目录
[1.1绝对装入方式(Absolute Loading Mode)](#1.1绝对装入方式(Absolute Loading Mode))
[1.2可重定位装入方式(Relocation Loading Mode)](#1.2可重定位装入方式(Relocation Loading Mode))
[1.3动态运行时的装入方式(Dynamic Run-time Loading)](#1.3动态运行时的装入方式(Dynamic Run-time Loading))
[2.1静态链接(Static Linking)方式](#2.1静态链接(Static Linking)方式)
[2.2装入时动态链接(Load-time Dynamic Linking)](#2.2装入时动态链接(Load-time Dynamic Linking))
[2.3运行时动态链接(Run-time Dynamic Linking)(作业题)](#2.3运行时动态链接(Run-time Dynamic Linking)(作业题))
[4.1首次适应算法(First Fit,FF)](#4.1首次适应算法(First Fit,FF))
[4.2循环首次适应算法(Next Fit,NF)](#4.2循环首次适应算法(Next Fit,NF))
[4.3最佳适应算法(Best Fit,BF)](#4.3最佳适应算法(Best Fit,BF))
[4.4最坏适应算法(Worst Fit,WF)](#4.4最坏适应算法(Worst Fit,WF))
[5.1快速适应算法(Quick Fit,QF)(也成为分类搜索法)](#5.1快速适应算法(Quick Fit,QF)(也成为分类搜索法))
[5.2伙伴系统(Buddy System,BS)](#5.2伙伴系统(Buddy System,BS))
一、存储器的层次结构
1.存储器的多层结构
1.1存储器的多层结构
CPU寄存器(寄存器)
--->主存(高速缓存-->主存储器-->磁盘缓存)
--->辅存(固定磁盘-->可移动存储介质)(断电可保存)
1.2可执行存储器
寄存器和主存储器
