目录
[八、接入 LLM](#八、接入 LLM)
引言
在信息高度分散的时代,热点内容散落在掘金、B 站、微博、今日头条等多个平台,人工整理成本高且标准不统一。本文基于蓝耘MaaS和Dify实战搭建一套多平台内容聚合与大模型自动总结的工作流方案。通过统一解析各平台数据结构,将结果交由 LLM 自动生成结构化热闻摘要,并支持 Markdown / PDF 输出。整套流程覆盖数据采集、平台解析、变量聚合、模型调用与结果交付,可直接复用与扩展。适用于每日热闻汇总、舆情监测及自动化内容运营等实际场景。
一、蓝耘平台
**蓝耘元生代**是一个面向开发者与企业级用户的一站式 AI 智算与模型服务平台,整合了云算力、模型即服务(MaaS)、应用开发与大模型生态等核心能力,致力于降低 AI 应用从"想法"到"落地"的整体门槛。
平台不仅提供多种预训练大语言模型(如 DeepSeek 系列),还覆盖弹性算力调度、模型托管、推理服务与工具集成等多种使用模式,为技术团队和业务方提供从模型调用到部署运行的一体化解决方案。
在能力形态上,蓝耘既可以作为模型调用平台 使用,也可以承载更复杂的智能应用构建与 工作流 编排,适合需要快速验证、持续迭代或规模化运行 AI 能力的场景。
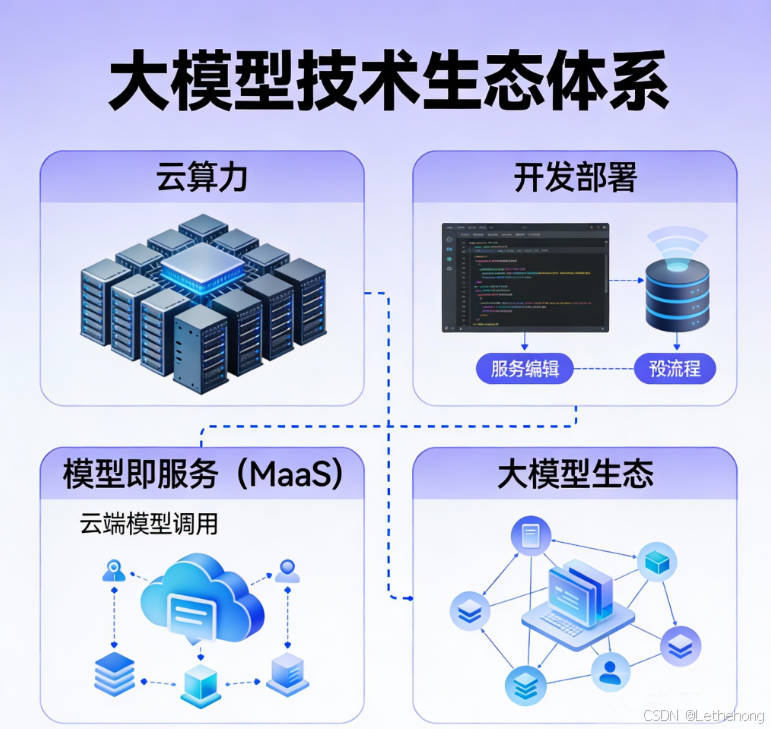
核心能力与产品
-
算力 调度与管理:支持分布式训练、弹性 GPU 调度、混合云与私有化部署,满足不同规模与负载特征的 AI 任务需求。
-
MaaS(模型即服务)平台:以 API 形式提供多种预训练模型能力,覆盖自然语言、图像与多模态场景,用户无需自行训练即可直接调用。
