kubernetes(简称k8s):
容器编排平台。对集群(多台机器)上的容器化应用程序进行自动化部署、扩展和管理。可自动更新、自动回滚、自动修复、可自动扩容等,根据声明式API自动完成相应操作。需会Linux命令和docker容器。
官方说明文档:https://kubernetes.io/docs/
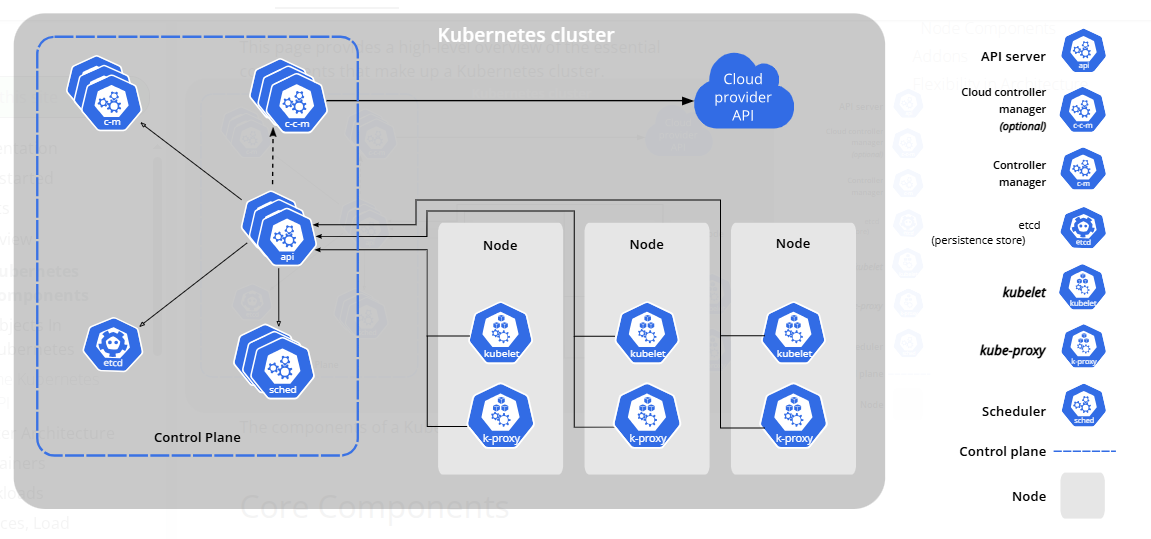
kubernetes集群有控制平面(Control Plane)和工作节点(Node)组成。控制平面是集群的大脑,负责全局决策和响应集群事件。工作节点是真正运行容器化工作负载的节点。一个控制平面或一个工作节点就是一个物理机或虚拟机。也有轻量版的单机集群(minikube,k3s,kind等)。
控制平面的组件:
- kube-apiserver:API server。集群的唯一入口。提供Kubernetes HTTP API(Restful API),与外部交互的接口。认证授权,处理请求,操作etcd。
- etcd:分布式键值存储系统。存储集群中所有关键数据(状态,配置信息,元数据)。不包括节点中应用程序的数据。
- kube-scheduler:调度器。将未绑定的pod分配到合适的节点。根据节点资源、调度策略等决策。
- kube-controller-manager:控制器。持续监测集群状态并自动将集群当前状态向用户期望状态调整。
- cloud-controller-manager:云服务控制器。与云服务交互的控制器。
节点的组件:
- kubelet:节点代理。持续监听API server并确保pod健康运行,管理容器的生命周期。
- kube-proxy:网络代理组件。维护网络规则,允许集群内外部与pod进行通信。
- container-runtime:容器运行时。负责运行容器(下载镜像,创建容器,启动容器,停止容器等)。
API server:
集群的入口。与用户交互的统一接口,用户可以使用命令行工具(kubectl)和其它UI工具等与API server交互通信。API server接收用户的请求,并处理请求,认证用户身份和权限等。保证了安全和简化了通信。
集群的中心枢纽。其它组件(例如:kube-scheduler, kubelet, kube-control-manager)持续监听API server,执行相应操作并向API server汇报结果(作为客户端向API server发送请求)。例如,kubelet监听API service,监测到pod被调度到本节点,kubelet就会调用容器运行时创建容器,持续关注容器状态,并向API service报告状态。
集群中唯一和etcd交互的组件。存储集群中所有状态的etcd,只能由API server操作(读写etcd中的数据),etcd也是API server唯一主动并直接交互的组件。保证了状态的安全和一致性。
etcd:
集群的数据库,存储集群内所有关键数据(状态、配置数据和元数据)。是分布式键值存储系统,即数据以键值对的形式存储在分布式集群中的数据库系统。
是唯一存储集群内所有资源状态(用户期望状态和当前状态)的组件。也是API server唯一主动并直接交互的组件。API service从etcd查询各资源的状态并更新新的状态,即只有API service可以读写etcd。
若集群宕机,重启时通过API service重新读取etcd的期望状态和当前状态,kube-controller-manager检测真实状态,若真实状态和存储的当前状态严重不符,则会根据期望状态和真实状态的差异,最终将实际运行状态重建到与期望状态一致的水平。
kube-control-manager:
观察当前状态(持续监听API server),分析当前状态与用户期望状态之间的差异,将当前状态朝着期望状态调整,确保当前状态和用户的期望状态保持一致。这种机制称为控制循环。
kube-control-manager是守护进程,运行着多个后台控制器,每个控制器都是一个独立的控制循环。而每个控制器管理着不同的功能,比如节点控制器管理节点的生命周期,监控和处理所有节点的状态。副本控制器管理pod副本数量和副本状态,端点控制器管理service和pod之间的正确关联。部署控制器管理deployment的状态更新,管理部署、滚动更新和回滚。还有命名空间控制器等。