2.主存储器与寄存器
2.1主存储器
保存进程运行时的程序和数据(可执行存储器)
2.2寄存器
具有与处理机相同的速度,对寄存器的访问速度最快
3.高速缓存和磁盘缓存
3.1高速缓存
介于寄存器和存储器之间的寄存器,用于存储在主存中常用的数据,减少处理机对主存储器的访问次数。
3.2磁盘缓存
暂时存放一些频繁使用的一部分磁盘数据和信息。
磁盘缓存与高速缓存的不同:磁盘缓存本身并不是一个实际存在的存储器,而是主存中断 部分存储空间,暂时存放从磁盘中读取的信息。
二、程序的装入和链接
(1)编译:编译用户源程序,形成若干个目标块
(2)链接:将目标块和所需库函数链接在一起,形成一个完整的装入模块
(3)装入:将装入模块装入内存
1.程序的装入
1.1绝对装入方式(Absolute Loading Mode)
操作系统很小且只能运行单道程序时,完全可以知道程序将会装入到内存的什么位置。
1.2可重定位装入方式(Relocation Loading Mode)
根据内存的具体情况将装入模块装入到合适的位置。(涉及物理地址与逻辑地址)
把在装入时对目标程序的指令和数据地址的修改过程称为重定位。由于该过程是在装入时一次完成的,在之后便不再改变,故又称为静态重定位。
1.3动态运行时的装入方式(Dynamic Run-time Loading)
在具有对换功能的系统中,进程可能被多次换出换入。
只有在程序真正被执行的时候,才将其逻辑地址转化为物理地址,在不执行的时候,仅使用其逻辑地址。以此减少地址转换对运行速度的影响。
2.程序的链接
2.1静态链接(Static Linking)方式
程序运行之前,先将目标模块与所需库函数进行链接形成一个完整的装入模块,以后不再拆开。
(如C++中的imgui库,#include"imgui.h")
cpp
// 编译时,ImGui的代码被直接链接到你的程序中
#include "imgui.h"
// 链接时使用imgui.lib(Windows)或libimgui.a(Linux)
// 最终生成一个独立的exe,不依赖外部DLL(1)对相对地址进行修改
