【进程替换目录
- 前言:
- ---------------进程替换---------------
- [1. 什么是程序的进程替换?](#1. 什么是程序的进程替换?)
- [2. 怎么实现进程的替换?](#2. 怎么实现进程的替换?)
- [3. 如何快速的记住exec函数族中的所有的函数?](#3. 如何快速的记住exec函数族中的所有的函数?)
- [4. 进程替换的本质是什么?](#4. 进程替换的本质是什么?)

往期《Linux系统编程》回顾:/------------ 入门基础 ------------/
【Linux的前世今生】
【Linux的环境搭建】
【Linux基础 理论+命令】(上)
【Linux基础 理论+命令】(下)
【权限管理】/------------ 开发工具 ------------/
【软件包管理器 + 代码编辑器】
【编译器 + 自动化构建器】
【版本控制器 + 调试器】
【实战:倒计时 + 进度条】/------------ 系统导论 ------------/
【冯诺依曼体系结构 + 操作系统基本概述】/------------ 进程基础 ------------/
【进程入门】
【进程状态】
【进程优先级】
【进程切换 + 进程调度】/------------ 进程环境 ------------/
【环境变量】
【地址空间】/------------ 进程控制 ------------/
【进程创建 + 进程终止】
【进程等待】
前言:
hi~,小伙伴们大家好呀!(ノ≧∀≦)ノ
好了好了我们快点开始学习进程控制的最后一讲 【进程替换】 吧! (゚∀゚)
- 等等,我好像听到有小伙伴在问,鼠鼠为什么这次只隔了一天,一大早就更新新作了?是不是因为之前停更太久,心里愧疚想弥补呀?ψ(`∇´)ψ, 嗯......ψ(._. )>,其实是鼠鼠上学期的学习到今天就算是结束了,练习编码一坤年的鼠鼠今天早上就要回家了,等你们看到这篇博客的时候,鼠鼠应该已经坐在回家的车上啦。
- 最后呢就是这次其实并不是鼠鼠的回归,而是鼠鼠短暂的离开~
时间过得比鼠鼠想象中还要快,这中间发生了很多的事情,接下来鼠鼠也要为了自己的目标全力以赴了。总之,还是想对大家说一句:"早安、晚安、谢谢、再见~"(。•́‿•̀。)♡
| --- 2025 年 12 月 31 日(冬月十二)周三,2025年最后一天 |
|---|
---------------进程替换---------------
1. 什么是程序的进程替换?
进程替换:是指使用一个新的程序替换当前进程的正文、数据、堆和栈段,使得当前进程转而执行新程序的功能。
- 简单来说:就是让一个进程 "变身" 去执行另一个不同的程序
我们在终端输入 ls、ls -al 等命令时,整个执行过程背后是 Linux 系统典型的 "进程创建 + 程序替换" 机制
具体逻辑可以拆解为以下几步,核心围绕
bash(命令行解释器)的工作流程展开:
1. 明确核心角色:bash 是父进程,命令是子进程
首先要明确一个基本关系:
bash本身是一个运行中的进程(我们登录终端时启动)- 而我们输入的
ls、ls -al等命令,最终都会以 "bash的子进程" 身份运行 ------所有终端命令的直接父进程都是 bash
2. 命令执行的完整流程:fork 创建子进程 → exec 替换程序
