文章目录
- [从 Pod 资源到 JVM 参数:我在生产环境中踩过的 Kubernetes 资源配置那些坑](#从 Pod 资源到 JVM 参数:我在生产环境中踩过的 Kubernetes 资源配置那些坑)
- 摘要
- 引言:我为什么还在写"资源配置"
- 从宿主机说起:资源并不是"无限的"
- [Kubernetes 的 requests / limits 到底在"限制"什么](#Kubernetes 的 requests / limits 到底在“限制”什么)
-
- requests:调度依据,而非性能保障
- limits:运行时的"硬上限"
- [requests / limits 与节点资源的真实关系](#requests / limits 与节点资源的真实关系)
- [容器里的 Java,JVM 真的"理解" Kubernetes 吗?](#容器里的 Java,JVM 真的“理解” Kubernetes 吗?)
-
- [JVM 并非天生为容器设计](#JVM 并非天生为容器设计)
-
- [JVM Server 模式默认规则(JDK 8 早期)](#JVM Server 模式默认规则(JDK 8 早期))
- 套数据算一下
- [Xms / Xmx 与 memory limit 的真实关系](#Xms / Xmx 与 memory limit 的真实关系)
- [JVM 内存 ≠ Heap](#JVM 内存 ≠ Heap)
- 真实生产中的内存账本(直接给数字)
-
- [❌ 错误配置(激进)](#❌ 错误配置(激进))
- 保守到底怎么"保守"?直接给公式
-
- [✅ 推荐通用安全比例(生产可用)](#✅ 推荐通用安全比例(生产可用))
-
- [举例:2Gi 内存 Pod(强烈推荐)](#举例:2Gi 内存 Pod(强烈推荐))
- [✅ 更稳妥(高并发 / Netty / RPC 服务)](#✅ 更稳妥(高并发 / Netty / RPC 服务))
- 直接给你一张「速查表」
- [Java 11+ 的"自动模式"也不是银弹](#Java 11+ 的“自动模式”也不是银弹)
-
- [👉 生产建议](#👉 生产建议)
- 一个真实的生产教训(总结版)
- 一套可落地的资源配置经验总结
- 写在最后:技术成长,来自对细节的尊重
- 总结
从 Pod 资源到 JVM 参数:我在生产环境中踩过的 Kubernetes 资源配置那些坑
------2025 年度技术总结
摘要
作为一名从业 8 年 的运维开发工程师,过去一年中我共输出了 96 篇技术文章 ,主要围绕 Kubernetes 在生产环境中的落地实践与经验总结展开。本文结合真实业务场景,系统梳理 Kubernetes 中
requests / limits、宿主机 CPU 与内存资源,以及 Java JVM 启动参数(如Xms / Xmx)三者之间的关系,重点分析容器化环境下常见的配置误区与优化思路,尝试沉淀一套可复用、可落地的资源配置经验,为云原生场景下的服务稳定运行提供参考。
引言:我为什么还在写"资源配置"
我在 2018 年加入 CSDN,至今码龄 8 年,今年一共输出了 96 篇技术文章,主要聚焦在 Linux、Kubernetes 以及生产环境运维实践上。目前已通过【运维】与【操作系统】领域认证。
这一年里,我发现一个现象:
看似简单的资源配置,往往是生产事故的根源。
Pod 被 OOM Kill、Java 服务无故变慢、节点资源"看着很空"却频繁异常,这些问题最终都会指向同一个核心------资源认知不一致。于是,我决定把这一年在 Kubernetes 资源模型与 Java 应用调优上的经验,系统性地整理出来。
从宿主机说起:资源并不是"无限的"
无论 Kubernetes 的抽象层级多么丰富,Pod、容器最终都运行在真实的宿主机之上。理解宿主机资源的边界,是理解 Kubernetes 资源模型的第一步。
首先,CPU 核数是真实存在的。Kubernetes 所谓的"超卖",本质上只是调度层面的策略,并不意味着节点真的拥有无限算力。当多个 Pod 同时竞争 CPU 时,最终仍然要回到物理核心上进行时间片分配,性能抖动也往往在这一阶段产生。