-
模型与生态广场:内置模型库、MCP 服务与工具集成、行业模板及可视化调试能力,加速应用开发与验证。
-
低代码 / 可视化开发支持:通过 UI 化方式构建 AI 工作流与模型调用逻辑,显著降低工程集成与维护成本。
可以将蓝耘理解为一个 "AI 智算 + 模型与工具服务集市": 你既可以通过网页或 API 直接调用现成模型(例如 DeepSeek-V3.2),也可以托管自有模型,或基于工作流构建更复杂的智能应用。
在本文的实战中,我们选择兼容蓝耘MaaS平台的 OpenAI-API-compatible 供应商进行配置,正是利用其兼容 API 的模型部署与推理能力------无需自行搭建底层算力或模型服务,只需将整理好的数据发送给模型,即可获得分析与生成结果。
二、工作流全景
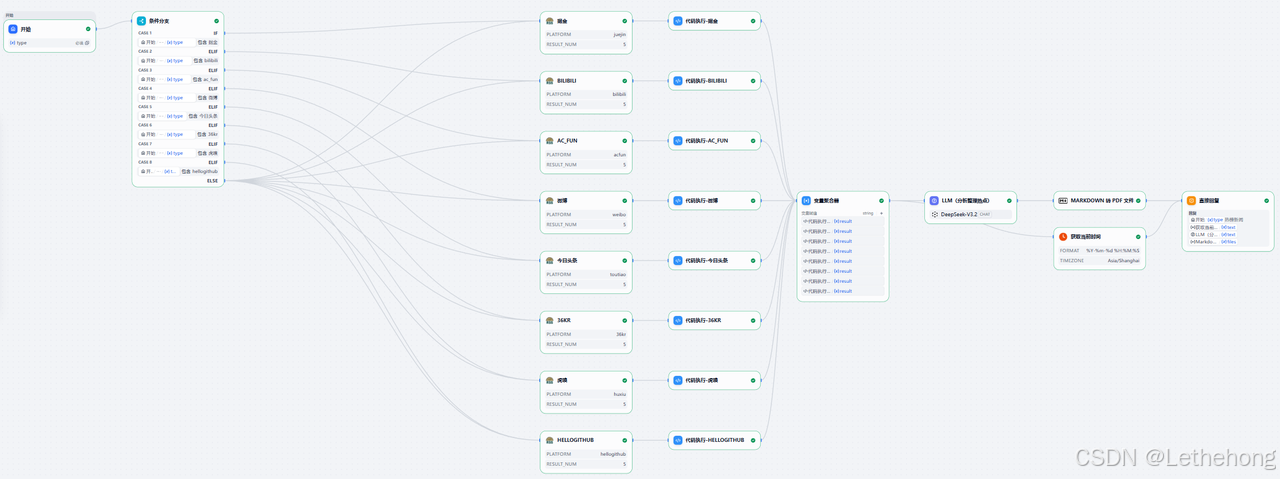
输出示例:
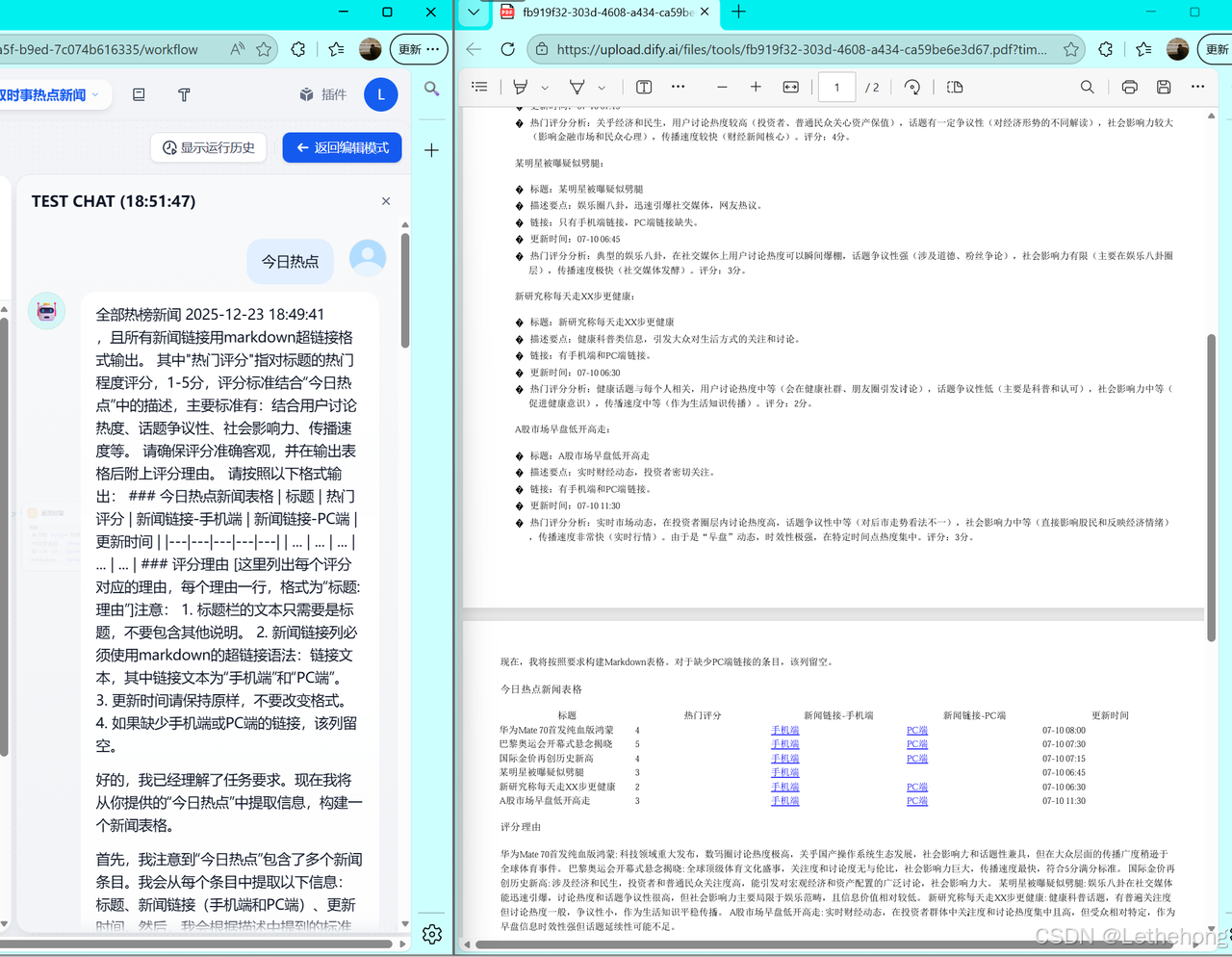
简单来说,整体流程可以概括为:
数据采集 → 平台 解析器 (统一格式) → 变量聚合器 → LLM 分析生成 → Markdown 转 PDF / 返回用户
通过工作流的方式,将"多平台差异"与"模型能力"解耦,保证流程清晰、结构可复用。
三、环境准备
在 Studio 中,首先需要安装以下三个插件(顺序无关):
-
rookie_rss(或你使用的其他抓取器)
-
OpenAI-API-compatible(用于对接兼容 OpenAI 接口的模型服务)
-
