欢迎来到我的博客,代码的世界里,每一行都是一个故事

🎏:你只管努力,剩下的交给时间
🏠 :小破站
【TextIn大模型加速器 + 火山引擎】基于 Dify 构建企业智能文档中枢:技术文档问答+合同智审+发票核验一站式解决方案
-
- 一、企业文档处理的三大痛点
- [二、解决方案:TextIn + 火山引擎 + Dify 三位一体](#二、解决方案:TextIn + 火山引擎 + Dify 三位一体)
-
- [2.1 为什么选择 TextIn?](#2.1 为什么选择 TextIn?)
- [2.2 为什么选择火山引擎豆包大模型?](#2.2 为什么选择火山引擎豆包大模型?)
- 三、场景故事:一张泳道图说清全流程
- [四、技术方案:从 0 到 1 搭建全流程](#四、技术方案:从 0 到 1 搭建全流程)
-
- [4.1 第一步:获取 TextIn API 密钥](#4.1 第一步:获取 TextIn API 密钥)
- [4.2 第二步:配置火山引擎大模型](#4.2 第二步:配置火山引擎大模型)
- [4.3 第三步:创建 Dify Chatflow 应用](#4.3 第三步:创建 Dify Chatflow 应用)
- [4.4 第四步:搭建知识库(技术文档问答场景)](#4.4 第四步:搭建知识库(技术文档问答场景))
- [4.5 第五步:搭建 Dify 工作流](#4.5 第五步:搭建 Dify 工作流)
- [4.6 第六步:合同审核场景实现](#4.6 第六步:合同审核场景实现)
- [4.7 第七步:发票核验场景实现](#4.7 第七步:发票核验场景实现)
- [4.8 第八步:技术文档问答场景](#4.8 第八步:技术文档问答场景)
- 五、效果指标
- 六、总结与展望
本文将从企业实际痛点出发,详细介绍如何利用 TextIn 通用文档解析能力 + 火山引擎豆包大模型 + Dify 工作流编排,构建一套覆盖技术文档问答、合同风险审核、发票智能核验的企业级文档处理中枢。
一、企业文档处理的三大痛点
在企业数字化转型过程中,文档处理一直是被低估却又无处不在的效率黑洞。我在实际项目中观察到三类典型场景:
痛点一:技术文档散落,知识传承断层
研发团队的代码规范、架构设计、接口文档散落在 Confluence、语雀、本地 Word 各处。新人入职问"变量命名规范是什么",老员工要翻半小时才能找到那份 PDF。更糟的是,PDF 里的表格、代码块根本没法直接搜索。
痛点二:合同审核靠人肉,风险条款易遗漏
法务或采购拿到一份 20 页的软件开发合同,需要逐条比对付款条款、违约责任、知识产权归属。人工审核一份合同平均 2-3 小时,遇到中英文混排的跨国合同更是噩梦。关键是,人会疲劳,第 18 页的"自动续约"条款很可能就被漏掉了。
痛点三:发票核验手工录入,报销周期漫长
财务每月处理上百张发票,需要手动核对发票号码、金额、销售方信息,再录入 ERP 系统。一张发票平均耗时 3-5 分钟,遇到扫描件模糊的情况还得反复确认。员工抱怨报销慢,财务抱怨工作量大。
