参考课程:
李哥深度学习实战
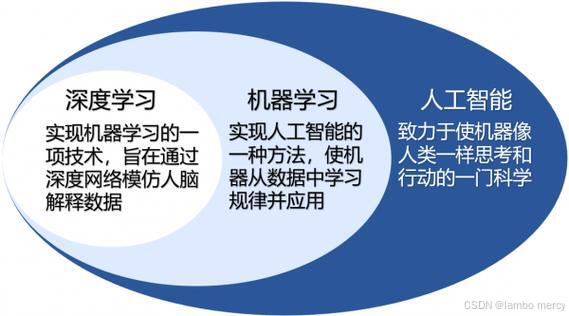
- 人工智能:机器展现的人类智能
- 机器学习:计算机利用已有的数据,得出了某种模型,并利用此模型预测未来的一种方法。
- 深度学习:实现机器学习的一种技术
生活中一个常见的例子:
当你打算注册一个账号,系统会弹出一个验证是否是真人的滑动框:
我们滑动对应拼图的时候是根据日常经验来完成的,那么对于机器来说他看到就是一个向量,想让他完成拼图就需要深度学习。现在的大模型都是几亿几百亿的参数,人的经验是有限的,而这些数据只要在合适的训练下可以被大模型迅速识别输出,这就是机器学习的优势。
机器学习
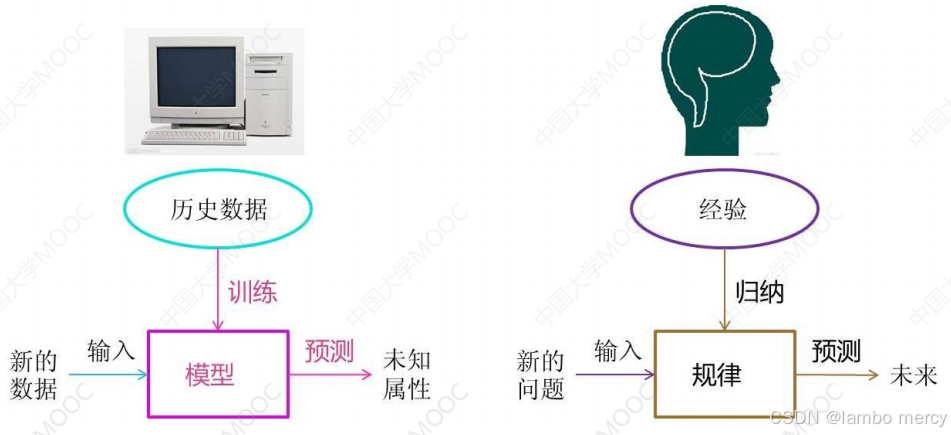
机器学习研究的是计算机怎样模拟人类的学习行为,以获取新的知识或技能,并重新组织已有的知识结构使之不断改善自身。
计算机从数据中学习出规律和模式,以应用在新数据上做预测的任务。
机器学习算法可以按照不同的标准来进行分类。比如
- 按函数的不同,机器学习算法可以分为线性模型和非线性模型;
- 按照学习准则的不同,机器学习算法也可以分为概率模型和非概率模型。
一般来说,我们会按照训练样本提供的信息以及反馈方式的不同,将机器学习算法大致分类为有监督学习、无监督学习和弱监督学习。(所谓的监督,你可以理解为一个标签) 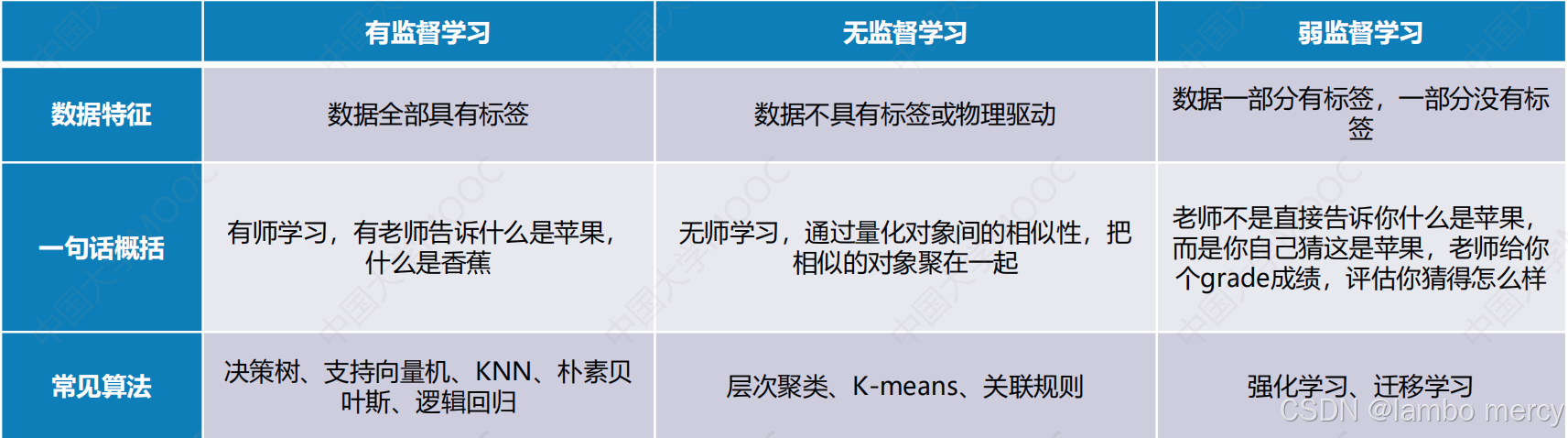
分类问题(监督学习) :
• 根据数据样本上抽取出的特征,判定其属于有限个类别中的哪一个