Markdown 转换器(用于将 Markdown 输出转换为 PDF)
安装完成后,确认插件在「已安装」列表中可见。
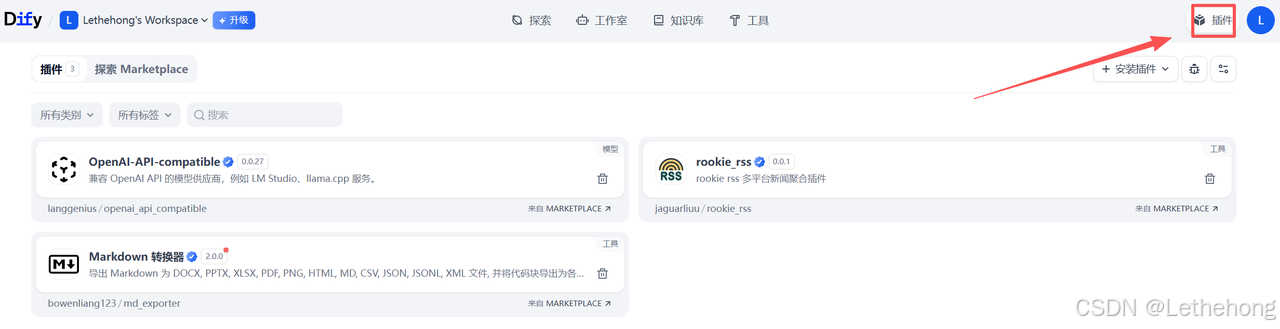
四、在工作室创建"空白应用"
步骤:
-
打开 Studio → 在窗口底部点击 创建空白应用。
-
进入应用后,添加第一个节点:数据输入(可以是 RSS / HTTP / webhook)。
-
添加条件分支节点(详见下一节),然后连接到不同平台的解析执行器(或统一解析器)。
五、条件分支说明
条件分支用于判断当前运行需要处理哪个平台的数据,举例判断字段 platform 的取值:"juejin", "bilibili", "weibo",或者 "all"。每个分支会把 arg1(原始 JSON)丢给对应的解析脚本或同一解析器的不同适配器。
设计建议:尽量把平台差异放在解析层(parser)里,工作流节点保持薄而专注,便于维护和扩展。
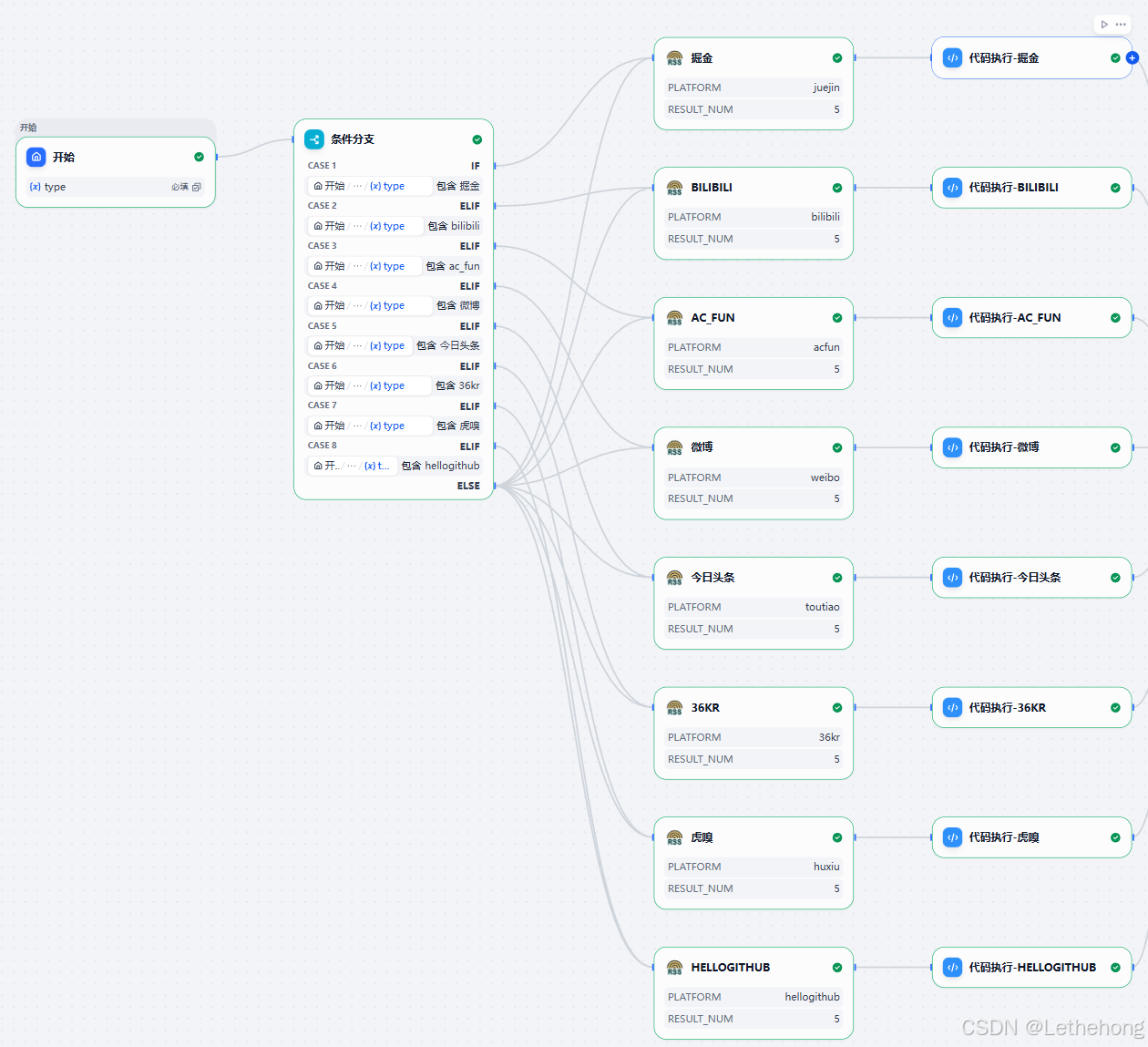
六、平台解析器
-
输入为 JSON 字符串、dict 或 list
-
自动提取
articles列表 -
统一输出表格(标题、热度、移动/PC 链接、更新时间)
-
时间戳解析:支持 ISO8601(有/无毫秒),以及秒/毫秒时间戳,最终转为上海时间(UTC+8)
推荐的可复用函数(放进 工作流 的"脚本执行"节点)
import json
from datetime import datetime, timezone, timedelta
