目录
[1. 单机架构](#1. 单机架构)
[2. 什么叫分布式系统](#2. 什么叫分布式系统)
[2.1 负载均衡](#2.1 负载均衡)
[2.2 数据库分离](#2.2 数据库分离)
[2.2.1 数据库读写分离](#2.2.1 数据库读写分离)
[2.2.2 数据库分库分表](#2.2.2 数据库分库分表)
今天我们来聊一聊分布式系统。
1. 单机架构
单机架构 是一种集中式的系统部署架构 ,指整个应用或计算任务的所有组件(包括数据存储、计算逻辑、业务处理等)都运行在一台独立的物理服务器或虚拟机上,所有的资源调用和数据交互都在这台机器内部完成,不依赖其他外部节点。
我们看下面这张图,单机架构的话其实就类似于下面这样,所有用户的请求都是由一台主机来进行接收已经回复的。
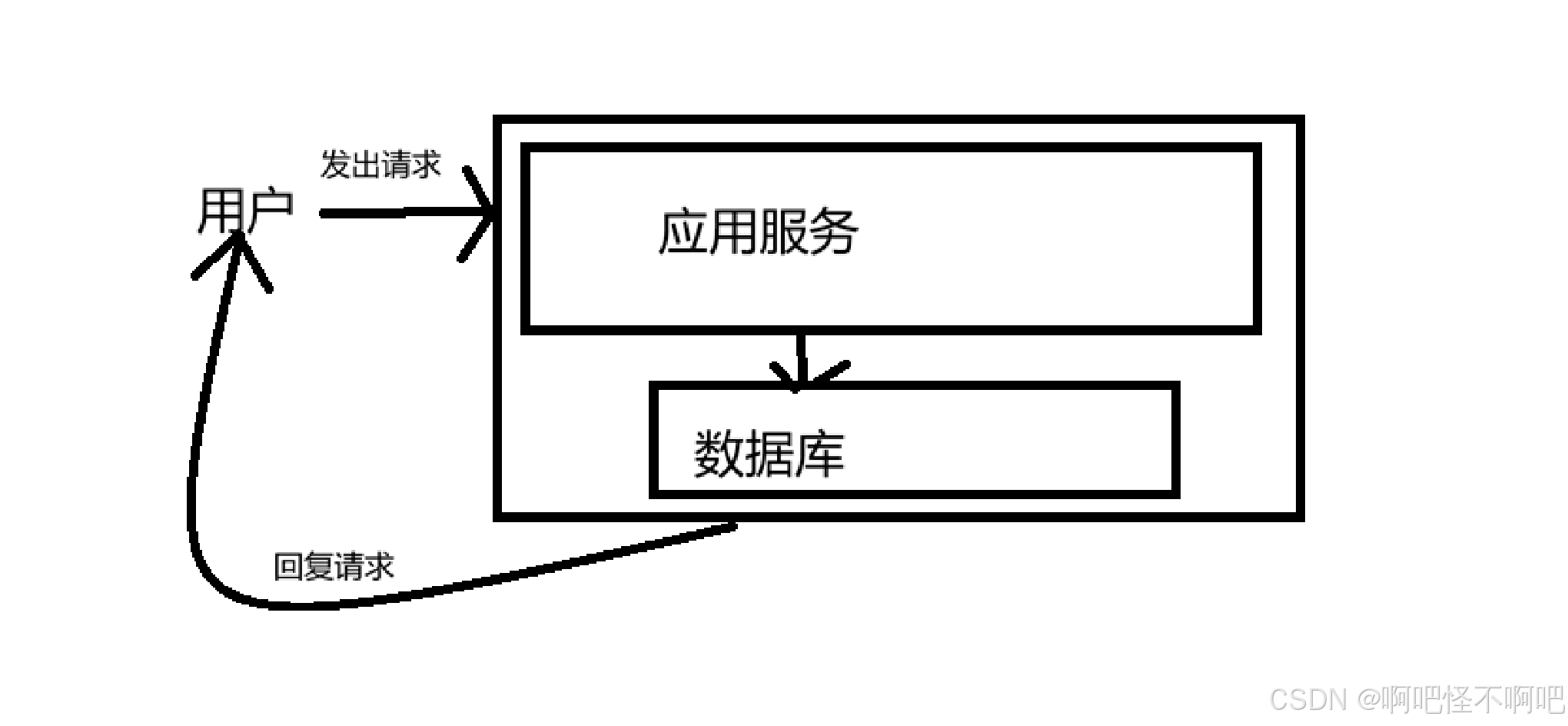
核心特点
- 资源独占所有硬件资源(CPU、内存、磁盘、显卡等)都为当前任务或应用服务,不会与其他节点共享。比如一台个人电脑上运行的单机版办公软件,就是典型的单机架构。
- 架构简单无需设计节点间的通信、协同机制,开发和部署成本低,适合小型应用或简单任务。
- 局限性明显
- 性能上限受单台机器的硬件配置限制,无法通过扩展节点来提升算力;
- 可靠性差,一旦这台机器故障,整个系统就会瘫痪;
- 难以处理大规模数据和高并发请求。
因此我们在单机架构的基础上引入了分布式系统,用来解决单机架构的局限性问题。
2. 什么叫分布式系统
分布式系统 是由多个地理上分散、通过网络连接的独立计算节点(服务器、计算机等)组成的系统,这些节点协同工作,对外呈现为一个统一的整体,共同完成单台机器难以承担的复杂任务。
我们看下面这张图片,这就是分布式架构,通过增加主机的数量,来使用户的请求得到快速的回应。
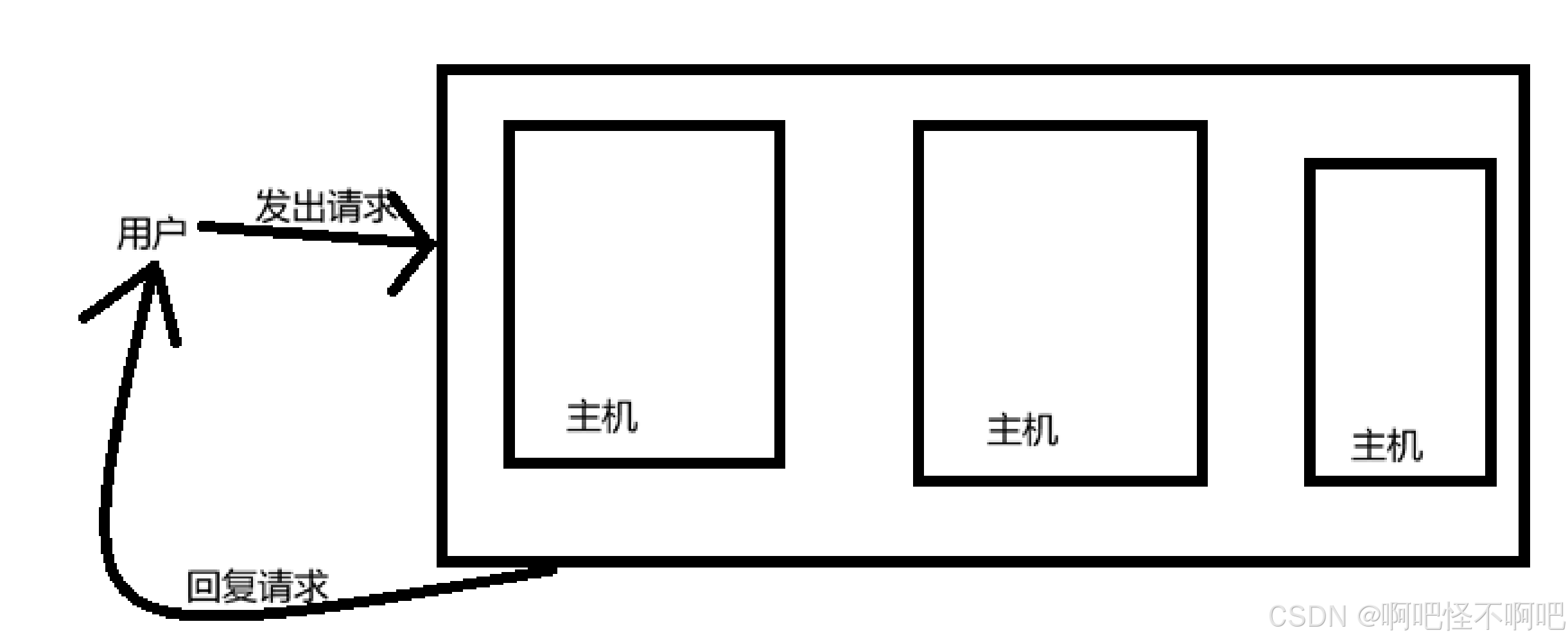
核心特点
- 节点自治每个节点都是独立的计算机,拥有自己的 CPU、内存、存储等硬件资源,能自主执行部分计算任务。
- 协同工作节点之间通过网络通信交换数据和指令,分工协作完成同一任务,比如把大模型训练任务拆分成多个子任务,分配给不同节点并行处理。
- 透明性对用户或上层应用来说,不需要关心任务是由哪个节点执行的,系统对外提供统一的服务接口,就像使用单机系统一样便捷。
- 可扩展性强当任务规模增大时,无需更换高性能单机,只需增加节点数量就能提升系统的整体算力和存储能力,这也是它适合大模型训练、大数据处理的核心原因。
- 高可靠性单个节点故障不会导致整个系统崩溃,其他节点可以接管故障节点的任务,具备容错能力。
接下来的内容就都是关于当前架构的不断升级,来使它能够适应各种场合。
2.1 负载均衡
负载均衡在这里就是指用户的各种请求能够平均的分配到各个主机,来让程序维持在相对的一种稳定状态。
当然,负载均衡在这里跟多的是一种思想,就跟贪心算法一样,我们可以根据这个思想来设计各种各样的算法来实现这个思想。防止某一台主机承接过多请求,导致响应变慢甚至宕机。
下面这几种是一般来说比较常见的实现负载均衡的算法。
- 轮询:按顺序依次将请求分配给每个节点,简单公平,适合节点性能相近的场景。
- 加权轮询:给性能更强的节点设置更高权重,分配更多请求,适配节点配置不均的情况。
- 最少连接数:优先将请求分配给当前活跃连接数最少的节点,适合请求处理时间差异较大的场景。
- IP 哈希:根据客户端 IP 计算哈希值,将同一客户端的请求固定分配给某一节点,保证会话一致性。
当然,一般来说我们会把算法设置到负载均衡器里面,通过负载均衡器来实现任务的分配。
类似于下面这张图片这样。用户的任务会先给负载均衡器,然后负载均衡器来把任务交给各个主机。
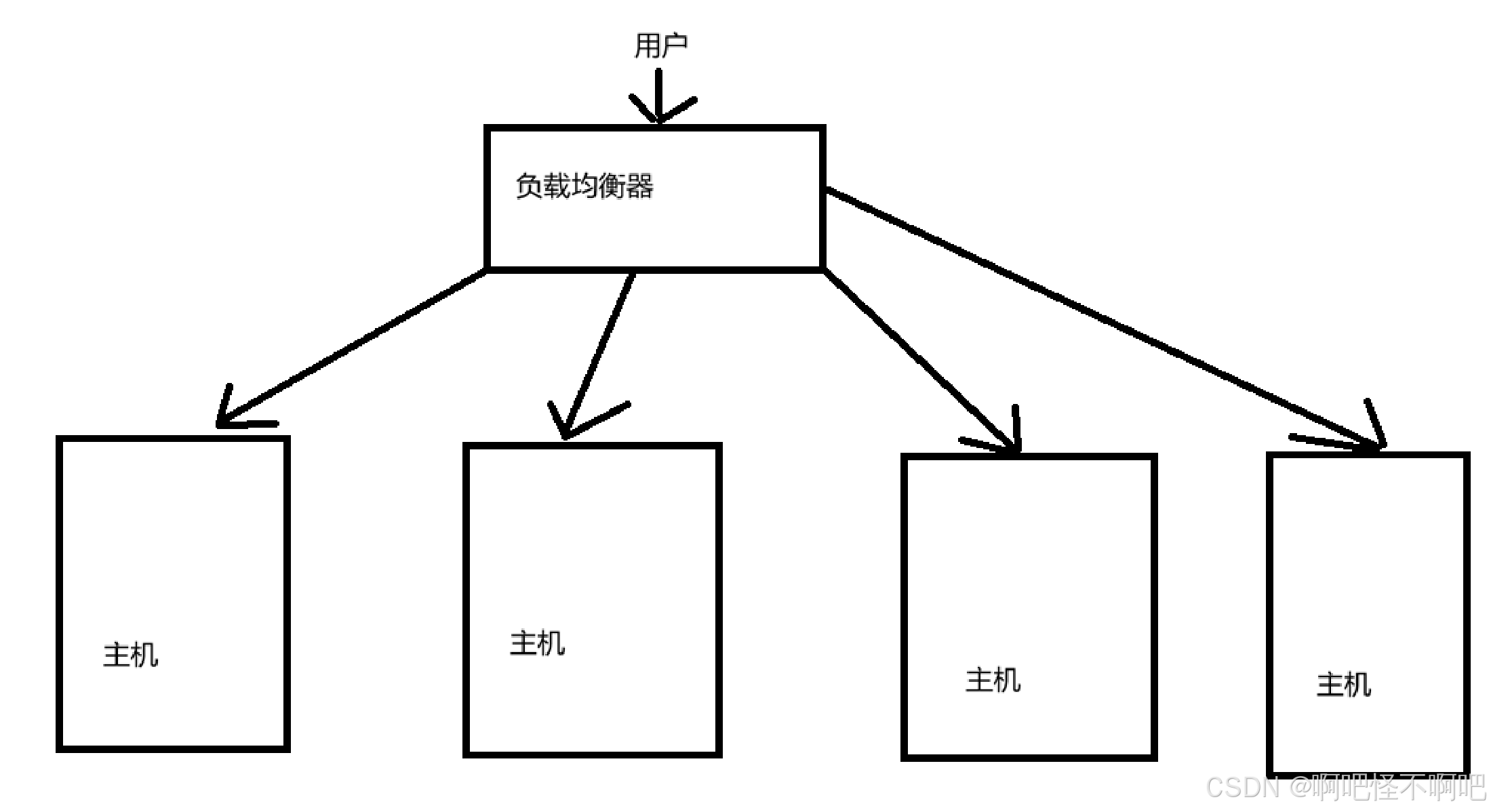
2.2 数据库分离
数据库的分离就是和上面的负载均衡思想不同的东西。当然它们的目的是一样的,都是为了更好更有效的利用主机资源。
简答来说就是更改数据库里面存储的内容,来实现更加高效的数据调用。因为已经提前知道了每一个数据库里面存放的内容,所以这样查找起来会格外的快。
2.2.1 数据库读写分离
读写分离就是根据用户请求的不同来进行分类,从而实现数据库的分离。
我们来看下面这个图片,读写分离的话就是根据用户请求的操作不同来进行分类。
- 主库(Master) :专门负责写操作(增、删、改),保证数据的一致性和事务性。
- 从库(Slave) :专门负责读操作(查询),从主库同步数据,一般可以部署多台。
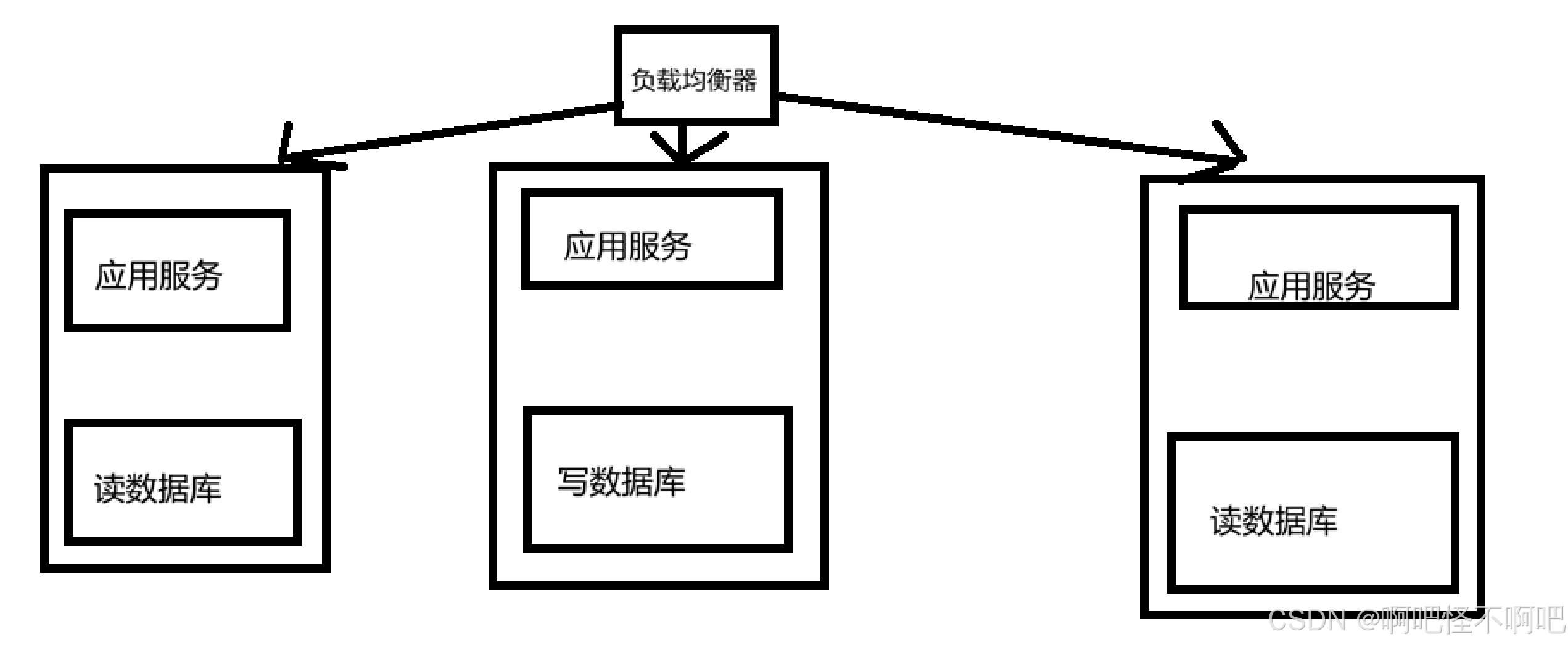
由于操作的不同,所以在这里会导致数据的不一致问题,所以在这边我们还需要会通过特定的同步机制,来让数据库达到一致。
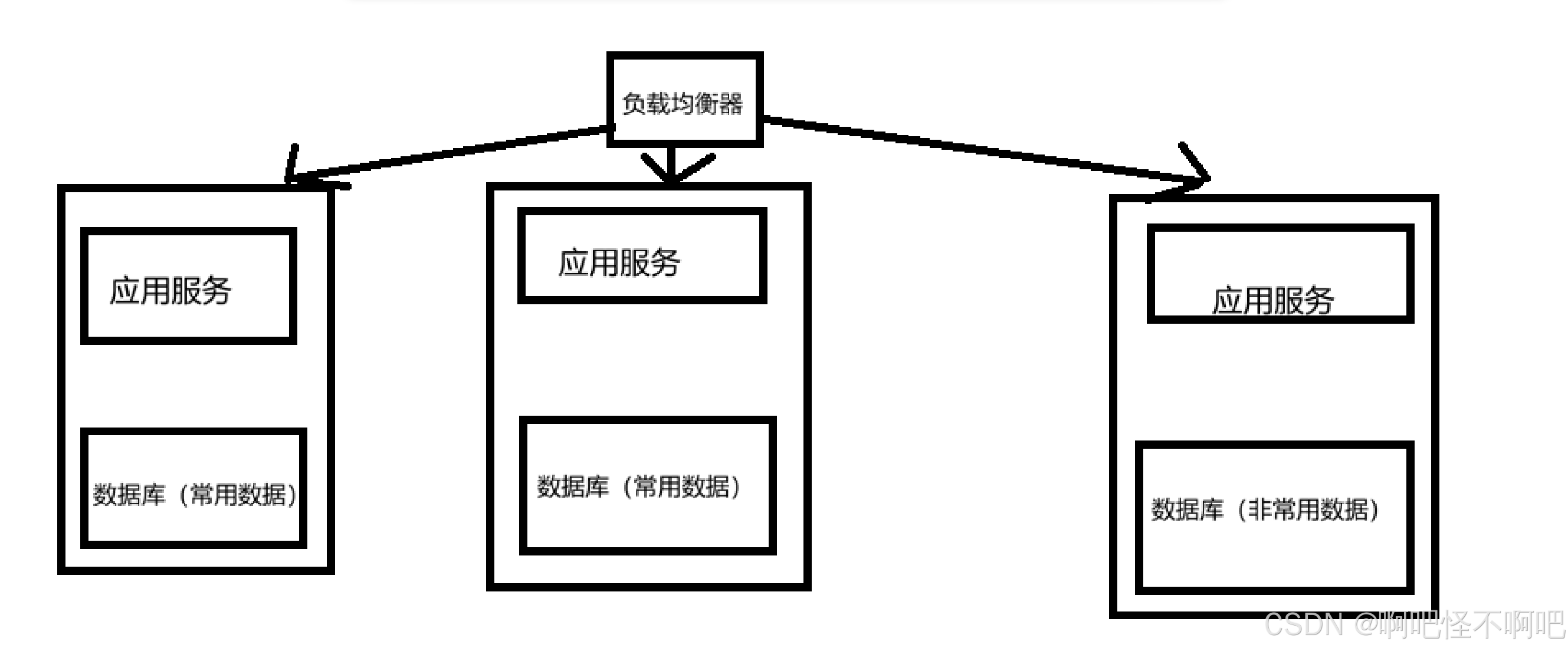
2.2.2 数据库分库分表
这个的话我们要先了解一个叫做二八定律的东西,在这里这个二八定律是指只有20%的数据会得到频繁访问,而80%的数据则很少被访问。所以我们就根据这个特性来设计主机里面的数据库。把常用的分到多几个库,把不常用的分到少几个库,这样就实现了数据库分库分表,从而提升了回应速度。
就像下面这张图一样。