📖目录
- 前言
- [1. 从"老式收音机"到"智能聚焦镜头":架构演进的逻辑](#1. 从"老式收音机"到"智能聚焦镜头":架构演进的逻辑)
- [2. 传统架构:RNN的"记忆"与局限](#2. 传统架构:RNN的"记忆"与局限)
- [3. Transformer的革命:注意力机制的"聚焦"能力](#3. Transformer的革命:注意力机制的"聚焦"能力)
- [4. 现代架构演进:效率与性能的平衡](#4. 现代架构演进:效率与性能的平衡)
-
- [4.1 稠密型模型(Dense Models):全职员工的"稳定表现"](#4.1 稠密型模型(Dense Models):全职员工的"稳定表现")
- [4.2 混合专家模型(MoE):专家团队的"精准调度"](#4.2 混合专家模型(MoE):专家团队的"精准调度")
- [4.3 状态空间模型(SSM):智能记忆系统的"长线思维"](#4.3 状态空间模型(SSM):智能记忆系统的"长线思维")
- [4.4 保留网络(RetNet):智能快递员的"高效递归"](#4.4 保留网络(RetNet):智能快递员的"高效递归")
- [4.5. RNN变体:RWKV的"双面能力"](#4.5. RNN变体:RWKV的"双面能力")
- [4.6 多模态架构:让AI"眼观六路,耳听八方"](#4.6 多模态架构:让AI"眼观六路,耳听八方")
- [5. 架构对比与选择指南](#5. 架构对比与选择指南)
- [6. 行业应用全景](#6. 行业应用全景)
- [7. 未来展望:架构融合的"黄金时代"](#7. 未来展望:架构融合的"黄金时代")
- [8. 经典文献推荐](#8. 经典文献推荐)
- [9. 结语:架构演进,永不止步](#9. 结语:架构演进,永不止步)
前言
你有没有想过,为什么现在AI能像人类一样理解复杂的故事?为什么它能一边听你说话,一边看着图片回答问题?这背后,是大模型架构的不断进化------从"机械记忆"到"智能理解"的飞跃。
1. 从"老式收音机"到"智能聚焦镜头":架构演进的逻辑
想象一下,你正在教一个刚学说话的孩子理解故事。如果只让他逐字逐句背诵(像早期的RNN),他可能记住"小猫",但不知道"小猫"为什么在追蝴蝶。如果给他一个"聚焦镜头"(像Transformer的注意力机制),他就能理解整个故事的逻辑和情感。
大模型架构的演进,本质上就是AI从"机械记忆"走向"理解"的历程。每一种架构的出现,都是为了更好地解决特定问题,就像不同类型的工具能解决不同的问题一样。
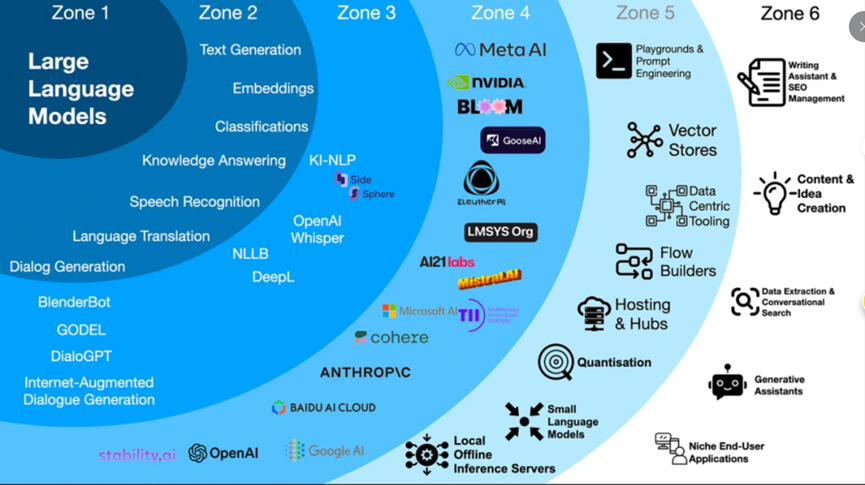
图1:大型语言模型架构的发展图谱
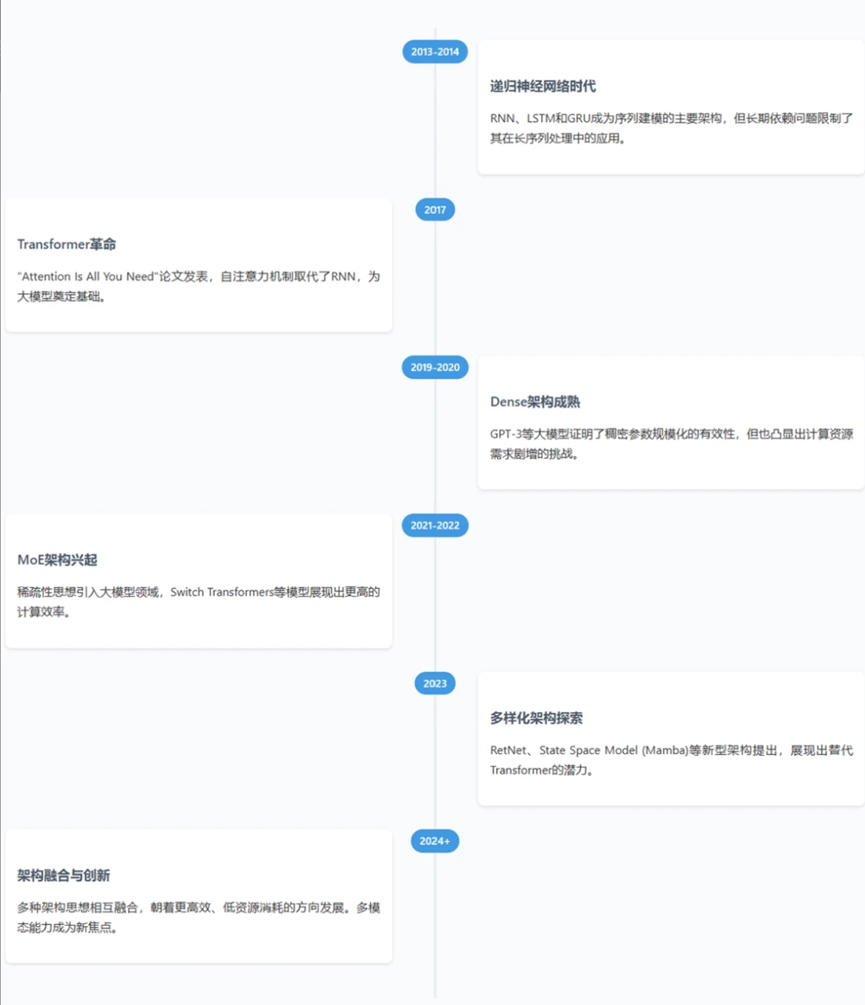
图2:从传统RNN到现代各类架构
2. 传统架构:RNN的"记忆"与局限
在Transformer出现之前,RNN(循环神经网络)是处理序列数据的"老大哥"。RNN就像一个有记忆的"快递员",它在处理序列数据时,会记住之前的信息,帮助理解当前内容。
RNN的工作原理 :
想象一下,你正在阅读一本小说,RNN就像一个快递员,每读完一页,它就会记住上一页的内容,这样就能理解故事的连贯性。但是,RNN有个大问题:它只能记住很短的"记忆",就像快递员只能记住最近的几个包裹,而记不住整本书的内容。
RNN的局限:
- 长期依赖问题:无法记住很长的序列(比如整本书的内容)
- 训练困难:像"老式收音机"一样,容易"失真"
- 无法并行计算:像"单线程快递",速度慢
RNN的变体,如LSTM和GRU,试图解决这些问题,就像给快递员配备了更好的记忆系统和导航工具。但它们依然无法解决长序列处理的效率问题。
3. Transformer的革命:注意力机制的"聚焦"能力

图3:典型的Transformer架构
2017年,Google的Vaswani等人提出了Transformer架构,这就像给AI装上了"聚焦镜头",让它能同时关注到整个故事的各个部分,而不仅仅是前几页。
Transformer的核心:注意力机制
想象一下,你正在看一场足球比赛,你不需要看完整场比赛,而是能快速抓住关键的进球瞬间。注意力机制就是让模型"聚焦"到最重要的部分,忽略不重要的细节。
Transformer的架构:
- 编码器:负责理解输入(如文本)
- 解码器:负责生成输出(如回答问题)
- 自注意力机制:让模型"关注"输入中的不同部分
Transformer的出现,就像给AI装上了"超级聚焦镜头",让它能同时理解整个文本的上下文,而不仅仅是前几个词。
4. 现代架构演进:效率与性能的平衡
随着大模型规模不断增大,传统Transformer架构遇到了计算效率的瓶颈。于是,研究者们开始探索更高效的架构。下面介绍几种主流架构:
4.1 稠密型模型(Dense Models):全职员工的"稳定表现"
Transformer架构,是下面的稠密模型的基础。在稠密模型中,计算复杂度与参数数量呈线性关系,性能提升通常依赖于增加模型参数规模。
大白话解释:就像一个全职员工,每次工作都要用到所有技能。所有参数在每次前向传播时都会被激活和使用。
优点:
- 结构简单,像"标准工具箱",容易理解和使用
- 训练稳定,像"老司机",开车稳当
- 通用性强,像"全能选手",啥活都能干
缺点:
- 计算量大,像"大卡车",需要大量燃料
- 处理长序列慢,像"慢吞吞的火车"
- 对硬件要求高,像"豪华跑车",需要好路
代表应用:GPT-4、PaLM、Claude、LLaMA系列
真实案例:Meta的Llama 3是稠密型模型的代表,它被广泛用于各种AI应用,从内容创作到代码生成,因为它稳定、可靠,适合各种通用任务。
4.2 混合专家模型(MoE):专家团队的"精准调度"
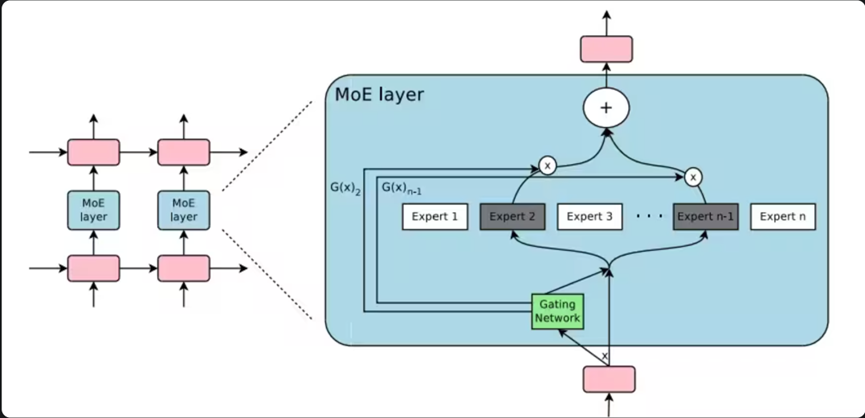
图4:混合专家模型(MoE)的基本架构,展示了路由器如何将输入分配到不同专家在MoE架构中:
- 路由器负责决定将输入的令牌(tokens)分发给哪些专家网络处理。
- 通常采用Top-k门控策略,即每个输入只会被路由到k个专家(常见的是Top-1或Top-2)。
- 这种设计使得MoE模型可以拥有比稠密模型多得多的参数,而计算效率却显著提高。

图5:MoE层集成到Transformer架构中的示意图
大白话解释:就像一个"专家团队",每次只让最合适的专家处理任务,而不是让所有专家都参与。模型中有很多"专家",但每次只激活部分专家。
优点:
- 计算效率高,像"精准调度",用最少的人力做最多的事
- 可扩展性强,可以无限增加专家数量
- 性能更好,像"专家团队",解决问题更专业
缺点:
- 内存需求大,需要把所有专家都存起来
- 训练不稳定,像"专家团队",有时会吵架
- 实现复杂,需要特殊训练策略
代表应用:Mixtral 8x7B、Switch Transformers
真实案例:Mixtral 8x7B是开源的MoE模型,拥有约470亿参数,但推理复杂度与12B参数的稠密模型类似。它被广泛用于需要高性能的推理场景,如企业级AI客服系统。
4.3 状态空间模型(SSM):智能记忆系统的"长线思维"

图6:Mamba模型架构图,展示了状态空间模型的选择性状态处理机制:
- Mamba模型引入了"选择性状态空间模型"(Selective State Space Model,S6)
- 模型能够根据输入内容动态地决定哪些信息需要保留,哪些信息可以忽略。
- 这种选择性机制使得SSM在处理长序列时既能捕捉到长期依赖关系,又能保持计算效率
大白话解释:就像一个"智能记忆系统",它能记住重要信息,同时忽略不重要的信息。特别适合处理长序列,比如整本书或基因序列。
优点:
- 处理长序列效率高,像"智能记忆",能记住很长的内容
- 计算复杂度低,像"轻量级工具",用起来不费劲
- 内存占用小,像"小背包",轻便好用
缺点:
- 技术较新,像"新发明",还在完善中
- 设计和调优难度大,需要专业知识
代表应用:Mamba、Mamba-2、MoE-Mamba
真实案例:Mamba被用于处理超长文本,如整本书的分析。在基因组学研究中,Mamba能高效处理数百万个碱基对的序列,帮助科学家快速分析DNA。
4.4 保留网络(RetNet):智能快递员的"高效递归"
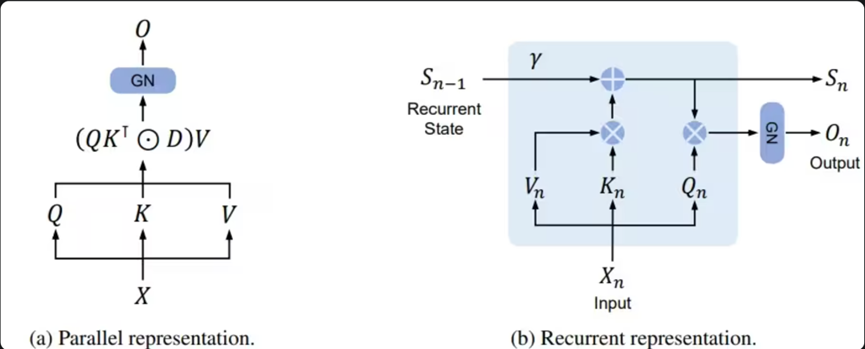
图7:RetNet架构图,展示了多尺度保留(MSR)机制替代注意力机制:
- RetNet架构中的核心组件是多尺度保留(Multi-Scale Retention, MSR)模块
- 该模块使用指数衰减来加权过去的状态,从而实现高效的信息保留
- 与Transformer的自注意力不同,RetNet的保留机制避免了二次计算复杂度,并通过递归表示支持O(1)复杂度的推理。
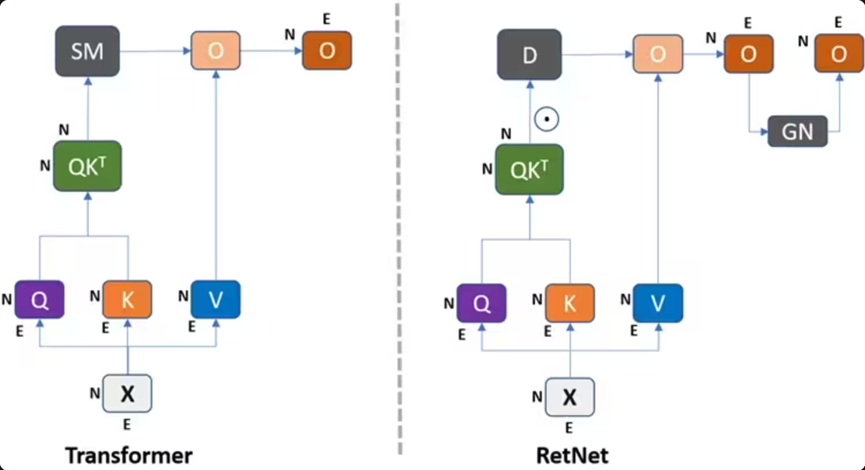
图8:RetNet与Transformer在推理效率和内存使用方面的比较
大白话解释:就像一个"智能快递员",它在处理长序列时,能记住关键信息,同时快速处理新信息。它结合了RNN的"记忆"和Transformer的"效率"。
优点:
- 训练时并行计算,像"团队协作",速度快
- 推理时递归计算,内存占用低,像"轻装上阵"
- 在大规模模型中表现优异,像"超级快递员"
缺点:
- 相对较新,生态系统和工具支持有限
- 在小规模模型上可能不如Transformer
代表应用:RetNet(研究中)
真实案例:研究表明,在6.7B参数模型上,RetNet的推理速度比同等大小的Transformer快8.4倍,内存使用率提高70%。这使得RetNet特别适合高吞吐量的在线服务,如实时客服系统。
4.5. RNN变体:RWKV的"双面能力"
大白话解释:就像一个"智能快递员",它既能像Transformer一样并行训练,又能像RNN一样递归推理。RWKV通过引入"受体加权键值"机制,实现了高效的时间混合。
优点:
- 计算复杂度低,适合长序列
- 内存占用小,适合资源受限环境
- 推理速度快,像"闪电快递"
缺点:
- 相对较新,生态系统和工具支持有限
代表应用:RWKV
真实案例:RWKV被用于移动设备上的AI应用,如手机上的实时翻译和语音助手。它能在有限的计算资源下提供高质量的AI服务。
4.6 多模态架构:让AI"眼观六路,耳听八方"
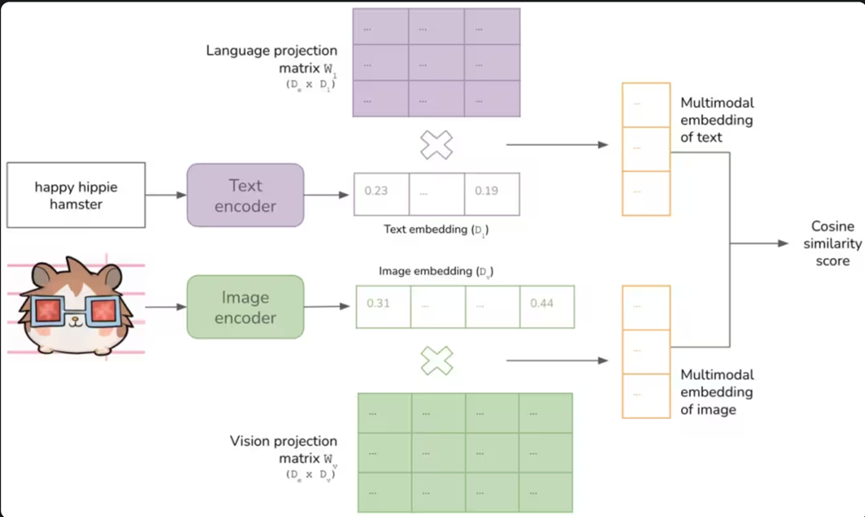
图9:典型的多模态模型架构示例(CLIP模型)
- 类型A:基于标准交叉注意力的深度融合(SCDF)
- 类型B:基于定制层的深度融合(CLDF)
- 类型C:非标记化早期融合(NTEF)

图10:多模态大模型的主要架构类型分类
大白话解释:就像人类不仅能看,还能听、说、闻一样,多模态架构让AI能同时处理文本、图像、音频等多种数据。
类型A:基于标准交叉注意力的深度融合(SCDF)
- 像"多感官融合",不同感官信息通过交叉注意力层深度融合
- 代表:Flamingo、OpenFlamingo
类型B:基于定制层的深度融合(CLDF)
- 像"专业融合",使用特定设计的定制层进行融合
- 代表:LLaMA-Adapter、CogVLM
类型C:非标记化早期融合(NTEF)
- 像"直接接入",不同模态信息直接送入模型输入端
- 代表:BLIP-2、LLaVA
类型D:标记化早期融合(TEF)
- 像"统一编码",多模态输入先分词,再送入模型
- 代表:LaVIT、CM3Leon
真实案例:LLaVA是多模态架构的代表,它能根据图片内容回答问题,如"这张图片里有几只猫?"。它被广泛用于AI助手和内容创作平台。
5. 架构对比与选择指南
| 架构类型 | 适合场景 | 优势 | 劣势 | 代表应用 |
|---|---|---|---|---|
| 稠密型模型 | 通用AI服务、需要稳定性的场景 | 结构简单,训练稳定,通用性强 | 计算资源需求高,处理长序列效率低 | GPT-4、PaLM、LLaMA |
| 混合专家模型 | 需要大规模参数但训练资源有限 | 计算效率高,可扩展性强,性能更好 | 内存需求大,训练不稳定 | Mixtral 8x7B、Switch Transformers |
| 状态空间模型 | 长文本处理、实时/低延迟场景 | 处理长序列效率高,内存占用小 | 技术较新,设计难度大 | Mamba、Mamba-2 |
| 保留网络 | 大规模语言模型、高吞吐量服务 | 训练并行,推理递归,内存占用低 | 生态系统支持有限 | RetNet(研究中) |
| RNN变体 | 资源受限的推理环境、超长序列处理 | 计算复杂度低,内存占用小 | 训练不易并行化 | RWKV |
| 多模态架构 | 多模态任务(文本+图像+音频) | 能同时处理多种数据 | 架构复杂,需要多模态训练 | CLIP、LLaVA、Gemini |
6. 行业应用全景
-
稠密型模型:GPT-4被用于各种AI服务,包括内容创作、代码生成、企业客服等。它的稳定性和通用性使其成为大多数AI应用的基础。
-
混合专家模型:Mixtral 8x7B被用于需要高性能的推理场景,如企业级AI客服系统。它能在有限的计算资源下提供高质量的响应。
-
状态空间模型:Mamba被用于处理超长文本,如整本书的分析。在基因组学研究中,Mamba能高效处理数百万个碱基对的序列。
-
保留网络:RetNet的研究显示,它在6.7B参数模型上推理速度比Transformer快8.4倍,内存使用率提高70%。这使得它特别适合高吞吐量的在线服务。
-
RNN变体:RWKV被用于移动设备上的AI应用,如手机上的实时翻译和语音助手。它能在有限的计算资源下提供高质量的AI服务。
-
多模态架构:LLaVA被广泛用于AI助手和内容创作平台,能根据图片内容回答问题。Gemini Ultra能处理多种模态输入,提供更全面的AI体验。
7. 未来展望:架构融合的"黄金时代"
-
计算效率优先:随着模型规模扩大,计算效率将成为首要考量。MoE、SSM、RetNet等高效架构将得到更广泛应用。
-
硬件协同设计:架构设计将更加关注与特定硬件平台的协同优化,如专为GPU/TPU/ASIC设计的算法。
-
动态与自适应:未来架构可能具备更强的动态性和自适应性,能根据输入内容和资源约束自动调整计算方式。
-
长序列处理能力:处理超长文本的能力将成为架构设计的关键考量,SSM和RetNet等架构在这方面具有先天优势。
-
多模态无缝集成:架构设计将更加关注多模态信息的无缝处理,打破模态边界。
8. 经典文献推荐
-
《Attention Is All You Need》 (Vaswani et al., 2017) - Transformer的开山之作,奠定了现代大模型的基础。这是所有大模型架构的起点,也是理解后续架构演进的关键。
-
《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》 (Gu et al., 2023) - SSM架构的代表作,提出了选择性状态空间模型,为长序列处理提供了新思路。
-
《Retentive Network: A Successor to Transformer for Large Language Models》 (Sun et al., 2023) - RetNet架构的代表作,提出了保留机制,解决了Transformer在长序列处理中的效率问题。
-
《Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity》 (Fedus et al., 2022) - MoE架构的代表作,证明了稀疏计算在大规模模型中的可行性。
9. 结语:架构演进,永不止步
大模型架构的演进,就像一场永不停歇的"工具革命"。从RNN的"简单记忆",到Transformer的"聚焦能力",再到MoE的"专家团队"、SSM的"智能记忆",每一种架构都是为了更好地解决特定问题。
未来,随着计算效率的提升和架构的融合,AI将变得更加智能、高效和普及。正如我们从"算盘"走向"计算机",从"纸质书"走向"电子书"一样,大模型架构的演进也将推动AI进入一个全新的时代。
最后思考:在AI架构的演进中,没有"最好"的架构,只有"最适合"的架构。就像选择工具一样,我们需要根据任务需求、计算资源和场景特点,选择最适合的架构。这正是大模型架构演进的智慧所在。
参考文献:
- Vaswani, A., et al. (2017). "Attention Is All You Need". NeurIPS 2017.
- Fedus, W., et al. (2022). "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity". Journal of Machine Learning Research.
- Gu, A., et al. (2023). "Mamba: Linear-Time Sequence Modeling with Selective State Spaces". arXiv:2312.00752.
- Sun, Z., et al. (2023). "Retentive Network: A Successor to Transformer for Large Language Models". arXiv:2307.08621.
- Peng, B., et al. (2023). "RWKV: Reinventing RNNs for the Transformer Era". arXiv:2305.13048.