其次,内存的 free 并不等于真正可用的内存。在 Linux 系统中,page cache、buffer 以及内核自身预留都会占用相当一部分内存空间。从节点监控上看,内存似乎还很充裕,但在实际运行过程中,一旦容器总内存使用触碰到限制,就可能触发 OOM 机制。
在生产环境中,我曾多次遇到这样的场景:
节点监控显示 CPU 与内存使用率并不高,但部分 Pod 却频繁被驱逐,或者无法启动成功,一直挂着,甚至直接被 OOM Kill。最终排查发现,问题并不在 Kubernetes 本身,而在于容器视角下的资源使用,与宿主机真实的内存消耗并不完全一致。
因此,如果只从 Kubernetes 的资源配置出发,而忽略宿主机层面的实际约束,往往会对系统的稳定性产生误判。
宿主机内存结构视角(Linux)
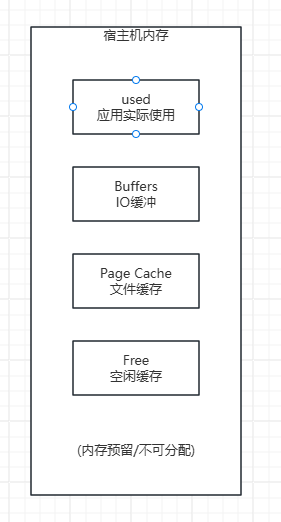
图:
free ≠ available
page cache 会被回收,但不是瞬间
容器 OOM 判断看的是 memory limit
Kubernetes 资源视角(Node → Pod → Container)
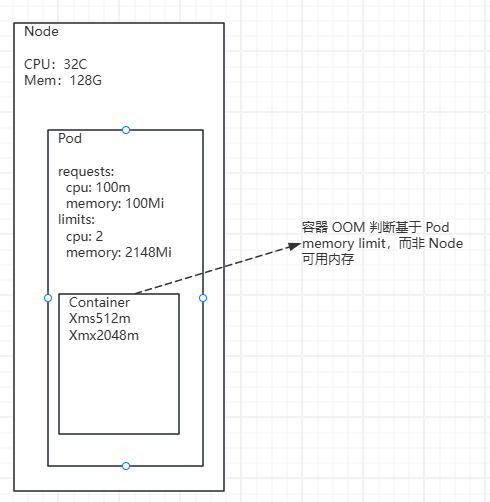
图: 同一份物理资源,在 Node、Pod 与容器内部呈现出完全不同的视角,如果忽略层级差异,往往会对系统稳定性产生误判。
Kubernetes 的 requests / limits 到底在"限制"什么
在 Kubernetes 中,requests 和 limits 是资源管理的核心,但它们经常被误解,甚至被当作"随便填的参数"。事实上,这两者分别站在调度层 和运行时层,解决的是完全不同的问题。
以下是一个非常常见的 Pod 资源配置示例:
yaml
resources:
limits:
cpu: "2"
memory: 2148Mi
requests:
cpu: 100m
memory: 100Mirequests:调度依据,而非性能保障
requests 定义的是 Pod 在调度阶段向集群声明的最小资源需求。Kubernetes 的 scheduler 会根据各节点的可分配资源(Allocatable),判断是否有节点"有能力"承载该 Pod。
需要强调的是,requests 并不保证运行时一定能获得对应资源。当节点上的多个 Pod 同时竞争 CPU 时,requests 只是决定"能不能被放上去",并不会参与后续的资源抢占与分配。
在生产环境中,requests 配置过低,往往会埋下隐患:
- Pod 被调度到资源已经较为紧张的节点
- 高峰期容易被其他 Pod 抢占 CPU
- 实际性能下降,但节点监控并不明显异常
这类问题通常不会立刻暴露,却会在业务高峰期集中爆发。
limits:运行时的"硬上限"
与 requests 不同,limits 才是容器在运行时真正受到约束的边界。
- CPU limit 由 Linux 的 CFS(Completely Fair Scheduler)控制,当容器使用 CPU 超过限制时,会被周期性地 throttle
- memory limit 一旦触发,容器会被内核直接 OOM Kill
需要特别指出的是,CPU limit 并不等于固定使用 2 个核心。当 limit 设置过低时,频繁的 CFS 限流反而会导致 Java 应用出现明显的延迟抖动,甚至吞吐量下降。
相比之下,内存限制更加"绝对",一旦超出 limit,Kubernetes 不会给容器任何缓冲空间。
经验提示:
对于延迟敏感的 Java 服务,如果 CPU limit 设置过低,即使节点整体 CPU 使用率不高,也可能出现明显的性能抖动。
requests / limits 与节点资源的真实关系
Kubernetes 允许通过 requests 与 limits 的组合,对节点资源进行一定程度的超卖,但超卖并不等于无限。
在节点层面,scheduler 只关心 requests 的总和是否小于节点的可分配资源;而在运行时,当多个 Pod 同时接近或触发各自的 limits,最终压力会直接回到宿主机。
这也解释了一个常见现象:
节点监控看起来资源尚可,但部分 Pod 仍然被 OOM Kill 或频繁重启。
本质原因在于,调度视角与运行时视角并不完全一致。
容器里的 Java,JVM 真的"理解" Kubernetes 吗?