装入模块的逻辑地址起始地址都是0,在进行链接的时候,需要进行相应的拼接。
(2)变换外部调用符号
将外部调用符号也转换为相对地址,如B的起始地址改为L。

2.2装入时动态链接(Load-time Dynamic Linking)
目标模块在装入内存时,边装入边链接。
(如C++中SDL的调用,#include<SDL.h>)
cpp
// 程序启动时,操作系统自动加载SDL.dll
#include <SDL.h>
// 链接时使用SDL.lib(导入库),只包含函数重定位信息
// 运行时需要SDL.dll文件在可执行文件目录或系统路径中(1)便于修改和更新
(2)便于实现对目标模块的共享
2.3运行时动态链接(Run-time Dynamic Linking)(作业题)
推迟链接时间。只有当前模块在被调用,且未被链接的时候,才开始去进行链接。(加快装入过程,节省内存空间)
(如C++中SDL库的手动加载)
cpp
// 手动加载DLL,获取函数指针
HMODULE hSDL = LoadLibrary("SDL2.dll");
if (hSDL) {
auto SDL_Init = (decltype(&::SDL_Init))GetProcAddress(hSDL, "SDL_Init");
SDL_Init(SDL_INIT_VIDEO);
// 使用后FreeLibrary(hSDL);
}三、连续分配存储管理方式
1.单一连续分配
在单道程序环境下,把内存氛围系统区和用户区两部分。系统区只提供给系统使用。用户区的整个内存空间都分配给当前程序使用。
(仅面向单道批处理系统,并发度为1)
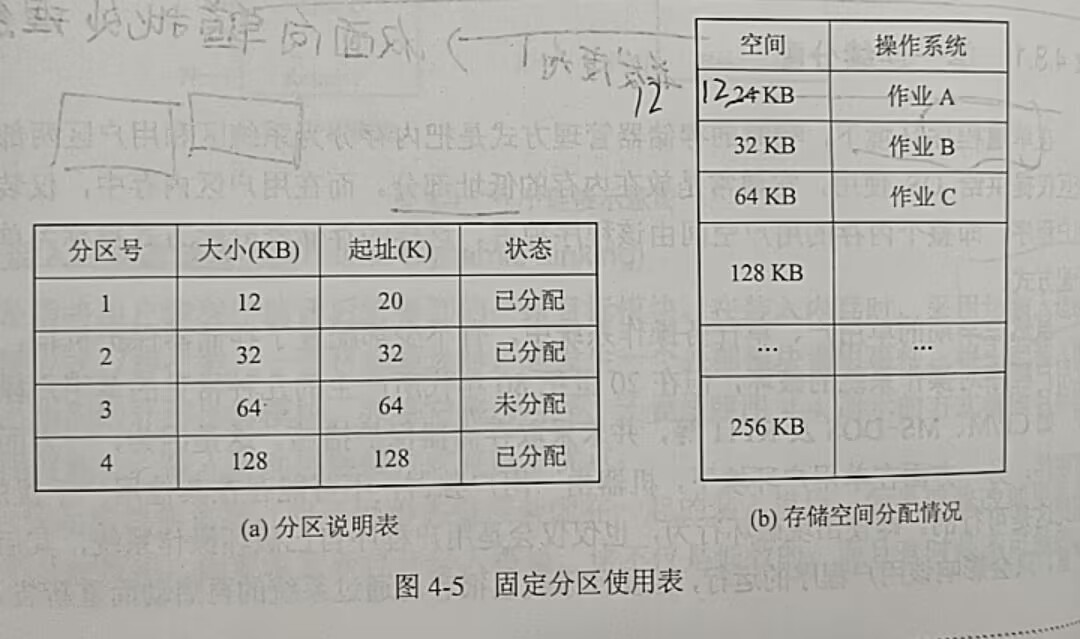
2.固定分区分配
2.1划分分区的方法
(1)分区大小相等。缺乏灵活性(程序太小会浪费,程序太大装不下),适用于内存空间大小相同/接近的情况,方便使用。
(2)分区大小不等。检查作业大小,根据需求划分。
2.2内存分配
依据用户程序大小检索分区说明表,从中找到一个满足要求且尚未分配的分区进行分配。