• 垃圾邮件识别(结果类别: 1 、垃圾邮件 2 、正常邮件)
• 文本情感褒贬分析(结果类别: 1 、褒 2 、贬)
• 图像内容识别(结果类别: 1 、喵星人 2 、汪星人 3、人类 4 、草泥马 5、都不是)
你可以看成是选择题。
回归问题(监督学习) :
• 根据数据样本上抽取出的特征,预测连续值结果
• 电影票房值
• 魔都房价具体值
• 刘德华和吴彦祖的具体颜值得分
你可以看成是填空题。
聚类问题 ( 无监督学习 ) :
• 根据数据样本上抽取出的特征,挖掘数据的关联模式
• 相似用户挖掘 / 社区发现
• 新闻聚类
强化学习 ( 弱监督学习 ) :
• 研究如何基于环境而行动,以取得最大化的预期利益
• 游戏 (" 吃鸡 ") 最高得分
• 机器人完成任务
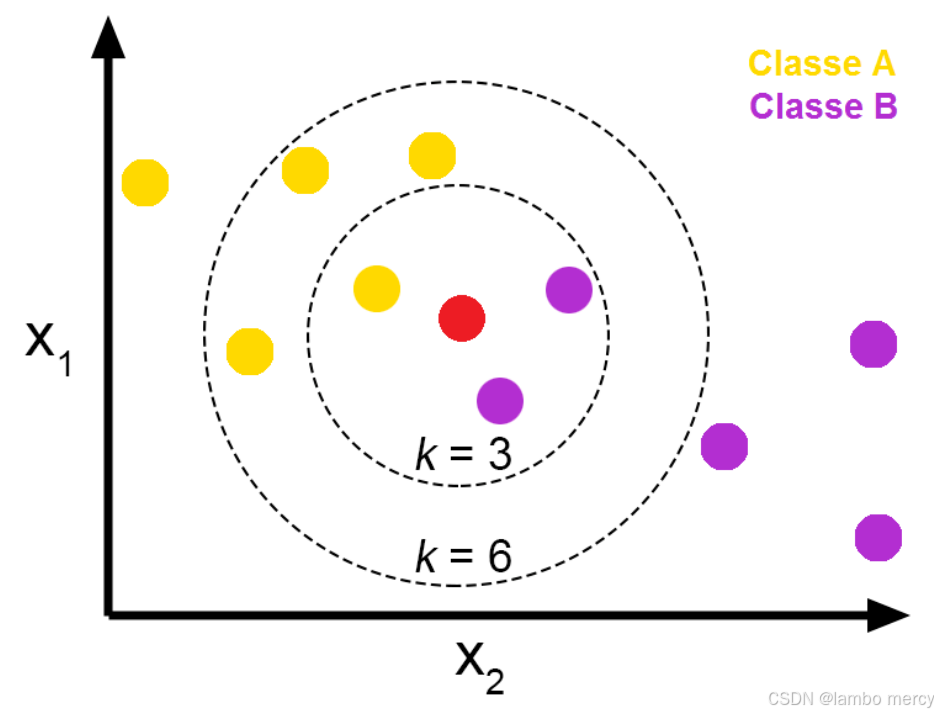
K最近邻居(K-Nearest Neighbors):
简称KNN,一种监督学习算法,用于分类和回归问题。它的基本思想是通过测量不同数据点之间的距离来进行预测。
现在要判断小明是清华的还是北大的取离他位置最近的 100 个人出来, 100 个都是北大的------推测小明来自北大
取离他位置最近的 100 个人出来, 89个都是清华的------推测小明来自清华
取离他位置最近的 200 个人出来, 111 个都是清华的, 89个北大的。------推测小明来自清华
取离他位置最近的 200 个人出来, 180个都是川大的。------推测小明来自清华或北大,但不能是川大,因为输出集中没有川大这个选项