当我们在终端敲下
ls -al并回车后,bash会按以下步骤完成命令执行:第一步:bash 调用 fork 创建子进程
bash首先通过fork()系统调用创建一个与自己完全相同的子进程。此时的子进程拥有独立的地址空间,但里面的代码、数据都和父进程(
bash)一模一样 ------ 简单说,子进程 "复制" 了bash的运行环境,但还没开始执行任何命令逻辑。
第二步:子进程通过 exec 函数族进行 "程序替换"
子进程创建后,并不会继续执行 bash 的逻辑,而是立即调用 exec 函数族进行程序替换:
- 子进程会根据命令名(如:
ls)找到对应的可执行文件路径(ls程序通常存放在/bin/ls)- 然后通过 exec 调用,用 /bin/ls 程序的代码、数据、堆栈段,完全替换掉子进程原本从 bash 复制来的内容
- 同时子进程会将命令参数(如:
-al)传递给 ls 程序,让 ls 按参数执行对应的功能(比如:-al表示 "长格式显示所有文件,包括隐藏文件")关键特点:程序替换不会创建新进程,只是 "改写" 了现有子进程的运行内容 ------ 子进程的 PID 不变,但执行的程序从 bash 变成了 ls
第三步:bash 阻塞等待子进程结束
在子进程执行 ls 程序的同时,父进程 bash 并不会继续接收新命令,而是通过 wait 或 waitpid 系统调用进入阻塞等待状态:
- 它会一直等待
ls子进程执行完毕(无论是正常退出还是异常终止)- 当
ls执行完成并退出后,bash会从阻塞中恢复,回收子进程的资源(避免僵尸进程),然后重新打印命令提示符(如:user@host:~$),等待我们输入下一个命令
总结:命令执行的本质是 "子进程程序替换"
简单来说,终端命令的执行逻辑可以概括为:
bash(父进程)→ fork() 创建空白子进程 → 子进程 exec() 替换为目标程序(如:ls)→ bash 等待子进程结束 → 恢复接收新命令
我们平时说的 "
ls是一个进程",其实就是这个被bashfork 出来、又通过exec替换为ls程序的子进程。而这个 "创建子进程后替换程序" 的过程,就是 Linux 中核心的进程替换机制
- 它让
bash无需自身执行命令,只需 "孵化子进程并让子进程变身"- 既保证了命令的独立运行,又避免了
bash自身被替换(否则执行一次命令bash就消失了)
2. 怎么实现进程的替换?
在 Linux 中:
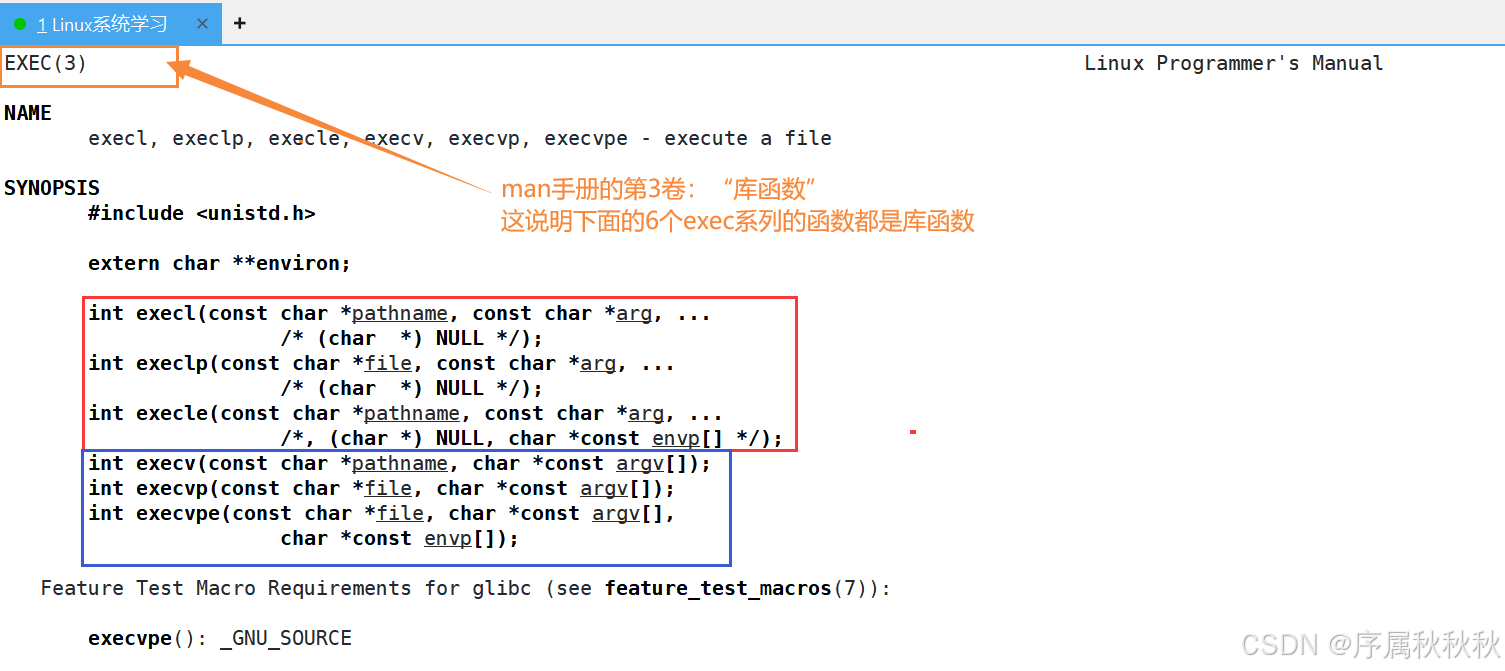
实现进程替换主要通过 **exec函数族 ** 完成,核心逻辑是用新程序的代码和数据替换当前进程的内容,而进程的 PID 等内核标识保持不变。
cpp
#include <unistd.h>
/*-------------------------------- execl --------------------------------*/
// execl:完整路径 + 可变参数列表
int execl(const char *path, const char *arg, ... /* (char *) NULL */);
// execlp:PATH查找 + 可变参数列表
int execlp(const char *file, const char *arg, ... /* (char *) NULL */);
