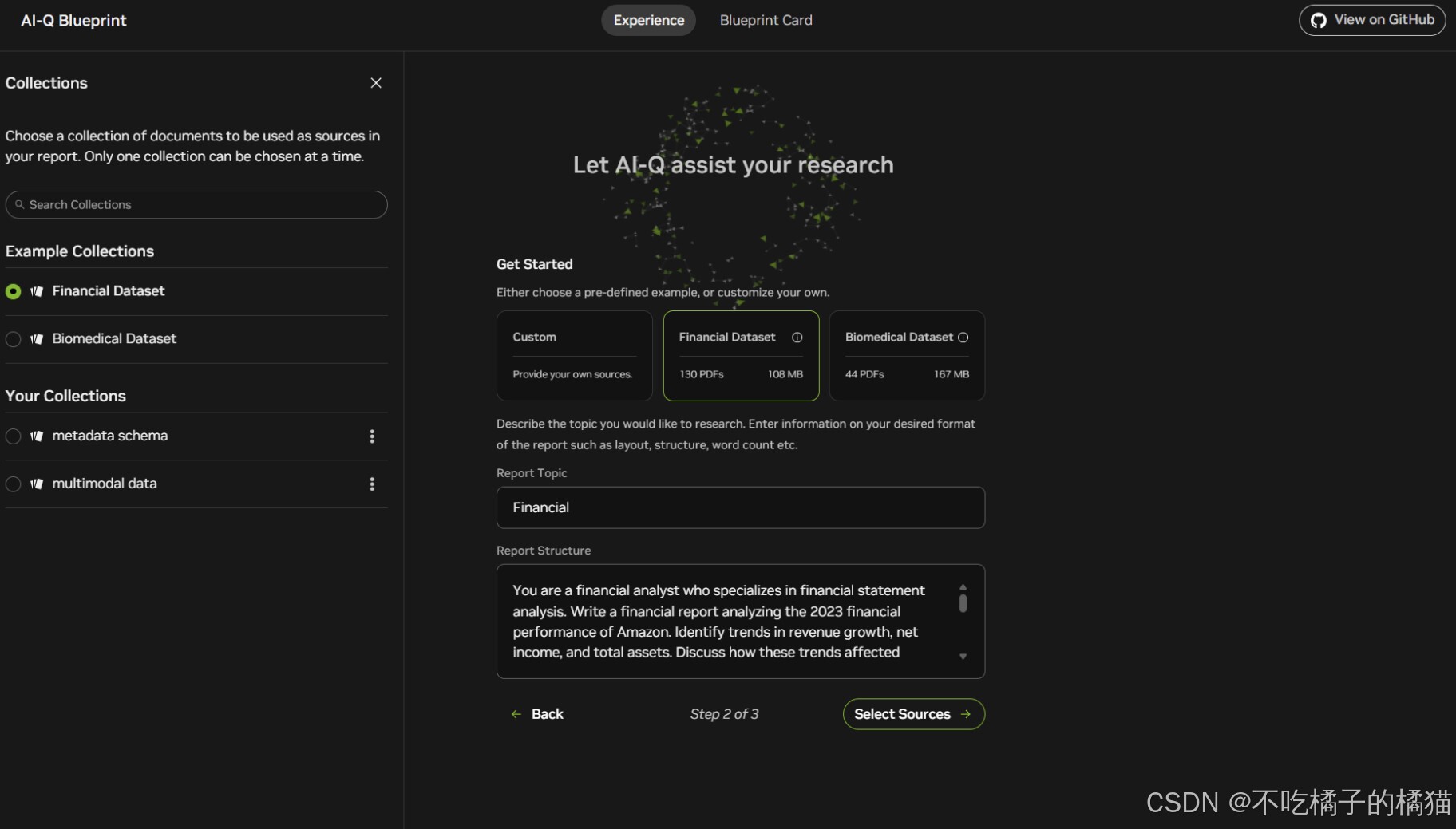
课程概要:
NVIDIA DLI 的课程《Build a Deep Research Agent》是一门自定进度的实践课程,课程内容为使用NVIDIA AI-Q Research Assistant Blueprint来构建并部署自己的深度研究代理。现代人工智能应用不仅仅是简单的问答------它们需要具备规划、推理、在多个来源中搜索以及综合生成全面报告等能力。这个课程讲的是从基础开始逐步部署一个完整的企业级深度研究系统。
课程链接:https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-FX-40+V1
页面如图所示:
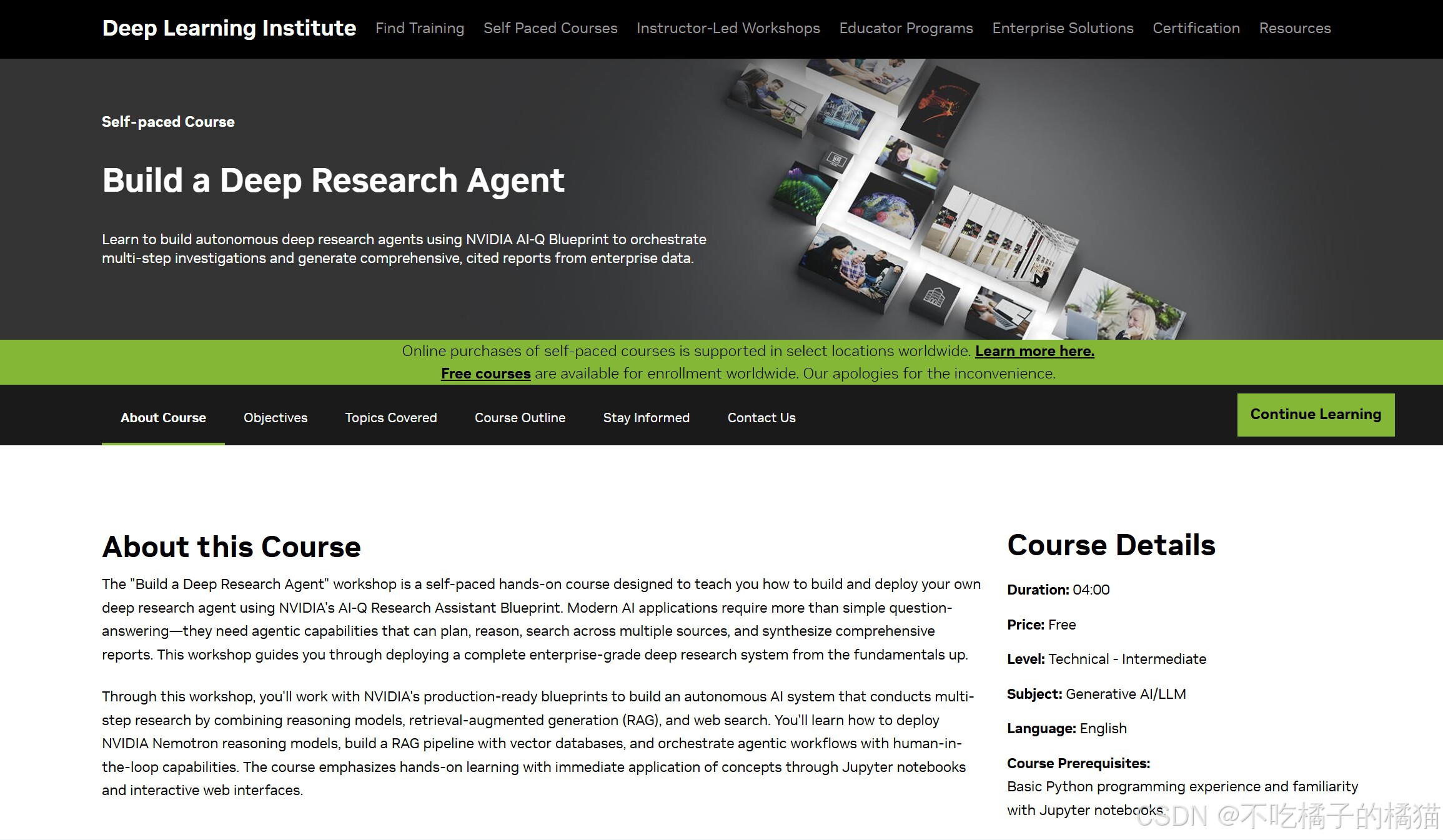
课程涵盖内容:
NVIDIA Nemotron reasoning models and test-time scaling
NVIDIA NIM (NVIDIA Inference Microservices)
Retrieval-Augmented Generation (RAG) architectureNeMo Retriever for embeddings and reranking
Milvus vector database for semantic search
NV-Ingest for multimodal document processing
Agentic workflows and human-in-the-loop systems
Tavily API for web search integration
Docker Compose for microservices orchestration
学习路径:
- 预备知识
(1)生成 NVIDIA NGC API 密钥(用于托管模型端点)
(2)生成 Tavily API 密钥(用于网络搜索功能)
- 部署推理 NIM
(1)理解 NVIDIA Nemotron 推理模型与 AI 智能体
(2) 探索推理 token 与测试时扩展概念
(3)通过 NVIDIA 托管端点部署并与推理模型交互
(4)比较启用与未启用推理的响应差异
(5)学习如何本地/本地化部署 NIM
- 部署 RAG
(1)理解 RAG 基本原理及其如何应对 LLM 限制
(2)部署完整的 RAG 系统(含向量数据库与数据摄取服务)
(3) 处理多模态文档(文本、表格、图像)
(4)学习文档摄取、检索与重排序 API
(5)比较启用与未启用知识库的响应差异
- 部署深度研究智能体
(1)理解深度研究与传统搜索及简单 RAG 的区别
(2)部署 NVIDIA AI-Q 研究助手蓝图
(3)创建带人工审批流程的研究计划
(4)并行检索 RAG 与网络来源
(5)生成带引用与来源标注的全面报告
(6)通过对话式问答与迭代编辑优化报告
小测验:

在 NVIDIA Nemotron 模型中,启用"推理令牌"(reasoning tokens)的主要目的是什么?
