在上一篇博文中,我们借助感知器实现了手写数字分类。但不知道大家是否思考过一个关键问题:感知器会对整张图片进行"无差别全局学习",若我们对数字图像进行旋转、平移等简单变换,训练好的模型性能会大幅下降。核心原因在于,感知器无法聚焦图像的核心特征------那么,如何精准"提取"图像的关键特征再进行训练?这正是卷积神经网络(CNN)要解决的核心问题。本文将从原理到结构,带你完整理解CNN的工作逻辑。
一、先明确核心目标:CNN为何能解决感知器的局限?
感知器的核心缺陷的是"忽视图像的局部特征关联性":它将图像所有像素平铺为一维向量输入,丢失了像素的空间位置信息(比如数字"8"的上下两个圆圈的位置关系)。而CNN的核心设计思路是:先通过专用组件提取图像的局部特征(如边缘、纹理、轮廓),再基于这些特征完成分类------即使图像发生轻微旋转、平移,核心局部特征仍能被精准捕捉,从而提升模型的泛化能力。
二、CNN核心组件拆解:一层卷积的完整流程
CNN的特征提取能力,源于"卷积层+激活函数+池化层"的组合设计,这三个组件共同构成一层完整的特征提取单元。我们逐一拆解其作用:
1. 卷积层:特征提取的核心(卷积核的滑动与内积)
卷积层的核心工具是"卷积核"(本质是可学习的权重矩阵,常见3×3、5×5),其工作过程是"滑动窗口+内积计算":
-
卷积核在原始图像上按固定步长(通常为1)滑动,每次覆盖一块与卷积核尺寸相同的局部像素区域;
-
对覆盖的像素区域与卷积核进行内积计算(对应元素相乘再求和),得到一个新的数值;
-
所有滑动窗口计算完成后,这些新数值会组成一张"特征图"------特征图中数值越大的位置,代表该区域与当前卷积核匹配的特征越明显(即成功提取到目标特征)。
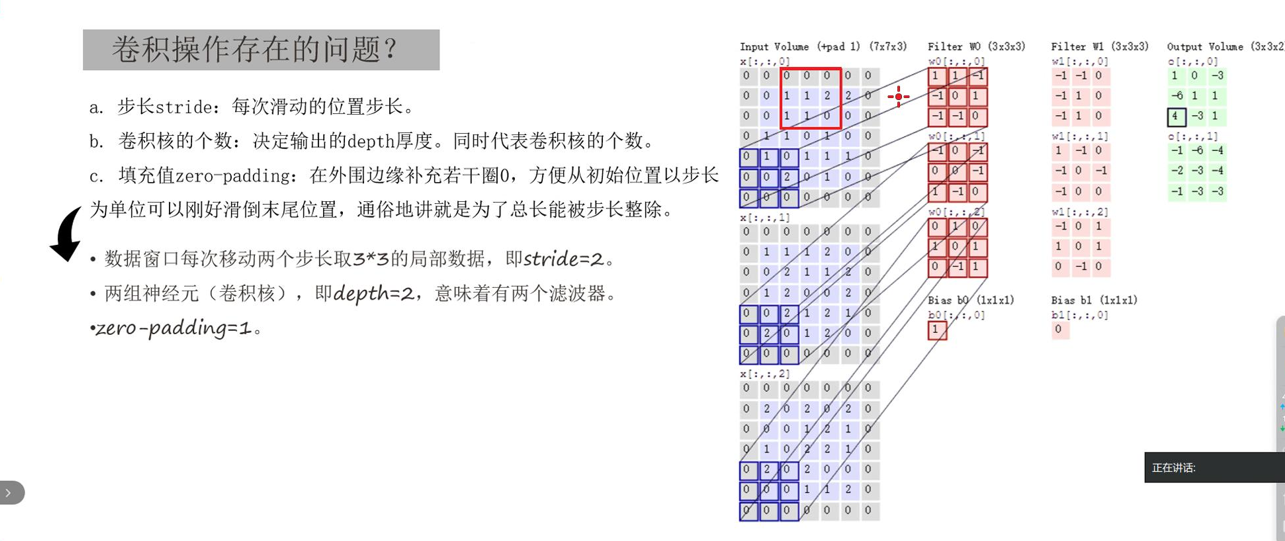
需要重点说明的是:每个卷积核对应一种特定特征(如垂直边缘、水平纹理),其权重并非人工设定,而是通过模型的梯度下降算法训练得到的。我们使用多个不同的卷积核,就能从原始图像中提取多种维度的特征,最终得到多张特征图(特征图数量=卷积核数量)。
从本质上看,CNN就是在感知器分类前增加了"特征提取环节":通过卷积层将原始图像转化为高维度的特征表示,再将这些特征输入后续网络完成分类,避免了感知器"盲目学习全局像素"的问题。
2. 激活函数:放大有效特征,注入非线性能力
