论文标题 :How Sememic Components Can Benefit Link Prediction for Lexico-Semantic Knowledge Graphs?
会议:EMNLP 2025
核心关键词:Sememe|Lexico-Semantic KG|Link Prediction|知识图谱补全|PLM
一、动机 & 问题背景
1. Link Prediction 的局限
Link Prediction(链接预测) 是图数据分析中的一项核心任务,目标是根据已有的图结构和节点信息,预测未来可能出现的边,或判断当前不存在的边是否应该存在。
在知识图谱补全 (Link Prediction, LP) 任务中,现有方法主要依赖:
-
结构信息 (embedding-based,如 TransE、RotatE) 基于嵌入的方法专注于利用KG中的结构信息来学习概念/关系表示,而通常忽略文本描述。
-
文本信息 (PLM-based,如 KG-BERT、SimKGC、MoCoKGC)基于PLM的方法优于基于嵌入的几个LP基准测试。
| 类别 | 代表工作 | 关键思路 | 与本文关系 |
|---|---|---|---|
| 基于嵌入 (EM-based) | TransE、ConvE、RotatE、CompGCN、HittER 等 | 仅利用 KG 结构信息,学习实体/关系嵌入并设计评分函数 | 未利用文本,更无义原,难以刻画细粒度词义差异 |
| 基于预训练语言模型(PLM-based) | KG-BERT、StAR、CSProm-KG、SimKGC、StructKGC、MoCoKGC 等 | 用预训练语言模型编码文本定义,辅以负采样或图重排 | 引入文本但把词义当原子,未挖掘内部义原成分;本文在此基础上追加义原信号 |
词汇语义知识图谱(Lexical Semantic Knowledge Graph, LSKG) 是一种以"词/概念"为核心节点,用 语义关系 将 词汇 系统性组织起来的知识图谱,用于刻画词 与词之间的语义结构、语义相似性与语义推理路径。
但在 词汇语义知识图谱(Lexico-Semantic KG) 中,这两类信息存在明显不足:
- 节点是 词义(word sense),而非实体
- 不同词义之间差异极其细微
- 文本定义高度相似,PLM 难以区分
现有 LP 方法把词义当成"不可分的原子"来建模
2. 语言学视角:Sememe(义原)
Sememe(义原):是用于描述和分解词义的最基本语义原子,多个义原组合在一起构成一个词或概念的完整含义。
示例:
boy = {human, male, immature}
girl = {human, female, immature}
child = {human, immature}词汇语义关系在 sememe 层面呈现出系统性模式:
| 关系类型 | Sememe 层面的规律 |
|---|---|
| 反义词 | 仅一个 sememe 相反 |
| 上下位 | sememe 的包含关系 |
| 整体-部分 | sememe 的结构组合 |
核心洞察:词义之间的语义关系,本质上是 sememe 组合差异
Sememe Prediction的相关工作:
| 资源 | 关键内容 | 与本文关系 | 备注 |
|---|---|---|---|
| HowNet | 含 2 540 个义原,23 万英汉词义标注,但无文本定义 | 本文通过"词义对齐"将 CCD 定义引入,解决 HowNet 无定义问题 | 每个词义都由一系列相关的义原来定义,但缺乏对词义的文本定义 |
| SememeBabel | 15 461 组 BabelNet synset 含定义与义原,中文仅 8 555 条 | 中文规模小;本文新构建 43 163 条中文 (definition, sememes) 对,规模扩增 5倍 | 包括文本定义和义原注释,有助于解决HowNet中定义缺失的问题。 |
3. 研究挑战
-
信息粒度不足
现有 LP 方法把词义视为原子节点,忽略了词义内部可分解的义原成分,导致对反义、上下位等词汇关系的系统性差异刻画乏力。
-
义原信息缺失
当前词汇-语义 KG 缺乏义原标注,而人工标注代价极高;自动义原预测(SP)存在噪声,难以直接利用。
-
数据资源稀缺
中文语境下同时缺少高质量的 SP 训练数据与标准化的 LP 评测基准,限制了义原知识在 LP 中的落地研究。
-
义原表示的有效性有限
主义原表示和全部义原表示可能包含噪声,这降低了最终表示的有效性;
-
义原动态变化无法处理
主义原表示和全部义原表示对LP的贡献动态变化,而静态权重的分配通常无法处理这种变化;
-
义原重要性不同
义原特征与其他特征是互补的,它们的相对重要性在不同的LP场景中有所不同。
二、整体解决方案概览
首先构建了一个语义预测(SP)数据集SememeDef,以及两个用于LP评估的中文数据集HN7和CWN5。
然后,提出了一种名为SememeLP的方法,更充分地使用知识进行LP。

SememeLP 通过一个三阶段的融合模块,将 组合的sememe特征 与 其他特征 相结合,以获得更强大的知识表示。
三、数据集与资源构建
1. SememeDef(Sememe Prediction 数据集)
用途:训练 sememe 知识编码器
| 英文 | 中文 | 结构 |
|---|---|---|
| 70,645 | 43,163 | 每条数据包含:词义定义、主义原 (MS)、全义原 (AS) |
构建方法:
- 基于 HowNet 与权威词典的词义对齐
- 使用多个 LLM(Qwen / DeepSeek / Yi)进行一致性评分
- 仅保留高一致性样本
- 人工验证 LLM 对齐质量
2. 中文 LP 数据集:HN7 & CWN5
| 数据集 | 来源 | 特点 |
|---|---|---|
| HN7 | HowNet | 语义关系源自 sememe |
| CWN5 | Chinese WordNet | 标准词汇语义关系 |
解决了中文 Lexico-Semantic LP 缺乏基准 的问题。
四、核心方法:SememeLP
SememeLP 通过一个三阶段的融合模块,将 组合的sememe特征 与 其他特征 相结合,以获得更强大的知识表示。
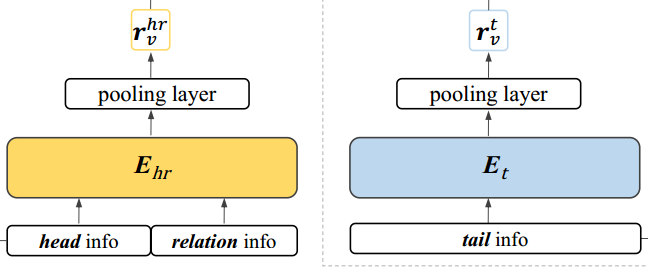
首先将(h,r)和t 的文本描述(即词义定义)分别送入基于BERT的编码器 E h r 和 E t E_hr和E_t Ehr和Et中。再分别pooling 后得到 r v h r 和 r v t r_{v}^{hr}和r_{v}^{t} rvhr和rvt.
利用BERT编码器Es,对SememeDef进行微调; 编码全义位表示为 r a r_a ra和编码主义位的主义位表示为 r m r_m rm.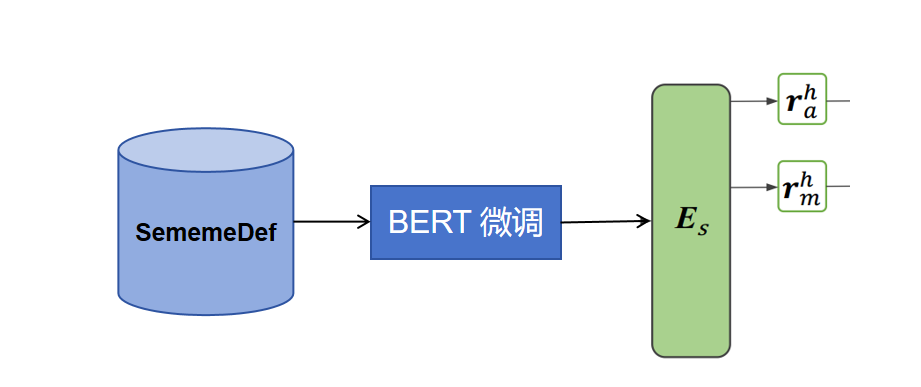
随后,将这两种类型的义原表示与vanilla表示相融合。
1. 两类 sememe 表示
| 表示 | 含义 | 功能 |
|---|---|---|
| All-sememe | 所有义原的组合 | 细粒度区分 |
| Main-sememe | 核心语义类别 | 类别约束 |
- 使用 BERT 编码定义
- 不直接用预测标签,而是使用 隐向量表示
2. 三阶段融合模块
(1)Independent Gated Fusion(IGF)
判断主Sememe(主义原 MS)和全Sememe(全义原 AS)表示的有效性,并使用vanilla表示来细化它们。
h i = g i ⊙ r v + ( 1 − g i ) ⊙ r s h_i = g_i ⊙ r_v + (1 − g_i ) ⊙ r_s hi=gi⊙rv+(1−gi)⊙rs
其中 g i ∈ R l = σ ( M L P ( r v ; r s )) g_i ∈ R _l = σ(MLP(r_v; r_s)) gi∈Rl=σ(MLP(rv;rs)),并且 r s ∈ r a , r m r_s ∈ {r_a,r_m} rs∈ra,rm,其中; 表示级联,并且σ表示sigmoid函数。 r a 和 r m r_a和r_m ra和rm的输出分别表示为 h a 和 h m h_a和h_m ha和hm
(2)Weighting Fusion(WF)
执行主Sememe(主义原 MS)和全Sememe(全义原 AS)表示的加权融合,以获得最终的义原知识表示。
加权层用于组合 h a 和 h m h_a和h_m ha和hm:
h w = w a h a + w m h m h_w = w_a h_a + w_m h_m hw=waha+wmhm
其中 w a , w m = s o f t m a x ( M L P ( h a ; h m )) w_a,w_m = softmax(MLP(h_a; h_m)) wa,wm=softmax(MLP(ha;hm))。
- 动态平衡 main-sememe 与 all-sememe
- 不同关系类型权重不同
(3)Final Gated Fusion(FGF)
将义原特征与其他特征相结合,用于最终的中心关系和尾部表示。
r f = g f ⊙ r v + ( 1 − g f ) ⊙ h w r_f = g_f⊙ r_v +(1-g_f) ⊙ h_w rf=gf⊙rv+(1−gf)⊙hw
其中 g f = σ ( M L P ( r v ; h w ; h a ; h m )) g_f = σ(MLP(r_v; h_w; h_a; h_m)) gf=σ(MLP(rv;hw;ha;hm))
- 决定最终表示中:原始语义 与 sememe 信息的占比
本质:语义可信度感知的动态融合机制
3. 与现有 LP 模型的结合
- 基于 SimKGC / MoCoKGC
- 保留其对比学习、负采样、结构提示等机制
- SememeLP 作为 语义增强模块 插入
4. 义原知识表示编码器
为了获得义原知识表示,利用SP任务中的定义,基于BERT的模型用作义原知识编码器Es,并在两个SP任务上进行微调:全义素预测(ASP),用于预测词义的所有义原,以及主义原预测(MSP),用于预测其主义原。
本文设计了一个带有软提示的输入模板:
"[CLS] [A1] [A2]...[AL] [ASP] [M1] [M2]...[ML] [MSP] d [SEP]"
其中[A1]-[ML]是可学习的模板tokens,
[ASP]和[MSP]分别作为ASP和MSP的分类标记ASP和MSP的最后隐藏状态,由 h A S P 和 h M S P h_{ASP}和h_{MSP} hASP和hMSP表示,被用作全义原表示 r a r_a ra和主义原表示 r m r_m rm。
(1) 全部义原预测(ASP)
ASP 是一个多标签分类任务,目标是预测一个词所关联的所有语义原。
- 设 S S S 为所有可能语义原的集合, ∣ S ∣ |S| ∣S∣ 为其大小。
- S d ⊆ S S_d \subseteq S Sd⊆S 表示当前词的真实义原集合(ground-truth)。
- 模型输出每个语义原 s \\in S 的预测得分 p s ∈ 0 , 1 p_s \in 0,1 ps∈0,1(通常通过 sigmoid 激活函数得到)。
其损失函数定义为归一化的二元交叉熵:
L asp = − 1 ∣ S ∣ ∑ s ∈ S d log p s + ∑ s ∉ S d log ( 1 − p s ) L_{\text{asp}} = -\frac{1}{|S|} \left \\sum_{s \\in S_d} \\log p_s + \\sum_{s \\notin S_d} \\log(1 - p_s) \\right Lasp=−∣S∣1 s∈Sd∑logps+s∈/Sd∑log(1−ps)
(2) 主义原预测(MSP)
MSP 是一个单标签多分类任务 ,目标是识别出最能代表该词的核心义原(称为"主义原" m s m_s ms)。
模型使用一个标准的 softmax 分类器:
p msp = softmax ( W msp h MSP + b msp ) p_{\text{msp}} = \text{softmax}(W_{\text{msp}} h_{\\text{MSP}} + b_{\text{msp}}) pmsp=softmax(WmsphMSP+bmsp)
其中:
- h MSP h_{\\text{MSP}} hMSP 是输入到 MSP 分类器的上下文表示;
- W msp W_{\text{msp}} Wmsp 和 b msp b_{\text{msp}} bmsp 是可学习参数;
- p msp ∈ R ∣ S ∣ p_{\text{msp}} \in \mathbb{R}^{|S|} pmsp∈R∣S∣ 是所有语义原的概率分布。
对应的损失函数为:
L msp = − log p m s L_{\text{msp}} = -\log p_{m_s} Lmsp=−logpms
其中 p m s p_{m_s} pms 是真实主语义原 m s m_s ms 对应的预测概率。
(3)联合训练:总损失函数
总损失函数为两个任务的加权和:
L sp = α L asp + ( 1 − α ) L msp L_{\text{sp}} = \alpha L_{\text{asp}} + (1 - \alpha) L_{\text{msp}} Lsp=αLasp+(1−α)Lmsp
- α ∈ 0 , 1 \alpha \in 0, 1 α∈0,1 是控制任务权重的超参数。
五、实验结果与分析
1. 性能提升
- 在 WN18RR / HN7 / CWN5 上均取得 SOTA
- 中文数据集提升尤为显著(HN7 +5.2 MRR)
2. 指标层面
- Hits@1 提升最大
- 说明 sememe 有助于 精确区分高度相似的候选词义
3.sememe 作用分析
正确预测样本中更大比例满足 sememe组合 的差异模式反义(只有一个 sememe 相反)或上下位关系(sememe 子集关系成立)尤为明显。
即 模型学到的不是表面相似度,而是 义原结构规律。
六、消融实验结论
- All-sememe 表示贡献最大(区分能力强)
- Main-sememe 提供稳定类别约束
- 三阶段融合优于所有简化方案
- IGF 对抗 sememe 噪声至关重要
七、论文价值与局限
价值:
- 将语言学知识"实质性"引入 LP
- 提供 SP → LP 的通用范式
- 中文资源贡献
- 方法鲁棒、可迁移
局限:
- 依赖 sememe 预测质量
- sememe 体系与 KG taxonomy 不一致时可能影响评估
- 训练成本高于 baseline
原文链接
How Sememic Components Can Benefit Link Prediction for Lexico-Semantic Knowledge Graphs?