答:在生成最终答案前,启用逐步思考能力。
解析:推理令牌让模型在输出答案前先"写下"自己的思考过程(如分析问题、列出步骤、验证逻辑),类似于人类解题时的草稿纸。这种方式显著提升了复杂任务(如数学、逻辑推理)的准确率,尽管会增加计算开销。

检索增强生成(RAG)主要解决什么问题?
答:使大语言模型能够访问其训练数据之外的最新和领域特定信息。
解析:大模型的知识截止于训练时间,且无法访问企业私有数据,还容易"幻觉"编造信息。RAG 通过实时检索外部文档,将真实、相关的信息注入生成过程,有效缓解这些问题,提升回答的准确性与时效性。
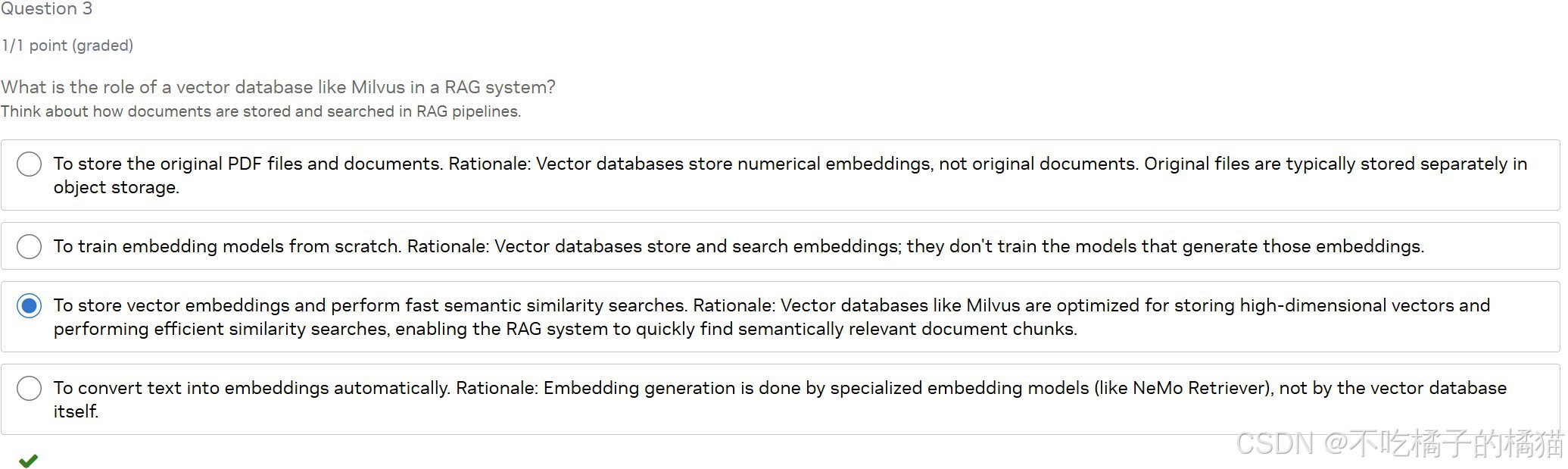
像 Milvus 这样的向量数据库在 RAG 系统中的作用是什么?
答:存储向量嵌入,并执行高效的语义相似性搜索。
解析:向量数据库专为高维向量设计,支持快速近似最近邻(ANN)搜索。在 RAG 中,它保存所有文档片段的嵌入向量,当用户提问时,系统将问题也转为向量,并在数据库中查找语义最接近的文档块,作为生成答案的依据。

AI 智能体(agent)与普通聊天机器人的主要区别是什么?
答:智能体能够自主规划、使用工具、保持上下文,并迭代完成任务。
解析:普通聊天机器人通常是"问-答"模式,被动响应;而 AI 智能体具备主动性:它能拆解复杂目标、调用搜索/代码/数据库等工具、记忆对话历史、自我反思并修正策略,像一个"数字研究员"一样持续工作直至任务完成。
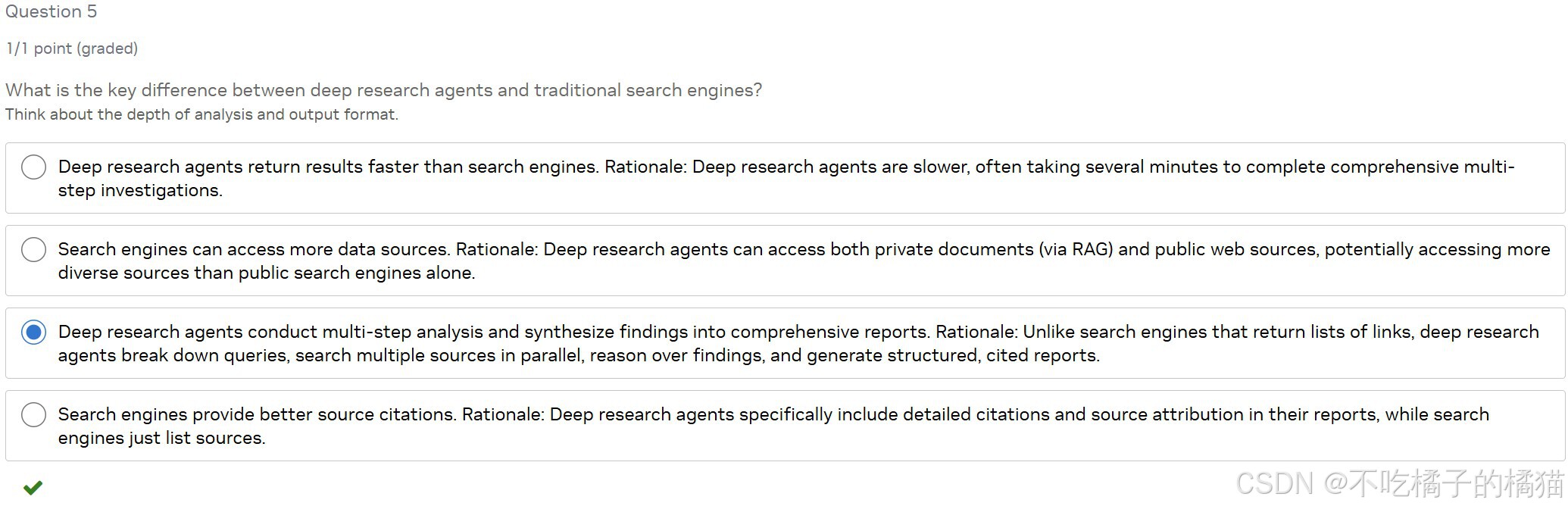
深度研究智能体(deep research agents)与传统搜索引擎的关键区别是什么?
答:深度研究智能体能进行多步骤分析,并将发现整合成综合报告。
解析:传统搜索引擎返回的是网页链接列表,而深度研究智能体会主动分解复杂问题、并行调用多个信息源、交叉验证内容、推理逻辑关系,最后生成结构清晰、带引用的完整报告,实现"思考+写作"一体化。

在两阶段 RAG 检索过程中,重排序(reranking)的目的是什么?
答:通过深入分析每个文本块与具体查询的相关性,提升检索结果的相关性。
解析:第一阶段通常用向量数据库做快速初筛(基于语义相似度),但可能不够精准。重排序阶段使用专门的模型(如交叉编码器)对候选文本逐个评估其与问题的匹配程度,重新排序,确保最相关的内容排在前面,提高最终回答质量。
在 AI-Q 研究助手的上下文中,"人在环路"(human-in-the-loop)是什么意思?
答:用户可以在执行开始前审查、编辑并批准研究计划。
解析:AI-Q 会先生成一个初步的研究计划,但不会立即执行。用户可以查看该计划,根据自己的专业判断进行修改或确认,确保后续的自动研究符合实际需求。这种设计增强了可控性和准确性,是"人在环路"的典型体现。

在 RAG 系统中,嵌入模型(embedding model)的主要作用是什么?
答:将文本转换为能够捕捉语义含义的数值向量。
解析:嵌入模型把文字(如句子或段落)映射到高维向量空间中,使得语义相近的内容在向量空间中距离更近。这样,RAG 系统就能通过计算向量相似度,快速从大量文档中找出与用户问题最相关的片段。
为什么 AI-Q 研究助手同时使用 RAG 检索和网络搜索(Tavily)?
答:为了结合企业内部知识与最新的外部信息。
解析:RAG(检索增强生成)能访问企业私有文档库(如内部报告、数据库),而 Tavily 等网络搜索工具可获取公开、实时的信息(如新闻、论文)。两者结合,既保证了数据的专属性,又确保了时效性和广度,从而生成更全面、可靠的分析结果。

NVIDIA NIM(NVIDIA 推理微服务)提供什么?
