引言
在人工智能的时代,神经网络就像是我们大脑的简化版模型,它能帮助计算机"学习"各种任务,比如识别图片、翻译语言,甚至开车。想象一下,你教一个小孩子骑自行车:一开始他可能会摔倒,你告诉他哪里错了,怎么调整姿势。下一次他就会做得更好。这里的"告诉哪里错了"和"怎么调整"就是神经网络训练的核心过程------反向传播(Backpropagation)。反向传播不是什么高深莫测的黑科技,它其实就是一种聪明的方法,让神经网络从错误中学习,逐步优化自己。
为什么叫"反向传播"呢?因为在神经网络中,信息先从输入端"向前"流动,计算出结果;然后,如果结果不对,就从输出端"向后"传播错误信号,告诉前面的部分该怎么改。这就像踢足球时,教练从球门处喊话给前锋:"你传球太偏了,下次往左一点!" 通过反复的向前计算和向后调整,网络就能越来越准。
本文将用通俗的语言解释神经网络的反向传播。我们会从基础开始,一步步拆解过程,避免复杂的数学公式(但会简单介绍必要的部分),并用生活中的比喻来辅助理解。文章会包括图示,帮助你可视化这些概念。准备好了吗?让我们开始吧!
神经网络的基础:像大脑一样的结构
首先,得明白神经网络长什么样。神经网络(Neural Network)灵感来源于人脑的神经元。脑子里有上百亿个神经元,每个神经元通过突触连接,传递信号。神经网络简化了这个:它由层层"神经元"组成,每层神经元之间有"权重"(weights)连接,这些权重就像连接的强度。
一个典型的神经网络有三部分:
- 输入层(Input Layer):接收数据。比如,识别猫狗的图片,这里输入就是图片的像素值。
- 隐藏层(Hidden Layers):中间的计算层,可以有多层。这里是魔法发生的地方,网络提取特征。
- 输出层(Output Layer):给出结果。比如,输出"这是猫"的概率。
每个神经元做什么?它接收来自上一层的信号,加权求和,然后通过一个"激活函数"(Activation Function)转化成输出。激活函数就像一个开关,决定信号是否"激活"传递下去。
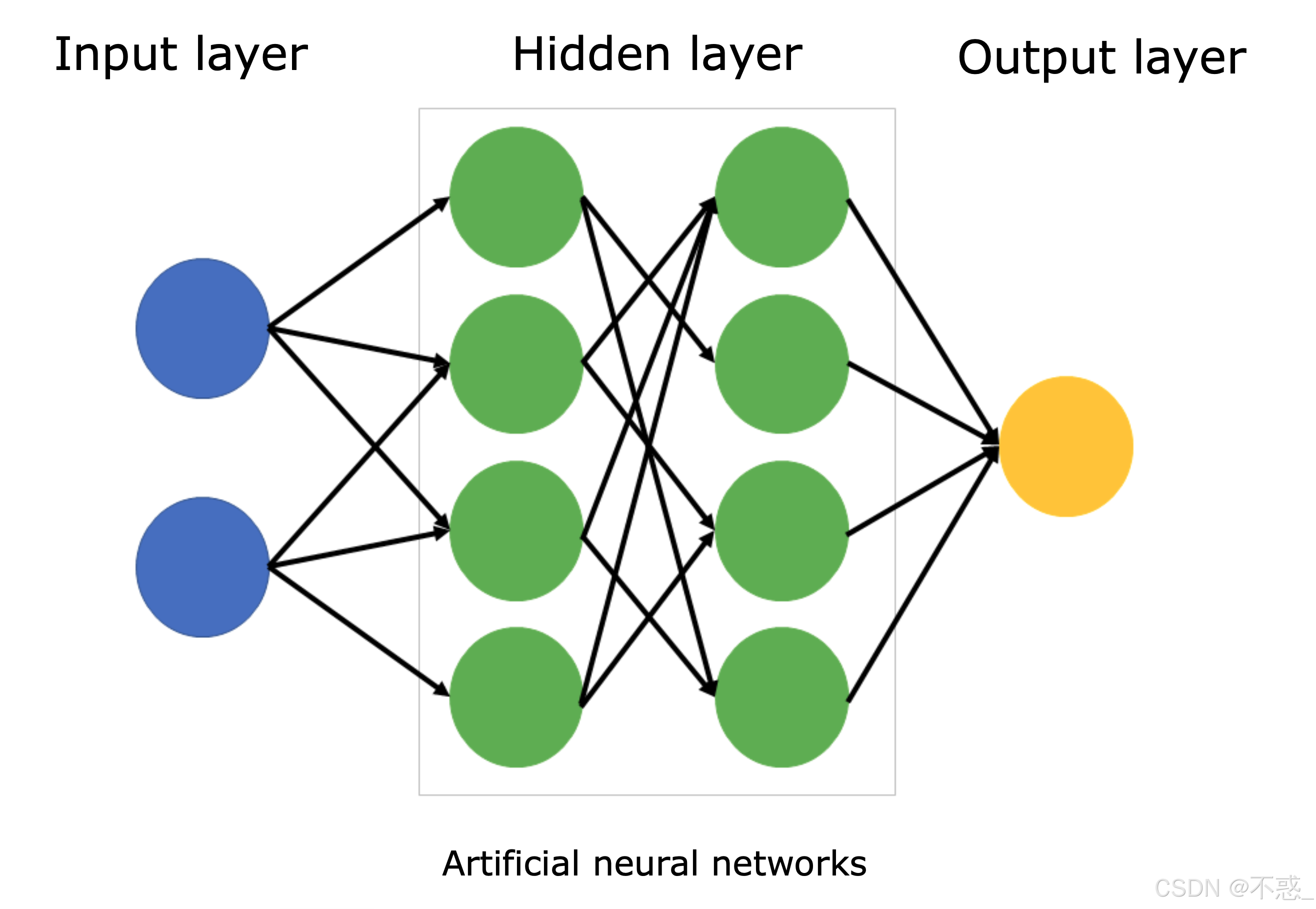
如上图所示,这是一个简单的神经网络示意图。输入层有几个节点(代表特征),隐藏层处理信息,输出层给出答案。箭头代表权重连接。实际网络可以有成千上万的节点,但原理一样。
为什么需要训练?因为刚开始,权重是随机的,网络的输出就像瞎猜。训练就是调整权重,让输出接近真实答案。这靠两个东西:前向传播(计算输出)和反向传播(调整权重)。
前向传播:信息从头到尾的流动
在谈反向传播前,先说前向传播(Forward Propagation)。这是神经网络的"正向"计算过程,就像水从上游流到下游。
假设我们有一个简单网络:输入两个数x1和x2(比如房屋面积和房间数),预测房价y。网络有一个隐藏层,两个神经元。
步骤:
- 输入层:x1和x2。
- 到隐藏层:每个隐藏神经元计算:z = w1x1 + w2x2 + b(b是偏置,bias,像一个基准值)。
- 激活:a = sigmoid(z) 或其他函数。
- 到输出层:类似,计算输出y_hat。
- 比较y_hat和真实y,计算损失(Loss),比如均方误差:Loss = (y - y_hat)^2 / 2。
前向传播就是这样一层一层推下去。每个层输出是下一层的输入。
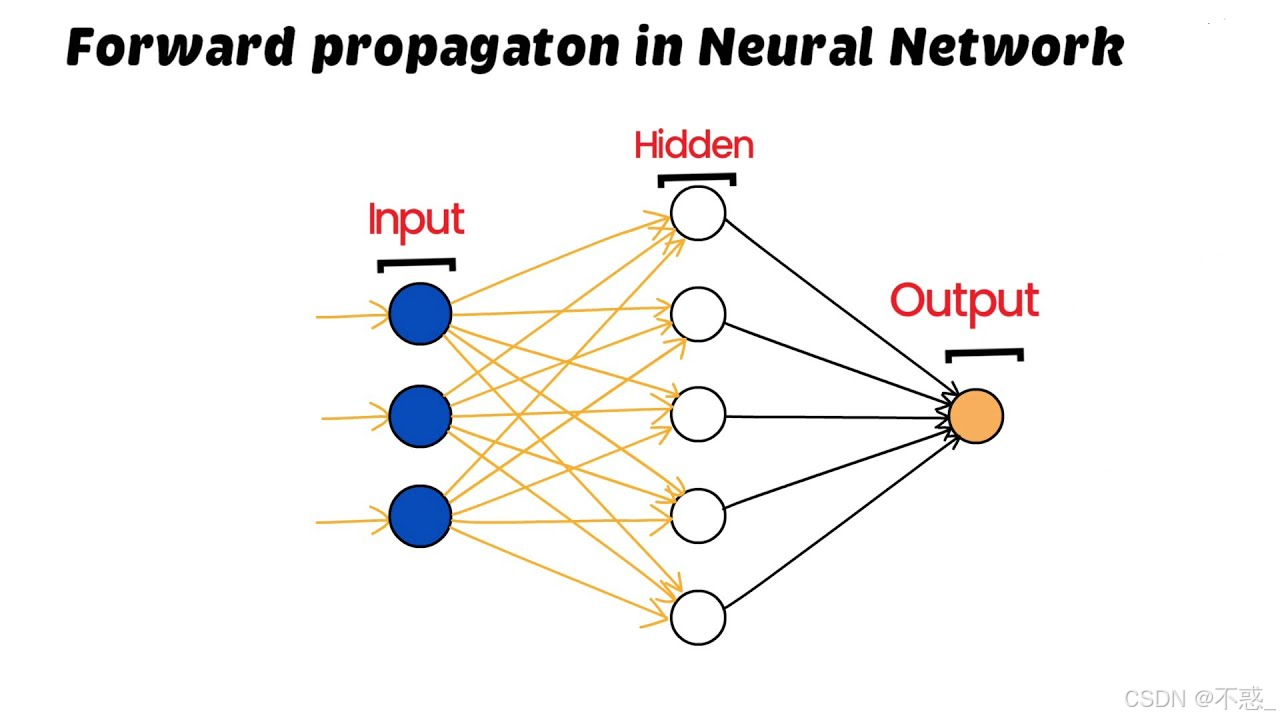
图中展示了前向传播的过程:数据从左到右流动,经过权重和激活,得出预测。这很简单,但如果预测错了,怎么办?这就是反向传播的舞台。
为什么需要反向传播:从错误中学习
神经网络的训练目标是最小化损失函数。损失函数衡量预测和真实的差距。怎么最小化?用梯度下降(Gradient Descent)。
梯度下降像下山:你在山上,想去谷底(最小损失)。你看脚下最陡的方向(梯度),迈一步。重复,直到谷底。
在神经网络中,"山"是个多维空间,参数是权重。梯度是损失对每个权重的偏导数,告诉我们"这个权重该怎么变才能减小损失"。
问题:怎么算这些梯度?如果网络层很多,手算太复杂。这时候,反向传播登场。它用链式法则(Chain Rule)高效计算所有梯度,从输出层反向推到输入层。
链式法则是微积分的基础:如果y = f(g(x)),则dy/dx = dy/dg * dg/dx。像多米诺骨牌,从后往前传导导数。
上图是梯度下降的可视化:曲线是损失函数,箭头显示迭代下降。反向传播就是计算这些箭头的方向和大小。
反向传播的原理:链式法则在行动
反向传播的核心是"错误反向传播"。从输出层开始,计算损失对输出的梯度,然后一层一层往前传。
用比喻:想象一个生产线,产品从A到B到C到D。如果D错了,你从D问C:"你贡献了多少错?" C再问B,以此类推。每个环节调整自己。
数学上:
- 损失L对输出y_hat的导数:∂L/∂y_hat = y_hat - y(对于均方误差)。
- 然后,∂L/∂w(某个权重) = ∂L/∂y_hat * ∂y_hat/∂z * ∂z/∂w (链式)。
这样,从后往前乘积,就能得到所有导数。
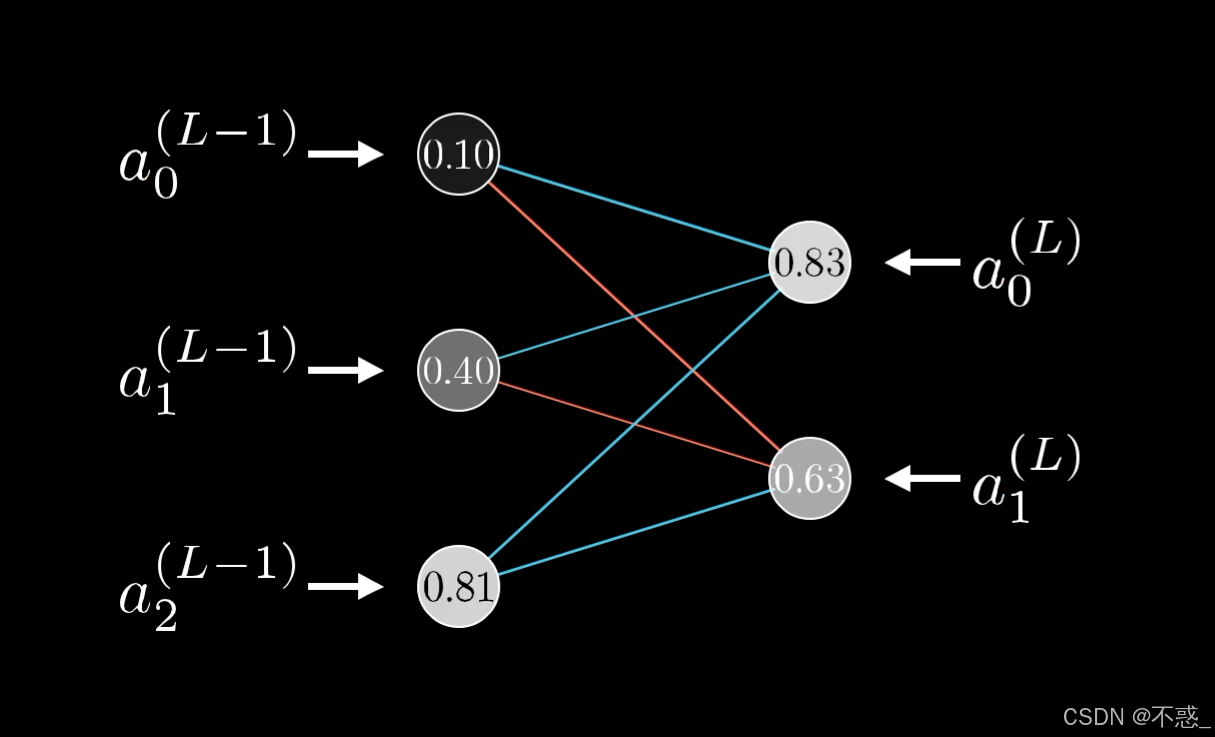
图中展示了链式法则在反向传播中的应用:导数像信号一样反向流动。
激活函数在这里很重要,因为导数涉及激活的 derivative。比如Sigmoid函数:f(z) = 1/(1+e^{-z}),其导数是f'(z) = f(z)(1-f(z))。如果不用激活,网络就退化成线性模型,学不了复杂东西。
常见激活函数:
- Sigmoid:输出0-1,适合概率。
- Tanh:-1到1,零中心。
- ReLU:max(0,z),简单高效,但有"死神经元"问题。
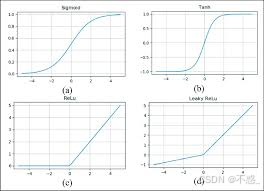
如图,这些函数的图形帮助理解非线性。
反向传播的详细步骤:用一个简单例子
让我们用一个超简单网络举例:单隐藏层,输入1个x,隐藏2个神经元,输出1个y。任务:学习y = x^2。
初始化权重随机。
步骤1: 前向传播
- 输入x。
- 隐藏层:z1 = w11x + b1, a1 = relu(z1)
z2 = w21x + b2, a2 = relu(z2) - 输出:y_hat = w_out1a1 + w_out2a2 + b_out
计算Loss = (y - y_hat)^2 / 2
步骤2: 反向传播计算梯度
- 从输出开始:δ_out = ∂L/∂y_hat = y_hat - y
- 输出层权重梯度:∂L/∂w_out1 = δ_out * a1
类似w_out2和b_out。 - 传到隐藏层:δ_a1 = δ_out * w_out1 (错误分配)
δ_z1 = δ_a1 * relu'(z1) (激活导数) - 隐藏层权重:∂L/∂w11 = δ_z1 * x
∂L/∂b1 = δ_z1
步骤3: 更新权重
用学习率η:w = w - η * ∂L/∂w
重复直到Loss小。
图中展示了反向传播的算法步骤:初始化、前向、计算损失、反向计算梯度、更新。
这个例子简化了,但实际网络类似,只是层多,计算用矩阵加速。
激活函数和梯度消失问题
为什么激活重要?没有它,网络就是线性回归,学不了XOR这样的非线性。
但Sigmoid/Tanh有"梯度消失":当z很大或很小时,导数接近0,梯度传不回去,像信号衰减。ReLU解决了这,但负值时导数0,导致"死"。
现代用Leaky ReLU或ELU,避免这些。
在训练中,还用批量梯度下降(Batch GD)、小批量(Mini-batch)等变体,提高效率。
反向传播在深度学习中的作用
深度网络(Deep Learning)层多,反向传播让训练可能。没有它,算梯度太慢。
但挑战:过拟合(用 dropout、正则化解决)、初始化(用Xavier)、优化器(Adam比SGD好)。
历史:反向传播1986年Rumelhart提出,开启神经网络复兴。
常见问题与误区
- 反向传播是BP算法吗? 是的,BP就是Backpropagation。
- 需要高等数学吗? 基础微积分够用,框架如TensorFlow自动算。
- 为什么叫"传播"? 因为错误像波一样传播。
- 和前向有何不同? 前向算输出,反向算梯度。
- 在CNN/RNN中呢? 类似,但有卷积/循环特定导数。
误区:不是生物脑的精确模拟,只是启发。
结论
反向传播是神经网络的灵魂,让机器从数据中学习。通俗说,它就是"试错-调整"的循环,用数学高效实现。通过前向计算预测,反向传播错误,梯度下降优化。
理解它,你就懂了AI训练的核心。实际编程,用PyTorch简单几行就行。但原理知道,能更好地调参、debug。
希望这篇文章帮你澄清概念。如果你想深入,试试手写一个简单BP网络。AI的世界,等你探索!