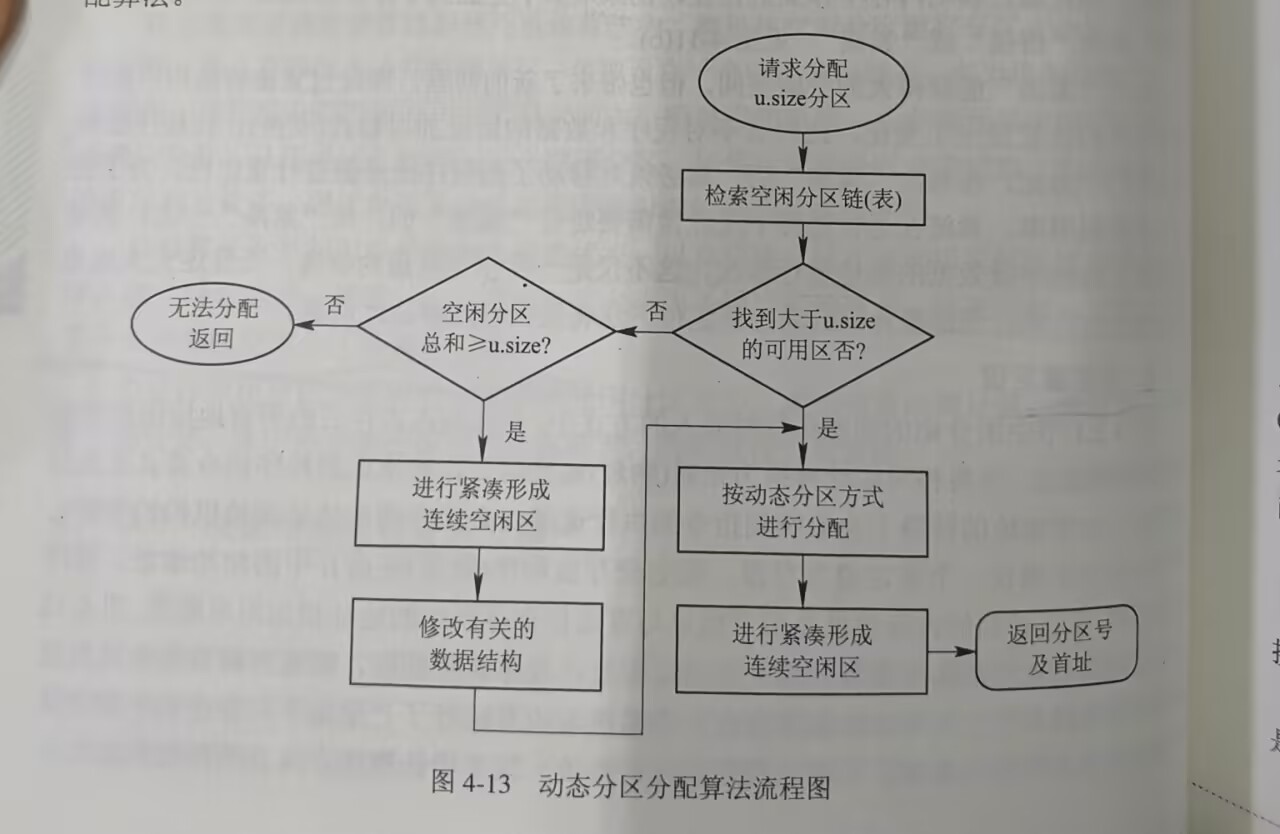
3.动态分区分配
根据实际需要,动态地为之分配内存
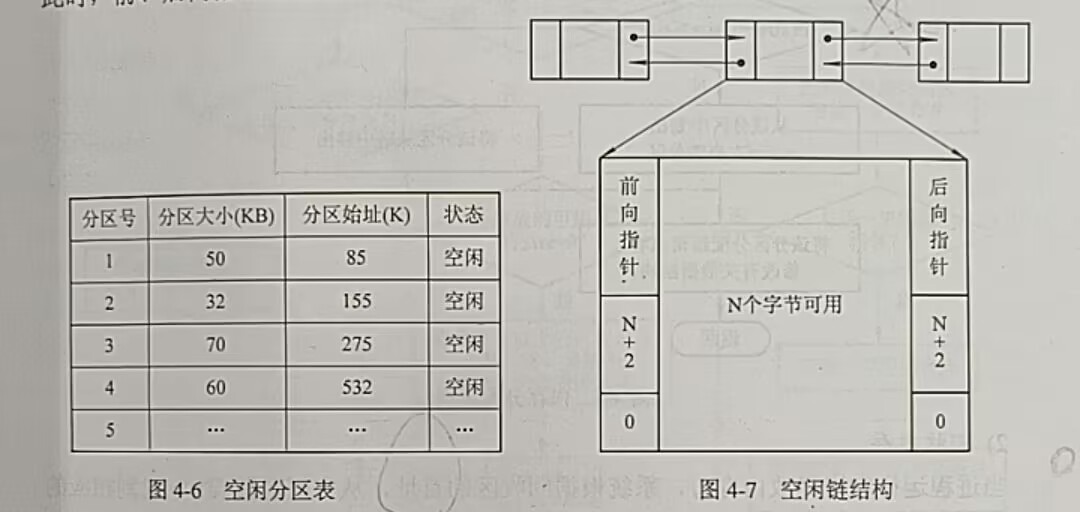
3.1数据结构
(1)空闲分区表。用于记录每个空闲分区的情况(分区号,分区大小,起始地址,状态)
(2)空闲分区链。将空闲分区链接成一个双向链
3.2算法
四种顺序式搜索算法 与三种索引式搜索算法(之后介绍)
3.3操作
分配内存和回收内存
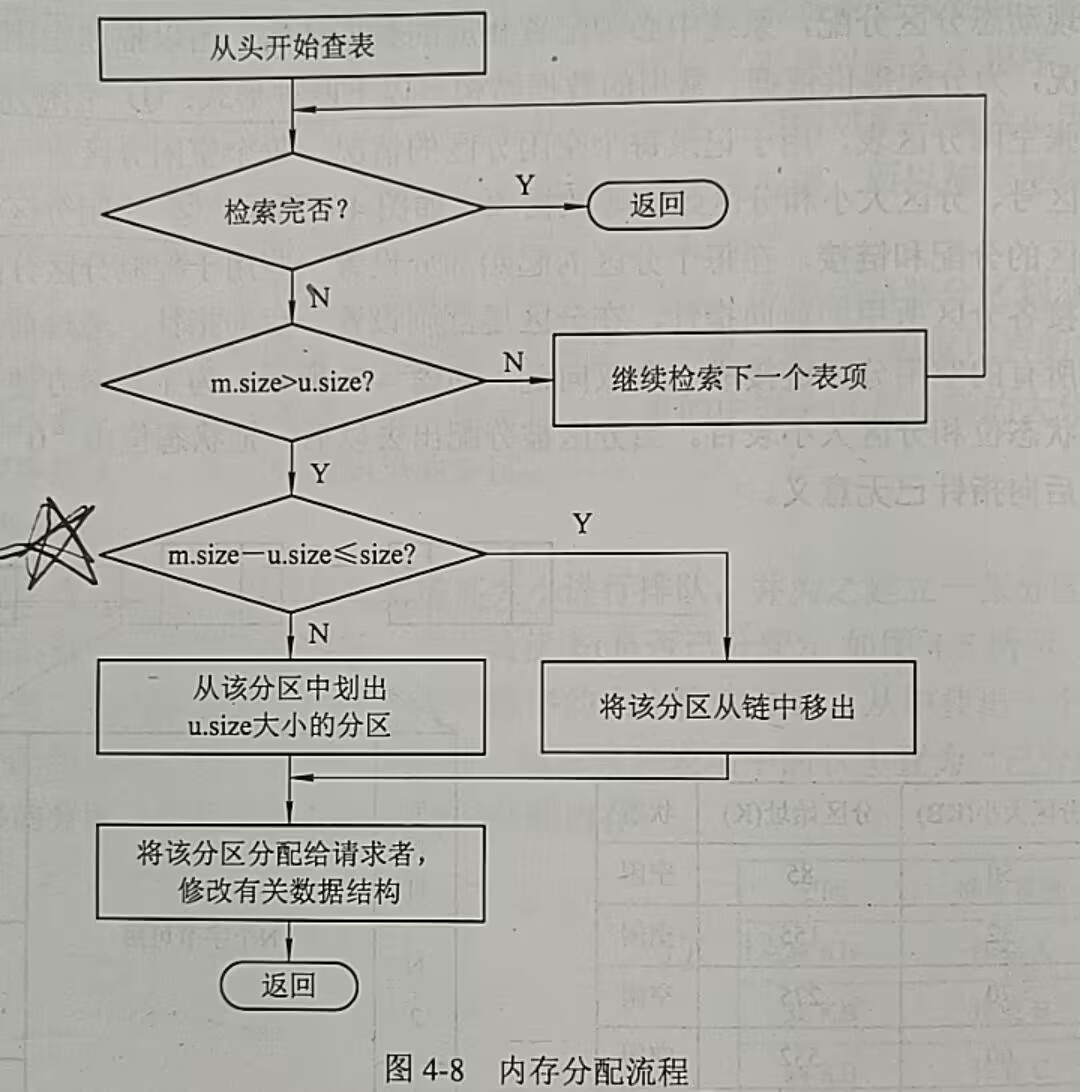
(1)分配内存
找到合适的内存进行分配,如果当前内存块剩余内存超出阈值,则多划分出剩余的部分。
(2)回收内存
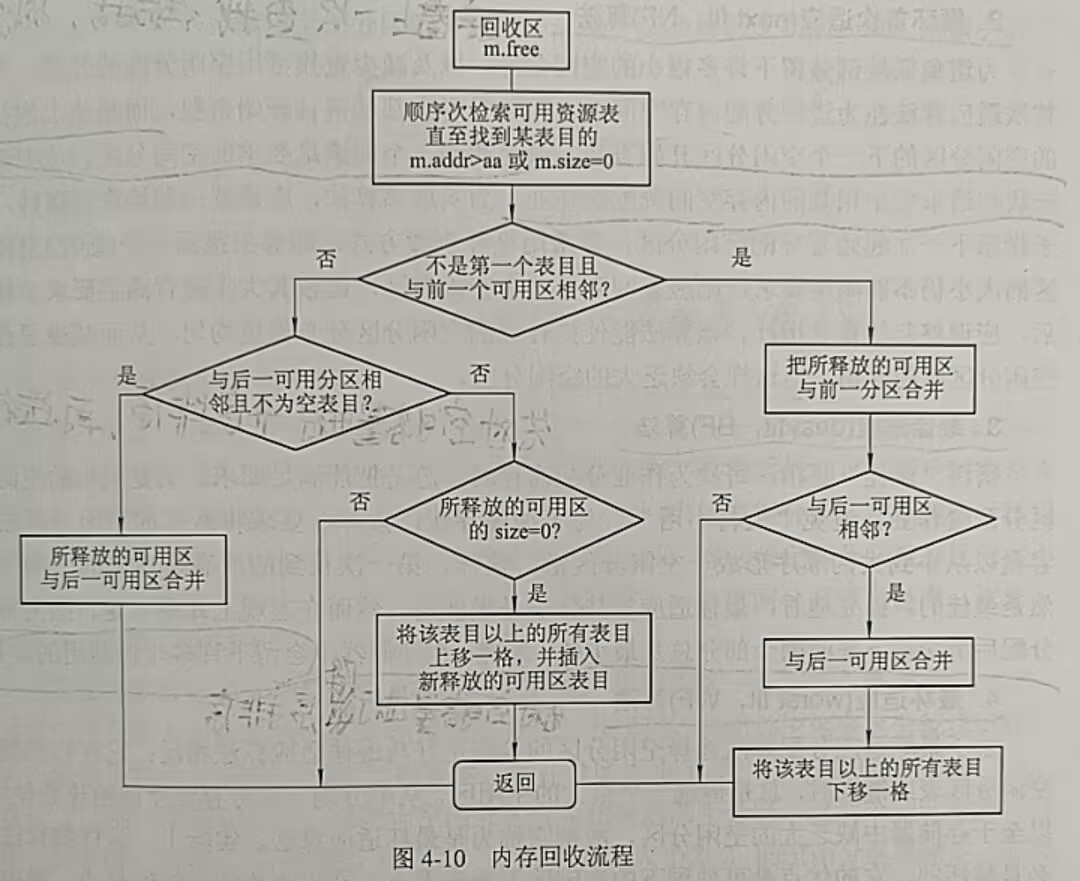
根据回收区的首地址,从空闲链(表)中找到相应的插入点:
①如图中(a)所示,回收区与前一个空闲分区F1邻接,不需要分配新的表项,直接修改F1的分区大小。
②如图中(b)所示,回收区与后一个空闲分区F2邻接,此时以回收区的首地址为新的首地址,分区大小为二者之和。
③如图中(c)所示,回收区与前后空闲分区F1、F2均邻接,此时使用F1的表项和首地址,分区大小改为三者之和。
④如图中(d)所示,回收区不存在邻接空闲分区表项,此时创建一个新的表项,设置首地址和分区大小。

内存回收流程如下:
4.基于顺序搜索的动态分区算法(作业题)

4.1首次适应算法(First Fit,FF)
从头到尾遍历一遍,直到找到大小足够的空间进行分配,否则分配失败。
(倾向于使用中低地址的空间,为大作业留下了足够的大空间。但是也产生了许多难以利用的、小的空间碎片,此外,每次从头遍历也增加了时间开销)
4.2循环首次适应算法(Next Fit,NF)
接续上一次的查找,继续向后查找,减少对前面分区的不必要扫描。
(可以使内存中的控件分区分布更加均匀,减少查找空闲分区的开销。但是也减少了大的空闲分区数量)
4.3最佳适应算法(Best Fit,BF)
先对内存分区进行升序排序,然后使用首次适应算法(FF)
