一、K-means聚类
1.K-means聚类是什么?
是一种无监督学习的算法,也就是训练数据中无标签
指定K值,把数据聚成多少个簇,分成多少类
距离上的度量一般采用欧氏距离
K-means分类步骤:
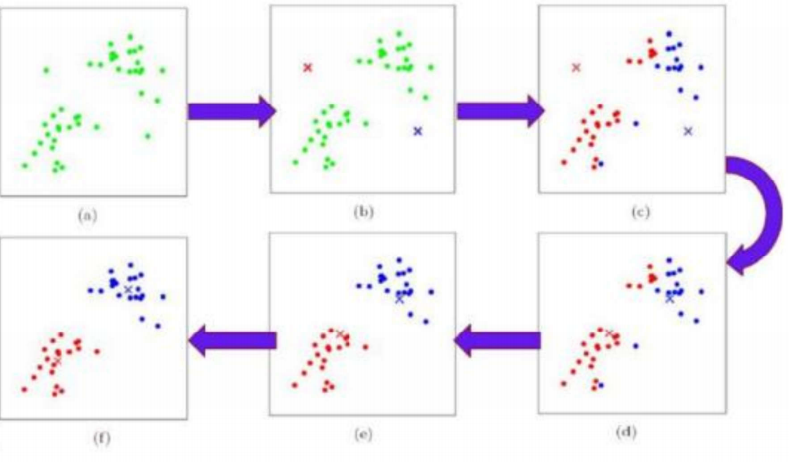
一堆数据点,如(a);
在其中选择两个数据点分为作为红蓝两类,如(b);
计算其他数据点到这两点的距离谁近就归为哪类,如(c);
再选择两个数据点作为红蓝两类重复一样的操作,如(d);
循环往复选择两类,进行距离计算分类,如(e);
最终分类结果不会再改变,确定的时候就结束分类,如(f);
2.轮廓系数
通常是聚类效果的通用指标,数据x,聚类标签labels,就可以使用metrics.silhouette_score(X, labels)计算
a(i)值:同一簇中,对于第i个元素xi,计算xi与其同一簇内所有其他元素距离的平均值,表示了簇内的凝聚程度。
b(i)值:非同一簇中,选取xi外的一个簇,计算xi与该簇内所有点的距离的平均距离,遍历其他所有簇,取所有平均值中最小的一个,表示簇间的分离度。
用a(i)和b(i)计算出xi轮廓系数:
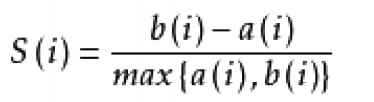
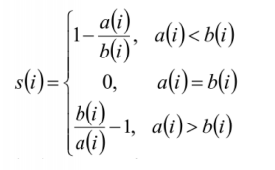
最后计算所有x的轮廓系数,求出平均值,就是当前聚类的整体轮廓系数
- 轮廓系数范围在-1,1之间,值越大,越合理。
- 轮廓系数s(i)接近1,则说明样本xi聚类合理
- 轮廓系数s(i)接近-1,则说明样本xi更应该分类到另外的簇
- 轮廓系数s(i)近似为0,则说明样本xi在两个簇的边界上
3.k-means算法的实现

参数没什么很重要,可以在https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans中查看
但又几个比较重要的属性

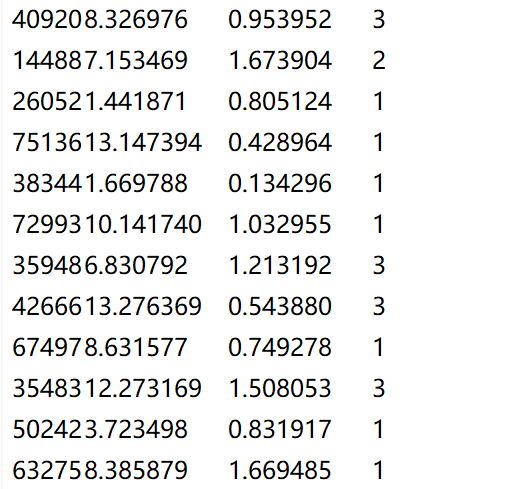
