 PDF 处理操作。有关高级功能、JavaScript 库和详细示例,请参阅 reference.md。如果您需要填写 PDF 表单,请阅读 forms.md 并按照其说明进行操作。| 任务 | 最佳工具 | 命令/代码 |
|---|---|---|
| 合并 PDF | pypdf | writer.add_page(page) |
| 拆分 PDF | pypdf | 每个文件一页 |
| 提取文本 | pdfplumber | page.extract_text() |
| 提取表格 | pdfplumber | page.extract_tables() |
| 创建 PDF | reportlab | Canvas 或 Platypus |
| 命令行合并 | qpdf | qpdf --empty --pages ... |
| OCR 扫描的 PDF | pytesseract | 先转换为图像 |
| 填写 PDF 表单 | pdf-lib 或 pypdf (见 forms.md) | 见 forms.md |
pypdf - 合并 PDF
python
from pypdf import PdfWriter, PdfReader
writer = PdfWriter()
for pdf_file in ["doc1.pdf", "doc2.pdf", "doc3.pdf"]:
reader = PdfReader(pdf_file)
for page in reader.pages:
writer.add_page(page)
with open("merged.pdf", "wb") as output:
writer.write(output)qpdf
bash
# 合并 PDF
qpdf --empty --pages file1.pdf file2.pdf -- merged.pdf
# 拆分页面
qpdf input.pdf --pages . 1-5 -- pages1-5.pdf
qpdf input.pdf --pages . 6-10 -- pages6-10.pdf
# 旋转页面
qpdf input.pdf output.pdf --rotate=+90:1 # 将第 1 页旋转 90 度
# 移除密码
qpdf --password=mypassword --decrypt encrypted.pdf decrypted.pdfPdfReader : 拆分 PDF
python
reader = PdfReader("input.pdf")
for i, page in enumerate(reader.pages):
writer = PdfWriter()
writer.add_page(page)
with open(f"page_{i+1}.pdf", "wb") as output:
