目录
[RestClient 查询文档](#RestClient 查询文档)

Elaticsearch,简称为 ES,ES 是一个开源的高扩展的分布式全文搜索引擎,是整个 Elastic Stack 技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
ElasticSearch的作用
- **
ElasticSearch**是一款非常强大的开源搜素引擎,具备非常强大的功能,可以帮助我们从海量数据中快速找到需要的内容
ELK技术栈
ElasticSearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域
倒排索引
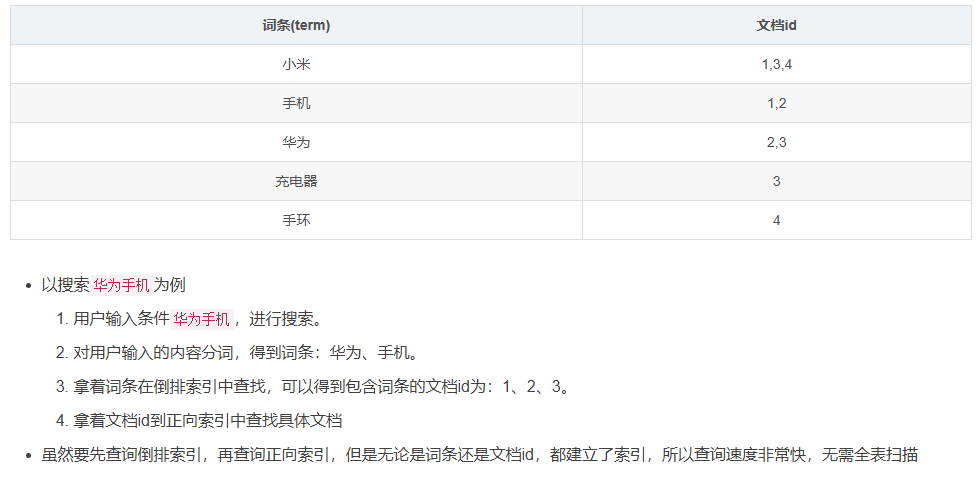
倒排索引中有两个非常重要的概念
- 文档(Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息
- 词条(Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我最喜欢的FPS游戏是Apex,就可以分为我、我最喜欢、FPS游戏、最喜欢的FPS、Apex这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
- 正向索引是最传统的,根据id索引的方式。但是根据词条查询是,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档查找词条的过程
- 而倒排索引则相反,是先找到用户要搜索的词条,然后根据词条得到包含词条的文档id,然后根据文档id获取文档,是根据词条查找文档的过程
那么二者的优缺点各是什么呢?
正向索引
- 优点:可以给多个字段创建索引,根据索引字段搜索、排序速度非常快
- 缺点:根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描
倒排索引
- 优点:根据词条搜索、模糊搜索时,速度非常快
- 缺点:只能给词条创建索引,而不是字段,无法根据字段做排序
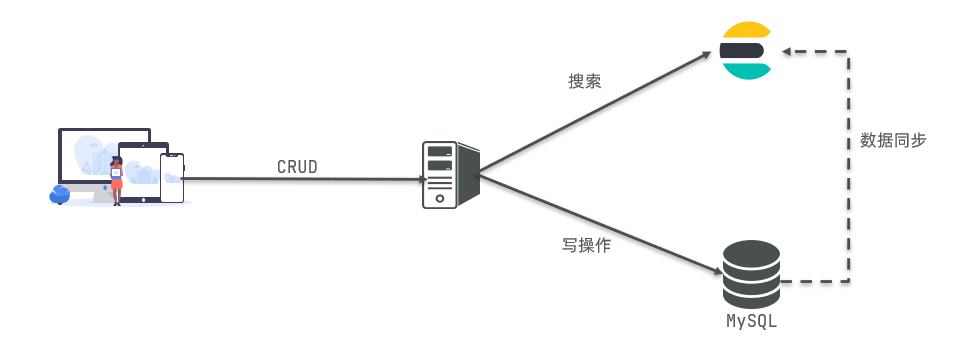
MySQL与ElasticSearch
ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。

索引库操作
- 索引库就类似于数据库表,mapping映射就类似表的结构
- 我们要向es中存储数据,必须先创建
库和表
mapping映射属性
- mapping是对索引库中文档的约束,常见的mapping属性包括
- type:字段数据类型,常见的简单类型有
- 字符串:text(可分词文本)、keyword(精确值,例如:品牌、国家、ip地址;因为这些词,分词之后毫无意义)
- 数值:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true,默认情况下会对所有字段创建倒排索引,即每个字段都可以被搜索。但是某些字段是不存在搜索的意义的,例如邮箱,图片(存储的只是图片url),搜索邮箱或图片url的片段,没有任何意义。因此我们在创建字段映射时,一定要判断一下这个字段是否参与搜索,如果不参与搜索,则将其设置为false
- analyzer:使用哪种分词器
- properties:该字段的子字段

创建索引库和映射
-
语法
PUT /{索引库名}
{
"mappings": {
"properties": {
"字段名1": {
"type": "text ",
"analyzer": "standard"
},
"字段名2": {
"type": "text",
"index": true
},
"字段名3": {
"type": "text",
"properties": {
"子字段1": {
"type": "keyword"
},
"子字段2": {
"type": "keyword"
}
}
}
}
}
}
查询索引库
-
语法
GET /{索引库名}
修改索引库
-
语法
PUT /{索引库名}/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
- 倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库
一旦创建,就无法修改mapping- 虽然无法修改mapping中已有的字段,但是却允许添加新字段到mapping中,因为不会对倒排索引产生影响
删除索引库
-
语法
DELETE /{索引库名}
文档操作
这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式。
新增文档
-
语法
POST /{索引库名}/_doc/{文档id}
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
查询文档
-
语法
GET /{索引库名}/_doc/{id}
删除文档
-
语法
DELETE /{索引库名}/_doc/{id}
修改文档
- 修改有两种方式
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档中的部分字段
全量修改
-
全量修改是覆盖原来的文档,其本质是
- 根据指定的id删除文档
- 新增一个相同id的文档
{% note warning no-icon %}
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了
{% endnote %}
-
语法
PUT /{索引库名}/_doc/{文档id}
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
增量修改
-
增量修改只修改指定id匹配文档中的部分字段
-
语法
POST /{索引库名}/_update/{文档id}
{
"doc": {
"字段名": "新的值",
...
}
}
RestClient操作索引库
初始化JavaRestClient
1.引入ES的RestHighLevelClient的依赖
XML
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>2.因为SpringBoot管理的ES默认版本为7.6.2,所以我们需要覆盖默认的ES版本
XML
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>3.初始化RestHighLevelClient
java
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));创建索引库
DSL语句
PUT /hotel
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address": {
"type": "keyword",
"index": false
},
"price": {
"type": "integer"
},
"score": {
"type": "integer"
},
"brand": {
"type": "keyword",
"copy_to": "all"
},
"city": {
"type": "keyword"
},
"starName": {
"type": "keyword"
},
"business": {
"type": "keyword",
"copy_to": "all"
},
"location": {
"type": "geo_point"
},
"pic": {
"type": "keyword",
"index": false
},
"all": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
代码示例:
java
@Test
void testCreateHotelIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("hotel");
request.source(MAPPING_TEMPLATE, XContentType.JSON);
client.indices().create(request, RequestOptions.DEFAULT);
}代码解析:
定义了静态常量MAPPING_TEMPLATE
java
public static final String MAPPING_TEMPLATE = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"address\": {\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"price\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"score\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"brand\": {\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"city\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"starName\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"business\": {\n" +
" \"type\": \"keyword\"\n" +
" , \"copy_to\": \"all\"\n" +
" },\n" +
" \"location\": {\n" +
" \"type\": \"geo_point\"\n" +
" },\n" +
" \"pic\": {\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"all\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";client.indics()方法的返回值是IndicesClient类型,封装了所有与索引库有关的方法
删除索引库
DSL语句
DELETE /hotel
代码示例:
java
@Test
void testDeleteHotelIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
client.indices().delete(request, RequestOptions.DEFAULT);
}判断索引库是否存在
DSL语句
GET /hotel
代码示例:
java
@Test
void testGetHotelIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("hotel");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists ? "索引库已存在" : "索引库不存在");
}总结
JavaRestClient对索引库操作的流程计本类似,核心就是client.indices()方法来获取索引库的操作对象
索引库操作基本步骤
- 初始化RestHighLevelClient
- 创建XxxIndexRequest。Xxx是Create、Get、Delete
- 准备DSL(Create时需要,其它是无参)
- 发送请求,调用ReseHighLevelClient.indices().xxx()方法,xxx是create、exists、delete
RestClient操作文档
前置工作:
注入IHotelService接口
java
@Autowired
private IHotelService hotelService;索引库实体类
java
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}新增文档
我们要把数据库中的酒店数据查询出来,写入ES中
DSL语句
POST /{索引库名}/_doc/{id}
{
"name": "Jack",
"age": 21
}
代码示例:
java
@Test
void testAddDocument() throws IOException {
// 1. 根据id查询酒店数据
Hotel hotel = hotelService.getById(61083L);
// 2. 转换为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3. 转换为Json字符串
String jsonString = JSON.toJSONString(hotelDoc);
// 4. 准备request对象
IndexRequest request = new IndexRequest();
// 5. 准备json文档
request.source(jsonString, XContentType.JSON);
// 6. 发送请求
client.index(request, RequestOptions.DEFAULT);
}查询文档
DSL语句
GET /hotel/_doc/{id}
代码示例:
java
@Test
void testGetDocumentById() throws IOException {
// 1. 准备request对象
GetRequest request = new GetRequest("hotel").id("61083");
// 2. 发送请求,得到结果
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3. 解析结果
String jsonStr = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(jsonStr, HotelDoc.class);
System.out.println(hotelDoc);
}修改文档
- 修改依旧是两种方式
- 全量修改:本质是先根据id删除,再新增
- 增量修改:修改文档中的指定字段值
增量修改
DSL语句
POST /test001/_update/1
{
"doc":{
"city":"北京",
"price":"1888"
}
}
代码示例:
java
@Test
void testUpdateDocumentById() throws IOException {
// 1. 准备request对象
UpdateRequest request = new UpdateRequest("hotel","61083");
// 2. 准备参数
request.doc(
"city","北京",
"price",1888);
// 3. 发送请求
client.update(request,RequestOptions.DEFAULT);
}删除文档
DSL语句
DELETE /hotel/_doc/{id}
代码示例:
java
@Test
void testDeleteDocumentById() throws IOException {
// 1. 准备request对象
DeleteRequest request = new DeleteRequest("hotel","61083");
// 2. 发送请求
client.delete(request,RequestOptions.DEFAULT);
}批量导入文档
代码示例:
java
@Test
void testBulkAddDoc() throws IOException {
BulkRequest request = new BulkRequest();
List<Hotel> hotels = hotelService.list();
for (Hotel hotel : hotels) {
HotelDoc hotelDoc = new HotelDoc(hotel);
request.add(new IndexRequest("hotel").
id(hotelDoc.getId().toString()).
source(JSON.toJSONString(hotelDoc), XContentType.JSON));
}
client.bulk(request, RequestOptions.DEFAULT);
}总结
文档初始化的基本步骤
- 初始化RestHighLevelClient
- 创建XxxRequest对象,Xxx是Index、Get、Update、Delete
- 准备参数(Index和Update时需要)
- 发送请求,调用RestHighLevelClient.xxx方法,xxx是index、get、update、delete
- 解析结果(Get时需要)
elasticsearch搜索功能
DSL查询分类
elasticsearch提供了基于JSON的DSL来定义查询。
常见的查询分类包括:
- 查询所有:查询出所有数据,一般测试用。例如:match_all
- 全文(full_text)检索查询:利用分词器对用户输入内容分词,然后如倒排索引库中匹配。如:
- match_query
- multi_match_query
- 精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。如:
- ids
- range
- term(某个值==?)
- 地理(geo)查询:根据经纬度查询。如:
- geo_distance
- geo_bounding_box
- 复合(compound)查询:可以将上述各种查询条件组合起来。合并查询条件。例如:
- bool
- function_score
DSL查询语法
GET /indexname/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}全文检索查询
全文检索查询,会对用户输入的内容分词,常用于搜索框搜索。
- 常见的全文检索包括
- match查询:单字段查询
- multi_match查询:多字段查询,任意一个字段符合条件就算符合查询条件

注意:搜索的字段越多,对查询性能影响就越大,因此建议采用**
copy_to**,然后使用单字段查询的方式
精确查询
- 精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有
term:根据词条精确值查询range:根据值的范围查询
term查询
- 因为紧缺查询的字段是不分词的字段,因此查询的条件也必须是部分词的词条。查询时,用户输入的内容跟字段值完全匹配时才认为符合条件。如果用户输入的内容过多或过少,都会搜索不到数据

range查询
- 范围查询,一般应用在对数值类型做范围过滤的时候。例如做价格范围的过滤

地理坐标查询
- 所谓地理坐标查询,其实就是根据经纬度查询,官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/geo-queries.html
常见的使用场景包括
- 携程:搜索附近的酒店
- 滴滴:搜索附近的出租车
- 微信:搜索附近的人
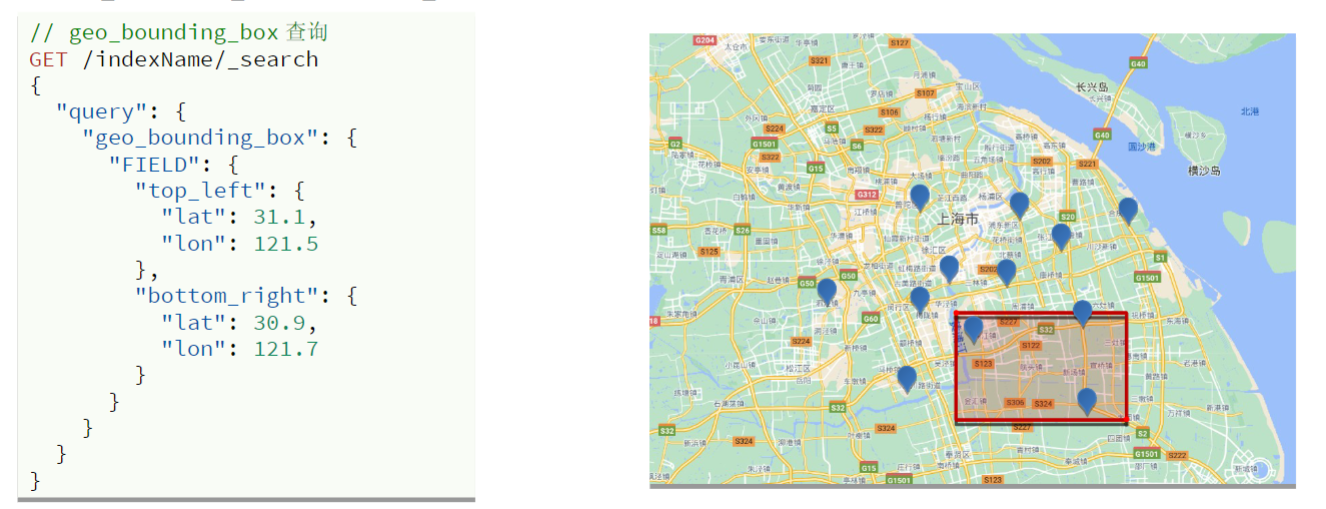
矩形范围查询(geo_bounding_box查询)
- 查询时。需指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形范围内的坐标,都是符合条件的文档
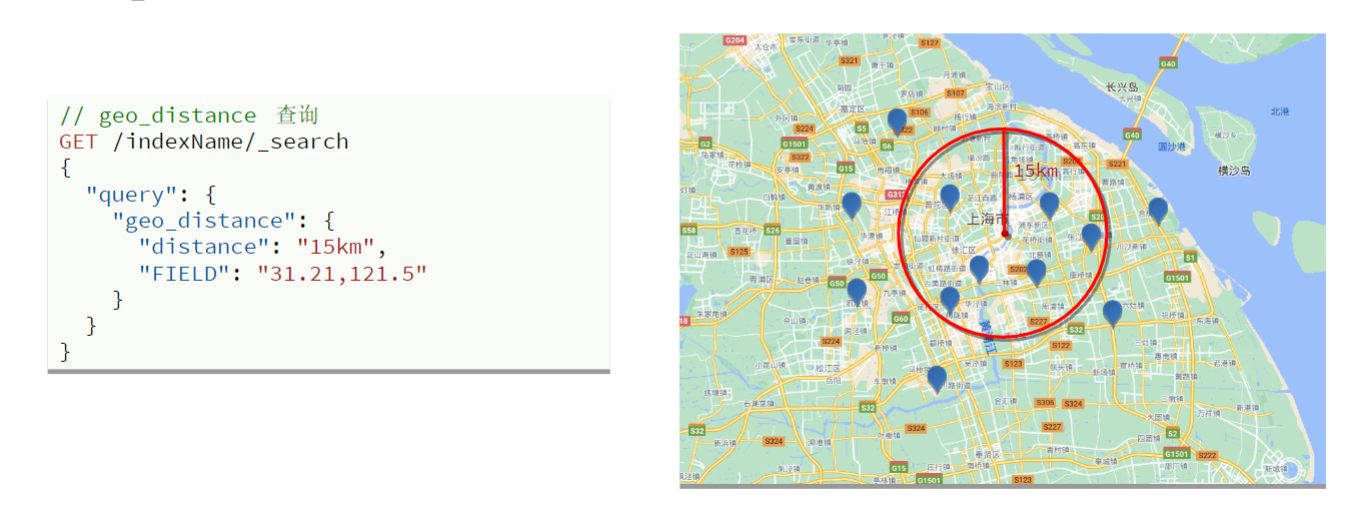
附近查询(geo_distance查询)
- 查询到指定中心点小于某个距离值的所有文档
- 以指定中心点为圆心,指定距离为半径,画一个圆,落在圆内的坐标都算符合条件
复合查询
复合查询可以将其他简单查询组合起来,实现更复杂的搜索逻辑,常见的有两种:
- function score:算分函数查询,可以控制文档相关性算分,控制文档排名(例如搜索引擎的排名,第一大部分都是广告)
- bool query:布尔查询,利用逻辑关系组合多个其他的查询,实现复杂搜索
相关性算分
-
当我们利用match查询时,文档结果会根据搜索词条的关联度打分(_score),返回结果时按照分值降序排列
-
在ES中,早期使用的打分算法是TF-IDF算法,公式如下

-
再后来的5.1版本升级中,ES将算法改进为BM25算法,公式如下

TF-IDF算法有一种缺陷,就是词条频率越高,文档得分也会越高,单个词条对文档影响较大。而BM25则会让单个词条的算分有一个上限,曲线更平滑

算分函数查询
- 可以修改文档的相关性算分(query score),根据新得到的算分排序**。**

布尔查询
- 布尔查询是一个或多个子查询的组合,每一个子句就是一个子查询。子查询的组合方式有
must:必须匹配每个子查询,类似与should:选择性匹配子查询,类似或must_not:必须不匹配,不参与算分,类似非filter:必须匹配,不参与算分
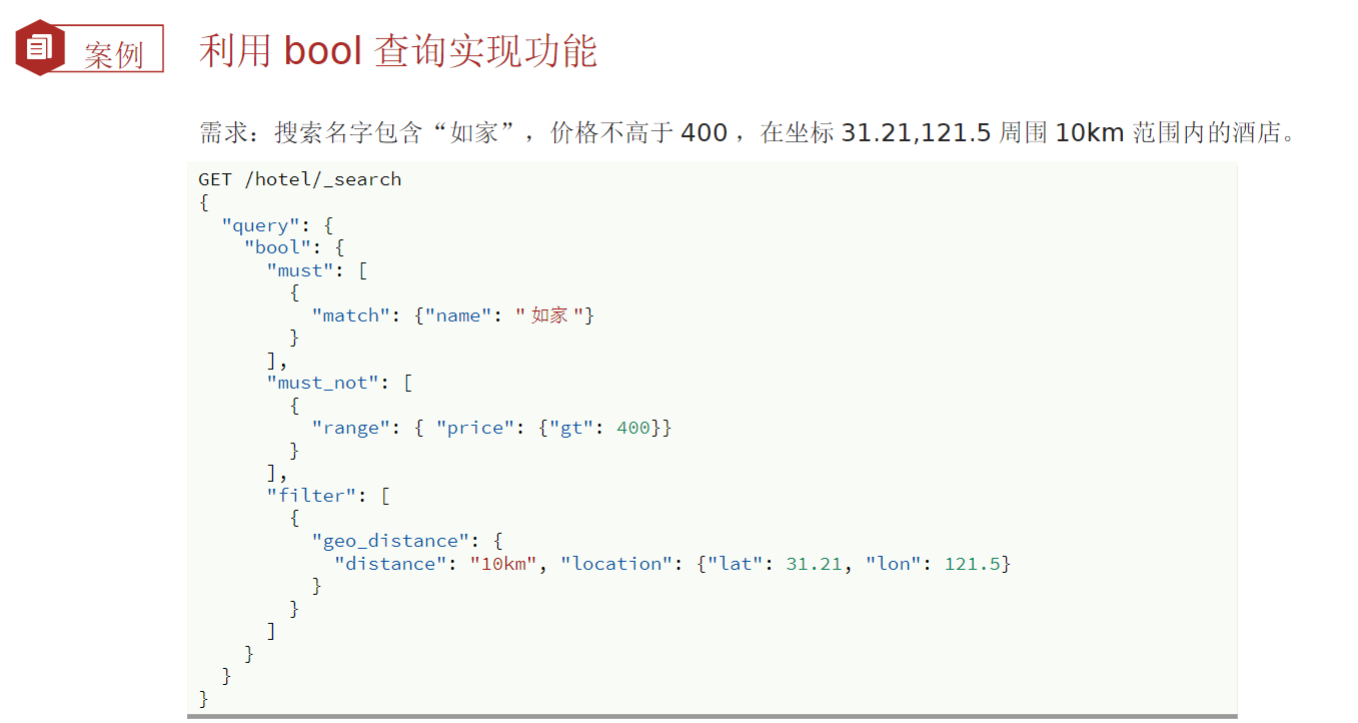
-
must和should一起用的时候,should会不生效
-
对于DSL语句的解决方案比较麻烦,需要在must里再套一个bool,里面再套should,但是对于Java代码来说比较容易修改
搜索结果处理
排序
elasticsearch 支持对搜索结果的排序,默认根据相关度算分(_score)来排序。
可以排序的字段类型有:
- keyword类型
- 数值类型
- 地理坐标类型
- 日期类型

分页
- ES默认情况下只返回
top10的数据。而如果要查询更多数据就需要修改分页参数了。 - ES中通过修改from、size参数来控制要返回的分页结果
from:从第几个文档开始size:总共查询几个文档
- 类似于mysql中的
limit ?, ?

深度分页问题
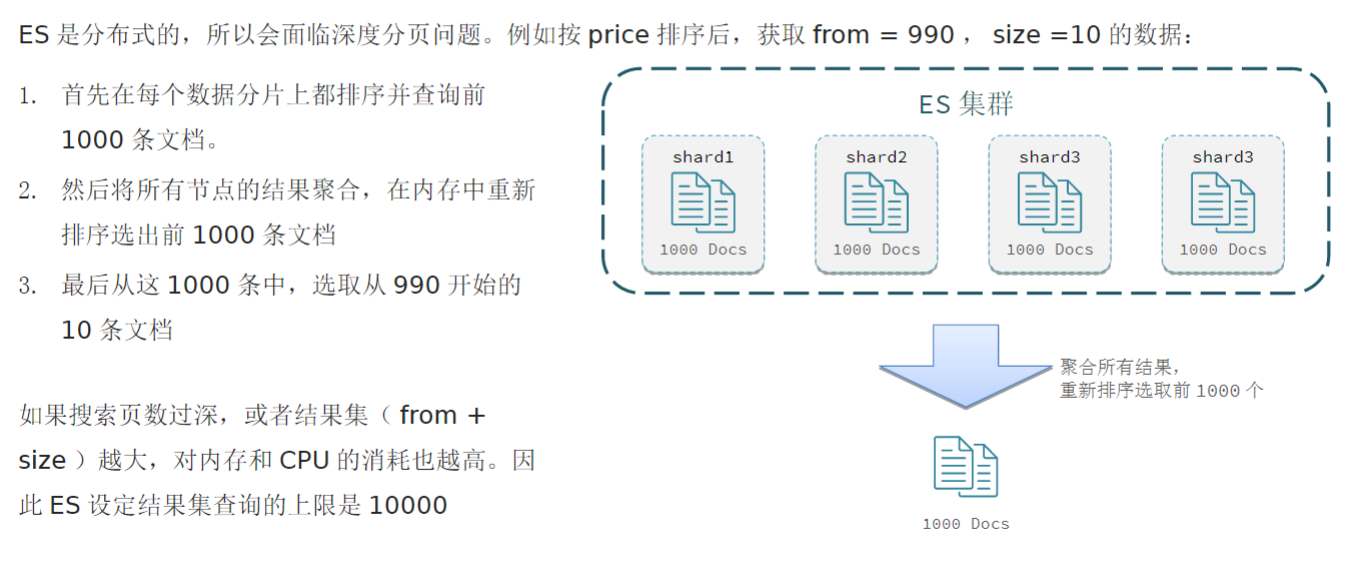
解决方案
针对深度分页,ES提供而两种解决方案,官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式
- scrool:原理是将排序后的文档id形成快照,保存在内存。官方已经不推荐使用
总结
分页查询的常见实现方案以及优缺点
from + size:
- 优点:支持随机翻页
- 缺点:深度分页问题,默认查询上限是10000(from + size)
- 场景:百度、京东、谷歌、淘宝这样的随机翻页搜索(百度现在支持翻页到75页,然后显示提示:限于网页篇幅,部分结果未予显示。)
after search:
- 优点:没有查询上限(单词查询的size不超过10000)
- 缺点:只能向后逐页查询,不支持随机翻页
- 场景:没有随机翻页需求的搜索,例如手机的向下滚动翻页
scroll:
- 优点:没有查询上限(单词查询的size不超过10000)
- 缺点:会有额外内存消耗,并且搜索结果是非实时的(快照保存在内存中,不可能每搜索一次都更新一次快照)
- 场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议使用after search方案
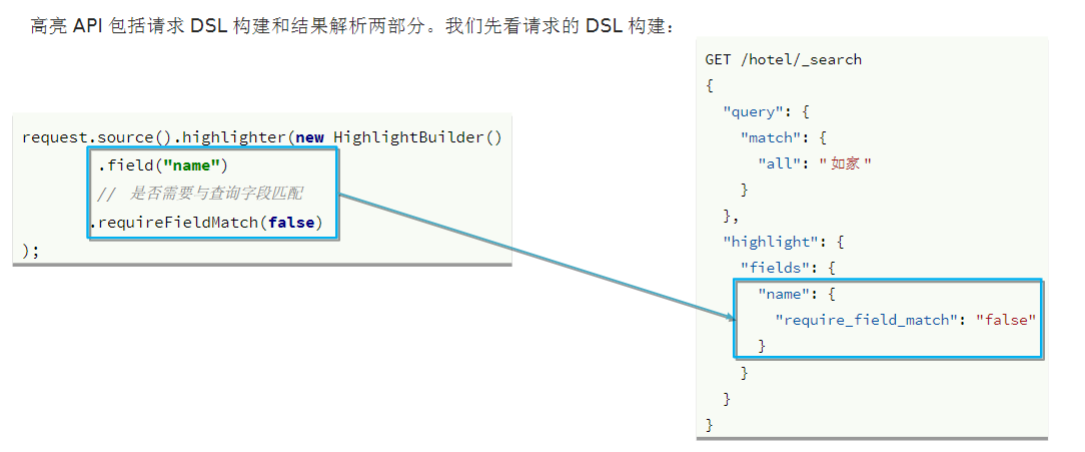
高亮
在搜索结果中把关键字突出显示。
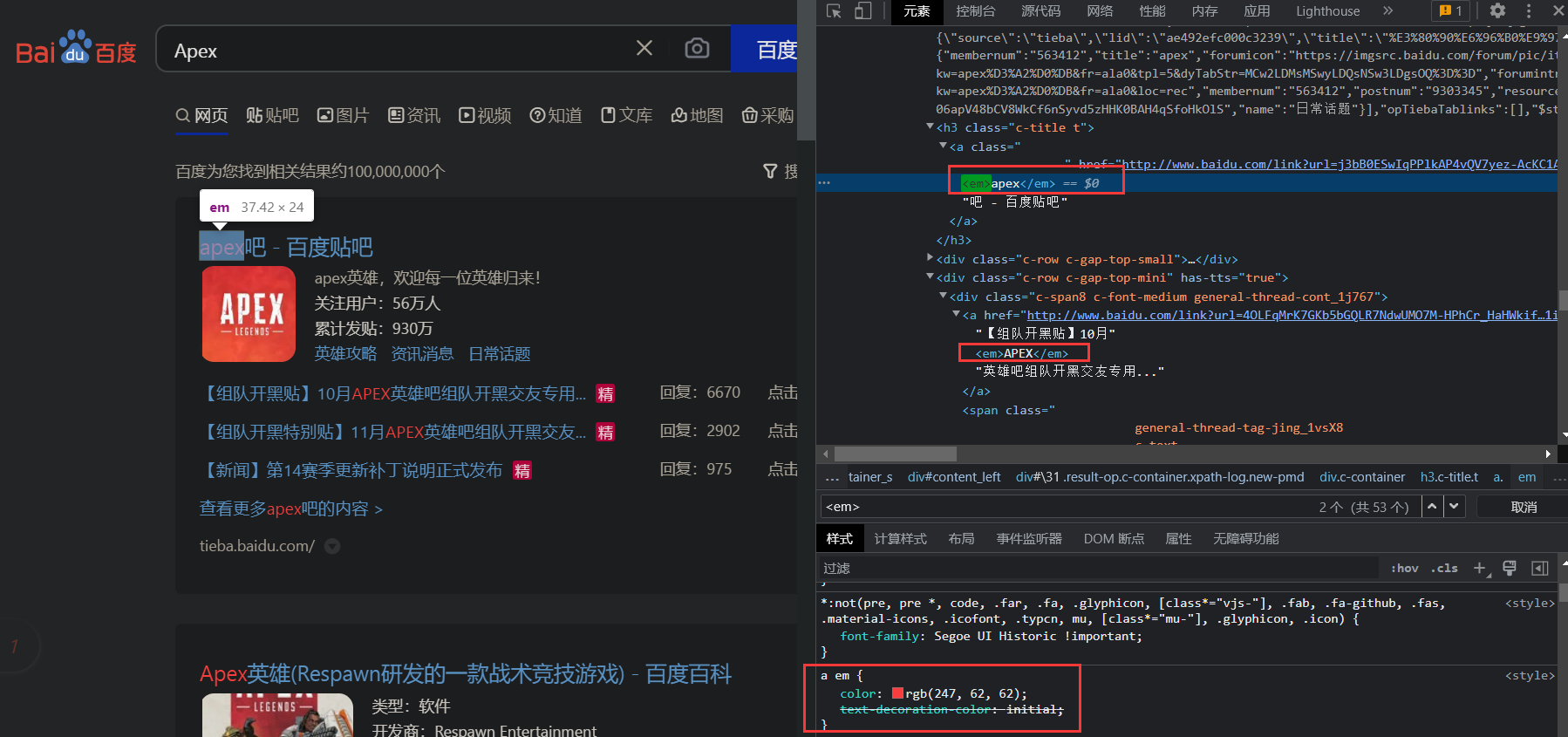
原理:
- 高亮显示的实现分为两步
- 给文档中的所有关键字都添加一个标签,例如
<em>标签 - 页面给
<em>标签编写CSS样式
- 给文档中的所有关键字都添加一个标签,例如

默认情况下就是加的<em>标签,所以我们也可以省略
GET /hotel/_search
{
"query": {
"match": {
"all": "上海如家"
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false"
}
}
}
}高亮查询,默认情况下,ES搜索字段必须与高亮字段一致;
但是可通过require_field_match属性配置;
RestClient 查询文档
实现步骤:
- 准备request
- 准备DSL
- 发送请求
通过match_all来演示基本的API:
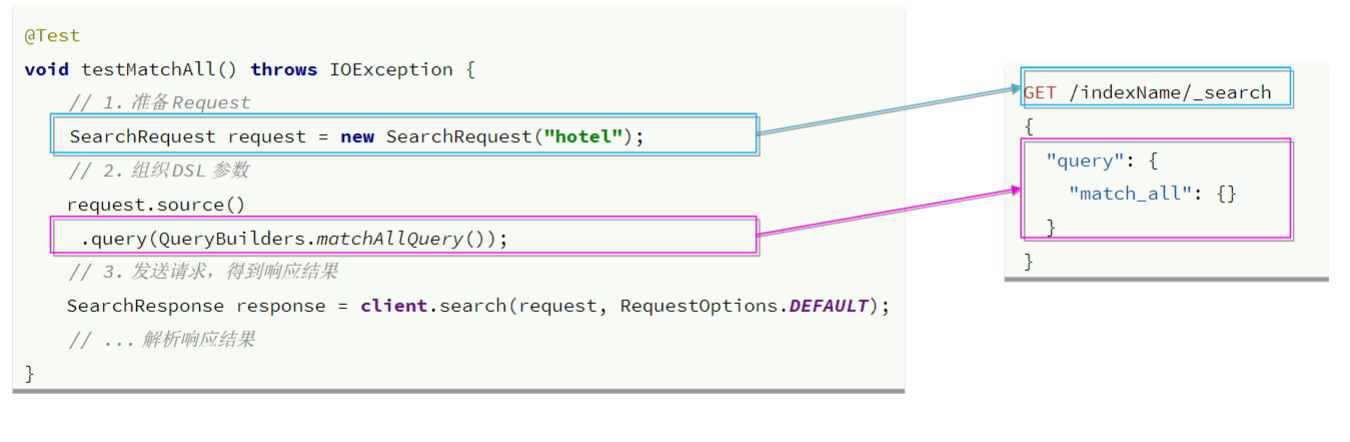
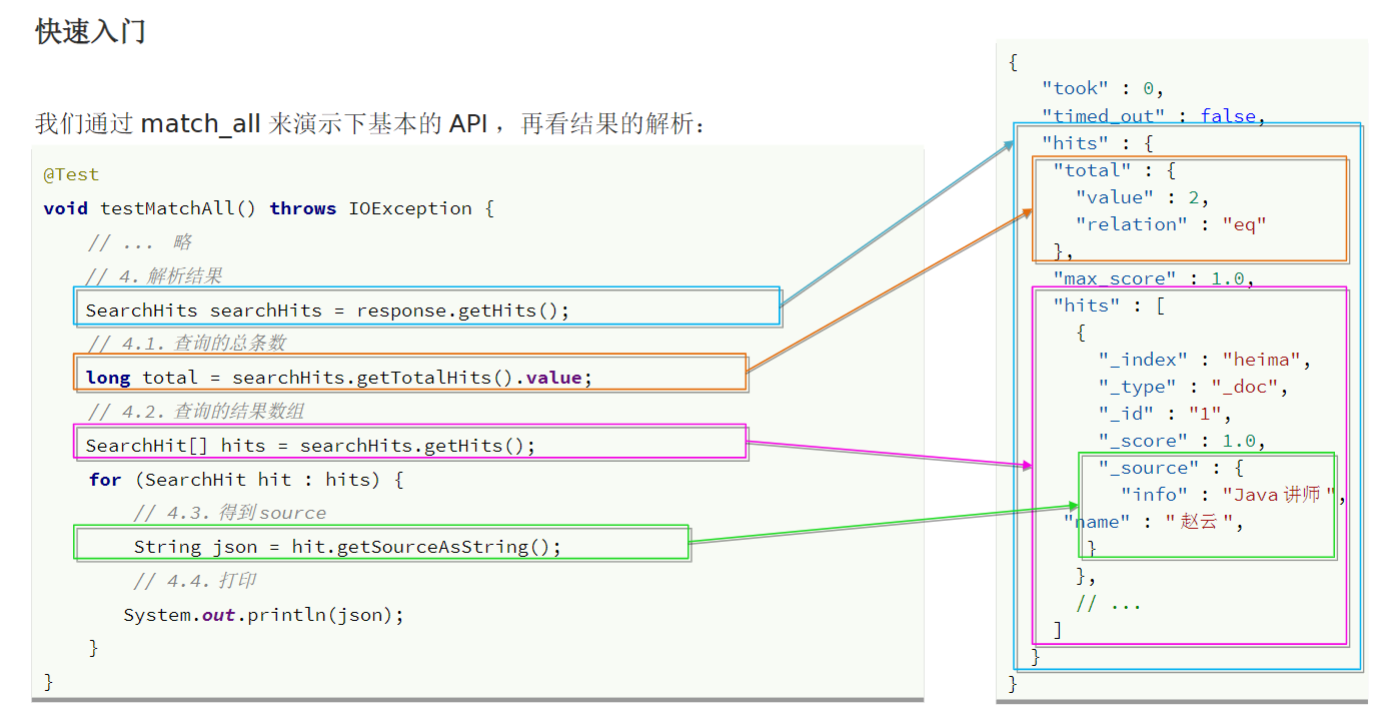

全文检索查询
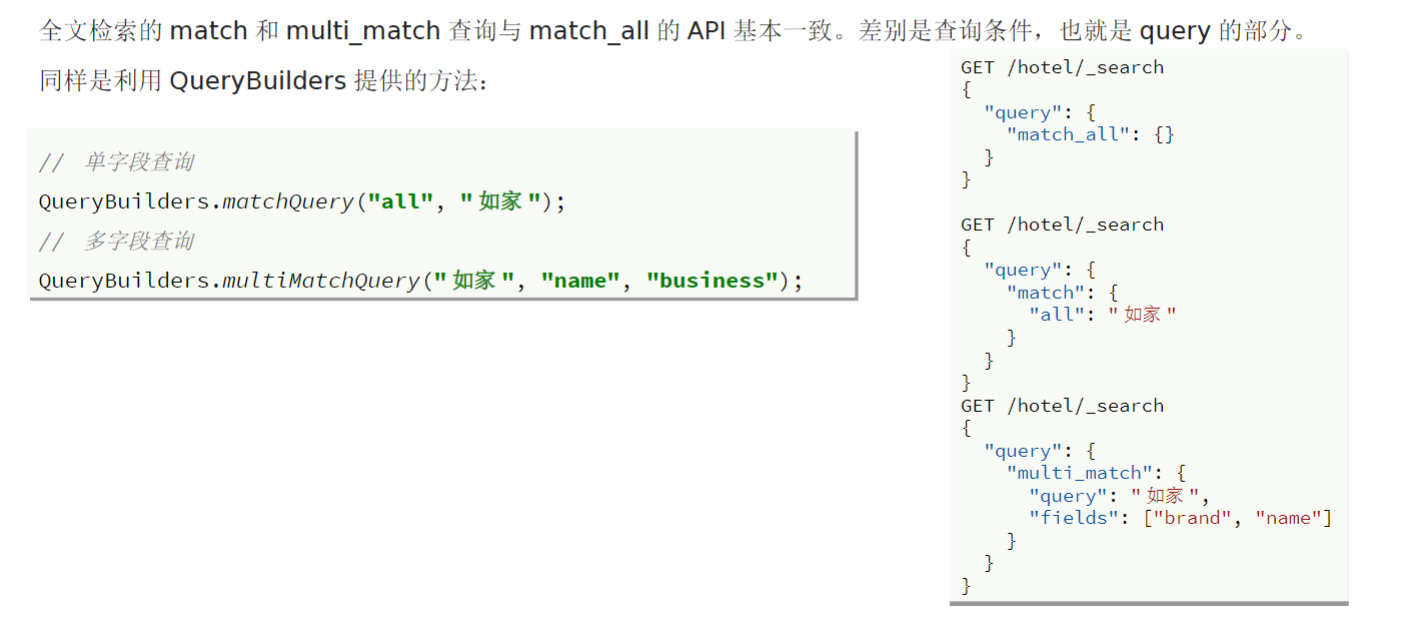
精确查询

复合查询

排序和分页
搜索结果的排序和分页是与query同级的参数:

高亮
结果解析处理