数据用的是之前的寝室分配数据
python
import pandas as pd
from sklearn.cluster import KMeans
from sklearn import metrics
import numpy as np
data=pd.read_csv(r"D:\learn\代码所用文本\datingTestSet2.txt",sep='\t',header=None)
data=data.iloc[:,:3]
k_values=list(range(2,11))
sse_scores=[]
sil_scores=[]
for k in range(2,11):
kmeans=KMeans(n_clusters=k)
labels=kmeans.fit_predict(data)
sse=kmeans.inertia_
sil_score=metrics.silhouette_score(data,labels)
sse_scores.append(sse)
sil_scores.append(sil_score)
print(f"K={k}:see={sse},sil_score={sil_score}")
best_k= k_values[np.argmax(sil_scores)]
best_score=max(sil_scores)
print(f'最优k值:{best_k},best_score:{best_score}')
import matplotlib.pyplot as plt
plt.plot(list(range(2,11)),sil_scores)
plt.xlabel('numebei of clusters initialized')
plt.ylabel('sihouette score')
plt.show()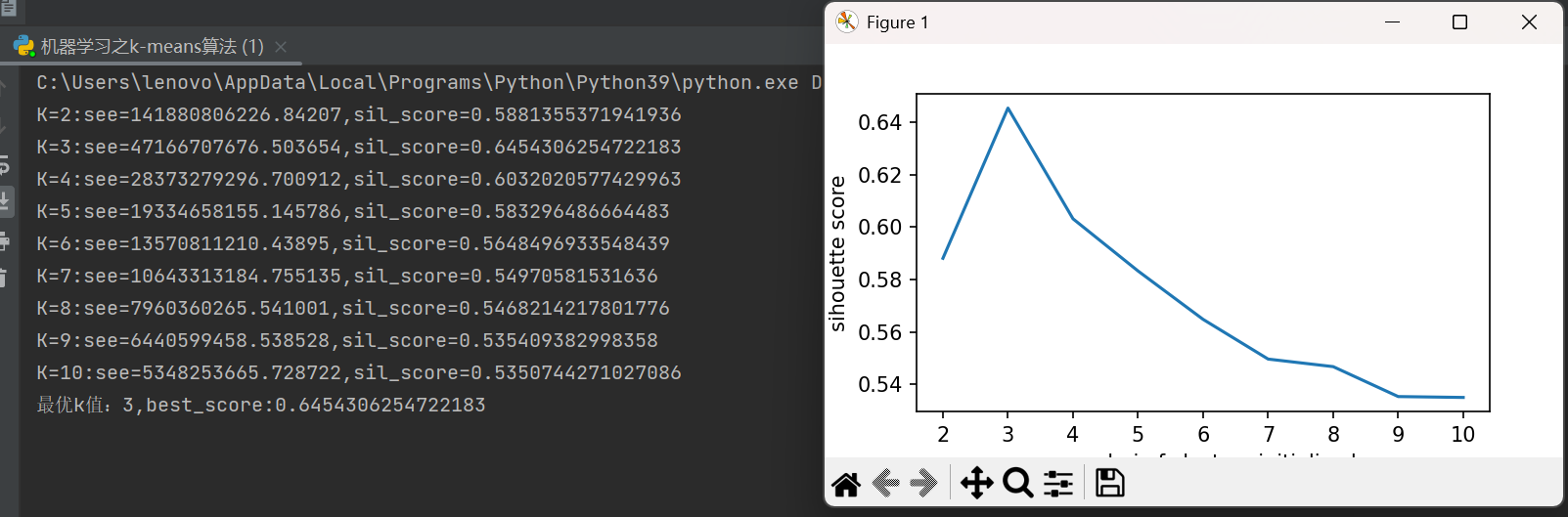
二、DBSCAN算法
1.为什么有DBSCAN?
k-means分类方法可以对没有标签的数据进行分类
但是有些情况下,K-means也无法很好的进行分类
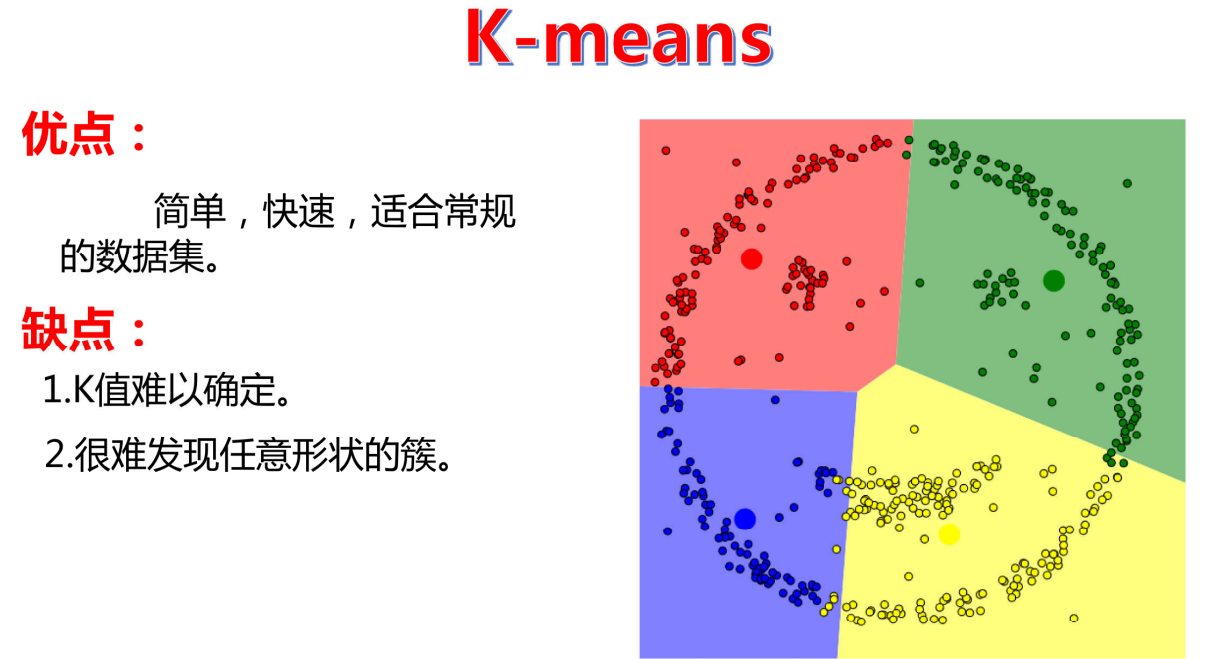
这样一对比就能看出K-means的弊端,DBSCAN的优势之处
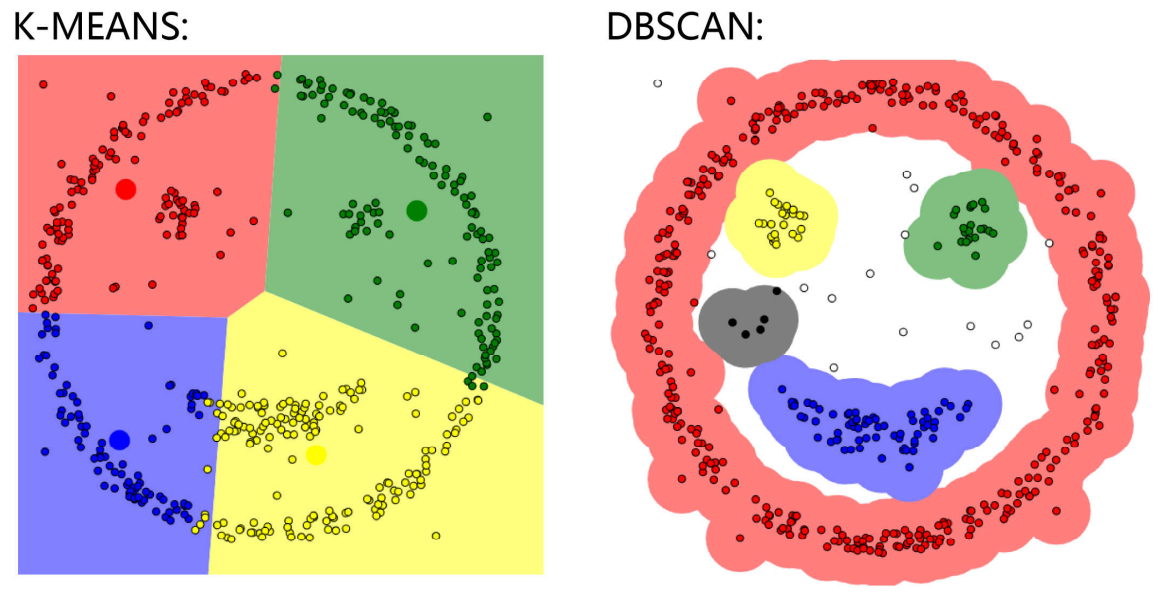
所以,DBSCAN也是对无标签的数据进行分类,比K-means要更灵活一些
2.DBSCAN是什么?