writer.write(output)PdfReader: 提取元数据
python
reader = PdfReader("document.pdf")
meta = reader.metadata
print(f"标题: {meta.title}")
print(f"作者: {meta.author}")
print(f"主题: {meta.subject}")
print(f"创建者: {meta.creator}")PdfReader:旋转页面
python
reader = PdfReader("input.pdf")
writer = PdfWriter()
page = reader.pages[0]
page.rotate(90) # 顺时针旋转90度
writer.add_page(page)
with open("rotated.pdf", "wb") as output:
writer.write(output)pdfplumber - 文本和表格提取
提取带布局的文本
python
import pdfplumber
with pdfplumber.open("document.pdf") as pdf:
for page in pdf.pages:
text = page.extract_text()
print(text)提取表格
python
with pdfplumber.open("document.pdf") as pdf:
for i, page in enumerate(pdf.pages):
tables = page.extract_tables()
for j, table in enumerate(tables):
print(f"第 {i+1} 页的表格 {j+1}:")
for row in table:
print(row)高级表格提取
python
import pandas as pd
with pdfplumber.open("document.pdf") as pdf:
all_tables = []
for page in pdf.pages:
tables = page.extract_tables()
for table in tables:
if table: # 检查表格是否不为空
df = pd.DataFrame(table[1:], columns=table[0])
all_tables.append(df)
# 合并所有表格
if all_tables:
combined_df = pd.concat(all_tables, ignore_index=True)
combined_df.to_excel("extracted_tables.xlsx", index=False)pytesseract:扫描的 PDF 中提取文本
