文章目录
- [类人脑的另一种计算 ------大语言模型large-lauguage-model](#类人脑的另一种计算 ——大语言模型large-lauguage-model)
-
- 一、出发点:函数f(x)
- 二、起点(线性回归)
- [三、进化(DNN 深度神经⽹络)](#三、进化(DNN 深度神经⽹络))
-
- 例题1:小狗识别函数模型
-
- [一次训练 = 前向传播&反向传播](#一次训练 = 前向传播&反向传播)
- 例题2:预测用户日均外卖消费模型
- 补充关键使用原则
- [为什么神经网络隐藏层要 "非常深"?(深度 = 更强的表达能力)](#为什么神经网络隐藏层要 “非常深”?(深度 = 更强的表达能力))
- [四、FM(因子分解机)------ 稀疏数据中的"特征相亲会"](#四、FM(因子分解机)—— 稀疏数据中的“特征相亲会”)
-
-
- [一、先搞懂:FM 要解决什么痛点?](#一、先搞懂:FM 要解决什么痛点?)
- [二、FM 的核心妙招:给每个特征发 "特质名片"(隐向量/embedding)](#二、FM 的核心妙招:给每个特征发 “特质名片”(隐向量/embedding))
- [三、FM 是什么?------ 线性模型的 "智慧升级版"](#三、FM 是什么?—— 线性模型的 “智慧升级版”)
-
- [FM 公式的 "升级三部曲"(附隐向量解读)](#FM 公式的 “升级三部曲”(附隐向量解读))
- [四、FM 的核心思想:化 "组合爆炸" 为 "向量内积"](#四、FM 的核心思想:化 “组合爆炸” 为 “向量内积”)
- [五、FM 如何工作?------ 以电影推荐为例](#五、FM 如何工作?—— 以电影推荐为例)
-
- [步骤 1:特征表示](#步骤 1:特征表示)
- [步骤 2:FM 前向计算](#步骤 2:FM 前向计算)
- [步骤 3:输出与训练](#步骤 3:输出与训练)
- [六、FM 的优缺点与总结](#六、FM 的优缺点与总结)
-
- 五、Transformer
-
-
- 5.1、先看Transformer解决了什么问题
- [5.2 RNN的思路:让AI拥有"短期记忆"------循环连接](#5.2 RNN的思路:让AI拥有"短期记忆"——循环连接)
- [5.3 Transformer思路:**让序列中的每个元素都能直接与所有其他元素对话**](#5.3 Transformer思路:让序列中的每个元素都能直接与所有其他元素对话)
- 自注意力如何工作:三张名片的故事
- [5.4 Transformer架构](#5.4 Transformer架构)
- [5.5 编码器|解码器](#5.5 编码器|解码器)
-
类人脑的另一种计算 ------大语言模型large-lauguage-model
第二章节:深入探究模型演变解析------模型怎么找出这种规律的
一、出发点:函数f(x)
在计算机的世界所有的数据都是0和1,也就是说都是符号化的,那么如何把这些符号表示为现实世界的某个现象?
在学到面向对象编程的时候就知道了,映射,把现实世界的物体映射为对象形式存储、展示
世界上所有一切的知识或逻辑都可以用函数来表达:"function describe the world"
人工智能早期的思路:::符号主义

一个最基础的线性函数: y = f(x) = wx + b
求物体做匀速直线运动的路程计算 (S=vt +s)
| 时间 t(秒) | 路程 s(米) |
|---|---|
| 1 | 7 |
| 2 | 9 |
| 3 | 11 |
可以求证:w =2、b=5
但是如果事先不知道匀速直线运动的路程公式是:S=vt +s
如何去求这个公式(规律/模型)? :(靠猜也能找出来规律)
数据点足够多了,线就出来了,y = 2x + 5 这个规律也就浮现出来了。
--y=2x+5
y
15 |
11 | ● (3,11)
9 | ● (2,9)
7 | ● (1,7)
5 | ● (0,5)
0 ─────────────── x
0 1 2 3 4这里介入两个个名词
- 训练数据:是⼀个完整的、宏观的集合。
- 样本:是这个集合中的单个成员。
二、起点(线性回归)
真实的世界中数据都不会是简单的一条直线的。如何寻找规律?
大差不差有时候也好用,比如说下图
这个叫联结主义:通过对大脑胜利结构复杂性模拟来实现智能
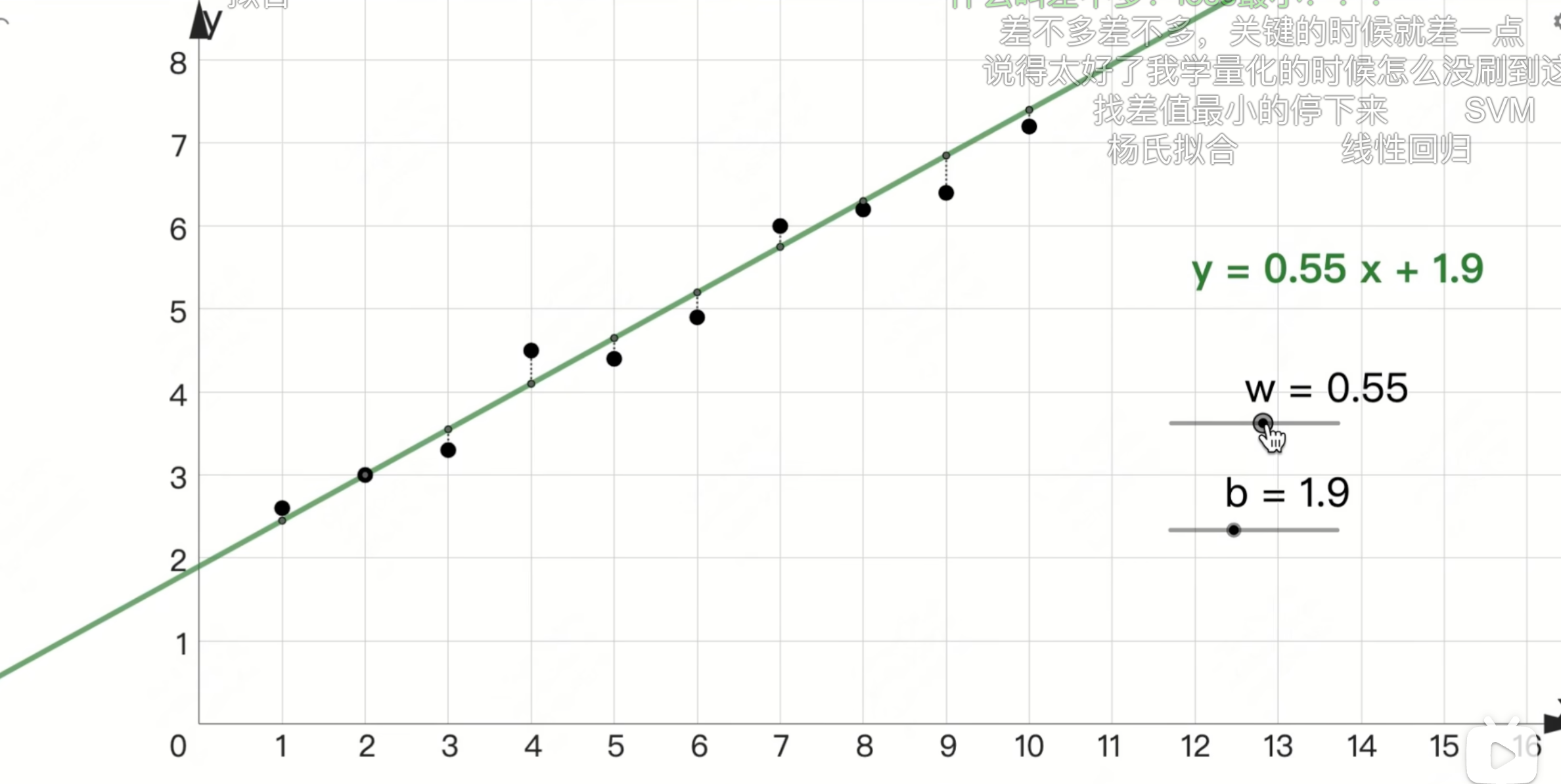
例:"每日学习时长(x,单位:小时)" 对应 "当日知识掌握得分(y,1-10 分)
给十组样本数据作为你的训练数据,让你总结规律
可以假设y = wx+b、y = sinbx + logw、y = (x * x + x/w)/b 、...
