前言
(1)开放域问答中的检索通常使用TF-IDF 或BM25来实现,它通过倒排索引有效地匹配关键字,可以看作是用高维稀疏向量(带加权)表示问题和上下文。
(2)相反,通过设计,密集的潜在语义编码与稀疏表示是互补的。例如,由完全不同的标记组成的同义词或释义仍可能映射到彼此接近的向量。不单单检索相同的"形状",还能匹配相近的"含义"。
一、开放域回答
开放域问答(Open-Dimain Question Answering, ODQA)是一项使用大量文档回答事实问题的任务。其依赖于高效的段落检索来选择候选上下文:
(1)上下文检索器首先选择一小部分段落,其中一些段落包含问题的答案;
(2)机器阅读器可以彻底检查检索到的上下文并确定正确答案。
主要流程如下:
(1)假设文档集合包含 个文档
。首先将每个文档拆分为长度相等的文本段落,作为基本检索单位;
(2)经过拆分, 个文档总共得到
个段落,组成语料库
。其中每个段落
可以被视为一系列token
;
(3)给定一个问题 ,任务是找到一个来自任意
中的跨度
,从而可以回答这个问题。
因此,任何开放域QA系统都需要包含一个高效的检索器组件,在应用阅读器提取答案之前,可以选择一小部分相关文本。
从形式上讲,检索器 是一个函数,它将问题
和语料库
作为输入,并返回一个更小的文本过滤器集
,其中
(即文本过滤器集
中的段落数量远远小于语料库中的总段落数)。对于固定的
,可以根据
检索准确率单独评估检索器。
二、Dense Passage Retriever (DPR)
给定 个文本段落的集合,DPR的目标是在低维连续空间中索引所有段落,以便在运行时为高效检索与输入问题相关的前
个段落。
需要注意的是, 可能非常大(例如,本文中有2100万),而
通常很小,如20-100。
2.1 DPR的模型结构
(1)文本段落编码器:编码器 ,本文设计为 BERT,它将文本段落映射到
向量(CLS token 处的表示作为输出),并为将用于检索的所有M个段落构建索引;
(2)输入问题(查询)编码器:编码器 ,本文设计为另外一个不同的BERT,它将输入问题映射到
维向量(CLS token 处的表示作为输出);
(3)使用向量的点积来定义问题和文章之间的相似性,检索k个向量最接近问题向量的段落:
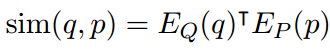
2.2 训练
设 是由
个实例组成的训练数据。每个实例包含一个问题
和一个相关(正)段落
,以及n个不相关(负)段落
。
将损失函数优化为正通道的负对数似然:
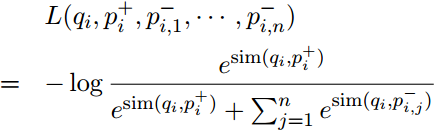
2.3 推理
2.3.1 FAISS介绍
在 DPR中,FAISS (Facebook AI Similarity Search)是一个用于高效相似度搜索 和向量聚类 的开源库。它的核心作用是加速大规模向量集合中的最近邻搜索。
(1)为什么需要FAISS?
虽然我们确实可以先得到问题向量 和所有段落向量
,然后逐一计算点积或余弦相似度,但这样的做法在实际应用中是不现实的,原因如下:
-
在本工作中,段落数量为 2100 万,计算量将是 O(2100万);
-
无法满足实时检索需求。
(2)FAISS 的作用是什么?
FAISS 通过构建索引结构 ,将高维向量组织成便于快速搜索的数据结构,实现亚线性时间的最近邻搜索。具体来说:
索引构建(离线):
-
将所有段落向量通过 FAISS 构建索引(如 HNSW、IVF 等)。
-
这个过程可以在训练完成后一次性完成,索引保存在内存或磁盘中。
快速检索(在线):
-
通过问题编码器得到
;
-
使用 FAISS 在索引中快速找到与
2.3.2 推理过程
在推理过程中:
(1)给定一个问题 ,使用问题(查询)编码器
对其进行编码,得到问题(查询)的嵌入向量
;
(2)使用段落编码器对所有段落进行编码,得到所有段落的嵌入向量;
(1)使用 FAISS ,在所有段落嵌入向量中快速找到与问题嵌入向量 最相似的 k 个向量,即检索
个段落。
三、总结
本工作的主要贡献:
(1)通过适当的训练设置,简单地微调现有问题-段落对上的问题编码器和段落编码器,就会明显优于BM25;
(2)实证结果还表明,可能不需要额外的预训练,就能比较好的完成开放域QA任务。