例如:节点控制器(Node Controller)。kubelet检测自身节点的变化,向API service发送相应请求,API service根据请求做相应处理。kubelet也定期检测自身节点的健康状况,并将状态上报给API server。
节点控制器监听API service,关注节点状态以及标注的污点,结合容忍期处理不健康的节点,保证节点持续健康。比如在规定时间内以及等待时间内都没有收到节点的心跳,节点控制器会将节点标识为不健康,在一定时间会给节点添加污点,立即驱逐该节点上无法容忍该污点的pod(删除pod)并在健康的节点重建新的pod。
又例如:Endpoints Controller通过Endpoints对象维护Service和pod之间的关联,Endpoints对象中包含所有匹配pod的ip地址和端口列表。新版本中EndpointSice Controller功能类似但更高效,将大型的Endpoints对象拆分成更小的EndpointSlice对象中。
kube-scheduler:
调度器。确保各节点工作负载均衡,避免某节点过载或闲置。最大化利用集群资源。
持续监听API service,若有新创建的、未绑定的pod,则根据可用资源和调度策略,将pod调度到合适的节点运行。过程:先检查所有节点,排除内存不足或不能容忍节点污点等不合适的节点,再通过打分挑选分数最高的节点,则将pod绑定到该节点。
kubelet:
节点的代理。持续监听API service,执行相关操作并向其汇报状态,检测本节点是否健康并检测pod是否健康,管理节点内的pod生命周期。
检测本节点健康,主要检测节点资源(磁盘、内存、PID、网络等)、依赖服务(容器运行时、CNI网络插件等)。检测有两种:一是按照固定的时间间隔,向API service发送心跳证明自己存活,使用PATCH请求汇报。二是全面检查节点状态,定期向API service汇报状况,主要也是使用PATCH请求汇报。
检测节点内pod健康,通过探针来检测。有三种探针:一是启动探针,二是存活探针,三是就绪探针。启动探针用于启动较慢的应用,此时其他探针都禁用直到启动探针成功完成。存活探针通过HTTP请求、建立TCP连接、在容器内执行命令来检测pod是否存活着,若检测失败表示不存活则kubelet会重启容器。就绪探针也通过HTTP请求、建立TCP连接、在容器内执行命令来检测是否准备好接收流量,若没有准备好则上报给API service,从Service(API对象,不是API service)的Endpoints对象中移除pod,发往该Service的流量将不再路由到该pod。
管理pod生命周期,包括拉取镜像、创建容器、启动容器、停止容器、删除容器等。具体执行由container runtime完成。
container-runtime:
容器运行时。是实际操作容器的组件,即真正执行创建、运行、管理和销毁容器的组件。简言之,kubelet管理容器生命周期,但真正执行操作的是container runtime。附:运行时是指让程序运行所需的环境和引擎。容器运行时通常指高级运行时(包含完整功能的守护进程,负责从镜像拉取、存储管理到最终运行容器的全生命周期管理)。
kubelet通过CRI接口(标准gRPC接口)与容器运行时通信,通过高级运行时containerd或者CRI-O来实现CRI并负责完整的容器管理,高级运行时调用底层运行时runc(遵循OCI标准)执行具体的容器操作。例如:kubelet向containerd发送创建容器(若没有镜像则拉取镜像)并启动容器的命令,containerd拉取镜像、创建容器文件系统并调用runc,runc创建namespaces实现隔离、创建cgroups实现资源限制、启动容器进程。
kube-proxy:
网络代理组件。是实现Service抽象的关键。因为节点故障、滚动更新、扩缩容等原因,pod很容易创建和销毁,pod的IP地址也会随之改变,为了保持集群内部网络稳定,只需知道稳定的Service对象的IP地址或DNS名,而Service对象会负责分发到健康的pod上。
维护网络规则。为当前节点制定流量转发规则,使流量负载均衡到后端的pod。kube-proxy配置iptables/IPVS等底层网络设施来转发流量,不直接处理数据包。iptables模式中数据包完全由内核层iptables处理,但负载均衡算法单一(随机算法)。而Linux内核的IPVS模块专为负载均衡设计,适合大规模集群,但需要节点内核支持。