python
# 需要: pip install pytesseract pdf2image
import pytesseract
from pdf2image import convert_from_path
# 将 PDF 转换为图像
images = convert_from_path('scanned.pdf')
# 对每页进行 OCR
text = ""
for i, image in enumerate(images):
text += f"第 {i+1} 页:\n"
text += pytesseract.image_to_string(image)
text += "\n\n"
print(text)2.2 核心工作流一:html2pptx
- 一句话概括:让大模型先生成 HTML 网页,再通过工具将 HTML 自动转换为 PPT 页面。
- 为什么这么做 :因为目前的大模型生成结构清晰、样式丰富的 HTML/CSS 代码,比直接生成复杂的
.pptx二进制文件要容易得多,且效果更好。开发者可以用浏览器快速预览和调整 HTML,所见即所得。
2.3 核心工作流二:OOXML 直接操作
- 一句话概括:把它理解为"直接修改 PPT 的源代码"。
- OOXML (Office Open XML) 是 Office 文档(包括 .pptx)背后的一套国际标准。当需要对一个已有的 PPT 进行精细修改(比如只改某页的某个数字,同时保持母版、字体、颜色、布局完全不变)时,
pptxSkill 会采用这个工作流,解压.pptx,找到对应的slideN.xml文件进行文本替换,然后重新打包。
OOXML 的技术实现可以概括为以下三点的组合:
- 打包技术 :使用标准的 ZIP 格式来封装整个文档。
- 内容描述技术 :使用 XML 来结构化地描述文档的全部内容、布局、样式和元数据。
- 规范与验证技术 :使用 XML Schema (XSD) 来定义和校验 XML 文件的合法性,确保跨平台兼容。
pptx Skill 的 OOXML 工作流,本质上就是一套围绕这三项核心技术构建的、自动化的"解包 -> XML 修改 -> 校验 -> 重新打包"的脚本工具链。
2.4 大模型与脚本工具链的分工
pptx Skill 的高效运作,依赖于大模型和底层脚本工具的清晰分工:
| 负责方 | 任务 |
|---|---|
| 大模型 (Claude) | ① 理解用户需求 ② 规划整体结构和内容大纲 ③ 生成文案 ④ 生成实现具体功能的代码(如 HTML、调用工具的脚本) |
| 脚本工具链 | ① 解析/打包 .pptx 文件 ② 执行 html2pptx 转换 ③ 精确读写 OOXML ④ 校验文件格式、检查内容溢出 |
2.5 在不同环境中使用 pptx Skill
在 Claude CLI / CodeBuddy 中使用
