
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. Python 字典:键值对的高效映射](#一. Python 字典:键值对的高效映射)
-
- [1.1 字典的核心特性](#1.1 字典的核心特性)
- [1.2 字典的核心操作](#1.2 字典的核心操作)
- [二. 文件操作:数据持久化的核心](#二. 文件操作:数据持久化的核心)
-
- [2.1 文件路径 与 打开方式](#2.1 文件路径 与 打开方式)
-
- [2.1.1 文件路径](#2.1.1 文件路径)
- [2.1.2 打开方式(open() 函数核心参数)](#2.1.2 打开方式(open() 函数核心参数))
- [2.2 文本文件的读写操作](#2.2 文本文件的读写操作)
- [2.3 中文编码处理(避坑重点)](#2.3 中文编码处理(避坑重点))
- [三. 上下文管理器:with语句简化文件操作](#三. 上下文管理器:with语句简化文件操作)
- 结尾:
前言:
在 Python 开发中,字典(
dict)和文件操作是两大高频核心技能:字典凭借键值对映射实现高效数据查询,是处理配置、缓存、映射关系的首选;文件操作则解决数据持久化问题,让内存中的数据能永久存储到硬盘。而上下文管理器(with语句)更是简化文件操作、避免资源泄露的 "神器"。本文从字典的底层原理、核心操作,到文件的读写逻辑、编码处理,再到上下文管理器的妙用,层层递进帮你吃透这些实用技能,从 "会用" 升级到 "活用"。
一. Python 字典:键值对的高效映射
字典是 Python 中唯一的内置映射类型,本质是哈希表,通过键(key) 快速定位 值(value),查询时间复杂度接近 O(1),比列表遍历高效得多。
1.1 字典的核心特性
- 键(key):必须唯一且哈希(不可变类型:整数,字符串,元组等;列表,字典等可变类型不能作为key);
- 值(value):可以是任意类型(整数,字符串,列表,甚至字典)
- Python 现在字典会保留键值对的插入顺序(3.7 版本之后)
- 支持动态新增,修改,删除键值对,灵活性极高。
1.2 字典的核心操作
(1)创建字典
python
# 1. 创建字典
# 方法1: 直接用 {} (推荐)
a = {}
print(type(a))
# 方法2: 用 dict() 函数
b = dict()
print(type(b))
# 2. 创建字典的同时设置初始值
# a = {'id' : 1, 'name' : 'Lotso'}
# 为了美观,会像下面这样书写,最后一个键值对带不带 , 都行
a = {
'id' : 1,
'name' : "Lotso"
}
print(a)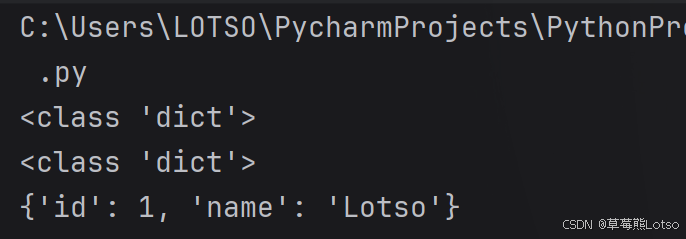
(2)增删查改
- 查:
python
# 1. 使用 in 来判定某个 key 是否在字典中存在.
a = {
'id' : 1,
'name' : "Lotso"
}
print('id' in a)
print('classId' in a)
# in 只是判定 key 是否存在,和 value 无关!
# print('Lotso' in a) # 这个会返回 false,因为这个是 value 值
# not in 来判定 key 在字典中是不是不存在
print('id' not in a)
print('classId' not in a)
# 2. 使用 [ ] 来根据 key 获取到 value
a = {
'id' : 1,
'name' : "Lotso",
100 : 'lisi'
}
print(a['id'])
print(a['name'])
print(a[100])
# print(a['classId']) # 会直接报错- 增 && 改 && 删:
python
# 1. 在字典中新增元素,使用 [ ] 来进行.
a = {
'id' : 1,
'name' : "Lotso"
}
# 这个操作就是往字典里插入新的键值对
a['score'] = 90
print(a)
# 2. 在字典中,根据 key 修改 value,也是用 [ ] 来进行的
a['score'] = 79
print(a)
# 3. 使用 pop 方法,根据 key 来删除键值对
a.pop('name')
print(a)(3)遍历字典
python
# 直接使用 for 循环来遍历字典
a = {
'name' : 'Lotso',
'id' : 1,
'score' : 90
}
# for key in a:
# print(key, a[key])
# print(a.keys())
# print(a.values())
# print(a.items())
# 推荐直接像下面这样
for key, value in a.items():
print(key, value)(4)合法 key 的判定
合法 key 必须是 "可哈希" 类型(能通过 hash() 函数计算哈希值),常见合法/非法 key:
python
# 使用 hash 函数能够计算出一个变量的哈希值。
print(hash(0))
print(hash(3.14))
print(hash('hello'))
print(hash(True))
print(hash((1,2,3)))
# 有的类型是不能计算哈希值的,不能作为 key
# print(hash([1,2,3]))
# Traceback (most recent call last):
# File "D:\Gitee.code\python-fundamentals-\PythonProject\2025--12--02\code54.py", line 9, in <module>
# print(hash([1,2,3]))
# ~~~~^^^^^^^^^
# TypeError: unhashable type: 'list'
# print(hash({ }))
# Traceback (most recent call last):
# File "D:\Gitee.code\python-fundamentals-\PythonProject\2025--12--02\code54.py", line 10, in <module>
# print(hash({ }))
# ~~~~^^^^^
# TypeError: unhashable type: 'dict'二. 文件操作:数据持久化的核心
变量存储在内存中,程序重启后数据丢失;文件操作则将数据写入硬盘,实现持久化存储。Python 文件操作支持文本文件,二进制文件(图片,视频等),核心流程是:"打开 -> 操作 -> 关闭"
2.1 文件路径 与 打开方式
2.1.1 文件路径
- 绝对路径 :从盘符/根目录开始(如:
D:/test.txt,home/user/test.txt) - 相对路径 :相对于当前程序所在目录(如:
./test.txt,./可省略) - 路径分隔符 :Windows用
\,Linux/Mac用/,Python
python
# 使用 open 打开一个文件
f = open('D:/Python环境/test.txt','r')
print(f)
print(type(f))
# 记得要关闭文件
f.close()
python
# 打开文件个数的上限
flist = []
count = 0
while True:
f = open('D:/Python环境/test.txt','r')
flist.append(f)
# f.close()
count += 1
print(f'打开文件的个数:{count}')
# 如果不关闭,文件打开有上限2.1.2 打开方式(open() 函数核心参数)
| 打开方式 | 含义 | 注意事项 |
|---|---|---|
'r' |
只读模式(默认) | 文件不存在会抛 FileNotFoundError |
'w' |
只写模式 | 覆盖原有内容,文件不存在则创建 |
'a' |
追加模式 | 在文件末尾写入,文件不存在则创建 |
'r+' |
读写模式 | 不覆盖原有内容,光标默认在文件开头 |
'wb' / 'rb' |
二进制写 / 读(用于图片、视频等非文本文件) | 无需指定 encoding 参数 |
补充说明:
'w+':读写模式,会清空文件后写入,文件不存在则创建。'a+':追加读写模式,文件不存在则创建,光标默认在文件末尾。'x':独占创建模式,文件已存在则报错,用于防止覆盖。
python
# 使用 write 来实现写文件的操作
f = open('D:/Python环境/test.txt','w')
f.write('hello world')
f.close()
# 写文件的时候,需要使用 w 的方式打开.如果是 r 方式打开,则会抛出异常.
# f = open('D:/Python环境/test.txt','r')
# f.write('hello world')
# f.close()
# Traceback (most recent call last):
# File "D:\Gitee.code\python-fundamentals-\PythonProject\2025--12--07\code57.py", line 9, in <module>
# f.write('hello world')
# ~~~~~~~^^^^^^^^^^^^^^^
# io.UnsupportedOperation: not writable
# 写方式打开,其实又有两种情况,直接写方式打开,追加写方式打开
f = open('D:/Python环境/test.txt','w')
f.write('1111\n')
f.close()
f = open('D:/Python环境/test.txt','a')
f.write('2222')
f.close()
# 如果文件对象已经关闭,那么意味着系统中和该文件相关的内存资源已经释放了.强行去写,就会出异常
# f = open('D:/Python环境/test.txt','w')
# f.close()
# f.write('hello')
# Traceback (most recent call last):
# File "D:\Gitee.code\python-fundamentals-\PythonProject\2025--12--07\code57.py", line 31, in <module>
# f.write('hello')
# ~~~~~~~^^^^^^^^^
# ValueError: I/O operation on closed file.2.2 文本文件的读写操作
(1)基本读写(手动关闭文件)
python
# 1. 写文件('w'模式,覆盖原有内容)
f = open("test.txt", "w", encoding="utf-8") # encoding指定字符编码(关键!)
f.write("床前明月光\n疑是地上霜\n") # 写入字符串,\n换行
f.write("举头望明月\n低头思故乡")
f.close() # 必须关闭文件,否则数据可能丢失(缓冲区未刷新)
# 2. 读文件('r'模式)
f = open("test.txt", "r", encoding="utf-8")
# 方式1:读指定长度字符
print(f.read(5)) # 输出:床前明月光
# 方式2:逐行读取(推荐,适合大文件)
f.seek(0) # 光标回到文件开头
for line in f:
print(line.strip()) # strip()去除换行符和空格
# 方式3:读取所有行(返回列表)
f.seek(0)
lines = f.readlines()
print(lines) # 输出:['床前明月光\n', '疑是地上霜\n', '举头望明月\n', '低头思故乡']
f.close() # 手动关闭,避免资源泄露
python
# 1. 使用 read 来读取文件内容.指定读几个字符.
# f = open('D:/Python环境/test.txt','r',encoding='utf-8')
# result = f.read(2)
# print(result)
# f.close()
# 2. 更常见的需求,是按行来读取~~
# 最常见的办法,直接 for 循环
# f = open('D:/Python环境/test.txt','r',encoding='utf-8')
# for line in f:
# print(f'line:{line}',end='')
# f.close()
# 3. 还可以使用 readlines 方法直接把整个文件所有内容读取出来,按照行组织到一个列表里.
f = open('D:/Python环境/test.txt','r',encoding='utf-8')
lines = f.readlines()
print(lines)
f.close()(2)追加写 'a'
python
f = open("test.txt", "a", encoding="utf-8")
f.write("\n------李白《静夜思》")
f.close()2.3 中文编码处理(避坑重点)
读写中文时最容易出现乱码或UnicodeDecodeError,核心是编码一致:
- 保存文件时指定编码(如
utf-8); - 读取文件时使用相同编码;
- Windows 默认编码是
gbk,Linux/Mac 默认是utf-8,建议统一用utf-8。
python
# 正确读写中文(指定encoding="utf-8")
f = open("中文测试.txt", "w", encoding="utf-8")
f.write("你好,Python!")
f.close()
f = open("中文测试.txt", "r", encoding="utf-8")
print(f.read()) # 正常输出:你好,Python!
f.close()三. 上下文管理器:with语句简化文件操作
打开文件之后,是容易忘记关闭的。Python提供了上下文管理器(可以类比C++中的智能指针来理解),来帮助程序员自动关闭文件
- 使用 with 语句打开文件。
- 当 with 内部的代码块执行完毕后,就会自动调用关闭方式。
python
with open('D:/Python环境/test.txt', 'r', encoding='utf8') as f:
lines = f.readlines()
print(line
python
# 上下文管理器 -- 作用类似 C++ 中的智能指针
# 有些时候非常容易遗漏 close
# 使用上下文管理器,解决这个问题
# def func():
# with open('D:/Python环境/test.txt','r',encoding='utf-8') as f:
# # 进行文件这里的处理逻辑
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# if cond:
# return
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# # 假设这里有很多的代码
# if cond:
# return结尾:
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:字典和文件操作是 Python 开发的 "基本功",而上下文管理器则是 "进阶优化" 的关键。掌握字典的高效映射,能让数据处理更快捷;精通文件操作,能解决数据持久化需求;善用with语句,能让代码更简洁、更安全。这些技能在实际开发中无处不在 ------ 从配置管理、数据缓存,到日志记录、文件解析,都是高频应用场景。多加练习,就能灵活运用到项目中。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