通过不断的计算发现当w = 0.55 b = 1.9的时候,这条线拟合的数据最好
那么怎么看拟合的好不好呢?
让模型的预测误差(损失)最小化也这些样本对于函数的均方误差(MSE) 最小
MSE =n 1∑i =1n (y p*red,i−*ytrain*,*i)2
通过不断的调整参数w和b,最后让MSE的值最小,
此时这条线y = o.55x+1.9就是我们要找的函数(规律)
important:在模型训练中的每一个函数都要经过回归操作
三、进化(DNN 深度神经⽹络)
前面说给出样本数据然后给出y = wx + b ,可以通过数据算出来w和b各是多少。
但是如果样本位置散乱,乍一看无规律性,还能假设函数是y = wx + b 然后去求w和b的值吗?
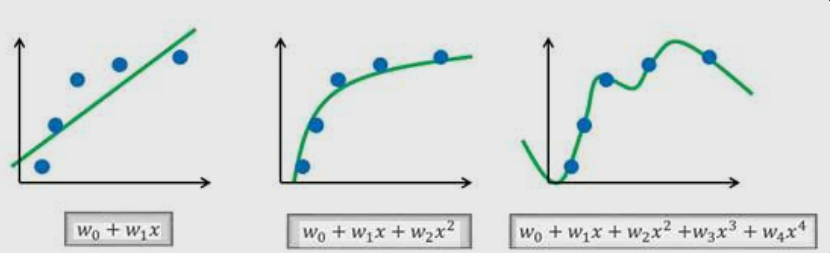
DNN就是为了解决这个问题,教你如何去构造假设函数,然后根据样本数据调整,最后训练出来贴近真实的函数。
为了解决传统模型搞不定的复杂非线性问题而诞生的工具
其本质是由大量神经元节点 和连接权重 组成的分层计算网络,核心是 多层复合函数 :通过"线性变换+非线性激活"的嵌套组合,拟合复杂的现实规律。
在理论上:只要神经⽹络⾜够宽或⾜够深,并配上合适的激活函数,它可以以任意精度逼近任何连续函数。
这个结论来⾃著名的"通⽤逼近定理(Universal Approximation Theorem)"。
DNN 涵盖所有(Depth ≥ 2)的神经⽹络
- MLP(多层感知机):全连接结构的 DNN,也是最基础的 DNN,比如后面的外卖消费预测模型;
- CNN(卷积神经网络):含卷积层、池化层,靠局部连接 / 权值共享减少参数,适合图像、语音等网格 / 序列数据;
- RNN/LSTM/GRU:带时序记忆能力的 DNN,适合文本翻译、语音识别等序列任务(LSTM/GRU 是 RNN 的改进版,解决梯度消失);
- Transformer:基于自注意力机制的 DNN,是大语言模型(GPT、BERT)的核心,适合长距离依赖的序列任务;
- GAN(生成对抗网络):由生成器 + 判别器组成的对抗式 DNN,用于图像生成、数据增强等生成式任务;
- ResNet/DenseNet:含残差连接 / 稠密连接的深层 DNN,解决超深层网络(几十到上百层)的训练难题。
:以mlp为例分析一下
由神经元节点之间做矩阵运算+偏置项+连接权重+激活函数+层级嵌套得到输出。
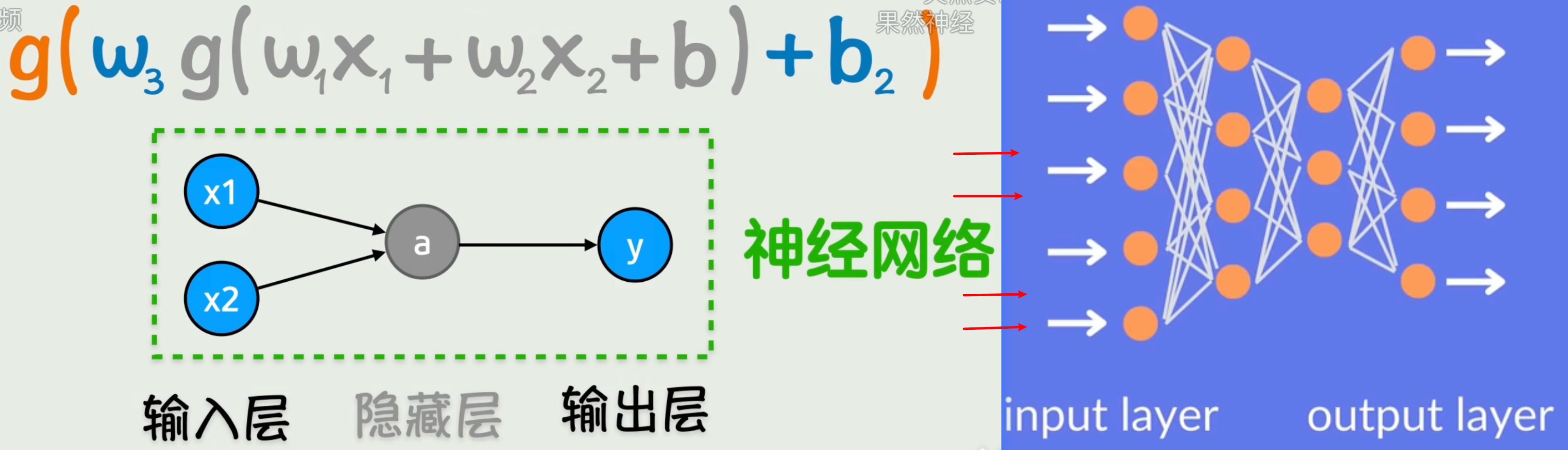
"神经网络"命名初衷是模仿人类神经元,但如今核心原理已与人类神经元运作模式无关,仅沿用旧名。
实际代码⾥,神经元和连线这些都不存在,只是数学上的依赖关系。
对于一个复杂的问题比如识别图片是否是小狗,需要多层(线性|非线性)函数一起努力才能实现此判断功能
例题1:小狗识别函数模型
简单列一列逻辑上如何去识别这个小狗
假设输入是一张 28×28 的小狗黑白图片 (计算机眼里是 784 个像素值),网络结构为:输入层 → 3 层隐藏层 → 输出层。
| 网络层级 | 核心任务 | 识别小狗的具体操作 | 形象比喻 |
|---|---|---|---|
| 输入层 | 接收原始数据 | 把 784 个像素值直接传入网络,不做任何计算。输入:[p1,p2,...,p784](p 是每个像素的明暗数值) |
把一堆打乱的拼图碎片交给工人,碎片只有黑白深浅,没人知道这是啥 |
| 第 1 层隐藏层(浅层) | 提取 底层基础特征:孤立的边缘、色块 | 每个神经元关注「相邻像素的明暗变化」,提取小狗的基础特征:1. 神经元 A 识别「垂直线条」→ 对应小狗的鼻梁边缘;2. 神经元 B 识别「半圆形边缘」→ 对应小狗的耳朵轮廓;3. 神经元 C 识别「短粗的水平线条」→ 对应小狗的嘴巴边缘。输出:一堆 "线条、半圆、短横线" 的基础特征 | 工人 1:只挑出所有 "竖条、半圆、短横线" 的碎片,不管这些碎片属于什么 |
| 第 2 层隐藏层(中层) | 整合底层特征 → 提取 局部部件特征 | 每个神经元接收第 1 层的基础特征,组合成小狗的局部部件:1. 神经元 X 把「垂直线条 + 短横线」组合 → 识别出「小狗的鼻子 + 嘴巴轮廓」;2. 神经元 Y 把「两个半圆形边缘」组合 → 识别出「小狗的耷拉耳朵」;3. 神经元 Z 把「平滑的曲线边缘」组合 → 识别出「小狗的圆脑袋轮廓」。输出:一堆 "鼻子、耷拉耳朵、圆脑袋" 的局部部件特征 | 工人 2:把工人 1 挑的碎片拼出 "小块零件",但还分不清是小狗的耳朵还是其他动物的 |