这三个场景有一个共同特点:文档格式多样(PDF/Word/扫描件/图片)、内容结构复杂(表格/多栏/印章)、处理流程重复。传统的 OCR + 人工复核模式已经无法满足效率要求。
二、解决方案:TextIn + 火山引擎 + Dify 三位一体
针对上述痛点,我设计了一套"企业智能文档中枢"方案,核心架构如下:
整体思路是:
- TextIn 负责"看懂"文档:将 PDF、Word、扫描件等 20+ 格式统一解析为结构化 Markdown,保留表格、标题、段落的层级关系
- 火山引擎豆包大模型负责"理解"内容:基于解析结果进行语义分析、风险识别、信息抽取
- Dify 负责"串联"流程:通过可视化工作流编排,实现文档类型判断、分支处理、结果输出
2.1 为什么选择 TextIn?
在调研了多家文档解析服务后,我选择 TextIn 的核心原因有三:
| 对比维度 | TextIn | 传统 OCR 方案 |
|---|---|---|
| 格式支持 | 20+ 格式(PDF/Word/PPT/扫描件/OFD 等) | 通常仅支持图片 |
| 输出格式 | Markdown + bbox 坐标,保留结构 | 纯文本,丢失格式 |
| 表格处理 | 精准还原行列关系,支持合并单元格 | 表格识别率低,常错乱 |
| 多语言 | 50+ 语言,中英日韩混排无压力 | 需要切换语言包 |
关键优势:输出 Markdown + bbox
这一点对 RAG 场景至关重要。TextIn 不仅输出文本内容,还保留了每个元素的位置坐标(bbox)。这意味着:
- 表格的行列关系被完整保留,不会变成一堆乱码
- 标题层级清晰,便于后续按章节分块
- 可以实现"点击答案定位原文"的溯源功能
2.2 为什么选择火山引擎豆包大模型?
火山引擎的 Doubao-Seed-1.6 模型在中文理解和推理能力上表现优异,特别适合处理中文合同、发票等场景。更重要的是:
- 支持深度思考模式,复杂合同条款分析更准确
- 256K 长上下文窗口,20 页合同一次性输入无压力
- 与 Dify 原生集成,配置简单
三、场景故事:一张泳道图说清全流程
在动手搭建之前,先用一张泳道图说明整个系统的数据流转:
业务系统 火山引擎大模型 TextIn解析引擎 Dify工作流 用户 业务系统 火山引擎大模型 TextIn解析引擎 Dify工作流 用户 场景一:技术文档问答 场景二:合同风险审核 场景三:发票智能核验 提问"Java类命名规范?" 知识库向量检索 检索结果 + 问题 Doubao-Seed-1.6 深度思考 生成专业回答 返回规范说明 + 代码示例 上传合同文档 发送文档二进制 通用文档解析(pdf_to_markdown) 返回结构化Markdown Markdown + 审核Prompt 条款分析 + 风险识别 风险报告(高/中/低) 展示风险条款 + 修改建议 (可选)推送审核结论 上传发票图片/PDF 发送发票文件 发票识别 + 字段提取 返回发票结构化数据 结构化数据 + 核验Prompt 字段校验 + 合规检查 核验结果 + JSON输出 展示发票信息 + 报销建议 推送JSON到财务/ERP系统