(看似最佳,但在宏观上可能会产生很多难以利用的空间碎片)
4.4最坏适应算法(Worst Fit,WF)
先对内存分区进行降序排序,然后使用首次适应算法(FF)
(查找效率很高,,产生碎片的可能性小,对中小作业有利。但是会缺乏大的空闲分区,对大作业不利)
5.基于索引搜索的动态分区分配算法(作业题)
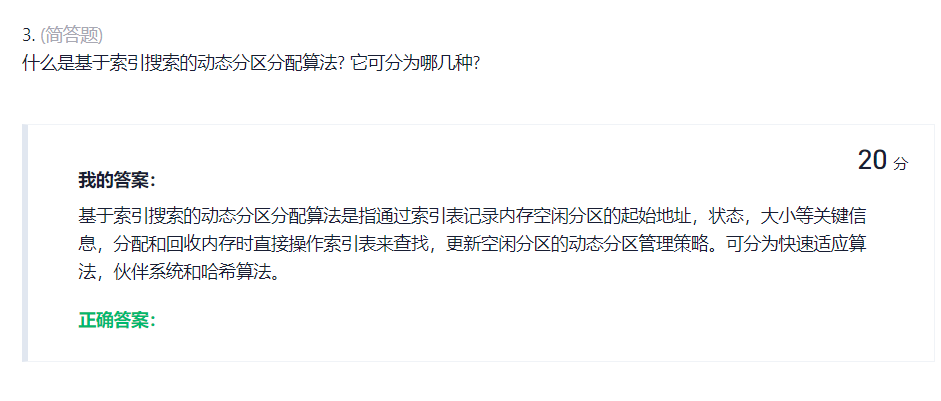
5.1快速适应算法(Quick Fit,QF)(也成为分类搜索法)
对于每一类具有相同容量的空闲分区,单独设立一个空闲分区链表(系统中会存在多个空闲分区链表,大小通常为2KB,4KB,8KB......)。之后,在内存中设立一张管理索引表,每个表项对应一种空闲分区类型,并记录该类空闲分区链表的表头指针。
分配步骤:
(1)根据进程长度,找到索引表中可容纳该进程的最小空闲区链表
(2)从链表中取下第一块进行分配(后续块往前推)
TIPS:该算法在进行空闲分区分配的时候,不会对任何分区产生分割!!!
优点:可以保留大的分区,满足对大空间的需求,也不会产生内存碎片。查找效率高
缺点:为了有效合并分区,在分区归还主存时的算法复杂,系统开销较大。在分配空闲分区时,一个分区只属于一个进程,存在一定的浪费。
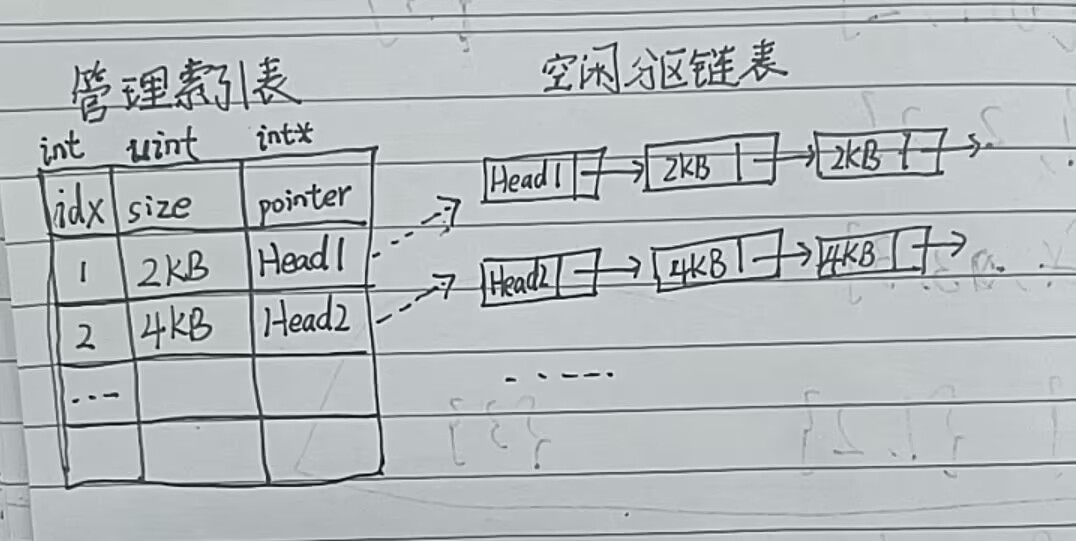
以下是我对该数据结构的配图(个人理解,如有错误,希望指出):
5.2伙伴系统(Buddy System,BS)
在系统开始时,整个内存区是一个大小为pow(2,m)的空闲分区。
若进程所需存储空间为n,锁定pow(2,i-1)<n<=pow(2,i),则应当找一个分区大小为pow(2,i)的分区进行分配,若找不到,则继续向上找i+1,i+2,etc。找到之后,逐步将该分区对半分成两块相等大小的分区(它们互为伙伴),直到大小为pow(2,i),分配给当前进程。
在内存的回收过程中,则是将伙伴进行合并。
不过,上述只是简述,旨在建立一个系统的认识,我们还需要注意的是:如何拆分,如何去找到空闲分区(数据结构是什么?),在合并的时候怎么知道伙伴是谁(它们存在何种地址关系?)