持续监听API service,若检测到Service对象新建、改变、删除或者Service对象的Endpoints对象发生变化等,kube-proxy立即更新本节点的网络规则。例如:新建Service对象的命令,kube-control-manager中的Endpoints/EndpointSlices-controller检测到新的Service,找到所有匹配的pod,创建同名的Endpoints/EndpointSlices对象,所有节点的kube-proxy检测到Service或ServiceEndpoints/EndpointSlices的创建事件,获取完整路由信息,并在本节点配置相应的iptables/IPVS规则。
简言之,**kube-control-manager中的Endpoints/EndpointSlices-controller维护Service和pod之间的关联,kube-proxy为本节点配置网络规则(流量转发规则),kubelet节点的代理、管理pod生命周期并网络规则的维护(基础网络设置),CNI插件保证底层网络通路的稳定。**而实现这些复杂的协作,除了具有匹配标签的pod,只需要一个声明式的文档--Service。
Service:
Service是一个声明式的文档,是访问pod的稳定抽象方式。
前面介绍过pod很容易销毁和重建,pod的ip地址也会改变,直接绑定pod就很容易出现问题,而Service是解决这种问题的方式。Service给内部其他组件或外部提供稳定的虚拟ip地址、稳定的DNS名和固定的端口,客户只需访问这个稳定的端口,Service就会通过其他组件(Kube-proxy, Endpoints-controller等)的协作自动将流量负载均衡到健康的pod。
Service的声明(YAML文件 )中内容主要包括Service的基础信息 (版本apiVersion、kind为Service、元数据metadata)、pod标签 (spec下的selector,定义需要匹配哪些pod)、端口 (spec下的port,定义如何将接受到的流量转发到pod)、类型(spec下的type,定义Service的暴露范围)等。类型有四种:CluserIP(默认,仅限集群内部)、NodePort(多用于开发、测试等,通过Node的IP和端口访问,默认端口范围30000-32767)、LoaderBalancer(用于云服务)、ExternalName(集群外部访问,例如网址)。其中,当访问集群外部而不是内部pod时则无需定义selector,需在文档内手动创建同名的Endpoints指定外部地址,但若直接使用类型ExternalName,可通过ExternalName指定外部域名。
| 无selector+手动Endpoints(外部地址) | 类型ExternalName(外部域名) |
|---|---|
apiVersion: v1 kind: Service metadata: name: external-api-service spec: ports: - port: (Service端口,例如80) targetPort: (外部服务端口,例如8080) apiVersion: v1 kind: Endpoints metadata: name: external-api-service subsets: - addresses: - ip: (外部服务的IP地址) ports: - port: (外部服务端口,与spec:ports:targetPort一致) |
apiVersion: v1 kind: Service metadata: name: external-db-service spec: type: ExternalName externalName: (外部域名,例如production.example.com) |
| [集群外部访问的Service举例] |
pod:
集群中最小可部署的计算单位。K8S调度的最小单位是pod而不是容器。一般不直接创建pod,而是通过更高级的资源Service或Deployment等来管理pod的声明周期。
一个pod里可以有一个或多个紧密关联的容器。大多数情况下一个pod运行一个容器。而如果是紧密关联的多个容器(应用程序、日志等)也可以在一个pod中,且多容器一起被创建一起被销毁,多容器的主要模式为Sidecar 模式。
pod有完整的生命周期(创建、销毁等)。pod有一个IP地址,但因为pod容易创建和销毁,IP地址会变化。一个pod内的容器共享网络、文件系统、资源等环境。使用标签来标记pod,便于Service中查找合适的pod。