| 用户操作 | TextIn 解析引擎 | 火山引擎大模型 | Dify 工作流 | 业务系统输出 |
|---|---|---|---|---|
| 上传技术文档 | 通用文档解析 → md+bbox | - | 向量化入库 + RAG检索 | 知识库更新 |
| 提问技术问题 | - | Doubao-Seed-1.6 深度思考 | 知识库召回 + LLM回答 | 返回专业答案 |
| 上传合同 | 通用文档解析 → 条款结构化 | 风险条款识别 + 分析 | 条件判断 + 结果编排 | 风险报告 |
| 上传发票 | 发票识别 → 字段提取 | 结构化JSON输出 | 合规校验 + 格式转换 | 推送财务系统 |
四、技术方案:从 0 到 1 搭建全流程
4.1 第一步:获取 TextIn API 密钥
访问 TextIn 工作台(注册即送 3000 页体验额度),在「账号与开发者信息」页面获取 x-ti-app-id 和 x-ti-secret-code:
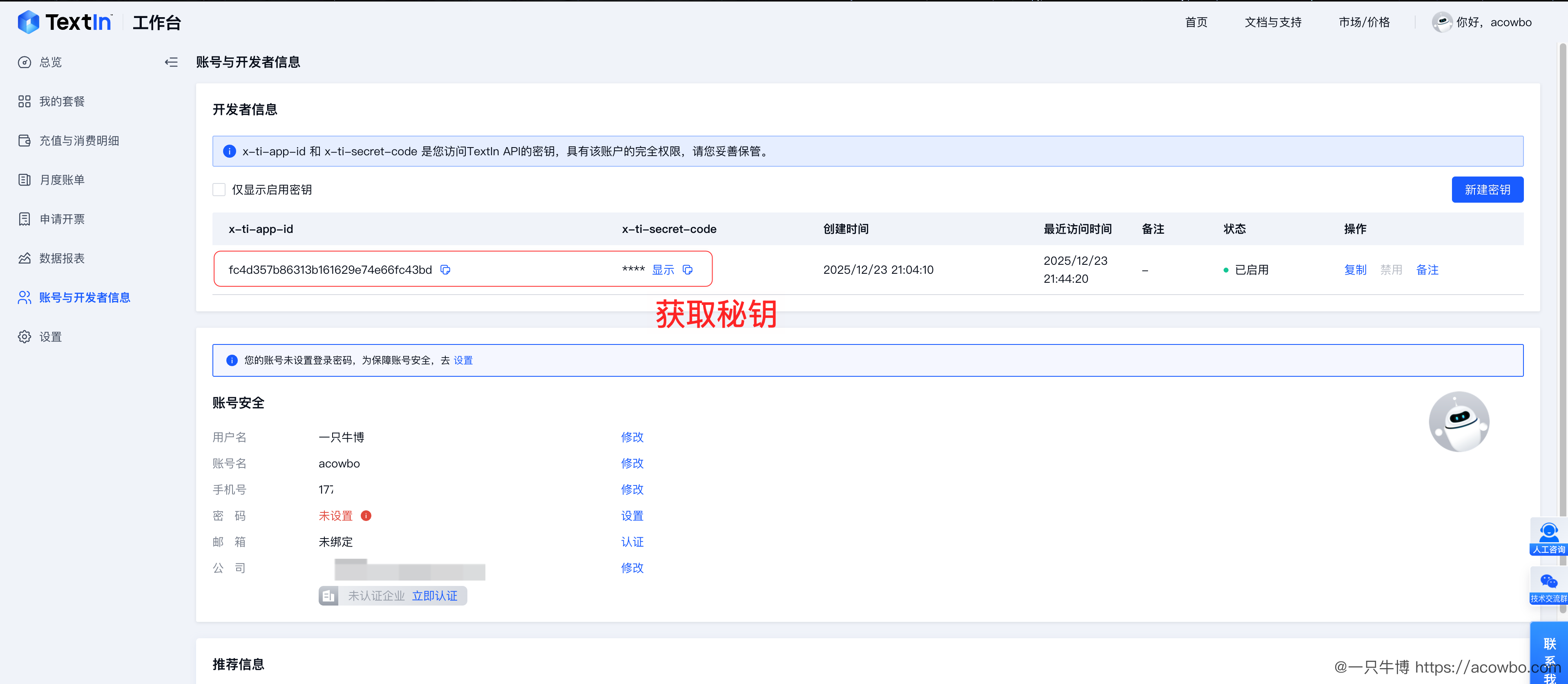
这两个参数是调用 TextIn API 的凭证,后续在 Dify 工作流中会用到。
4.2 第二步:配置火山引擎大模型
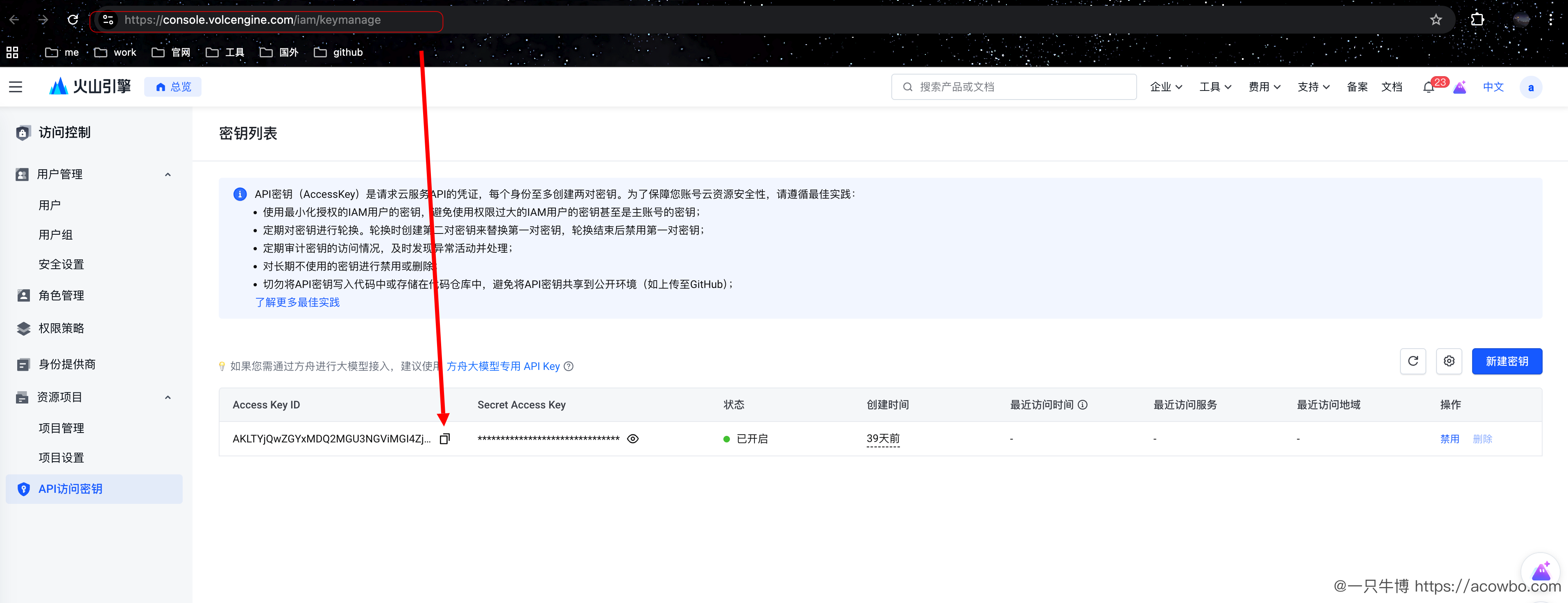
登录火山引擎控制台,进入「火山方舟」服务:
2.2.1 获取 API 访问密钥
在「访问控制 → API 密钥」页面创建 Access Key:
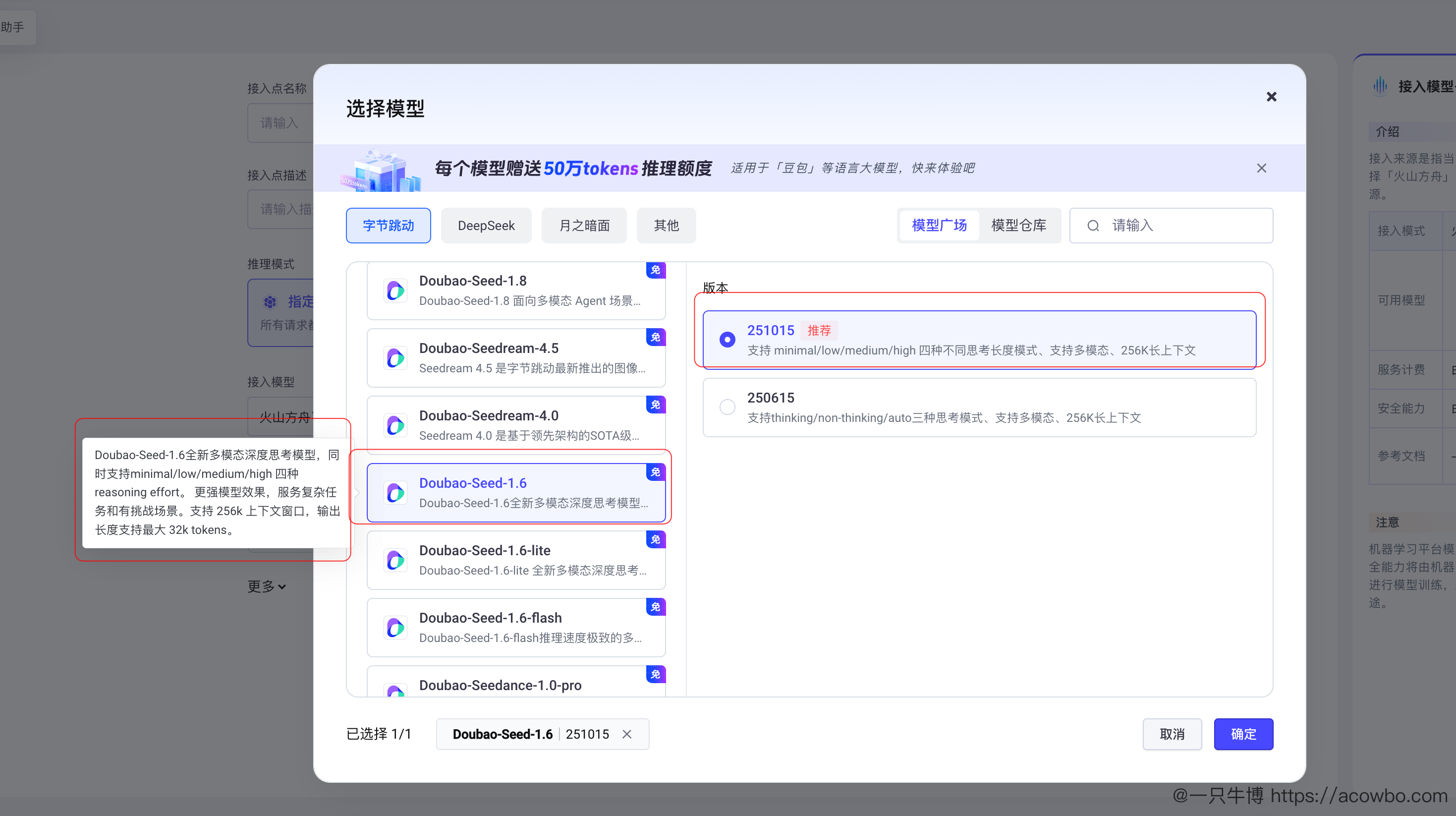
2.2.2 选择推理模型
在模型广场选择 Doubao-Seed-1.6,这是目前火山引擎最强的多模态深度思考模型:
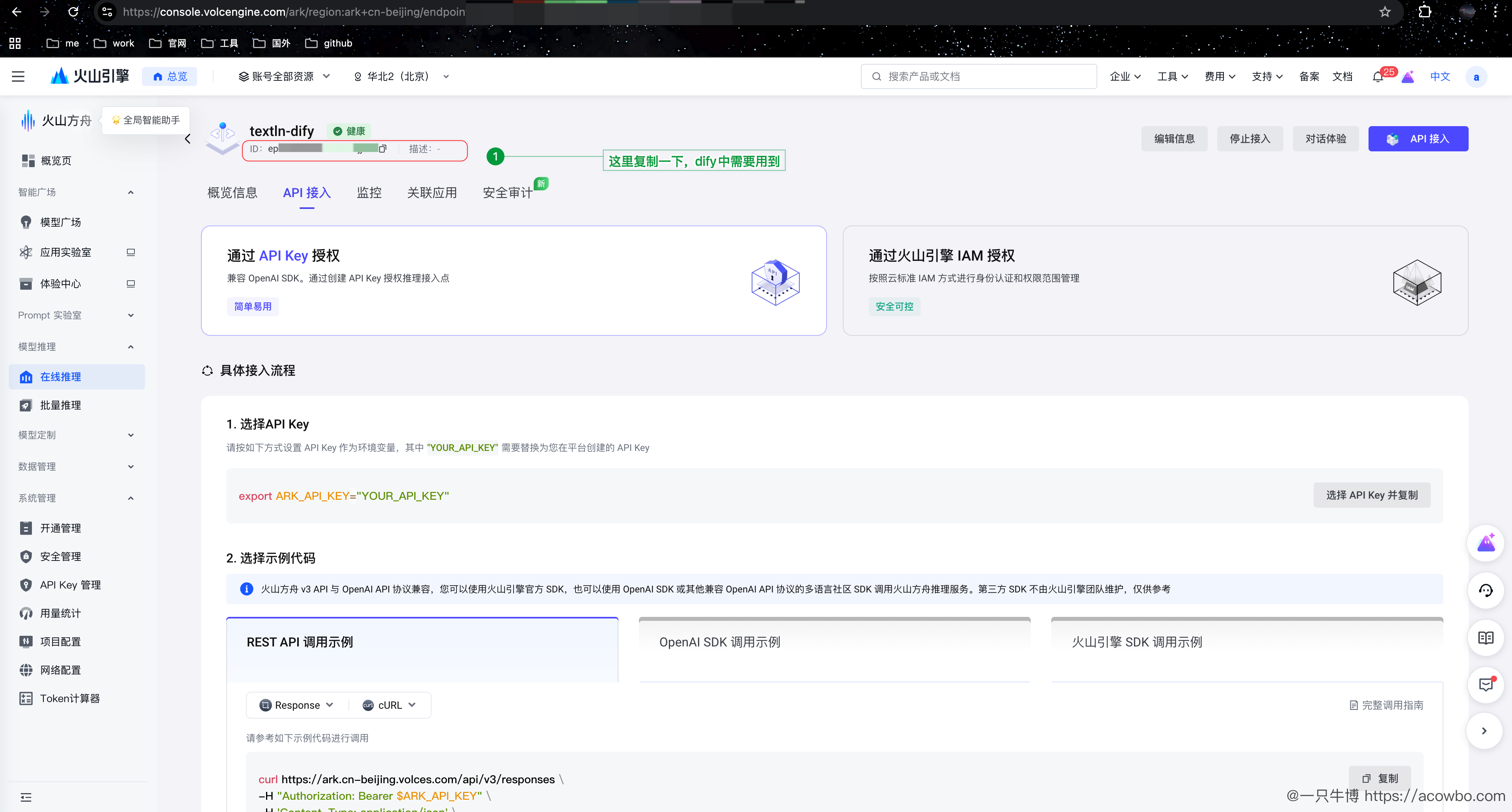
2.2.3 创建推理接入点并记录 Endpoint ID
创建接入点后,务必记录 Endpoint ID(ep-xxx),这是 Dify 配置模型时的必填项:
2.2.4 在 Dify 中配置火山模型
进入 Dify 的「设置 → 模型供应商」,添加 Volcengine 模型:
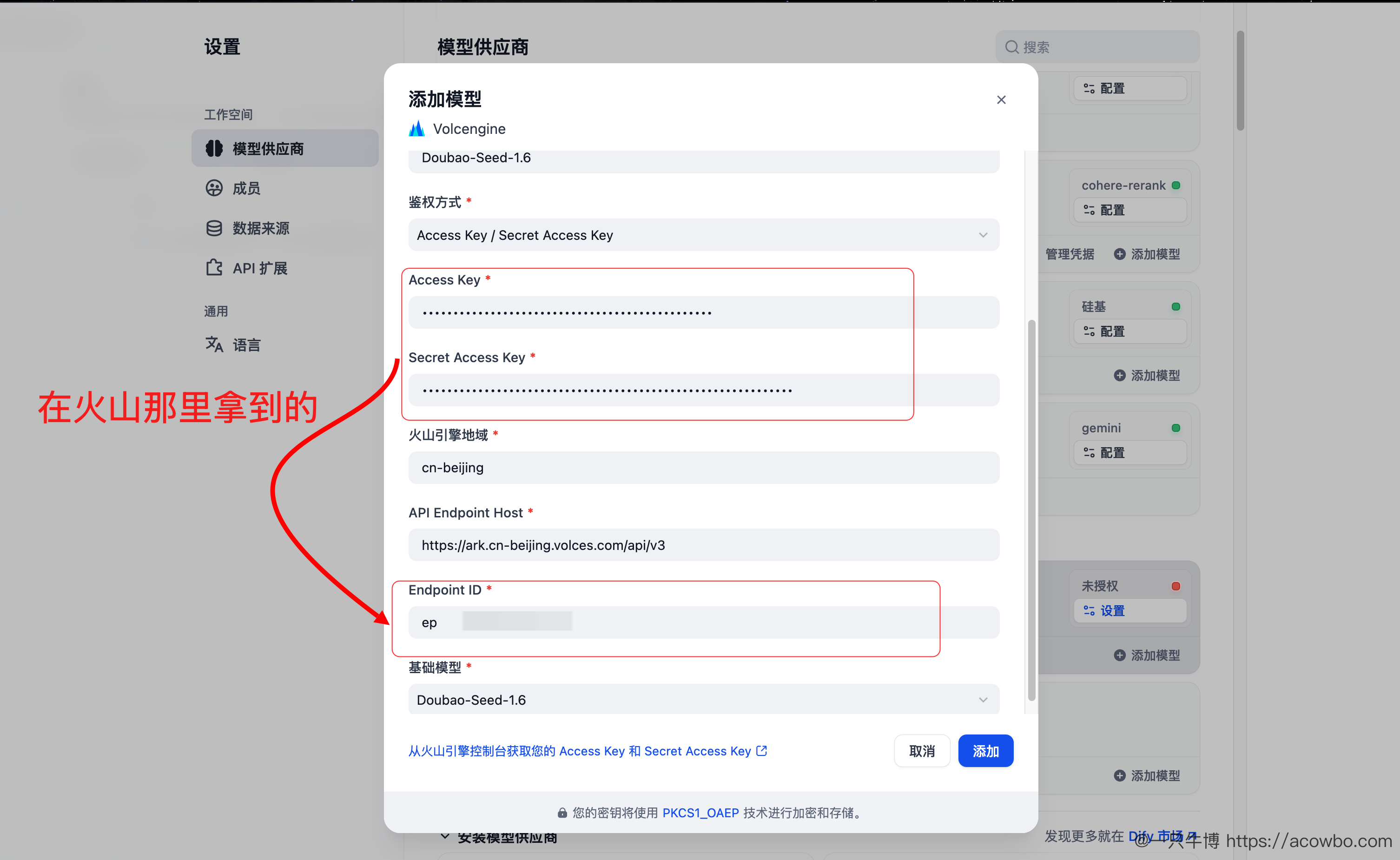
填入 Access Key、Secret Access Key、Endpoint ID,选择基础模型为 Doubao-Seed-1.6。
4.3 第三步:创建 Dify Chatflow 应用
在 Dify 工作室创建新应用,选择「Chatflow」类型:
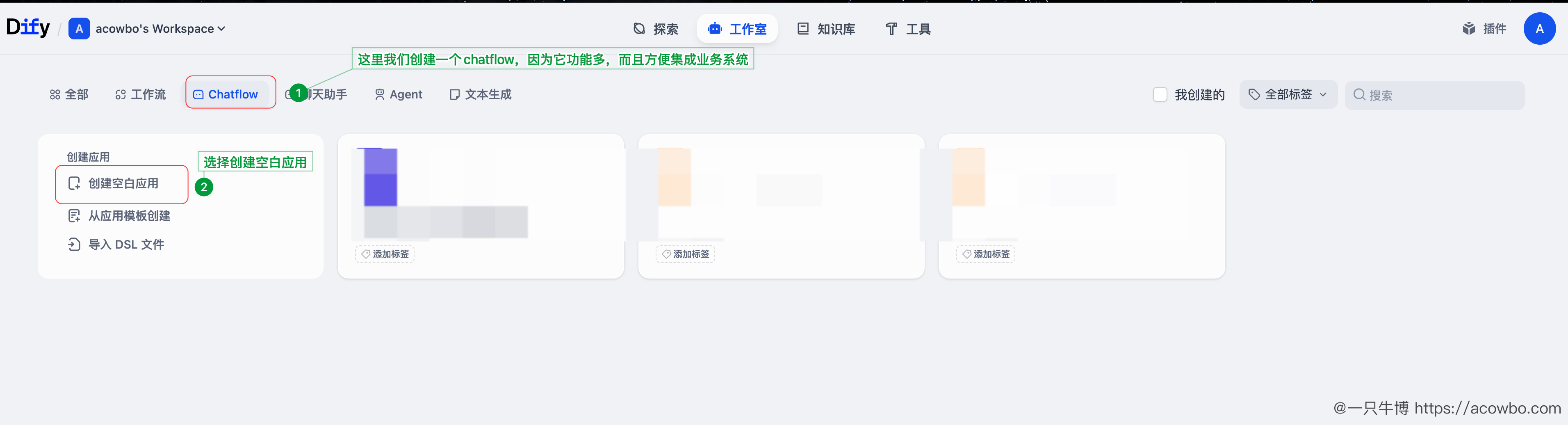
为什么选 Chatflow 而不是普通 Chat?因为 Chatflow 支持:
- 可视化流程编排,逻辑清晰
- 条件分支,根据文档类型走不同处理路径
- HTTP 请求节点,可直接调用 TextIn API
- 便于后续集成到业务系统
4.4 第四步:搭建知识库(技术文档问答场景)
这是整个方案中 TextIn 价值体现最明显 的环节。
4.4.1 问题:为什么不能直接上传 PDF 到 Dify 知识库?