from typing import Any, List, Dict
SH_TZ = timezone(timedelta(hours=8))
def parse_update_time(raw: Any) -> str:
if not raw:
return ""
s = str(raw)
# ISO 带毫秒: 2024-01-01T12:00:00.123Z
for fmt in ("%Y-%m-%dT%H:%M:%S.%fZ", "%Y-%m-%dT%H:%M:%SZ"):
try:
dt = datetime.strptime(s, fmt).replace(tzinfo=timezone.utc)
return dt.astimezone(SH_TZ).strftime("%Y-%m-%d %H:%M:%S")
except Exception:
pass
# 时间戳(秒或毫秒)
try:
ts = int(s)
if len(s) == 13:
ts = ts / 1000
dt = datetime.fromtimestamp(ts, tz=timezone.utc)
return dt.astimezone(SH_TZ).strftime("%Y-%m-%d %H:%M:%S")
except Exception:
return s
def extract_articles(data: Any) -> List[Dict]:
if isinstance(data, dict) and "articles" in data:
return data.get("articles", [])
if isinstance(data, list):
out = []
for item in data:
if isinstance(item, dict):
out.extend(item.get("articles", []))
return out
return []
def build_table_from_arg(arg1: Any) -> List[List[str]]:
# arg1 可以是 JSON 字符串 / dict / list
if isinstance(arg1, str):
try:
parsed = json.loads(arg1)
except Exception:
parsed = arg1
else:
parsed = arg1
# 支持包装 {"arg1": ...} 的情况
data = parsed.get("arg1", parsed) if isinstance(parsed, dict) else parsed
articles = extract_articles(data) if data else []
table = [["标题", "热门评分", "新闻链接-手机端", "新闻链接-PC端", "更新时间"]]
for item in articles:
title = item.get("title", "") if isinstance(item, dict) else ""
hot_score = item.get("hot_score", "")
