目录
- 循环神经网络相关知识点梳理
-
- 一、LSTM/GRU
-
- [1. LSTM(长短期记忆网络)](#1. LSTM(长短期记忆网络))
- [2. GRU(门控循环单元)](#2. GRU(门控循环单元))
- [3. 两者区别](#3. 两者区别)
- [4. 通俗类比](#4. 通俗类比)
- 二、字符级与词级对比
- 案例实现:以长篇英文小说《傲慢与偏见》为例,进行文本生成
-
- 代码实现逻辑
- 重点代码解析
-
- [1. 数据加载CharDataset()](#1. 数据加载CharDataset())
-
- 1)`init`:初始化数据集
- [2) `len`:返回数据集的总样本数](#2)
__len__:返回数据集的总样本数) - 3)`getitem`:返回单个训练样本
- [2. 超参数定义](#2. 超参数定义)
- [3. 数据加载器构建:](#3. 数据加载器构建:)
- [4. RNN模型定义:RNNModel](#4. RNN模型定义:RNNModel)
- [5. 模型输入输出](#5. 模型输入输出)
- [6. 模型的保存 torch.save()](#6. 模型的保存 torch.save())
- 完整代码
循环神经网络相关知识点梳理
一、LSTM/GRU
二者都是循环神经网络(RNN)的改进版本,核心解决传统RNN无法捕捉长序列依赖、易出现梯度消失/爆炸的问题,是处理文本、语音等序列数据的核心模型:
1. LSTM(长短期记忆网络)
- 核心 :通过 输入门、遗忘门、输出门 + 细胞状态 控制信息的存储/丢弃,像带"记忆抽屉"的RNN------有用的长距离信息(比如文本开头的"主角名字")能被保留,无用的噪声(比如无关标点)被遗忘。
- 特点:结构稍复杂,但记忆能力强,适合长序列(如长文本、语音)。
2. GRU(门控循环单元)
- 核心:LSTM的简化版,合并了LSTM的门结构,仅保留「更新门、重置门」,用更少参数实现近似效果。
- 特点:结构更简单、训练更快,显存占用低,短序列/中小数据集下效果接近LSTM。
3. 两者区别
| 维度 | LSTM | GRU |
|---|---|---|
| 门数量 | 3个(输入/遗忘/输出) | 2个(更新/重置) |
| 参数量 | 多 | 少(约LSTM的2/3) |
| 训练速度 | 慢 | 快 |
| 长序列适配 | 更优 | 稍弱(但足够用) |
4. 通俗类比
- 传统RNN:记事儿的人,但只能记住最近的事,早的事全忘;
- LSTM:带笔记本的人,会筛选"记什么、忘什么",能记住很久前的关键信息;
- GRU:简化版笔记本,少了些功能,但更轻便,记事儿效率更高。
二、字符级与词级对比
1. 字符级模型的核心优势
| 维度 | 字符级模型 | 词级模型(如Word2Vec+RNN) |
|---|---|---|
| 词汇表大小 | 极小(英文仅26字母+标点≈50个),模型轻量化 | 极大(比如《傲慢与偏见》词汇量≈1万+),需更大嵌入层/显存 |
| OOV(未登录词) | 无OOV问题(所有字符都在映射中) | 易出现生僻词/拼写错误(如人名、变体词),模型无法处理 |
| 文本生成流畅性 | 能生成任意字符组合(包括新词、拼写),适合文学文本的连续生成 | 受限于词汇表,生成时易重复/生硬,难以处理词形变化(如walk→walking) |
| 数据效率 | 小词汇表+简单映射,训练速度快、显存占用低 | 大词汇表需更多训练数据,小数据集下易过拟合 |
2. 本案例采用字符级
- 文本特性:英文小说以连续字符构成词,字符级模型能捕捉字母组合规律,生成的文本更符合英文拼写/语法习惯;
- 工程落地 :代码使用CPU/GPU均可训练(词汇表仅几十维),若用词级模型,仅Embedding层就需
1万×128=128万参数,小显存设备(如普通显卡)易OOM; - 生成目标:代码目标是"续写文本",字符级生成更细腻,能模拟作者的标点、换行、拼写风格。而词级生成易出现"词堆砌",如重复出现"pride""prejudice"。