答:用于部署经过优化的 AI 模型的预构建容器,并提供标准化 API。
解析:NVIDIA NIM 是一种容器化的微服务解决方案,将 AI 模型(如 Nemotron、嵌入模型、重排序模型等)与其优化后的推理引擎打包在一起,并通过与 OpenAI 兼容的 API 提供服务。这大大简化了企业级 AI 模型的部署流程,无需从头搭建推理环境。
实验部分:
部署部分:
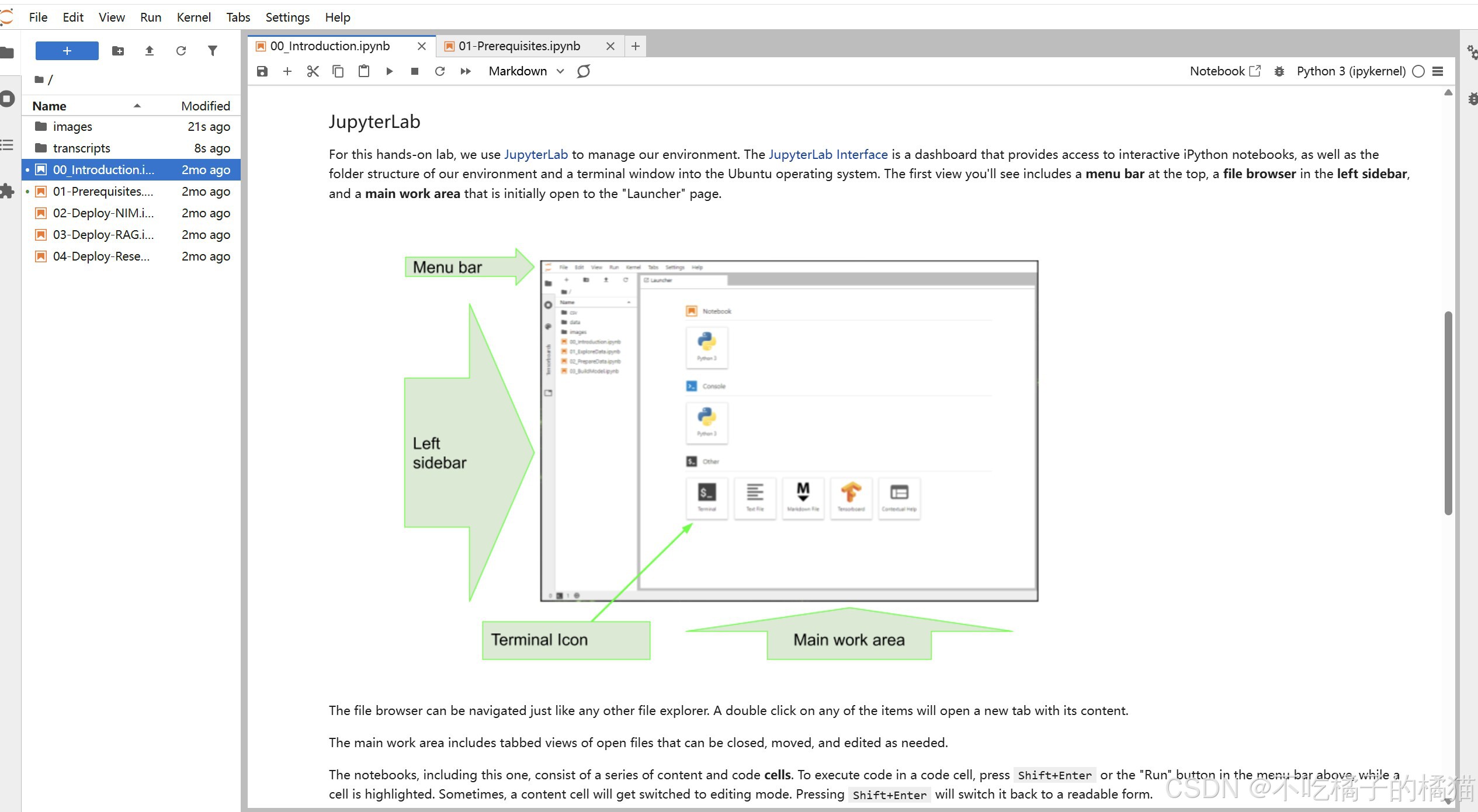
页面介绍如图,用 JupyterLab 来管理环境。JupyterLab 界面是一个仪表板,它能让你访问交互式的 iPython 笔记本,同时还能显示我们环境的文件结构以及进入 Ubuntu 操作系统的终端窗口。对任何项目进行双击操作后,将会打开一个新标签页并显示其内容。 主要的工作区域包含可展开显示的打开文件的标签视图,这些文件可以随时关闭、移动和编辑。 这些笔记本由一系列的内容单元格和代码单元格组成。要在代码单元格中执行代码,请按 Shift+Enter 键或者在上方菜单栏中的"运行"按钮上进行操作,同时要确保该单元格处于被选中的状态。有时,一个内容单元格会切换到编辑模式。按 Shift+Enter 键会将其切换回可读形式。
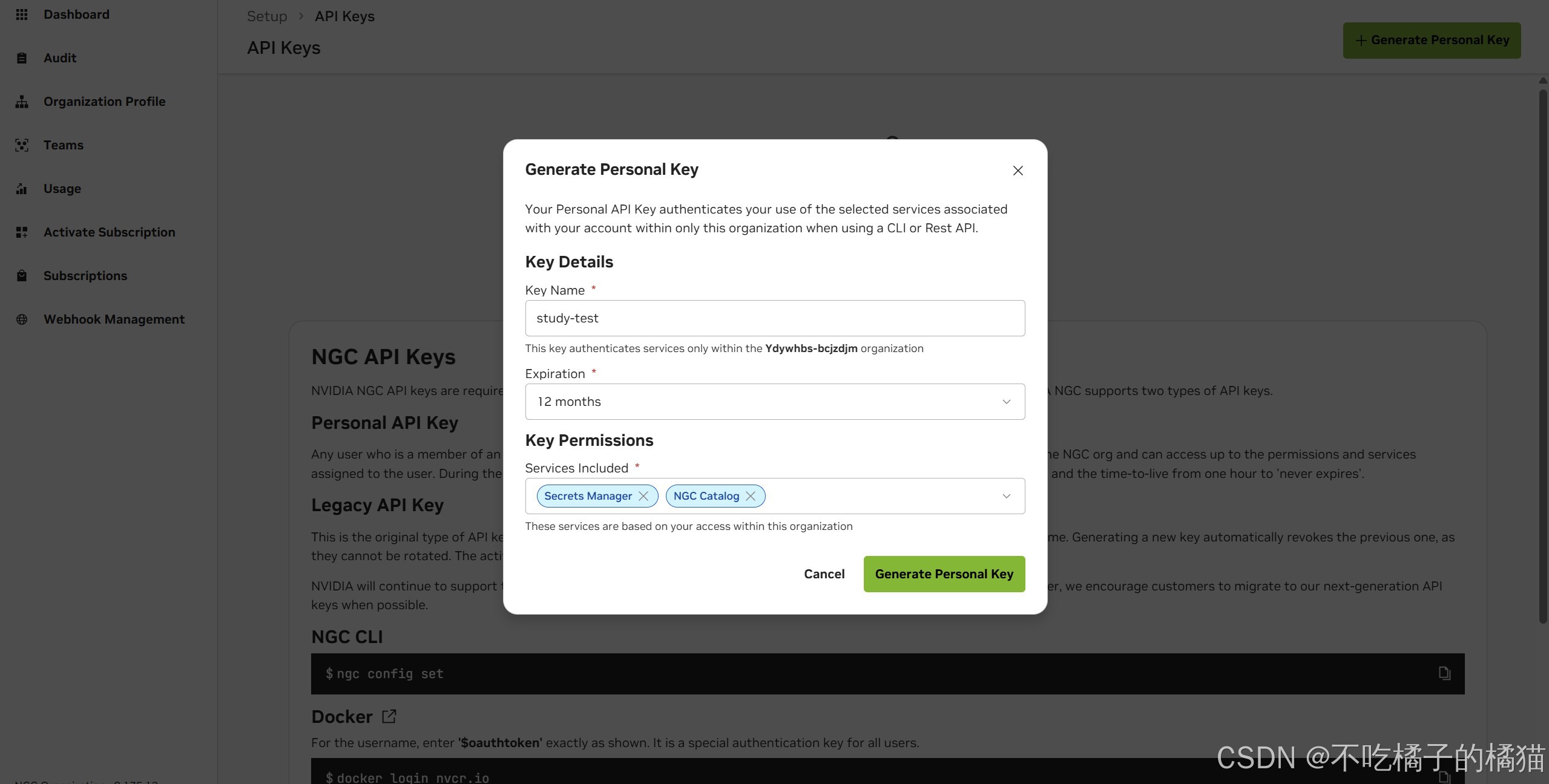
创建API密钥,通过 NVIDIA NGC 平台生成此密钥。
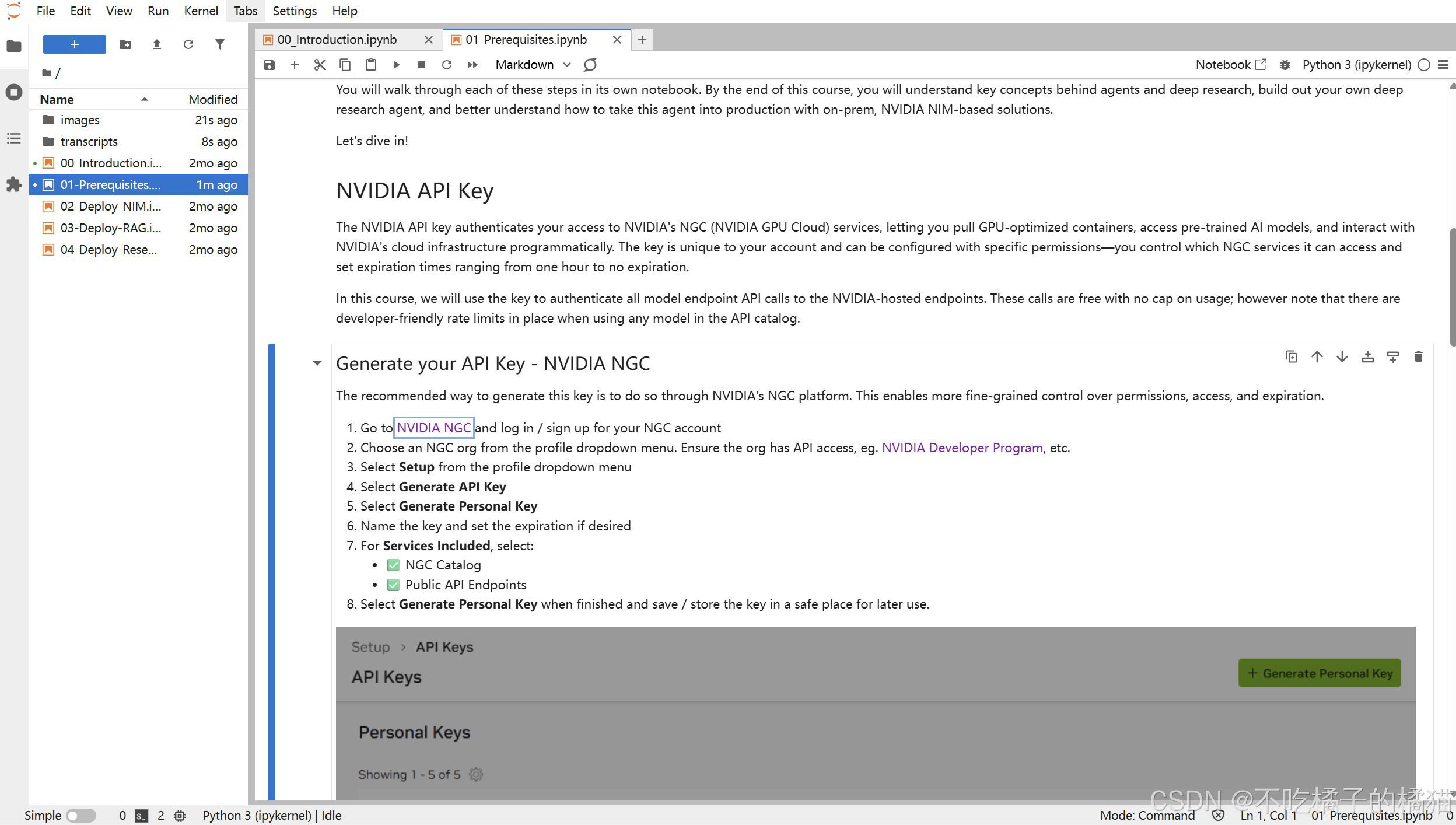
具体步骤:
1.前往NVIDIA NGC网站,登录/注册NGC账户'
2.从个人资料下拉菜单中选择一个NGC组织。确保该组织具有API访问权限,例如NVIDIA开发者计划等;
3.从配置文件下拉菜单中选择设置;
4.选择生成API密钥;
5.选择生成个人密钥;
6.指定密钥并设置有效期;
7.对于所包含的服务,选择NGC目录,公共API 端点;
8.完成操作后,生成个人密钥,然后将该密钥保存在安全的地方以备日后使用。
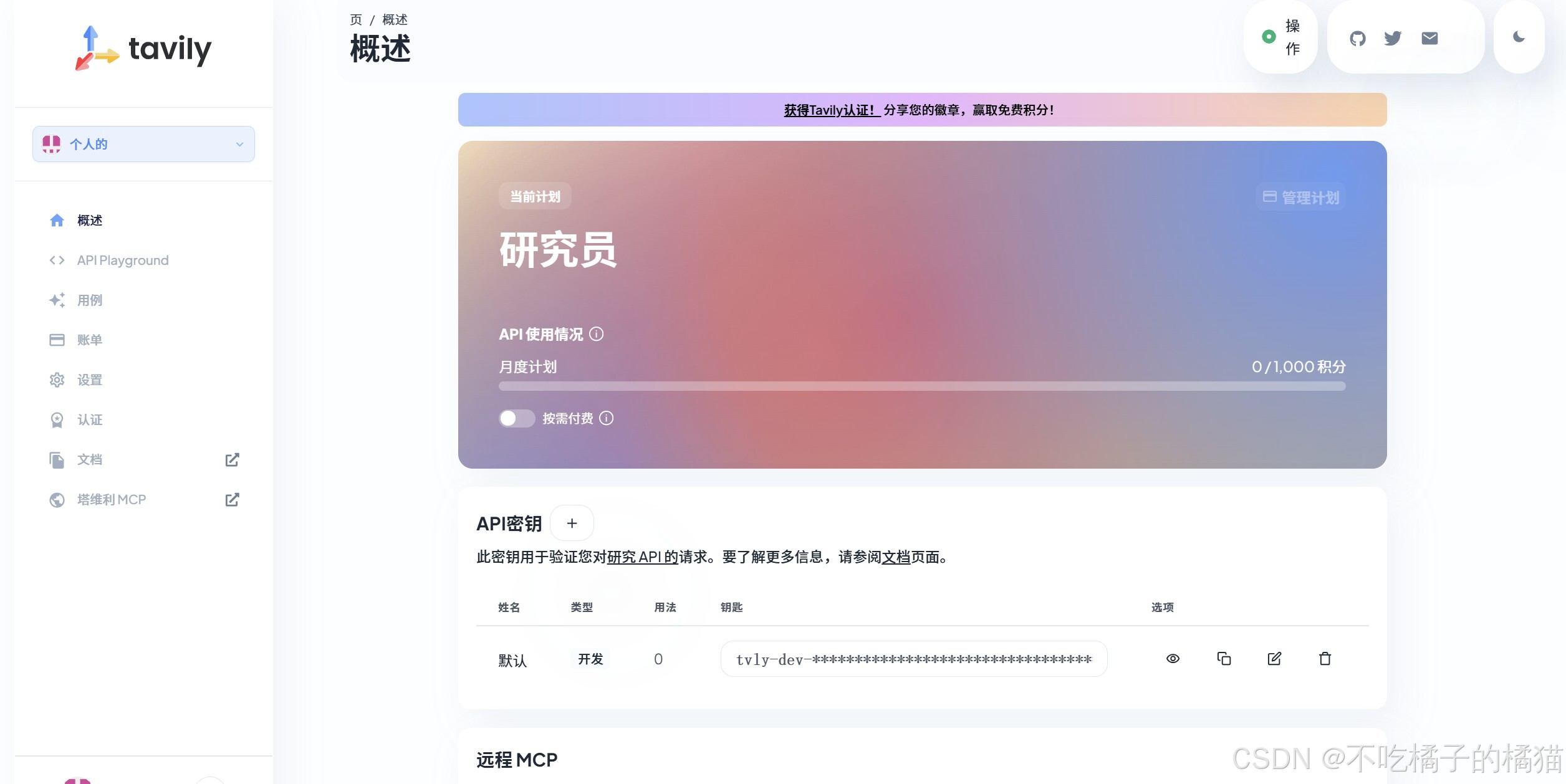
生成Tavily API key
1.访问https://www.tavily.com/,然后创建一个免费账户;
2.在主页上,点击"API密钥"旁边的加号按钮,生成一个密钥;