如下所示将会给出分配的例子。

在这里,所有的空闲分区存储结构同**快速适应算法(QF)**的存储结构一致。

在伙伴系统中,由于需要一系列伙伴关联性的处理,其时间性能 要比快速适应算法 差。(但是还是要比顺序搜索算法 好)。在其空间性能 上,对空闲分区进行了合并,减少了空闲分区,提高了空闲分区的可利用率,要优于快速适应算法 。(当然劣于顺序搜索算法)。
5.3哈希算法(Hash)
构造一张以空闲分区大小为关键字的哈希表,该表的每一个表项记录了一个对应的空闲分区链表表头指针。
WaWaJie 的个人理解:
据我的理解,哈希算法并不像上面的QF和BS算法是一个完整的内存分配和内存回收的算法,它只是一个结构的优化,通过哈希的查找来快速找到对应分区的表头指针,其完全可以应用到前面两个算法当中。
6.动态可重定位分区分配
6.1紧凑
计算机运行一段时间后,其内存空间会被分成很多很小的分区。此时如果有一个大作业需要运行,就很难找到一个完整的大空间进行分配。因此,就需要将那些小的空闲分区进行**"紧凑"** ,从而得到一个大空间(如下图所示)。但是,这么做的话也会导致程序的地址发生变化,因而就需要进行**"动态重定位"**。

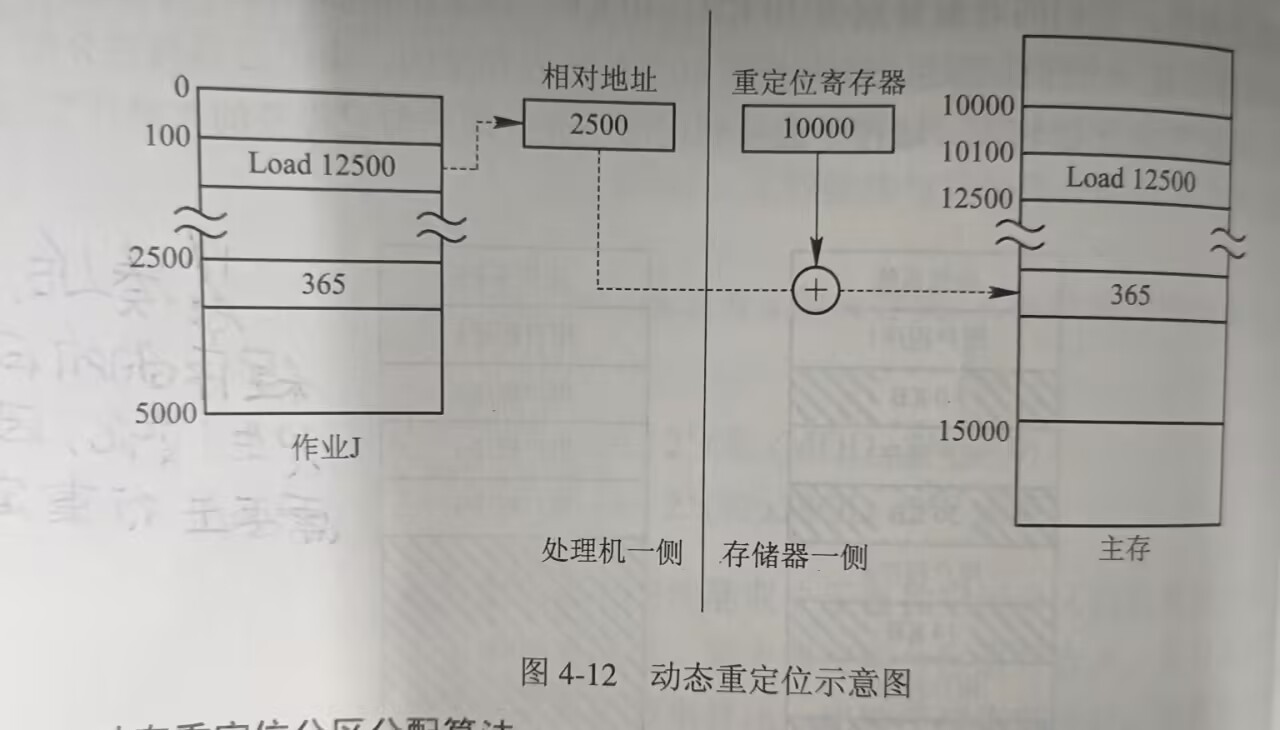
6.2动态重定位
作业装入内存后的所有地址仍是相对地址(逻辑地址) ,只有在其真正执行的时候,才会将相对地址 转化为绝对地址(物理地址) 。而为了减少地址转换 所造成的性能消耗,在系统中增设了一个重定位寄存器 ,用于地址转换。作业在执行时,其实际访问的内存地址就是其相对地址+重定位寄存器存储的起始地址 。那么,当内存进行了**"紧凑"** 之后,程序就不需要进行任何修改,只需要用新的起始地址去替换原本的起始地址。