3. 字符级vs词级的适用场景对比
| 模型类型 | 适用场景 | 不适用场景 |
|---|---|---|
| 字符级RNN | 短文本生成、低资源语言、拼写纠错、文学续写 | 语义理解、情感分析、长文本摘要 |
| 词级RNN/Transformer | 语义任务、机器翻译、问答系统、情感分析 | 小数据集、生僻词多、低显存设备 |
4. 两种文本的预测生成过程
1)字符级文本
以单个字符为单位,逐字符预测、逐字符拼接,全程依赖"上一步生成的字符"作为下一步输入,是典型的自回归生成。
具体步骤:
- 初始输入 :给定起始文本,先把每个字符转成索引,形成初始输入序列
[5,20,11,...]。 - 第一次预测 :模型接收初始序列,输出每个位置的"下一个字符概率",但只取最后一个位置的预测结果 :
- 模型输出所有字符的概率分布(如
t:0.3, h:0.25, a:0.1); - 温度参数调整概率(温度0.8会稍微拉平概率,避免只选最高概率);
- 通过
torch.multinomial抽样选一个字符,拼接到生成文本后。
- 模型输出所有字符的概率分布(如
- 循环迭代 :把上一步选中的字符作为新的输入(仅这一个字符),模型基于它预测下一个字符(比如
a),拼接后变成"it is a truth ha"; - 终止条件:重复步骤3,直到生成指定长度(如500个字符),最终得到连续文本。
2)词级文本
:以单个词为单位,逐词预测、逐词拼接,步骤和字符级一致,但最小单位从"字符"换成"词"。也属于自回归预测生成。
具体步骤:
- 初始输入 :给定起始文本(如
"it is a truth"),先分词得到词列表["it", "is", "a", "truth"],再转成词索引(如it→10, is→25, a→3, truth→108),形成初始输入序列[10,25,3,108]。 - 第一次预测 :模型接收初始词序列,输出每个位置的"下一个词概率",取最后一个位置的预测结果:
- 模型输出所有词的概率分布(如
universally:0.4, acknowledged:0.3, universally:0.2); - 温度参数调整概率后抽样,选中
universally,拼接后生成文本:"it is a truth universally";
- 模型输出所有词的概率分布(如
- 循环迭代 :把上一步选中的词(
universally)作为新输入,预测下一个词(如acknowledged),拼接后变成"it is a truth universally acknowledged"; - 终止条件:重复直到生成指定词数,最终得到连续文本。
案例实现:以长篇英文小说《傲慢与偏见》为例,进行文本生成
代码实现逻辑
基于字符级RNN(LSTM/GRU)的《傲慢与偏见》文本生成模型:
- 数据预处理:加载文本→清洗(去噪、过滤低频字符)→字符去重排序→建立字符↔数字索引映射→转为索引序列;
- 数据集构建 :按固定序列长度切分文本,构建"输入序列-目标序列"对(输入
[idx:idx+100],目标[idx+1:idx+101],即预测下一个字符); - 模型搭建:Embedding层(字符转向量)→LSTM/GRU层(捕捉序列依赖)→全连接层(预测下一个字符的概率);
- 训练过程:梯度下降优化交叉熵损失,梯度裁剪防止爆炸,监控困惑度(文本生成的核心指标);
- 文本生成:给定起始文本,通过温度调节概率分布,逐字符生成连续文本。
重点代码解析
1. 数据加载CharDataset()
继承自pytorch里面的 Dataset , 构建字符级序列数据集。PyTorch的Dataset是自定义数据集的基类,必须实现__len__(返回样本总数)和__getitem__(返回单个样本)两个方法,CharDataset专门处理字符索引序列的切分。
1)__init__:初始化数据集
python
def __init__(self, text_idx, seq_len=100):
self.text_idx = text_idx # 整个文本的字符索引序列(如[5,20,1,9,...])