mobile_link = item.get("links", {}).get("mobile", "") if isinstance(item, dict) else ""
pc_link = item.get("links", {}).get("pc", "") if isinstance(item, dict) else ""
update_time_raw = item.get("metadata", {}).get("update_time", "") if isinstance(item, dict) else ""
update_time = parse_update_time(update_time_raw)
table.append([title, hot_score, mobile_link, pc_link, update_time])
return table
# 在工作流里你可以把返回值转成 JSON 字符串或直接作为 node 输出
def main(arg1):
try:
tbl = build_table_from_arg(arg1)
return {"result": tbl}
except Exception as e:
return {"error": str(e)}说明:把这段代码放到"脚本执行"节点,并为不同平台的分支都调用此函数(因为原始数据结构一致时可直接复用)。如果某个平台的
articles结构不同,再写一个小 adapter 层把它规范成articles的格式。
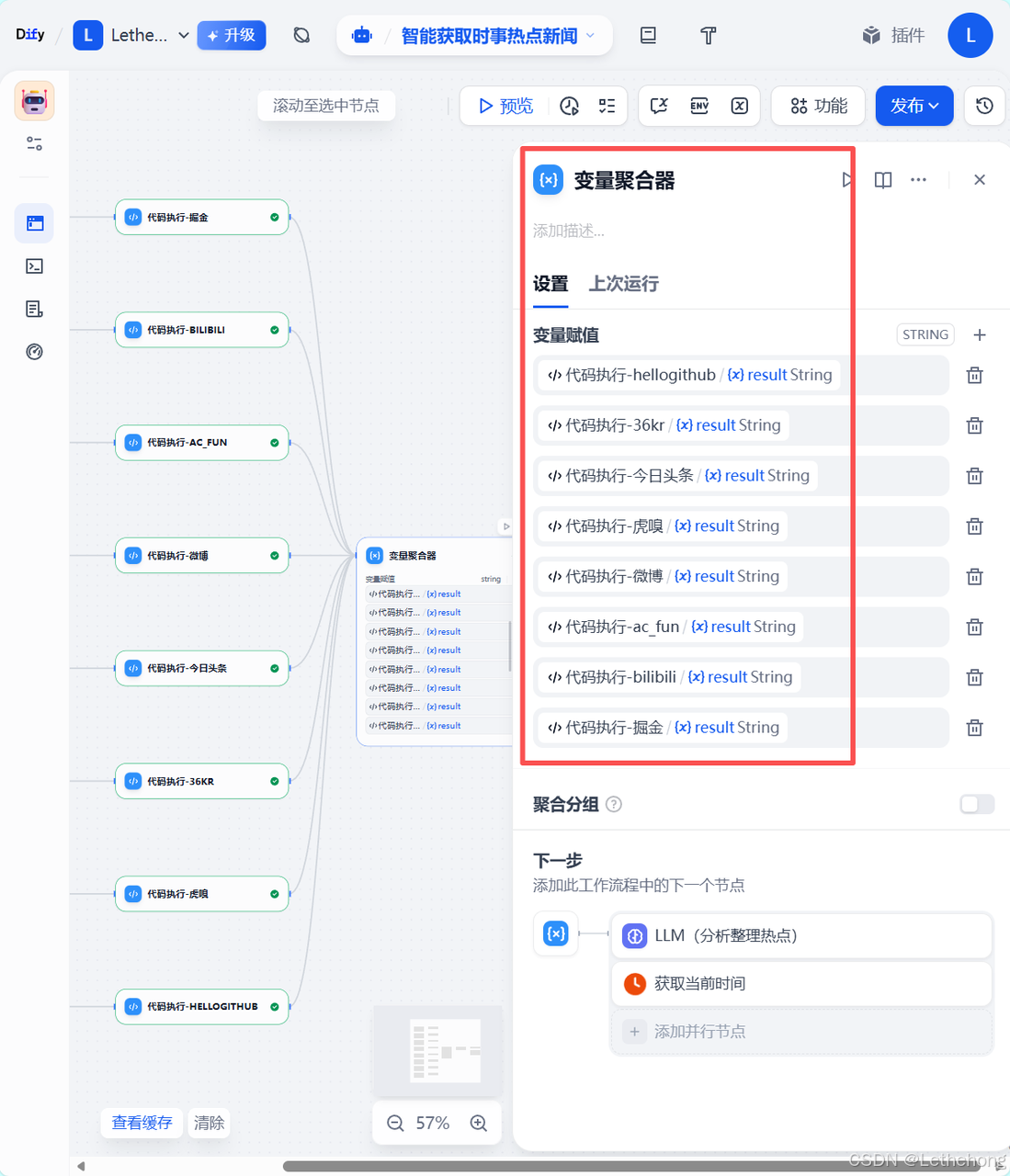
