本期内容为自己总结归档,基于JDK8,共分5章,本人遇到过的面试问题会⭐重点标记。
第四章:JVM 调优
(若有任何疑问,可在评论区告诉我,看到就回复)
第四章:JVM 调优
1. JVM调优方法论:从数据驱动到精准优化
JVM调优不是"玄学",而是建立在可观测性、可实验性、可验证性基础上的系统工程。正确的调优流程遵循"测量-假设-验证"循环。
1.1 系统化调优流程框架
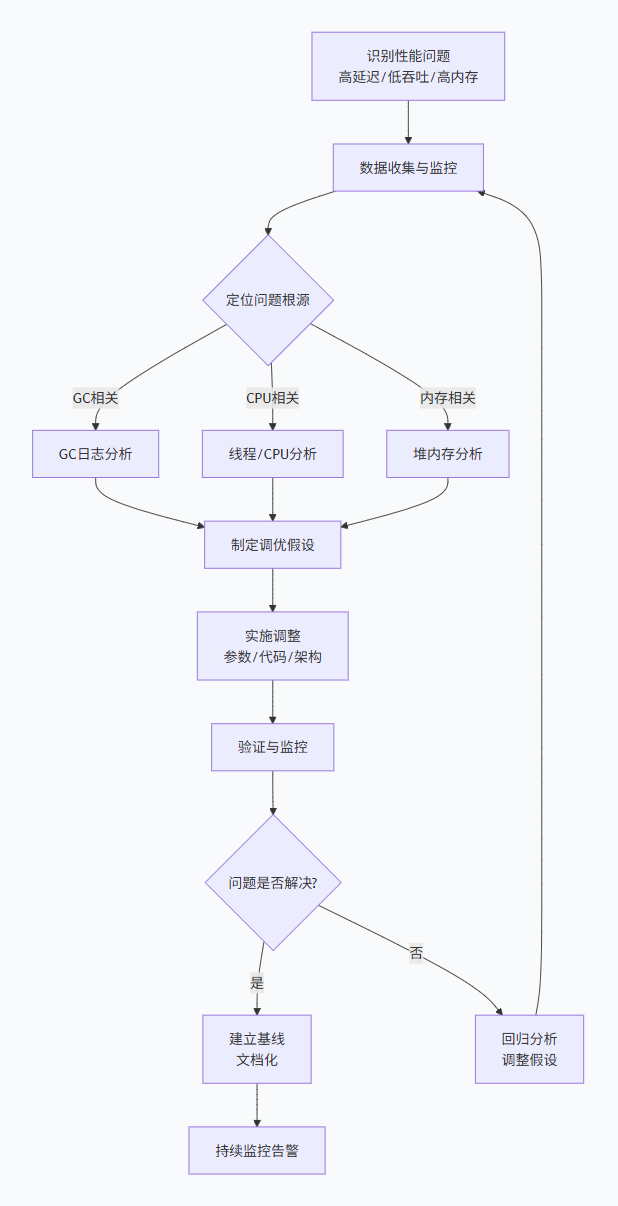
黄金法则:先测量,后调优
-
不测量就优化是万恶之源:没有指标数据支撑的调优如同盲人摸象
-
一次只改变一个变量:确保能准确评估每个调整的效果
-
区分症状与根源:频繁Full GC可能是症状,内存泄漏才是根源
1.2 关键性能指标体系
| 指标类别 | 具体指标 | 健康阈值 | 监控工具 |
|---|---|---|---|
| 堆内存 | 堆使用率、老年代使用率、元空间使用率 | <70% (建议安全阈值) | jstat、VisualVM |
| GC效率 | GC频率、平均暂停时间、吞吐量 | 暂停时间 < 100ms (多数应用) | GC日志、GCEasy |
| 线程状态 | 运行中线程数、阻塞线程数、死锁检测 | 无长时间阻塞/死锁 | jstack、Thread Dump |
| 类加载 | 已加载类数、类加载速率 | 稳定后无异常增长 | jstat -class |
2. 内存问题诊断:从OOM到内存泄漏
2.1 OOM的三种典型类型
| 类型 | 错误信息 | 根本原因 |
|---|---|---|
| 堆内存溢出 | java.lang.OutOfMemoryError: Java heap space |
对象创建速度 > 回收速度,堆不足 |
| 元空间溢出 | java.lang.OutOfMemoryError: Metaspace |
动态生成类过多(如CGLIB代理、Groovy脚本) |
| 直接内存溢出 | java.lang.OutOfMemoryError: Direct buffer memory |
NIO ByteBuffer.allocateDirect() 超限 |
💡 JDK8中永久代已移除 ,故不再出现
PermGen space错误。
2.2 诊断步骤:以堆内存OOM为例
步骤1:启用堆转储(Heap Dump)
# JVM启动参数
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/data/dumps/
-XX:OnOutOfMemoryError="kill -9 %p" #生产不建议使用
-Xms2g -Xmx2g # 固定堆大小避免动态调整开销
-XX:NewRatio=3 # 老年代:新生代=3:1 (新生代512MB)
-XX:SurvivorRatio=8 # Eden:Survivor=8:1 (Eden 365MB, 每个Survivor 73MB)
// 大对象直接进入老年代
-XX:PretenureSizeThreshold=1m // 大于1MB的对象直接在老年代分配步骤2:分析堆转储文件
使用 Eclipse MAT(Memory Analyzer Tool) 或 VisualVM 打开 .hprof 文件。
关键分析视图:
- Dominator Tree:找出占用内存最大的对象及其引用链
- Histogram:按类统计实例数和内存占用
- Leak Suspects Report:MAT自动检测疑似泄漏点
案例:缓存未设上限导致OOM
public class CacheService {
private static Map<String, Object> cache = new HashMap<>(); // 无限增长!
public void put(String key, Object value) {
cache.put(key, value);
}
}MAT分析结果:
java.util.HashMap$Node[]占用 1.2GB- 引用链:
CacheService.cache → HashMap → Node[]
修复方案:
-
改用
ConcurrentHashMap+ LRU淘汰策略(如Caffeine) -
设置最大容量:
cache = new LinkedHashMap<>(16, 0.75f, true) protected boolean removeEldestEntry(Map.Entry eldest){ return size() > MAX_SIZE; }
2.3 元空间(Metaspace)调优
调优建议:
-XX:MetaspaceSize=128m # 触发首次Metaspace GC的阈值
-XX:MaxMetaspaceSize=256m # 防止耗尽物理内存
# 监控类加载器泄漏
-XX:+TraceClassLoading
-XX:+TraceClassUnloading # 追踪类卸载,确认无泄漏📌 注意:Metaspace GC由类加载器卸载触发,若ClassLoader无法回收(如静态引用),即使设置上限也无效
3. 垃圾收集器选择与调优
3.1 收集器选择决策矩阵
| 收集器组合 | 适用场景 | 优点 | 缺点 | 关键配置 |
|---|---|---|---|---|
| Parallel Scavenge + Parallel Old (JDK8默认) | 后台计算型应用,追求高吞吐量 | 吞吐量高,配置简单 | 暂停时间不可控 | -XX:MaxGCPauseMillis -XX:GCTimeRatio |
| ParNew + CMS | Web应用,追求低延迟 | 并发收集,停顿短 | CPU敏感,碎片化 | -XX:CMSInitiatingOccupancyFraction -XX:+UseCMSInitiatingOccupancyOnly |
| G1 (JDK9+默认,JDK8可用) | 大内存(>4G),可预测停顿 | 预测性停顿,综合性能好 | 内存占用稍高 | -XX:MaxGCPauseMillis=200 -XX:G1HeapRegionSize=4m |
3.2 CMS深度调优实战
# CMS完整配置示例(针对8-16GB堆的Web应用)
-XX:+UseConcMarkSweepGC # 启用CMS
-XX:+UseParNewGC # 新生代使用ParNew
-XX:CMSInitiatingOccupancyFraction=70 # 老年代70%时触发CMS
-XX:+UseCMSInitiatingOccupancyOnly # 仅使用上面阈值,禁止自动调整
-XX:+CMSScavengeBeforeRemark # Remark前做Young GC,减少Remark暂停
-XX:+CMSClassUnloadingEnabled # 启用类卸载
-XX:+CMSParallelRemarkEnabled # 并行Remark
-XX:+CMSParallelInitialMarkEnabled # 并行初始标记
-XX:+CMSEdenChunksRecordAlways # 更精确的跨代引用记录
# 处理并发模式失败
-XX:+UseCMSCompactAtFullCollection # Full GC时压缩
-XX:CMSFullGCsBeforeCompaction=2 # 控制压缩频率3.3 G1调优要点
# G1基础配置(堆内存>4G)
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200 # 目标暂停时间
-XX:G1HeapRegionSize=4m # Region大小,默认根据堆计算
# 调优进阶
-XX:InitiatingHeapOccupancyPercent=45 # 堆占用45%时开始并发周期
-XX:G1ReservePercent=10 # 保留空间,避免to-space溢出
-XX:G1MixedGCCountTarget=8 # Mixed GC最大次数
-XX:G1HeapWastePercent=5 # 可容忍浪费空间百分比4. 常见热点问题与解决方案
4.1 内存泄漏诊断与修复
步骤1:确认泄漏存在
# 监控堆使用趋势,判断是否持续增长不回收
jstat -gcutil <pid> 1000 100 # 每秒采样,共100次
# 关注OU(老年代使用率)是否持续上升步骤2:堆转储分析
# 生成堆转储
jmap -dump:live,format=b,file=heap.hprof <pid>
# 或使用OOM时自动转储
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/path/to/dumps步骤3:使用MAT分析支配树
// 常见泄漏模式1:静态集合累积
public class MemoryLeak {
private static final List<Object> CACHE = new ArrayList<>();
public void addToCache(Object obj) {
CACHE.add(obj); // 对象永不被移除,即使业务不再需要
}
}
// 修复:使用弱引用或定期清理
private static final Map<Object, SoftReference<Object>> CACHE = new WeakHashMap<>();
// 常见泄漏模式2:未关闭资源
public void readFile() {
InputStream is = new FileInputStream("large.txt");
// 使用后未关闭,Native内存泄漏
// 修复:使用try-with-resources
try (InputStream is = new FileInputStream("large.txt")) {
// 自动关闭
}
}4.2 ⭐**(面试高频考点)**100%CPU占用过高诊断
排查流程:
# 1. 定位高CPU线程
top -Hp <pid> # 查看线程级别CPU
# 或
pidstat -t -p <pid> 1 10 # 更详细的线程统计
# 2. 将线程ID转为十六进制
printf "%x\n" <thread_id>
# 3. 获取线程堆栈
jstack <pid> > thread_dump.txt
# 在堆栈中搜索对应的nid(十六进制线程ID)
# 4. 分析热点代码
jcmd <pid> Thread.print # 替代jstack
# 结合profiling工具
jcmd <pid> JFR.start duration=60s filename=profile.jfr常见原因及解决:
-
无限制循环:检查自旋锁、忙等待
-
频繁GC:减少对象创建,优化数据结构
-
锁竞争激烈:减少锁粒度,使用并发集合
4.3 线程阻塞与死锁检测
查看线程状态:
jstack <pid> | grep "java.lang.Thread.State"典型状态:
RUNNABLE:正常执行BLOCKED:等待 synchronized 锁WAITING:Object.wait() / LockSupport.park()TIMED_WAITING:sleep() / wait(timeout)
死锁自动检测:
jstack -l <pid> # -l 参数显示锁持有信息若存在死锁,JVM会输出:
Found one Java-level deadlock:
=============================
"Thread-1": waiting to lock monitor 0x00007f...
which is held by "Thread-2"
"Thread-2": waiting to lock monitor 0x00007f...
which is held by "Thread-1"5. 监控与诊断工具链
5.1 命令行工具矩阵**(⭐面试高频考点)**
| 工具 | 主要用途 | 关键命令示例 |
|---|---|---|
| jps | 查看Java进程 | jps -lv |
| jstat | JVM统计监控 | jstat -gcutil <pid> 1s |
| jmap | 内存分析 | jmap -heap <pid> |
| jstack | 线程分析 | jstack -l <pid> |
| jcmd | 多功能诊断 | jcmd <pid> VM.flags |
| jinfo | 参数查看修改 | jinfo -flags <pid> |
5.2 GC日志深度分析配置
# 详细GC日志配置
-XX:+PrintGCDetails # 打印GC详情
-XX:+PrintGCDateStamps # 带时间戳
-XX:+PrintGCTimeStamps # 带JVM启动后时间戳
-Xloggc:/path/to/gc.log # 输出到文件
-XX:+UseGCLogFileRotation # 日志轮转
-XX:NumberOfGCLogFiles=5 # 保留5个文件
-XX:GCLogFileSize=10M # 每个文件10MB
# 额外的诊断信息
-XX:+PrintTenuringDistribution # 对象年龄分布
-XX:+PrintReferenceGC # 引用处理日志
-XX:+PrintPromotionFailure # 晋升失败详情
# 使用工具分析GC日志
// 1. GCViewer (可视化)
// 2. GCEasy (在线分析)
// 3. gclogparser (自建分析)6. 本章总结
| 调优维度 | 核心原则 | 实用工具 |
|---|---|---|
| 内存调优 | 分代优化、预防泄漏 | jmap、MAT、heap dump |
| GC调优 | 匹配应用模式、平衡暂停与吞吐 | GC日志、GCEasy、VisualVM |
| CPU调优 | 定位热点、减少竞争 | jstack + 线程ID定位热点代码 |
| 启动优化 | 并行化、预热 | JIT编译日志、类加载监控 |
特别提醒:
-
不要过度调优:默认参数在大多数情况下已经过良好优化
-
关注应用代码:优化算法和数据结构往往比JVM调优效果更显著
-
建立性能文化:性能是设计出来的,不是调优出来的