// execle:完整路径 + 可变参数列表 + 自定义环境变量
int execle(const char *path, const char *arg, ... /* (char *) NULL, char * const envp[] */);
/*-------------------------------- execv --------------------------------*/
// execv:完整路径 + 参数数组
int execv(const char *path, char *const argv[]);
// execvp:PATH查找 + 参数数组
int execvp(const char *file, char *const argv[]);
// execvpe:PATH查找 + 参数数组 + 自定义环境变量(POSIX.1-2001标准新增)
int execvpe(const char *file, char *const argv[], char *const envp[]);
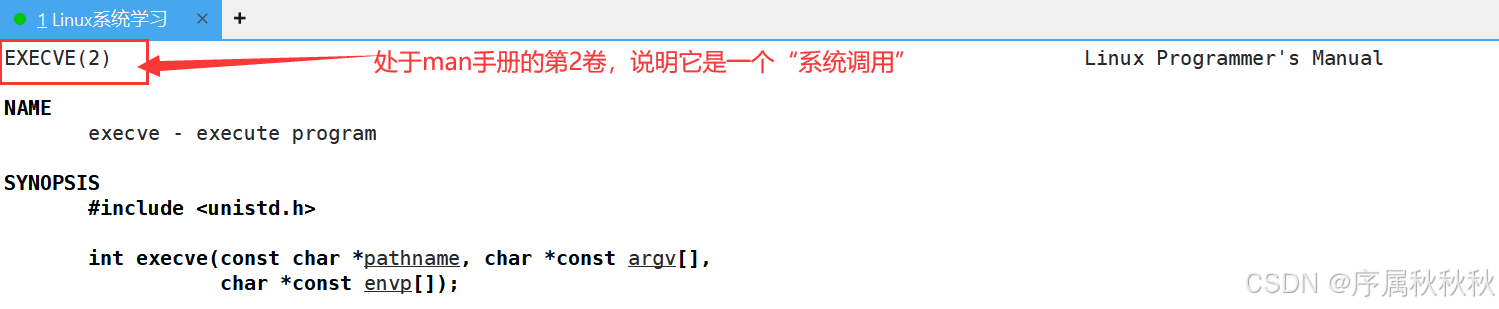
/*-------------------------------- 唯一的系统调用:execve --------------------------------*/
// execve:系统调用原函数(完整路径 + 参数数组 + 环境变量数组)
int execve(const char *pathname, char *const argv[], char *const envp[]);
exec函数族说明如下:
- execl :需要
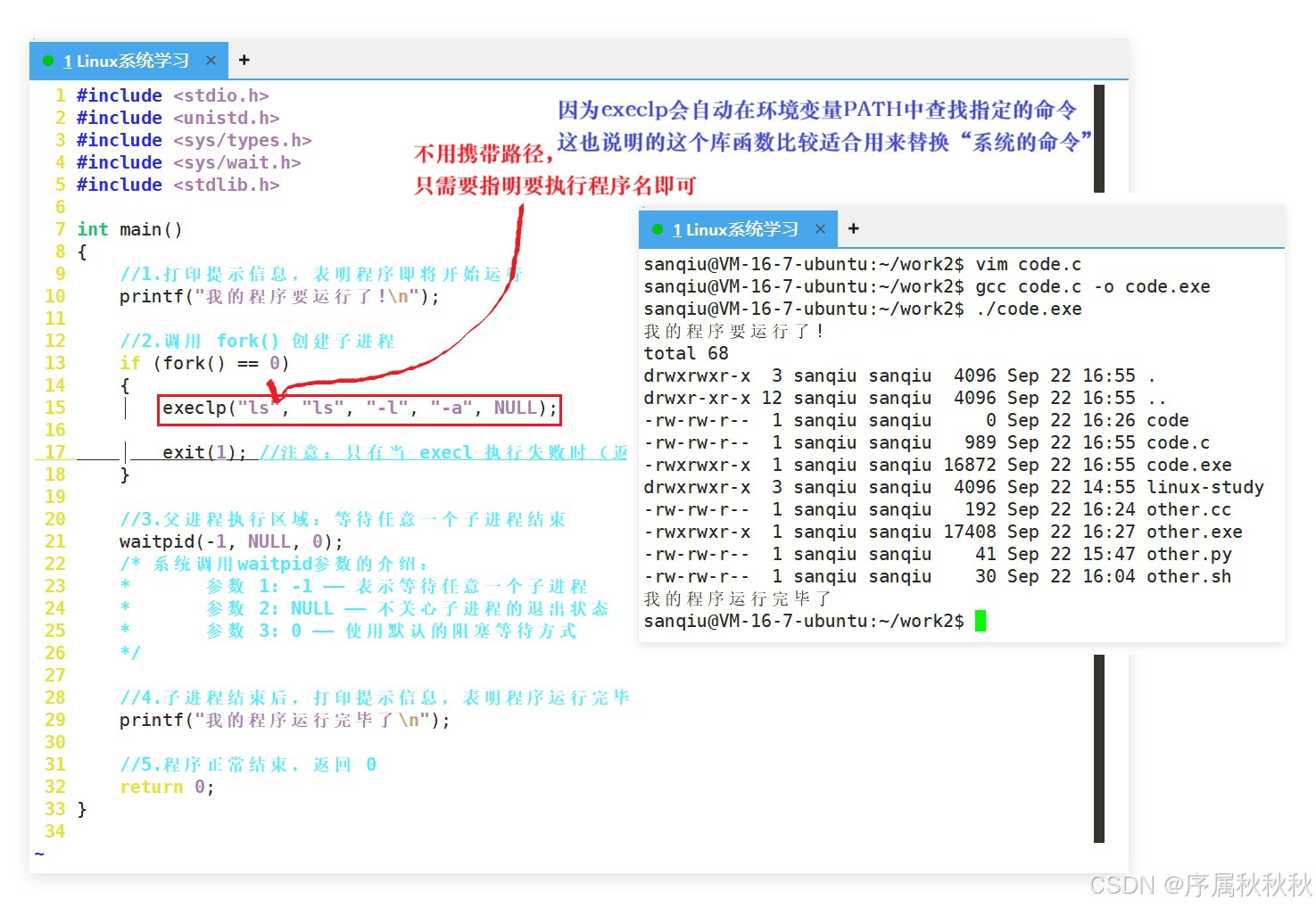
指定可执行文件的完整路径,可变参数列表传递给新程序的参数,以NULL结尾- execlp :不需要指定可执行文件的完整路径,会在环境变量PATH 指定的目录中查找可执行文件,
参数传递方式和execl相同- execle :需要
指定可执行文件的完整路径,可变参数列表传递参数(以NULL结尾),同时显式指定环境变量数组(数组以NULL结尾),不继承当前进程环境- +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
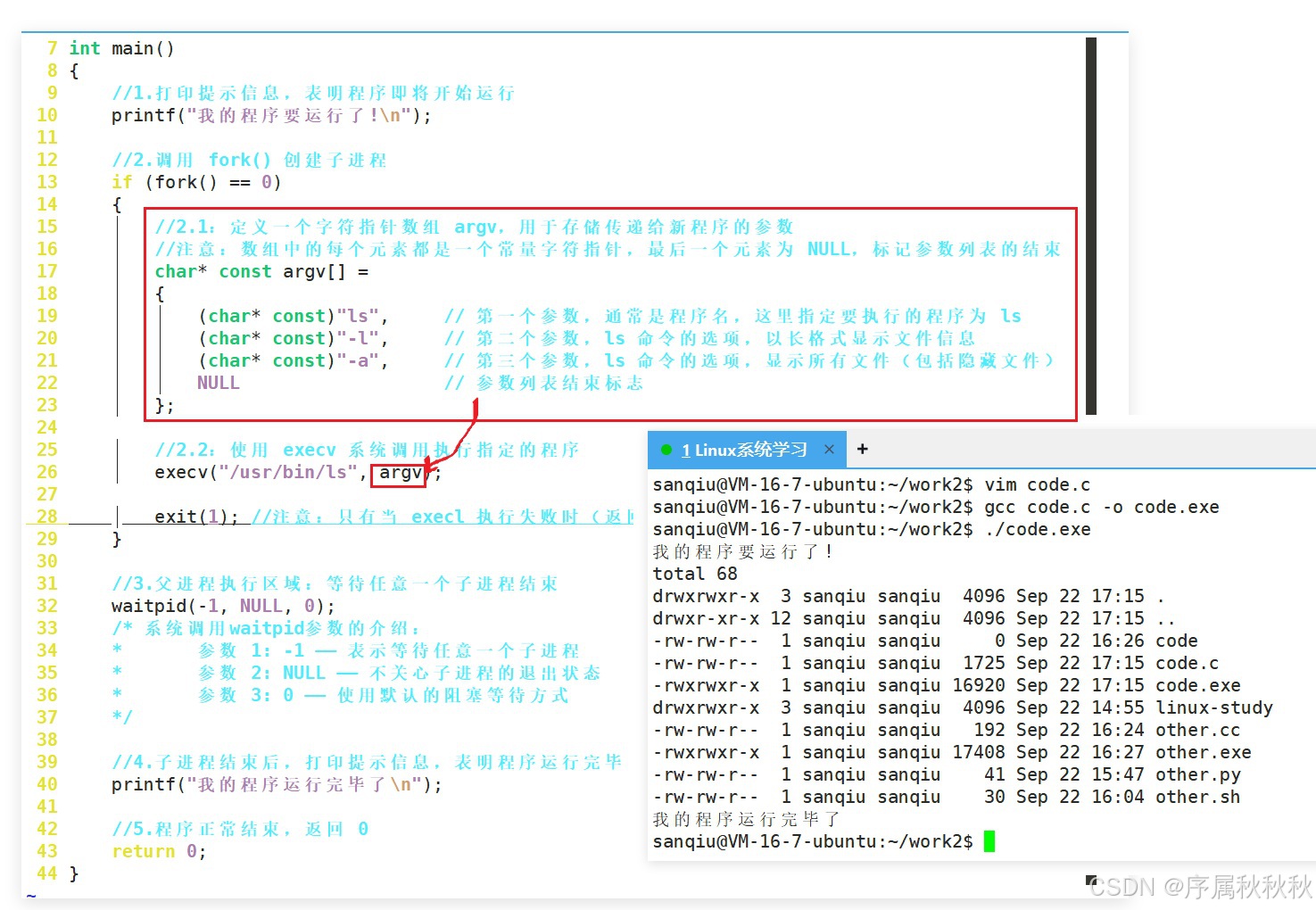
- execv :通过
一个指向字符串数组的指针来传递参数,同样需要指定可执行文件的完整路径- execvp :在PATH指定目录中查找可执行文件,
参数通过字符串数组传递- execvpe :不需要指定可执行文件的完整路径(依赖PATH查找),通过
字符串数组传递参数,同时显式指定环境变量数组,不继承当前进程环境
- execve :是exec函数族中唯一的系统调用,其他exec 函数最终都会调用execve,它需要
指定可执行文件的完整路径,通过数组传递参数,也可指定环境变量数组
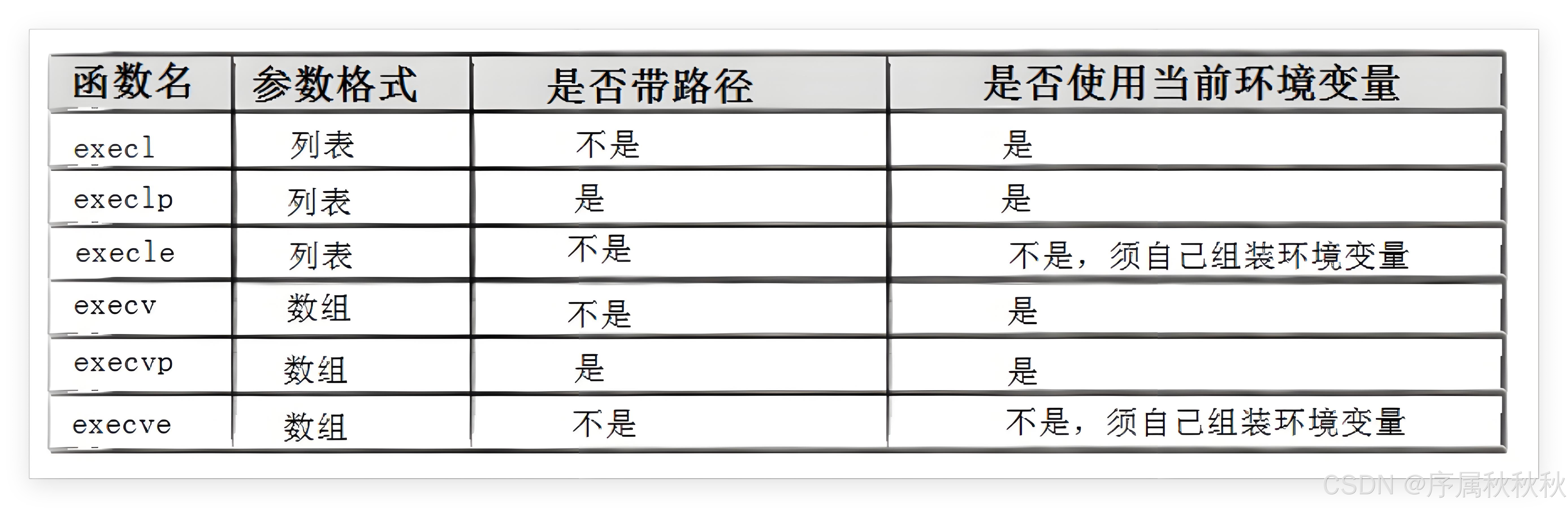
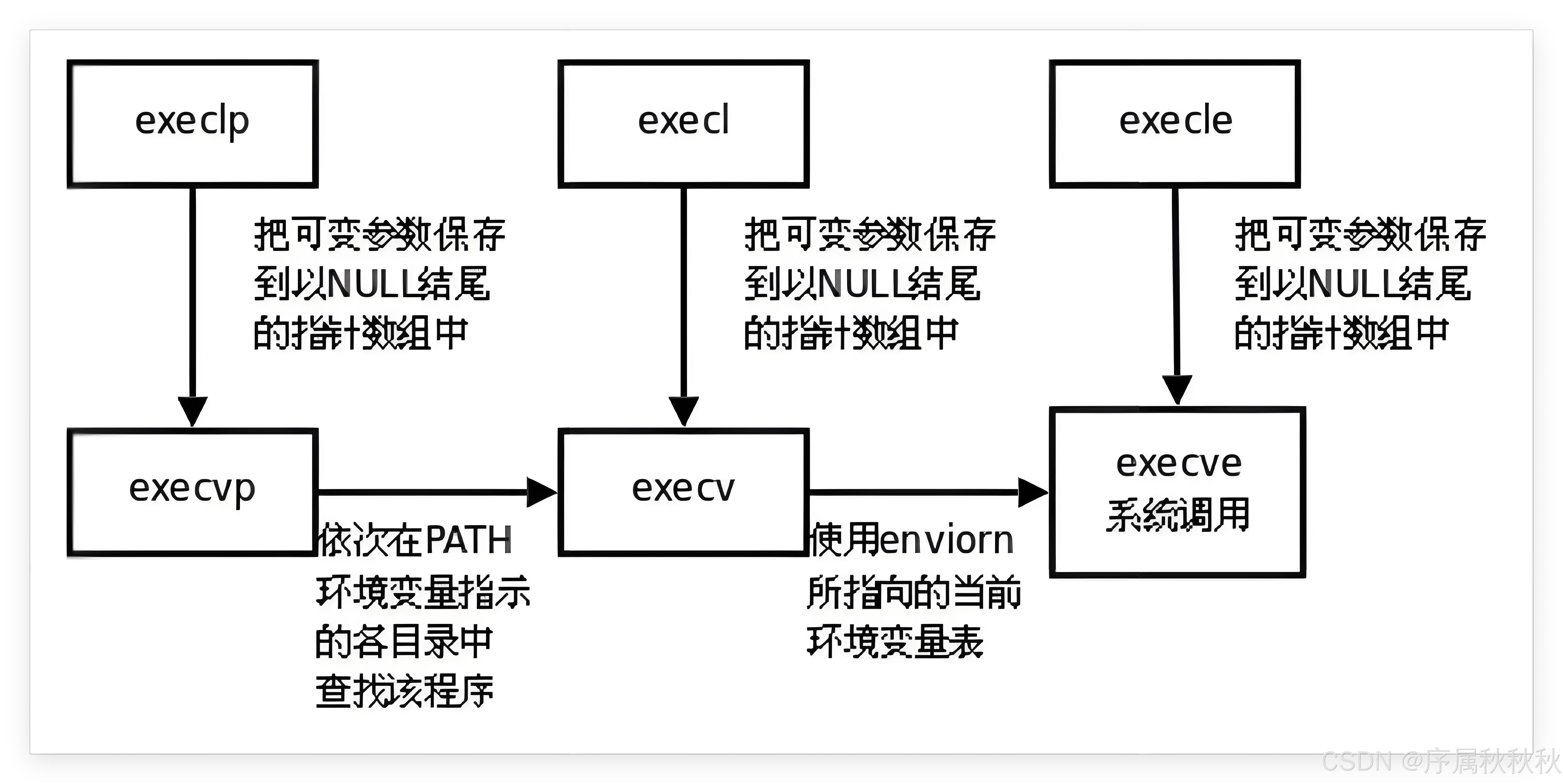
3. 如何快速的记住exec函数族中的所有的函数?