3.保存并存储此密钥,以便日后使用。
Nemotron 的特别之处
1.强大的推理能力:与直接生成答案的标准 LLM 不同,Nemotron 推理模型在给出最终答案前会进行显式的推理过程。
2.开源许可:采用宽松许可证发布,支持在任意环境部署------从云端到本地基础设施均可。
3.企业就绪:通过 NVIDIA NIM 微服务进行生产级优化,便于部署和扩展。
4.智能体工作流优化:特别针对智能体系统进行了调优,在这类系统中,模型需要具备规划、推理和执行复杂任务的能力。
AI 智能体
AI 智能体是一种自主系统,能够:
1.感知环境(接收用户查询、数据或工具返回结果等输入)
2.推理应采取的行动
3.执行决策(生成回复、调用 API、使用工具)
4.从反馈中学习,持续改进或迭代
与仅能提供一次性回复的简单聊天机器人不同,智能体可以:
1.将复杂问题拆解为多个步骤,并制定行动计划;
2.调用外部工具(如计算器、数据库、搜索引擎);
3.在多轮交互中保持上下文(支持人工介入);
4.通过自我反思逐步构建更稳健的回答;
5.在出错时进行自我修正;
Reasoning Tokens推理标记
当模型使用推理标记时,它会:
1.生成内部推理过程(即"思考"步骤)
2.得出结论(即最终答案)
3.根据用户偏好,可选择向用户展示完整推理轨迹,或仅显示最终答案
| Without Reasoning Tokens | With Reasoning Tokens |
|---|---|
| Model jumps to conclusions single-shot | Model thinks step-by-step |
| Higher error rates on complex problems | Better accuracy through deliberation |
| Cannot self-correct during generation | Can identify and fix mistakes mid chain-of-thought |
| Limited multi-step problem solving | Excels at dynamic planning and execution |
为什么 /think 很重要?