self.seq_len = seq_len # 每个样本的序列长度(默认100个字符)- 输入参数 :
text_idx:预处理后整个文本的 字符→索引 映射序列seq_len:每个训练样本包含的字符数量(超参数,这里默认100)
- 作用:把原始字符索引序列和序列长度保存为数据集的属性,供后续切分样本使用。
2) __len__:返回数据集的总样本数
python
def __len__(self):
return len(self.text_idx) - self.seq_len # 有效样本数- 计算逻辑 :
假设整个文本的字符索引序列长度是N,序列长度是100,那么能切分的有效样本数是N - 100。 每个索引对应一个起始位置。 - 每个样本需要取
seq_len个连续字符作为输入,最后一个样本的起始位置只能是N - seq_len(否则会超出序列范围)。
3)__getitem__:返回单个训练样本
python
def __getitem__(self, idx):
# input: [idx, idx+seq_len),目标: [idx+1, idx+seq_len+1)
input_seq = torch.tensor(self.text_idx[idx:idx+self.seq_len], dtype=torch.long)
target_seq = torch.tensor(self.text_idx[idx+1:idx+self.seq_len+1], dtype=torch.long)
return input_seq, target_seq-
核心逻辑(字符级自回归的训练样本构建) :
模型的训练目标是"输入一段字符,预测下一个字符",因此每个样本是错位的输入-目标序列对:
input_seq(输入序列):从索引idx开始,取seq_len个字符索引(如[idx, idx+1, ..., idx+99]);target_seq(目标序列):从索引idx+1开始,取seq_len个字符索引(如[idx+1, idx+2, ..., idx+100])。
-
数据类型 :
torch.long(长整型)是PyTorch Embedding层要求的输入类型(索引必须是整数)。
2. 超参数定义
python
seq_len = 100 # 序列长度
batch_size = 64 # 批次大小seq_len=100:- 每个训练样本包含100个字符索引,模型通过这100个字符学习"上下文依赖";
- 取值依据:太短(如20)无法捕捉长依赖,太长(如500)会增加显存占用、减慢训练速度,100是字符级文本生成的常用值。
batch_size=64:- 每次训练时一次性输入64个样本(64个长度为100的字符序列),通过批量计算提升训练效率;
- 取值依据:需适配硬件显存。
3. 数据加载器构建:
python
dataset = CharDataset(text_idx, seq_len)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)1)核心作用
dataset:基于自定义的CharDataset,把整文本的字符索引序列切分成「输入-目标」序列对(每个样本长度为seq_len);dataloader:PyTorch的批量数据迭代器,把dataset中的样本按batch_size打包、打乱顺序,供训练时批量读取,提升训练效率和泛化性。
2)关键参数解读
batch_size=64:每次返回64个样本,输入模型时维度为(64, 100)(64个样本,每个样本100个字符索引);shuffle=True:每个epoch训练前打乱样本顺序,避免模型学习到样本的顺序规律(如文本的章节顺序),防止过拟合。
3)数据流转逻辑
训练时遍历dataloader会得到:
inputs:形状(64, 100),64个长度为100的字符索引输入序列;targets:形状(64, 100),对应每个输入字符的下一个字符索引(目标序列)。
4. RNN模型定义:RNNModel
这是字符级文本生成的核心模型,整体流程为:字符索引→嵌入向量→RNN特征提取→全连接层预测下一个字符。
1)__init__:模型层初始化
python
def __init__(self, vocab_size, embed_dim=128, hidden_dim=256, num_layers=2, model_type="lstm", dropout=0.2):
super().__init__()
self.embed = nn.Embedding(vocab_size, embed_dim) # 字符嵌入层
self.dropout = nn.Dropout(dropout)
# 选择LSTM/GRU
if model_type == "lstm":
self.rnn = nn.LSTM(embed_dim, hidden_dim, num_layers, dropout=dropout, batch_first=True)
elif model_type == "gru":
self.rnn = nn.GRU(embed_dim, hidden_dim, num_layers, dropout=dropout, batch_first=True)
else:
raise ValueError("model_type must be 'lstm' or 'gru'")
self.fc = nn.Linear(hidden_dim, vocab_size) # 输出层
self.hidden_dim = hidden_dim
self.num_layers = num_layers各层作用拆解
| 层/参数 | 功能与意义 |
|---|---|
nn.Embedding |
字符嵌入层:把离散的字符索引(如5代表i)转为连续的向量(维度embed_dim=128),让模型学习字符的语义/拼写特征; 输入:(batch_size, seq_len) → 输出:(batch_size, seq_len, embed_dim) |