这些
exec函数族的原型初看容易混淆,但只要掌握命名里的规律,就很好记忆:
- l(list,列表):代表参数采用可变参数列表的形式传递。
- 比如:
execl后续直接跟多个参数,最后以NULL结尾,像列清单一样逐个指定传给新程序的参数- v(vector,向量) :表示参数通过字符串数组传递。
- 例如:
execv需要传入一个字符串数组指针,数组里存着要传给新程序的参数,最后一个元素是NULL,用数组这种 "向量式" 结构来组织参数- p(path,路径) :如果函数名里有 p,会自动搜索环境变量 PATH 来查找要执行的可执行文件,不用我们指定完整路径。
- 比如:
execlp只需给出可执行文件的名字,系统会去 PATH 包含的目录里找- e(env,环境) :意味着函数可以自行维护环境变量。
- 例如:
execle调用时能显式传入一个环境变量数组,新程序会使用这个自定义的环境变量集合,而不是继承当前进程的环境变量
一、execl
① 介绍
execl:是一个用于执行可执行文件的系统调用函数,它属于 exec 函数族。
- exec函数族的作用是用新的程序替换当前进程的正文、数据、堆和栈段,简单来说就是让当前进程去执行另一个程序
函数原型
c#include <unistd.h> int execl(const char *path, const char *arg, ...);
path:要执行的可执行文件的路径。
- 可以是绝对路径(如:
/bin/ls)- 也可以是相对路径(前提是当前目录下存在该可执行文件)
arg:传递给新程序的参数列表。
- 第一个参数通常要与要执行的程序名一致(虽然系统并不严格检查,但这是一种约定俗成的写法)
- 参数列表以NULL结尾,用于标识参数的结束
...:表示可变参数,即可以传入多个参数。
返回值
如果执行成功,它不会返回调用者,因为当前进程的执行空间已经被新的程序替换
- exec系列的函数,不用做返回值判断,只要返回,就是失败!
如果执行失败,它会返回
-1,并设置全局变量errno来指示错误的原因,常见的错误原因包括:
- 没有找到指定的可执行文件,
errno被设置为ENOENT- 没有执行权限,
errno被设置为EACCES
② 使用
-------父进程直接替换-------
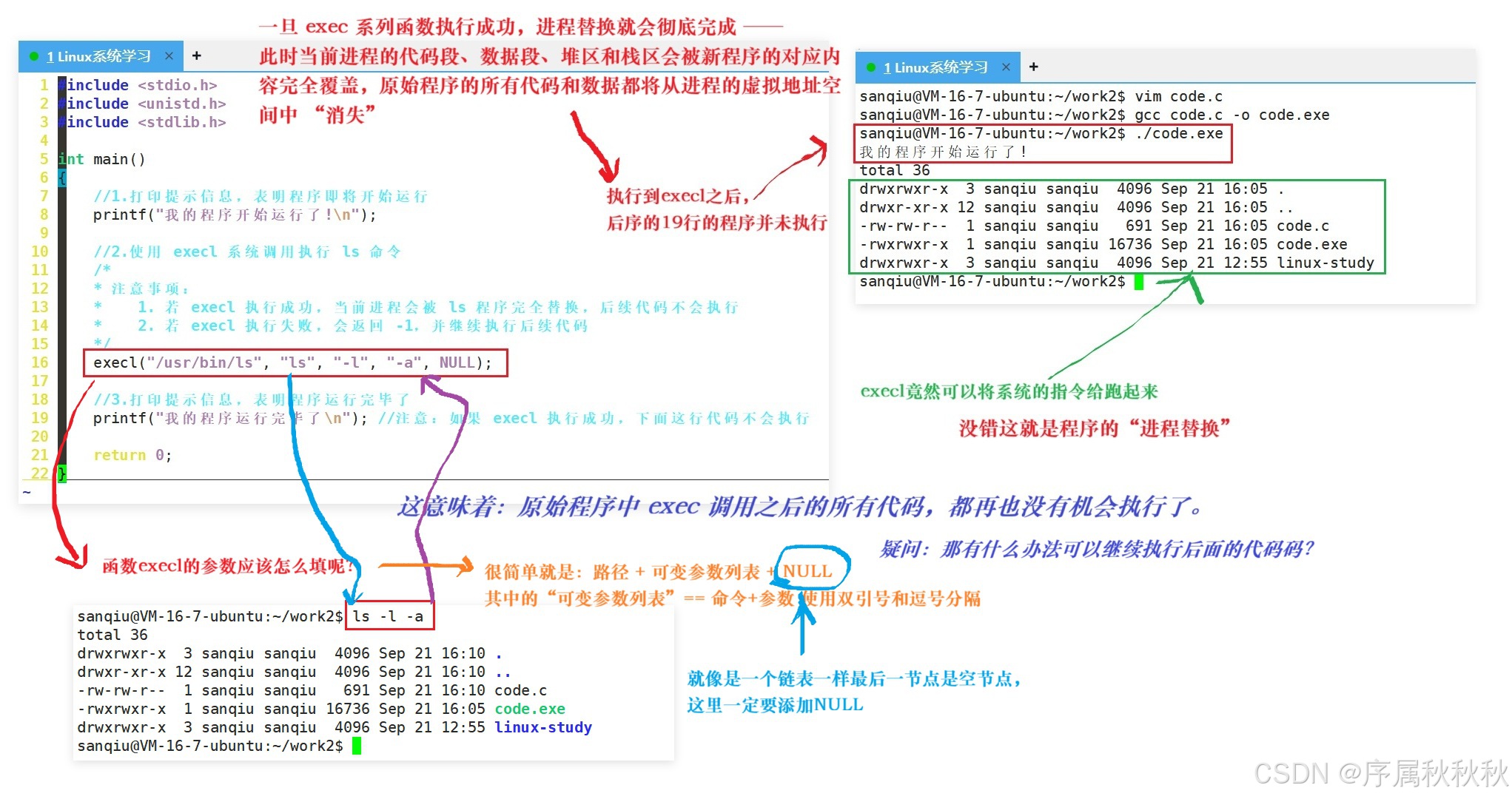
-------子进程替换系统命令-------
上面的示例清晰地展示了进程替换的核心特性:
- 一旦
exec函数族调用成功,当前进程的执行空间(代码段、数据段、堆栈等)会被新程序完全覆盖- 原始程序中
exec调用之后的所有代码,都彻底失去了执行的机会 ------ 因为承载这些代码的 "内存载体" 已经被新程序替换了
这就引出一个关键问题:如果我们既想执行新程序,又希望保留原始程序的逻辑(让
exec之后的代码能继续运行),有什么办法呢?答案很简单:不要在 "原始进程" 中直接执行进程替换,而是先创建子进程,让子进程去执行替换,原始进程(父进程)则继续保留并执行自己的后续代码
总结:
- 进程替换的核心限制是 "替换当前进程的代码和数据",因此若想保留原始程序的逻辑,必须通过 "父进程创建子进程,子进程承担替换" 的模式
- 这种模式既利用了进程替换的灵活性(让子进程执行任意新程序),又保证了原始进程的完整性(父进程可继续处理其他任务),是 Linux 系统中进程管理的经典实践
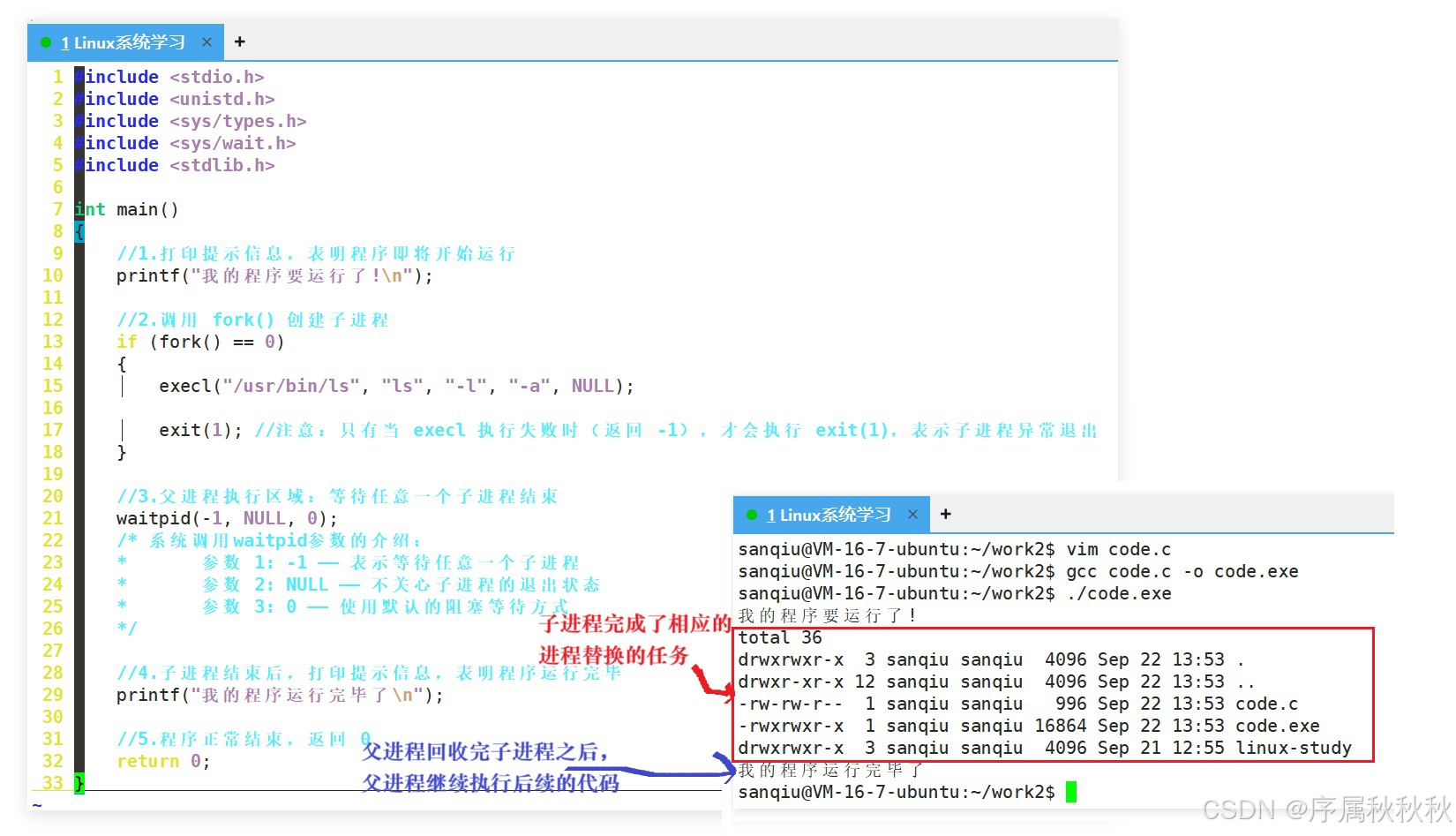
-------子进程替换自定义程序-------
到这里,想必很多小伙伴会产生这样的好奇:
- 进程的程序替换,能替换成我们自己编写的程序吗?