七、变量聚合器
变量聚合器的作用是把各平台解析结果和一些元数据(抓取时间、平台名、爬虫状态、样本条数、top N 关键词等)聚合成一个统一 context,传给 LLM。示例字段:
-
fetch_time(格式:2025-12-23 14:30:00) -
platforms("juejin","bilibili") -
article_table(上一步生成的表格) -
summary_prompt_template(你想让 LLM 怎样写总结的提示词) -
top_n(传给 LLM 的候选量,比如 top 5)
八、接入 LLM
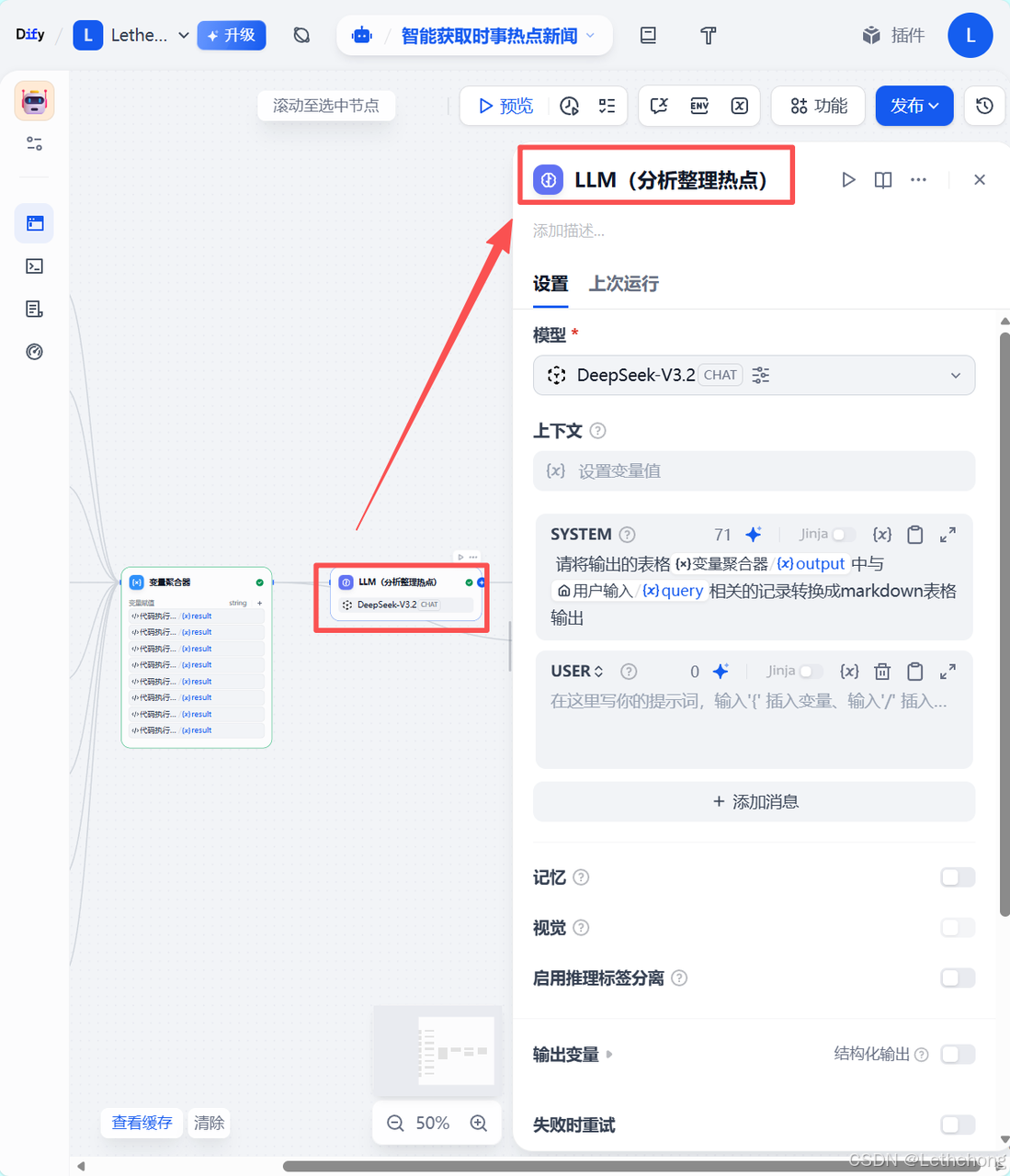
1、点击右上角头像 → 设置 → 模型供应商(Model Providers)→ 选择 OpenAI-API-compatible
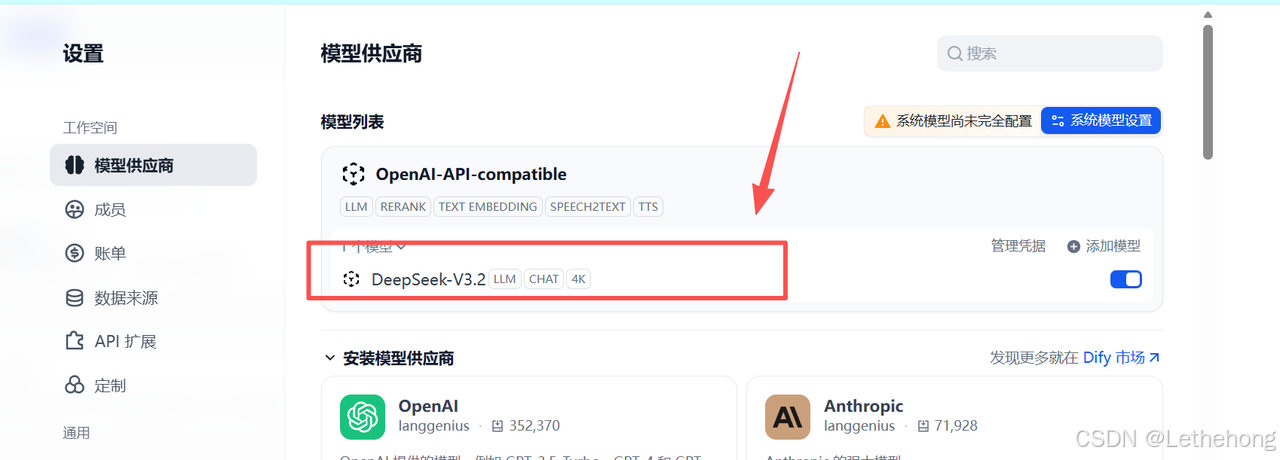
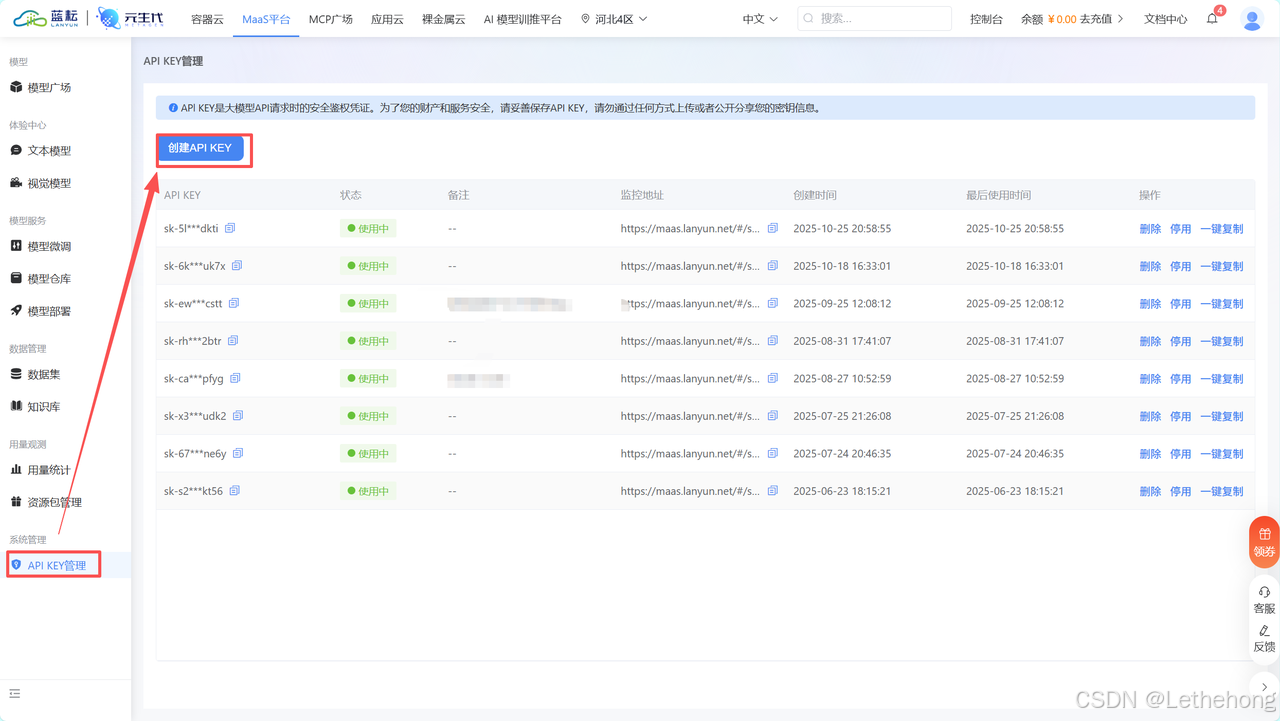
2、把 API Key / Endpoint / 必要参数填进去
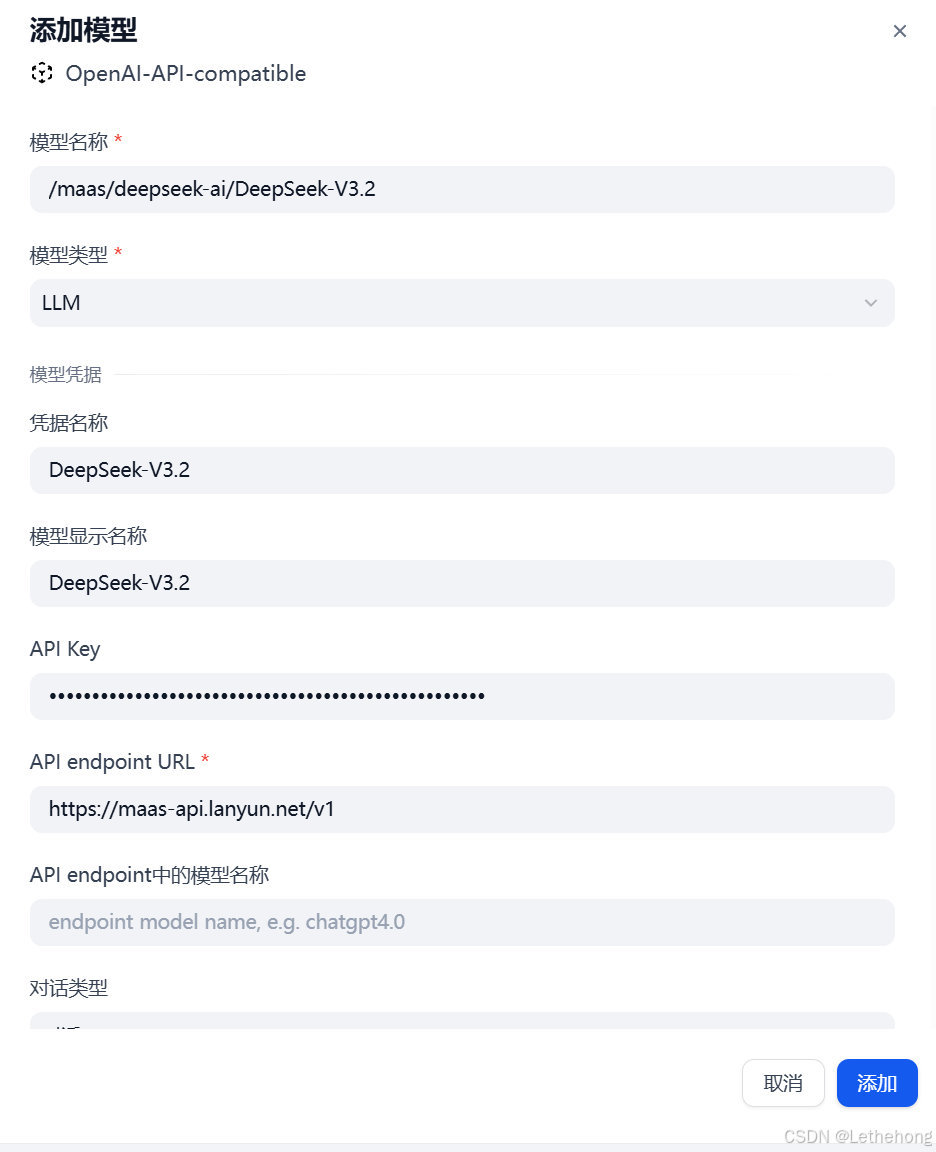
2、在"模型调用"节点里选择 deepseek-v3.2 并设置合适的 temperature、max_tokens、和 system prompt(比如"你是一位清晰、专业的内容编辑,给出要点式总结并加入发布时间")。
示例 prompt(传给模型的用户提示):
