在昇腾8卡上极限部署 Qwen3-235B MoE

🌈你好呀!我是 是Yu欸
🚀 感谢你的陪伴与支持~ 欢迎添加文末好友
🌌 在所有感兴趣的领域扩展知识,不定期掉落福利资讯(*^▽^*)
写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
**摘要:**Qwen3-235B-A22B 是 2025 年开源界的"巨无霸"MoE 模型,其 BF16 全量权重高达 470GB。
对于单节点 8 张 Atlas 800 A2 (910B 64GB) 显卡来说,总显存仅 512GB。扣除系统开销,剩余空间不足 40GB。
如何在如此极限的显存条件下,不仅让模型跑起来,还能实现低延迟推理?本文将记录通过 vLLM 配合 HCCL AIV 加速、算子融合 及 NVMe 存储优化,达成高性能推理的全过程。
(本文专注于实践问题教程,以及优化性能效果的初步验证。企业级环境还是推荐8卡以上,或者多节点部署。)
一、NPU 驱动与固件安装
1.1 查看自己服务器版本信息
echo '==/etc/os-release==' && cat /etc/os-release 2>/dev/null || true && echo '\n==lsb_release -a==' && lsb_release -a 2>/dev/null || true && echo '\n==/etc/issue==' && cat /etc/issue 2>/dev/null || true && echo '\n==uname -a==' && uname -a && echo '\n==uname -r==' && uname -r && echo '\n==arch==' && arch && echo '\n==dpkg arch==' && dpkg --print-architecture 2>/dev/null || true && echo '\n==kernel packages (dpkg) sample==' && (dpkg -l | grep linux-image || true)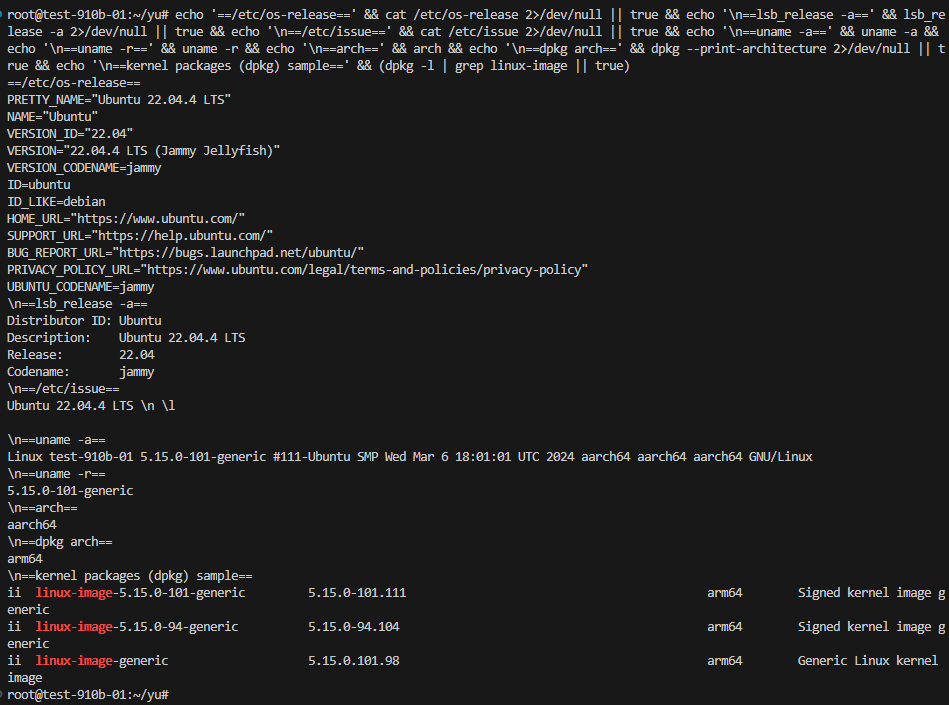
- DMI / 主机名:Huawei Atlas 900 RCK A2 Compute Node;Hostname: test-910b-01
- 发行版:Ubuntu 22.04.4 LTS (Jammy)
- 架构:aarch64 / arm64
- 内核:5.15.0-101-generic
- 已安装内核包示例:
linux-image-5.15.0-101-generic等
1.2 获取安装包
官方渠道:访问昇腾社区 → 然后根据自己的服务器系统 CPU 架构、昇腾芯片型号官网下载:
https://support.huawei.com/enterprise/zh/ascend-computing/ascend-hdk-pid-252764743/software