- 比如,用一个我们自己写的 C 语言程序,去替换当前进程正在运行的 C++ 程序,这样的操作可行吗?
答案是完全可以
进程替换的核心逻辑,是用新程序的 "可执行代码和数据" 覆盖当前进程的内存空间
- 而这个 "新程序" 的编程语言 、开发工具并不受限制
- 只要它能被操作系统编译或解释为可独立运行的可执行文件(比如:Linux 下的 ELF 格式、Windows 下的 EXE 格式),能被加载到内存并转换为进程,就可以作为替换目标
无论是系统自带的
ls、pwd等命令,还是我们用 C、C++、Python、Go 等任何语言编写的程序(只要生成了符合系统标准的可执行文件),在进程替换的逻辑中本质是一样的 ------ 都是"可供操作系统加载执行的代码与数据集合"
总而言之 :只要一个程序能被操作系统识别并启动为独立进程,就可以成为进程替换的目标,与它的编写语言、开发框架无关
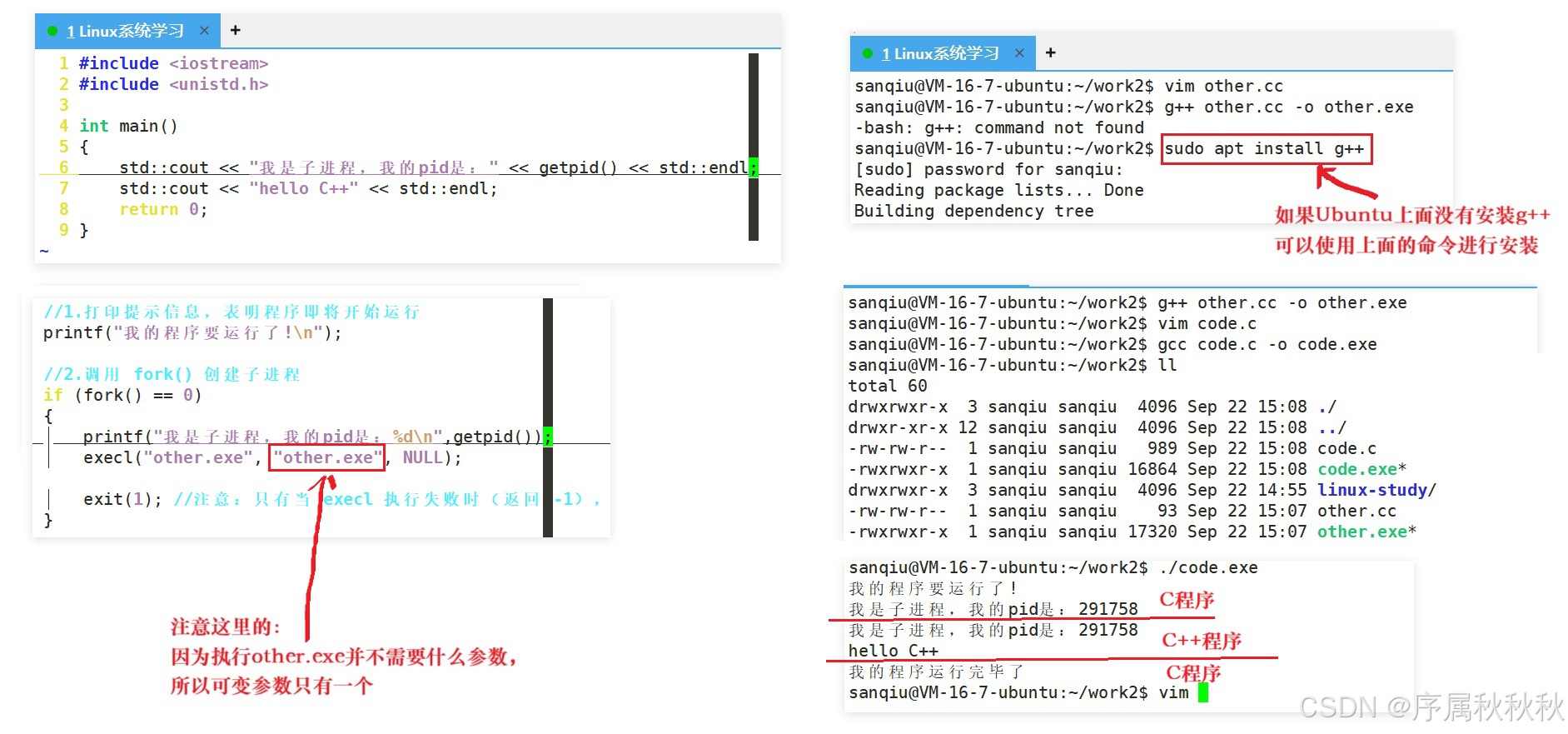
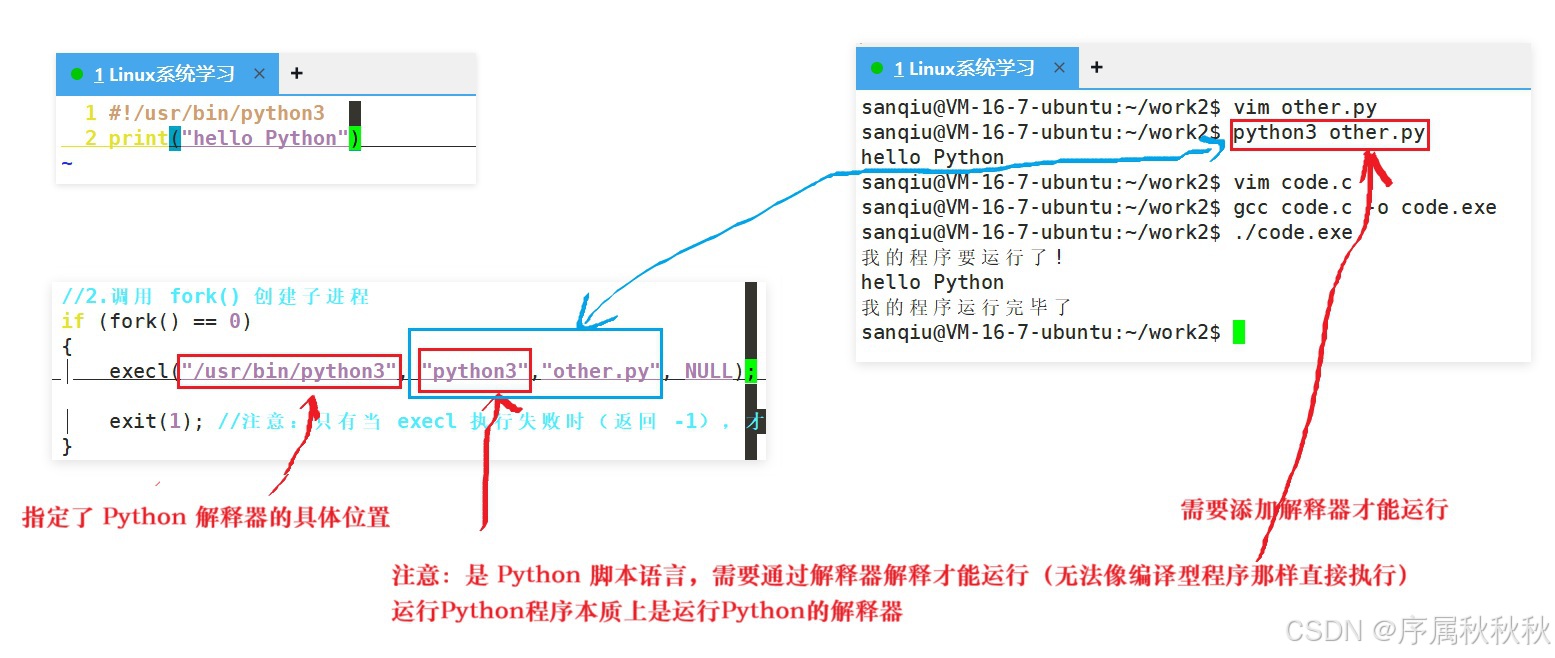
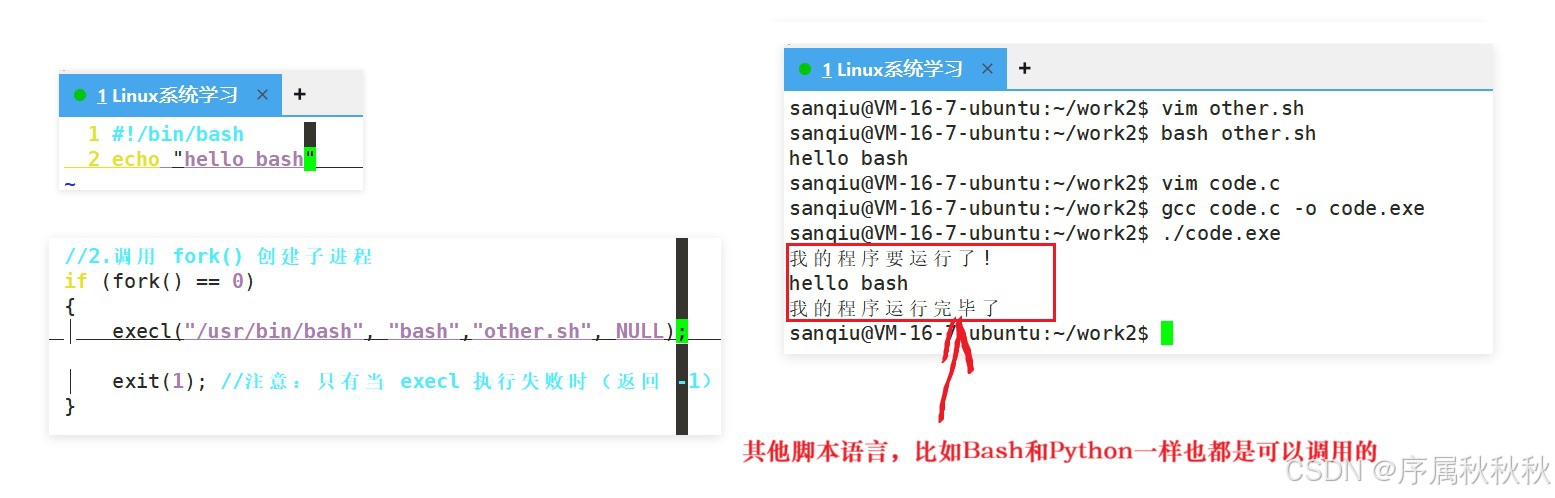