卷积层的内积计算是线性变换,无法拟合图像中复杂的特征组合规律(如"边缘+纹理"构成的数字轮廓)。因此,卷积层输出后必须紧跟激活函数(常用ReLU),核心作用有两个:
-
放大有效特征:将特征图中小于0的数值置0(过滤无效特征响应),保留并放大有效特征的响应值;
-
注入非线性:让模型能够学习图像中非线性的特征组合规律(如不同角度边缘的交叉关系),增强模型的拟合能力。
3. 池化层:压缩数据维度,保留核心特征

经过卷积和激活后,特征图仍包含较多冗余信息(如相邻像素的特征响应高度相似)。池化层的作用是"数据压缩与特征提纯",常用方法有最大池化、平均池化,核心特点是:只压缩特征图的尺寸,不改变核心特征的分布规律。
以最常用的最大池化(2×2窗口,步长2)为例:它会在2×2的局部窗口中取最大值作为输出------这个最大值对应窗口内最显著的特征响应,既能将特征图尺寸压缩为原来的1/4(减少计算量),又能保留核心特征,同时提升特征的鲁棒性(轻微位置偏移不影响最大响应值的提取)。
总结:卷积层提取特征→激活函数放大有效特征→池化层压缩提纯,三者共同完成一次局部特征的提取与优化,这就是一层卷积的完整工作流程。我们可以通过堆叠多层这样的结构,实现从简单特征到复杂特征的逐步学习。
三、关键概念:感受野------理解CNN特征分层的核心
要真正理解"多层卷积为何能学习复杂特征",就必须掌握"感受野"的概念。它能帮我们清晰知道:特征图上的每个像素,对应原始图像的多大范围区域。
1. 感受野的定义
感受野指:CNN某一层特征图上的一个像素点,其数值由原始输入图像上"一块固定大小的像素区域"计算得来------这块原始图像上的区域,就是该特征点的感受野。简单说,感受野就是特征点"能看到"的原始图像范围。
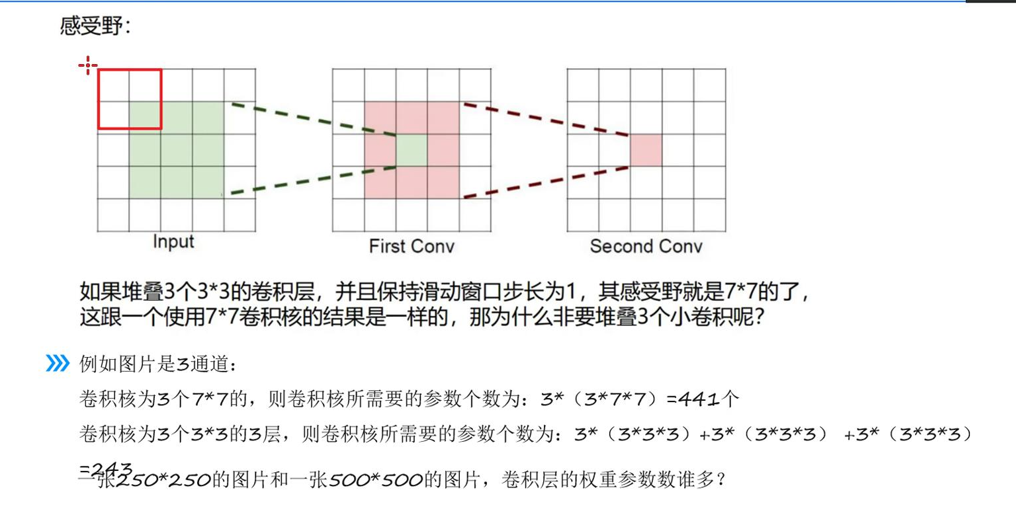
2. 感受野的核心规律(以3×3卷积核为例)
很多人会误以为:第一层3×3卷积的感受野是3×3,第二层再用3×3卷积,感受野就是3×3×3×3=9×9------这是典型误区!实际感受野的扩大遵循"边缘重叠扩展"规律,具体如下:
-
第1层卷积(3×3):特征点感受野=3×3(对应原始图像3×3的像素区域);
-
第2层卷积(3×3):特征点感受野=5×5(而非9×9);
-
第3层卷积(3×3):特征点感受野=7×7;
-
通用规律:n层3×3卷积(步长=1、padding=1)的感受野=(2n+1)×(2n+1)。
3. 关键误区纠正:为什么第二层感受野是5×5?
核心原因是"卷积核作用于前一层特征图,且相邻特征点的感受野存在重叠":
第二层卷积核需要覆盖第一层特征图的3×3个相邻像素,而这3×3个像素各自的感受野(3×3)在原始图像上是重叠的------9个重叠的3×3区域,最终只会覆盖原始图像5×5的范围,而非9×9的独立区域。这种重叠设计,正是CNN能精准捕捉特征组合的关键。
4. 感受野与特征分层的关系
感受野的大小,直接决定了CNN能学习的特征复杂度:
-
浅层卷积(小感受野,3×3/5×5):只能看到原始图像的局部区域,因此只能学习简单特征(如像素的明暗变化、线条边缘、基础纹理);
-
深层卷积(大感受野,7×7及以上):能看到原始图像的更大区域,因此可以在浅层简单特征的基础上,学习复杂的特征组合(如数字的轮廓、人脸的眼睛和鼻子等)。
5.三个3*3卷积核相比一个7*7卷积核的优势
四、从特征提取到分类:全连接层的作用
经过多层卷积+池化后,我们已经得到了编码图像核心特征的高维度特征图。接下来需要将这些特征转化为分类结果------这就是全连接层的使命,在CNN中,全连接层本质就是我们之前学习的"感知器"。
具体工作流程:
-
将多层卷积输出的特征图"展平":把二维的特征图转化为一维的特征向量(如64张7×7的特征图,展平后为64×7×7=3136维向量);
-
将一维特征向量输入全连接层(用PyTorch的
nn.Linear实现):全连接层本质是"只有输入层和输出层的简单感知器",其核心作用是学习"特征向量与分类标签的映射关系"(如"数字8的特征组合→标签8"); -
输出分类结果:全连接层的输出维度对应分类任务的类别数(如手写数字分类为10类,输出维度即为10)。
五、CNN的完整结构与训练逻辑
1. 完整结构总结
一张原始图像从输入到输出分类结果,需经过"特征提取→分类"两大阶段,完整结构为:
原始图像 → 卷积层(提取特征)→ 激活函数(放大特征)→ 池化层(压缩提纯)→ 多层卷积堆叠(学习复杂特征)→ 特征图展平 → 全连接层(感知器分类)→ 分类结果
2. 训练核心:优化卷积核参数
CNN的训练过程,核心是通过"损失计算→反向传播→梯度下降"找到最优参数,需要明确的是:
-
可训练参数:仅卷积核的权重和全连接层的权重/偏置(激活函数的计算规则、池化的方法是我们提前设定的,不参与训练);
-
训练逻辑:通过反向传播,将分类损失(预测值与真实标签的差距)传递到每一层,再通过梯度下降调整卷积核和全连接层的权重,让卷积核越来越精准地匹配图像特征,最终实现稳定分类。
六、项目案例:卷积神经网络实现首席数字分类
代码:
python
'''卷积神经网络
实现手写数字分类'''
import torch
import torch.nn as nn
from torchvision import datasets, transforms
# 加载数据时修改transform,增加Normalize
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # MNIST的均值和标准差(官方推荐值)
])
training_data = datasets.MNIST(
root="data",
train=True,
download=True,
# transform=transforms.ToTensor()
transform=transform
)
test_data = datasets.MNIST(
root="data",
train=False,
download=True,
# transform=transforms.ToTensor()
transform=transform
)
''' 定义神经网络 '''
class CNN(nn.Module):#类的名称。 2用法
def __init__(self): # 输入大小
super(CNN, self).__init__()#初始化父类
self.conv1 = nn.Sequential( #将多个层组合成一起。创建了一个容器,将多个网络合在一起
nn.Conv2d( #2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序列数据28*28
in_channels=1, # 图像通道个数,1表示灰度图(确定了卷积核 组中的个数),
out_channels=16, # 要得到多少个特征图,卷积核的个数
kernel_size=5, # 卷积核大小,5×5
stride=1, # 步长
padding=2, # 一般希望卷积核处理后的结果大小与处理前的数据大小相同,效果会比较好。那padding该如何设计呢?建议stride为1
), # 输出的特征图为16*28*28
nn.ReLU(), # relu层,不会改变特征图的大小
nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域),输出结果为16*14*14
)
self.conv2 = nn.Sequential( # 输入16*14*14
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=2), # 输出32*14*14
nn.ReLU(), # relu层
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), # 输出32*14*14
nn.ReLU(),
nn.MaxPool2d(2), #32*7*7
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), #64*7*7
nn.ReLU(), # 输出
)
self.out = nn.Linear(64 * 7 * 7, out_features=10) # 全连接层得到的结果
def forward(self, x):#这里必须要写 forward是来自于父类nn里面的函数 要继承父类的功能
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)#输出(64,64, 7, 7)
x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 64 * 7 * 7)
output = self.out(x)
return output
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CNN().to(device)#类的初始化完成,就会创建一个对象,model
print(model)
from torch.utils.data import DataLoader
batch_size = 64
train_dataloader = DataLoader(training_data, batch_size=batch_size,shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
# 5. 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
model.train() # 切换到训练模式
batch_size_num = 1 # 统计batch数量
for X, y in dataloader: # dataloader是函数形参,调用时传入train_dataloader/test_dataloader;迭代返回批次级数据:X为批次图片张量(shape[batch_size,1,28,28]),y为批次标签张量(shape[batch_size]),对应批次内所有样本的图片和标签
# 数据移动到设备
X, y = X.to(device), y.to(device)
# 前向传播计算预测值
pred = model(X) # 可省略.forward,model(X)会自动调用forward
loss = loss_fn(pred, y) # 计算损失
# 反向传播更新参数
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播计算梯度(原代码中Loss大写,修正为loss)
optimizer.step() # 更新模型参数
# 每100个batch打印一次损失
loss_value = loss.item()
if batch_size_num % 100 == 0:
print(f"Loss: {loss_value:>7f} [batch: {batch_size_num}]")
batch_size_num += 1
# 6. 定义测试函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集总样本数
num_batches = len(dataloader) # 测试集batch数量
model.eval() # 切换到测试模式
test_loss, correct = 0, 0
# 测试时关闭梯度计算,节省资源
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item() # 累计损失
# 计算正确预测数(取预测最大值对应的索引)
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# 计算平均损失和准确率
test_loss /= num_batches
correct /= size
print(f"Test result: \n Accuracy: {(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
# 7. 初始化损失函数和优化器
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失(适用于分类任务)
# optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # SGD优化器
# 原代码的optimizer替换为Adam
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Adam默认lr=0.001即可
# 8. 执行训练和测试
print("开始训练:")
train(train_dataloader, model, loss_fn, optimizer) # 训练一轮
test(train_dataloader, model, loss_fn) # 训练一轮运行结果: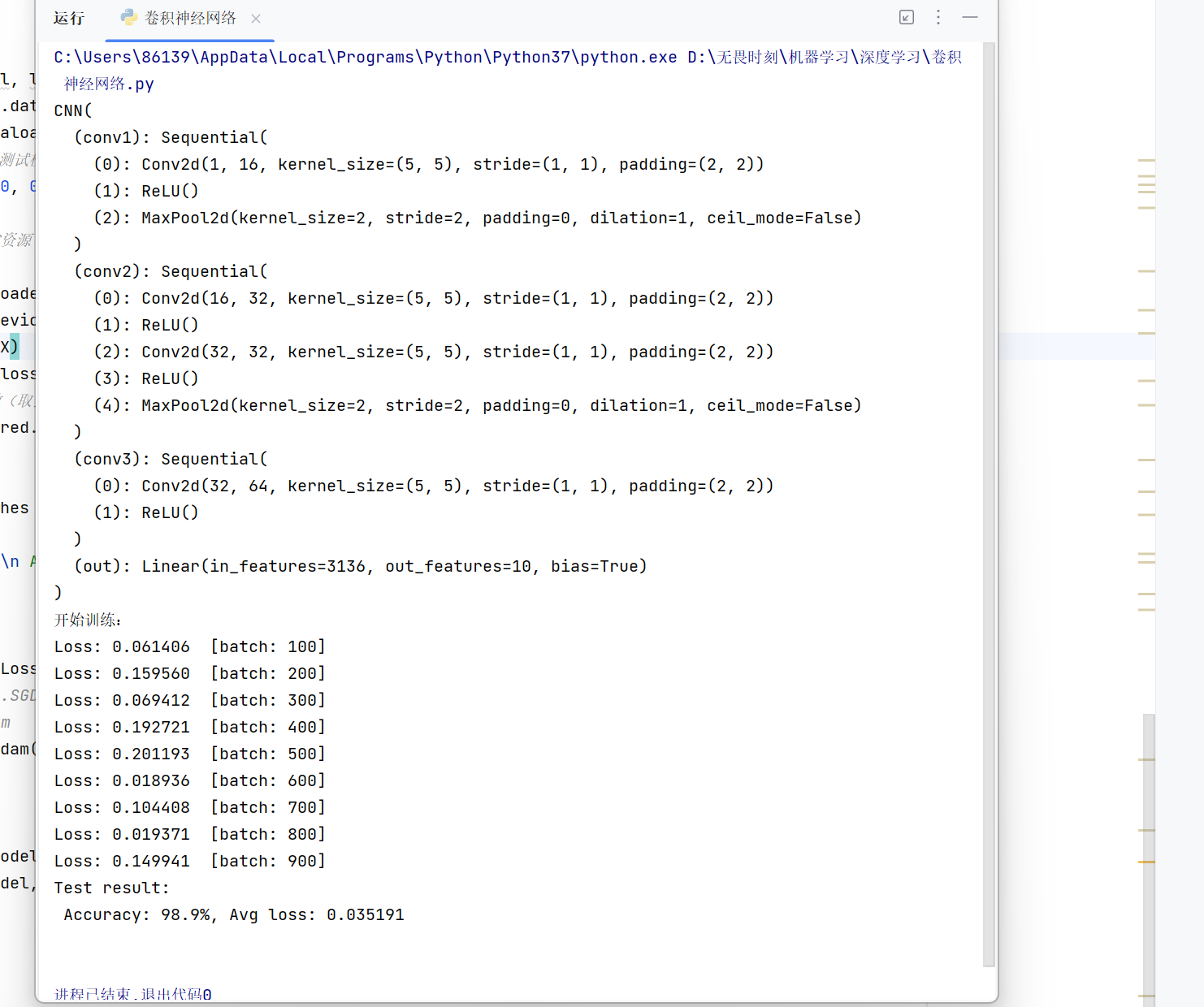
总结
CNN的核心优势,在于突破了感知器"无差别全局学习"的局限------通过卷积核提取局部特征、激活函数注入非线性、池化层压缩提纯,再借助感受野的渐进扩大实现"简单特征→复杂特征"的分层学习,最后通过全连接层(感知器)完成分类。理解CNN的关键,是搞懂"卷积核的训练逻辑"和"感受野的重叠扩展规律",这两个点也是区分"表面理解"与"深度掌握"的核心。