这是我今年踩坑最多、也是线上事故最隐蔽的地方之一。
JVM 并非天生为容器设计
如 **OpenJDK 8u111 **,JVM 默认感知的是 宿主机内存 ,而不是容器的 memory limit:
- 宿主机 64G
- Pod limit 2G
👉 JVM 会认为「我有 64G 可用」
结果往往是:
- 启动阶段正常
- 运行一段时间后突然 OOM Kill
- 容器日志里 什么都没有
即使在 Java 8u191+ / Java 11+ 已支持容器感知,如果你:
- 手动设置了
-Xmx - 或 JVM 参数过于激进
依然会踩坑。
[root@sonar ~]# free -mh
total used free shared buff/cache available
Mem: 15G 2.5G 738M 856M 12G 11G
Swap: 0B 0B 0B
[root@sonar ~]# docker run -m 1024m -it openjdk:8u111 bash -c "java -XshowSettings:vm -version"
Unable to find image 'openjdk:8u111' locally
8u111: Pulling from library/openjdk
5040bd298390: Pull complete
fce5728aad85: Pull complete
76610ec20bf5: Pull complete
60170fec2151: Pull complete
e98f73de8f0d: Pull complete
11f7af24ed9c: Pull complete
49e2d6393f32: Pull complete
bb9cdec9c7f3: Pull complete
Digest: sha256:c1ff613e8ba25833d2e1940da0940c3824f03f802c449f3d1815a66b7f8c0e9d
Status: Downloaded newer image for openjdk:8u111
VM settings:
Max. Heap Size (Estimated): 3.42G
Ergonomics Machine Class: server
Using VM: OpenJDK 64-Bit Server VM
openjdk version "1.8.0_111"
OpenJDK Runtime Environment (build 1.8.0_111-8u111-b14-2~bpo8+1-b14)
OpenJDK 64-Bit Server VM (build 25.111-b14, mixed mode)
[root@sonar ~]# 结论先给出来: openjdk:8u111 根本不认识 Docker 的 -m 1024m,它看到的是宿主机 15G 内存,于是按"物理机规则"给自己算了一个 约3.4G 的最大堆。
JVM Server 模式默认规则(JDK 8 早期)
在 Server VM + 未显式指定 -Xmx 时:
text
MaxHeap ≈ 物理内存 × 1/4套数据算一下
text
15G × 25% ≈ 3.75G而 JVM 还会:
-
扣除:
- Metaspace
- CodeCache
- JVM 内部结构
-
再做一层 Ergonomics 修正
最终结果:
text
≈ 3.42G📌 所以这个数是"宿主机内存推导值",和 容器的 1G 一点关系都没有
Xms / Xmx 与 memory limit 的真实关系
一个非常常见、非常危险的配置是:
yaml
resources:
limits:
memory: 2Gi
bash
-Xms2g
-Xmx2g表面上看:刚刚好
实际上:必炸
JVM 内存 ≠ Heap
JVM 实际内存结构大致如下:
| 内存类型 | 是否算在 limit 内 | 典型占用 |
|---|---|---|
| Java Heap(Xmx) | ✅ | 主要内存 |
| Metaspace | ✅ | 100M~300M |
| Direct Memory | ✅ | 200M~1G(Netty) |