需要注意的是,前端语言(如:HTML、CSS、JavaScript 等)无法进行进程替换,这与它们的运行机制密切相关:
- 这些语言并非直接运行在操作系统上,而是由浏览器(或其他前端运行时环境)作为解释器来执行的 ------ 它们更像是浏览器进程内部的 "脚本逻辑",而非独立的操作系统进程
- 相比之下,进程替换的前提是 "目标程序必须能以独立进程的形式运行在操作系统中"
- 无论是 C/C++ 编译生成的可执行文件
- Python 脚本(通过 Python 解释器启动为进程)、Shell 命令
- 还是 Java 程序(通过 JVM 启动为进程)
- 只要它们能被操作系统识别并创建为独立进程(拥有自己的 PID、内存空间等),就可以成为进程替换的目标
简单来说:
- 只有那些能在操作系统中以独立进程为载体运行的程序,才具备被进程替换的条件
- 而前端语言由于依赖浏览器等宿主环境运行,本身并不具备独立进程的属性,因此自然无法参与进程替换
二、execlp
三、execv
四、execvp

五、execvpe
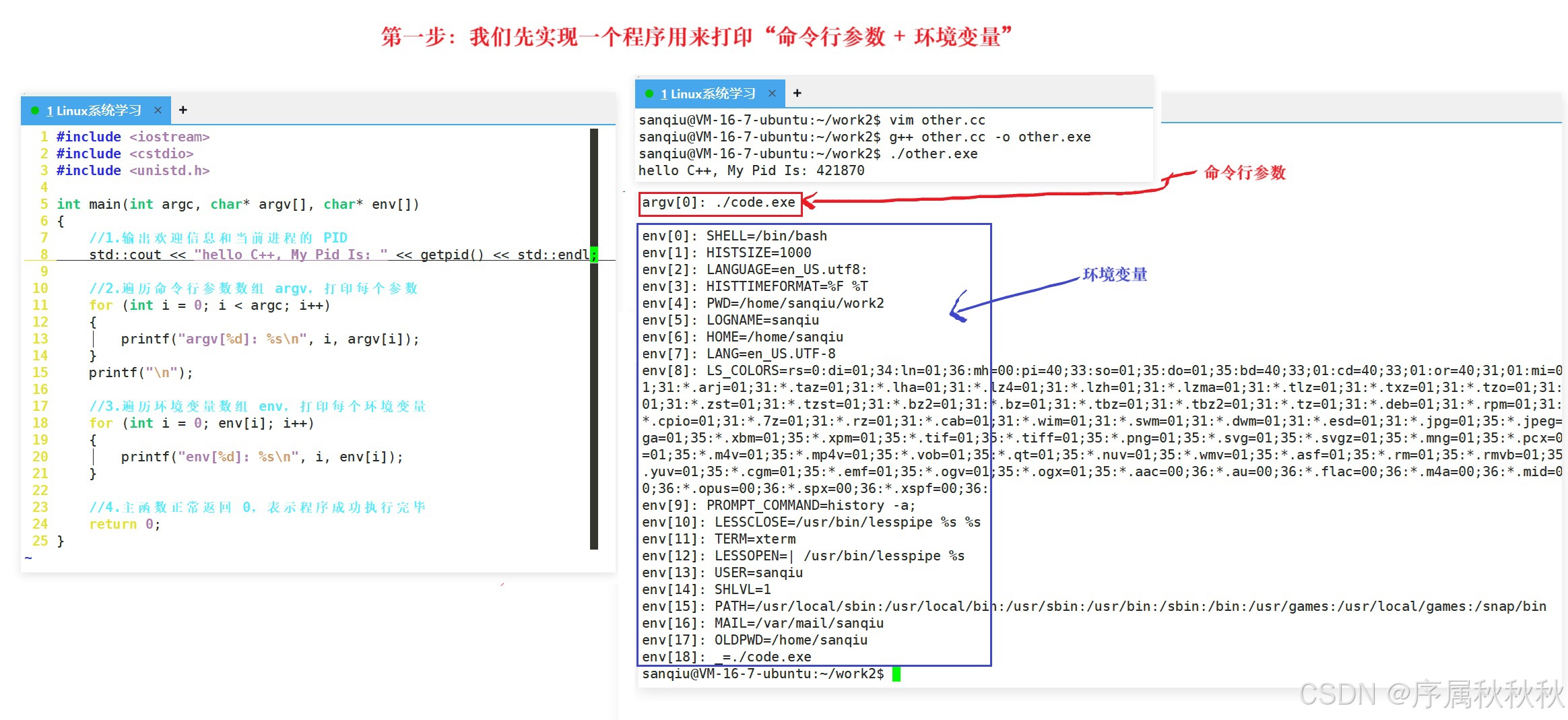