系统消息 /think 至关关键------它告诉 Nemotron 模型使用推理标记(reasoning tokens)。
如果不加 /think,模型会直接给出答案(可能出错),如果加上 /think,模型会展示其逐步推理过程,从而大幅提高准确性。
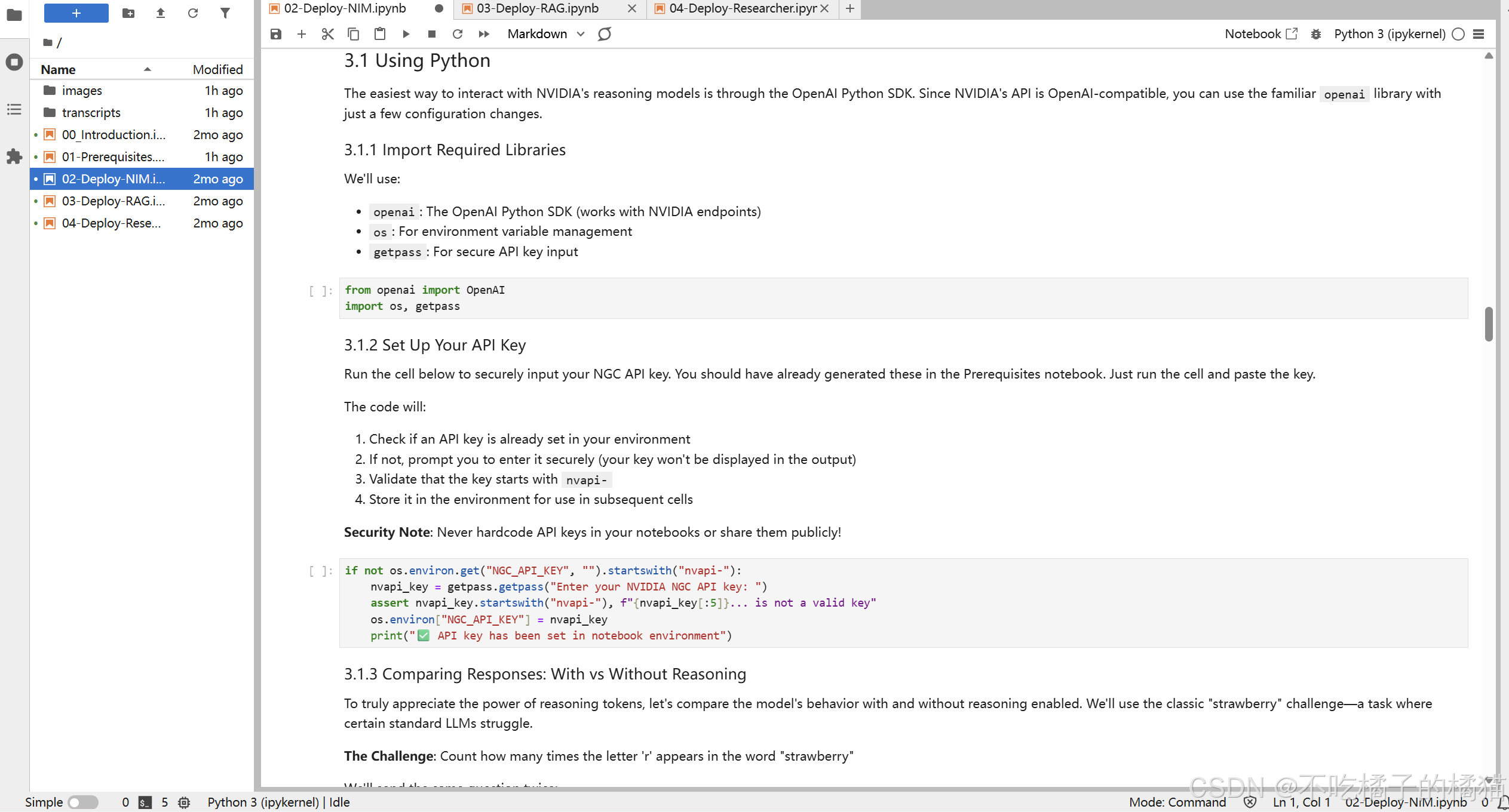
创建启用推理的补全请求
python
completion_with_reasoning = client.chat.completions.create(
model="nvidia/llama-3.3-nemotron-super-49b-v1.5",
messages=[
{"role":"system", "content":"/think"}, # 启用推理模式
{"role":"user", "content":"单词 'strawberry' 中有多少个字母 'r'?"}
],
temperature=0.6,
top_p=0.95,
max_tokens=65536, # 增大以容纳推理过程产生的额外 token
stream=True
)重要参数:
| Parameter | Value | Purpose |
|---|---|---|
messages[0] |
"/think" |
Activates reasoning mode - tells the model to show its thinking process |
temperature |
0.6 |
Moderate creativity (higher = more creative, lower = more focused) |
top_p |
0.95 |
Considers top 95% probability tokens (nucleus sampling) |
max_tokens |
65536 |
Allows very long responses (important for reasoning, which can be verbose) |
stream |
True |
Returns response incrementally, like ChatGPT's typing effect |
| 参数 | 值 | 用途 |
|---|---|---|
messages[0] |
"/think" |
激活推理模式 ------ 告诉模型展示其思考过程 |
temperature |
0.6 |
中等创造性(值越高越有创意,越低越聚焦) |
top_p |
0.95 |
采用核采样(nucleus sampling),仅考虑累计概率前 95% 的 token |
max_tokens |
65536 |
允许非常长的回复(推理过程通常较冗长,需更大空间) |
stream |
True |
逐 token 返回响应,实现类似 ChatGPT 的"打字"效果 |
当设置了 stream=True的时候,模型会在生成每个 token 时立即返回。以下循环处理每个数据块(chunk),这样子我们就完成了流式输出显示响应。
python
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
# chunk.choices[0] accesses the first (and usually only) completion choice
# .delta.content contains the new text fragment for this chunk
# end="" prevents newlines, creating a smooth streaming effect未启用推理和启用推理有几个重要差异:
- 回答质量
未启用推理:模型可能直接跳到结论,给出错误答案(常误答为 "2" 而非 "3")
启用推理:模型会逐个字母仔细计数,反复检查,最终得出正确答案("3")
- 透明度
未启用推理:只能看到最终答案,无法了解其推导过程
启用推理:可清晰看到模型的逐步思考逻辑,便于发现错误、建立信任
- 自我修正能力
未启用推理:若中途出错,无法回溯或纠正
启用推理:模型常会在思考过程中自我复核,并主动修正错误
- 回答长度
未启用推理:非常简洁,通常只有几个 token
启用推理:因包含显式推理步骤而更长,但可靠性显著提升
为何这对 AI 智能体至关重要?
AI 智能体需要做出复杂决策,通常涉及多个步骤和工具调用。推理标记(reasoning tokens)使智能体能够:
1.行动前先规划:思考完成目标所需的步骤
2.自我调试:识别即将犯的错误并提前规避
3.解释决策:在高风险场景中提供透明、可审计的推理链
4.处理复杂性:系统性地拆解多步骤问题
stream true与false
流式响应("stream": true)示例:
python
data: {
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1234567890,
"model": "nvidia/llama-3.3-nemotron-super-49b-v1.5",
"choices": [{
"index": 0,
"delta": {
"content": "Let"
},
"logprobs": null,
"finish_reason": null
}]
}
data: {
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1234567890,
"model": "nvidia/llama-3.3-nemotron-super-49b-v1.5",
"choices": [{
"index": 0,
"delta": {
"content": "'s"
},
"logprobs": null,
"finish_reason": null
}]
}
...
data: [DONE]非流式响应("stream": false)示例:
python
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1234567890,
"model": "nvidia/llama-3.3-nemotron-super-49b-v1.5",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "字母 'r' 在单词 'strawberry' 中出现了 3 次......"
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 25,
"completion_tokens": 150,
"total_tokens": 175
}
}响应说明:
finish_reason:模型停止生成的原因
"stop":自然结束(模型认为回答已完成)
"length":达到 max_tokens 限制
usage:token 使用统计,用于计费和监控
prompt_tokens:输入提示所用 token 数
completion_tokens:模型生成内容所用 token 数total_tokens:总 token 消耗量
只需修改 OpenAI SDK 的 base_url 即可使用本地端点。
python
from openai import OpenAI
client = OpenAI(
base_url="http://0.0.0.0:8000/v1", # 本地端点
api_key="not-needed-for-local" # 本地部署通常无需认证
)
completion = client.chat.completions.create(
model="nvidia/nvidia-nemotron-nano-9b-v2",
messages=[
{"role": "system", "content": "/think"},
{"role": "user", "content": "写一首关于 GPU 计算之妙的五行打油诗。"}
],
stream=True
)| 方面 | NVIDIA 托管服务 | 本地部署 |
|---|---|---|
| 基础 URL | https://integrate.api.nvidia.com/v1 |
http://0.0.0.0:8000/v1 |
| 身份验证 | 需要 Authorization: Bearer $NGC_API_KEY |
无需认证(由您的网络环境保障安全) |
| 延迟 | 取决于网络位置 | 极低(仅限本地网络) |
| 成本 | 免费额度后按用量计费 | 仅硬件成本 |
当需要数据始终停留在内部,对响应要求很高,需要绕过API调用频率限制,离线访问,自定义配置时推荐本地部署。
检索增强生成(Retrieval-Augmented Generation, RAG)
检索增强生成(RAG)是一种强大的 AI 架构,它将大语言模型(LLM)的推理能力与访问外部知识源的能力相结合。与仅依赖训练期间所学知识的传统模型不同,RAG 系统在生成回答前,会先从文档、数据库或知识库中检索相关的上下文信息。
| 局限性 | 传统 LLM 的问题 | RAG 如何解决 |
|---|---|---|
| 静态预训练知识 | LLM 的知识在其训练截止日期后即被"冻结",无法获取新信息,除非进行昂贵的重新训练。它们不了解训练之后发生的事件、新产品或新进展。 | RAG 能实时从更新后的知识库中检索最新信息,无需重新训练模型即可访问当前数据。 |
| 无法访问私有/专有数据 | LLM 仅了解其公开训练数据中的内容,无法访问公司内部文档、政策、客户记录或专有数据库。 | RAG 可连接到您的私有文档存储、数据库和知识库,使 LLM 能基于组织特有的数据生成回答。 |
| 幻觉与事实错误 | 当 LLM 不知道答案时,常会基于训练数据中的模式生成看似合理但错误的信息(即"幻觉")。 | RAG 通过引用检索到的源文档来生成回答,大幅减少幻觉,并提供可验证的事实依据。 |
| 缺乏来源引用 | 传统 LLM 通常在不标注来源的情况下生成答案,难以验证信息或追溯知识出处。 | RAG 系统会返回用于生成回答的源文档,实现完全透明,便于事实核查。 |
| 领域专业知识不足 | 通用 LLM 在法律、医疗、工程等专业领域可能缺乏深度知识,或使用过时术语。 | RAG 从领域特定的知识库中检索信息,利用专家整理的专业内容生成准确回答。 |
| 上下文窗口限制 | LLM 具有固定的上下文长度,无法一次性处理整个文档库或大型知识库。 | RAG 利用语义搜索,仅检索最相关的信息片段,高效处理远超上下文窗口容量的海量知识库。 |
混合部署模式 部署 NVIDIA RAG:
NVIDIA 托管 NIM:使用 NVIDIA 提供的免费、GPU 加速端点运行计算密集型模型
本地 Docker 容器:在本地运行支撑性基础设施
为何采用此混合模式?