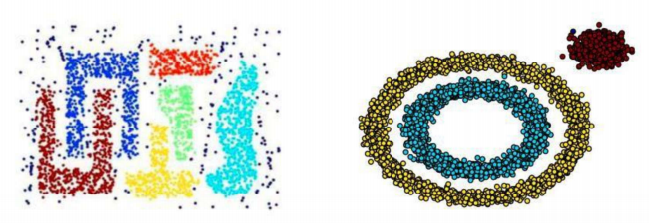
是一种聚类分类无监督,基于密度的带噪声的空间聚类应用算法,它是将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并在噪声的空间数据集重活发现任意形状的聚类
噪声就是那些不符合密度要求的点,可能是异常点,稀疏区域的正常点,两个簇之间的边界点,把他们归为标签-1
DBSCAN鲁棒性比K-means强,鲁棒性的意思就是抗干扰能力。DBSCAN算法,可识别噪声,一两个异常点不会影响整体聚类结果;K-means算法会受异常点影响,一个异常点会拽着聚类中心跑偏。
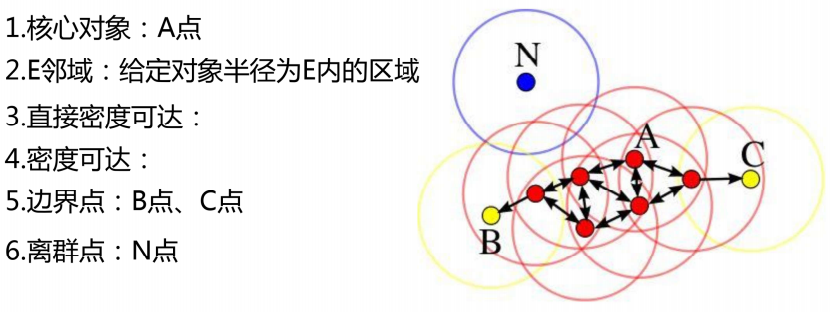
以A为原点,E为半径形成一个圆的范围,在圆之内的点被划为与A同类,随之以这些点为圆心,E为半径形成圆的区域,在范围内的数据点就会被划为该类,一直这样进行扩张,当领域扩张的时候密度小于密度阈值就会停止继续扩张,密度值就是圈内包括这个圆心点的数据个数,密度阈值就是一个临界,圈内数据点个数小于密度阈值就停止扩张。但需要注意并不是所有点都能被作为圆心,向外扩张,
3.DBSCAN的实现
实现过程中,我们要做的就是输入数据集,指定领域大小,指定密度阈值。所以DBSCAN算法最重要的两个参数就是领域大小合密度阈值。
想要感受DBSCAN的过程可以在https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/中体验

一下就是比较重要的两个参数

数据:

python
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn import metrics
beer = pd.read_table("data.txt",sep=' ', encoding='utf8', engine='python')
X = beer[["calories","sodium","alcohol","cost"]]
db = DBSCAN(eps=20, min_samples=2).fit(X)#归一化,
labels = db.labels_
beer['cluster_db'] = labels
beer.sort_values('cluster_db')
score = metrics.silhouette_score(X,beer.cluster_db)
print(score)
寝室分配案列
python
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.preprocessing import StandardScaler
beer = pd.read_csv(r"D:\learn\代码所用文本\datingTestSet2.txt",sep='\s+',header=None)
X = beer.iloc[:,:-1]
scaler=StandardScaler()
X=scaler.fit_transform(X)#归一化
eps_list=[0.05,0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5]
best_score=-1#设置成-1确保每次比较
best_eps=eps_list[0]
for eps in eps_list:
db=DBSCAN(eps=eps,min_samples=2).fit(X)
labels = db.labels_#获取每个点的聚类标签,-1表示噪声
#条件判断:确保能计算出轮廓系数
#1.至少有2种不同的标签(不止一个聚类)
#2.非噪声点的数量>1(轮廓系数至少需要两个样本)
if len(set(labels))> 1 and (labels != -1).sum()>1:
mask=labels !=-1#创建掩码,只选择非噪声点(标签 !=-1)
score=metrics.silhouette_score(X[mask],labels[mask])#计算轮廓系数,只对非噪声点计算
if score > best_score:#记录历史最高评分
best_score=score
best_eps=eps
print(best_eps)
db = DBSCAN(eps=best_eps, min_samples=2).fit(X)#归一化,eps要小点,数据的尺度变了
labels = db.labels_
beer['cluster_db'] = labels
beer.sort_values('cluster_db')
score = metrics.silhouette_score(X,beer.cluster_db)
print(score)这里我们结果评价用的是轮廓系数,最终结果在-1和0之间,说明效果不好,当然我们这里用轮廓系数作为评价指标也不是很好的,有局限性