" 近朱者赤,近墨者黑"
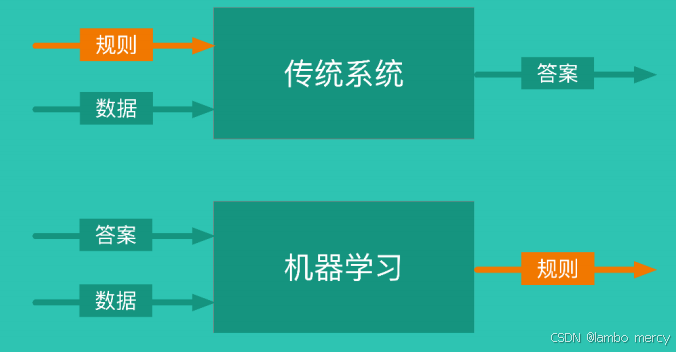
机器学习
机器学习,具有数学上的可解释性,但准确率不是百分百,且不灵活。
对于象棋来说,你可以使用多重if......else......循环来穷尽,这是传统的系统可以做到的。
但对于围棋来说ifelse是无法穷尽的,让你写一个程序实现是不可能的,如何让机器自己学习,这就是深度学习实现的机器学习。
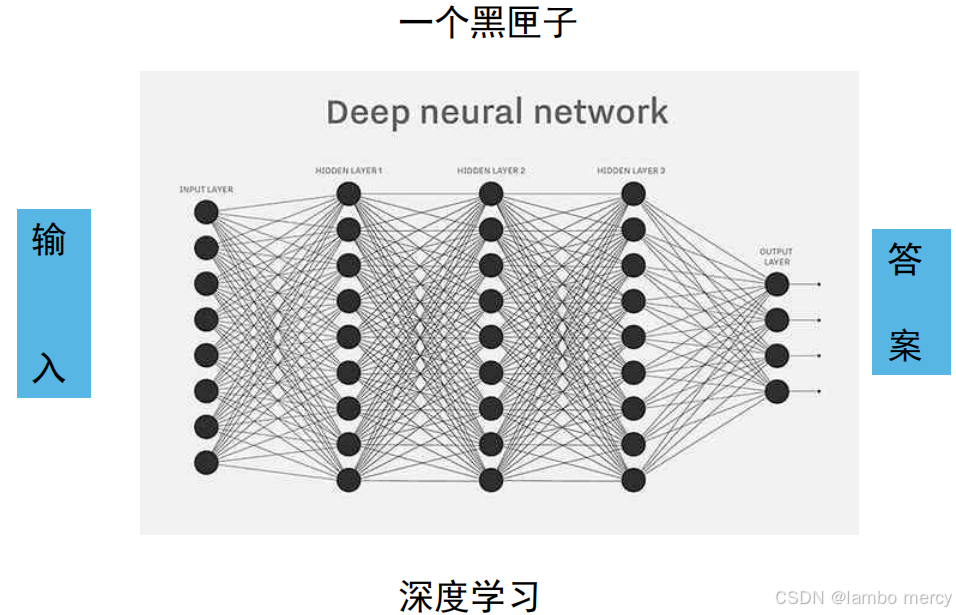
深度学习就是找一个函数f。
设计一个很深的网络架构让机器自己学。
他是怎么学的,我不知道,只要答案是对的,就没毛病,中间过程要多复杂有多复杂,但我不需要知道这个函数,这就黑匣子。
神经网络
常见的神经网络的输入, 一般有三种数据形式
1 : 向量:比如说一个人的身高、体重、财富( 180 , 140 , -1000)
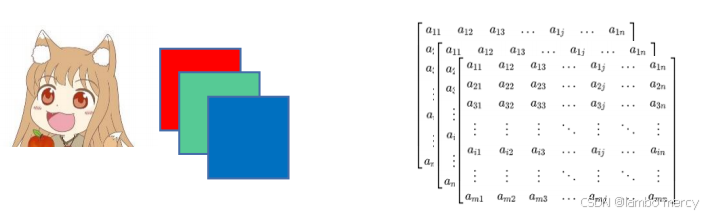
2 : 矩阵/张量 :一个像素点是RGB向量,一张照片就是一个矩阵
3 : 序列: **按时间顺序或特定顺序排列的数据,单个数据没有意义,必须是前后有关系的数据,**常见于自然语言、时间序列、音频、DNA序列等领域。
这是一张图片,第一个像素点是由(a11,b11,c11)组成
序列:但把"你"字拎出来是没有意义的,必须放到句子中,前后关系中才能推断出实际含义

输出 ( 任务类别 ) 一般也有下面几种:
1 : 回归任务(填空题): 根据以前的温度推测明天的温度大概有多高 。
2: 分类任务(选择题):判断图片: 猫/狗、分类时, 是用数字来表示类别,比如猫0/狗1
3:结构化任务(简答题):deepseek
根据种子的大小,重量等属性预测发芽概率------输入向量(大小、重量等)输出(回归任务)
根据视频生成字幕------输入序列(音频)输出(结构化任务)
自动填充代码。------输入序列(代码)输出(结构化任务)
判断图片中人物是谁。------输入矩阵(图片)输出(分类任务)
根据内容判断两部动漫是否为同一部。------输入序列(音频)输出(分类任务)
判断动漫声优是否为同一个人。------输入序列(音频)输出(分类任务)
判断淘宝商品的配图和文字标题是否是一致的?------输入序列(文字、图片)输出(分类任务)
圈出图片中的羊,并且识别为羊。------输入矩阵(图片)输出(圈出羊是回归任务、识别羊是分类任务)
根据车摄像头看到的画面,把人,路,车的轮廓准确的画出来。------输入矩阵(图片)输出(结构化任务)
ChatGPT------输入序列(文字描述)输出(结构化任务)
以上你已经对深度学习有了基本认识,你可以发现:分类和回归就是结构化的基础。
当你需要多个类型的数据时,就是多模态了,比如 图片, 文字, 声音
回归与神经元
大家都说深度学习需要数据,为什么? 因为要从数据中找到函数
如何从数据中找到想要的函数? 实践和认识的辩证运动:实践、认识、再实践、认识
如何开始深度学习?