| 组件 | 运行位置 | 原因 |
|---|---|---|
| Milvus 向量数据库 | 本地(Docker) | 您的数据保留在自有基础设施中 |
| Ingestor 与 RAG 服务器 | 本地(Docker) | 编排逻辑靠近数据,降低延迟 |
| 嵌入/重排序 NIM | NVIDIA 托管端点 | 免费使用 GPU 加速,无需本地 GPU |
| 文档处理 NIM | NVIDIA 托管端点 | 免费 GPU 加速,简化部署 |
| Nemotron LLM | NVIDIA 托管端点 | 无需自建基础设施即可使用强大推理模型 |
混合模式特别适合快速开发与原型验证 ,尤其在计算资源有限的情况下。
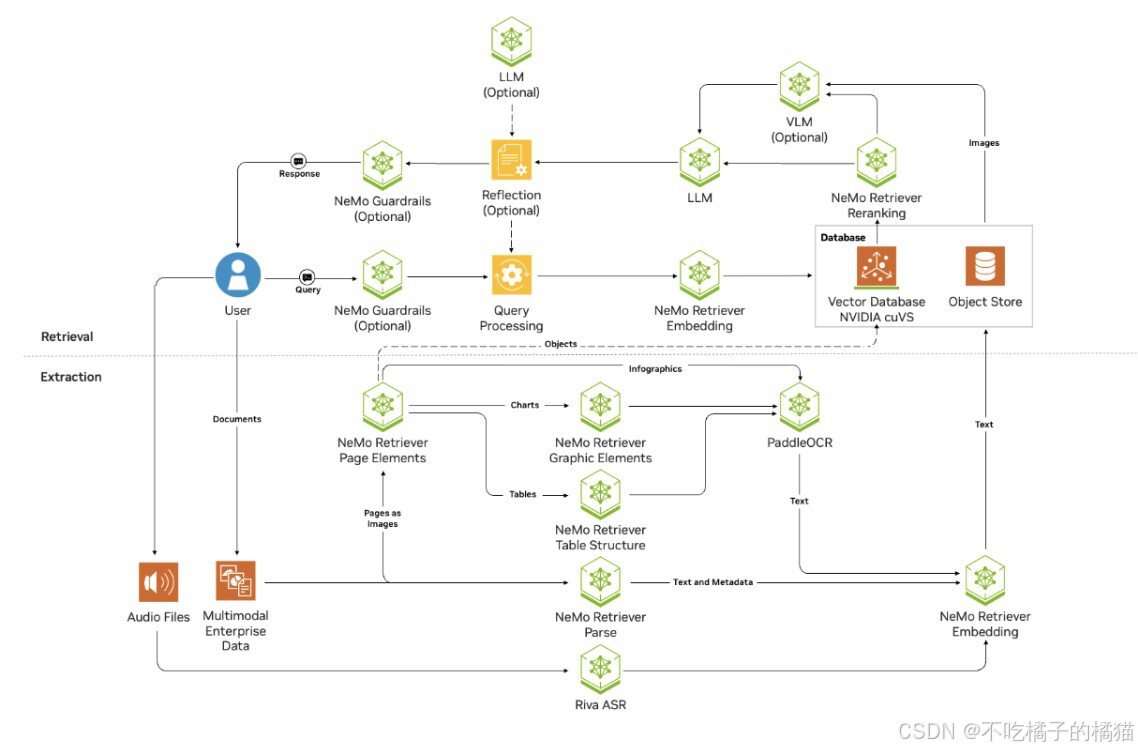
部署共包含 8 个微服务:
基础设施层(Infrastructure Layer)
Milvus Standalone:向量数据库,用于存储嵌入
MinIO:Milvus 使用的对象存储
etcd:Milvus 的元数据存储
Redis:用于缓存日志、对话历史等
处理层(Processing Layer)
NV-Ingest Runtime:多模态文档提取引擎
Ingestor Server:文档上传与摄取 API
RAG 层(RAG Layer)
RAG Server:查询与检索编排 API
RAG Playground:用于聊天和测试的 Web 界面
克隆 GitHub 仓库
仓库地址:https://github.com/NVIDIA-AI-Blueprints/rag.git
运行以下命令将仓库克隆到本地环境:
python
!git clone https://github.com/NVIDIA-AI-Blueprints/rag.git && cd rag && git checkout f0af4a2
python
import os
os.chdir('rag')注:API Key 相当于密码,切勿公开分享或提交
Docker 与 NGC 认证(Authenticate Docker with NGC)
在部署之前,Docker 需要获得从 NVIDIA 容器注册表(nvcr.io)拉取镜像的权限。我们将使用您的 NGC API Key 完成认证。
认证过程说明:
docker login nvcr.io:向 NVIDIA 容器注册表进行身份验证
用户名固定为 $oauthtoken:这是 NVIDIA 用于 API Key 认证的特殊占位符
NGC API Key 将作为密码使用
运行下方代码单元以完成 Docker 认证:
python
!echo "${NGC_API_KEY}" | docker login nvcr.io -u '$oauthtoken' --password-stdin成功认证后,Docker 即可从 nvcr.io 拉取 NVIDIA 提供的官方容器镜像。
然后,我们需要配置部署以使用 NVIDIA 托管端点,在启动服务前,我们需要配置系统,使其使用 NVIDIA 托管的 NIM 端点,而不是在本地运行所有模型微服务。
RAGL流水线:用户查询 → 生成查询向量 → 在 Milvus 中搜索 → 重排序 → 将检索结果作为上下文注入提示词 → 调用 LLM → 返回答案
使用的 API 端点:
| 端点 | 用途 | 关键参数 |
|---|---|---|
/v1/chat/completions |
带 RAG 的问答 | use_knowledge_base, collection_name |
/v1/search |
纯检索(返回相关文档) | query, vdb_top_k, enable_reranker |
/v1/health |
检查服务健康状态 | 无 |
示意图:
部署完成后,即可访问http://<your-ip-or-hostname>:8090. 替换 <your-ip-or-hostname> 为你服务器的ip地址,如果本地运行,就替换成 localhost。对课程而言,就是实验室地址。
页面如图所示: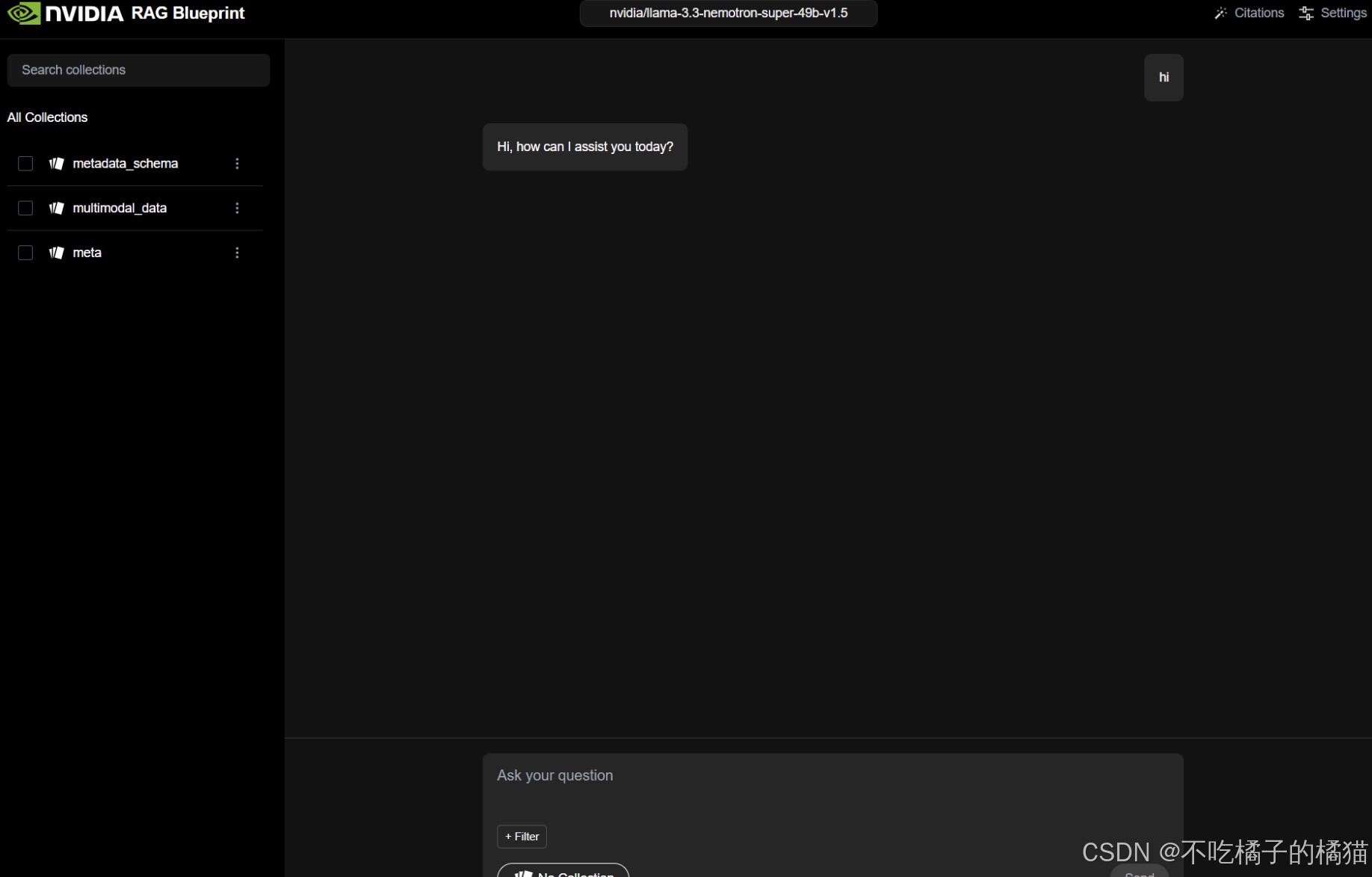
学习部署之后,剩下的工作便是学习通过API与RAG系统交互。
交互部分:
创建集合接口(Create Collection Endpoint
async def create_collections(
collection_names: list = None,
collection_type: str = "text",
embedding_dimension: int = 2048
):
"""在向量存储中创建一个或多个集合。
Args:
collection_names (list): 要创建的集合名称列表
collection_type (str): 集合类型,默认为 "text"
embedding_dimension (int): 嵌入向量维度,默认为 2048
Returns:
API 返回结果,若失败则返回错误详情
"""
# 创建集合所需的参数
params = {
"vdb_endpoint": "http://milvus:19530", # Milvus 向量数据库端点
"collection_type": collection_type, # 集合类型
"embedding_dimension": embedding_dimension # 嵌入维度
}
HEADERS = {"Content-Type": "application/json"}
# 发起 POST 请求以创建集合
async with aiohttp.ClientSession() as session:
try:
async with session.post(
f"{INGESTOR_BASE_URL}/v1/collections",
params=params,
json=collection_names,
headers=HEADERS
) as response:
await print_raw_response(response)
except aiohttp.ClientError as e:
return 500, {"error": str(e)}
# 示例:创建名为 "multimodal_data" 的集合
await create_collections(collection_names=["multimodal_data"])分析
| 功能 | 说明 |
|---|---|
| 用途 | 在 Milvus 数据库中创建新的集合(Collection),用于存储特定类型的嵌入数据 |
| 关键参数 | - collection_names: 支持批量创建 - collection_type: 可选 "text"、"image" 等,影响后续处理逻辑 - embedding_dimension: 必须匹配嵌入模型输出维度(如 2048) |
| HTTP 方法 | POST 到 /v1/collections |
| 调用方 | Ingestor Server 作为中间层代理请求至 Milvus |
获取集合列表接口(Get Collections Endpoint)
# 先创建另一个集合
await create_collections(collection_names=["multimodal_data1"])
# 现在获取所有集合的列表
async def fetch_collections():
"""从 Milvus 向量数据库获取所有集合的列表。
通过 GET 请求调用 ingester API 端点,获取指定 Milvus 服务器上的所有集合名称。
Returns:
API 返回的结果(包含集合列表),若失败则打印错误信息。
"""
url = f"{INGESTOR_BASE_URL}/v1/collections"
params = {"vdb_endpoint": "http://milvus:19530"}
async with aiohttp.ClientSession() as session:
try:
async with session.get(url, params=params) as response:
await print_raw_response(response)
except aiohttp.ClientError as e:
print(f"Error: {e}")
await fetch_collections()分析
| 功能 | 说明 |
|---|---|
| 用途 | 查询当前 Milvus 中存在的所有集合名称 |
| HTTP 方法 | GET 到 /v1/collections |
| 返回值 | JSON 格式数组,例如:["multimodal_data", "multimodal_data1"] |
| 应用场景 | - 用户界面展示可用知识库 - 自动化脚本检查是否存在目标集合 |
删除集合接口(Delete Collections Endpoint)
from typing import List
async def delete_collections(collection_names: List[str] = "") -> None:
"""从 Milvus 向量数据库删除指定的集合。
向 ingester API 发送 DELETE 请求,移除指定集合。
Args:
collection_names (List[str]): 要删除的集合名称列表,默认为空字符串
Returns:
None。成功时打印响应;失败时打印错误消息。
Example:
await delete_collections(collection_names=["collection1", "collection2"])
"""
url = f"{INGESTOR_BASE_URL}/v1/collections"
params = {"vdb_endpoint": "http://milvus:19530"}
async with aiohttp.ClientSession() as session:
try:
async with session.delete(
url,
params=params,
json=collection_names
) as response:
await print_raw_response(response)
except aiohttp.ClientError as e:
print(f"Error: {e}")
# 删除上一节创建的集合
print("\nDeleting collection 'multimodal_data1'...")
await delete_collections(collection_names=["multimodal_data1"])
# 再次获取剩余集合列表
print("\nFetching remaining collections:")
print("-" * 30)
await fetch_collections()分析
| 功能 | 说明 |
|---|---|
| 用途 | 删除不再需要的集合,用于数据治理、合规性或清理测试数据 |
| HTTP 方法 | DELETE 到 /v1/collections |
| 安全性 | 直接删除会导致数据永久丢失,需谨慎使用 |
| 企业场景 | - 数据保留策略(data retention policy) - 敏感信息清除(GDPR 合规) - 环境重置 |
健康检查接口(Health Check Endpoint)
# 假设所有服务都在同一 Docker 网络中
IPADDRESS = "ingestor-server"
# 服务端口
ingestor_server_port = "8082"
# 构造基础 URL
INGESTOR_BASE_URL = f"http://{IPADDRESS}:{ingestor_server_port}"
# 测试 RAG 服务器的健康检查端点
url = f"{INGESTOR_BASE_URL}/v1/health"
print("\nStep 1: Testing RAG server health endpoint")
print("_" * 60)
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
await print_raw_response(response)分析
| 功能 | 说明 |
|---|---|
| 用途 | 检查 Ingestor Server 是否正常运行 |
| 预期响应 | 成功返回 HTTP 200,表示服务就绪 |
| 实际作用 | 用于监控系统状态、CI/CD 自动部署前验证、负载均衡器健康探测 |
RAG Server 访问配置
import requests
import json
import aiohttp
# IP 地址(假设所有服务在同一 Docker 网络)
IPADDRESS = "rag-server"
# 端口号
rag_server_port = "8081"
# 构造基础 URL
RAG_BASE_URL = f"http://{IPADDRESS}:{rag_server_port}"
async def print_raw_response(response):
"""辅助函数:打印 API 响应内容。
尝试解析 JSON 并格式化输出,否则输出原始文本。
"""
try:
response_json = await response.json()
print(json.dumps(response_json, indent=2))
except aiohttp.ClientResponseError:
print(await response.text())分析
| 功能 | 说明 |
|---|---|
| 核心作用 | 设置 RAG Server 的访问地址和通用响应打印工具 |
| URL 结构 | http://rag-server:8081 ------ 对应 Docker 容器名与端口映射 |
| print_raw_response | 优雅地处理 API 返回,支持 JSON 和文本两种格式,提升调试体验 |
测试 RAG 服务器健康与聊天接口
# 1. 测试 RAG 服务器健康检查端点
url = f"{RAG_BASE_URL}/v1/health"
print("\nStep 1: Testing RAG server health endpoint")
print("_" * 60)
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
await print_raw_response(response)
# 2. 测试基本聊天完成接口(禁用 RAG 功能)
payload = {
"messages": [
{
"role": "user",
"content": "Hi" # 简单测试消息
}
],
"use_knowledge_base": False, # 关闭 RAG 功能
"temperature": 0.2, # 更聚焦的回答
"model": os.environ["APP_LLM_MODELNAME"]
}
chat_url = f"{RAG_BASE_URL}/v1/chat/completions"
print("\nStep 2: Testing chat completion endpoint")
print("_" * 60)
print("\nSending request to:", chat_url)
print("With payload:", json.dumps(payload, indent=2))
async with aiohttp.ClientSession() as session:
async with session.post(chat_url, json=payload) as response:
await print_raw_response(response)深度研究与AI-Q:
带有搜索工具的 LLM与传统深度研究智能体比较
| 方面 | 带有搜索工具的 LLM | 传统深度研究智能体 |
|---|---|---|
| 主要数据源 | 私有企业数据(RAG) | 公共网络信息 |
| 搜索角色 | 私有数据的增强层 | 核心自主研究能力 |
| 搜索行为 | 反应式 ------ 仅在需要时搜索 | 主动式 ------ 自主探索 |
| 搜索量级 | 目标导向(1--5 次查询) | 扩展性高(10--50+ 次查询) |