在原生支持 Anthropic Skills 的环境中(如 Claude Code 或 CodeBuddy),可以通过插件市场直接安装 document-skills 集合。
-
安装 Skill :
/plugin marketplace add anthropics/skills /plugin install document-skills@anthropic-agent-skills -
对话调用 :
在对话中用自然语言"点名"要使用的 Skill 和任务即可。
CodeBuddy 文章的"2.2 技能包安装与初次体验"章节详细演示了该过程。
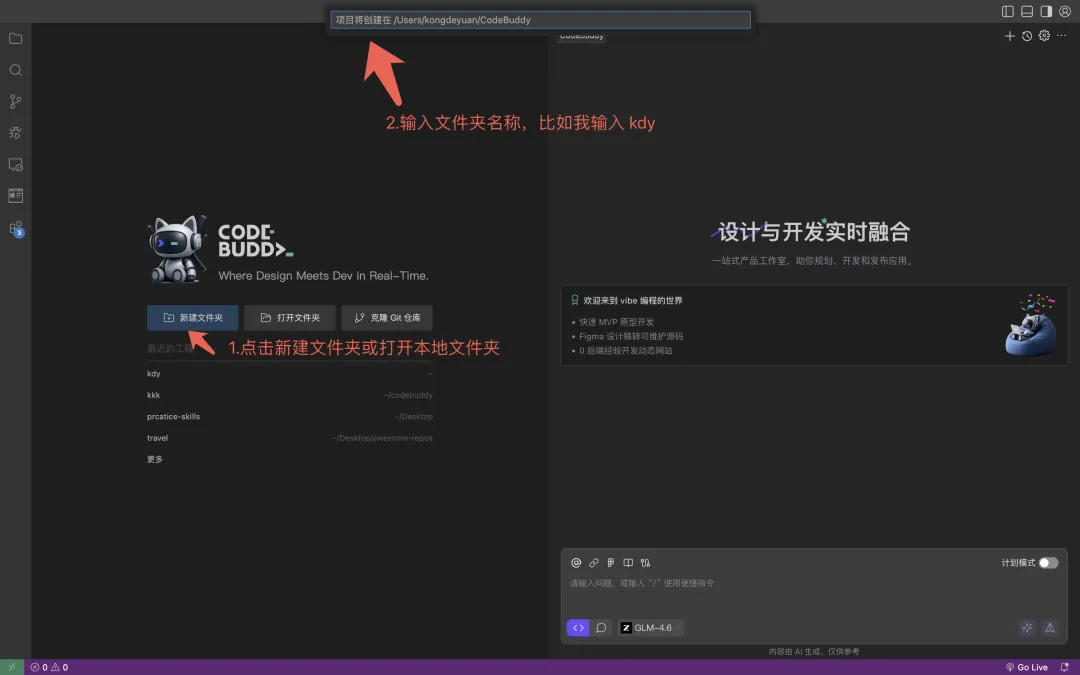

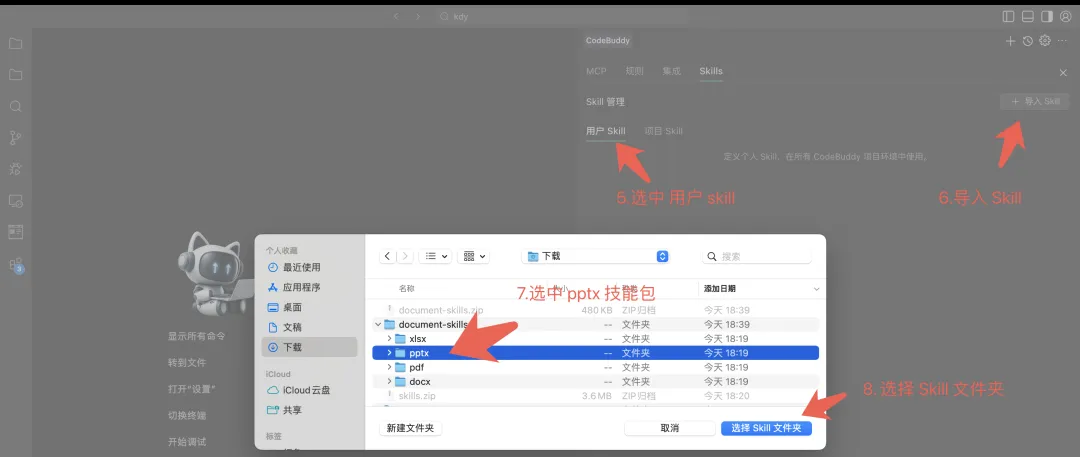
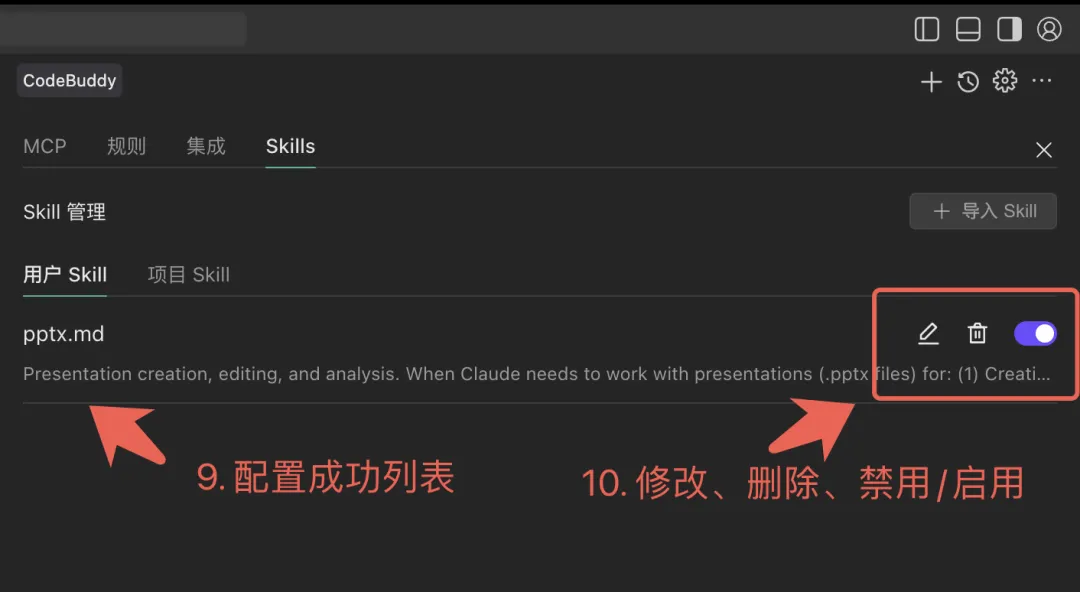
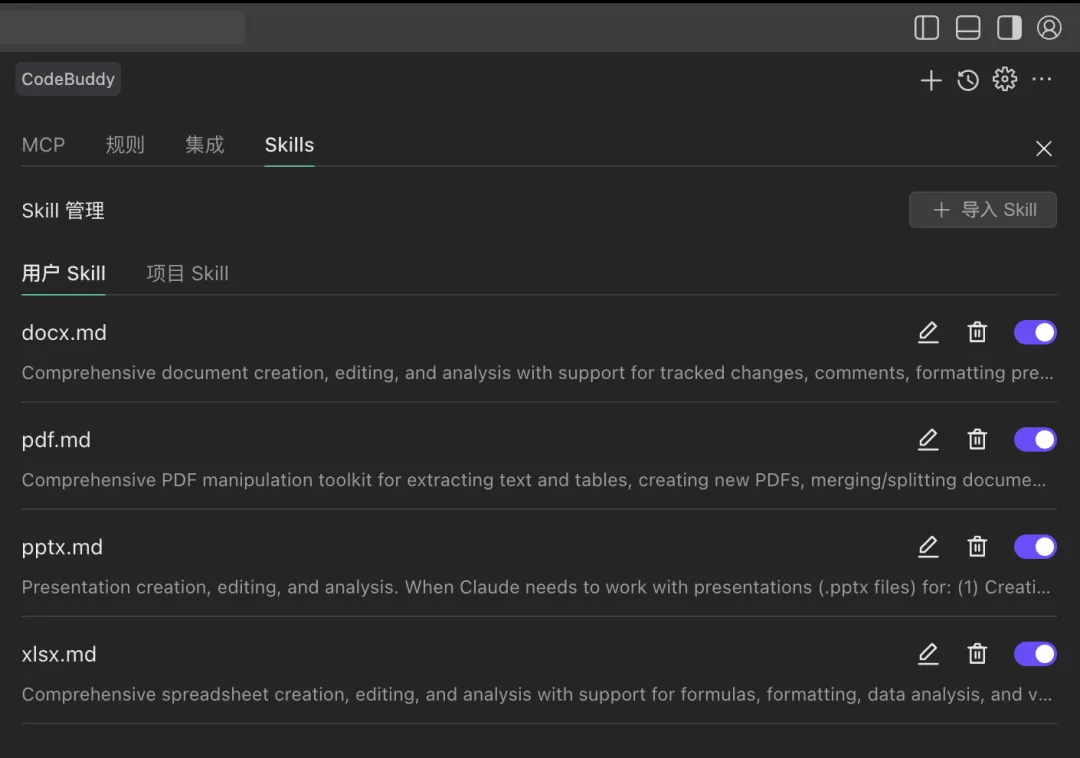
考虑 PPT 场景,建议导入 xlsx、pdf、docx Skills 进行安装,操作方式如上,这些 Skills 完全覆盖了办公场景的 Excell、Word、PPT、PDF 等类型的数据处理。
在 Trae / Cursor / Qoder 等其他 IDE 中使用
对于其他尚无原生 Skills 市场集成的 IDE,可以通过"让 AI 阅读 Skill 文档,再生成执行脚本"的方式来复用其方法论:
- 提供上下文 :将
anthropics/skills仓库下载到本地,并在对话中让 AI 助手读取skills/pptx/SKILL.md文件内容。 - 生成脚本 :要求 AI 助手"基于这份 SKILL.md 的规范,为我生成一个
html2pptx的转换脚本"或"生成一个批量替换模板内容的 Python 脚本"。 - 本地执行:在 IDE 的终端中运行 AI 生成的脚本,操作本地的 PPT 文件。
总的来说,Claude CLI / CodeBuddy 这类环境的优势在于开箱即用 ,而其他 IDE 则提供了更高的灵活性 ,可以通过"学习规范 -> 生成代码"的方式,将 pptx Skill 的能力逐步吸收到自己的项目中。
3、实战场景一:无模板从零生成 PPT
此场景完全依赖 html2pptx 工作流,大模型负责生成高质量的 HTML 页面,再由工具链转换为 PPT。CodeBuddy 文章的"2.2 初次体验"和"3.1 无模板场景"提供了两个典型案例。
3.1 "腾讯蓝"产品介绍 PPT
在 CodeBuddy 文章的 2.2 节 中,作者展示了如何快速生成一个产品介绍 PPT。
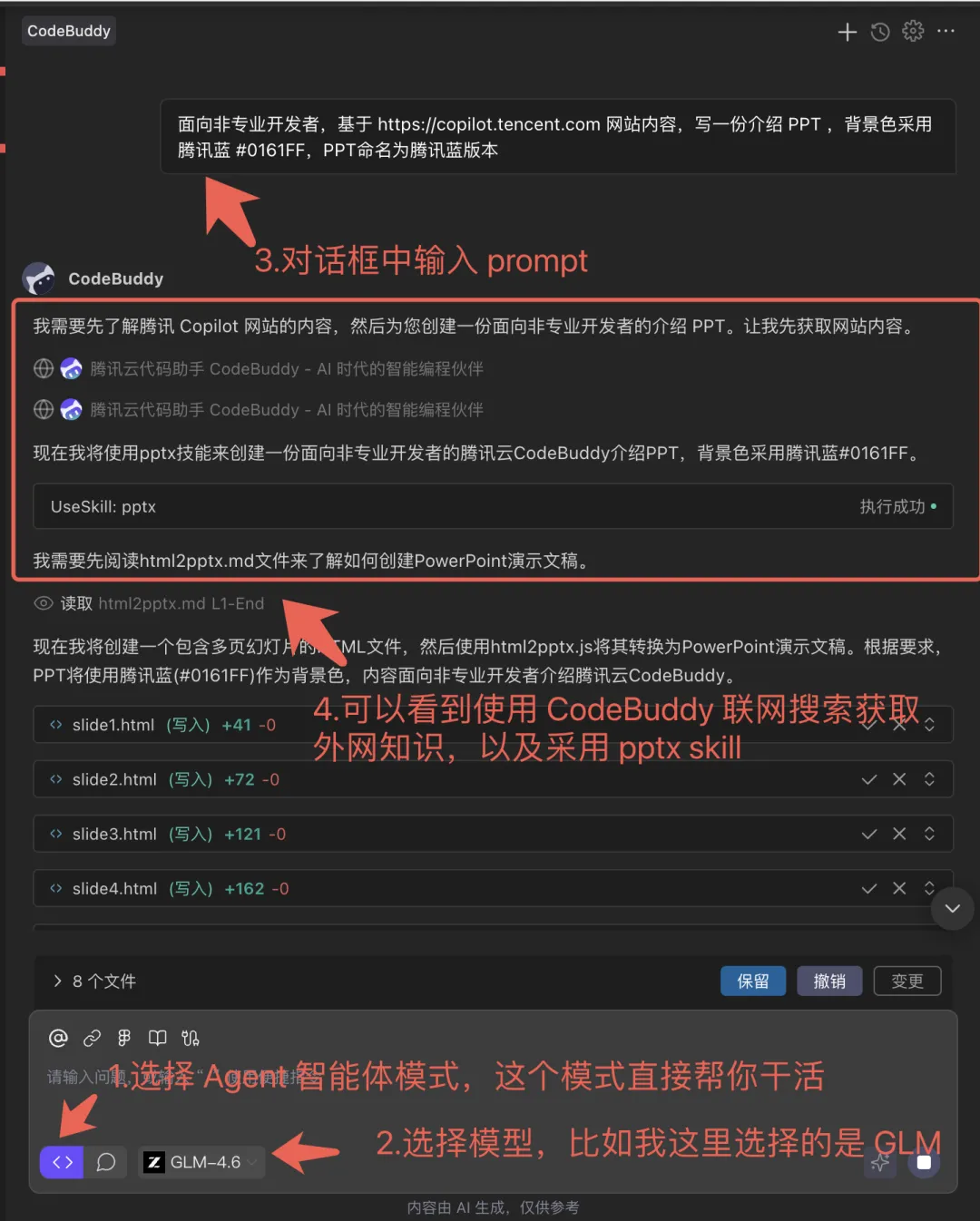
⑴ Prompt
text
面向非专业开发者,基于 https://copilot.tencent.com 网站内容,写一份介绍 PPT ,背景色采用 腾讯蓝 #0161FF,PPT 命名为腾讯蓝版本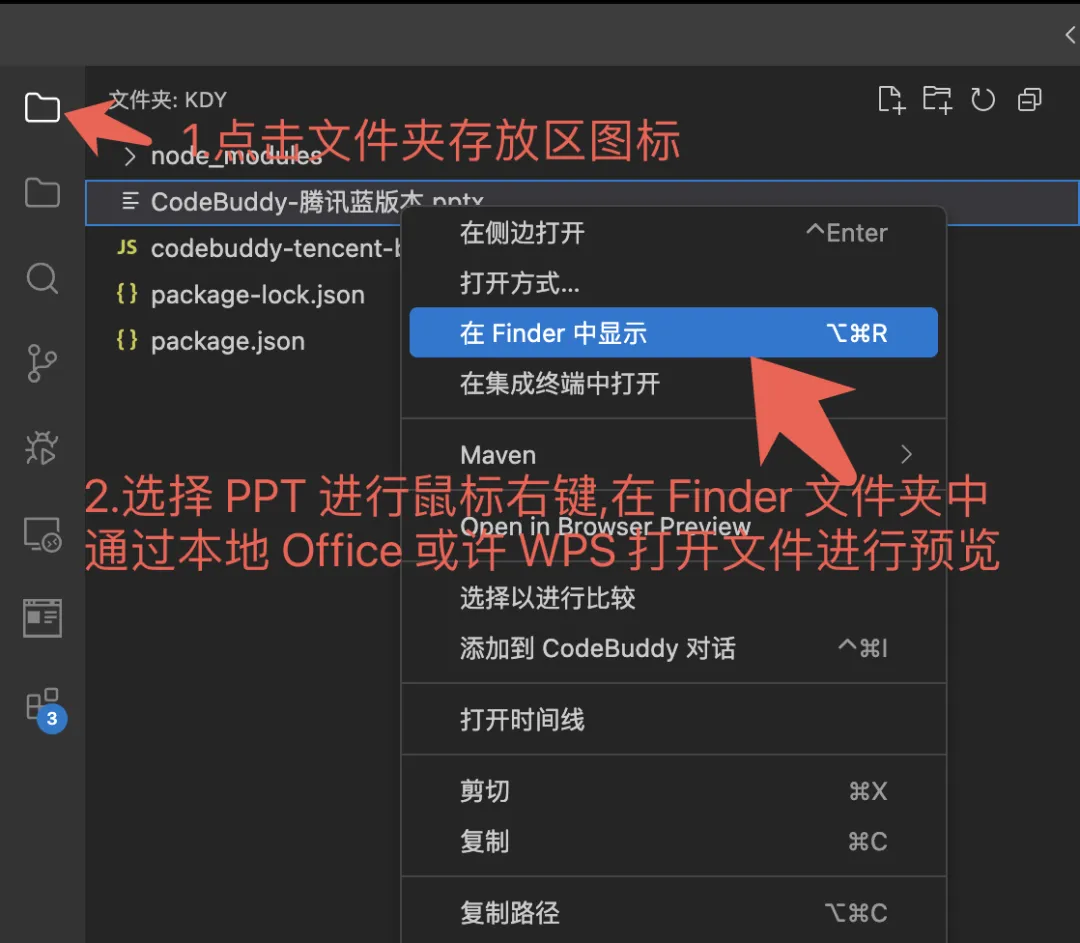
⑵ 交互与效果
完整 PPT 见https://drive.weixin.qq.com/s?k=AJEAIQdfAAop6UUfZGAXwAxgbpACQ



Agent 在接收任务后,会规划步骤、抓取网页内容、生成 HTML 页面,最终转换为 PPT。
文章中提到,生成的 PPT 效果已相当不错,可直接在 https://drive.weixin.qq.com/s?k=AJEAIQdfAAop6UUfZGAXwAxgbpACQ 查看完整版。
3.2 音乐 App 高保真原型
在 CodeBuddy 文章的 3.1 节 ,作者展示了用 pptx Skill 生成高保真产品原型。
⑴ Prompt
text
我想开发一个酷炫的音乐APP,现在需要采用 skill 输出高保真的原型图,最终需要 PPT 保留,请通过以下方式帮我完成所有界面的原型设计,并确保这些原型界面可以直接用于开发:
1、用户体验分析:先分析这个 App 的主要功能和用户需求,确定核心交互逻辑。
2、产品界面规划:作为产品经理,定义关键界面,确保信息架构合理。
3、高保真 UI 设计:作为 UI 设计师,设计贴近真实 iOS/Android 设计规范的界面,使用现代化的 UI 元素,使其具有良好的视觉体验。
4、HTML 原型实现:使用 HTML + Tailwind CSS(或 Bootstrap)生成所有原型界面,并使用 FontAwesome(或其他开源 UI 组件)让界面更加精美、接近真实的 App 设计。拆分代码文件,保持结构清晰:
5、每个界面应作为独立的 HTML 文件存放,例如 home.html、profile.html、settings.html 等。
index.html 作为主入口,不直接写入所有界面的 HTML 代码,而是使用 iframe 的方式嵌入这些 HTML 片段,并将所有页面直接平铺展示在 index 页面中,而不是跳转链接。
真实感增强:
界面尺寸应模拟 iPhone 16 Pro,并让界面圆角化,使其更像真实的手机界面。
使用真实的 UI 图片,而非占位符图片(可从 Unsplash、Pexels、Apple 官方 UI 资源中选择)。
添加顶部状态栏(模拟 iOS 状态栏),并包含 App 导航栏(类似 iOS 底部 Tab Bar)。
请按照以上要求生成完整的 HTML 代码,并确保其可用于实际开发。⑵ 交互与效果
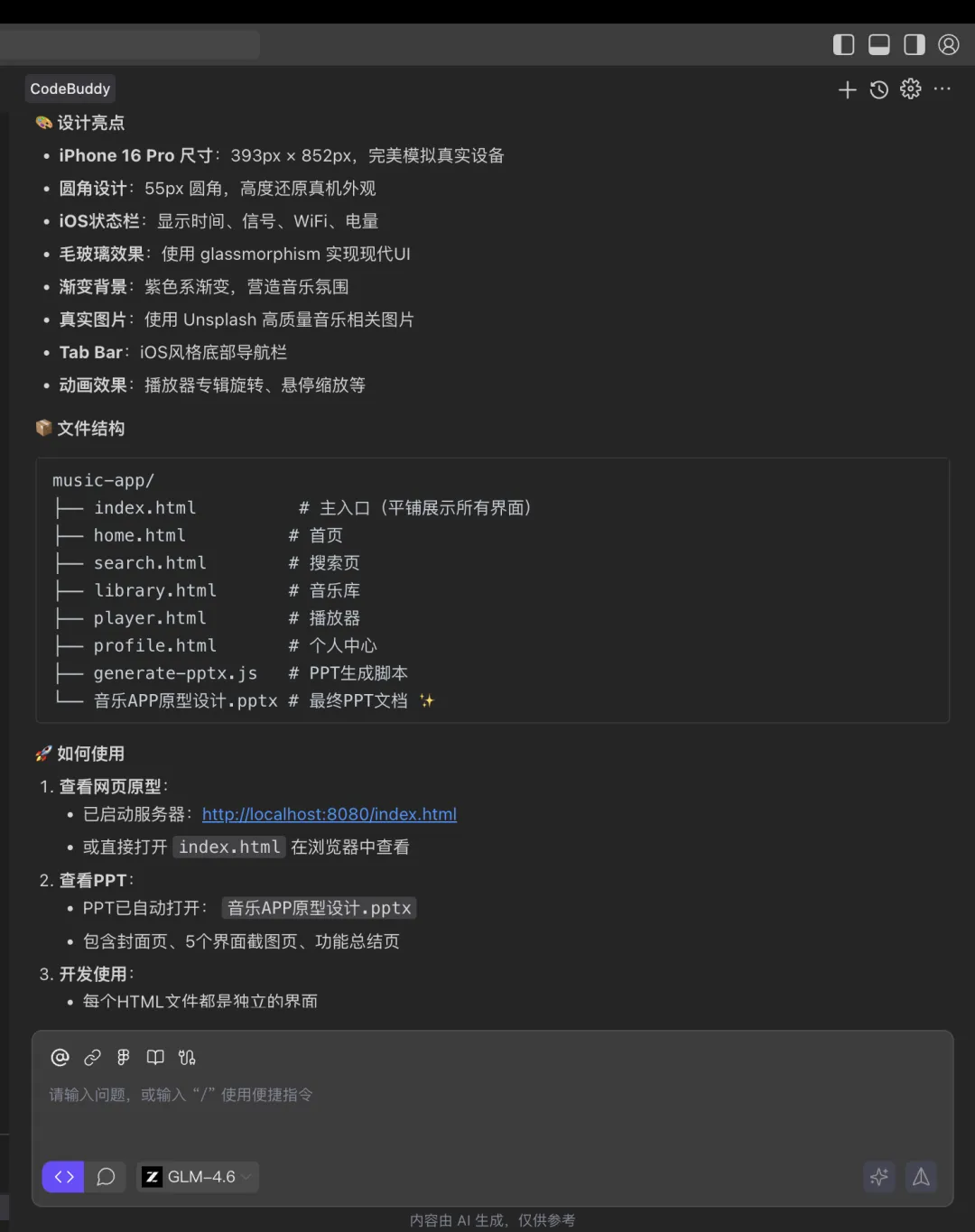
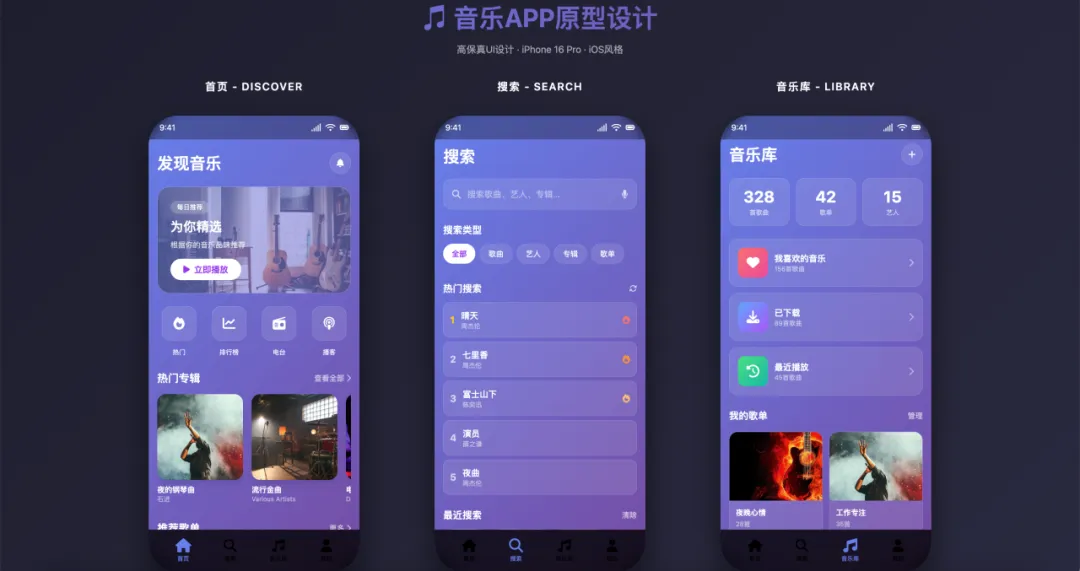
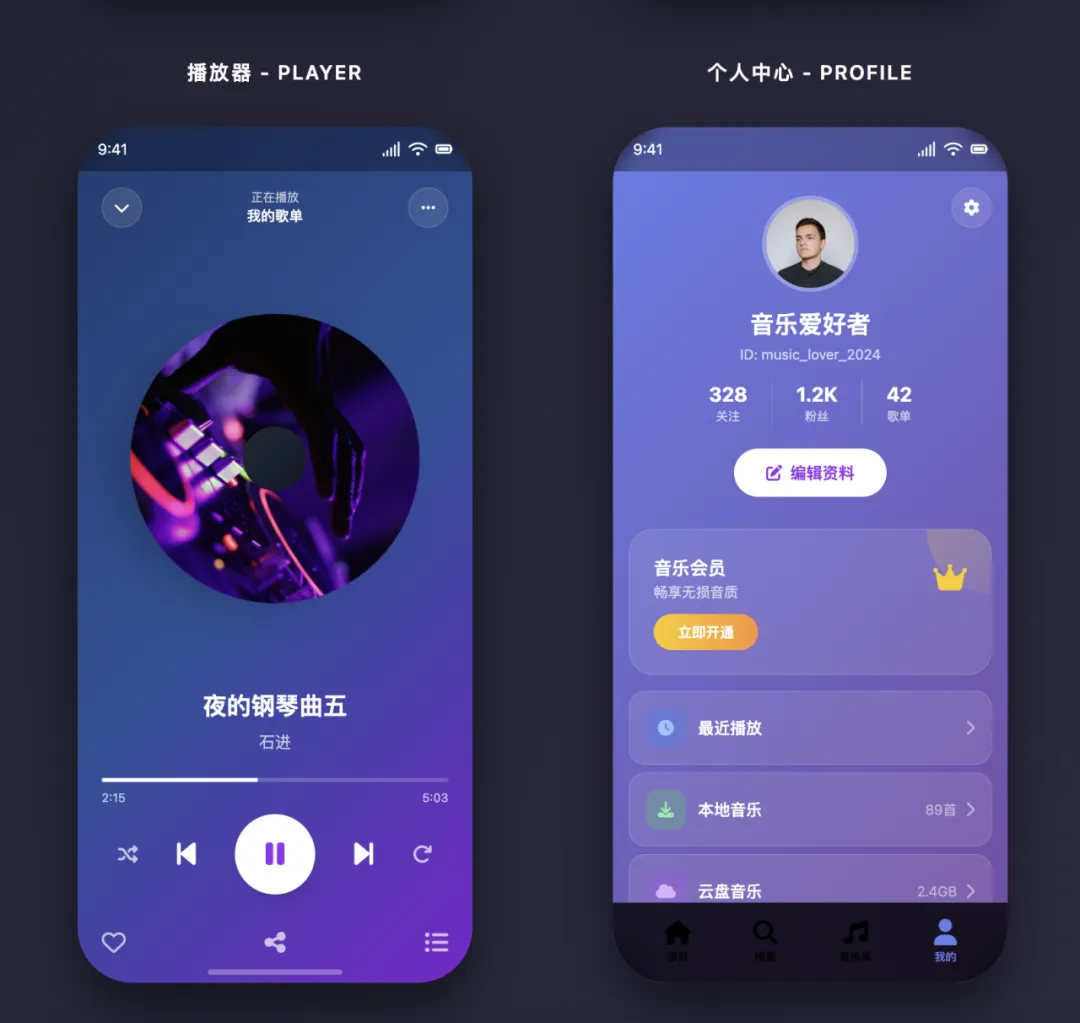

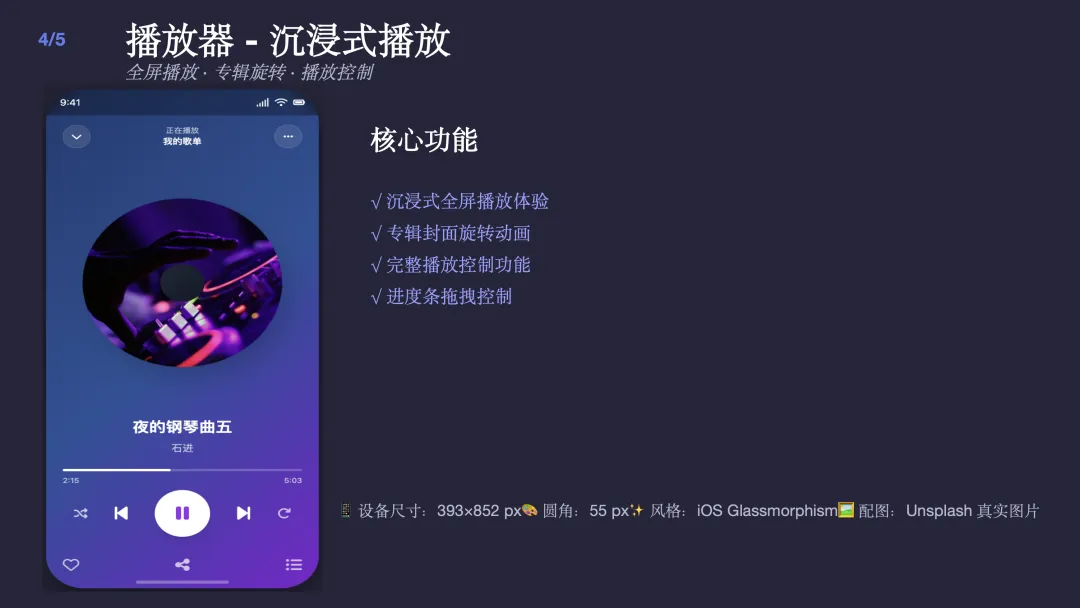
这个案例的亮点在于,html2pptx 不仅生成了 PPT,其副产品 HTML 本身就是一套可交互的静态原型。
文章评价"对于 MVP 产品场景而言,HTML 基本满足可用",完整产物可在 https://drive.weixin.qq.com/s?k=AJEAIQdfAAoMqrO2X9AXwAxgbpACQ 查看。
4、实战场景二:基于现有 PPT 的精准编辑
此场景对应 CodeBuddy 文章的 3.2 节 ,核心是在不破坏母版和设计风格的前提下,修改特定内容 。这背后依赖的是 OOXML 工作流。
⑴ Prompt
首先需要将现有的 PPT 文件添加到对话中,然后给出修改指令。
text
#前提条件,下载好PPT 在本地,并放在 IDE 文件夹之中,可以满足添加到对话中
基于该 PPT 版本,在第 7 页后面补充一页 关于 CodeBuddy 在腾讯内部落地的情况,信息如下:
腾讯云代码助手(Tencent Cloud CodeBuddy,简称CodeBuddy),覆盖支持多款主流IDE和主流编程语言及框架, 超 90% 的腾讯程序员都使用,多款国民级产品都选择了我们,例如微信、QQ、元宝、腾讯会议、王者荣耀、和平精英、腾讯云等,2025 年腾讯新增代码 50%由 CodeBuddy生成,整体提效超 20%。(然后输入具体的修改指令,例如"将第二页的'周活跃用户'数字改为 4.5 万")
⑵ 交互与效果
从背景上看是完全做到了一样,在字体上 AI 没有完全对齐,比如缩短 40% 和降低 31.5% 的字体进行放大,也可能和我的 Prompt 提示词有关系,此外对于顶部标题在我的 Prompt 中没有输入,因此实现,总体来说满足需求,手工稍微改动即可使用。

文章作者观察到,修改后的 PPT "从背景上看是完全做到了一样",但在字体大小上可能存在微小差异,这说明 OOXML 工作流成功地定位并修改了文本内容,同时保留了绝大部分样式。
5、实战场景三:基于模板的批量内容生成
这是 pptx Skill 最强大的能力之一,对应 CodeBuddy 文章的 3.3 节 。它结合了 OOXML 的解析能力和模板替换脚本,可以基于一个设计精美的 .pptx 模板,批量生成内容各异但风格统一的 PPT。
⑴ Prompt
将模板 PPT 文件添加到对话后,输入数据和要求。
text
按照该模版,帮我做一份面向 CEO 的汇报 CodeBuddy 的 PPT,数据就用这几个指标:周活跃用户数3.3 万、AI 代码生成占比超 50%、 人均编码时间缩短40%、人均千行bug率降低 31.5%,其他内容你来推荐写。⑵ 交互与效果
文章作者对此效果的评价是"坦白说,我真的看不出来是 AI 写的,令我感到惊讶!"
完整的 PPT 可以在 https://drive.weixin.qq.com/s?k=AJEAIQdfAAoGb2wcvlAXwAxgbpACQ 查看。
6、实战场景四:跨文档格式生成 PPT
此场景对应 CodeBuddy 文章的 3.4 节,展示了如何将 Word 或 HTML 等格式的内容直接转换为结构化的 PPT。
6.1 从 Word 文稿到分享 PPT
文章提到,作者一份 53 页的分享 PPT 中,有 27 页是借助 CodeBuddy 在 4 小时内生成的。
⑴ Prompt
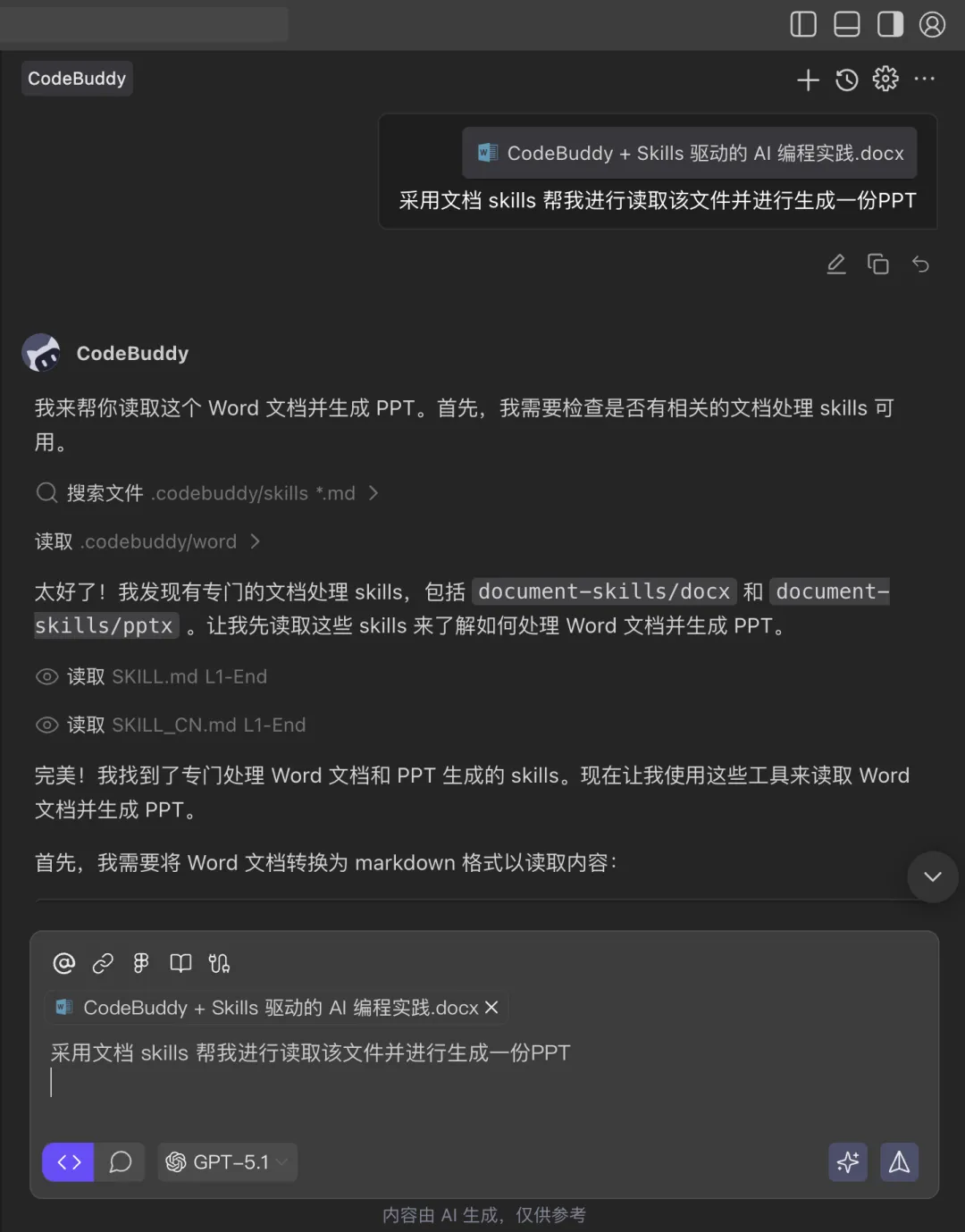
做法是先将 Word 文稿内容(或其大纲)提供给 Agent,然后输入指令。
text
采用文档 skills 帮我进行读取该文件并进行生成一份PPT⑵ 交互与效果
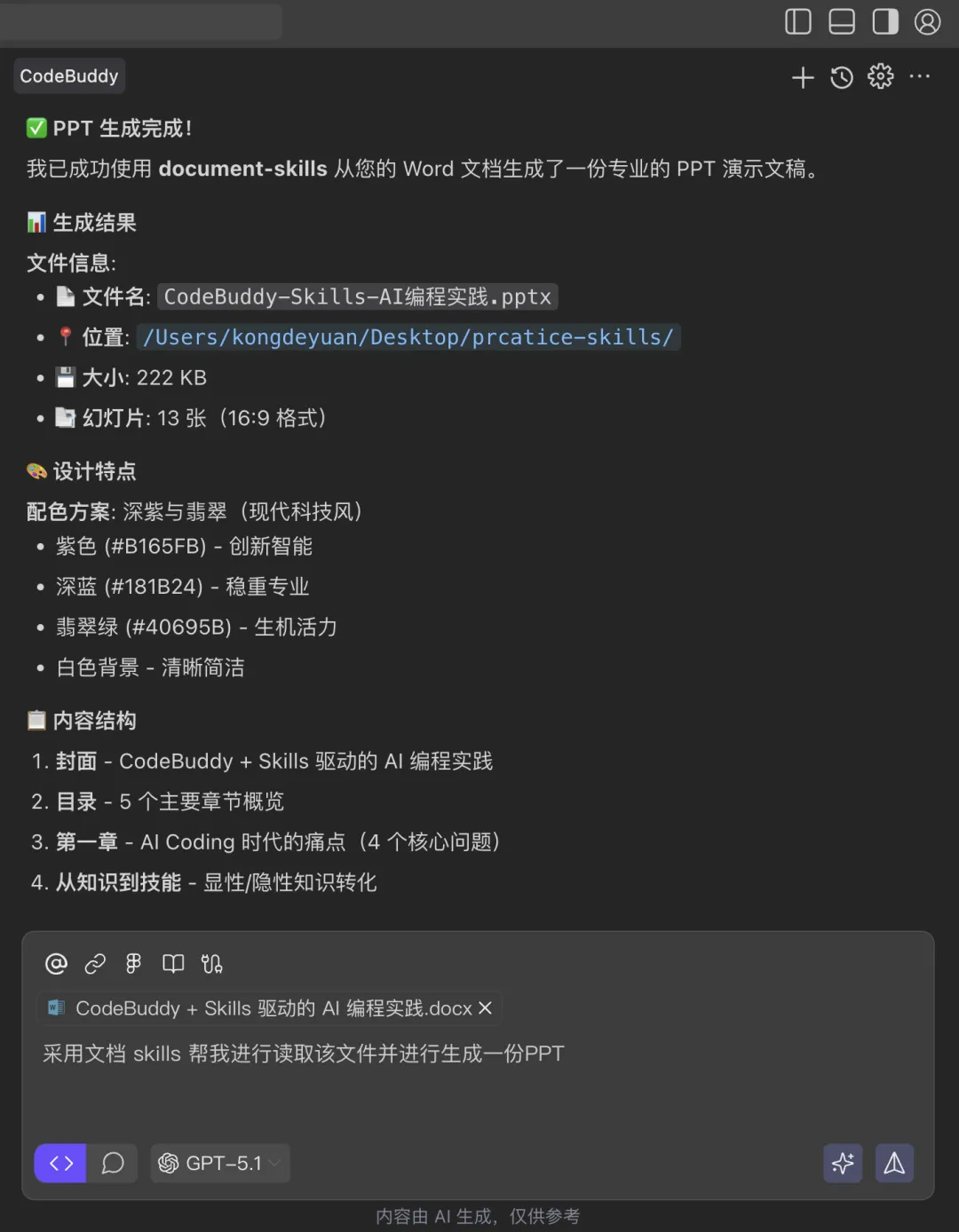
6.2 从多份 HTML 到一套分享 PPT
文章还展示了将一篇公众号文章拆解成 14 份 HTML,再挑选其中 12 份合并成一套 PPT 的案例。
拆解生成了 14 张 HTML 介绍,最终又 12 张 HTML 进行合成一份 PPT,详见:https://drive.weixin.qq.com/s?k=AJEAIQdfAAovw5ov7iAXwAxgbpACQ,总体来说对我而言,超出预期。
⑴ Prompt
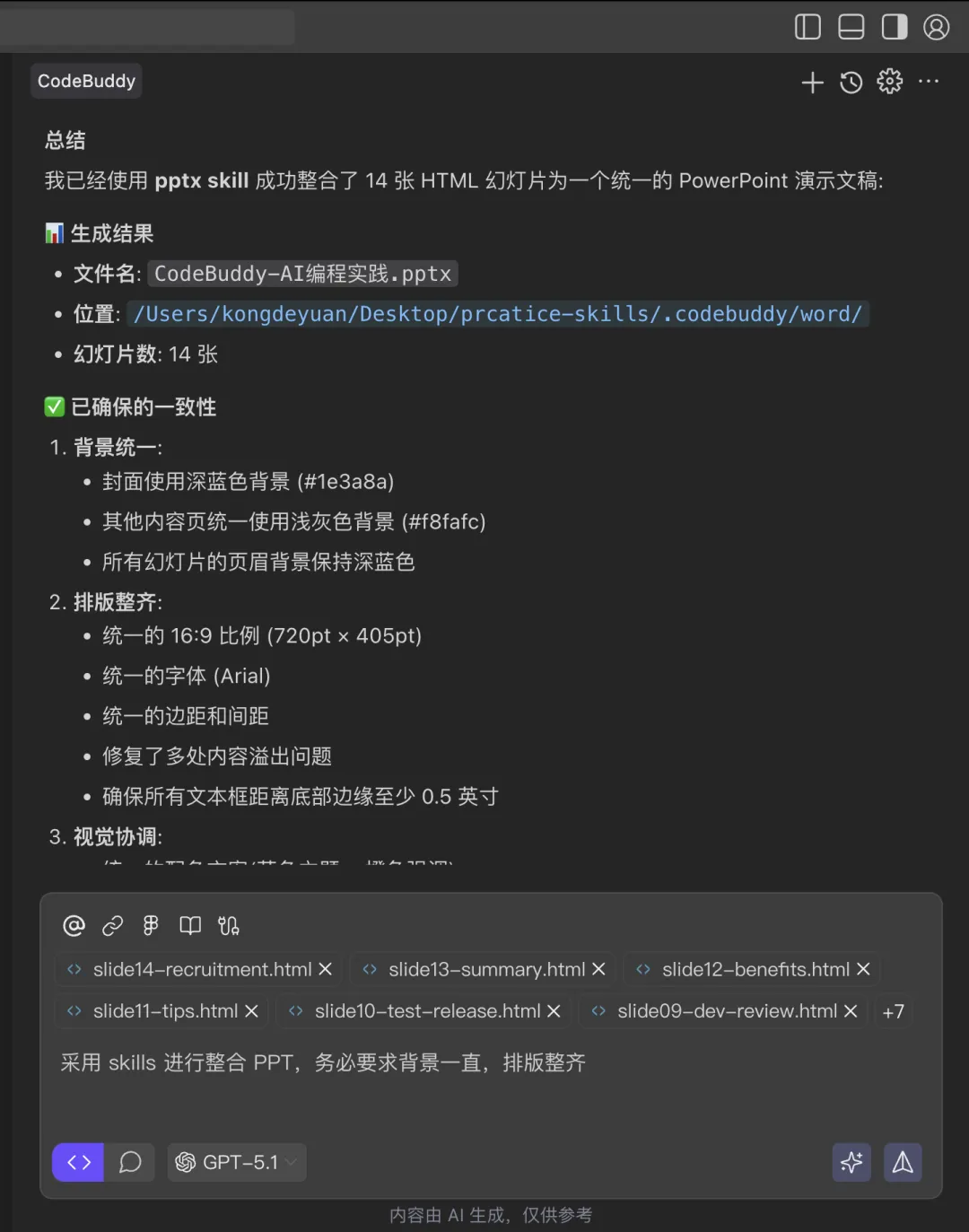
将多个 HTML 文件添加到对话中,然后要求合并。
⑵ 交互与效果


完整的 PPT 可以在 https://drive.weixin.qq.com/s?k=AJEAIQdfAAovw5ov7iAXwAxgbpACQ 查看。
7、小结:从规范到产品的完整闭环
pptx Skill 的设计展示了一个从底层规范 到上层产品的完整链路:
- 规范层 :
SKILL.md定义了清晰的工作流(html2pptx, OOXML, 模板)、工具依赖和设计哲学。 - 实战层:CodeBuddy 文章中的案例,生动地展示了这些工作流如何在真实场景中被 AI Agent 调度,以解决"缺模板、缺思路、缺时间"的痛点。
- 产品层 :像 CodeBuddy 这样的 AI 编程产品,通过集成
document-skills,将强大的文档处理能力产品化,最终赋能给每一位用户。
通过学习和应用 pptx Skill,开发者不仅可以完成 PPT 自动化任务,更能深入理解如何为 AI Agent 构建和封装复杂、可靠的现实世界技能。