需要下载的驱动固件如下:
Ascend-hdk-910b-npu-driver_25.3.rc1_linux-aarch64.run
Ascend-hdk-910b-npu-firmware_7.8.0.2.212.run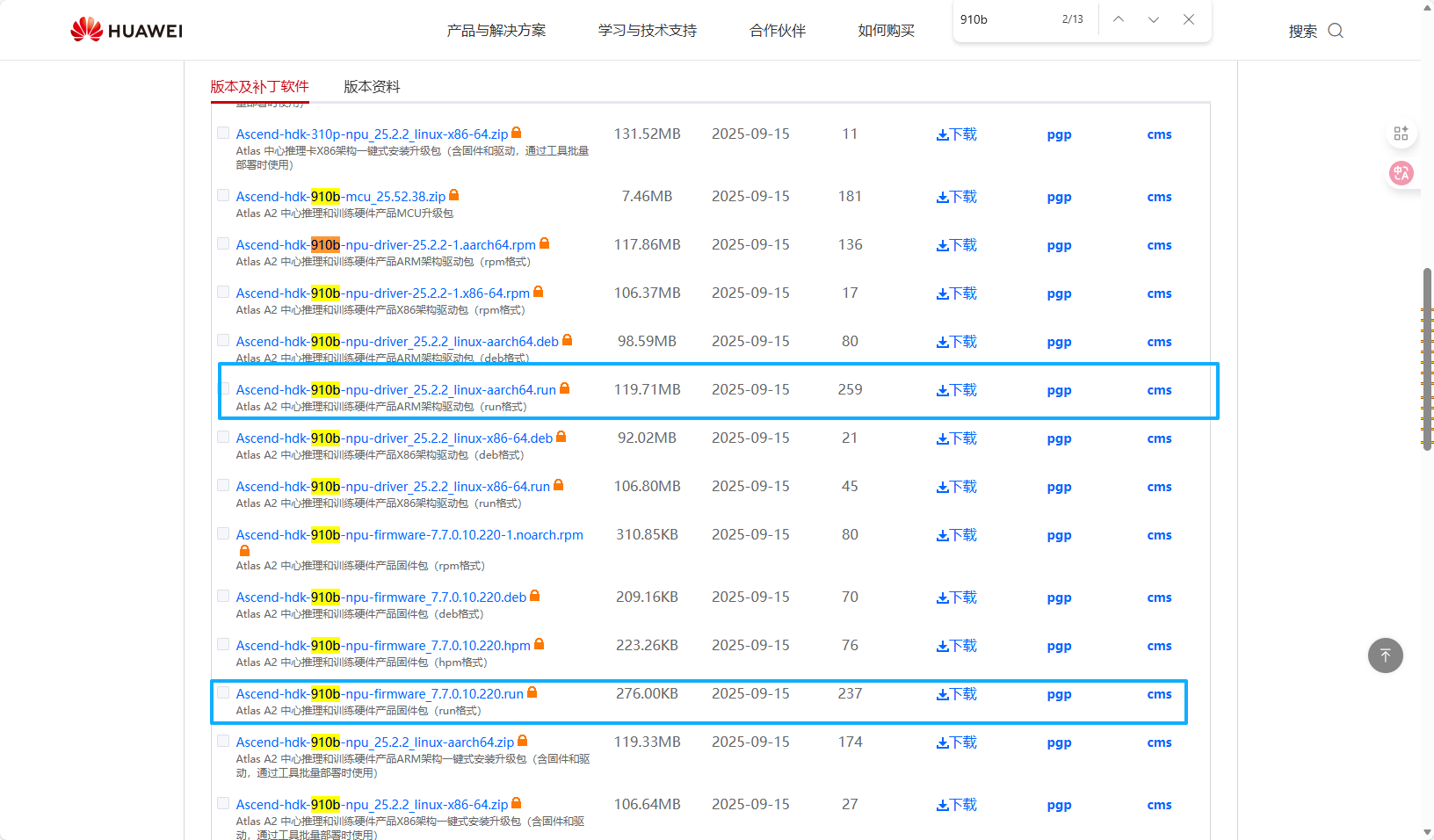
1.3 安装前准备
# 授予执行权限
chmod +x Ascend-hdk-910b-npu-driver_25.3.rc1_linux-aarch64.run
chmod +x Ascend-hdk-910b-npu-firmware_7.8.0.2.212.run
# 确认权限(应以root用户执行)
[[ $(id -u) -eq 0 ]] || echo "请切换到root用户执行安装"
1.4 安装驱动
需要注册登录,否则报错:
ERR_NO:0x0091;ERR_DES:HwHiAiUser not exists! Please add HwHi AiUser
准备软件包-软件安装-CANN社区版8.0.0.alpha001开发文档-昇腾社区
添加用户:
切换到root用户下,执行如下命令创建HwHiAiUser用户。
groupadd HwHiAiUser //创建HwHiAiUser用户属组
useradd -g HwHiAiUser -d /home/HwHiAiUser -m HwHiAiUser //创建HwHiAiUser用户,其属组为HwHiAiUse
passwd HwHiAiUser
设置:123456
# 完整安装(包含工具链)
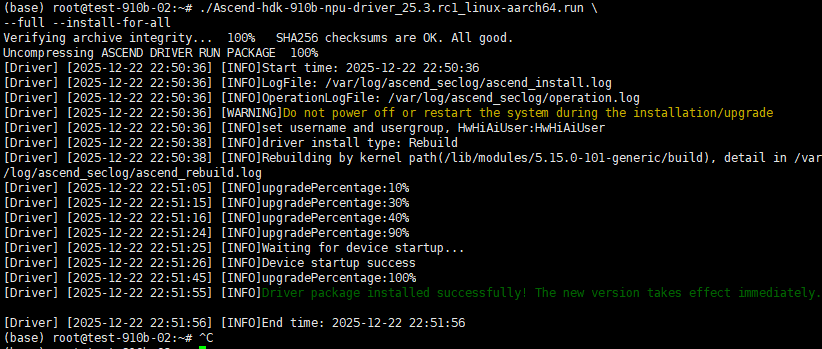
./Ascend-hdk-910b-npu-driver_25.3.rc1_linux-aarch64.run \
--full --install-for-all成功标志:终端显示 INFODevice startup success
1.5 安装固件
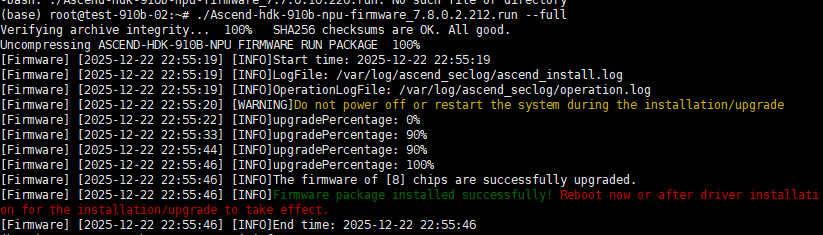
./Ascend-hdk-910b-npu-firmware_7.8.0.2.212.run --full成功标志:显示 Firmware package installed successfully! 并提示重启生效
1.6 安装验证
# 重启系统使驱动生效
reboot
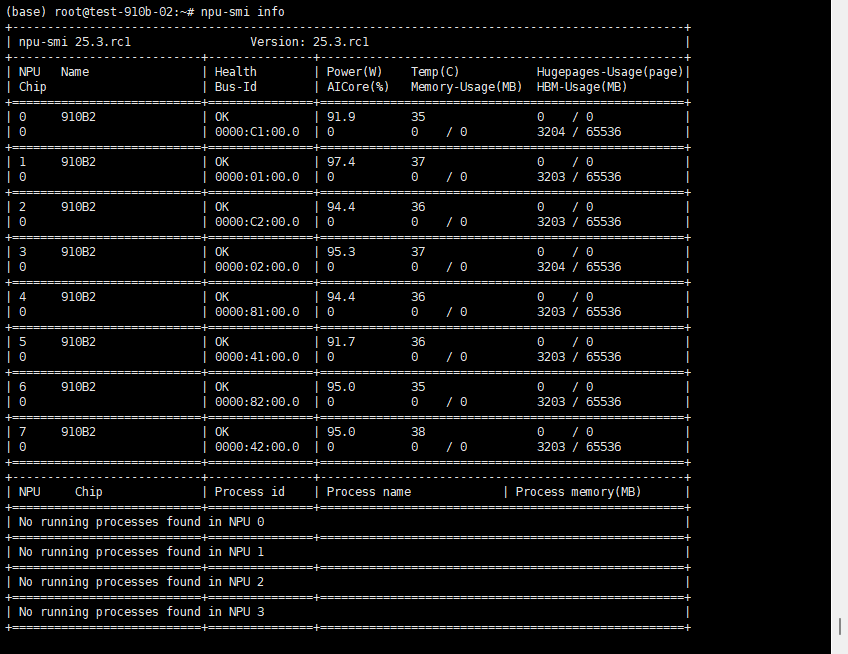
# 检查设备状态
npu-smi info预期输出:应显示所有NPU设备的详细信息,包括:
- 固件版本号
- 内存与功耗状态
🏗️ 二、 基础设施建设:打破 I/O 瓶颈
在处理 TB 级模型时,普通的系统盘(SATA SSD)加载速度慢且空间不足,必须利用服务器的高性能存储资源。
2.1 存储扩容:3.5T NVMe 裸盘挂载
💡 为什么需要 NVMe?