第一步:定义一个函数f(模型)
第二步:定义一个合适的损失函数(loss)
第三步:根据损失函数,不断调整模型,优化模型
如何找一个函数呢?
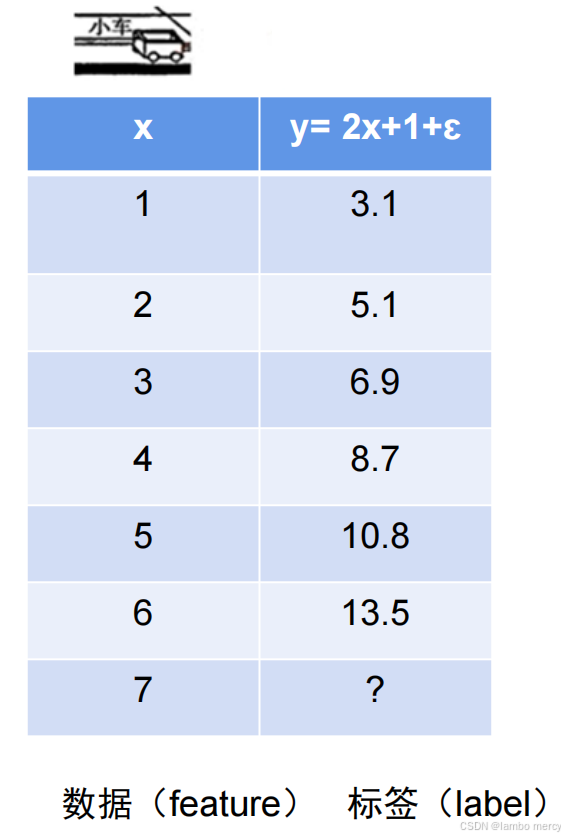
这是一辆小车,x表示时间,y表示当前速度,我们只有多组的(x,y)值,如何推断出y和x之间的函数关系?
我们可以先假设一个最简单的线性模型,通过调整权重和偏差来优化模型,优化的标准就是loss函数,如果预测的值和实际的值最接近,说明函数优化调整越接近真实函数。
Loss 就是这些未知参数的函数。
Loss: 判断我们选择的这组参数怎么样。
loss最小值就是优化最佳值
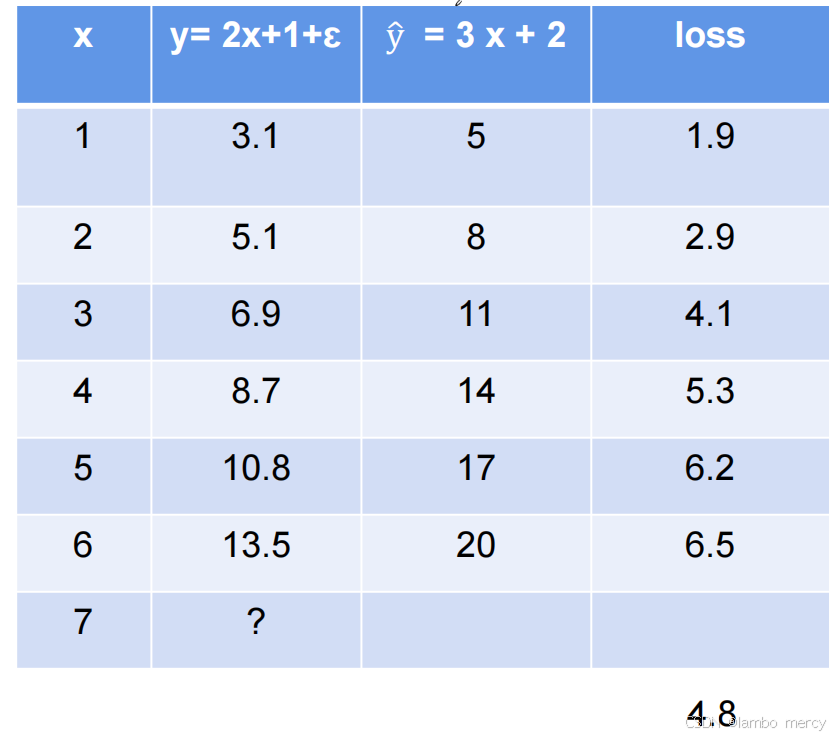