nn.Dropout |
随机丢弃20%的神经元,防止模型过拟合(比如记住文本中的个别字符组合,失去泛化能力) |
nn.LSTM/GRU |
序列特征提取层: - embed_dim:输入特征维度(嵌入向量维度); - hidden_dim:RNN隐藏层维度(256,决定特征表达能力); - num_layers:RNN堆叠层数(2层,增强特征提取能力); - batch_first=True:指定输入/输出维度为(batch_size, seq_len, dim)(默认是(seq_len, batch_size, dim),更符合使用习惯) |
nn.Linear |
输出层:把RNN输出的隐藏特征(维度256)映射到词汇表大小(如50个唯一字符),输出每个字符的预测概率; 输入:(batch_size, seq_len, 256) → 输出:(batch_size, seq_len, vocab_size) |
2)forward:模型前向传播
python
def forward(self, x, hidden):
# x: (batch_size, seq_len) 输入字符索引序列
embed = self.dropout(self.embed(x)) # (batch_size, seq_len, embed_dim)
out, hidden = self.rnn(embed, hidden) # out: (batch_size, seq_len, hidden_dim)
out = self.dropout(out)
out = self.fc(out) # (batch_size, seq_len, vocab_size)
return out, hidden前向传播步骤
- 字符嵌入+dropout :
x(64,100)→ 嵌入为(64,100,128)→ dropout后维度不变,减少过拟合; - RNN特征提取 :
- 输入嵌入向量和初始隐藏状态
hidden; - 输出
out:每个位置的RNN隐藏特征(64,100,256),包含每个字符的上下文信息; - 输出
hidden:更新后的隐藏状态(供下一次迭代使用,自回归生成关键);
- 输入嵌入向量和初始隐藏状态
- dropout+全连接层 :
out(64,100,256)→ dropout → 全连接层映射为(64,100,vocab_size),即每个位置预测所有字符的概率。
3)init_hidden:初始化RNN隐藏状态
python
def init_hidden(self, batch_size, device):
# 初始化隐藏状态(全0),适配LSTM/GRU的不同格式
weight = next(self.parameters()).data # 获取模型参数的设备/数据类型
if isinstance(self.rnn, nn.LSTM):
# LSTM有两个隐藏状态:h_0(隐藏层)、c_0(细胞状态),均为(num_layers, batch_size, hidden_dim)
return (weight.new(self.num_layers, batch_size, self.hidden_dim).zero_().to(device),
weight.new(self.num_layers, batch_size, self.hidden_dim).zero_().to(device))
else: # GRU只有一个隐藏状态h_0
return weight.new(self.num_layers, batch_size, self.hidden_dim).zero_().to(device)- RNN的隐藏状态记录了序列的上下文信息,训练/生成前需初始化(全0);
- 适配LSTM/GRU的不同结构:LSTM需要
(h_0, c_0)两个张量,GRU仅需h_0; - 动态适配
batch_size和device(CPU/GPU),保证隐藏状态和输入数据在同一设备。
5. 模型输入输出
| 输入 | 形状/类型 | 输出 | 形状/类型 |
|---|---|---|---|
x |
(batch_size, seq_len) | out |
(batch_size, seq_len, vocab_size) |
hidden |
LSTM:(2, num_layers, batch_size, hidden_dim);GRU:(num_layers, batch_size, hidden_dim) | hidden |
同输入hidden形状(更新后的隐藏状态) |
batch_first=True:必须保证输入x的维度是(batch_size, seq_len),否则RNN输入维度会错位;- 隐藏状态的
detach():训练时需对hidden做detach()(截断反向传播),避免梯度爆炸; - 输出维度匹配损失函数:
out需展平为(batch_size×seq_len, vocab_size),目标序列展平为(batch_size×seq_len),才能用CrossEntropyLoss计算损失。
6. 模型的保存 torch.save()
保存模型参数的核心价值是:固化训练成果,实现模型的复用、迁移和后续推理。
1)模型保存的两种核心方式
| 保存方式 | 核心原理 | 优点 | 缺点 |
|---|---|---|---|
| 方式1:保存参数(state_dict) | 仅保存模型的权重/偏置(参数字典) | 文件小、跨版本兼容、灵活 | 复用需重新定义模型结构 |
| 方式2:保存整个模型 | 序列化保存模型结构+参数 | 加载方便(无需定义结构) | 文件大、兼容性差(PyTorch版本易报错) |
2)通用保存代码
python
import torch
import torch.nn as nn
# ========== 方式1:保存state_dict(推荐) ==========
torch.save(model.state_dict(), "model_weights.pth")