| Thread Stack | ✅ | 1M × 线程数 |
| Code Cache | ✅ | ~100M |
| JVM 自身 & libc | ✅ | 数十 MB |
👉 容器只看一件事:总内存是否超过 limit
不会关心你是不是"合法的 JVM 内存"。
真实生产中的内存账本(直接给数字)
我们用一个2Gi 内存的 Pod来算一笔账。
❌ 错误配置(激进)
memory limit: 2048Mi
Xmx: 2048Mi实际运行时可能是:
| 项目 | 内存 |
|---|---|
| Heap | 2048Mi |
| Metaspace | 200Mi |
| Direct Memory | 300Mi |
| Thread Stack(200线程) | 200Mi |
| Code Cache + JVM | 100Mi |
| 合计 | ≈2850Mi ❌ |
👉 结果:必然 OOM Kill
保守到底怎么"保守"?直接给公式
✅ 推荐通用安全比例(生产可用)
Heap ≤ memory limit 的 60%~70%
举例:2Gi 内存 Pod(强烈推荐)
yaml
memory limit: 2Gi
bash
-Xms1024m
-Xmx1280m| 项目 | 内存 |
|---|---|
| Heap | 1280Mi |
| Metaspace | 200Mi |
| Direct Memory | 300Mi |
| Thread Stack | 200Mi |
| JVM & 其他 | 100Mi |
| 总计 | ≈2080Mi(安全) |
✅ 更稳妥(高并发 / Netty / RPC 服务)
Heap = limit × 60%
bash
-Xmx1200m适合场景:
- Spring Boot + Netty
- 大量线程 / 连接
- 使用 DirectBuffer
直接给你一张「速查表」
| memory limit | 推荐 Xmx | 场景 |
|---|---|---|
| 512Mi | 256M | 极轻量服务 |
| 1Gi | 512M~640M | 普通 Web |
| 2Gi | 1.2G~1.4G | 常见生产 |
| 4Gi | 2.5G~2.8G | 高并发服务 |
| 8Gi | ≤5.5G | 大内存应用 |
👉 永远不要 Xmx = limit
Java 11+ 的"自动模式"也不是银弹
很多人用:
bash
-XX:MaxRAMPercentage=75问题在于:
- 75% 对 Netty / 大线程数服务 依然偏激进
- JVM 不知道你会开多少线程
- 也不知道 Direct Memory 用多少
👉 生产建议
bash
-XX:MaxRAMPercentage=60或干脆 显式 Xmx,更可控。
一个真实的生产教训(总结版)
我曾在生产中遇到:
- Java 服务 每天固定时间重启
- Node 内存看起来还有富余
- JVM 日志无 OOM
最终原因:
Xmx = memory limit × 90%
当业务高峰期:
- Direct Memory + 线程暴涨
- 容器瞬间超 limit
- kubelet 直接 OOM Kill
一套可落地的资源配置经验总结
结合实际经验,我逐渐形成了一套相对稳妥的配置思路:
- memory limit:作为容器总上限
- Xmx:建议控制在 limit 的 60%~70%
- requests:不低于服务稳定运行时的真实消耗
- CPU:对延迟敏感的 Java 服务,避免过度限制
合理的资源配置,目标不是"压到极限",而是稳定可预期。
写在最后:技术成长,来自对细节的尊重
回顾这一年,从最初的资源"拍脑袋",到现在能较为系统地规划 Pod、节点与 JVM 之间的关系,我深刻体会到:
运维的价值,往往体现在那些不出问题的细节中。
写博客,对我来说不仅是记录,更是一种反思和沉淀。希望这篇文章,能为正在使用 Kubernetes 承载 Java 服务的你,少踩几个坑。
总结
Kubernetes 的资源模型、宿主机的实际能力,以及 Java JVM 的内存管理,本质上是一个整体系统。
理解它们之间的边界与联系,是在云原生环境中保障业务稳健运行的关键。
只有尊重细节、合理规划资源,才能让服务真正稳定可控。