现在我们选取 𝑤 0 = 3、 𝑏 0 = 2 ,计算出每组数据对应的loss值,取平均得到的loss值为4.8,误差较大,需要优化

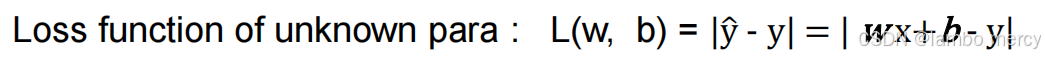
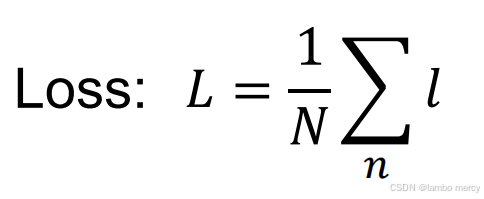
优化是盲目的取w和b吗? 求偏导
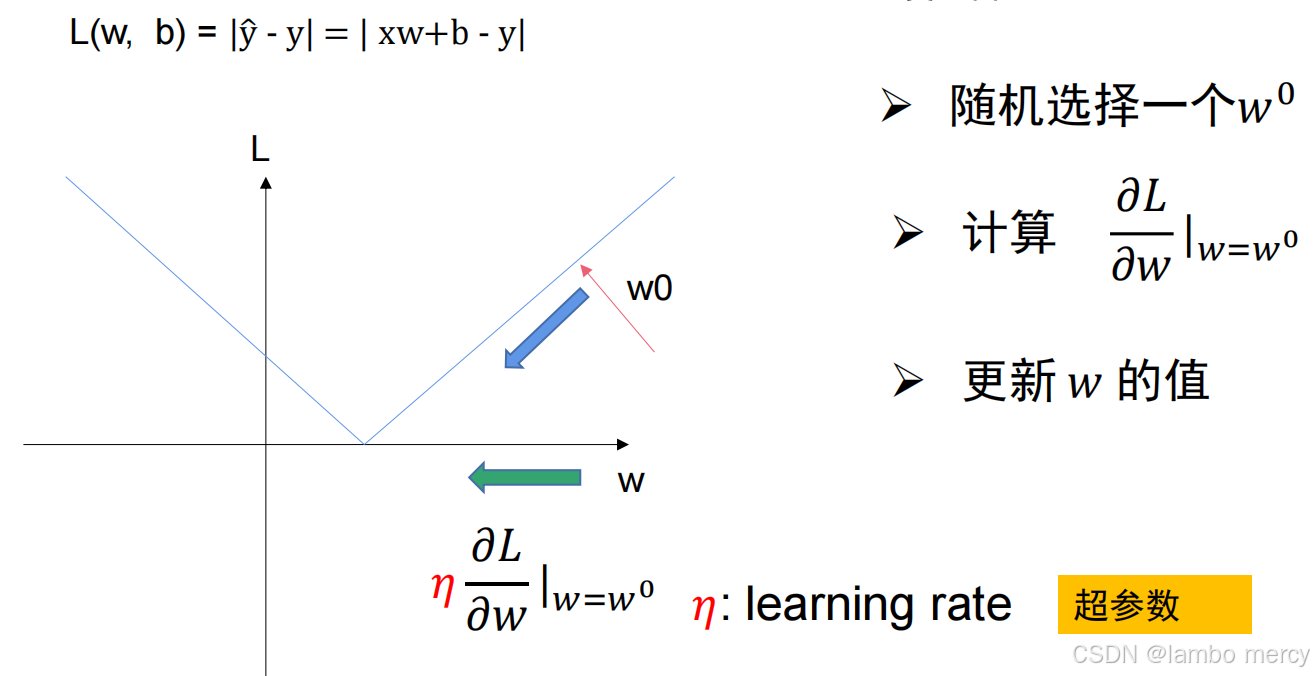
明确目标:我们要找的是loss最小值
如果求出来的偏导大于0,说明随着w的增大,loss随之增大,应该减小w
如果求出来的偏导小于0,说明随着w的减小,loss随之增大,应该增大w
在不断的尝试中,loss趋于最小,函数趋于最优解
w增大或者减小多少呢?
超参数是不变的,事先人为决定的

梯度大,移动的远,梯度小,移动的近
定义一个函数
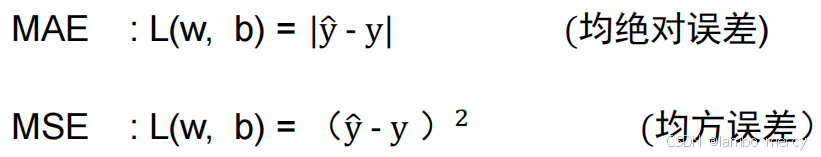
有 torch 框架可以帮我们自动计算。
(模型)
线性函数与多层神经元
现实中的问题,往往不是一个线性函数就能解决的,我们引入多层神经元
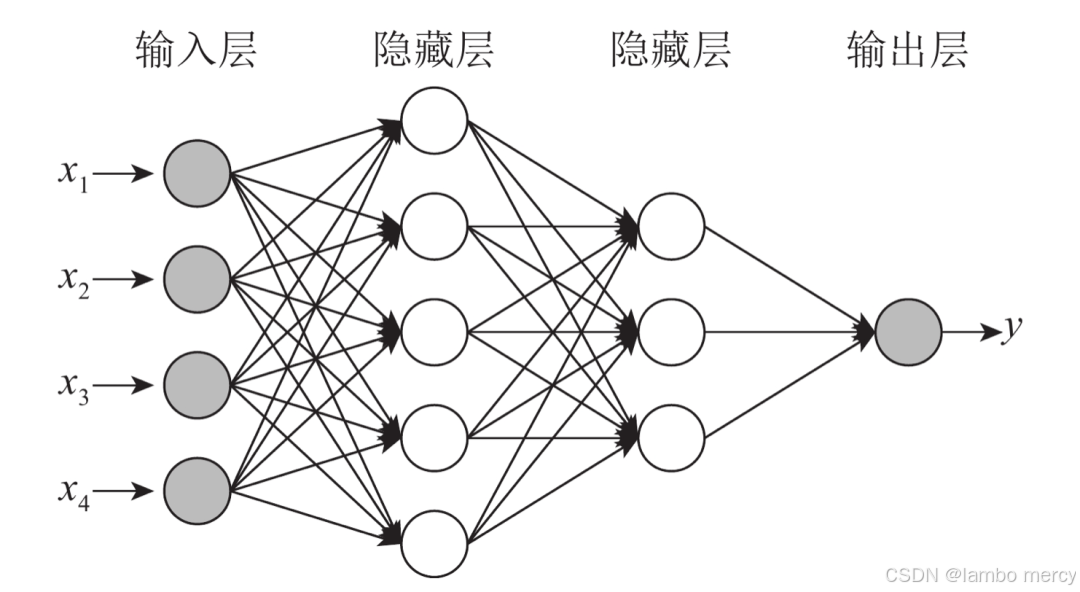
神经网络通常由多层神经元组成,主要分为输入层、隐藏层和输出层:
- 输入层(Input Layer):接收原始数据输入,每个输入节点对应数据的一个特征。
- 隐藏层(Hidden Layer):位于输入层和输出层之间的一层或多层神经元。隐藏层对输入进行非线性变换和特征提取,使得网络能够学习到更复杂的模式和表示。
- 输出层(Output Layer):输出层的节点产生最终的模型输出,通常对应任务的预测结果。例如,在分类任务中,输出层的节点表示各个类别的预测概率。