6.3动态重定位分区分配算法
相较于动态分区分配算法,多了当内存不够的时候,进行**"紧凑"**的步骤。其他流程基本一致。
四、对换(Swapping)
1.多道程序环境下的对换技术
1.1对换的引入
问题①:某些进程被阻塞运行却占用了大量的内存空间。
问题②:作业过多,但是由于内存空间不足,一直驻留在外存。
问题解决:引入**"对换"**
把内存中暂时不能运行的进程或暂时不用的程序和数据换出到外存上,把已具备运行条件的进程或进程所需的程序和数据换入内存。
对换时改善内存利用率的有效措施,直接提高处理机的利用率和系统的吞吐量。
1.2对换的类型
(1)整体对换。处理机的中级调度。
(2)页面(分段)对换。
2.对换控件的管理
2.1对换空间管理的主要目标
(1)对文件区管理:提高文件存储空间的利用率
(2)对对换空间管理的主要目标:提高进程换入换出的速度
2.2对换区空间盘块管理中的数据结构
空闲分区表/空闲分区链
2.3对换空间的分配与回收
同内存分配与回收
3.进程的换入换出
3.1进程的换出
(1)选择被换出的进程:选择阻塞或睡眠状态的进程(若有多个,则选择优先级最低的)
(2)进程换出过程:申请对换空间---》启动磁盘---》将进程的程序和数据传送到磁盘对换区上。
3.2进程的换入
找出就绪状态的进程(若有多个,则选择已经被换出磁盘最久的那个),申请内存空间并调入内存。
五、分页存储管理方式
连续分配内存 的方式会产生许多内存"碎片",虽然可以通过**"紧凑"** 的方式得到大块空间,但还是需要付出很大的代价。于是就产生了离散分配方式,将一个进程直接分散地装入到许多不邻接的分区中。离散分配方式有:
①分页存储管理方式:将用户程序的地址空间氛围若干个固定大小的区域,称为"页"。
②分段存储管理方式:把用户的地址空间分成若干个大小不同的段,每段可定义一组相对完整的信息。
③段页式存储管理方式:二者优点结合
1.分页存储管理的基本方法
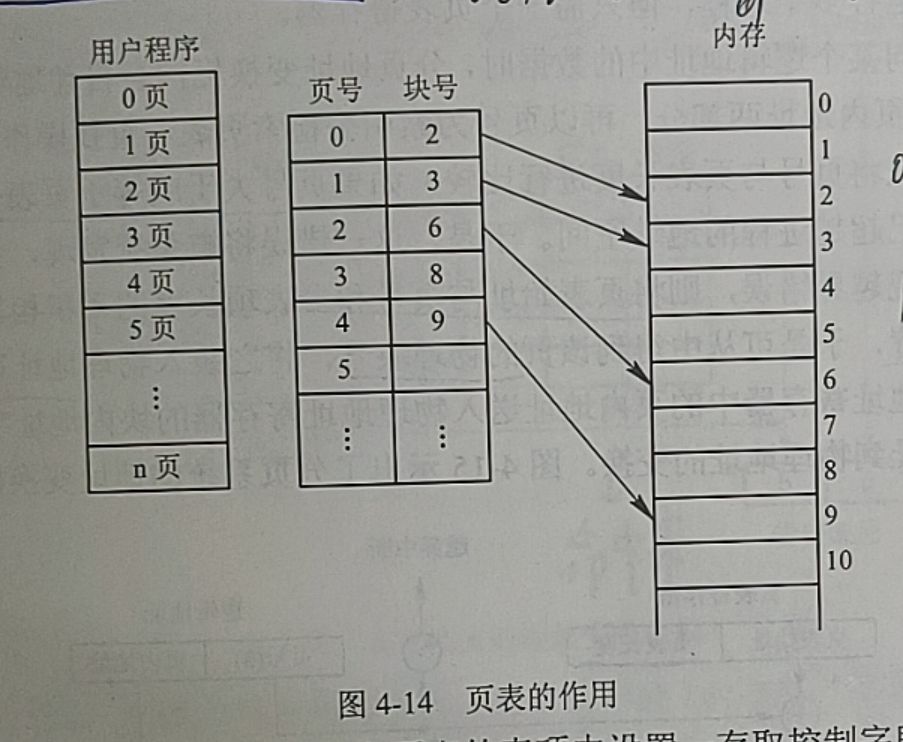
1.1页面和物理块
(1)页面:逻辑地址空间分成若干个页,内存的物理地址空间分成若干个块。在为进程分配内存时,页块对应分配。
(2)页面大小
1.2地址结构
页号+位移量
若给出一个逻辑地址空间中的地址为A,页面大小为L,则页号P和页内地址d:
P=A/L(向下取整) d=A%L
1.3页表
一看便知
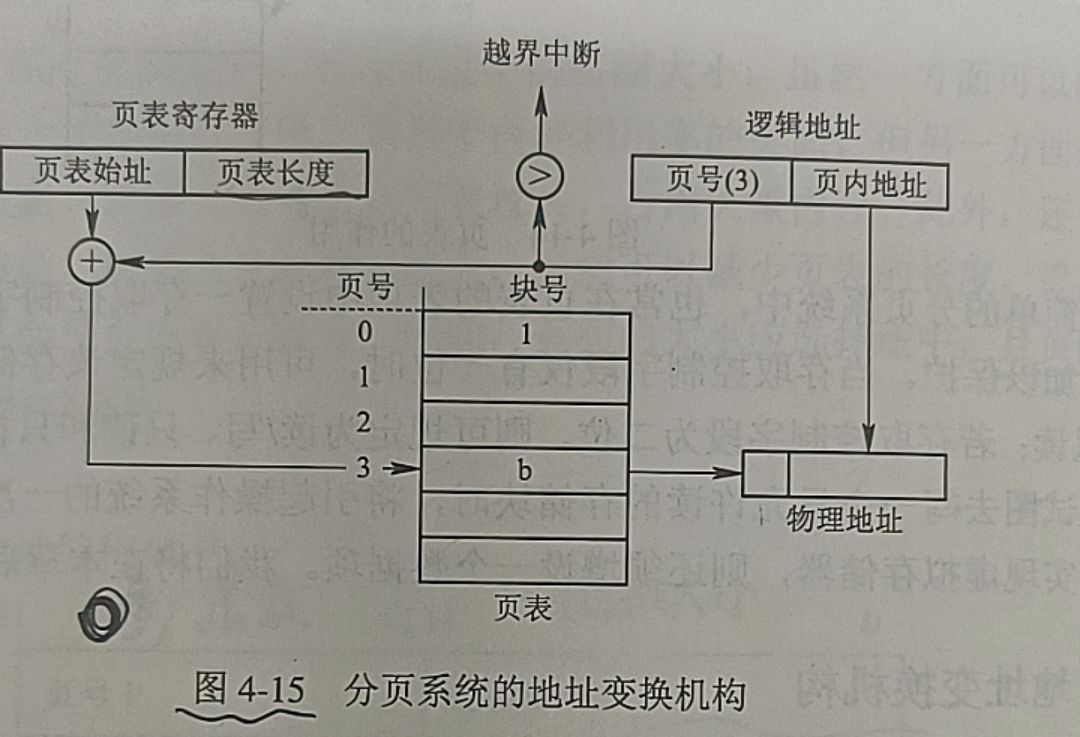
2.地址变换机构(作业题)

2.1基本的地址变换机构
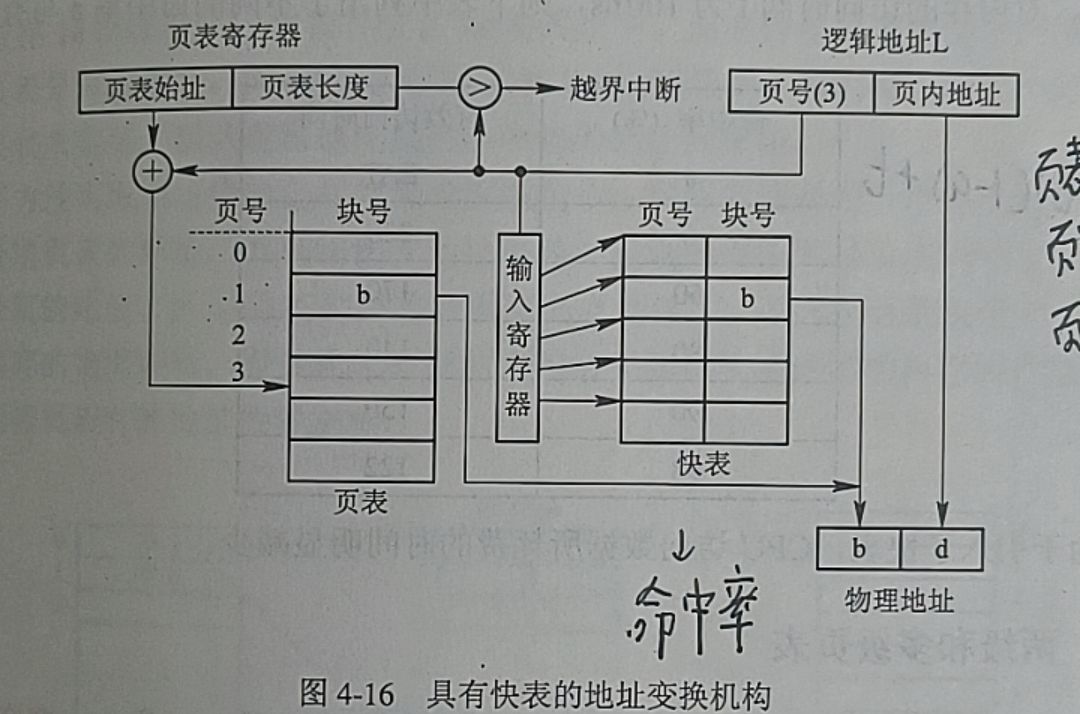
2.2具有快表的地址变换机构
3.访问内存有效时间(EAT)
(1)基本分页存储管理方式:
EAT = t(查找页表项)+t(物理块号与页内地址拼接成实际的物理地址)=2t
(2)引入快表后:
λ表示查找快表所需要的时间,a表示命中率,t表示访问一次内存的时间
EAT=a*λ+(t+λ)(1-a)+t=2t+λ-t*a
4.两级和多级页表
没有重点讲
5.反置页表
没有重点讲
六、分段存储管理方式(作业题)
老师说知道个概念即可。
 分页和分段的区别:(P158)
分页和分段的区别:(P158)
(1)页是信息的物理单位;段则是信息的逻辑单位。
(2)页的大小固定且由系统决定;段的长度不固定。
(3)分页的用户程序地址空间是一维的;分段是用户的行为,地址空间是二维的