# ========== 方式2:保存整个模型(不推荐) ==========
torch.save(model, "full_model.pth")3)模型复用
分为以下五步:
步骤1:准备必要文件
RNN字符级文本生成任务:
- 模型参数文件(.pth)
- 字符映射表(char_to_idx/idx_to_char)
- 模型超参数(embed_dim/hidden_dim等)
- 文本预处理逻辑(清洗/编码规则)
CNN图像识别任务:
- 模型参数文件(.pth)
- 图像预处理规则(归一化/尺寸/通道)
- 类别映射表(label2idx)
- 模型超参数(通道数/层数等)
步骤2:还原模型结构
必须复刻训练时的模型类定义 (层数、维度、激活函数、网络结构完全一致),结构不一致会导致参数加载失败
- RNN文本生成:需还原LSTM/GRU的层数、hidden_dim、embed_dim、输出层维度;
- CNN图像识别:需还原卷积层(Conv2d)的通道数、核大小、池化层、全连接层维度。
步骤3:加载模型参数
-
方式1(state_dict):先初始化模型结构,再加载参数
python# 1. 还原结构(以CNN为例) class CNN(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 32, 3) # 与训练时一致 self.fc1 = nn.Linear(32*30*30, 10) # 与训练时一致 def forward(self, x): # 与训练时一致的前向逻辑 pass # 2. 初始化模型+加载参数 model = CNN().to(device) model.load_state_dict(torch.load("model_weights.pth", map_location=device)) -
方式2(全模型):直接加载
pythonmodel = torch.load("full_model.pth", map_location=device)
步骤4:切换推理模式
- 调用
model.eval():禁用训练时的Dropout、BatchNorm等层的随机行为,保证推理结果稳定; - 推理时禁用梯度计算:
with torch.no_grad():(节省显存、加速推理)。
步骤5:数据预处理
推理数据的预处理逻辑必须和训练集完全一致,否则模型无法正确识别特征:
- RNN文本生成:字符编码规则、清洗规则必须与训练时一致;
- CNN图像识别:图像尺寸、归一化、通道顺序必须与训练时一致。
步骤6:执行推理
- RNN文本生成:自回归逐字符预测(输入起始文本→预测下一个字符→更新输入循环);
- CNN图像识别:输入预处理后的图像→输出类别概率→解码为标签。
完整代码
python
import requests
import re
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
from collections import Counter
import json
#清理缓存
torch.cuda.empty_cache()
# 从网站上面加载文本
# url = "https://www.gutenberg.org/cache/epub/1342/pg1342.txt"
# response = requests.get(url)
# text = response.text
# 本地加载
file_path=r"E:\wwproject\rnn-text\pg1342.txt"
try:
with open(file_path,'r',encoding="utf-8") as f:
text=f.read()
except UnicodeDecodeError:
with open(file_path,"r",encoding="gbk") as f:
text=f.read()
except FileNotFoundError:
raise FileNotFoundError(f"未找到文件")
# 定位正文范围(《傲慢与偏见》正文起始/结束标识)
start_idx = text.find("Chapter I") # 正文从第一章开始
end_idx = text.rfind("END OF THE PROJECT GUTENBERG EBOOK PRIDE AND PREJUDICE") # 正文结束位置
text = text[start_idx:end_idx]
# 仅去除非打印字符,保留大小写、换行、连字符等核心特征
text = re.sub(r"[^\x20-\x7E\n]", "", text) # 保留ASCII可打印字符+换行
# 合并连续空格/换行
text = re.sub(r" +", " ", text) # 多个空格→单个空格
text = re.sub(r"\n+", "\n", text) # 多个换行→单个换行
text = text.strip() # 去除首尾空格
# 过滤重复字符(如"aaaaa"→"a",避免噪声)
text = re.sub(r"(.)\1{2,}", r"\1", text) # 连续3个及以上相同字符保留1个
MIN_FREQ = 2
# 过滤低频字符(减少词汇表大小,提升模型泛化)
char_counter = Counter(text)
low_freq_chars = [char for char, cnt in char_counter.items() if cnt < MIN_FREQ]
for char in low_freq_chars:
text = text.replace(char, "") # 移除低频字符
# 提取唯一字符列表
chars = sorted(list(set(text))) # set()将字符串拆分为单个字符,并去重。然后转化为列表,默认按ASCII码排序
char_to_idx = {ch: i for i, ch in enumerate(chars)} # ['字符1':0,'字符2':1,...]