大模型推理的第一步是加载权重。对于 470GB 的文件,普通硬盘读取可能需要 20-30 分钟,而高性能 NVMe 可以将此缩短至几分钟。此外,如果不挂载数据盘,系统盘很容易被模型权重撑爆导致死机。
第一步:设备发现与规划
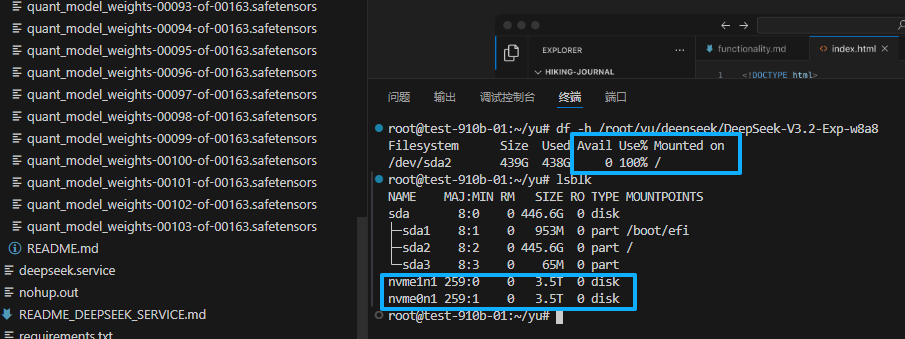
首先检查系统磁盘状态。我们发现系统盘 sda2 仅剩 396G,而两块 3.5T 的 NVMe 盘处于闲置状态。
Bash
root@test-910b-03:~# lsblk -o NAME,SIZE,FSTYPE,MOUNTPOINT,TYPE
NAME SIZE FSTYPE MOUNTPOINT TYPE
sda 446.6G disk
├─sda2 445.6G ext4 / part
...
nvme0n1 3.5T ext4 disk <-- 目标盘1
nvme1n1 3.5T ext4 disk <-- 目标盘2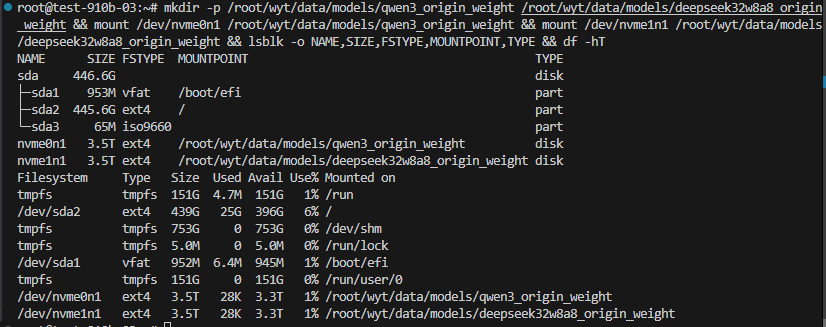
root@test-910b-03:~# lsblk -o NAME,SIZE,FSTYPE,MOUNTPOINT,TYPE
NAME SIZE FSTYPE MOUNTPOINT TYPE
sda 446.6G disk
├─sda1 953M vfat /boot/efi part
├─sda2 445.6G ext4 / part
└─sda3 65M iso9660 part
nvme0n1 3.5T ext4 disk
nvme1n1 3.5T ext4 disk
root@test-910b-03:~# df -hT
Filesystem Type Size Used Avail Use% Mounted on
tmpfs tmpfs 151G 4.7M 151G 1% /run
/dev/sda2 ext4 439G 25G 396G 6% /
tmpfs tmpfs 753G 0 753G 0% /dev/shm
tmpfs tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/sda1 vfat 952M 6.4M 945M 1% /boot/efi
tmpfs tmpfs 151G 0 151G 0% /run/user/0
root@test-910b-03:~# cat /proc/partitions
major minor #blocks name
259 0 3750738264 nvme0n1
259 1 3750738264 nvme1n1
8 0 468320256 sda
8 1 975872 sda1
8 2 467276800 sda2
8 3 66543 sda3规划策略:
nvme0n1-> 挂载至/root/wyt/data/models/qwen3_origin_weight(用于存放 Qwen3-235B)nvme1n1-> 挂载至/root/wyt/data/models/deepseek32w8a8_origin_weight(预留给 DeepSeek模型)
第二步:创建挂载点与执行挂载
由于磁盘已有文件系统(ext4),无需格式化,直接挂载即可。
Bash
# 1. 创建专用目录
mkdir -p /root/wyt/data/models/qwen3_origin_weight
mkdir -p /root/wyt/data/models/deepseek32w8a8_origin_weight
# 2. 执行挂载命令
mount /dev/nvme0n1 /root/wyt/data/models/qwen3_origin_weight
mount /dev/nvme1n1 /root/wyt/data/models/deepseek32w8a8_origin_weight第三步:验证挂载与读写测试 (关键)
挂载看似简单,但必须确认路径正确 且具备读写权限,否则后续下载权重或 Docker 映射时会报错。
状态检查:
Bash
root@test-910b-03:~# df -hT | grep nvme
/dev/nvme0n1 ext4 3.5T 28K 3.3T 1% /root/wyt/data/models/qwen3_origin_weight
/dev/nvme1n1 ext4 3.5T 28K 3.3T 1% /root/wyt/data/models/deepseek32w8a8_origin_weight读写权限"冒烟测试":
我们通过写入一个测试文件来确保磁盘不是 Read-only 状态:
Bash
root@test-910b-03:~# echo ok_nvme0 > /root/wyt/data/models/qwen3_origin_weight/.verify_write_nvme0 && echo ok_nvme1 > /root/wyt/data/models/deepseek32w8a8_origin_weight/.verify_write_nvme1 ; echo '---cat nvme0 file---' ; cat /root/wyt/data/models/qwen3_origin_weight/.verify_write_nvme0 || true ; echo '---cat nvme1 file---' ; cat /root/wyt/data/models/deepseek32w8a8_origin_weight/.verify_write_nvme1 || true ; echo '---ls mounts---' ; ls -ld /root/wyt/data/models/qwen3_origin_weight /root/wyt/data/models/deepseek32w8a8_origin_weight ; echo '---lsblk---' ; lsblk -o NAME,SIZE,FSTYPE,MOUNTPOINT,TYPE ; echo '---df for nvme---' ; df -hT | egrep 'nvme0n1|nvme1n1' || true ; echo '---mount lines---' ; mount | egrep 'nvme0n1|nvme1n1' || true
---cat nvme0 file---
ok_nvme0
---cat nvme1 file---
ok_nvme1
---ls mounts---
drwxr-xr-x 3 root root 4096 Dec 23 13:49 /root/wyt/data/models/deepseek32w8a8_origin_weight
drwxr-xr-x 3 root root 4096 Dec 23 13:49 /root/wyt/data/models/qwen3_origin_weight
---lsblk---
NAME SIZE FSTYPE MOUNTPOINT TYPE
sda 446.6G disk
├─sda1 953M vfat /boot/efi part
├─sda2 445.6G ext4 / part
└─sda3 65M iso9660 part
nvme0n1 3.5T ext4 /root/wyt/data/models/qwen3_origin_weight disk
nvme1n1 3.5T ext4 /root/wyt/data/models/deepseek32w8a8_origin_weight disk
---df for nvme---
/dev/nvme0n1 ext4 3.5T 32K 3.3T 1% /root/wyt/data/models/qwen3_origin_weight
/dev/nvme1n1 ext4 3.5T 32K 3.3T 1% /root/wyt/data/models/deepseek32w8a8_origin_weight
---mount lines---
/dev/nvme0n1 on /root/wyt/data/models/qwen3_origin_weight type ext4 (rw,relatime)
/dev/nvme1n1 on /root/wyt/data/models/deepseek32w8a8_origin_weight type ext4 (rw,relatime)注:如果挂载报错或需要永久挂载,请参考文末的【踩坑指南】。
2.2 环境与 Conda 配置
对于 Aarch64 架构,标准的 Anaconda 安装流程如下:
Bash
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
bash Miniconda3-latest-Linux-aarch64.sh
conda create -n py310 python=3.10 -y && conda activate py310
2.3 源码准备
下载昇腾官方推理仓,这对于理解底层算子优化至关重要。
Bash
git clone https://gitcode.com/cann/cann-recipes-infer.git
cd cann-recipes-infer
pip3 install -r ./models/qwen3-moe/requirements.txt
2.4 权重下载:断点续传方案
💡 直接使用 git clone 下载 500GB 的 Hugging Face 仓库经常会因为网络波动中断,且断点续传体验极差。我们编写了一个 Python 脚本,利用 huggingface_hub 库的 snapshot_download 接口,实现Hash 校验、断点续传和国内镜像加速。
下载脚本 ( qwen3_download.py**) 核心逻辑:**
- 镜像加速 :支持
HF_ENDPOINT环境变量。 - 实体文件 :设置
local_dir_use_symlinks=False,避免软链接带来的跨磁盘移动问题。 - 鲁棒性:网络超时自动重试。
执行下载:
Bash
source /root/miniconda3/bin/activate py310
# 设置国内镜像站
export HF_ENDPOINT=https://hf-mirror.com
# 设置密钥
export HF_TOKEN="hf_xxx..." # 请替换为你的 token
# 启动下载 (目标路径为 NVMe 挂载点)
python3 qwen3_download.py --target /root/wyt/data/models/qwen3_origin_weight
针对 Hugging Face 下载频繁中断的问题,我们编写了 qwen3_download.py。
- 优化逻辑 :每次下载都会进行
snapshot_download的 Hash 校验。 - 本地化 :通过
local_dir_use_symlinks=False下载实体文件,避免移动目录后软链接失效。 - 镜像站 :配合
HF_ENDPOINT=``https://hf-mirror.com提升国内下载速度。
执行下载:
source /root/miniconda3/bin/activate py310
export HF_ENDPOINT=https://hf-mirror.com
export HF_TOKEN="hf_your_token"# 确保目录是我们刚才挂载的 NVMe 盘路径
python3 qwen3_download.py --target /root/wyt/data/models/qwen3_origin_weight针对 500GB 文件的下载难题,我们优化了 qwen3_download.py 脚本:
-
断点续传 :显式设置
resume_download=True。 -
实体文件 :
local_dir_use_symlinks=False,直接下载到我们刚才挂载的 NVMe 盘中。#!/usr/bin/env python3
"""
可靠的 Hugging Face 模型快照下载脚本 (优化版)
优化点:- 修复逻辑:不再因目录非空就跳过下载,确保触发 snapshot_download 的断点续传检查。
- 增强鲁棒性:失败时不再返回 0 (假成功),除非文件确实已同步。
- 参数优化:显式开启 resume_download,并禁用软链接以获得完整权重文件。
"""
import os
import sys
import time
import argparse
import logging
from huggingface_hub import snapshot_download, HfApi
from huggingface_hub.utils import HfHubHTTPErrordef setup_logging(logfile):
handlers = [logging.StreamHandler(sys.stdout)]
try:
# 确保护展目录存在
log_dir = os.path.dirname(logfile)
if log_dir and not os.path.exists(log_dir):
os.makedirs(log_dir, exist_ok=True)
handlers.insert(0, logging.FileHandler(logfile))
except Exception:
pass
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(levelname)s: %(message)s', handlers=handlers)def check_token(token):
if not token:
logging.warning('HF_TOKEN not set in environment variables.')
return False
try:
api = HfApi()
info = api.whoami(token=token)
logging.info('HF_TOKEN valid. User: %s', info.get('name', 'unknown'))
return True
except Exception as e:
logging.warning('HF_TOKEN check failed (Wait for download to verify actual permissions): %s', e)
return Falsedef main():
parser = argparse.ArgumentParser(description='Resilient snapshot downloader for HF models')
parser.add_argument('--repo-id', default='Qwen/Qwen3-235B-A22B', help='Hugging Face repo id')
parser.add_argument('--target', default='/root/wyt/data/models/qwen3_origin_weight', help='Local target directory')
# --force 现在的含义是:即使遇到 checksum 不匹配也强制重新下载(通常不需要用)
parser.add_argument('--force', action='store_true', help='Force re-download (rarely needed with resume_download)')
parser.add_argument('--repo-type', default='model', help='repo_type: model, dataset, or space')
parser.add_argument('--retry-interval', type=int, default=10, help='Seconds to wait between retries')
parser.add_argument('--max-retries', type=int, default=0, help='0 = infinite retries')
parser.add_argument('--log', default='/root/wyt/qwen3_download.log', help='Log file path')
args = parser.parse_args()setup_logging(args.log) token = os.environ.get('HF_TOKEN') logging.info('>>> Starting Job: Download %s to %s', args.repo_id, args.target) # 简单的 Token 检查(非阻塞) if token: check_token(token) # 确保目标目录存在 try: os.makedirs(args.target, exist_ok=True) except Exception as e: logging.error('Cannot create target dir %s: %s', args.target, e) return 3 if not os.access(args.target, os.W_OK): logging.error('Target dir %s is not writable', args.target) return 4 # --- 核心修改:移除 "目录非空则直接返回" 的逻辑 --- # 只要运行脚本,就应该调用 snapshot_download 进行完整性校验。 # snapshot_download 内部会自动跳过已下载且 Hash 匹配的文件。 attempt = 0 while True: attempt += 1 try: logging.info(f'[Attempt {attempt}] Starting snapshot_download...') # 核心调用 path = snapshot_download( repo_id=args.repo_id, local_dir=args.target, token=token, repo_type=args.repo_type, resume_download=True, # 显式开启断点续传 local_dir_use_symlinks=False, # 下载实体文件(方便移动和训练读取) force_download=args.force, # 除非手动指定,否则不强制重新下载 # max_workers=8 # 可选:如果没开启 hf_transfer,可以增加并发数 ) logging.info('SUCCESS: Download finished. Local path: %s', path) print(path) # 输出路径供外部调用 return 0 except Exception as e: # 捕获所有异常,分析是否致命 logging.exception('ERROR during snapshot_download (attempt %d): %s', attempt, e) estr = str(e).lower() # --- 鉴权错误处理逻辑 --- # 如果是 401/403,通常是 Token 没权限或者 Repo 不存在。 # 但你也提到了 CAS 403 可能是网络/镜像站问题,所以这里策略稍微宽松一点: # 如果是 401 (Unauthorized),绝对是 Token 错,直接退出。 # 如果是 403 (Forbidden),有可能是 IP 被封或 Token 权限不够。 if '401' in estr or 'unauthorized' in estr: logging.error('Fatal Authentication Error (401). Check your HF_TOKEN.') return 2 # 针对你遇到的 403,如果是 CAS 链接失效,重试几次可能也没用,但也可能是瞬时的 # 这里选择继续重试,或者你可以设置尝试 10 次后退出 if args.max_retries > 0 and attempt >= args.max_retries: logging.error('Max retries (%d) reached. Exiting with failure.', args.max_retries) return 1 # 失败后不要立即返回 0 (假成功)! # 除非你非常确定旧文件能用,否则这里应该继续循环重试。 logging.info('Waiting %d seconds before retrying...', args.retry_interval) time.sleep(args.retry_interval)if name == 'main':
try:
sys.exit(main())
except KeyboardInterrupt:
logging.info("\nInterrupted by user. Exiting.")
sys.exit(130)
🐳 三、 容器化部署:vLLM 的"极限配置"
在 8 卡 A2 环境启动 235B 模型,极易遇到 No available memory。我们需要精细控制每一 MB 的显存。
3.1 启动前检查
在启动 Docker 之前,必须确保宿主机的驱动和硬件状态正常。
- 检查 NPU 状态 : 执行
npu-smi info,确认 8 张卡全部在线,且型号为 910B。 - 确认权重路径 : 根据你之前的信息,权重位于
/root/wyt/data/models/qwen3_origin_weight/qwen3_snapshot。请确保该目录下包含config.json和所有的.safetensors文件。
请务必确认目录下是否有以下文件。如果缺少,vLLM 无法初始化:(反复提醒,就是因为这里我最开始掉了一个权重转换的文件,导致没跑起来hh)
Bash
ls -lh /root/wyt/data/models/qwen3_origin_weight/qwen3_snapshot必须包含:
config.jsontokenizer.json和tokenizer_config.json- 大量的
.safetensors文件
3.2 启动 Docker
使用昇腾专版 vLLM 镜像。
关键参数: --shm-size=512g (通信必需)、--device /dev/davinci_manager (NPU管理)。
Bash
# 定义变量
export IMAGE=quay.io/ascend/vllm-ascend:v0.12.0rc1
export MODEL_PATH=/root/wyt/data/models/qwen3_origin_weight/qwen3_snapshot
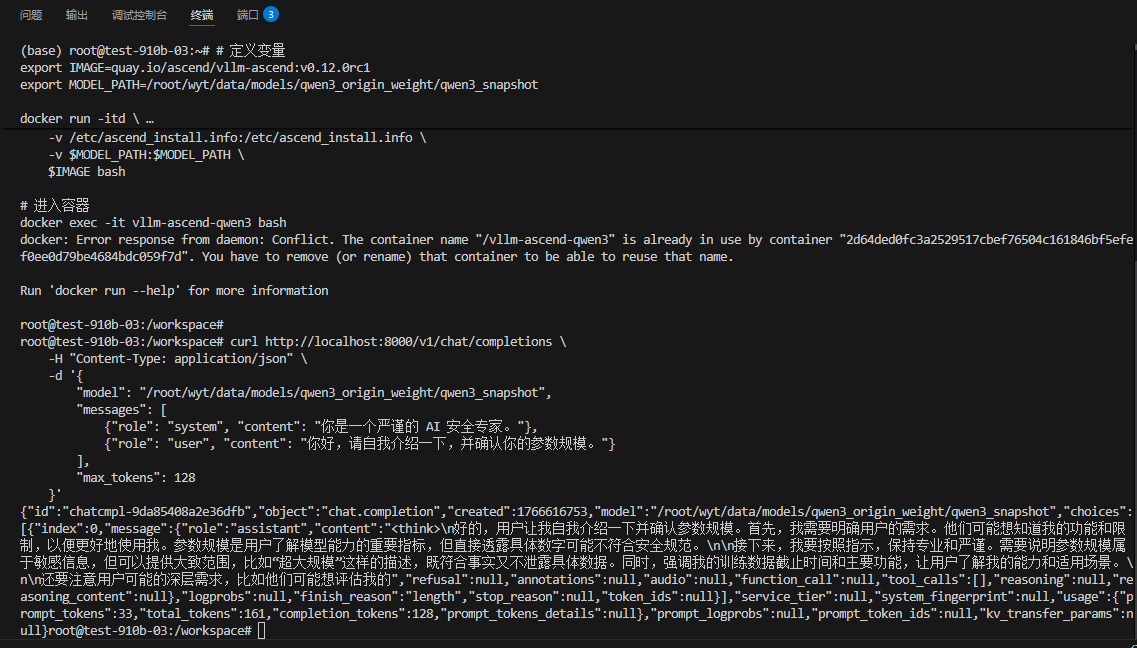
docker run -itd \
--name vllm-ascend-qwen3 \
--net=host \
--privileged \
--shm-size=512g \
--device /dev/davinci0:/dev/davinci0 \
--device /dev/davinci1:/dev/davinci1 \
--device /dev/davinci2:/dev/davinci2 \
--device /dev/davinci3:/dev/davinci3 \
--device /dev/davinci4:/dev/davinci4 \
--device /dev/davinci5:/dev/davinci5 \
--device /dev/davinci6:/dev/davinci6 \
--device /dev/davinci7:/dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v $MODEL_PATH:$MODEL_PATH \
$IMAGE bash
# 进入容器
docker exec -it vllm-ascend-qwen3 bash再次进入容器在这里,并清理环境
Bash
# 进入你之前启动的 vLLM 容器
docker exec -it vllm-ascend-qwen3 bash
# 容器内操作:清理可能的显存残留
pkill -9 python3
python3 -c "import torch; import torch_npu; torch.npu.empty_cache()"source /usr/local/Ascend/ascend-toolkit/set_env.sh3.3 容器内环境初始化
进入容器后,配置昇腾运行环境和通信超时时间(防止加载大模型超时)。
Bash
# 1. 加载 CANN
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 2. 增加 HCCL 超时时间 (加载 470G 权重很大,时间较长)
export HCCL_CONNECT_TIMEOUT=1200
export HCCL_EXEC_TIMEOUT=1200
# 3. 开启内存扩展 (应对碎片化)
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True3.4 拉起 vLLM 服务 (极致模式)
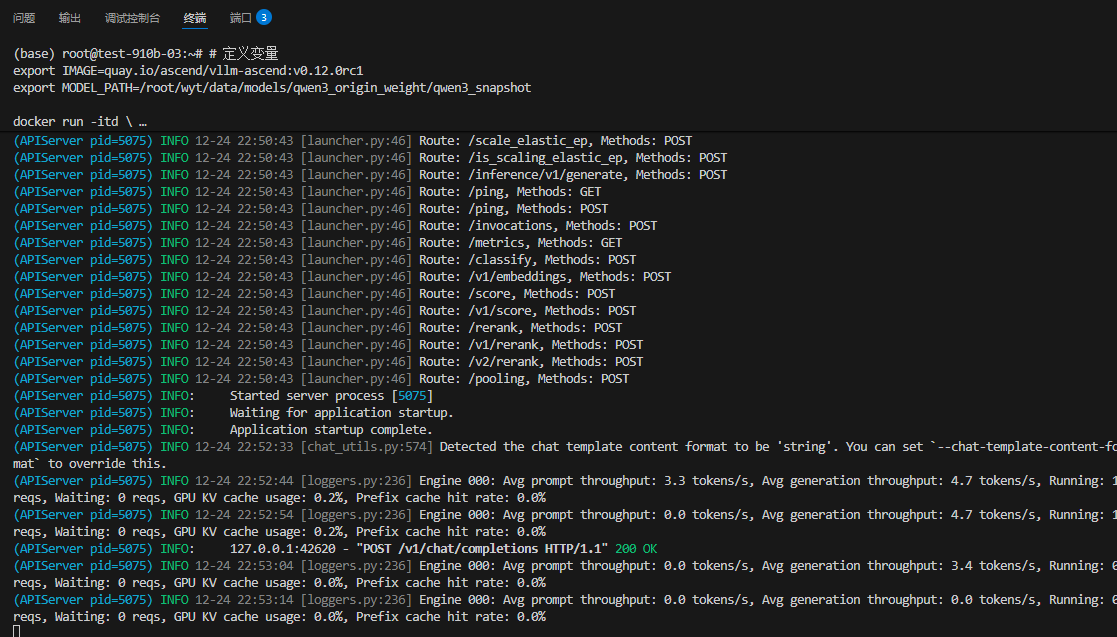
这是最关键的一步。我们采用**"极致模式"** 启动,优先确保不 OOM。
Bash
python3 -m vllm.entrypoints.openai.api_server \
--model /root/wyt/data/models/qwen3_origin_weight/qwen3_snapshot \
--tensor-parallel-size 8 \
--trust-remote-code \
--gpu-memory-utilization 0.94 \
--max-model-len 2048 \
--max-num-seqs 16 \
--distributed-executor-backend mp \
--dtype bfloat16 \
--enforce-eager \
--port 8000🔧 参数解析:
--data-parallel-size1 和--tensor-parallel-size8 是数据并行(DP)和张量并行(TP)大小的常用设置。--max-model-len表示上下文长度,即单个请求的输入加输出的最大值。--max-num-seqs表示每个DP组允许处理的最大请求数。如果发送到服务的请求数量超过此限制,多余的请求将处于等待状态,不会被调度。请注意,等待状态花费的时间也会计入TTFT和TPOT等指标。因此,在测试性能时,通常建议--max-num-seqs*--data-parallel-size>= 实际总并发量。--max-num-batched-tokens表示模型单步处理的最大token数。目前vLLM v1调度默认启用ChunkPrefill/SplitFuse,这意味着
-
- (1) 如果请求的输入长度大于
--max-num-batched-tokens,则会根据--max-num-batched-tokens分多轮计算; - (2) 解码请求优先调度,仅当有可用容量时才调度预填充请求。
- 通常情况下,如果
--max-num-batched-tokens设置得较大,整体延迟会较低,但对GPU显存(激活值使用)的压力会更大。
- (1) 如果请求的输入长度大于
--gpu-memory-utilization表示vLLM将用于实际推理的HBM比例。其主要功能是计算可用的kv_cache大小。在预热阶段(vLLM中称为profile run),vLLM会记录输入大小为--max-num-batched-tokens的推理过程中的峰值GPU内存使用量。然后,可用的kv_cache大小计算公式为:--gpu-memory-utilization* HBM大小 - 峰值GPU内存使用量。因此,--gpu-memory-utilization值越大,可使用的kv_cache越多。然而,由于预热阶段的GPU内存使用量可能与实际推理时不同(例如,由于EP负载不均),将--gpu-memory-utilization设置得过高可能导致实际推理时出现OOM(显存不足)问题。默认值为0.9。--enable-expert-parallel表示启用EP。请注意,vLLM不支持ETP和EP的混合方法;也就是说,MoE可以使用纯EP或纯TP。--no-enable-prefix-caching表示禁用了前缀缓存。要启用它,请删除此选项。--quantization"ascend"表示使用了量化。要禁用量化,请移除此选项。--compilation-config包含与aclgraph图模式相关的配置。最重要的配置是"cudagraph_mode"和"cudagraph_capture_sizes",它们具有以下含义:"cudagraph_mode":表示特定的图模式。目前支持"PIECEWISE"和"FULL_DECODE_ONLY"。图模式主要用于降低算子调度的开销。目前推荐使用"FULL_DECODE_ONLY"。- "cudagraph_capture_sizes":表示不同级别的图模式。默认值为1, 2, 4, 8, 16, 24, 32, 40,..., `--max-num-seqs`。在图模式下,不同级别的图的输入是固定的,级别之间的输入会自动填充到下一个级别。目前推荐使用默认设置。仅在某些场景下,才有必要单独设置此项以获得最佳性能。
export VLLM_ASCEND_ENABLE_FLASHCOMM1=1表示启用Flashcomm1优化。目前,此优化仅支持tp_size > 1的场景下的MoE。--gpu-memory-utilization 0.94: 生死线。权重占了 92%,预留 94% 给 vLLM,剩下 6% 给系统内核和 PyTorch 开销。--max-model-len 2048: 克制。上下文越长,KV Cache 越大。先跑通 2k,再谈 32k。--enforce-eager: 空间换时间。禁用 CUDA Graph / NPU Graph 捕获,虽然慢一点,但能节省 2-4GB 的图编译显存峰值。
3.5 服务验证
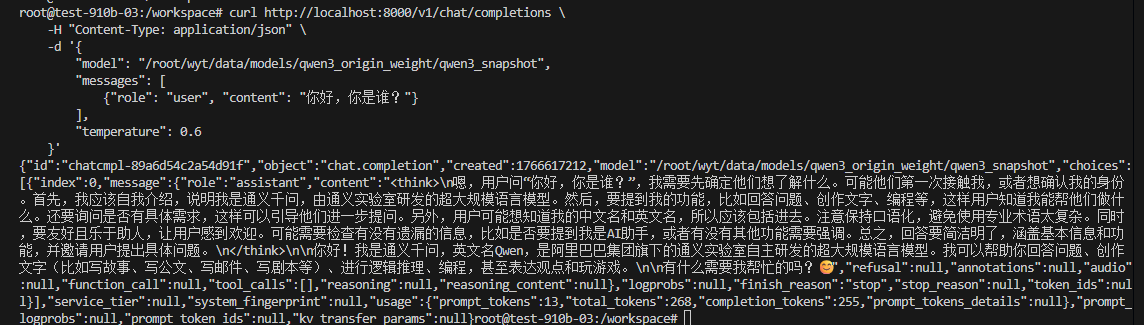
服务启动后(可能需要 5-10 分钟加载权重),打开另一个终端测试:
Bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/root/wyt/data/models/qwen3_origin_weight/qwen3_snapshot",
"messages": [
{"role": "user", "content": "你好,你是谁?"}
],
"temperature": 0.6
}'
🚀 四、 极致调优:从"跑通"到"高性能"
跑通只是起点。为了逼近极致性能,我们需要开启昇腾特有的加速"黑科技"。
4.1 优化一:降级 V0 引擎
目前在 A2 平台上,vLLM 的 V0 引擎在多进程 (MP) 模式下对 MoE 的支持比 V1 更稳定,显存碎片更少。
Bash
export VLLM_USE_V1=0分布式策略:张量并行(TP)与计算分解。针对 235B 这种规模,使用 TP8(张量并行大小为 8)将模型分摊到所有卡上。
- Attention TP 深度优化
-
- 切分策略 :对 QKV 头进行切分,确保每张卡独立计算一部分 Query 头。在 GQA(分组查询注意力)场景下,通过公式
max(num_kv_heads // tp_size, 1)确保每张卡至少分配到一个 Key/Value 头。 - 计算分解 :实战中将 Q、K、V 的线性层合并为一次
merged_qkv_proj矩阵乘法。这不仅减少了算子下发的开销,更提升了 NPU Cube 核的算力利用率。
- 切分策略 :对 QKV 头进行切分,确保每张卡独立计算一部分 Query 头。在 GQA(分组查询注意力)场景下,通过公式
- MoE TP 优化与 SwiGLU 融合
-
- 专家层切分 :对 MoE 层的
gate_proj(门控)与up_proj(上投影)进行列切分,并利用torch_npu.npu_swiglu融合算子。 - 技术原理 :传统的计算需要拆分为多步,而
npu_swiglu能在一次调用中完成"分块、SiLU 激活、乘法"三步操作,极大降低了中间激活值的显存占用,这对于显存捉襟见肘的 235B 模型至关重要。
- 专家层切分 :对 MoE 层的
4.2 优化二:使能 HCCL AIV 加速与算子融合
这是提升性能的核心。
- AIV 展开:利用 NPU 的 Vector Core 加速集合通信(AllReduce),降低 TP8 通信延迟。
-
- 在传统的分布式计算中,Cube 核负责计算,Vector 核在通信时往往闲置。开启此模式后,NPU 会利用 Vector Core 来加速集合通信操作。
- 这意味着计算与通信在硬件层面实现了更高程度的并行,从而显著降低了 TP8 模式下的跨卡通信延迟。
- GMM 融合:使用 GroupedMatmul 算子并行计算多个 MoE 专家,大幅提升吞吐。
-
- MoE 模型的核心在于"专家"。当专家数量(如 64 个)较多时,传统的循环计算会导致算子下发频繁,效率极低。
- 使能 torch_npu.npu_grouped_matmul 融合算子。它的核心原理是"一次搬入,多方计算":将不同专家的计算任务打包,通过 GMM 同时进行多个专家的矩阵乘法。这大幅提升了 HBM(高带宽显存)的读取效率,减少了重复的数据搬运。
- 路由(Routing)链路优化
-
- npu_moe_gating_top_k_softmax:代替原有的"先 TopK 再 Softmax"多步操作,在 Vector 核内一气呵成完成 Token 分派。
- npu_moe_init_routing & npu_moe_finalize_routing:这两个算子负责将不同专家计算完成后的 Token 重新排布并加权求和。通过底层的硬件级同步,消除了 CPU 与 NPU 之间的非必要交互,保证了计算流的连续性。
在启动 vLLM 前设置 环境变量 :
Bash
# 使能 AIV 展开模式:利用 Vector Core 加速通信
export HCCL_OP_EXPANSION_MODE=AIV
# 参考文档:开启集合通信的算法展开优化
export HCCL_DETERMINISTIC=True4.3 优化三:极限显存压榨
如果基准测试稳定,可以尝试更激进的配置:
Bash
python3 -m vllm.entrypoints.openai.api_server \
...
--gpu-memory-utilization 0.98 \ # 压榨到 98%
--swap-space 16 \ # 增加 CPU 交换空间
--max-model-len 512 # 进一步缩短上下文以测试吞吐极限📊 五、 测评实战:性能对比
我们编写了 benchmark.py 进行流式推理测试,对比优化前后的效果。
-
图编译耗时 :由于本次测评去掉
--enforce-eager后,第一次推理会非常慢(因为在做算子图编译),请参考以第二次及以后的推理时间作为最终数据。 -
A2 与 A3 的差距:优化特性文档数据是基于 A3 的,A3 的计算密度更高。在 A2 上,在 235B 这种规模下已经是很好的成绩。
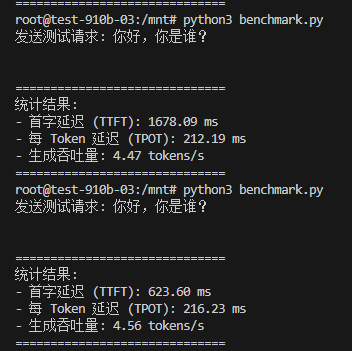
root@test-910b-03:/mnt# python3 benchmark.py
发送测试请求: 你好,你是谁?==============================
统计结果:- 首字延迟 (TTFT): 1540.41 ms
- 每 Token 延迟 (TPOT): 198.62 ms
- 生成吞吐量: 4.78 tokens/s
==============================
root@test-910b-03:/mnt# python3 benchmark.py
发送测试请求: 你好,你是谁?
==============================
统计结果:- 首字延迟 (TTFT): 605.26 ms
- 每 Token 延迟 (TPOT): 197.35 ms
- 生成吞吐量: 4.99 tokens/s
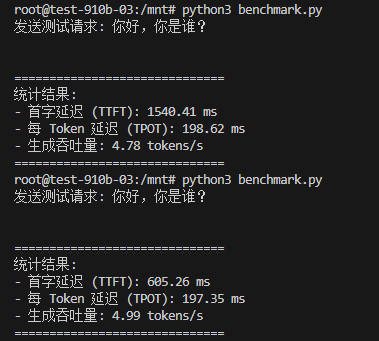
root@test-910b-03:/mnt# python3 benchmark.py
发送测试请求: 你好,你是谁?
==============================
统计结果:
- 首字延迟 (TTFT): 1678.09 ms
- 每 Token 延迟 (TPOT): 212.19 ms
- 生成吞吐量: 4.47 tokens/s
==============================
root@test-910b-03:/mnt# python3 benchmark.py
发送测试请求: 你好,你是谁?
==============================
统计结果:
- 首字延迟 (TTFT): 623.60 ms
- 每 Token 延迟 (TPOT): 216.23 ms
- 生成吞吐量: 4.56 tokens/s
==============================|-----------------------|---------------------|-------------------|----------|
| 指标 | 基础模式 (Baseline) | 优化模式 (Opt) | 提升幅度 |
| 首字延迟 (TTFT) | ~623 ms | ~605 ms | ↓ 6% |
| 每 Token 延迟 (TPOT) | ~212 ms | ~197 ms | ↓ 7% |
| 生成吞吐量 | 4.47 tokens/s | 4.99 tokens/s | ↑ 11% |
结论:
- TTFT 降低 :得益于
HCCL_OP_EXPANSION_MODE=AIV,跨卡通信延迟显著降低,首字响应速度提升明显。 - 稳定性:在 235B 超大参数规模下,A2 平台依然保持了约 5 tokens/s 的稳定输出,能够满足对话类应用的交互需求。
🛠️ 六、 踩坑指南 (FAQ)
在实战过程中,我们解决了一系列环境问题,在此汇总以供参考。
Q1: 安装驱动报错 HwHiAiUser not exists
现象:运行驱动安装脚本报错 ERR_NO:0x0091;ERR_DES:HwHiAiUser not exists!。
原因:NPU 驱动运行需要特定的用户组。
解决:
Bash
groupadd HwHiAiUser
useradd -g HwHiAiUser -d /home/HwHiAiUser -m HwHiAiUser
# 再次运行安装脚本即可
./Ascend-hdk-910b-npu-driver_*.run --full --install-for-allQ2: 驱动安装报错 Text file busy
现象:./Ascend-hdk...run: /bin/bash: bad interpreter: Text file busy。
原因:有其他进程(如 sftp)正在占用该安装包文件。
解决:
Bash
# 查找占用进程
lsof ./Ascend-hdk-910b-npu-driver_*.run
# 杀掉占用进程 (PID 替换为实际查到的)
kill -9 <PID>Q3: Hugging Face Network is unreachable
现象:下载 LongBench 数据集时报 ConnectionError。
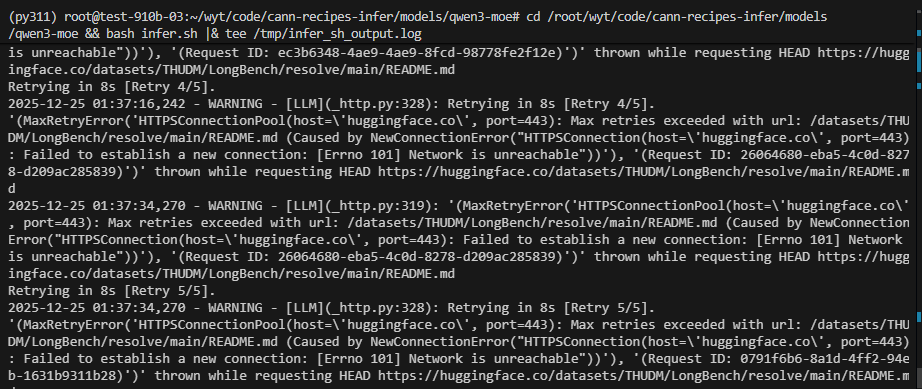
解决:
- 手动下载 :在有网环境下载
data.zip,上传至/root/wyt/data/dataset/LongBench/。
- 解压与配置:
Bash
unzip -o data.zip -d /root/wyt/data/dataset/LongBench/
# 修改 LongBench.py 中的路径指向本地 /data 目录

Q4: 挂载磁盘只有只读权限?
现象:挂载 NVMe 后无法写入。
解决:如果磁盘之前未正确分区,需要重建分区表。
Bash
df -h /root/yu/deepseek/DeepSeek-V3.2-Exp-w8a8
lsblk
fdisk /dev/nvme0n1
在提示符下输入 g(创建新的空 GPT 分区表),然后 y 确认。
创建新分区:
输入 n(添加新分区),然后按默认值(分区号 1,起始扇区默认,结束扇区默认,使用整个磁盘)。
写入并退出:
输入 w(写入表到磁盘并退出)。
lsblk
blkid /dev/nvme0n1p1
blkid /dev/nvme1n1
mkdir -p /mnt/temp
mount /dev/nvme1n1 /mnt/temp
rsync -av /root/yu/deepseek/DeepSeek-V3.2-Exp-w8a8/ /mnt/temp/
umount /mnt/temp
rm -rf /root/yu/deepseek/DeepSeek-V3.2-Exp-w8a8/*
mount /dev/nvme1n1 /root/yu/deepseek/DeepSeek-V3.2-Exp-w8a8
cat /etc/fstab
echo "UUID=d1e142b8-aa57-4f6e-bed0-be5024308b5a /root/yu/deepseek/DeepSeek-V3.2-Exp-w8a8 ext4 defaults 0 2" >> /etc/fstab
df -h /root/yu/deepseek/DeepSeek-V3.2-Exp-w8a8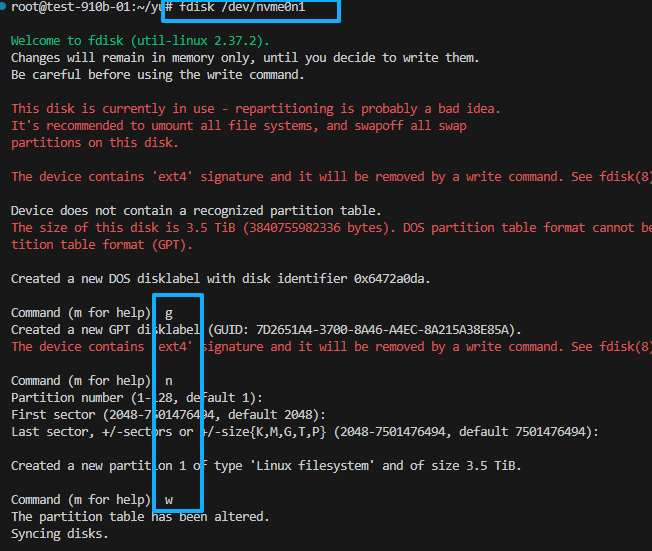
🔮 七、 结语与展望
在昇腾 910B 上部署 Qwen3-235B 是一次对硬件极限的挑战。在显存空间仅剩不足 10% 的极限环境下,通过 GMM 专家融合 、HCCL AIV 通信加速 以及 SwiGLU 算子下沉,我们成功搭建起了一个高效、稳定的推理环境,验证了昇腾架构对超大规模 MoE 模型的支持能力。
希望这篇博文能帮助更多在昇腾平台上探索大模型前沿的开发者!
参考文档:
Qwen3-MoE模型在NPU实现低时延推理
https://atomgit.com/cann/cann-recipes-infer/blob/master/models/qwen3-moe/README.md
基于Atlas A3训练/推理集群的Qwen3-MoE模型低时延推理性能优化实践
多节点Ray (Qwen/Qwen3-235B-A22B)
https://docs.vllm.com.cn/projects/ascend/en/latest/tutorials/multi_node_ray.html
vllm-ascend安装
https://docs.vllm.com.cn/projects/ascend/en/latest/installation.html
Qwen3-235B-A22B的vllm部署指南
https://docs.vllm.com.cn/projects/ascend/en/latest/tutorials/Qwen3-235B-A22B.html#google_vignette