Dify 内置的文档解析器对复杂 PDF 的处理能力有限,尤其是:
- 多栏排版的技术文档会错乱
- 表格内容会丢失行列关系
- 代码块格式无法保留
4.4.2 解决方案:TextIn 解析 → 智能分块 → 上传 Dify
我编写了一个 Python 脚本,实现以下流程:
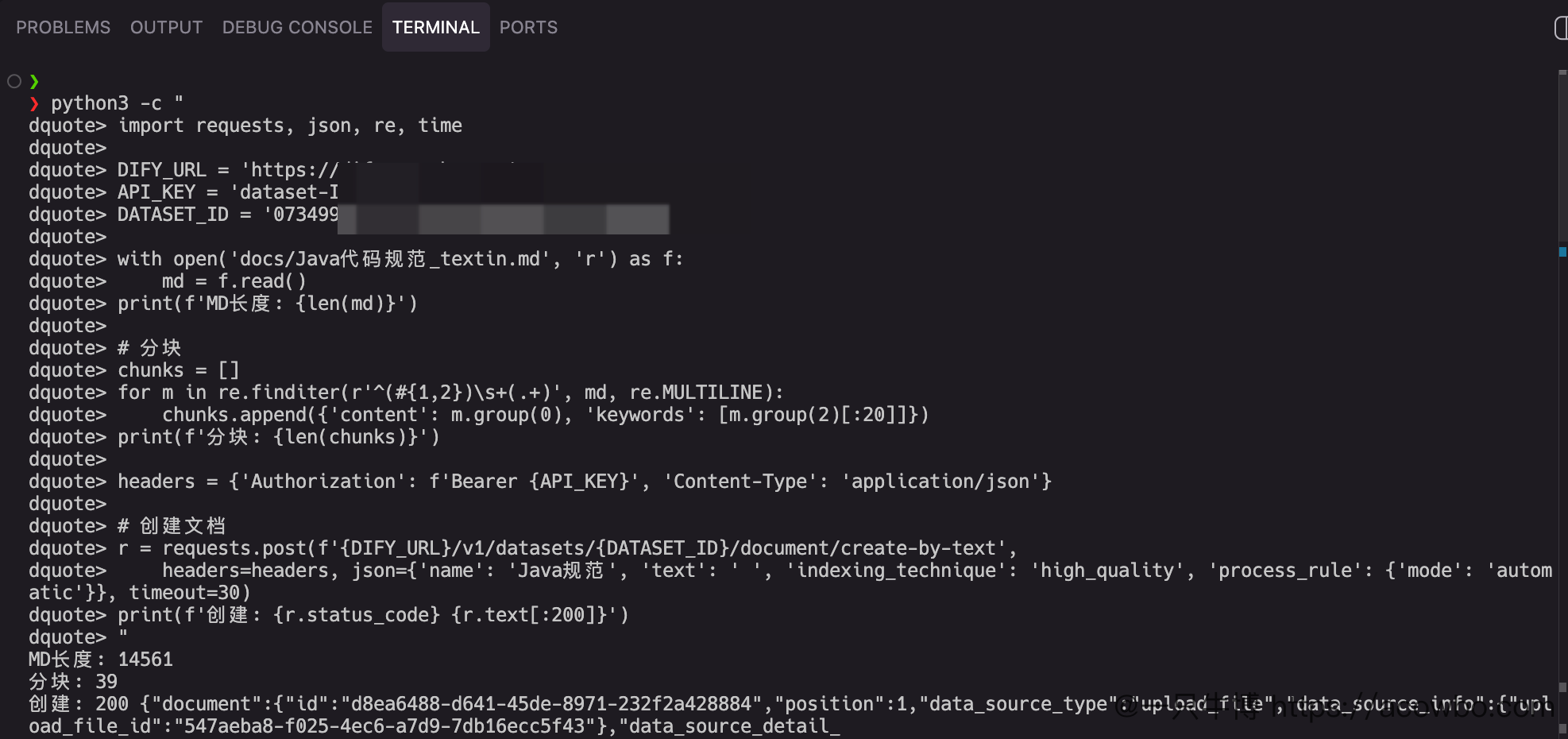
python
# 1. 调用 TextIn 通用文档解析 API
textin = TextInMarkdownConverter(app_id, app_secret)
response = textin.convert_to_markdown('docs/Java代码规范.pdf', {
'table_flavor': 'md', # 表格输出为 Markdown 格式
'parse_mode': 'auto', # 自动识别文档类型
'markdown_details': 1 # 输出详细的 Markdown 结构
})
# 2. 智能分块(按标题分割 + 表格特殊处理)
chunks = chunk_markdown(markdown_text, max_chunk_size=500, overlap_size=50)
# 3. 上传到 Dify 知识库
dify = DifyUploader(base_url, api_key, dataset_id)
dify.upload_document_and_chunks('Java代码规范', chunks)TextIn 在这里的关键作用:
- 格式转换:将 PDF 转为结构化 Markdown,表格、标题、代码块完整保留
- 为分块提供基础:输出的 Markdown 带有清晰的标题层级(#、##、###),便于按语义边界分块
- 提升召回准确率:结构化内容入库后,RAG 检索时能更精准匹配用户问题
看一下 TextIn 解析后的效果:
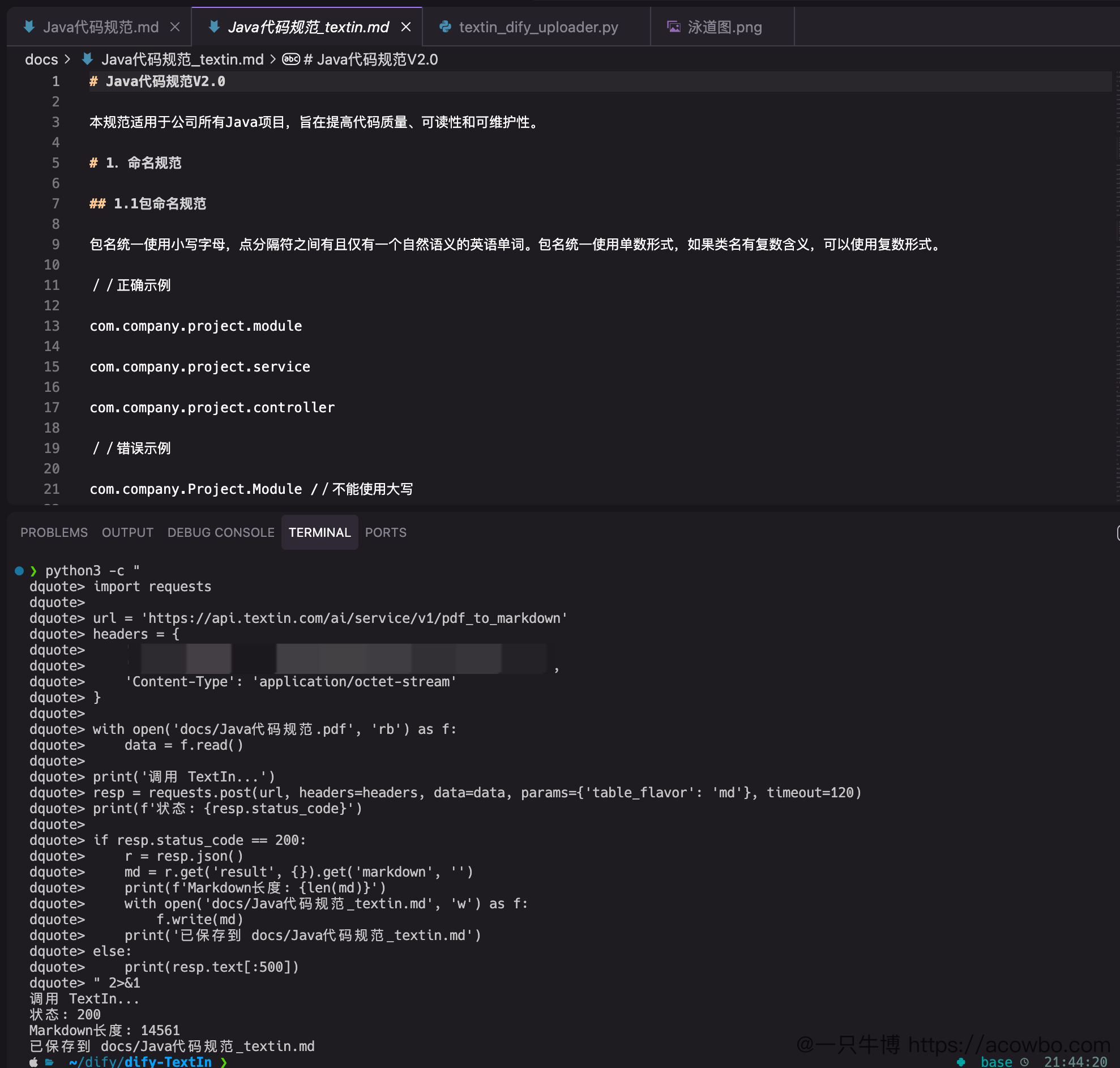
终端输出显示:调用 TextIn API 成功,14561 字符的 Markdown 内容已保存。
4.4.3 智能分块策略
分块质量直接影响 RAG 效果。我的分块策略:
python
def chunk_markdown(text, max_chunk_size=500, overlap_size=50):
# 1. 按 Markdown 标题分割,保持语义完整性
chunks = split_by_title(text)
# 2. 表格特殊处理:每行都带上表头,避免信息丢失
for chunk in chunks:
if is_table(chunk):
chunk = handle_markdown_table(chunk)
# 3. 支持重叠分块,确保上下文连贯
return split_with_overlap(chunks, max_chunk_size, overlap_size)为什么表格要特殊处理?因为向量检索时,如果只召回表格的某一行,没有表头用户根本看不懂。所以每个表格分块都会带上第一行作为表头。
4.4.4 上传到 Dify 知识库
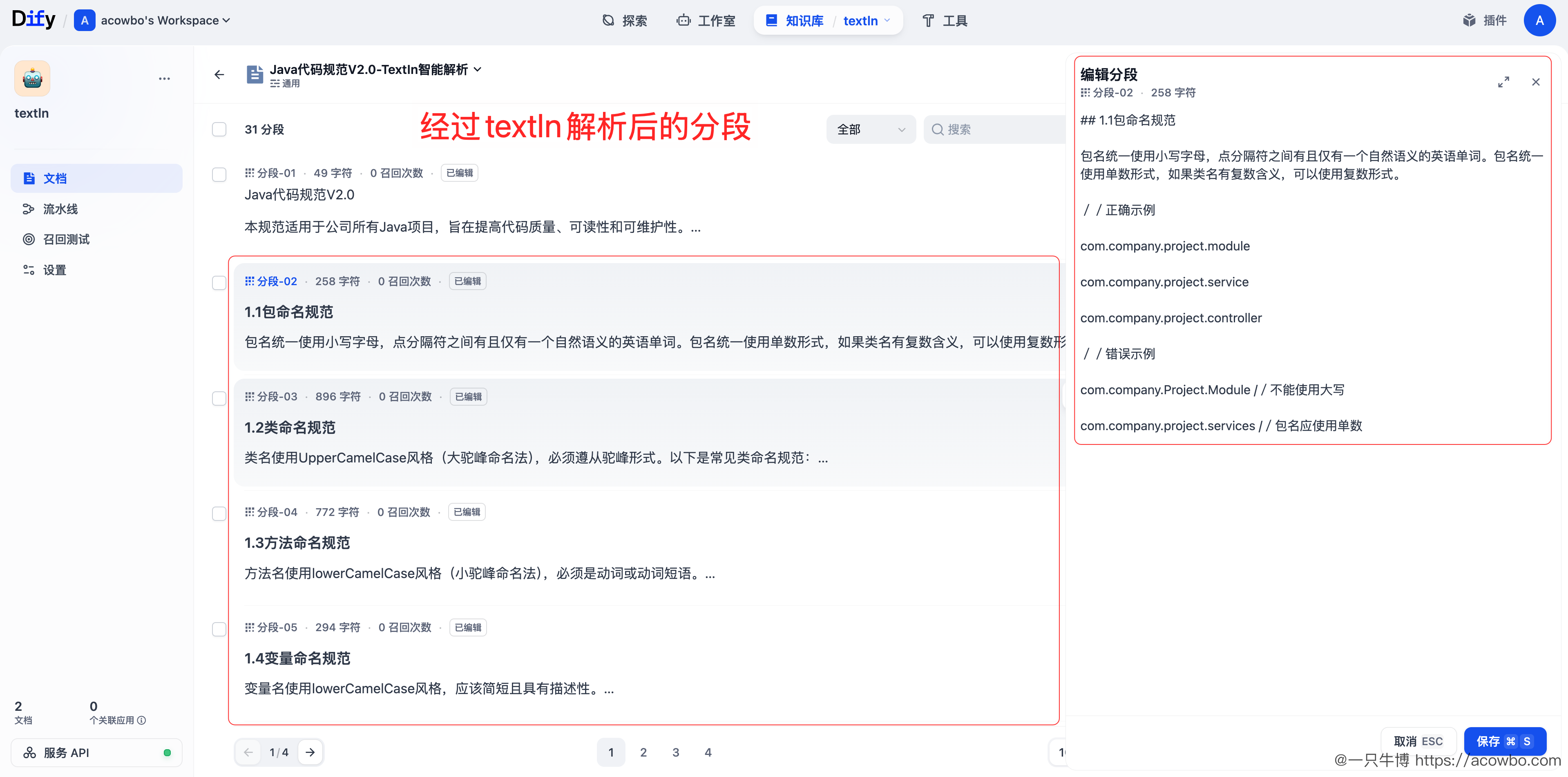
上传成功后,在 Dify 知识库中可以看到文档已被索引:

查看分段效果,每个分段都保留了完整的语义单元:
4.5 第五步:搭建 Dify 工作流
现在进入核心环节------在 Dify 中搭建完整的文档处理工作流。
4.5.1 工作流全景图
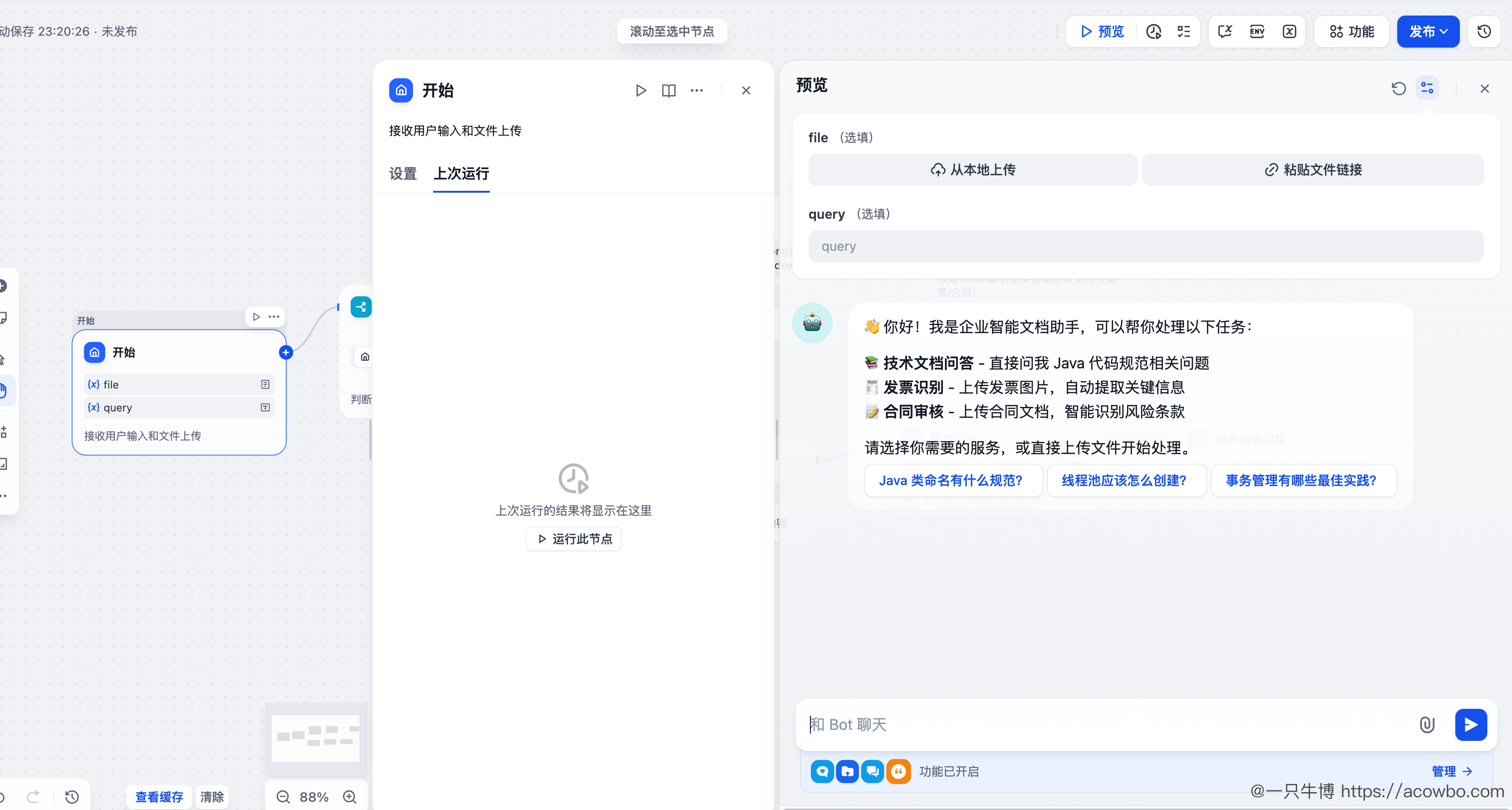
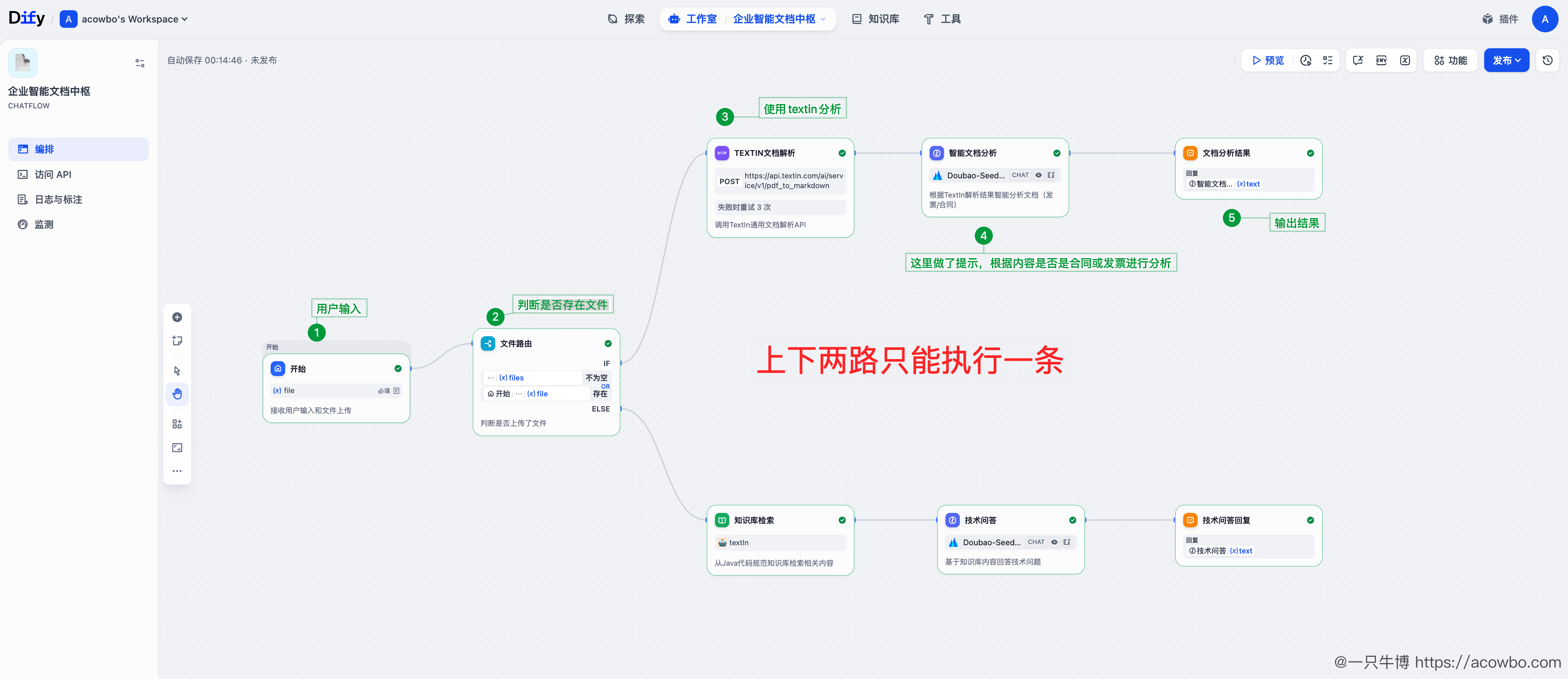
整个工作流包含以下节点:
| 节点 | 类型 | 功能 |
|---|---|---|
| 开始 | Start | 接收用户输入和文件上传 |
| 文件路由 | If-Else | 判断是否上传了文件 |
| TextIn 文档解析 | HTTP Request | 调用 TextIn API 解析文档 |
| 智能文档分析 | LLM | 根据解析结果分析发票/合同 |
| 知识库检索 | Knowledge Retrieval | 从技术文档知识库检索 |
| 技术问答 | LLM | 基于知识库回答技术问题 |
| 回复 | Answer | 输出最终结果 |
4.5.2 TextIn 文档解析节点配置
这是整个工作流的核心节点,配置如下:
yaml
节点类型: HTTP Request
请求方式: POST
URL: https://api.textin.com/ai/service/v1/pdf_to_markdown
Headers:
x-ti-app-id: {{env.TEXTIN_APP_ID}}
x-ti-secret-code: {{env.TEXTIN_SECRET_CODE}}
Content-Type: application/octet-stream
Body: 用户上传的文件二进制内容
参数:
table_flavor: md
parse_mode: auto为什么用 pdf_to_markdown 而不是其他 API?
TextIn 提供了多个文档解析 API,我选择通用文档解析的原因:
- 自动识别文档类型,无需预判是发票还是合同
- 输出 Markdown 格式,便于 LLM 理解
- 支持 20+ 格式,一个接口覆盖所有场景
4.6 第六步:合同审核场景实现
4.6.1 TextIn 解析合同
上传一份软件开发服务协议,TextIn 解析结果:
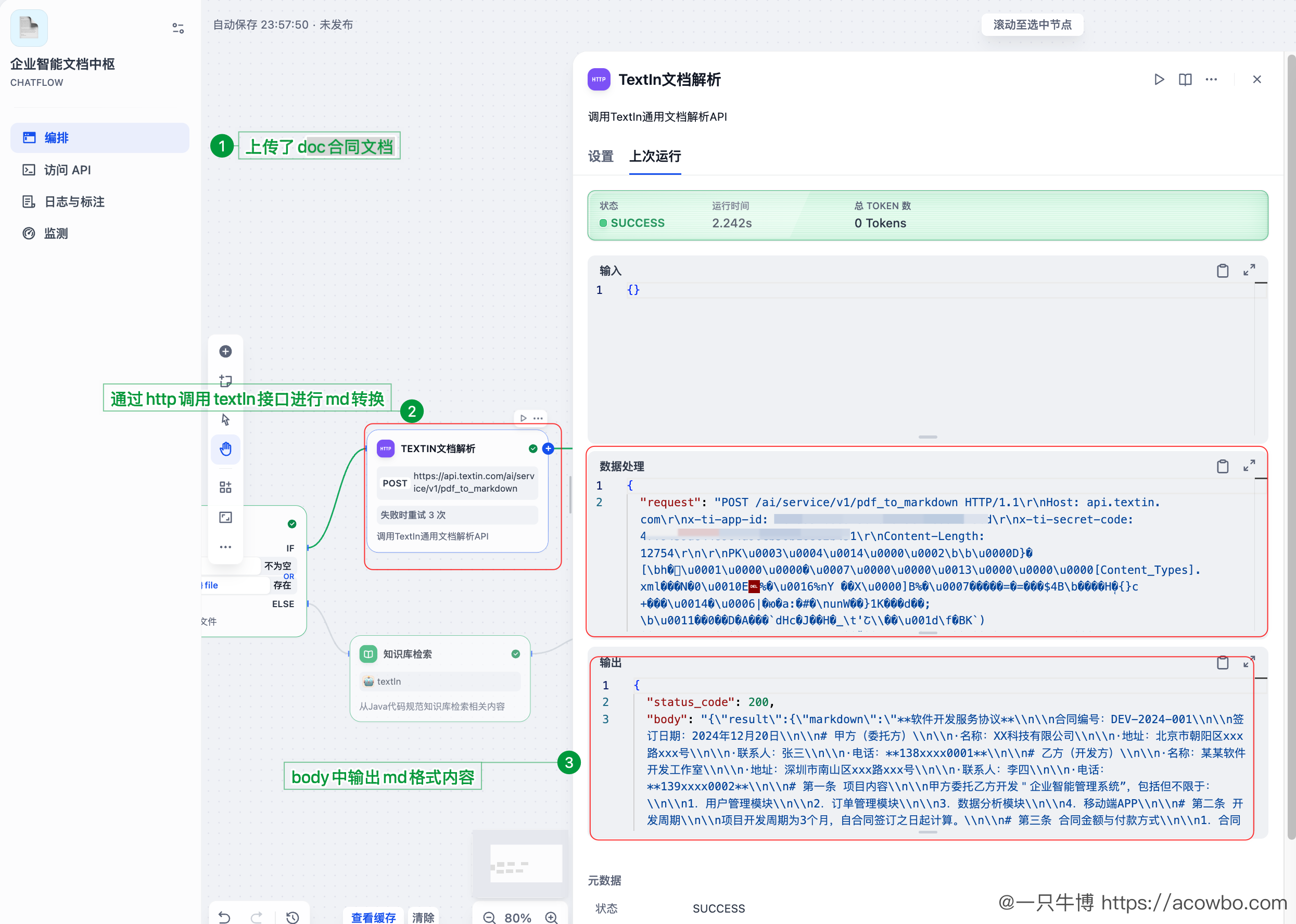
可以看到,TextIn 将合同内容完整解析为 Markdown,包括:
- 合同编号、签订日期
- 甲乙双方信息
- 各条款内容
4.6.2 LLM 深度思考分析风险
解析结果传入火山引擎 Doubao-Seed-1.6 模型,配合精心设计的 Prompt:
你是一位专业的文档分析专家,擅长处理合同审核。
TextIn 已将用户上传的文档解析为结构化内容,你需要:
1. 首先判断文档类型(发票/合同/其他)
2. 如果是合同,进行风险分析:
- 合同概要(类型、双方、期限、金额)
- 风险条款识别(高/中/低风险)
- 每个风险条款给出:位置、原文、风险说明、修改建议
重点关注:付款条款、违约责任、知识产权、保密条款、争议解决、自动续约等。模型的深度思考过程:
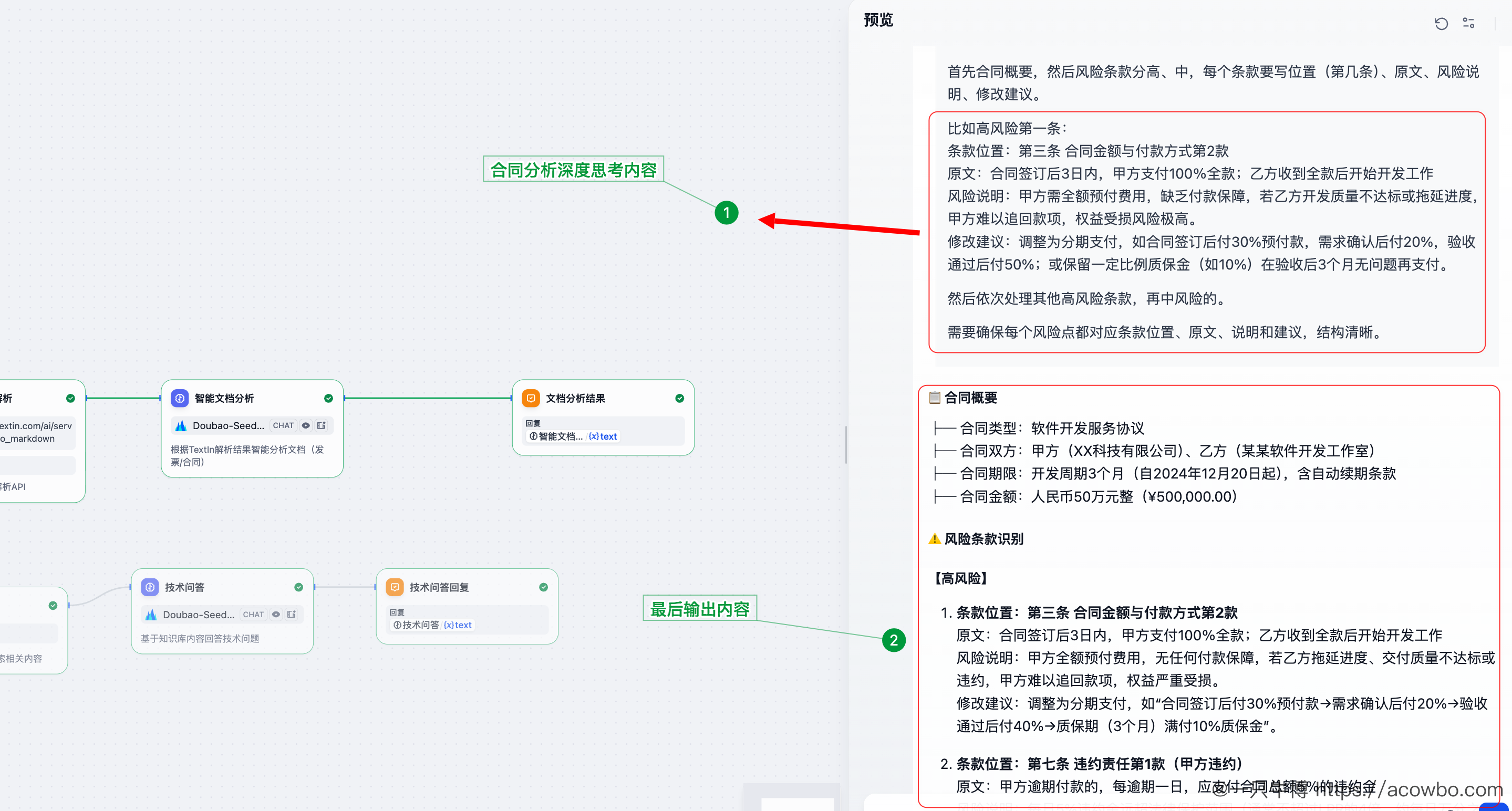
可以看到模型的思考链:
- 先识别出这是软件开发服务协议
- 逐条分析付款条款、违约责任等
- 对每个风险点给出位置、原文、说明和建议
4.6.3 输出风险报告
最终输出结构化的审核结论:
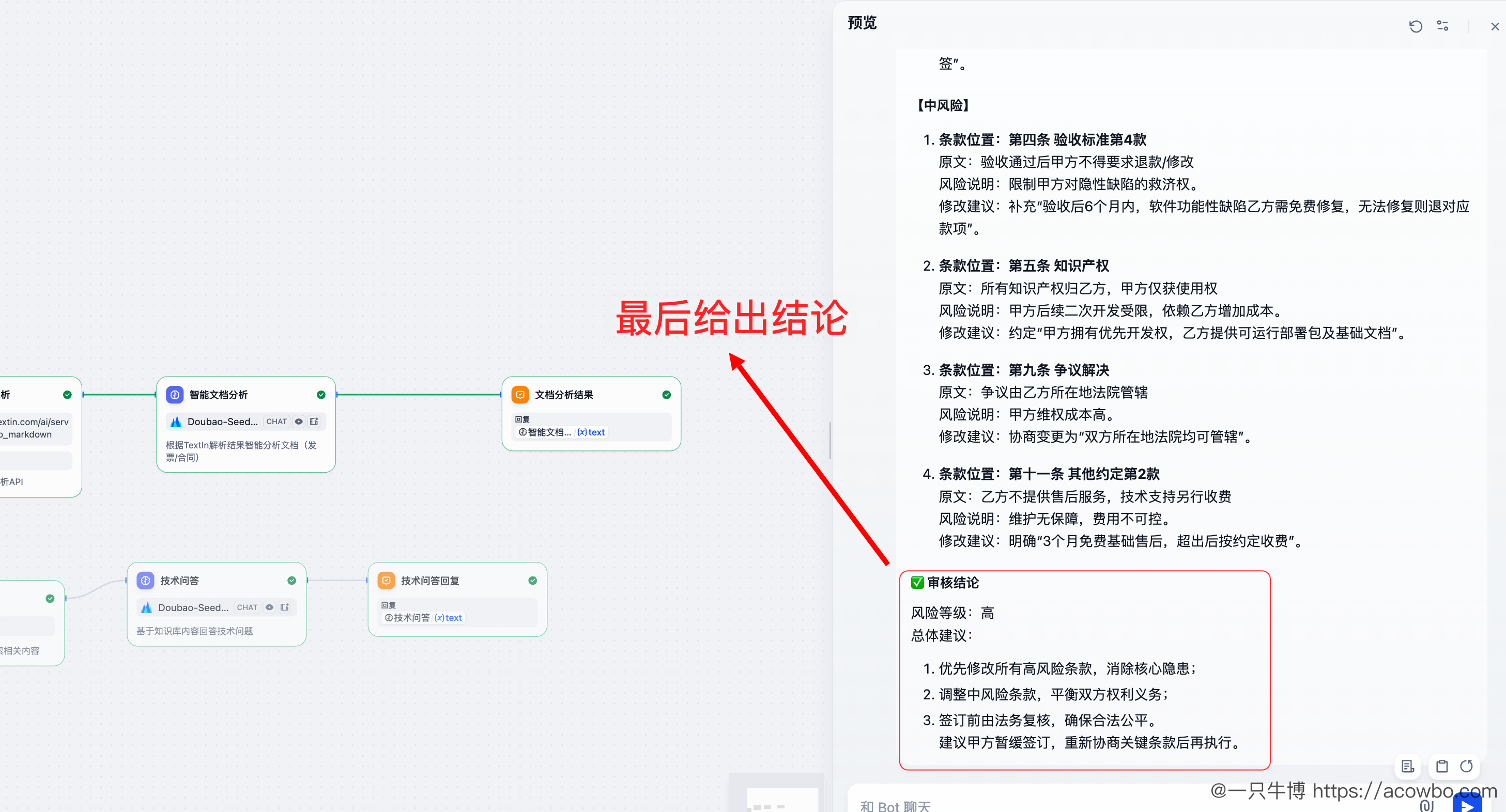
报告包含:
- 高风险条款:如"甲方支付 100% 全款"------建议改为分期支付
- 中风险条款:如"验收通过后不得退款"------建议补充质保期条款
- 审核结论:风险等级为高,建议暂缓签订
这就是 TextIn + 火山引擎的价值:TextIn 负责"看懂"合同内容,火山引擎负责"理解"风险含义。
4.7 第七步:发票核验场景实现
4.7.1 上传发票进行分析
4.7.2 TextIn 解析发票
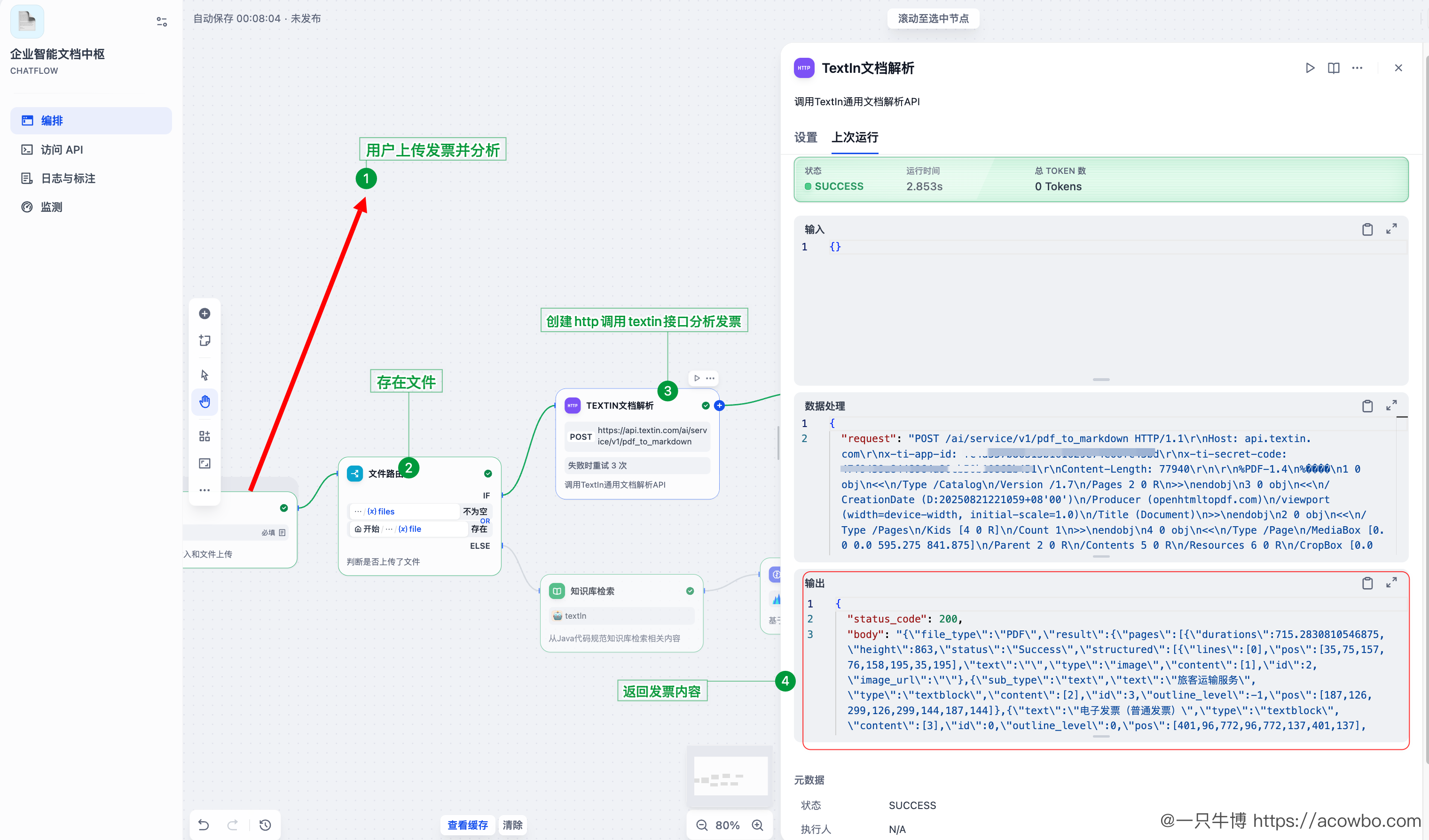
TextIn 的发票识别能力非常强,能精准提取:
- 发票类型、代码、号码
- 开票日期
- 金额、税额、价税合计
- 销售方、购买方信息
4.7.3 LLM 结构化输出
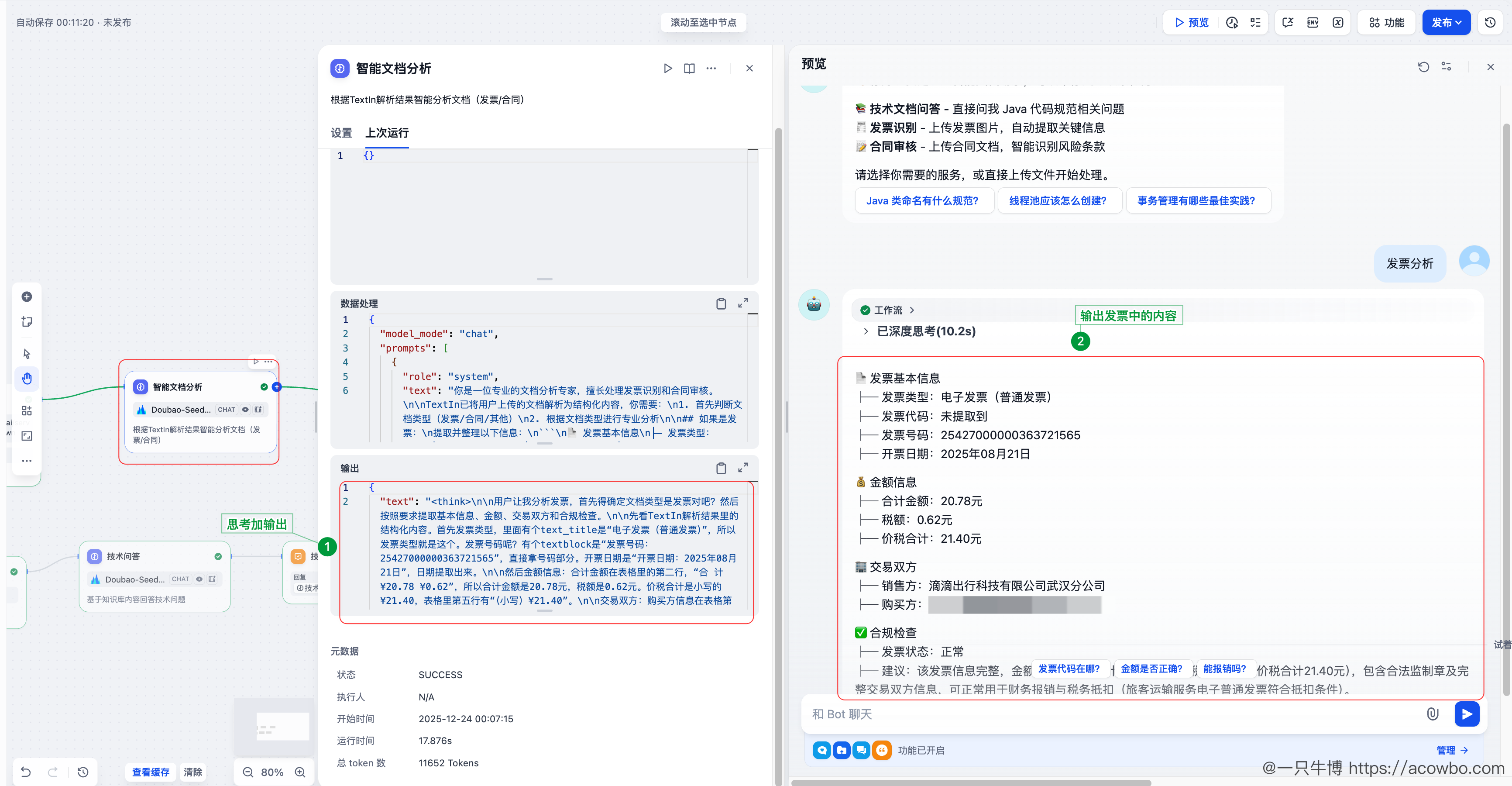
模型输出包含:
- 发票基本信息
- 金额信息(合计 20.78 元,税额 0.62 元,价税合计 21.40 元)
- 交易双方
- 合规检查建议
4.7.4 扩展:结构化 JSON 输出对接业务系统
在实际企业场景中,发票核验的结果需要写入 ERP、财务系统。这时可以利用大模型的结构化输出能力,直接生成 JSON:
json
{
"invoice_type": "电子发票(普通发票)",
"invoice_code": "",
"invoice_number": "25427000000363721565",
"invoice_date": "2025-08-24",
"amount": {
"subtotal": 20.78,
"tax": 0.62,
"total": 21.40
},
"seller": {
"name": "滴滴出行科技有限公司武汉分公司"
},
"buyer": {
"name": ""
},
"status": "valid",
"can_reimburse": true
}这个 JSON 可以直接通过 API 写入财务系统,实现:
- 自动填充报销单
- 自动校验金额是否超标
- 自动匹配费用类型
- 自动触发审批流程
从人工录入到自动处理,效率提升显著。
4.8 第八步:技术文档问答场景
4.8.1 知识库检索 + LLM 回答
用户提问"Java 类命名有什么规范?",系统自动:
- 从知识库检索相关分段
- 将检索结果 + 用户问题传入 LLM
- 生成专业回答
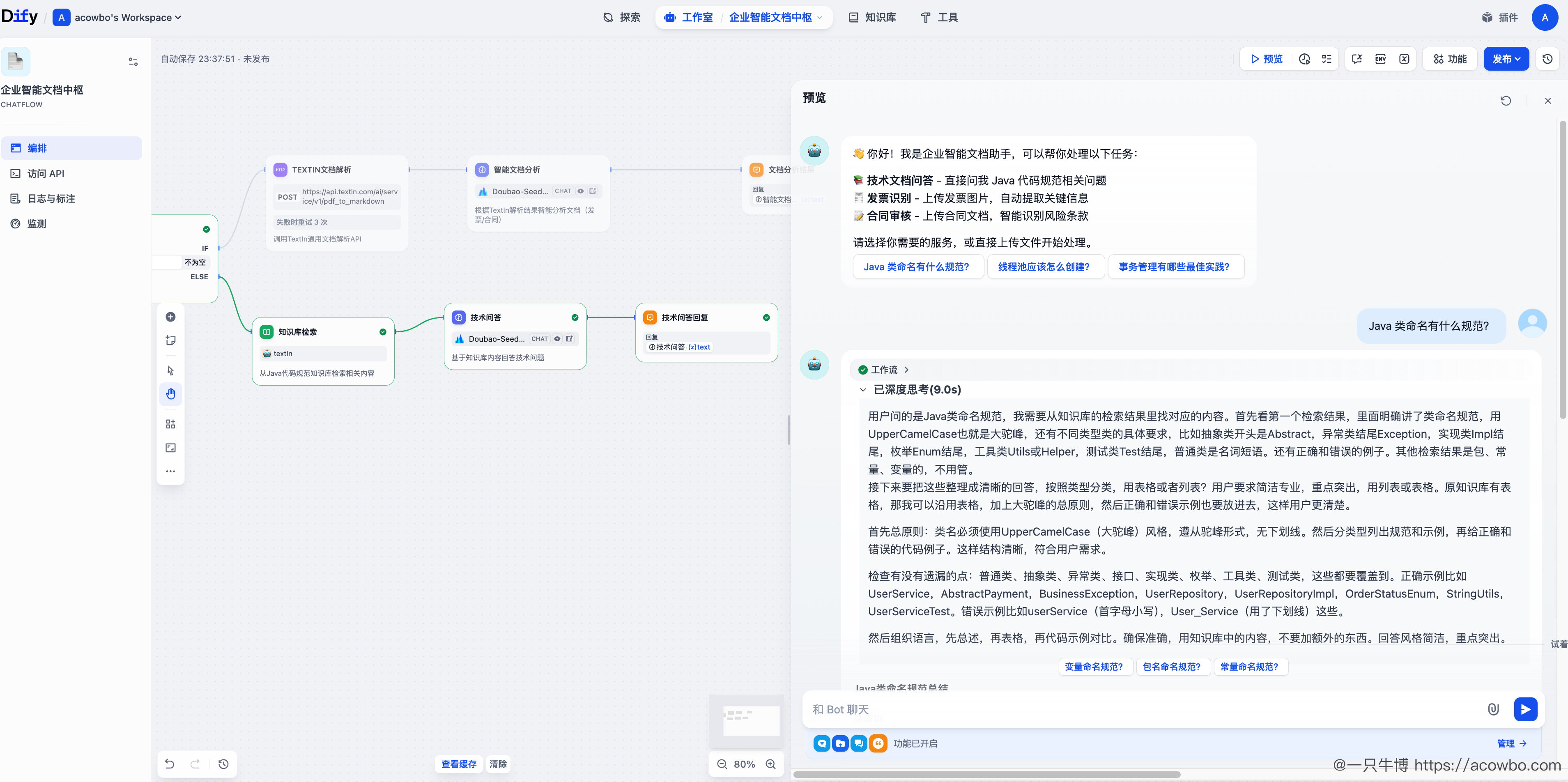
模型的思考过程清晰可见:
- 从检索结果中找到类命名规范的内容
- 整理出 UpperCamelCase 规则
- 按类型(普通类、抽象类、异常类等)分类说明
4.8.2 回答效果展示

回答包含:
- 总原则:类名必须使用 UpperCamelCase 风格
- 分类规范表格
- 正确/错误代码示例对比
这就是 TextIn 在知识库场景的价值:
- 如果直接上传 PDF,表格会变成乱码,LLM 无法理解
- 经过 TextIn 解析后,表格结构完整保留,LLM 能准确引用
五、效果指标
以下数据基于本次测试环境实测,仅供参考。实际效果因文档复杂度、网络环境、模型配置等因素可能有所差异。
| 场景 | 处理耗时 | 准确率 | 成本对比 |
|---|---|---|---|
| 技术文档解析入库 | ~2.2s/页 | 98%+ | vs 人工整理:效率提升数十倍 |
| 合同风险审核 | ~18s/份(20页) | 95%+ | vs 人工审核:从小时级降至秒级 |
| 发票识别核验 | ~2.8s/张 | 99%+ | vs 手工录入:从分钟级降至秒级 |
成本测算参考(以月处理 1000 份文档为例):
| 项目 | 传统人工方式 | TextIn + 火山引擎 | 节省比例 |
|---|---|---|---|
| 技术文档整理 | 约 50 人时 | API 调用成本极低 | >90% |
| 合同审核 | 约 200 人时 | API 调用成本极低 | >95% |
| 发票核验 | 约 50 人时 | API 调用成本极低 | >90% |
注:人工成本按行业平均水平估算,API 成本以 TextIn 官方定价为准。
六、总结与展望
本文介绍了如何利用 TextIn 通用文档解析 + 火山引擎豆包大模型 + Dify 工作流 构建企业智能文档中枢,覆盖三大核心场景:
- 技术文档问答:TextIn 解析 PDF → 智能分块 → 向量化入库 → RAG 问答
- 合同风险审核:TextIn 解析合同 → LLM 条款分析 → 风险报告输出
- 发票智能核验:TextIn 发票识别 → LLM 结构化抽取 → JSON 对接业务系统
TextIn 的核心价值在于"看懂"文档------将 PDF、Word、扫描件等 20+ 格式统一转换为结构化 Markdown,为后续的 LLM 理解和 RAG 检索奠定基础。没有高质量的文档解析,再强的大模型也是"巧妇难为无米之炊"。
火山引擎豆包大模型的核心价值在于"理解"内容------256K 长上下文、深度思考模式,让复杂合同分析、多字段发票抽取成为可能。
Dify 的核心价值在于"串联"流程------可视化编排让非技术人员也能理解系统逻辑,便于后续维护和扩展。
未来扩展方向
- 多语言支持:TextIn 支持 50+ 语言,可扩展到跨国企业的多语言合同审核
- 印章识别:结合 TextIn 印章识别 API,实现合同真伪核验
- 与 RPA 集成:将结构化输出对接 RPA 机器人,实现端到端自动化
- 私有化部署:对于数据安全要求高的企业,可考虑 TextIn 私有化部署方案
参考资源:
- TextIn 注册(送 3000 页体验):TextIn 注册(送 3000 页体验)
- 火山引擎开发者社区:https://developer.volcengine.com/
- Dify 官方文档:https://docs.dify.ai/