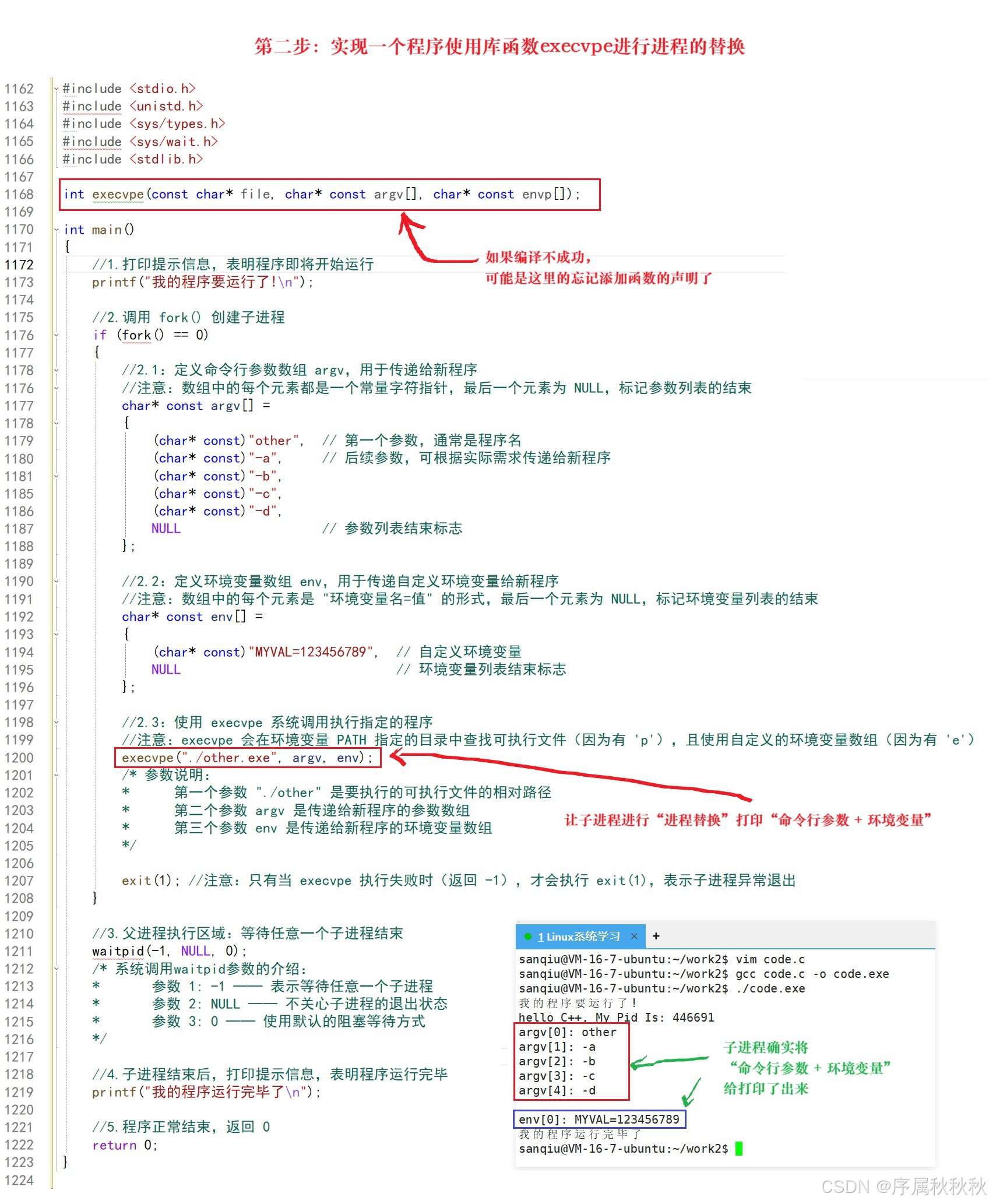
所以今天我们通过代码验证了一个核心逻辑:
在父进程中,我们通过
exec系列函数的参数传入了命令行参数和环境变量,而被替换的other程序确实成功接收到了这些参数和环境变量列表。这清晰地证明了 :被替换程序的命令行参数和环境变量,正是通过父进程调用
exec系列函数时传递的参数而来的。
不过我们也发现了一个关键现象:
other程序最终打印的环境变量,只剩下我们手动传入的那些,原本父进程中存在的旧环境变量(比如:系统默认的PATH、HOME等)全都消失了。这并非意外,而是
execvpe函数的特性决定的:
- 当使用带有 e 选项的 exec 函数(如:execvpe、execve)时,被替换的子进程会使用全新的环境变量列表,而非继承父进程的旧环境
- 它会用你明确传入的
env数组完全覆盖历史环境变量,旧的环境信息自然就不会保留
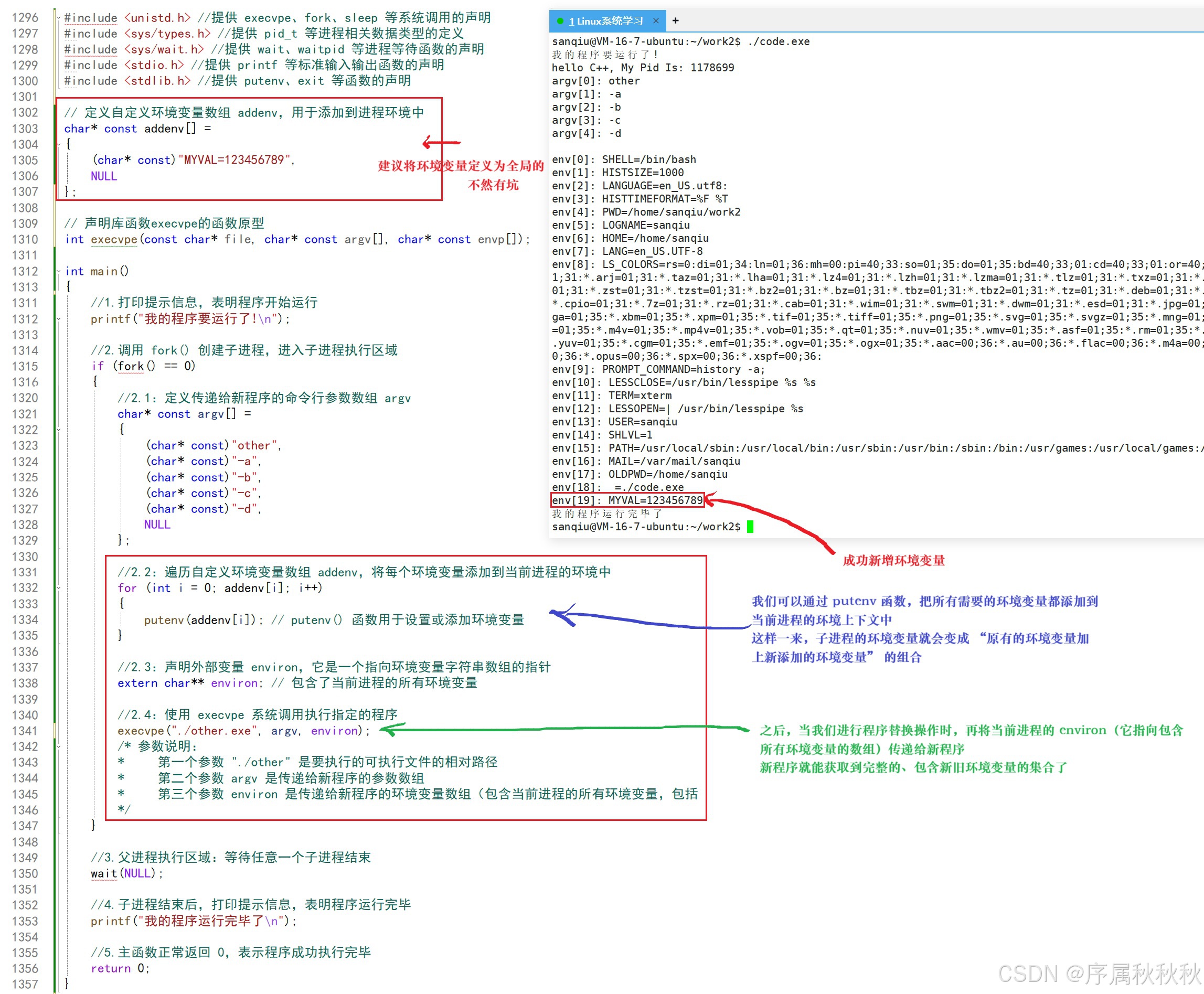
到这里,肯定有小伙伴会问:如果我不想用新环境变量覆盖旧的,只想以 "新增" 的方式给子进程添加环境变量,该怎么做呢?