| 企业适用性 | 生产就绪,适合企业部署 | 研究/实验用途为主 |
| 数据治理 | 优先保护私有数据,网络为补充 | 以网络信息为主导 |
| 主要用途 | 使用内部知识回答问题 | 深度网络研究综合 |
| 类型 | 代表系统 | 特点 | 适用场景 |
|---|---|---|---|
| 传统深度研究智能体 | Perplexity、Google Gemini Advanced | 主动探索、高自由度 | 科研、实验、个人使用 |
| AI-Q(带搜索工具的 LLM) | NVIDIA AI-Q | 私有优先、可控、企业级 | 金融、法律、医疗、政府等敏感行业 |
注:AI-Q 的定位是"企业级研究助手",不是"通用搜索引擎"。
系统架构:
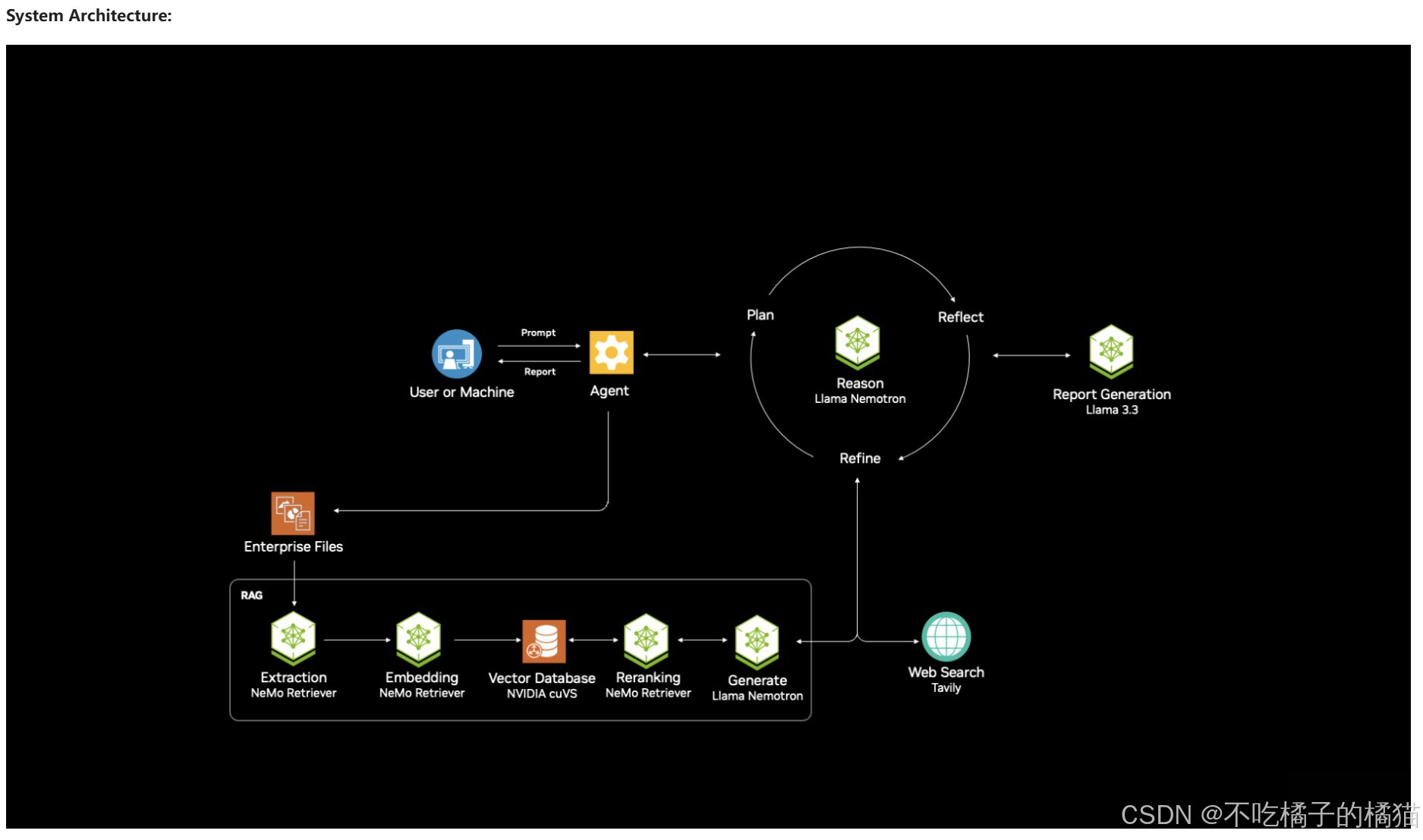
NVIDIA AI-Q Research Assistant 部署流程:
部署步骤总览
-
克隆仓库:获取 AI-Q 蓝图代码
-
设置环境变量:配置 API 密钥和服务端点
-
部署服务:启动 Docker 容器
-
验证部署:确认所有服务健康运行
-
上传数据:摄取样本文档用于研究
流程:
1.将仓库克隆到本地环境:
!git clone https://github.com/NVIDIA-AI-Blueprints/aiq-research-assistant.git && cd aiq-research-assistant && git checkout 841d60e
import os
os.chdir('aiq-research-assistant')2.配置 NVIDIA 托管端点环境(Configure Environment for NVIDIA-Hosted Endpoints)
在部署服务前,需要配置环境以使用 NVIDIA 托管的 NIM 端点。该配置告诉 AI-Q 系统如何查找其依赖的 AI 模型和服务。
os.environ["AIRA_HOSTED_NIMS"] = "true" # 使用 NVIDIA 托管模型而非本地部署
os.environ["APP_LLM_MODELNAME"] = "nvidia/llama-3.3-nemotron-super-49b-v1.5" # 推理模型
os.environ["APP_EMBEDDINGS_MODELNAME"] = "nvidia/llama-3.2-nv-embedqa-..." # 嵌入模型
os.environ["APP_RANKING_MODELNAME"] = "nvidia/llama-3.2-nv-rerankqa-..." # 重排序模型
os.environ["OCR_HTTP_ENDPOINT"] = "https://ai.api.nvidia.com/v1/cv/baidu/paddleocr" # OCR 服务
os.environ["YOLOX_HTTP_ENDPOINT"] = "https://ai.api.nvidia.com/v1/cv/nvidia/nemoretriever-page-elements-v2" # 页面元素检测
os.environ["ENABLE_RERANKER"] = "false" # 关闭重排序以降低延迟
os.environ["NGC_API_KEY"] = nvapi_key # NVIDIA 认证密钥
os.environ["TAVILY_API_KEY"] = tavily_key # 可选:Tavily 网络搜索 API 密钥-
启动 AI-Q 服务(Launch the AI-Q Services)
docker compose -f deploy/compose/docker-compose.yaml --profile aira up -d
| 参数 | 说明 |
|---|---|
docker compose |
多容器应用编排工具 |
-f deploy/compose/docker-compose.yaml |
指定配置文件路径 |
--profile aira |
仅启动标记为 "aira" 的服务(AI-Q 专用) |
up |
创建并启动容器 |
-d |
后台运行,保持终端可用 |
4.验证部署(Verify Deployment)
确认所有服务正常运行。docker ps 命令列出所有运行中的容器,显示部署状态。
应看到的内容:
至少 10 个容器运行中(8 个来自 RAG + 2 个新 AI-Q 服务):
AI-Q 新增服务(本笔记本新增):
aira-backend:智能体编排引擎
aira-frontend:Web 用户界面
RAG 服务(来自 Notebook 03):
ingestor-server:文档上传 API
rag-server:查询与检索 API
compose-nv-ingest-ms-runtime-1:文档处理引擎
standalone:Milvus 向量数据库
minio:Milvus 对象存储后端
etcd:Milvus 元数据存储
redis:日志与对话历史缓存层
rag-playground:RAG 测试接口(可选)
输出字段说明:
| 字段 | 含义 |
|---|---|
| CONTAINER ID | 每个容器的唯一标识符 |
| IMAGE | 使用的 Docker 镜像 |
| STATUS | 健康状态(应为 "Up X minutes") |
| PORTS | 暴露的网络端口 |
| NAMES | 人类可读的容器名称 |
研究工作流(The Research Workflow)
当部署 AI-Q 后,启用完整的研究工作流:
Phase 1: 研究规划(Research Planning)
Phase 2: 并行调查(Parallel Investigation)
Phase 3: 报告生成(Report Generation)
Phase 4: 迭代优化(Iterative Refinement)
部署组件概览
后端服务(Backend Services):
aira-backend:核心智能体编排引擎,负责:
1.创建和管理研究计划协调
2.RAG 与网络的并行搜索
3.使用 Nemotron 推理生成并优化报告
4.管理人机协作审批流程
5.前端服务(Frontend Services):
aira-frontend:基于 React 的 Web 应用,提供:
1.研究主题与结构输入界面
2.研究计划审查与编辑 UI
3.实时研究进度追踪
4.带来源引用的报告查看
5.Q&A 接口用于报告优化
关键环境变量说明
| 变量 | 值 | 用途 |
|---|---|---|
AIRA_HOSTED_NIMS |
"true" |
使用 NVIDIA 托管模型,避免本地 GPU 部署 |
APP_LLM_MODELNAME |
"nvidia/llama-3.3-nemotron-super-49b-v1.5" |
推理模型(研究规划与报告生成) |
APP_EMBEDDINGS_MODELNAME |
"nvidia/llama-3.2-nv-embedqa-..." |
文本转向量嵌入模型(来自 Notebook 03) |
APP_RANKING_MODELNAME |
"nvidia/llama-3.2-nv-rerankqa-..." |
重排序模型(提升检索相关性) |
EMBEDDING_NIM_ENDPOINT |
https://integrate.api.nvidia.com/v1/... |
NVIDIA 托管推理端点 |
PADDLE_HTTP_ENDPOINT |
https://ai.api.nvidia.com/v1/cv/baidu/paddleocr |
图像文本提取(OCR) |
YOLOX_HTTP_ENDPOINT |
https://ai.api.nvidia.com/v1/cv/nvidia/nemoretriever-page-elements-v2 |
页面元素检测(表格、图表、文本块) |
ENABLE_RERANKER |
"false" |
关闭重排序以降低延迟(可选优化) |
NGC_API_KEY & NVIDIA_API_KEY |
您的 API 密钥 | 认证 NVIDIA 托管服务 |
TAVILY_API_KEY |
您的 Tavily 密钥(可选) | 启用网络搜索,补充实时互联网数据 |
如图所示: