🔥个人主页:胡萝卜3.0****
📖个人专栏:************************************************************************************************************************************************************************************************************************************************************《C语言》、《数据结构》 、《C++干货分享》、LeetCode&牛客代码强化刷题****************************************************************************************************************************************************************************************************************************************************************
⭐️人生格言:不试试怎么知道自己行不行
🎥胡萝卜3.0🌸的简介:


目录
[1.1 背景介绍](#1.1 背景介绍)
[1.2 核心作用](#1.2 核心作用)
[1.3 核心概念](#1.3 核心概念)
二、理解make/makefile的编译工作的推导过程,依赖关系和依赖方法
[2.1 定义:什么是依赖关系与依赖方法?在什么地方?](#2.1 定义:什么是依赖关系与依赖方法?在什么地方?)
[2.2 make 的执行引擎:它如何解读并运行你的 Makefile?](#2.2 make 的执行引擎:它如何解读并运行你的 Makefile?)
[3.1 什么是清理工程?](#3.1 什么是清理工程?)
[3.2 什么叫做总是被执行?](#3.2 什么叫做总是被执行?)
[3.3 显式与隐式:为什么make不总是执行命令,而需要.PHONY?](#3.3 显式与隐式:为什么make不总是执行命令,而需要.PHONY?)
[4.1 最佳实践](#4.1 最佳实践)
[4.2 实用语法](#4.2 实用语法)
前言
在 Linux C/C++ 开发中,当项目规模增长、源文件数量增多时,手动键入冗长的
gcc命令会迅速变得难以维护------开发者不仅要时刻厘清头文件与源文件间错综复杂的依赖关系,还需谨慎处理编译顺序,并确保每次编译参数的一致性与正确性。这正是 Makefile 与
make工具大显身手的场景。其核心价值在于 "自动化构建" :通过一份声明式的配置文件(Makefile),将编译、链接、清理等操作规则固化下来。此后,仅需一个简单的make命令,系统便能自动完成所有必要的步骤,将开发者从重复劳动中解放出来,从而极大提升开发效率和构建的可重复性。本文将从Makefile 的基本原理入手,逐步拆解其语法规则、依赖关系、伪目标、变量与函数等核心概念,最终通过一个结构清晰的工程化示例演示其完整用法。我们的目标是帮助你彻底告别"手动编译"的泥潭,系统掌握"自动化构建"的利器,从而游刃有余地应对中小型乃至更复杂的 C/C++ 项目开发。
我们将从以下几个方面进行讲解:
- 见一下,如何使用make/makefile
- 理解Makefile/make编译工作的推导过程,依赖关系和依赖方法
- 学习makefile的最常见的语法和特殊符号
一、初识构建工具:Make与Makefile
1.1 背景介绍
- 会不会写makefile,从侧面说明了一个人是否具备完成大型工程的能力
- 一个工程中的源文件不计其数,其按类型,功能,模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于更复杂的操作
- makefile 带来的好处就是 -- "自动化编译",一旦写好,只需要一个 make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
- make 是一个命令工工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi 的 make,Visual C++ 的 namke,Linux下GNU的make。可见,makefile都成为了一种在工厂方面的编译方法。
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
1.2 核心作用
- 定义源文件之间的依赖关系(如可执行文件依赖目标文件,目标文件依赖源文件);
- 指定编译规则(如如何将.c文件编译为.o文件,如何链接为可执行文件);
- 支持增量编译(只重新编译修改过的文件,减少重复工作);
- 提供项目清理功能(一键删除编译产物,方便重新构建)。
1.3 核心概念
- make:解释 Makefile 规则的命令工具,默认查找当前目录下名为Makefile或makefile的文件;
- 目标(target):要生成的文件或要执行的命令(如可执行文件、清理操作);
- 依赖(prerequisites):生成目标所需要的文件或条件(如生成myproc依赖myproc.c);
- 命令(command):生成目标的具体操作(如gcc -o myproc myproc.c),必须以 Tab 键开头
关键所在------
- **make:**一个命令
- makefile/Makefile:一个文件------描述的是如何编译当前工程(这个文件需要我们自己创建)
ok,那我们先来看一下猪跑------
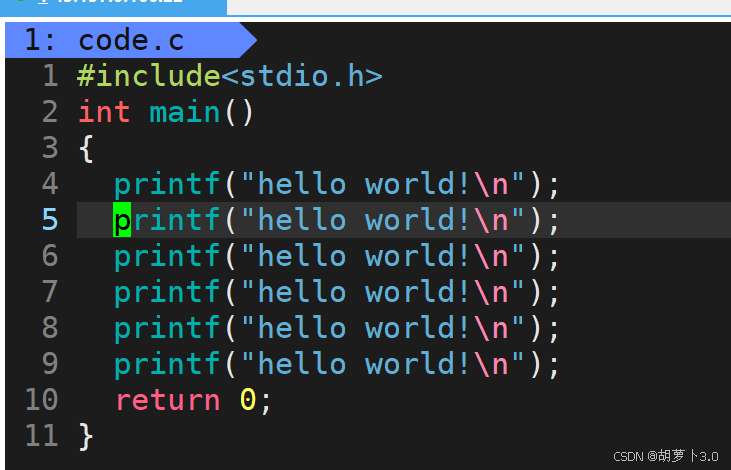
我们先来创建一个code.c源文件,并在里面写一个简单的C语言代码:
bash
[carrot@VM-0-16-centos ~]$ touch code.c
[carrot@VM-0-16-centos ~]$ vim code.c
[carrot@VM-0-16-centos ~]$ cat code.c
#include<stdio.h>
int main()
{
printf("hello world!\n");
printf("hello world!\n");
printf("hello world!\n");
printf("hello world!\n");
printf("hello world!\n");
printf("hello world!\n");
return 0;
}
ok,建完之后,我们创建一个makefile文件,并用vim 编译器打开这个文件(这里先不要管这是怎么写的)------
bash
[carrot@VM-0-16-centos ~]$ touch makefile
[carrot@VM-0-16-centos ~]$ vim makefile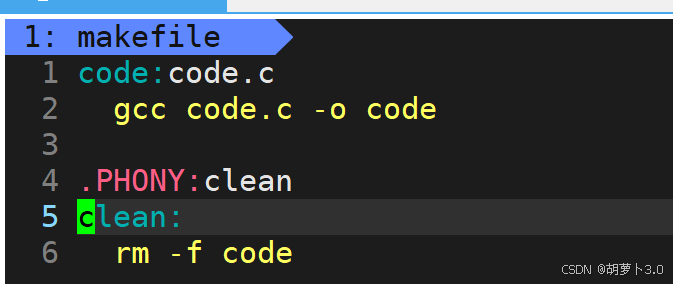
然后,执行------
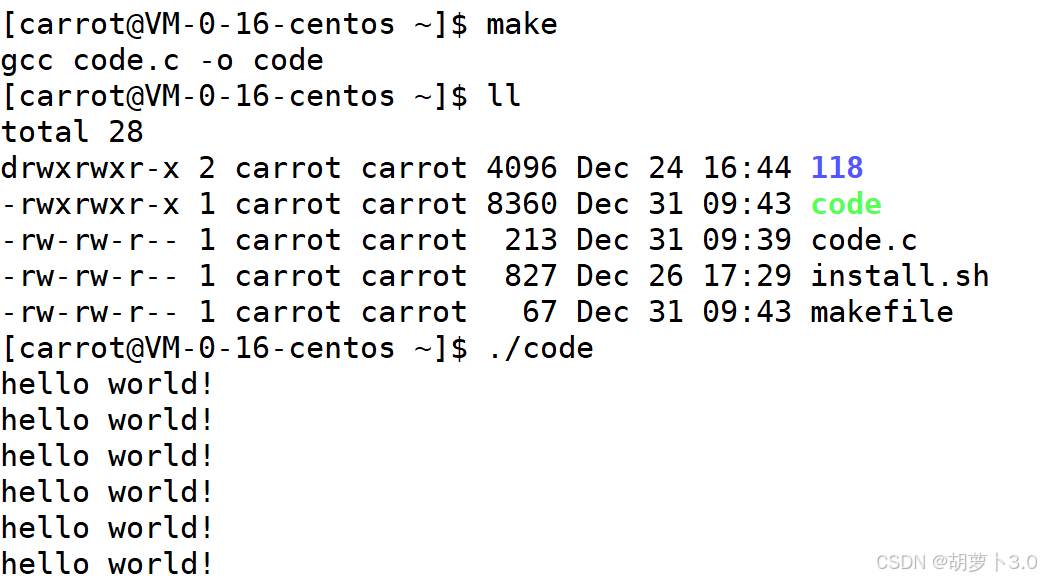
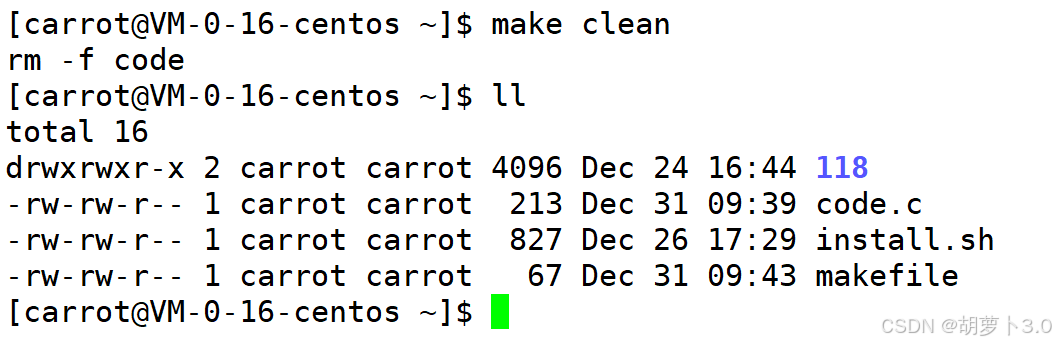
- 当我们在命令行中输入:make,它会自动的给我链接一个code的可执行程序;
- 在命令行输入:make clean,自动清理刚刚生成的可执行临时文件
我知道写到这里会有很多uu会感到疑惑?我去,这是怎么做到的。
ok,接下来我们一起来看一下这里面的原理究竟是什么?
二、理解make/makefile的编译工作的推导过程,依赖关系和依赖方法
所谓的make/makefile,其实就是一个依赖关系和依赖方法的集合!!!
2.1 定义:什么是依赖关系与依赖方法?在什么地方?
上图中所展示的就是依赖关系和依赖方法。
ok,接下来我们对上图中所展示的内容进行解释------

😯,原来makefile文件中就是存放着一些依赖文件和依赖方法的文件啊!!!
那makefile文件是怎么执行的呢?为什么是像下面的那种执行方法呢?
bash
[carrot@VM-0-16-centos ~]$ make
gcc code.c -o code
[carrot@VM-0-16-centos ~]$ make clean
rm -f code执行make就生成了code可执行程序,执行make clean 就清理了code可执行临时程序文件呢?
2.2 make 的执行引擎:它如何解读并运行你的 Makefile?
bash
[carrot@VM-0-16-centos ~]$ make
gcc code.c -o code
[carrot@VM-0-16-centos ~]$ ll
total 28
drwxrwxr-x 2 carrot carrot 4096 Dec 24 16:44 118
-rwxrwxr-x 1 carrot carrot 8360 Dec 31 09:43 code
-rw-rw-r-- 1 carrot carrot 213 Dec 31 09:39 code.c
-rw-rw-r-- 1 carrot carrot 827 Dec 26 17:29 install.sh
-rw-rw-r-- 1 carrot carrot 67 Dec 31 09:43 makefile
[carrot@VM-0-16-centos ~]$ ./code
hello world!
hello world!
hello world!
hello world!
hello world!
hello world!
[carrot@VM-0-16-centos ~]$ make clean
rm -f code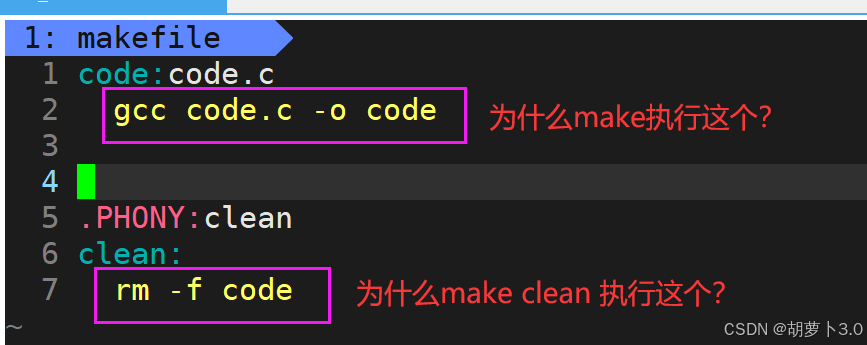
当命令行执行make命令时,make会从上往下扫描makefile文件
- 在命令行直接执行 make 命令:默认形成的是make会从上往下扫描makefile文件中第一个遇到的目标文件!!!且仅执行与该目标文件相关的依赖关系和命令
- 当 Makefile 中有多个目标文件时,我要形成确定的目标文件,使用
make 目标文件可以构建指定的目标文件
😯,原来是这样啊------
默认执行第一个目标
bash
# Makefile 示例
code: code.c # ← make 默认执行这个(第一个目标)
gcc code.c -o code
clean: # ← 这个不会默认执行
rm -f code执行逻辑:
-
make→ 自动找到第一个目标 (code) -
检查依赖关系:
code需要code.c -
如果
code.c比code新(或code不存在),执行gcc code.c -o code
指定执行特定目标
bash
# Makefile 示例
code: code.c
gcc code.c -o code
clean: # ← 需要明确指定
rm -f code执行方式:
-
make clean→ 明确告诉 make:"我要执行clean目标" -
make 会跳过默认的第一个目标,直接执行
clean对应的命令
但是一般情况下,我们会将形成可执行程序的目标文件放在最开头!!!以便我们直接执行make生成可执行程序!!!
ok,这个我们理解了之后,我们接着来看------
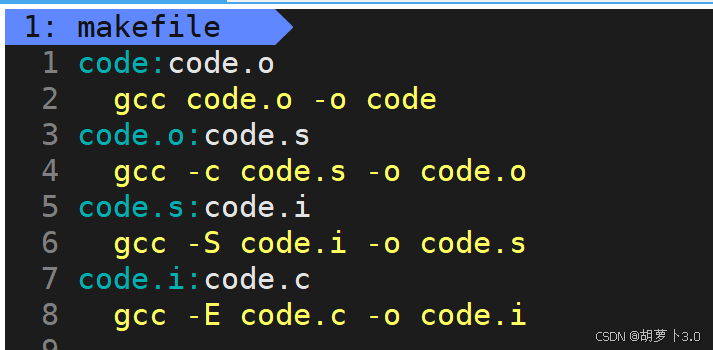
当我们在makefile文件中写出了gcc编译的详细过程,然后在命令行中直接输入:make
这时会发生什么?
执行make------
bash
[carrot@VM-0-16-centos ~]$ make
gcc -E code.c -o code.i
gcc -S code.i -o code.s
gcc -c code.s -o code.o
gcc code.o -o code 嗯?有没有发现什么?
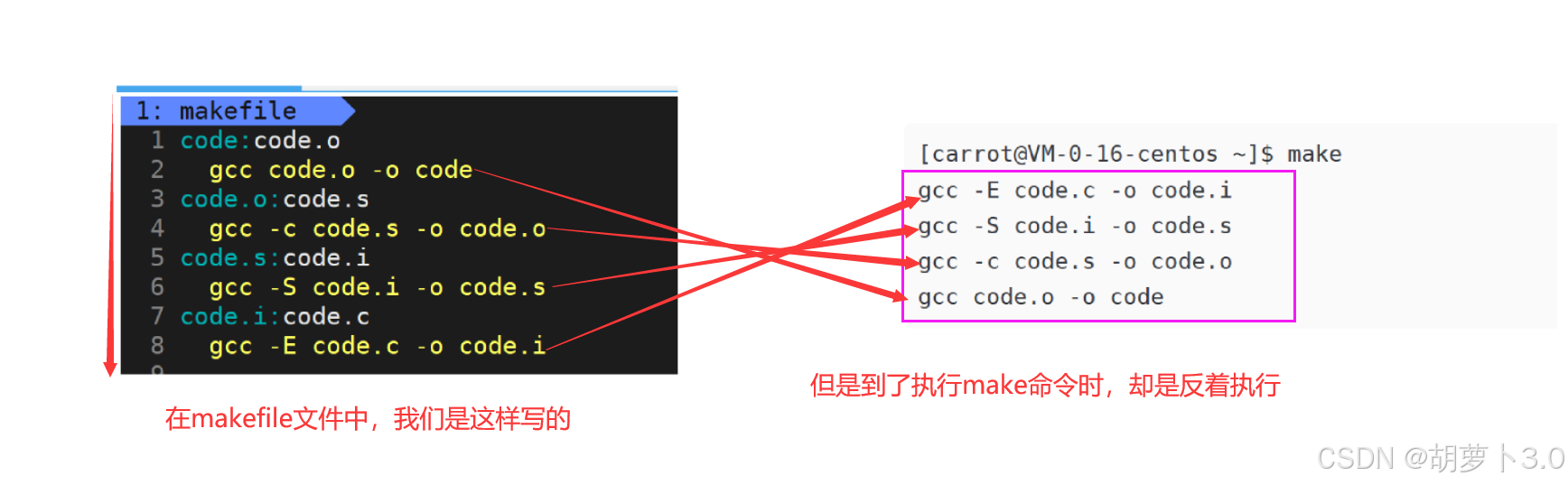
- 这是为什么?
还记得我们前面说的:make会从上向下扫描makefile文件
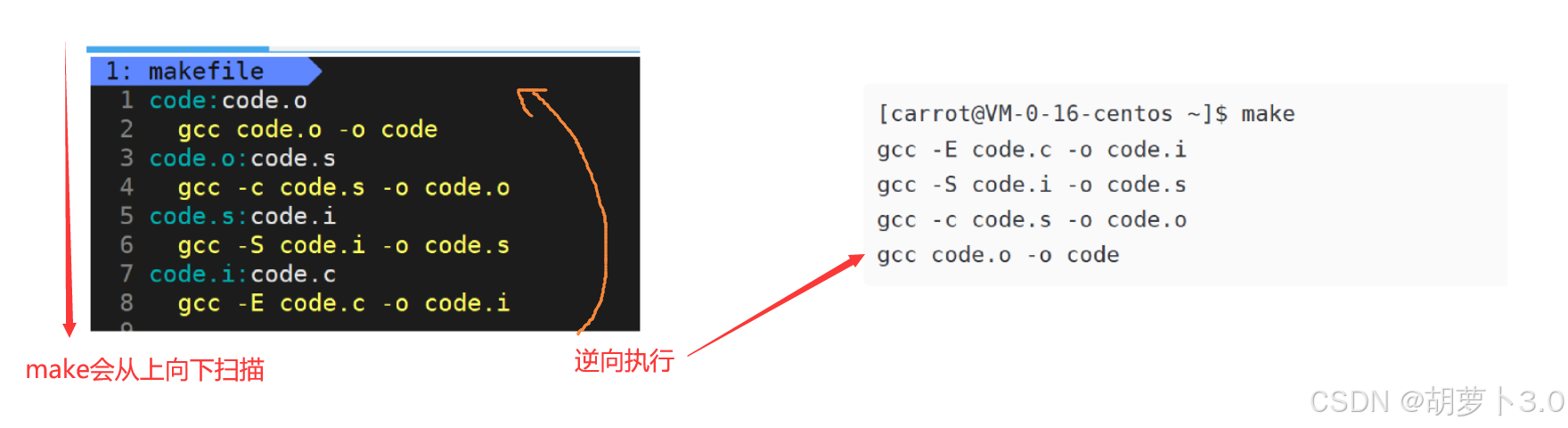
- 这是什么原理?
这个是不是就有点像栈结结构啊!其实在make命令内部会维护一个栈结构!!!

make会根据依赖关系,若依赖目标文件不存在,就把依赖方法直接入栈,直到依赖目标文件存在,然后将依赖方法出栈,依次执行依赖方法,形成目标文件

- 核心:
make会利用栈结构来对自己当前对应的依赖关系,尤其是依赖文件列表不存在时,就要将自己当前依赖方法入栈,直到推导出口(也就是依赖文件列表存在),再把所有入栈的依赖方法依次出栈,执行就可以完成语法推导
三、构建工程+清理工程
3.1 什么是清理工程?
执行 rm命令,删除工程的临时文件,就叫做清理工程
也就是这样------
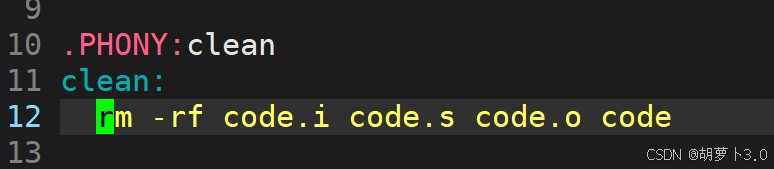
但是,这里好像有那么一点看不懂哎!

这里的依赖方法可以是任何Linux命令!!!
也就是说我们可以这样写------
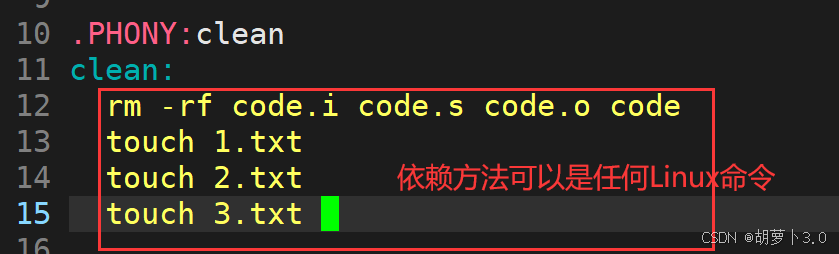
ok,这上面的内容应该都可以理解,但是这个是什么------
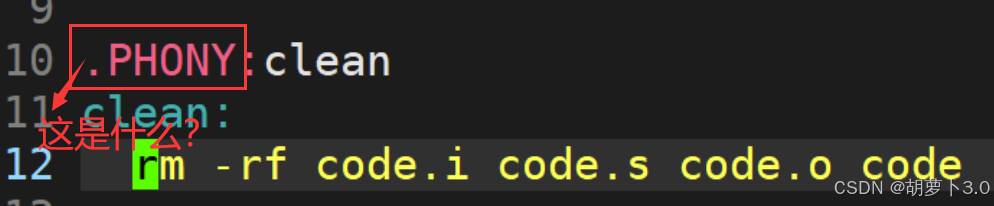
.PHONY 就如同C语言中的int,double......是一个关键词,用来形容后序跟的clean,表明他是一个伪目标。
.PHONY 是一个修饰词,告诉make clean是一个伪目标,伪目标也是目标,也有依赖方法。
伪目标表达的含义是:被 .PHONY 修饰的目标文件,他所对应的依赖方法总是被执行
啥意思?什么叫做总是被执行?
3.2 什么叫做总是被执行?
在看总是被执行之前,我们先来看看不总被执行
- 不总被执行,那就是目标文件 没有被 .PHONY 修饰
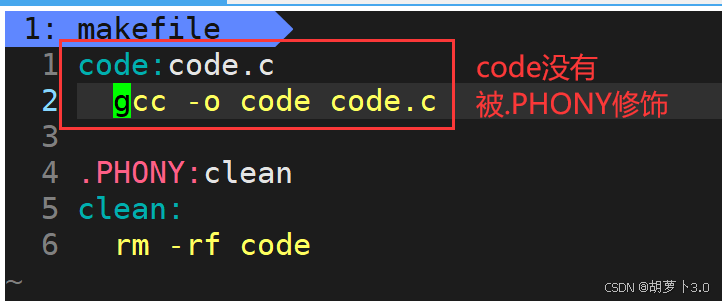
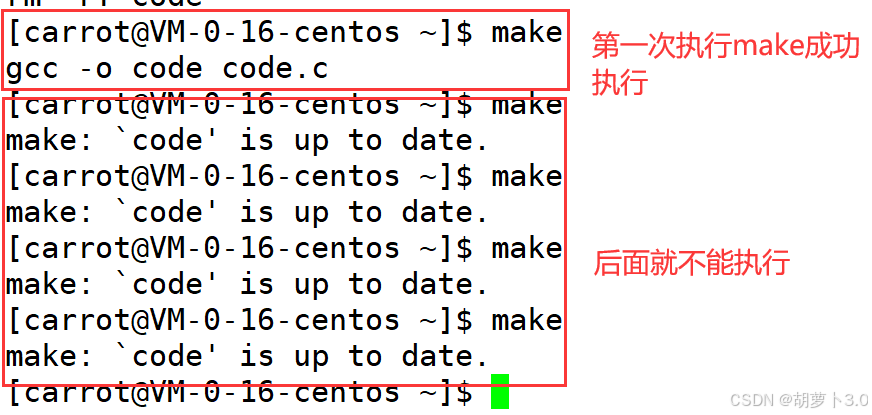
- 我们再来看总是被执行(也就是目标文件被.PHONY修饰)------

所以,.PHONY关键字一旦修饰目标文件,就代表着将来依赖的某种方法,未来总是被执行,每一次都会被执行
但是,最佳实践:
- clean 用.PHONY ,形成工程;其他目标可执行文件,不建议用.PHONY修饰
3.3 显式与隐式:为什么make不总是执行命令,而需要.PHONY?
为什么?为什么默认不带.PHONY,对应的gcc和make默认不让我总是被执行?

- .PHONY修饰目标文件时,代表的是:不要管目标文件是新还是旧,直接调用依赖方法
- .PHONY不修饰目标文件,gcc就要去关心修饰目标文件是老的还是新的,有没有被修改过
在这里,我们要秉承一个原则------
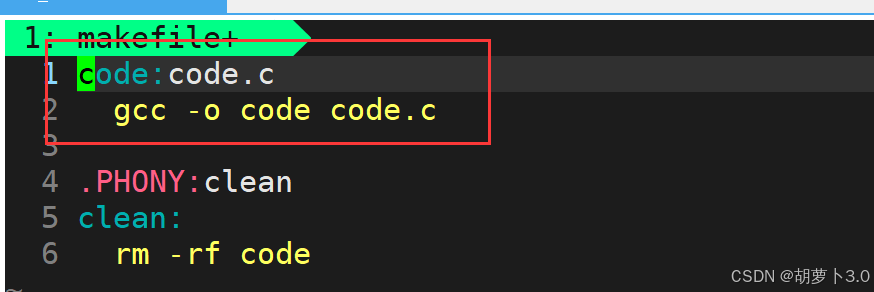
目标文件可以执行,不建议使用.PHONY修饰,code可执行文件就是要让gcc形成程序时,维持一个不总被执行的特性,只会编译新文件
通过上面的解释,我们只能明白.PHONY的作用是什么,并没有真正理解为什么是这样做的。
ok,那通过下面的一个问题,我们就能理解了------
- make是如何知道code.c是否需要被重新编译?
那我们就需要来看几个时间了------
bash
[carrot@VM-0-16-centos ~]$ stat code.c
File: 'code.c'
Size: 213 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 786967 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ carrot) Gid: ( 1001/ carrot)
Access: 2025-12-31 09:39:45.160827997 +0800
Modify: 2025-12-31 09:39:45.159827991 +0800
Change: 2025-12-31 09:39:45.159827991 +0800
Birth: -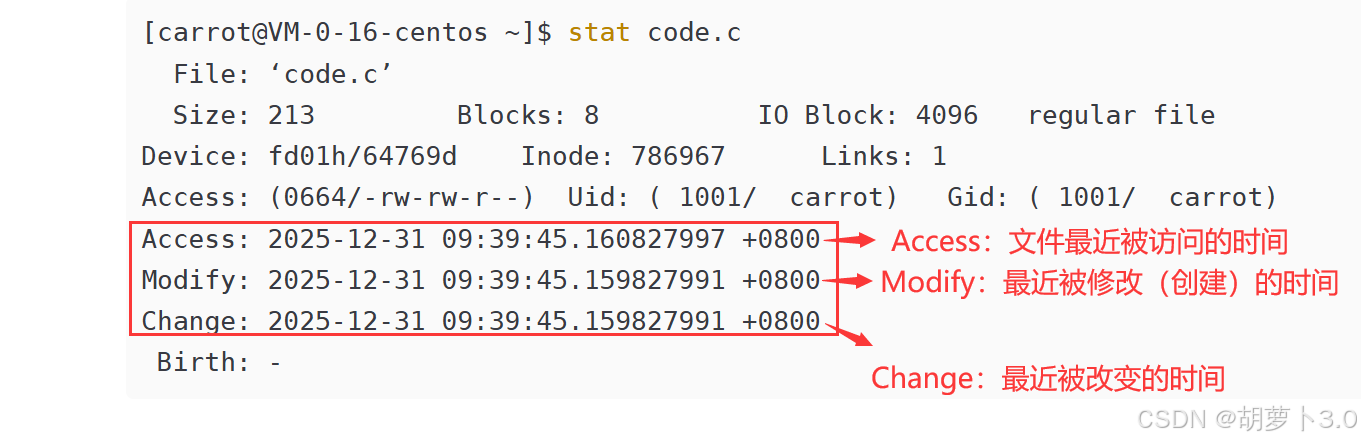
那为什么要说这个时间呢?
我们知道文件=内容+属性
- 修改属性:单纯的修改文件所对应的属性就会更改Change时间
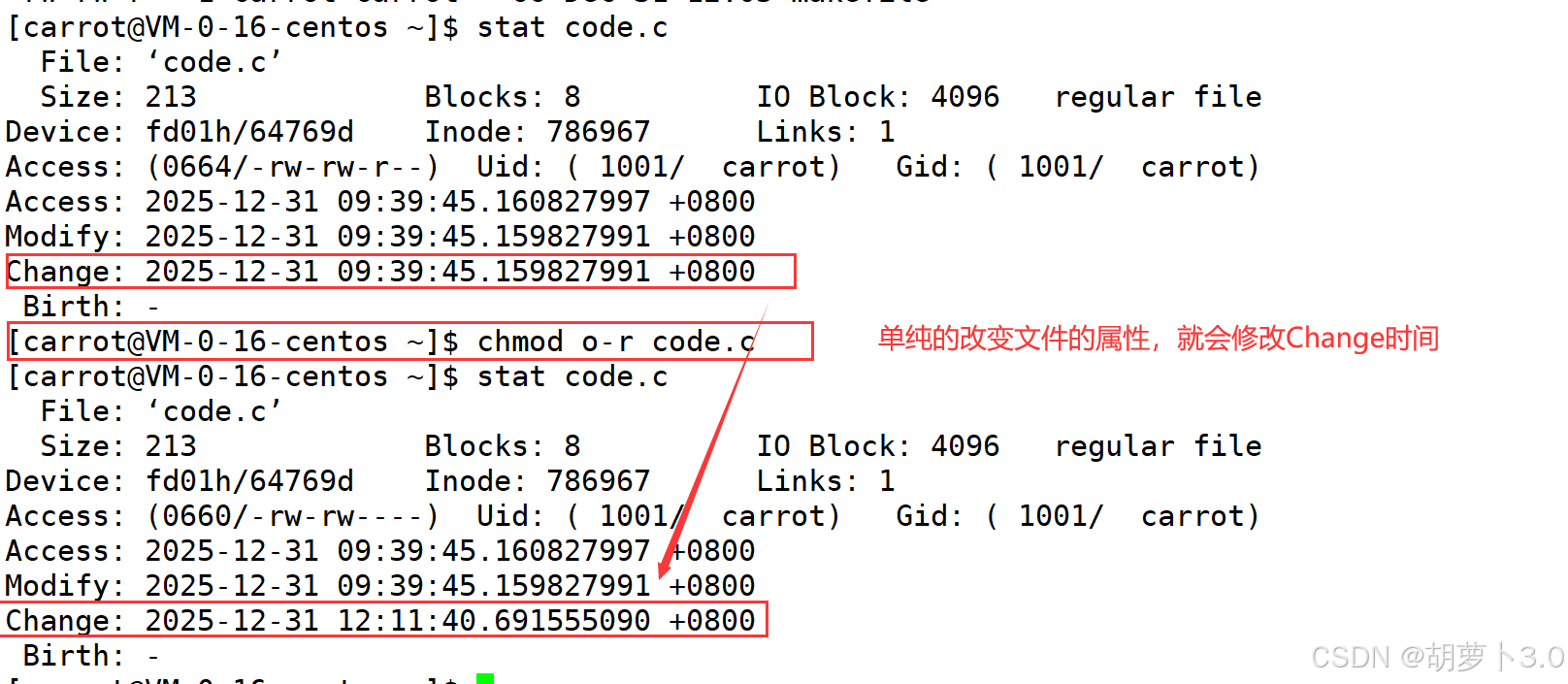
- 修改内容:单纯的修改内容,就会更改Modify时间和Change时间(改变内容,文件属性会自动改变)
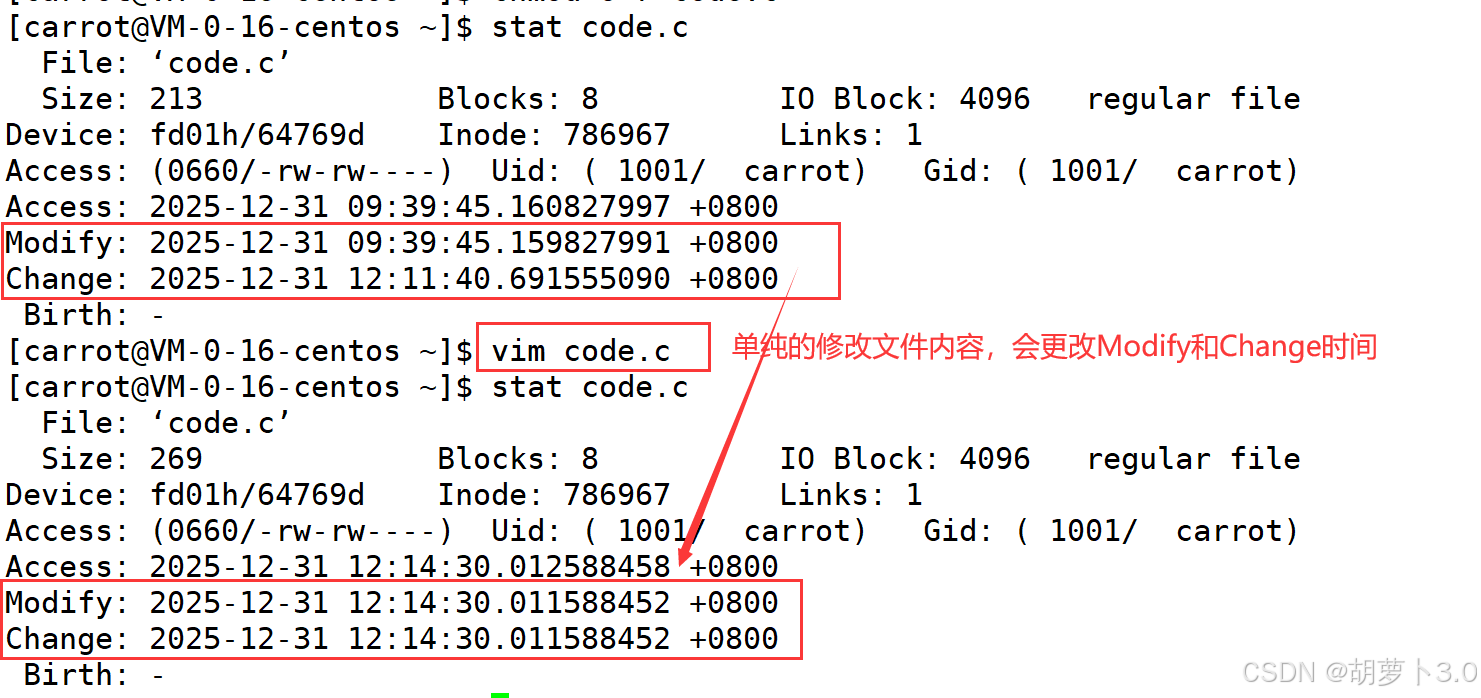
但是这个Access时间有点不同------
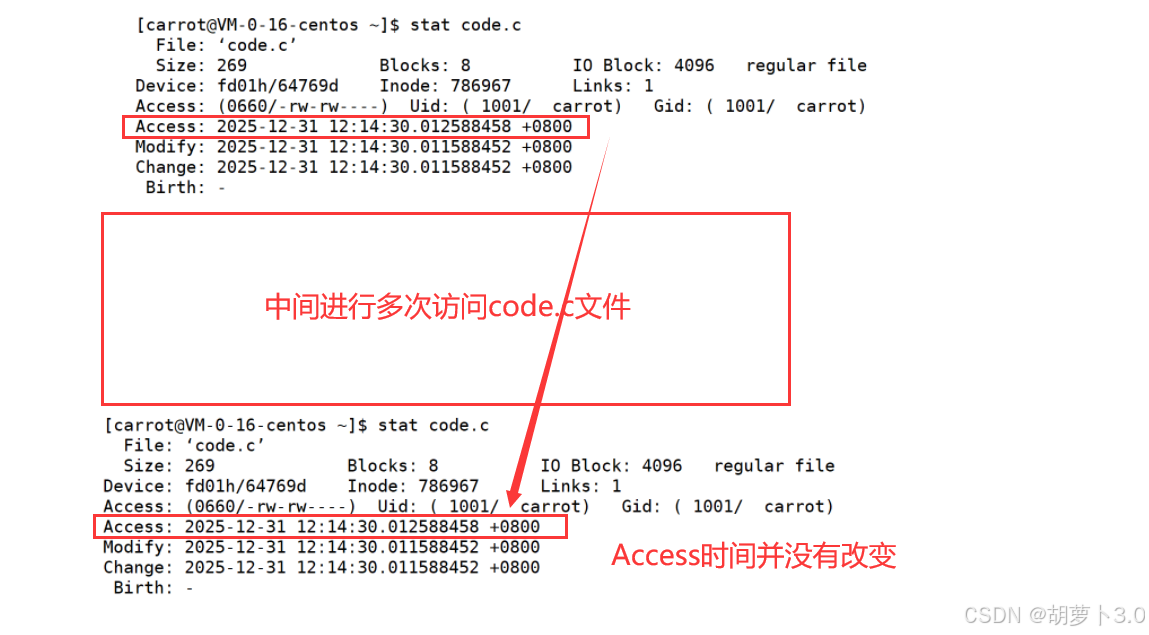
在未来的程序中,我们会经常对文件进行访问的操作,如果每次访问文件,都要修改相应的Access时间,是不是有点浪费,所以:访问文件若干次后,Access时间才会修改,不是时时更新,它有自己的更新策略,和系统有关
补充命令:
bash
# 将A C M 时间更新到系统的最新时间
touch 已存在文件那我怎么知道文件有没有被修改,这个指标是什么?
- Modfiy时间
make可以通过对比Modfiy时间来看文件是否被修改!!!
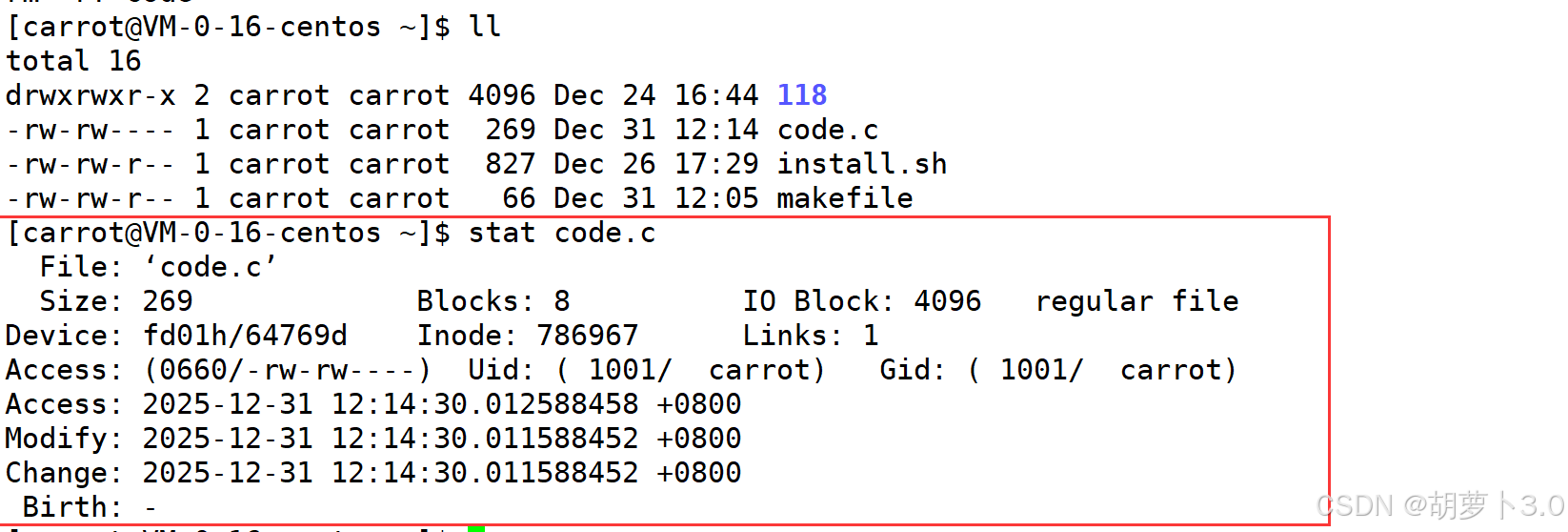
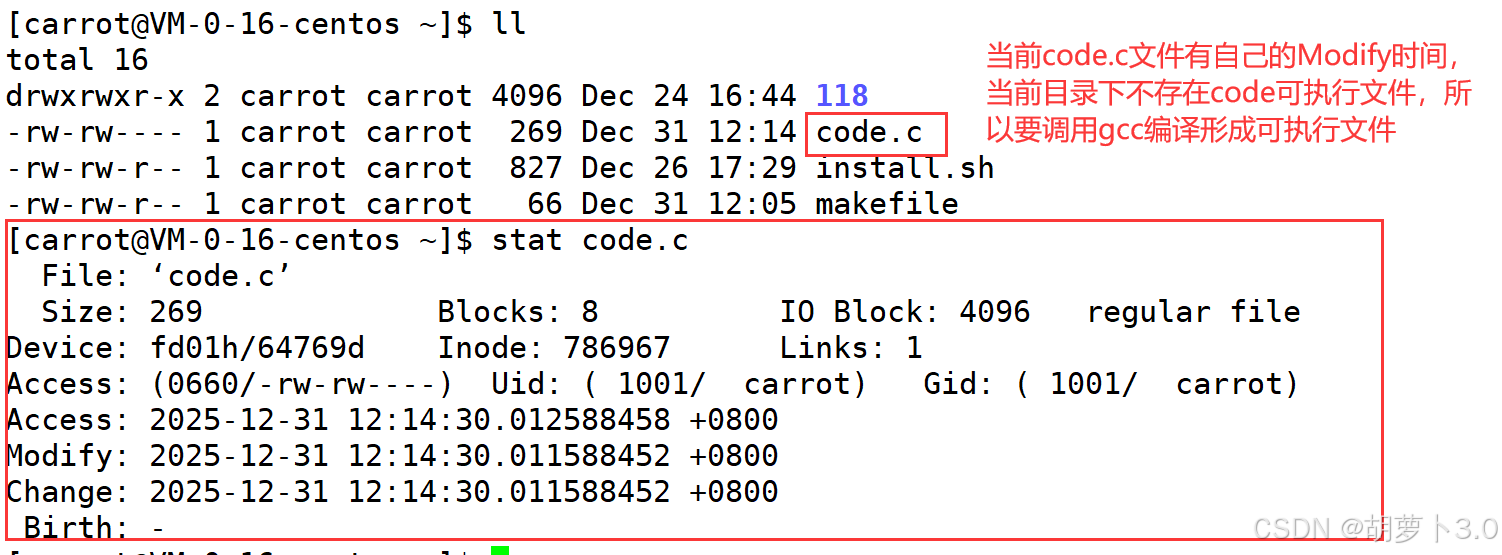
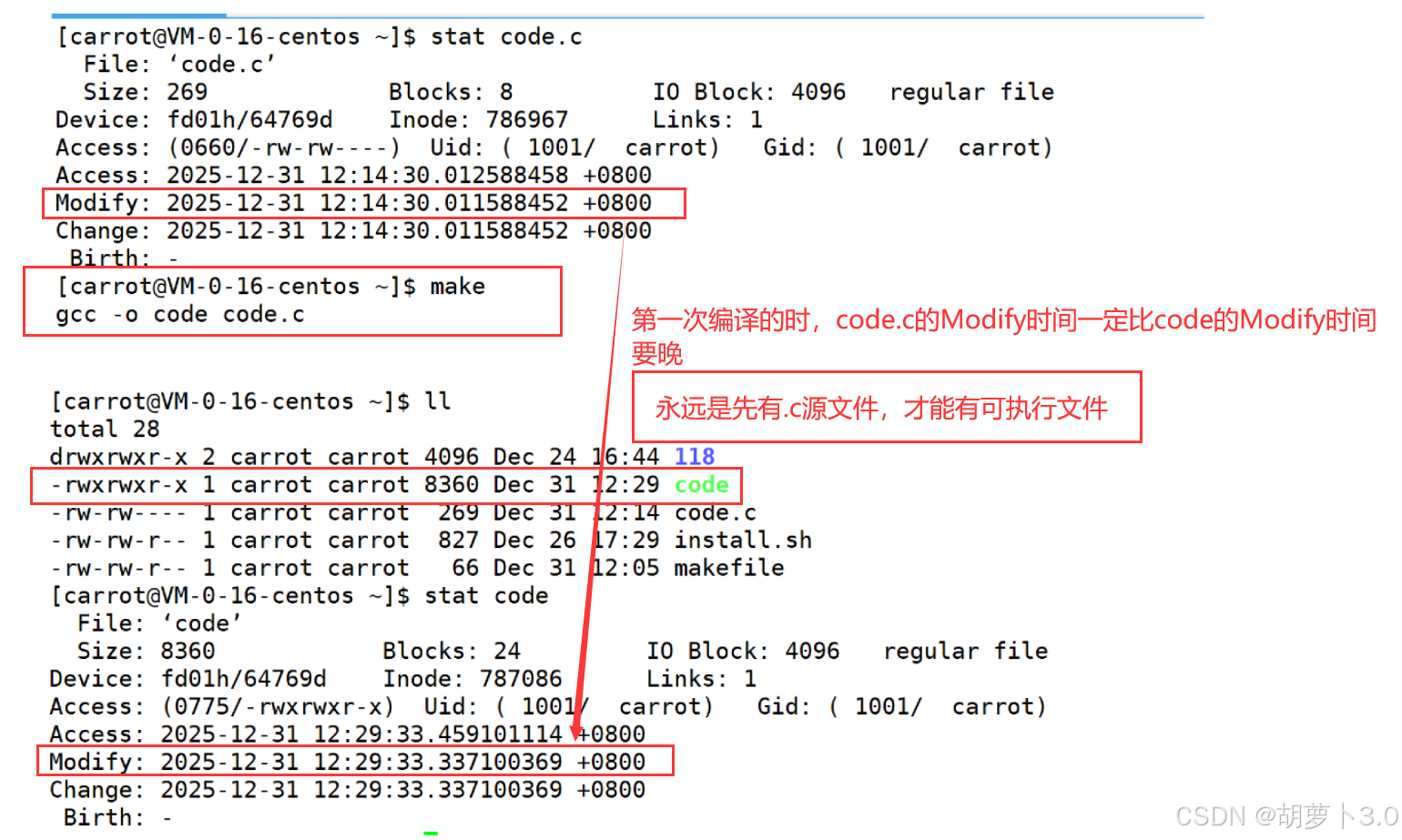
- 总结:
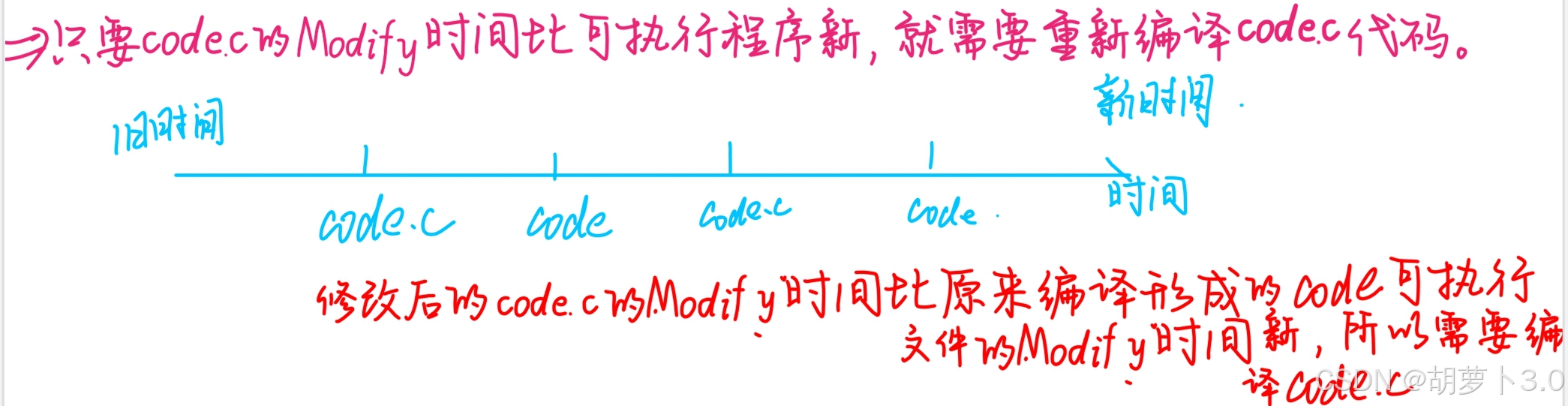
判断目标文件和源文件到底需不需要编译------
取决于Modify时间:比较两个文件的Modify时间谁更新
- 若可执行程序的Modify时间更新,就不需要重新编译;
- 若源文件的Modify时间更新,就需要重新编译代码
那我们会过头来看一下:.PHONY修饰目标文件是怎么做到让依赖方法总是被执行呢?
.PHONY忽略源文件和可执行文件的Modify时间对比,就可以让依赖方法总是被执行
四、makefile最佳实践和实用语法
4.1 最佳实践
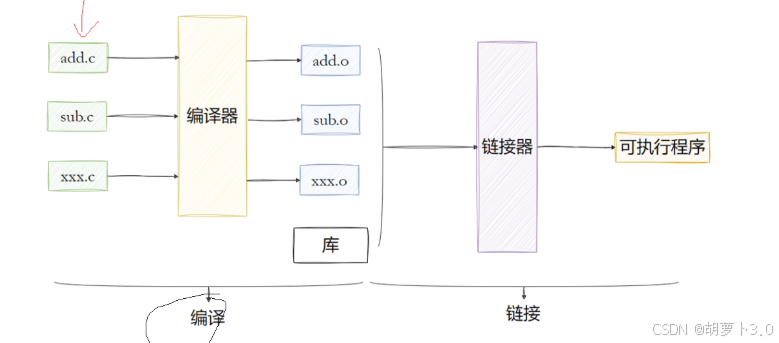
**最佳实践:**先将源文件编成 .o 文件,然后再把 .o 文件链接成 可执行文件
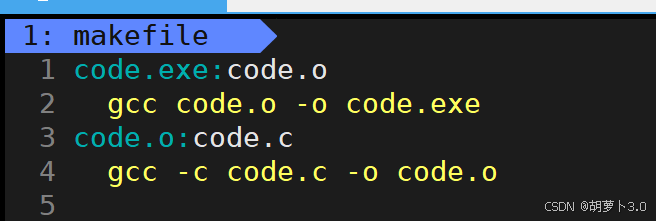
- 还有一种简洁的写法:
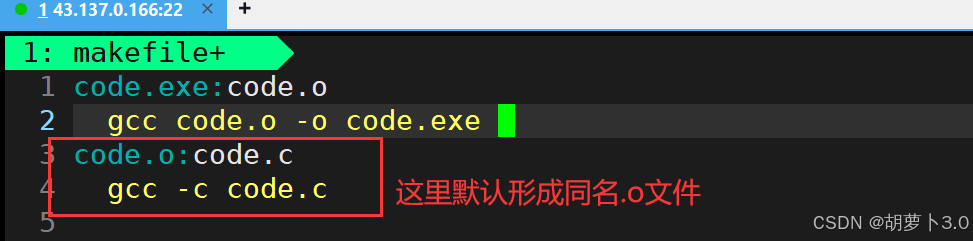
4.2 实用语法
语法1:
bash
1: makefile ? ? ?? buffers
1 code.exe:code.o
2 gcc -o $@ $^
3 code.o:code.c
4 gcc -c code.c语法解释:
-
code.exe:code.o:目标code.exe依赖于code.o -
gcc -o $@ $^:编译命令-
$@:代表目标文件名(code.exe) -
$^:代表所有依赖文件(code.o)
-
相当于:
bash
code.exe: code.o
gcc -o code.exe code.o解释:
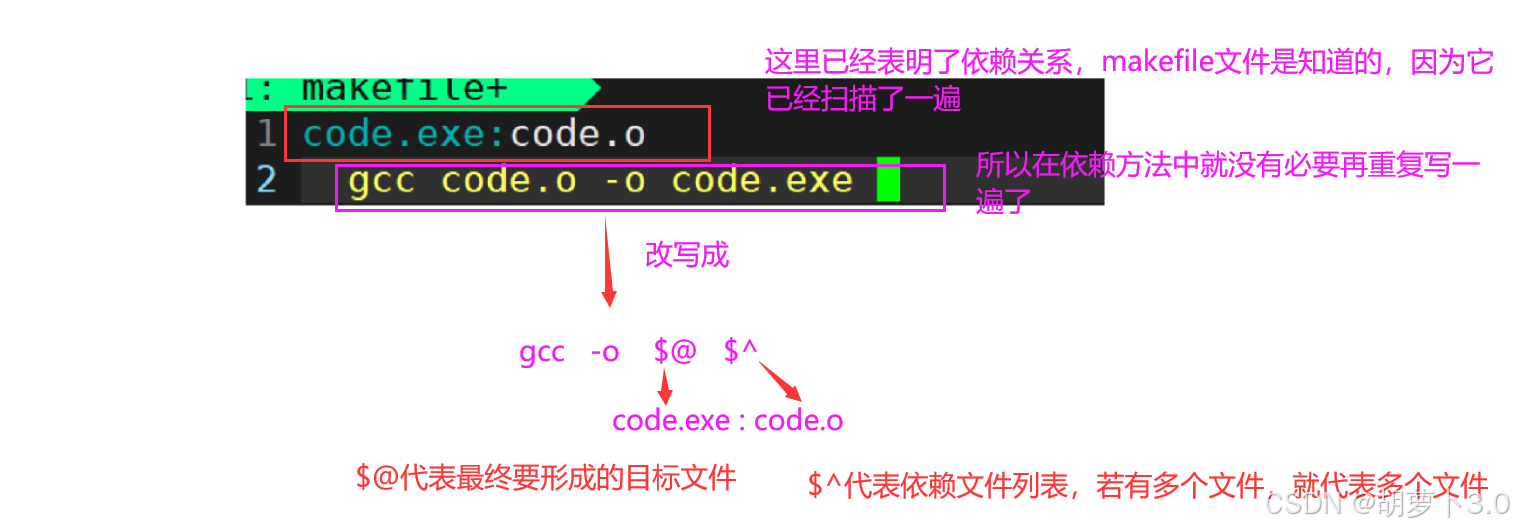
语法2:
makefile文件中可以定义变量
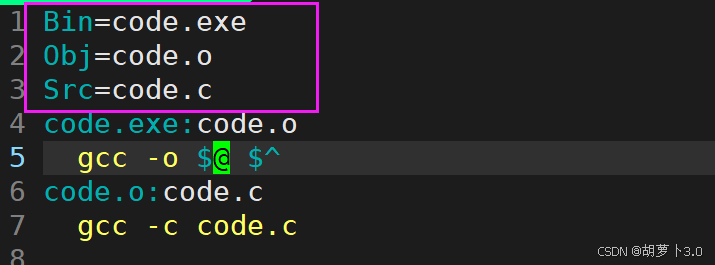
在定义了变量之后,我们就可以对上面的依赖方法进行改写------
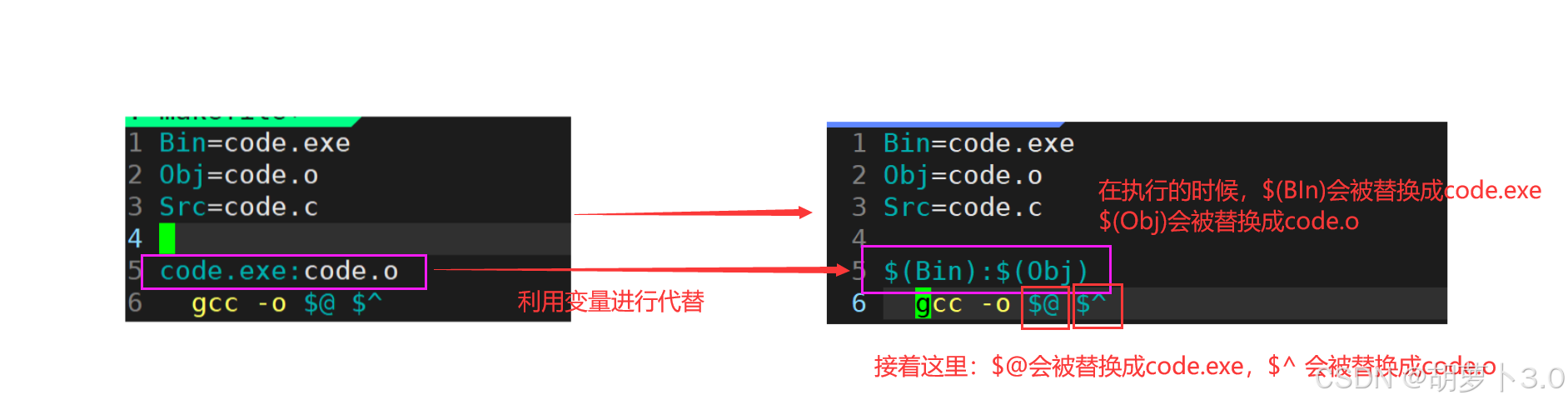
语法3:
此时,博主有一个想法,想在每个执行的步骤前面,给个提醒,让我们知道此时进行的是哪一步,我们可以这样做:
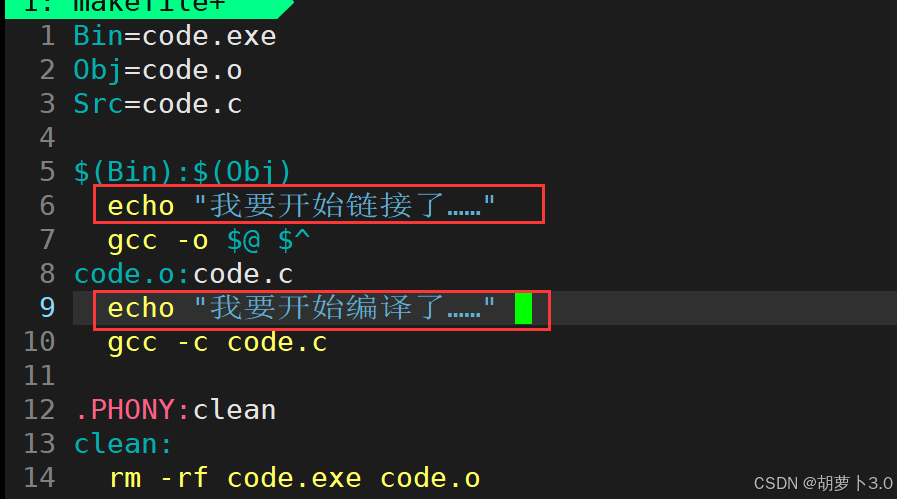
在命令行执行一下make------
bash
[carrot@VM-0-16-centos ~]$ make
echo "我要开始编译了......"
我要开始编译了......
gcc -c code.c
echo "我要开始链接了......"
我要开始链接了......
gcc -o code.exe code.o😯,在这里确实知道我要进行哪一步,但是echo命令会显了,makefile执行任何命令都会把命令给回显到显示器上。
但是,此时我不想让命令回显出来,直接回显字符串就可以了,那我们可以这样做------
- 命令前+@:禁止makefile对命令进行回显

bash
[carrot@VM-0-16-centos ~]$ make
我要开始编译了......
gcc -c code.c
我要开始链接了......
gcc -o code.exe code.o我们在执行命令前面带@,不要让他把命令的执行过程回显出来,方便后续对makefile的输出进行定制化输出
注意:
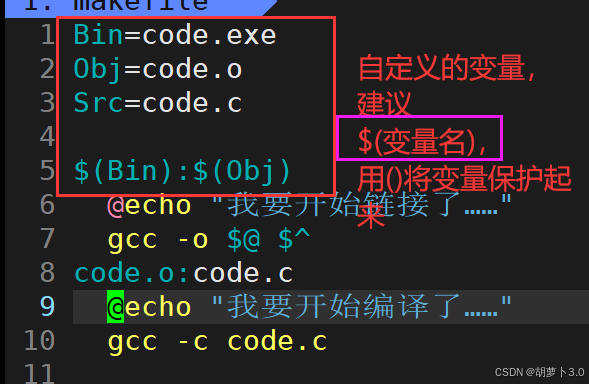
除此之外,我们还可以在echo的双引号里面添加变量,echo的双引号里面可以直接识别变量的内容------
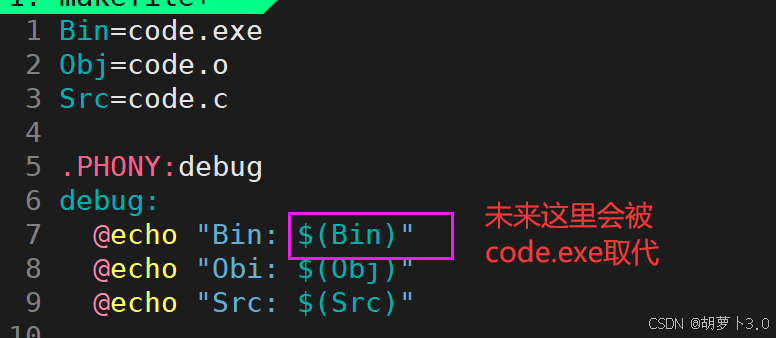
bash
[carrot@VM-0-16-centos ~]$ make debug
Bin: code.exe
Obi: code.o
Src: code.c既然我们可以对文件名取变量,那我们就可以对命令取个变量------
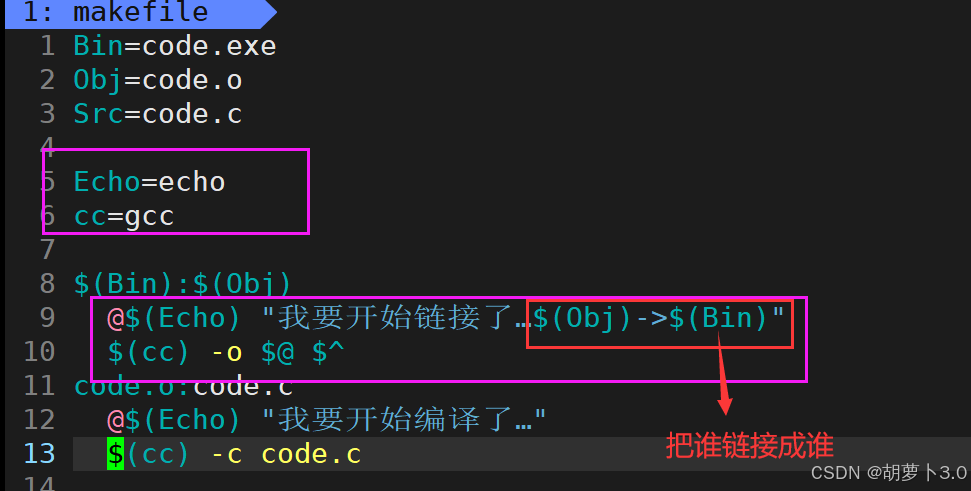
语法4:
接下来,我们对这块进行符号化------

这里可以这样替换------
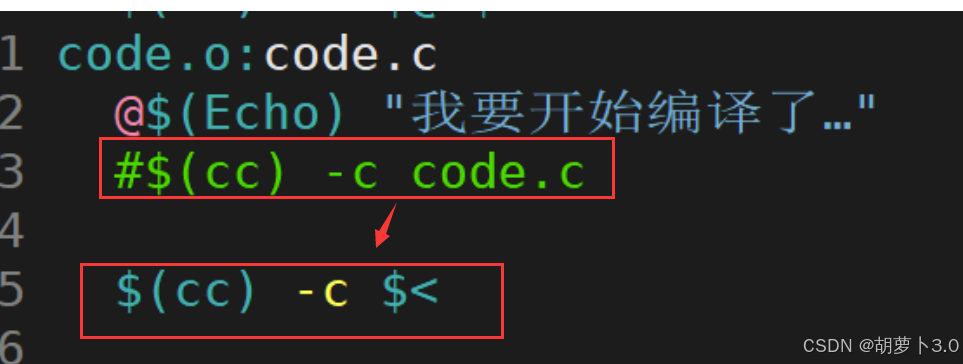
这里的意思就是------
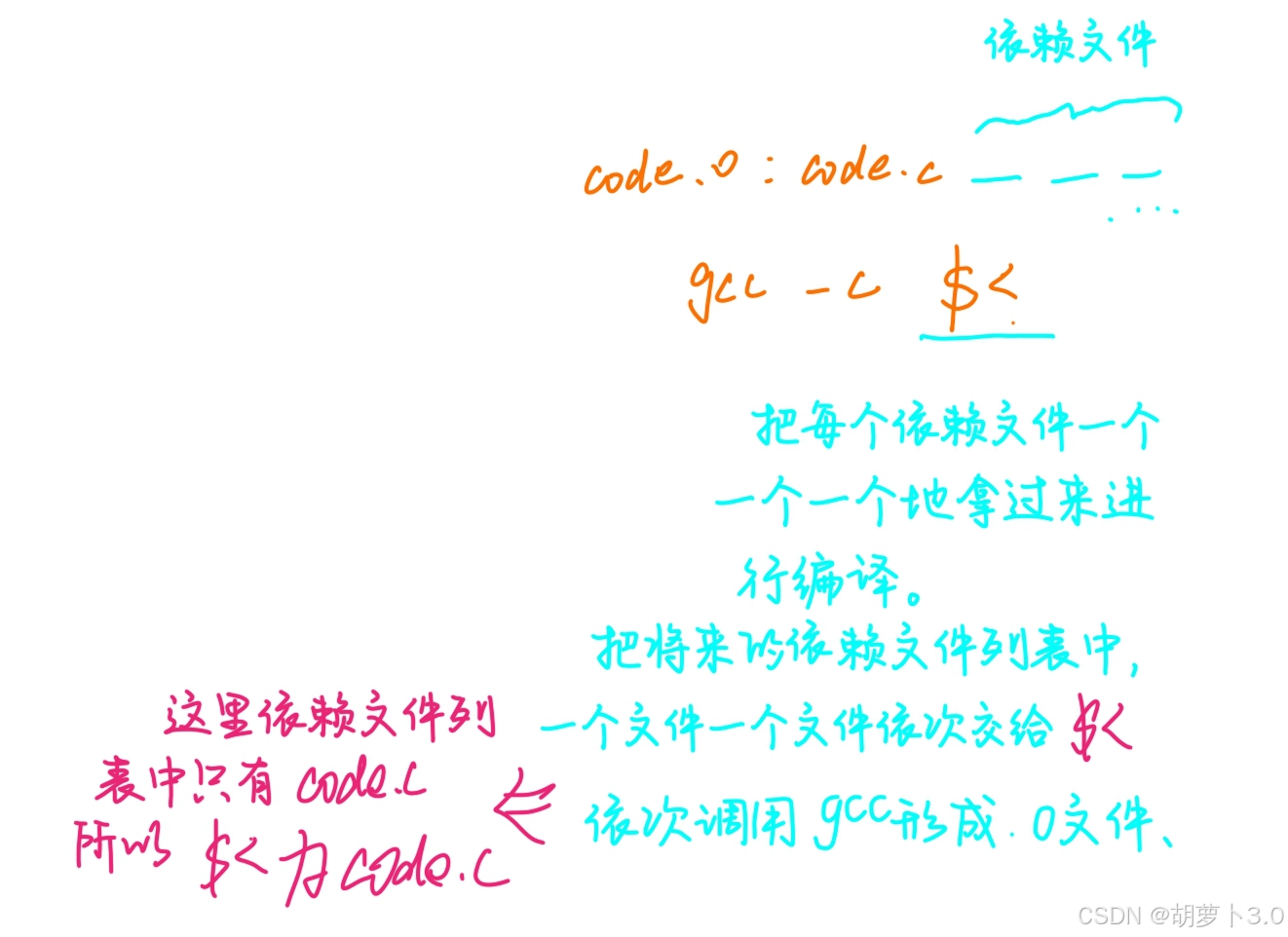
语法5

在makefile中,一般把源文件**.c文件** 编译成**.o文件,** 并不需要把 .o文件 和.c文件的名字明确写出来
我们可以这样写------


%.o 有点像***.c**,都是通配符!!!
那这里的这个是什么意思呢?

ok,假设我们这里有多个源文件:code.c code1.c code2.c,这里的意思就是------
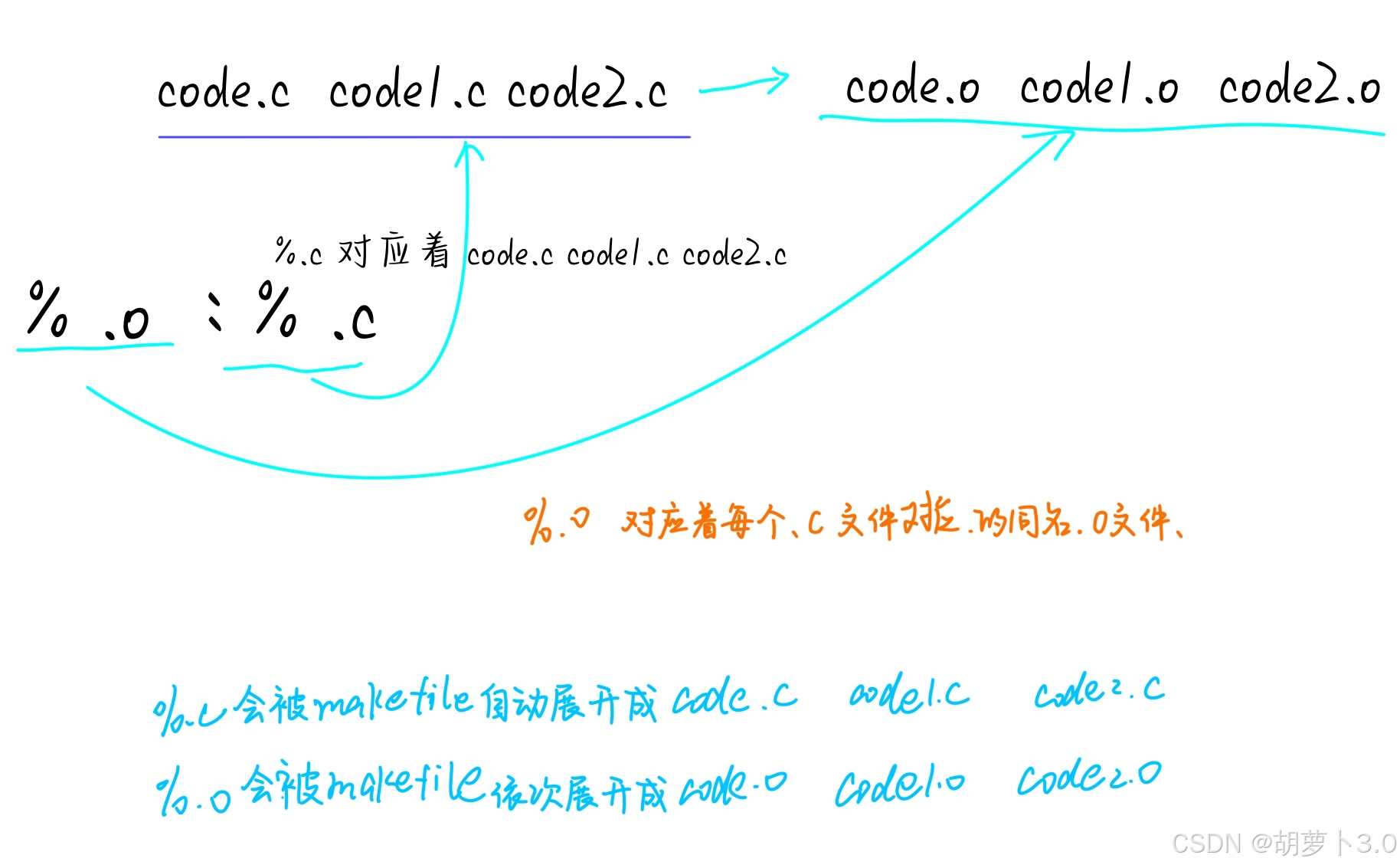
或者这样理解------

假设现在我们创建了10个.c源文件,并且要对这些源文件都要编译成可执行文件,该怎么做呢?
- 首先,我们必须获取所有源文件:
那我们这样获取吗?

一个一个列举吗?是不是有点太挫了
动态获取当前目录下的所有源文件:
bash
Src=$(shell ls *.c) #做法1
Src=$(wildcard *.c) #做法2 做法1的意思是:执行shell命令ls *.c,然后把ls *.c的结果作为变量的内容赋给Src
- 然后,我们要将所有的源文件编译成.o文件
动态地将所有源文件编译成.o文件
bash
Obj=$(Src:.c=.o) 将Src中的每一个以 .c 结尾的文件统一改成同名的 .o文件,makefile自动识别它!!!
- 完整代码------
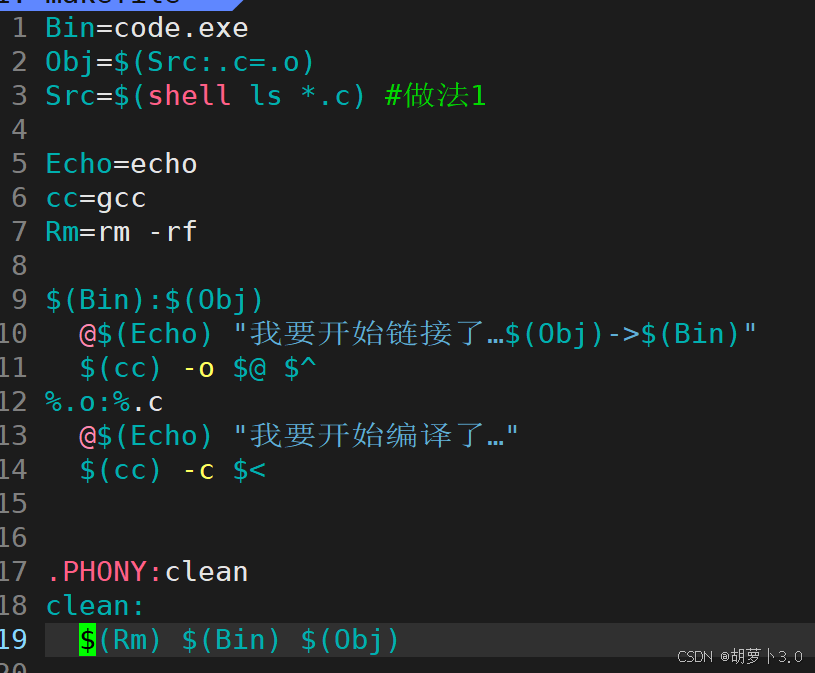
命令行输入:make,运行结果------
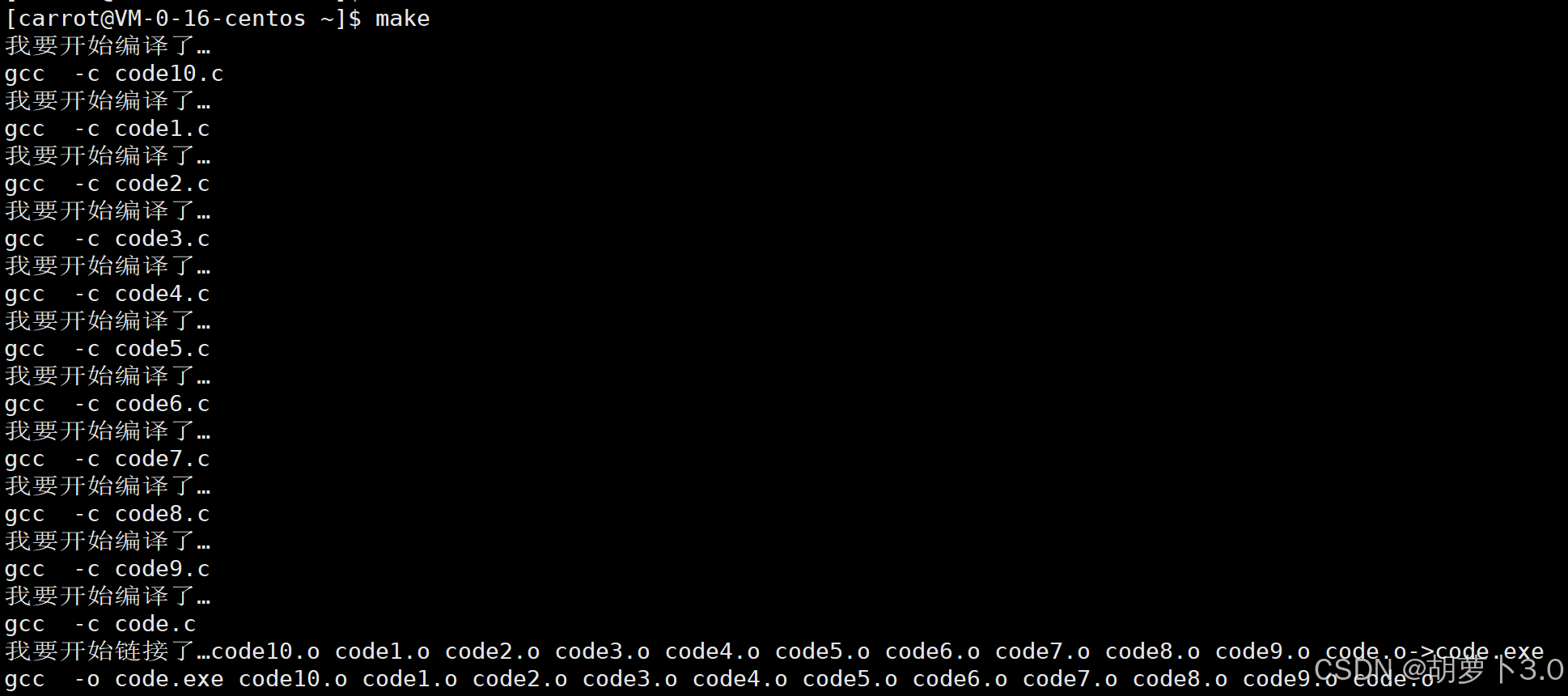
makfile可以直接帮助我们把当前目录下的所有.c源文件依次展开成同名的 .o文件,然后.o文件依次被链接,有多少个源文件就被展开成多少份!!!

结尾
希望对学习Linux相关内容的uu有所帮助,不要忘记给博主"一键三连"哦!