方法一:putenv函数
其实我们之前也注意到一个细节:创建子进程后,如果调用不带
e选项的exec函数(比如:execvp),即便不手动传递环境变量,子进程也能获取到父进程的环境变量,这是为什么?答案藏在进程的底层机制里:
- 任何进程都存在一个名为 environ 的全局指针,它指向当前进程的环境变量表,而这个表本身就存储在进程的地址空间中
- 当我们调用
execvp这类不带e选项的函数时,虽然没有显式传递环境变量参数,但execvp内部会默认将当前进程的environ指针传递给被替换的子进程 ------ 换句话说,子进程直接继承了父进程的环境变量表,根本不需要我们额外 "传参"
所以:若想实现 "追加式" 传递环境变量(即保留父进程旧环境,同时添加新变量),核心思路就是
- 先在父进程(或替换前的子进程)中修改自己的 environ 表
- 再让 exec 函数传递这个更新后的表
而实现这一点的关键函数,就是
putenv
putenv的功能很直接:谁调用它,就会在谁的环境变量列表中新增(或修改)一个环境变量
- 举个例子:如果进程 A 创建了进程 B,进程 B 又创建了进程 C,若在进程 B 的上下文里调用
putenv("MYVAL=123")- 那么这个新增的
MYVAL环境变量只有进程 B 和它的子进程 C 能看到,进程 A 是看不到的 ------ 这也符合环境变量 "父子继承" 的传递规则
总结一下环境变量的传递逻辑:
- 使用带有
e选项的exec函数(如:execvpe、execve)时,子进程会使用你传入的全新env数组,覆盖所有旧环境- 若想保留旧环境并追加新变量,无需手动构建完整的
env数组 ------ 只需在调用 exec 前,用 putenv 给当前进程的 environ 表新增变量,再让 exec 传递这个包含 "旧环境 + 新变量" 的 environ 指针,子进程就能同时拿到历史环境和新增变量了

方法二:environ指针
六、execle
想必大家在学习了上面这些库函数之后,对
execle的使用方法应该已经很清楚了吧,这里鼠鼠就不再进行赘述了。
七、execve(系统调用)
现在大家可以数一数,我们已经学习了多少个
exec系列的函数了。鼠鼠已经帮大家数过,上面我们一共介绍了六个exec系列的库函数。哈哈,想必大家已经猜到了 ------ 还剩最后一个 "成员" 没和大家见面。不过更准确地说,接下来我们要介绍的,是
exec家族的 "根":系统调用execve
- 其实我们之前学习的六个
exec函数,本质上都是对编程语言层面的封装
- 这些封装为了适配不同的使用场景,给我们提供了多种传参形式
- 比如有的不需要手动传环境变量,有的支持直接通过
PATH查找程序- 但追根溯源,所有
exec系列的函数最终都会调用同一个底层接口 ------ 系统调用execve
而
execve作为最基础的系统调用,有一个固定要求:必须显式传递三个核心参数 ------可执行文件的路径、命令行参数数组、环境变量数组
- 这意味着,我们之前用的那些 "不需要手动传递环境变量" 的
exec库函数(比如:execvp),并不是真的没传递环境变量,而是它们在封装时自动帮我们使用了当前进程默认的环境变量(即:environ指针指向的环境表)- 一旦我们使用的是带有
e后缀的exec函数(比如:execvpe、execle)并手动传入环境变量数组,它们就会将我们传入的数组传递给底层的execve,让新程序使用我们指定的环境变量,而非默认值
4. 进程替换的本质是什么?
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
//1.打印提示信息,表明程序即将开始运行
printf("我的程序开始运行了!\n");
//2.使用 execl 系统调用执行 ls 命令
/*
* 注意事项:
* 1. 若 execl 执行成功,当前进程会被 ls 程序完全替换,后续代码不会执行
* 2. 若 execl 执行失败,会返回 -1,并继续执行后续代码
*/
execl("/usr/bin/ls", "ls", "-l", "-a", NULL);
//3.打印提示信息,表明程序运行完毕了
printf("我的程序运行完毕了\n"); //注意:如果 execl 执行成功,下面这行代码不会执行
return 0;
}当我们的程序执行到
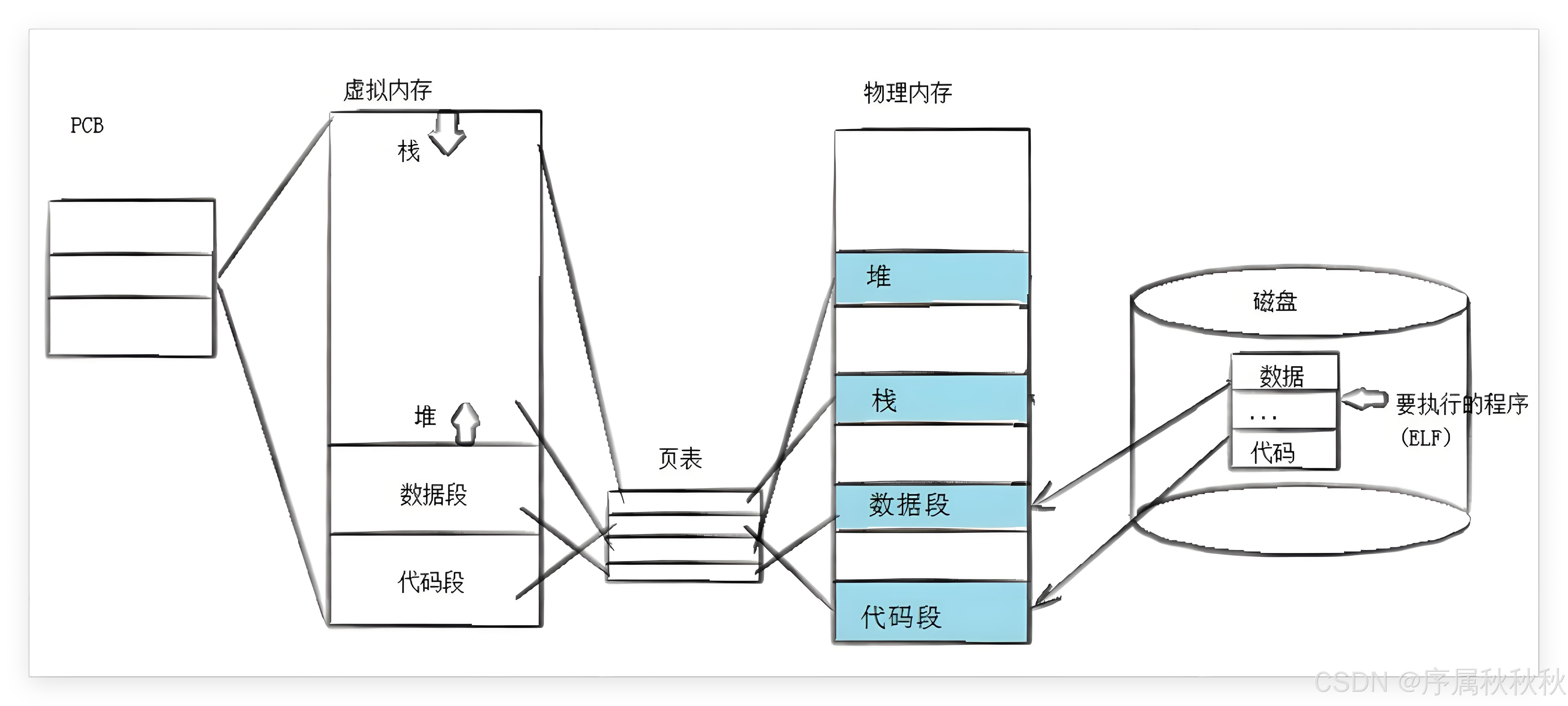
printf等语句时,它本身就是一个正在运行的进程。这个进程从创建之初就拥有完整的组成部分:
- 内核中的进程控制块(PCB)、独立的虚拟地址空间、映射虚拟地址与物理地址的页表,以及虚拟地址空间中划分的代码段、数据段、堆区和栈区
- 其中页表的核心作用就是将虚拟地址空间中的代码段、数据段等区域,映射到物理内存中实际存储代码和数据的位置
当进程执行到
execl(或其他exec函数族)时,本质上是告诉系统:"我要切换到一个新的程序运行"。这个 "新程序" 其实就是一组新的代码和数据(通常存储在磁盘上的可执行文件中)
execl执行成功后,系统会完成以下关键操作:
- 替换代码和数据:将新程序的代码加载到当前进程的代码段,将新程序的数据(初始化数据、未初始化数据等)加载到数据段,同时重置堆区和栈区(以适应新程序的内存需求)
- 调整页表映射:更新页表中与代码段、数据段相关的映射关系,让虚拟地址空间中的代码段、数据段指向新程序在物理内存中的位置
- 保留核心内核结构:进程的 PCB 不会改变(包括 PID、进程状态、优先级等元信息),虚拟地址空间的整体框架也保持不变 ------ 因为进程的 "身份标识" 和 "内存管理边界" 并未消失
这就是进程替换 的核心逻辑:它只替换了进程的 "代码和数据" 部分,而进程的内核数据结构(PCB)和虚拟地址空间框架得以保留
简单来说:进程 = 内核数据结构(PCB ) + 代码和数据。进程替换的本质,就是在保持 "内核数据结构" 不变的前提下,彻底替换 "代码和数据",让同一个进程 "改头换面" 去执行新的任务。
我们知道:任何一个程序要运行起来,必须先被载入内存并转化为进程 ------ 程序的加载过程,本质上就是操作系统动态创建进程的过程。
后来学习 Shell 时我们又了解到:我们在命令行上启动的所有进程,其实都是 Shell 进程的子进程。那么问题来了,这些命令究竟是怎么 "跑起来" 的呢?
结合我们现在的知识来拆解,答案就很清晰了:
- 当我们在 Shell 中输入一条命令时,Shell 进程会先通过
fork系统调用创建一个子进程;此时父进程(Shell)会进入阻塞状态,通过wait系列函数等待子进程的执行结果- 而子进程则会立刻调用 exec 系列接口进行程序替换------ 这个过程中,子进程原有的代码、数据会被新程序(即我们输入的命令对应的可执行文件)完全覆盖,新程序的代码和数据被载入内存后,子进程就摇身一变成为了执行该命令的进程。这样一来,我们输入的命令自然就 "跑起来" 了
从这个角度看,exec 系列接口其实就属于程序加载器的核心实现范畴
- 换句话说,无论是 Shell 这样的命令解释器,还是其他需要动态加载并执行程序的工具(比如:各种 IDE、脚本引擎)
- 只要它们涉及 "加载新程序并替换当前进程执行逻辑" 的需求,底层依赖的核心接口必然是 exec 系列函数