| 第 3 层隐藏层(深层) | 整合局部部件 → 提取 全局抽象特征 | 每个神经元接收第 2 层的局部部件,组合成小狗的整体特征:1. 神经元 P 把「耷拉耳朵 + 圆脑袋 + 鼻子嘴巴」组合 → 识别出「小狗的头部特征」;2. 神经元 Q 把「头部特征 + 短粗的身体轮廓」组合 → 识别出「小狗的专属整体特征」。输出:和小猫、兔子完全不同的 "小狗特征向量" | 工人 3:把工人 2 拼的零件组装,拼出 "带耷拉耳朵、短鼻子的小动物脑袋",能明显区分出不是小猫 |
| 输出层 | 特征分类 → 输出最终结果 | 把第 3 层的 "小狗特征向量" 和训练过的 "狗 / 猫 / 兔子特征模板" 对比,计算匹配概率:- 匹配 "狗模板" 概率:98%- 匹配 "猫模板" 概率:2%取概率最大的类别,输出结论 | 质检员:对比成品和 "狗的标准样本",判断 "这就是一只小狗" |
- 浅层抓「基础细节」(边缘、线条);
- 中层拼「局部部件」(耳朵、鼻子);
- 深层整「全局特征」(动物专属特征);
- 输出层做「最终分类」。
多层神经网络的每一层都有明确分工,相当于流水线式的特征加工:
并且在一层的多个神经元之间可以进行并行运算,利用CPU强大的矩阵运算
神经元 A识别的垂直线条和和神经元D识别的短横线经过g(x)的处理输入给神经元X
神经元B识别的半圆形和和神经元B识别的半圆形经过g_2(x)的处理输入给神经元Y
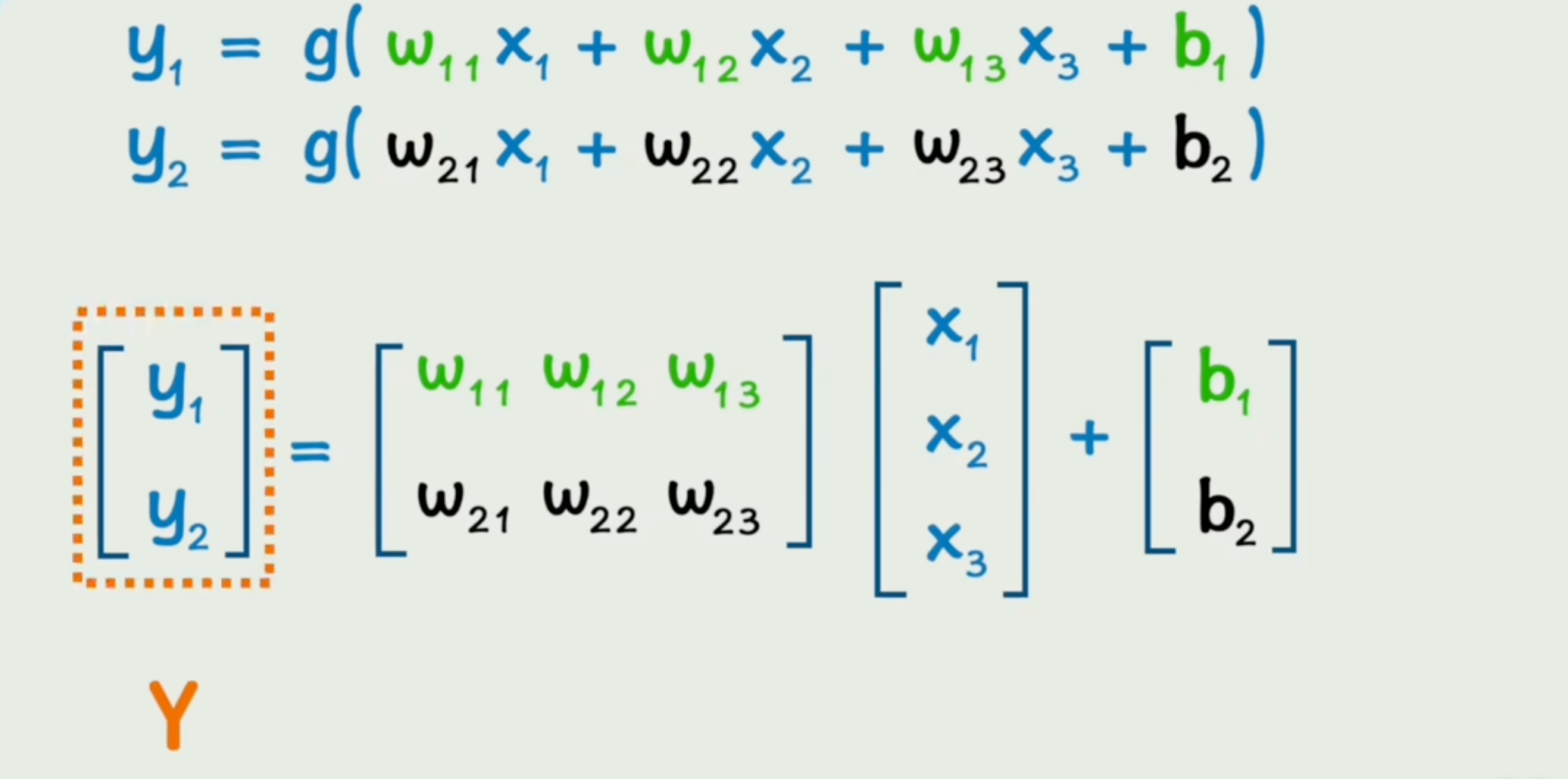
一次训练 = 前向传播&反向传播
用5 层识别小狗的神经网络,一句话讲清核心逻辑:
- 前向传播 = 从输入到输出的 "猜答案" 过程
- 反向传播 = 从误差到参数的 "改错题" 过程
两者循环跑,模型就从 "瞎猜" 变成 "精准识别小狗"。
一、前向传播:猜答案
用求导方式找梯度下降方向。
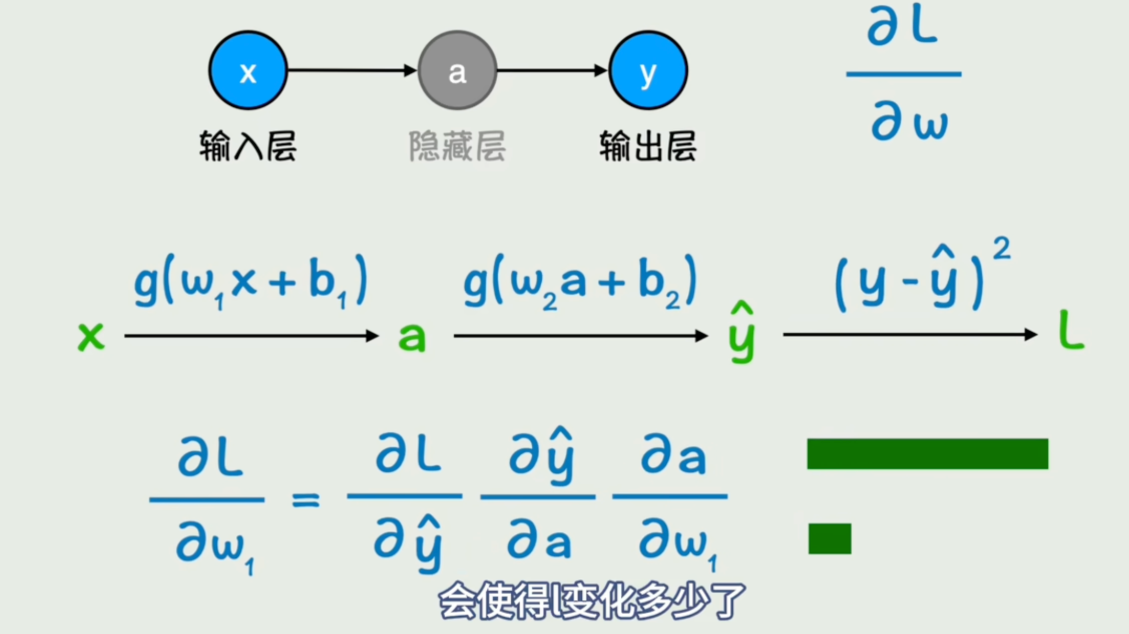
- 输入:把小狗图片的像素数据喂给第 1 层。
- 逐层计算 :每一层用随机的 w (权重)和 b(偏置),把数据加工成特征(边缘→耳朵→小狗轮廓),最后传到输出层。
- 出结果:输出层猜一个答案(比如 "是小狗的概率 20%")。
- 算误差:拿猜测结果和真实答案("是小狗,概率 100%")对比,用 MSE 之类的公式算出误差有多大。
第一次猜肯定差很远!因为 w 和 b 都是随机的。
二、反向传播:改错题
- 从后往前算 :从输出层的误差出发,一层一层倒着算 ------ 每一层的 w 和 b 错在哪、该怎么调(求导的方式)。
- 调整参数 :把每一层的 w 和 b 往 "减小误差" 的方向改一点点。
- 结束一轮:改完所有层的参数,反向传播就完成了。
三、循环迭代:越练越准
- 一次前向传播 + 一次反向传播 = 模型学习了一次
- 反复练成千上万次,w 和 b 就会调到最优
- 最后模型看到新图片,能直接精准猜出 "这是小狗"
链式法则:底层数学基础,解决大模型中"复合函数梯度怎么算"的问题(大模型是多层函数嵌套,需通过链式法则拆解梯度计算);
梯度下降:反向传播中调整参数的目的
例题2:预测用户日均外卖消费模型
一、场景背景与核心变量
- 预测目标
因变量 ( y ):用户日均外卖消费金额(单位:元)------ 连续值,对应MLP的回归任务。
- 输入特征(自变量)
选取3个影响外卖消费的核心数值特征(对应MLP的输入层神经元):
- ( x_1 ):用户月可支配收入(单位:千元)
- ( x_2 ):用户日均工作时长(单位:小时)
- ( x_3 ):用户与最近外卖商家的平均距离(单位:km)
训练MLP模型常用的激活函数
激活函数的核心作用是给线性计算引入非线性,让模型能拟合复杂的现实规律(比如外卖消费决策)。以下是训练中最常用的4种,按适用场景分类整理:
| 函数名称 | 公式 | 值域 | 适用层级 | 核心作用 & 现实含义(外卖消费场景) |
|---|---|---|---|---|
| ReLU(修正线性单元) | ReLU(z) = max(0,z) | [0, +∞) | 隐藏层(首选) | 1. 过滤负数:消费潜力/意愿不可能为负,直接置0 2. 计算快,缓解梯度消失,适合深层网络 |
| Sigmoid(逻辑斯蒂函数) | Sigmoid(z) = 1/(1+e⁻ᶻ) | (0,1) | 二分类输出层 | 1. 压缩值域到0~1:可表示"消费概率"(比如下单概率0.8)2. 输出层用它映射到概率区间,符合分类任务需求 |
| Tanh(双曲正切函数) | Tanh(z) = (eᶻ - e⁻ᶻ)/(eᶻ + e⁻ᶻ) | (-1,1) | 隐藏层(少数场景) | 1. 输出中心化(均值接近0),比Sigmoid收敛快 2. 适合需要区分"正负向影响"的特征(比如"优惠力度"对消费的正负作用) |
| Softmax | Softmax(zᵢ) = eᶻⁱ / Σ(从j=1到n)eᶻʲ | (0,1)(所有输出和为1) | 多分类输出层 | 1. 输出类别概率分布:比如预测用户"点快餐/正餐/饮品"的概率分别是0.6/0.3/0.12. 适用于消费类型、商家品类等多分类任务 |
补充关键使用原则
- 隐藏层优先用ReLU:计算高效,梯度稳定,是最主流的选择;
- 输出层看任务类型:二分类用Sigmoid,多分类用Softmax,回归任务可不用激活函数;
- 避免Sigmoid用于深层隐藏层:容易出现梯度消失,导致模型训练不动。
-
每层都是简单非线性函数 ,但嵌套叠加后会形成高度复杂的非线性映射,曲线的 "弯曲程度" 随层数增加而显著提升。
-
层数越多,函数的表达能力越强,能拟合的现实规律越复杂(对应深度神经网络的 "深层优势")。
-
最终输出 y (x ) 与原始输入 x 无任何线性关系,这是多层激活函数实现复杂任务的核心原理。

二、复合函数的分层定义(对应MLP层级)
复合函数的本质是"函数套函数",下一层的输入是上一层的输出。关键修改:给每层函数赋予现实含义,让抽象计算对应具体的消费影响逻辑,以下分层拆解既贴合MLP前向传播,又容易理解:
- 第一层(输入层→隐藏层1:"基础消费能力"计算,线性组合+ReLU激活)
核心逻辑:先整合"收入、工作时长、距离"3个基础信息,计算用户的"基础外卖消费潜力"------ 收入越高、工作越忙(没时间做饭)、距离商家越近,基础潜力越高;再用ReLU过滤"负潜力"(现实中没有"负消费能力"):
h₁(x₁,x₂,x₃) = ReLU(w₁₁x₁ + w₁₂x₂ + w₁₃x₃ + b₁)
现实含义说明:
h 1=ReLU(z 1)=max(0,z1)
( w_{11},w_{12},w_{13} ):特征权重(可理解为"影响系数")------ 比如( w_{11} )(收入权重)最大,因为收入是消费的核心决定因素;( w_{13} )是负数(距离越远,消费潜力越低);( b_1 )是基础偏移(比如"不管什么条件,都可能有一点外卖需求")
ReLU激活函数:ReLU(z) = max(0,z)------ 现实中"消费潜力"不可能为负,比如收入极低、工作极闲、距离极远的用户,基础消费潜力设为0(不会考虑外卖),这就是ReLU"过滤负信号"的现实意义
( h_1 ):最终的"基础消费能力"得分(比如0~10分),是对3个基础特征的第一次抽象整合
- 第二层(隐藏层1→隐藏层2:"消费意愿强化"计算,线性缩放+ReLU激活)
核心逻辑:基于"基础消费能力",进一步强化"高潜力用户的消费意愿"、弱化"低潜力用户的意愿"------ 比如基础能力强的用户,再放大其消费倾向;基础能力弱的用户,进一步压低,再用ReLU确保"意愿不为负":
h₂(h₁) = ReLU(w₂·h₁ + b₂)
现实含义说明:
( w_2 ):"意愿放大系数"(比如1.2)------ 让基础能力强的用户(比如得分8分)变成9.6分,意愿更明确;( b_2 ):"意愿补偿"(比如给基础能力一般的用户加0.5分,避免直接忽略)
( h_2(h_1) ):"强化后消费意愿"得分(比如0~12分)------ 现实中,消费决策不是"基础能力"的简单叠加,而是会有"意愿放大"效应(比如高收入用户不仅能消费,还更愿意为便利付费),这就是第二层嵌套的现实意义
- 第三层(隐藏层2→输出层:"实际消费金额"转换,线性映射+Sigmoid约束)
核心逻辑:把"强化后消费意愿"(得分)转换成真实的"日均消费金额"------ 先用Sigmoid把得分约束在01之间(统一"意愿强度"的范围),再通过线性缩放映射到现实的消费金额区间(比如0200元):
y(h₂) = w₃·Sigmoid(w₄·h₂ + b₃) + b₄
现实含义说明:
( w_4 ):"意愿强度调节系数"------ 调整Sigmoid的敏感程度(比如让意愿得分5分以上就接近1,5分以下快速降低);( w_3 ):"金额缩放系数"(比如200,把01的强度映射到0200元);( b_3,b_4 ):金额偏移(比如( b_4=10 ),确保最低消费不低于10元,符合外卖起送价逻辑)
Sigmoid激活函数:Sigmoid(z) = 1/(1+e⁻ᶻ)------ 现实中消费金额有上限(再愿意消费,日均也不会花几千元),Sigmoid就是给"意愿得分"加一个"天花板",避免预测出不合理的高金额
在拟合过程中会发现有些函数只是用类似于w₁₁x₁ + w₁₂x₂ + w₁₃x₃ + b₁永远实现不了效果,输出层只有3个特征不够推理。
可以通过构建交叉特征做来一个输入层的内容,比如w₁₄ × (x₁ × x₂²)、w₁₄ × (x₁ / x₂²)、、、
新增了交叉特征,函数的图像会有显著的差别,效果也就不约而同
三、完整的复合函数表达式(整合所有层级)
将分层函数逐步嵌套,结合现实逻辑,最终得到完整复合函数(每一层都对应真实的消费决策过程):
y(x₁,x₂,x₃) = w₃·Sigmoid(w₄·ReLU(w₂·ReLU(w₁₁x₁ + w₁₂x₂ + w₁₃x₃ + b₁) + b₂) + b₃) + b₄
四、与神经网络/MLP的核心对应关系
| 复合函数组成部分 | 对应MLP的结构/概念 | 核心作用 |
|---|---|---|
| 原始输入 ( x_1,x_2,x_3 ) | MLP输入层神经元 | 提供模型学习的原始数据 |
| 线性变换(如 w₁₁x₁ + w₁₂x₂ + w₁₃x₃ + b₁) | MLP的权重矩阵乘法+偏置加法 | 对输入特征进行线性组合,提取基础特征 |
| ReLU/Sigmoid激活函数 | MLP的激活层 | 引入非线性,让模型能拟合复杂的现实规律(核心!没有激活的多层线性组合依然是线性函数) |
| 分层嵌套(h₂(h₁(x₁,x₂,x₃))) | MLP的隐藏层堆叠 | 通过深层嵌套,逐步学习从"简单特征"到"复杂特征"的映射(如从"收入"到"消费能力"的抽象) |
| 最终输出 y(x₁,x₂,x₃) | MLP输出层神经元 | 给出预测结果(日均外卖消费金额) |
为什么神经网络隐藏层要 "非常深"?(深度 = 更强的表达能力)
"深" 指的是隐藏层的层数多(比如深度学习里的几十层、上百层网络),这么做的核心原因有两个:
-
深度网络的 "效率优势":用更少的参数实现更强的拟合 理论上,一个足够宽的单层网络 (神经元数量极多)也能拟合复杂函数(万能逼近定理),但它需要的参数数量会爆炸式增长。
- 比如:要拟合 "识别狗" 的函数,单层网络可能需要百万级神经元;而深度网络(比如 ResNet50)只用 50 层、几十万参数就能实现,参数效率远超单层。
- 原因是:深度网络通过逐层复用特征,把复杂任务拆解成多个简单子任务(边缘→纹理→轮廓),每层只负责解决一个小问题,每层中单个神经元无需处理不想干的内容,叠加起来就解决了大问题。
-
深度网络的 "能力优势":捕捉更抽象的规律层数越深,网络能捕捉的特征就越抽象,越接近任务的本质:
-
比如在金融风控
场景:
- 浅层:提取用户的 "单笔消费金额、还款延迟天数" 等基础特征;
- 中层:整合出 "月均消费波动、还款稳定性" 等中层特征;
- 深层:抽象出 "用户违约风险倾向" 这种核心特征。
-
如果层数不够深,网络只能停留在表面特征,无法理解数据背后的深层规律。
-
-
补充:通⽤逼近定理并不符合现实,一方面是数据、特征不足,算力、网络结构不可能无限延伸,即便能,神经网络也不是越深越好 ------ 避免过拟合和梯度消失 深度也有副作用:层数太多会导致梯度消失 (训练时梯度传递到浅层几乎为 0,参数无法更新)、过拟合 (模型学了太多训练数据的噪声)。所以现在的深度网络会用残差连接(ResNet)、批量归一化(BN) 等技术解决这些问题,让深层网络能稳定训练。
一句话总结:
多层结构是为了实现层级化特征提取 ,解决单层网络无法处理的复杂非线性问题;而深层隐藏层是为了用更高的参数效率,捕捉更抽象的规律,让模型在复杂任务(图像、语音、文本、金融预测)上表现更好。
四、FM(因子分解机)------ 稀疏数据中的"特征相亲会"
FM
它没有选择搭建复杂的多层舞台,而是为每个特征赋予一个"潜在特质向量 "。通过计算向量间的"默契度"(内积)来优雅地建模所有两两特征的"对手戏"。它在稀疏、高维特征交叉 这个特定领域,提供了计算高效、泛化性强的卓越解决方案。
一、先搞懂:FM 要解决什么痛点?
在前面,我们领略了深度神经网络(DNN)如何通过复杂的多层嵌套函数,像精密的流水线一样,从图像中识别小狗、从多个特征中预测消费金额。DNN的强大之处在于其能够自动学习并组合出高度非线性的特征函数。
然而,在现实世界的另一类关键问题中,DNN的"大力出奇迹"却可能遭遇尴尬。这类问题的典型代表就是推荐系统 和点击率预测(CTR)。
想象这个场景:
你要为一家视频网站预测用户用户A是否会点击电影《星际穿越》。
你的特征可能包括:
- 用户ID:
用户A - 电影ID:
《星际穿越》 - 用户历史平均评分:
4.5 - 电影平均评分:
9.0 - 今天是周几:
周六
特征数据被处理成"稀疏特征向量 "。例如,用户ID和电影ID这类类别型特征,会使用"独热编码 (one-hot)"变成一个极长的、大部分位置为0,只有一个位置为1的向量(类似于redis中的BITMAP,因为DNN只能处理述职型数据,所以需要把特征转换为ID)。
text
用户A -> [0, 0, 1, 0, 0, ... 0] (假设在100万用户中排第3位)
《星际穿越》 -> [0, 1, 0, 0, 0, ... 0] (假设在10万个电影中排第2位)核心挑战浮现:
- 特征极度稀疏:对于任何一条样本(一次用户-物品交互),特征向量中99.99%以上的元素都是0。
- 组合爆炸与冷启动 :我们凭经验知道,"用户A"和"《星际穿越》"这个组合本身蕴含着极强的信息。但这是一个二阶特征交叉 。在稀疏数据中,很多用户-物品组合可能从未出现过(例如新用户遇到新电影)。传统线性模型(
y = wx + b)无法学习这种组合,而DNN虽然理论上能学,但在数据稀疏时,需要海量样本才能学到有效的交叉权重,极易过拟合或根本学不到。
用 "相亲会" 比喻理解现有方法的不足:
- 线性回归:只看单个嘉宾的自身条件(收入、身高),不管嘉宾间是否合拍;
- DNN:能学习复杂的匹配模式,但需大量相亲案例才能总结规律,对新嘉宾的匹配度判断极不准;
- FM:兼顾 "单个条件" 和 "匹配度",且无需海量案例,是稀疏场景下的最优解。
这就是因子分解机(Factorization Machine, FM)登场的时刻。
二、FM 的核心妙招:给每个特征发 "特质名片"(隐向量/embedding)
隐向量就是 embedding ,它可以理解为一个数组,如0.85,0.1,0.32,0,0.25...
这个embedding也不是人定义的,而是经过大模型独立一万万本书后算出来的
模型会根据真实标签的反馈不断调整隐向量数值,最终让同一维度在不同特征上具备 "可匹配的语义"。
每个位置处代表一个特征值,用两个向量的点积或余弦相似度表示向量之间的相似度
以此将自然语言转化为了用数学公式计算出来的方式。
引⼊了 embedding 的概念,某个特征不再是有⼀个参数,⽽是有⼀批参数。
这也是大模型理解人类语言的方式:
比如说man和woman都是人类,但是性别截然相反
可理解为向量数组
- 假设1维隐向量代表是否为雄性,二维向量代表是否为雌性、三维向量代表是否为人类,
- man:0.9,0.1.9...
- woman:0.1,0.9,0.9...
向量可以表示很多个维度,描述和理解更清晰,同时相似的词对应的向量坐标也会距离更近
比如说三个长度表示也就是三维坐标(在gpt3中长度是12288)中,每个词组用向量表示(xyz以及长度:实际可能更多方向坐标),这样不同的词组它们的向量会是靠近的。比如根据余弦相似度(两个向量的角度)或欧几里得距离(两个向量的空间中的直线距离)来度量对象之间的相似性,这样也能快速判别出吃的苹果和用的苹果手机中都是苹果但它们的向量值是相差很远的

三、FM 是什么?------ 线性模型的 "智慧升级版"
FM 是逻辑回归 / 线性回归的直接扩展,通过 "分解思想" 建模所有特征的两两交互(二阶交叉),核心是 "给每个特征分配隐向量,用向量匹配度代替直接计算组合权重"。
假设说
-
一维特征代表:优质内容偏好 / 优质内容属性
-
二维特征代表:"大众属性"
FM 公式的 "升级三部曲"(附隐向量解读)
| 模型部件 | 公式片段 | 现实世界的意义 | 相亲会比喻 |
|---|---|---|---|
| 1. 偏置项 | b | 全局基础倾向(如平台整体平均点击率) | 相亲会的整体氛围基调(如全场氛围活跃,所有人的基础交流意愿更高) |
| 2. 线性项 | Σwᵢxᵢ | 单个特征的独立影响力(如用户 A 本身爱点电影、《星际穿越》本身热度高) | 单个嘉宾的自身吸引力分数(如收入高、性格好等独立条件的加分) |
| 3. 交叉项(FM 核心) | ΣΣ⟨vᵢ,vⱼ⟩xᵢxⱼ | 特征两两组合的 "化学效应"(如用户 A 与《星际穿越》的科幻偏好匹配),其中:① vᵢ/vⱼ:特征 i/j 的隐向量;② ⟨vᵢ,vⱼ⟩:向量内积(匹配度);③ xᵢxⱼ:特征 i/j 是否同时出现 | 两个嘉宾的 "配对分数"(通过各自的 "特质档案"(隐向量)计算匹配度) |
匹配度(内积)计算示例 :用户 A 隐向量[0.9, 0.2]、《星际穿越》隐向量[0.85, 0.1],匹配度 = 0.9×0.85 + 0.2×0.1 = 0.785(值越大,特征匹配度越高)。
完整的FM模型方程如下:
y(x) = b + Σⁿᵢ₌₁wᵢxᵢ + Σⁿᵢ₌₁Σⁿⱼᵢ₊₁⟨vᵢ,vⱼ⟩xᵢxⱼ
|| |_____________________|
线性部分 核心:二阶交叉部分
其中:
- y(x) 是预测值(如点击概率)。
- xᵢ 是第 i 个特征的值。
- wᵢ 是第 i 个特征的线性权重(与传统逻辑回归相同)。
- vᵢ 是一个 k 维的隐向量,这是FM的灵魂。
- ⟨vᵢ,vⱼ⟩ 代表向量 vᵢ 和 vⱼ 的点积(内积),它衡量了特征 i 和特征 j 的交互强度(匹配度)。
- i=1,j=i+1:两两组合,不重复算
四、FM 的核心思想:化 "组合爆炸" 为 "向量内积"
关键问题:为什么不直接用一个新的权重 wᵢⱼ 来表示特征 i 和 j 的交叉呢?(即 y = ... + ΣΣwᵢⱼxᵢxⱼ)
答
- 如果有 n 个特征,那么二阶交叉参数 wᵢⱼ 的数量是 O(n²),对于百万级特征,参数将达到万亿级,无法训练。
- 更重要的是,在稀疏数据中,绝大多数 (i, j) 组合在训练数据中从未同时出现(例如,"某个小众用户"和"某个冷门电影"),对应的 wᵢⱼ 根本得不到有效训练,始终为随机值,预测时毫无意义。
- 这会带来参数爆炸和数据稀疏灾难。
FM的智慧解决方案------分解思想:
FM为每个特征 i 学习一个 k 维的隐向量 vᵢ,然后用两个特征隐向量的内积 ⟨vᵢ,vⱼ⟩ 来作为它们交叉权重 wᵢⱼ 的估计。
wᵢⱼ ≈ ⟨vᵢ,vⱼ⟩ = vᵢ₁vⱼ₁ + vᵢ₂vⱼ₂ + ... + vᵢₖvⱼₖ
这一设计的核心价值:
- 参数大幅减少:参数从 O (n²) 降至 O (n・k)(k 为隐向量维度,通常取 16-64),百万级特征 + 32 维隐向量仅需 3200 万参数,可高效训练;
- 解决冷启动问题:即使 "用户 A + 电影 Z" 从未出现,用户 A 的隐向量(通过与其他电影交互学习)、电影 Z 的隐向量(通过与其他用户交互学习)仍可计算匹配度,实现有效预测。
相亲会比喻强化理解:
- 隐向量 vᵢ:嘉宾的 "潜在特质档案"(如浪漫度、幽默感、事业心),通过与其他嘉宾的互动学习得到;
- 内积⟨vᵢ,vⱼ⟩:两个嘉宾的特质匹配度(浪漫配浪漫、幽默配幽默得分高),即使未约会过,也能预测合拍程度。
五、FM 如何工作?------ 以电影推荐为例
模拟 FM 预测 "用户 A 点击《星际穿越》" 的完整流程:
步骤 1:特征表示
将类别特征(用户 ID、电影 ID)独热编码,与数值特征(评分、周几)拼接为稀疏特征向量 x,特征索引如下:1: 用户 A(x₁=1)、2:《星际穿越》(x₂=1)、3: 用户平均分 4.5(x₃=4.5)、4: 电影平均分 9.0(x₄=9.0)、5: 周六(x₅=1)。
步骤 2:FM 前向计算
-
线性部分 :计算
b + w₁x₁ + w₂x₂ + w₃×4.5 + w₄×9.0 + w₅×1,与逻辑回归计算方式一致; -
交叉部分(核心)
:计算所有非零特征的两两交互:
- 非零特征:用户 A、《星际穿越》、用户分 4.5、电影分 9.0、周六;
- 计算逻辑:取出两个特征的隐向量→算内积(匹配度)→乘以特征值乘积(xᵢ×xⱼ);
- 核心交叉项:(用户 A, 《星际穿越》)=
⟨v_用户A,v_星际穿越⟩×1×1,即两者的专属匹配度。
步骤 3:输出与训练
- 输出:线性部分 + 交叉部分求和后,通过 Sigmoid 函数转换为 0-1 的点击概率;
- 训练:通过反向传播调整线性权重 wᵢ和隐向量 vᵢ,使预测概率贴近真实标签(点击 / 未点击)。训练中,用户 A 的隐向量会根据其与所有交互电影的隐向量调整,《星际穿越》的隐向量会根据所有点击用户的隐向量调整,最终每个特征的隐向量都蕴含其与其他特征的交互模式。
六、FM 的优缺点与总结
| 方面 | 说明 |
|---|---|
| 核心优势 | 1. 高效处理稀疏特征交叉 :分解思想降低参数规模,可泛化到未出现的特征组合;2. 线性时间复杂度 :交叉项计算复杂度为 O (kn),计算极快;3. 兼顾表达与泛化:比线性模型强,比 DNN 在稀疏场景更稳健。 |
| 主要局限 | 1. 仅限二阶交叉 :仅建模两两特征交互,高阶复杂模式(如 "年轻男性 + 周末晚上 + 科幻片")需结合 DNN(如 DeepFM);2. 隐向量解释性弱:"潜在特质" 无直观物理含义,不如 wᵢ易理解。 |
| 经典应用 | CTR 预估、推荐系统、广告竞价等大规模稀疏特征交叉场景。 |
FFM 模型引⼊了特征域的概念,不同的特征在和其他域的特征交叉的时候,使⽤不同的 embedding,毕竟不同的域信息也不太一样。
在实际项⽬⾥在⽤的时候也可以灵活一点,不需要对所有特征都进⾏交叉,可以挑⼀部分,⽽且不同特征交叉的时候使⽤的 embedding ⻓度也可以不⼀样。
五、Transformer
这个知识名词举例+解释有点复杂了。。。主要介绍一下思想
在Transformer之前,处理文本、语音这类序列数据的主流模型是**循环神经网络(RNN)**及其改进版 LSTM 和 GRU。
Transformer来自于谷歌2017年的文章**《Attention Is All You Need》**
5.1、先看Transformer解决了什么问题
用计算机的思路去读以下两句话找区别
"我找到了一本去年在旧书市场错过、封面泛黄且纸页发脆的故事书",
"I found a storybook yesterday when I was tidying up the old bookshelf in the study room that has yellowed pages and brittle paper and was missed in the second-hand book market last year.
以及计算机如何理解:用毒毒毒蛇毒蛇会不会被毒毒死?
5.2 RNN的思路:让AI拥有"短期记忆"------循环连接
循环神经网络(RNN)的设计灵感源于一个朴素的想法:让网络记住之前看到过的内容。
与传统神经网络不同,RNN引入了"隐藏状态(Hidden State)"的概念。可以把隐藏状态想象成模型的"记忆卡片":
text
输入序列: ["我", "爱", "中国"]
时间步 t=0: 看到"我" → 更新记忆卡片 → 输出对"我"的理解
时间步 t=1: 看到"爱" + 带上一步的记忆卡片 → 更新记忆 → 输出对"我爱"的理解
时间步 t=2: 看到"中国" + 带上一步的记忆卡片 → 更新记忆 → 输出对"我爱中国"的理解RNN有个致命问题:记忆会随着时间逐渐淡化。就像人只能记住最近几句话,早期的信息很容易丢失。
5.3 Transformer思路:让序列中的每个元素都能直接与所有其他元素对话
自注意力如何工作:三张名片的故事
想象你在一个社交场合,想快速了解每个人:
-
制作三张名片(三个向量)(通常是embedding维度的1/头数,如512/8=64):
- Query(查询):代表"我想了解什么"
- Key(键):代表"我有什么特点"
- Value(值):代表"我的详细信息"
-
匹配过程
对于每个人A: 用A的Query与所有人的Key比较相似度(点积) 得到注意力分数:A与B的关联度、A与C的关联度... 用这些分数作为权重,加权求和所有人的Value 得到A的"综合印象" 公式:Attention(Q, K, V) = softmax(Q·K^T / √d_k) · V -
多头注意力:多角度观察
Transformer更进一步,使用多头注意力:就像多个人从不同角度观察同一场景。
# 伪代码:多头注意力 头1 = 注意力(从"语法角度"看的Q,K,V) # 关注句子结构 头2 = 注意力(从"语义角度"看的Q,K,V) # 关注词语含义 头3 = 注意力(从"情感角度"看的Q,K,V) # 关注情感倾向 最终表示 = 拼接(头1, 头2, 头3) × 权重矩阵 -
位置编码:告诉模型"顺序"信息
为理解序列的顺序问题,给每个位置的token(词)添加额外的位置信息
cpu并行优势:可以同时理解一整句话,速度也比rnn快几十倍
5.4 Transformer架构
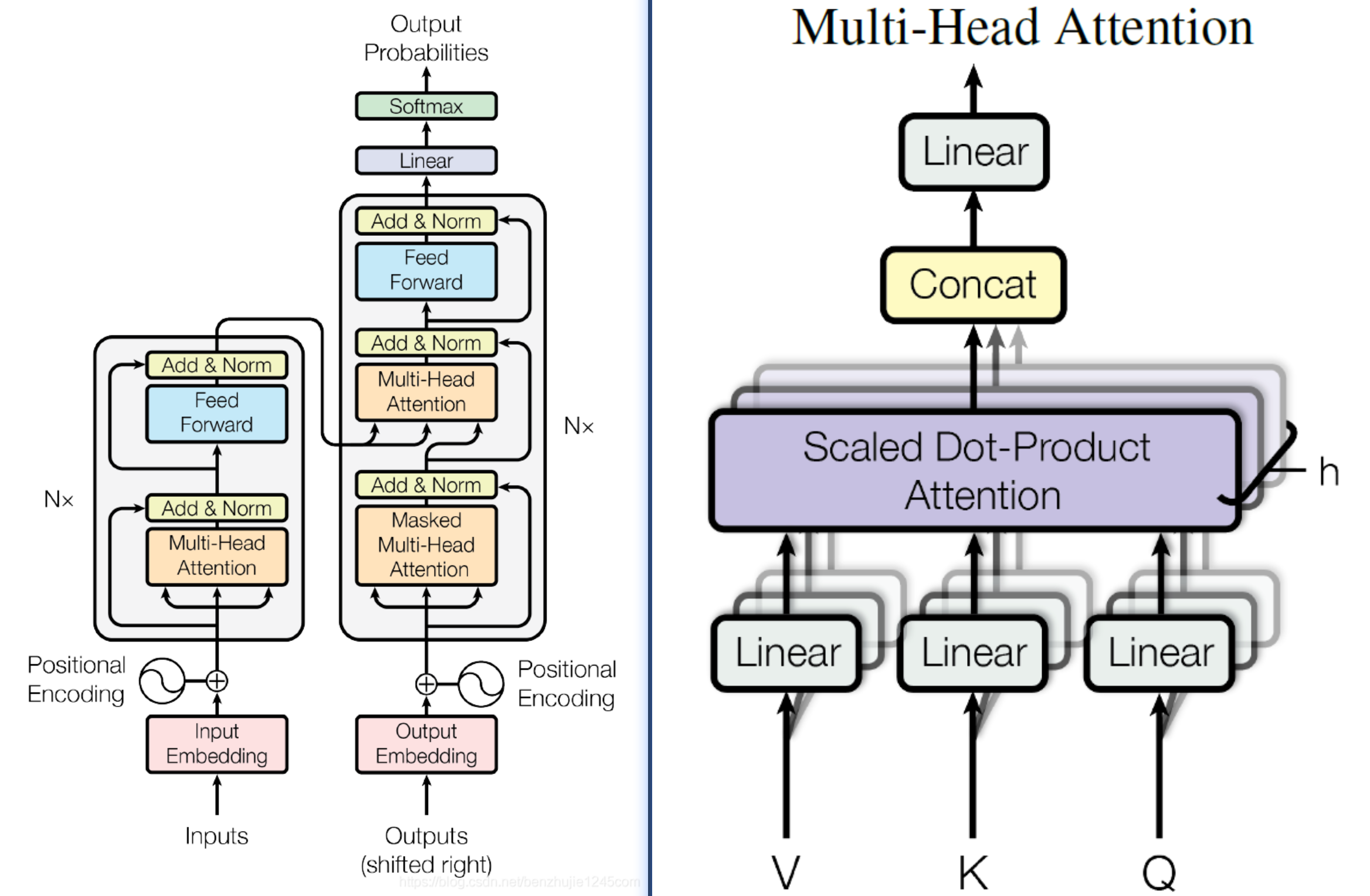
左侧 Transformer 整体架构部分
- Inputs:输入
- Input Embedding:输入嵌入
- Positional Encoding:位置编码
- Multi-Head Attention:多头注意力
- Add & Norm:残差连接与层归一化
- Feed Forward:前馈神经网络
- Outputs (shifted right):输出(右移)
- Output Embedding:输出嵌入
- Masked Multi-Head Attention:掩码多头注意力
- Linear:线性层
- Softmax:Softmax 函数
- Output Probabilities:输出概率
- N×:N 层堆叠(表示该模块重复 N 次)
右侧多头注意力细节部分
- Multi-Head Attention:多头注意力
- Concat:拼接
- Scaled Dot-Product Attention:缩放点积注意力
- h:注意力头数
- Q:查询向量(Query)
- K:键向量(Key)
- V:值向量(Value)
Transformer 区分编码器、解码器的根本原因:不同任务的核心需求不同 ------ 一类需要 "理解完整输入",另一类需要 "生成有序输出"。
因为 **"理解" 和 "生成" 是两种完全不同的任务逻辑 **:
- 理解任务需要 "全局视角":编码器无掩码,能看到所有输入,适合学习完整的语义关联;
- 生成任务需要 "因果视角":解码器加掩码,只能看到前文,适合学习 "前文→后文" 的生成规律;
- 翻译等跨序列任务需要 "两者结合":编码器理解源序列,解码器生成目标序列,缺一不可。
如果不区分二者,用一个统一的结构去处理所有任务,要么会导致理解任务效率低下(带掩码会限制全局视野),要么会导致生成任务 "作弊"(无掩码会看到未来内容,训练出的模型推理时无法正常生成)。
5.5 编码器|解码器
- 编码器的训练:只看 "完整输入",学 "全局理解"(情感分析)
适用任务:文本分类、命名实体识别、句子相似度计算(都是 "输入一段文本,输出一个标签 / 结果")。
-
训练输入
:完整的源序列(如 "这篇电影影评很棒")+ 对应的标签(如 "正面情感")。
编码器的多头自注意力层没有掩码,每个词可以看到序列中所有词 ------ 比如 "很棒" 能直接关联 "影评",模型能完整理解 "影评很棒" 的语义。
-
训练目标:让编码器把输入序列转换成一个包含全局语义的特征向量,这个向量能准确映射到标签。
-
为什么不用解码器:这类任务不需要生成新内容,只需要 "读懂" 输入即可,解码器的 "生成逻辑" 是多余的。
- 解码器的训练:看 "部分输入",学 "因果生成"(GPT)
适用任务:文本生成、机器翻译(都是 "输入一段内容,输出一段新的序列")。