请基于以下表格生成一段不超过 300 字的热闻摘要,要求:
1. 概述每个平台上最热的 3 条内容(用 bullet 列出)
2. 每条后面标注平台和抓取时间
3. 最后给出 1 条行动建议(如转发、深入追踪或忽略)
表格数据:<插入 article_table>
抓取时间:<fetch_time>九、输出与交付
将模型生成的摘要内容与解析后的表格合并,生成统一的Markdown文档(包含标题、抓取时间、表格与 LLM 总结文本)。 随后通过Markdown 转换器插件,将 Markdown 文档转换为 PDF,用于存档、分享或二次分发。
建议在 Markdown 文档开头显式插入抓取时间,例如:
抓取时间:2025-12-23 14:30:00
以保证结果具备时间可追溯性。
总结
本文展示了一套可复用、可扩展的实战流水线,用于将掘金、B 站、微博、今日头条等多平台的新闻与帖子数据进行统一解析与聚合,并交由大语言模型生成结构化的热点摘要,最终导出为 Markdown / PDF 报告。
整套方案涵盖以下核心模块:
插件准备(数据抓取、模型调用与 Markdown 转换)、Studio 中的空白应用与条件分支设计、可复用的 Python 平台解析器(统一为 articles 表格结构)、变量聚合器(整合表格与元数据)、模型调用(示例:DeepSeek-V3.2)以及最终的 Markdown → PDF 输出。
实践中的关键经验在于:将平台差异封装在解析层、统一时间格式(UTC+8)、并将 prompt 模板与抓取时间作为显式变量传递,从而保证生成结果具备一致性、可审计性与长期复用价值。