idx_to_char = {i: ch for i, ch in enumerate(chars)} # ['0':字符1,'1':字符2,...]
vocab_size = len(chars) # 统计词汇表大小(唯一字符数)
# 保存字符映射
char_mapping={
"chars":chars,
"char_to_idx":char_to_idx,
"idx_to_char":{str(k):v for k,v in idx_to_char.items()}, # json不支持int键,转字符串
"vocab_size":vocab_size
}
with open("char_mapping.json","w",encoding="utf-8") as f:
json.dump(char_mapping,f,ensure_ascii=False,indent=2)
# 文本转为索引序列
text_idx = [char_to_idx[ch] for ch in text] # 将原文的文本通过索引来表示
# 继承自pytorch里面的 Dataset , 构建字符级序列数据集
class CharDataset(Dataset):
def __init__(self, text_idx, seq_len=100):
self.text_idx = text_idx
self.seq_len = seq_len #每个样本的序列长度,默认为 100 字符
#返回样本总数
def __len__(self):
return len(self.text_idx) - self.seq_len # 能切分的有效样本数。每个样本需要取seq_len个连续字符作为输入,最后一个样本的起始位置就只能是 n-seq_len
#返回单个样本
def __getitem__(self, idx):
# input: [idx, idx+seq_len), target: [idx+1, idx+seq_len+1)
input_seq = torch.tensor(self.text_idx[idx:idx+self.seq_len], dtype=torch.long)
target_seq = torch.tensor(self.text_idx[idx+1:idx+self.seq_len+1], dtype=torch.long)
return input_seq, target_seq
# 超参数
seq_len = 100 # 序列长度
batch_size = 64
# 构建数据集和数据加载器
dataset = CharDataset(text_idx, seq_len)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
#模型定义
class RNNModel(nn.Module):
#vocab_size: 唯一字符数 embed_dim:输入特征维度 hidden_dim:RNN隐藏层维度 num_layers:RNN堆叠层数
def __init__(self, vocab_size, embed_dim=128, hidden_dim=256, num_layers=2, model_type="lstm", dropout=0.2):
super().__init__()
self.embed = nn.Embedding(vocab_size, embed_dim) # 字符嵌入层,把离散的字符索引转为连续的向量
self.layer_norm = nn.LayerNorm(embed_dim) # 加入层归一化,稳定训练
self.dropout = nn.Dropout(dropout) # 随机丢弃 20% 的神经元,防止模型过拟合
# 选择模型类型(LSTM/GRU)
if model_type == "lstm":
self.rnn = nn.LSTM(embed_dim, hidden_dim, num_layers, dropout=dropout, batch_first=True)
elif model_type == "gru":
self.rnn = nn.GRU(embed_dim, hidden_dim, num_layers, dropout=dropout, batch_first=True)
else:
raise ValueError("model_type must be 'lstm' or 'gru'")
self.fc = nn.Linear(hidden_dim, vocab_size) # 输出层(预测下一个字符)
self.hidden_dim = hidden_dim
self.num_layers = num_layers
# 模型前向传播
def forward(self, x, hidden):
# x: (batch_size, seq_len)
embed = self.dropout(self.embed(x)) # (batch_size, seq_len, embed_dim)
out, hidden = self.rnn(embed, hidden) # out: (batch_size, seq_len, hidden_dim)
out = self.dropout(out)
out = self.fc(out) # (batch_size, seq_len, vocab_size)
return out, hidden
# 初始化RNN隐藏状态
def init_hidden(self, batch_size, device):
# 初始化隐藏状态
weight = next(self.parameters()).data
if isinstance(self.rnn, nn.LSTM):
return (weight.new(self.num_layers, batch_size, self.hidden_dim).zero_().to(device),
weight.new(self.num_layers, batch_size, self.hidden_dim).zero_().to(device))
else: # GRU
return weight.new(self.num_layers, batch_size, self.hidden_dim).zero_().to(device)
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 模型初始化(以LSTM为例)
model = RNNModel(vocab_size, embed_dim=128, hidden_dim=256, num_layers=2, model_type="lstm").to(device)
# 损失函数与优化器
criterion = nn.CrossEntropyLoss() # 字符分类任务
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练参数
epochs = 5
clip = 5 # 梯度裁剪(防止梯度爆炸)
model.train()
for epoch in range(epochs):
hidden = model.init_hidden(batch_size, device)
total_loss = 0.0
for batch_idx, (inputs, targets) in enumerate(dataloader):
batch_size_current=inputs.size(0) #获取当前batch的实际大小
inputs, targets = inputs.to(device), targets.to(device)
# 每次迭代重新初始化匹配当前batch_size的隐藏状态
hidden=model.init_hidden(batch_size_current,device)
# 重置隐藏状态(截断反向传播)
hidden = tuple([h.detach() for h in hidden]) if isinstance(hidden, tuple) else hidden.detach()
# 前向传播
optimizer.zero_grad()
outputs, hidden = model(inputs, hidden)
# 计算损失(outputs需展平,targets需展平)
loss = criterion(outputs.reshape(-1, vocab_size), targets.reshape(-1))
total_loss += loss.item()*batch_size_current #加权累计损失
# 反向传播与优化
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip) # 梯度裁剪
optimizer.step()
# 打印进度
if batch_idx % 100 == 0:
print(f"Epoch {epoch + 1}/{epochs}, Batch {batch_idx}/{len(dataloader)}, Loss: {loss.item():.4f}")
# 每个epoch打印平均损失
avg_loss = total_loss / len(dataset)
perplexity = torch.exp(torch.tensor(avg_loss)) # 困惑度:文本生成/语言模型任务的核心评价指标,本质是衡量模型预测下一个字符的不确定性.这里是平均交叉熵损失的指数
print(f"Epoch {epoch + 1} Average Loss: {avg_loss:.4f}, Perplexity: {perplexity:.4f}")
torch.cuda.empty_cache()
# 保存模型
torch.save(model.state_dict(), "austen_rnn_lstm.pth")
# 保存模型超参数
hyper_params = {
"seq_len": seq_len, # 序列长度
"batch_size": batch_size, # 批次大小
"embed_dim": 128, # 嵌入维度
"hidden_dim": 256, # 隐藏层维度
"num_layers": 2, # RNN层数
"model_type": "lstm", # 模型类型
"dropout": 0.2, # dropout率
"lr": 0.001, # 学习率
"epochs": epochs # 训练轮数
}
with open("hyper_params.json", "w", encoding="utf-8") as f:
json.dump(hyper_params, f, indent=2)
torch.cuda.empty_cache()
def generate_text(model, start_text, char_to_idx, idx_to_char, num_chars=500, temperature=0.8):
model.eval()
device = next(model.parameters()).device
# 初始输入
input_seq = torch.tensor([char_to_idx[ch] for ch in start_text], dtype=torch.long).unsqueeze(0).to(device)
hidden = model.init_hidden(1, device) # batch_size=1
generated = start_text
with torch.no_grad():
for _ in range(num_chars):
# 前向传播
outputs, hidden = model(input_seq, hidden)
# 取最后一个字符的预测结果,按温度调整概率
output = outputs[:, -1, :] / temperature
probs = torch.softmax(output, dim=1)
idx = torch.multinomial(probs, num_samples=1).item()
# 生成下一个字符
generated_char = idx_to_char[idx]
generated += generated_char
# 更新输入(仅保留最后一个字符,实现序列延续)
input_seq = torch.tensor([[idx]], dtype=torch.long).to(device)
return generated
# 训练完成后,基于初始字符生成连续文本
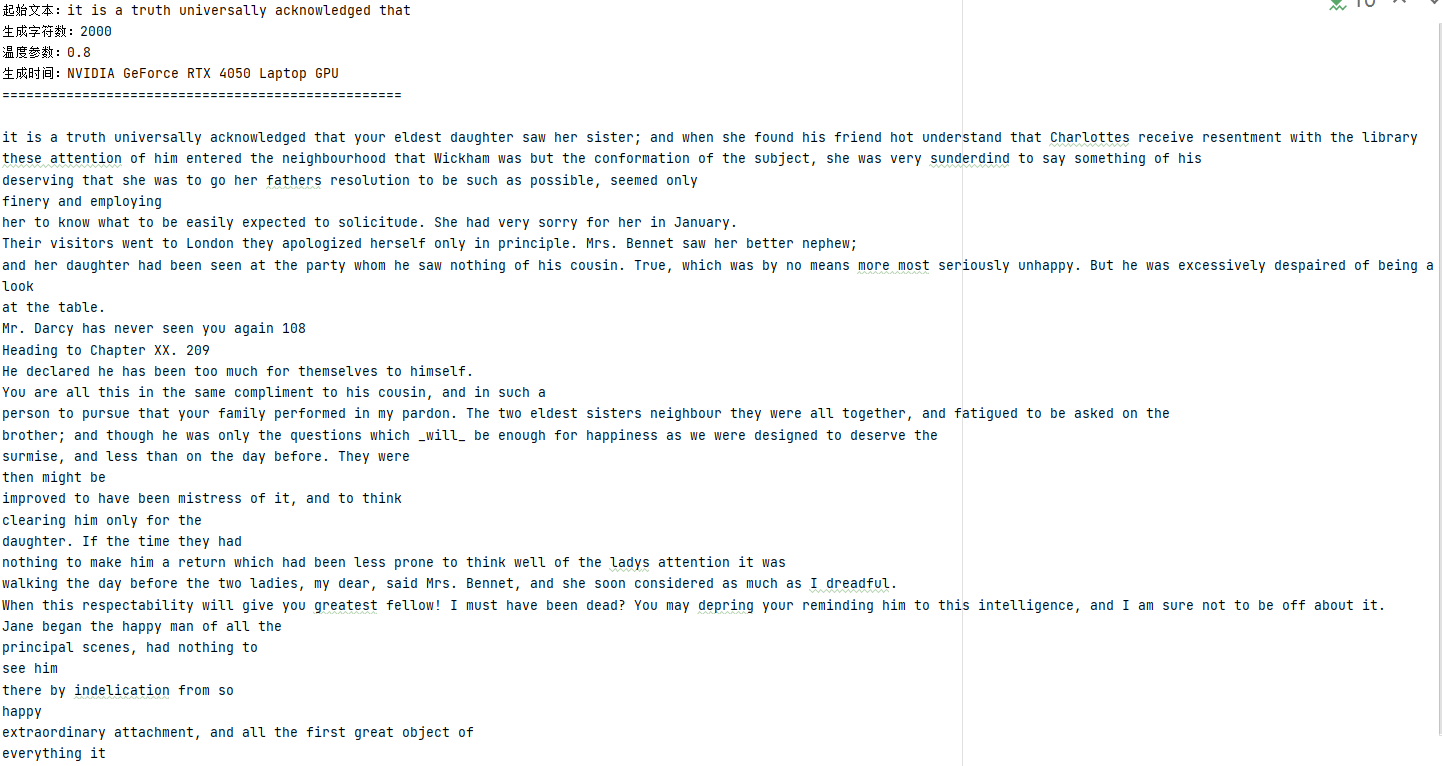
# 字符预测,生成文本(以"it is a truth universally acknowledged that "为起始)
start_text = "it is a truth universally acknowledged that "
generated_text = generate_text(model, start_text, char_to_idx, idx_to_char, num_chars=500)
torch.cuda.empty_cache()
print(generated_text)往后预测2000字符的运行结果: