目录
前言
-
Flink CDC (Change Data Capture) 是一个基于 Apache Flink 的开源实时数据集成框架,它能从主流数据库(如 MySQL, PostgreSQL, Oracle等)实时捕获数据变更(增/删/改),并将这些变化转化为流数据,构建低延迟、高吞吐的数据管道、实时同步、数据仓库入湖等场景。支持全量或增量同步。
-
Flink CDC同步有两种方式(本文使用Flink SQL):
- 方式一、编写代码引入驱动包(Flink DataStream/Table API),灵活定制,适用于复杂业务。
- 方式二、使用Flink SQL,极简搭建,适用于简单业务。
-
早期我使用Flink 2.1.1版本,发现缺少一些Jar包,所以退到了1.20.3版。
准备
| 软件 |
|---|
| JDK 17 |
| MySQL 8.0+ |
| Elasticsearch 7.9.3 |
| Kibana 7.9.3 |
| Flink 1.20.3 |
软件包
- Elasticsearch 7.9.3 https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-9-3
- Kibana 7.9.3 https://www.elastic.co/downloads/past-releases/kibana-7-9-3
- ik分词 https://release.infinilabs.com/analysis-ik/stable/elasticsearch-analysis-ik-7.9.3.zip
- Flink 1.20.3 https://dlcdn.apache.org/flink/flink-1.20.3/flink-1.20.3-bin-scala_2.12.tgz
JDK
shell
sudo apt install openjdk-17-jdk -yJar 包
- flink-sql-connector-mysql-cdc-3.5.0.jar
- mysql-connector-java-8.0.33.jar
- flink-sql-connector-elasticsearch7-3.1.0-1.20.jar
- 要放到Flink
lib目录里。
Flink
- config.yaml
yml
rest:
# 开放外部访问
address: 0.0.0.0
bind-address: 0.0.0.0
taskmanager:
# 能运行的任务数量,一般是 CPU核心数 * 2
numberOfTaskSlots: 12- 启动
shell
zzq@computer:~/software/flink-1.20.3$ ./bin/start-cluster.sh 
ES
- config/elasticsearch.yml
yml
cluster.name: my-application
node.name: node-1
discovery.type: single-node
network.host: 0.0.0.0
http.port: 9200
#geo 报错
ingest.geoip.downloader.enabled: false-
启动,
-d后台启动。zzq@computer:~/software/elasticsearch-7.9.3$ ./bin/elasticsearch -d
Kibana
-
config/kibana.yml
外部访问
server.host: "0.0.0.0"
禁用报表
xpack.reporting.enabled: false
-
/etc/systemd/system/kibana.service
shell
[Unit]
Description=Kibana
After=network.target
[Service]
User=zzq
Group=zzq
Type=simple
ExecStart=/home/software/kibana-7.9.3-linux-x86_64/bin/kibana
[Install]
WantedBy=multi-user.target-
启动(注意:要先安装
NodeJS 18)sudo systemctl start kibana
MySQL 初始化表和数据
sql
CREATE TABLE `t_user` (
`id` int(11) NOT NULL COMMENT '主键',
`name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`email` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
INSERT INTO `test`.`t_user` (`id`, `name`, `email`, `create_time`) VALUES (1, 'zzq123', '100@qq.com', '2025-11-09 16:39:32');
INSERT INTO `test`.`t_user` (`id`, `name`, `email`, `create_time`) VALUES (2, 'Zhou1', '200@qq.com', '2025-11-09 16:39:52');
INSERT INTO `test`.`t_user` (`id`, `name`, `email`, `create_time`) VALUES (3, 'Zhou Zhongqing', '200@qq.com', '2025-11-09 16:39:52');
INSERT INTO `test`.`t_user` (`id`, `name`, `email`, `create_time`) VALUES (4, 'zzq4', '400@qq.com', '2025-11-30 16:58:52');
INSERT INTO `test`.`t_user` (`id`, `name`, `email`, `create_time`) VALUES (5, 'zzq5', '500@qq.com', '2025-12-02 21:50:29');Flink SQL同步数据
-
启动sql控制台
zzq@computer:~/software/flink-1.20.3$ ./bin/sql-client.sh
-
将以下代码分块复制到控制台执行
sql
CREATE TABLE mysql_user (
id INT,
name STRING,
email STRING,
create_time TIMESTAMP(3),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.39.166',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'database-name' = 'test',
'table-name' = 't_user',
'scan.startup.mode' = 'initial'
);
CREATE TABLE es_user (
id INT,
name STRING,
email STRING,
create_time TIMESTAMP(3),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://192.168.117.129:9200',
'index' = 'index_user'
);
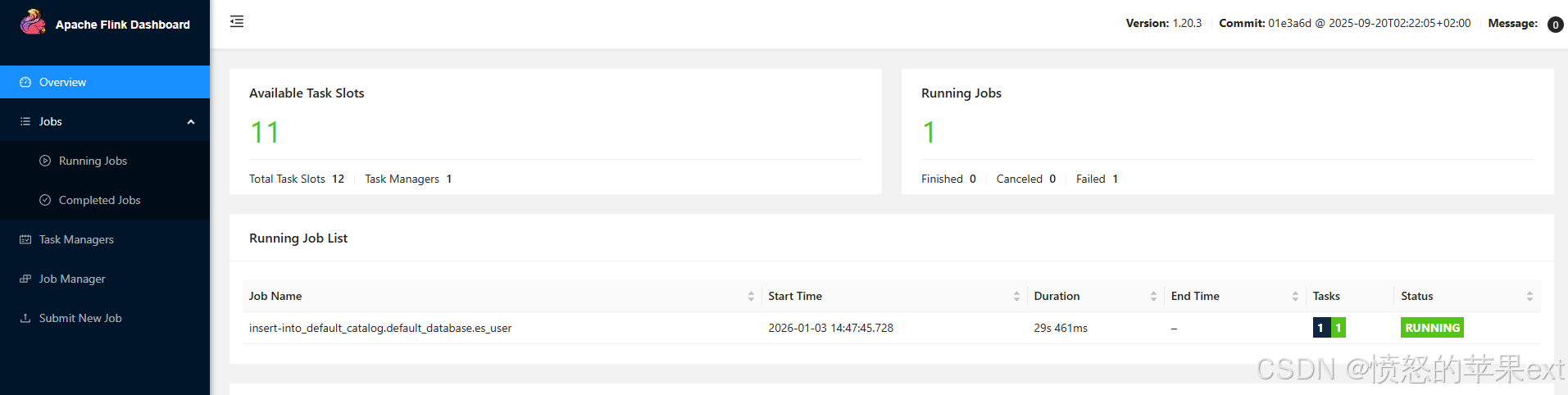
INSERT INTO es_user SELECT id, name, email, create_time FROM mysql_user;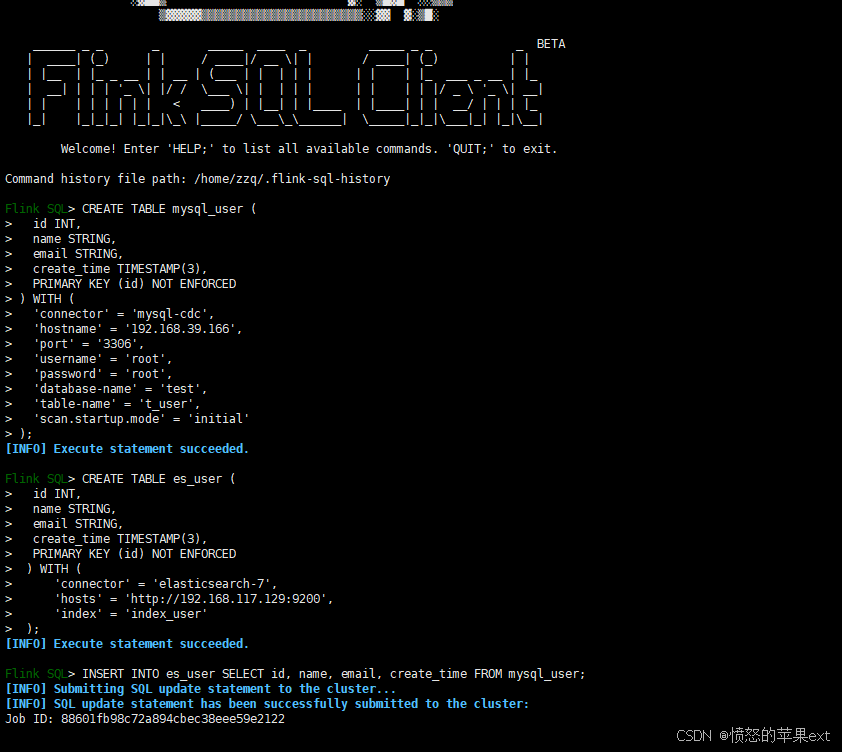
scan.startup.mode 参数的取值有:
initial : 先全量快照,再增量同步
latest-offset : 跳过全量,直接从当前最新日志位点开始增量同步
timestamp : 跳过全量,从指定时间戳对应的日志位点开始增量
specific-offset : 跳过全量,从指定日志位点(文件名 + 偏移量)开始增量
earliest-offset : 从可能的最早偏移量开始
group-offsets : 从 Zookeeper/Kafka 中某个指定的消费组已提交的偏移量开始
- 快捷提交job的方式,把上面sql写道一个sql文件里,用命令:
./bin/sql-client.sh -f xxx.sql。
验证效果
-
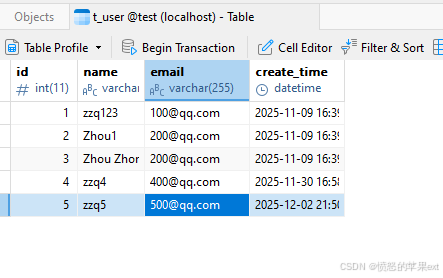
MySQL中的数据
-
MySQL的数据已同步到ES,如下图所示
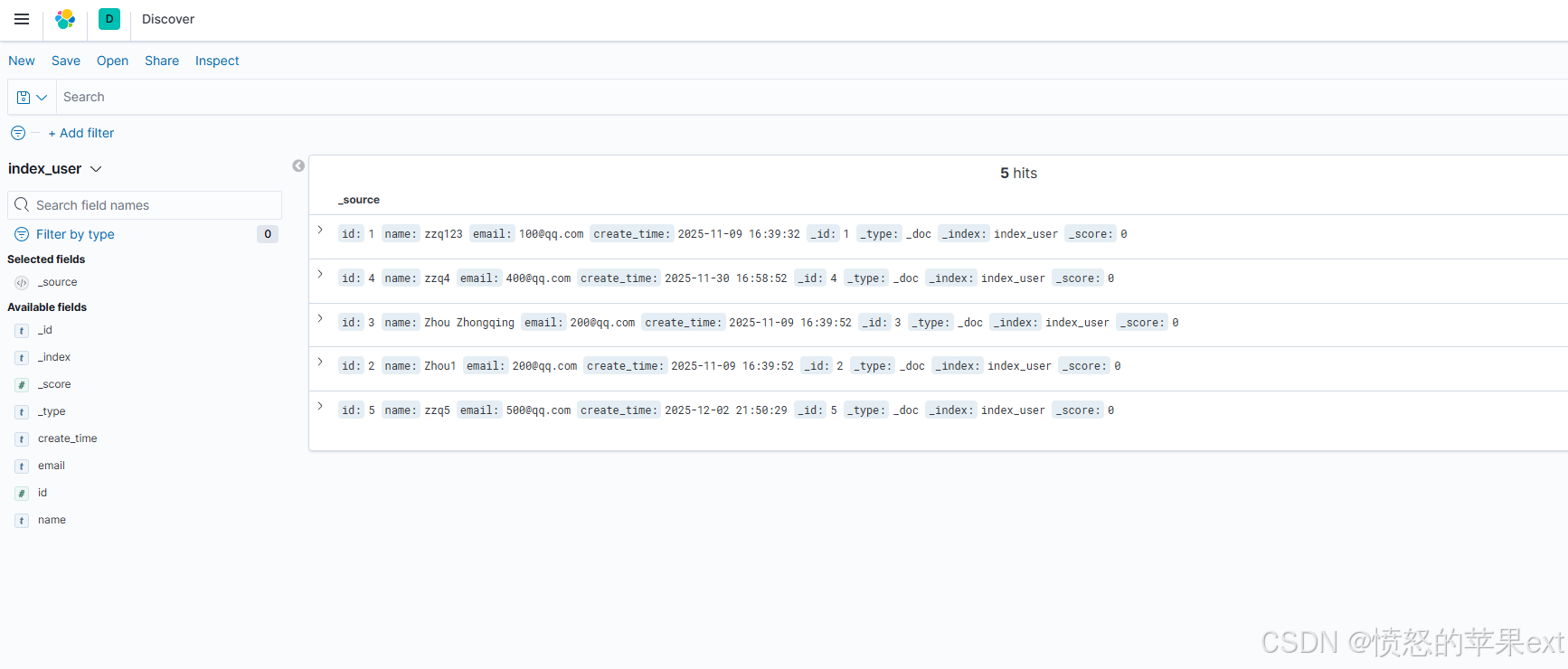
遇到的问题
客户端隔一段时间不访问ES,ES闲置一段时间后,第二天同步报错
org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
java.lang.RuntimeException: An error occurred in ElasticsearchSink.
at org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkBase.checkErrorAndRethrow(ElasticsearchSinkBase.java:415)
at org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkBase.checkAsyncErrorsAndRequests(ElasticsearchSinkBase.java:420)
at org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkBase.invoke(ElasticsearchSinkBase.java:317)
at org.apache.flink.table.runtime.operators.sink.SinkOperator.processElement(SinkOperator.java:65)
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:75)
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:50)
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:29)
at org.apache.flink.streaming.api.operators.TimestampedCollector.collect(TimestampedCollector.java:52)
at org.apache.flink.table.runtime.operators.sink.SinkUpsertMaterializer.retractRow(SinkUpsertMaterializer.java:194)
at org.apache.flink.table.runtime.operators.sink.SinkUpsertMaterializer.processElement(SinkUpsertMaterializer.java:152)
at org.apache.flink.streaming.runtime.io.RecordProcessorUtils.lambda$getRecordProcessor$0(RecordProcessorUtils.java:64)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:238)
at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:157)
at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:114)
at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)
at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:638)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:231)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:973)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:917)
at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:970)
at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:949)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:763)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)
at java.base/java.lang.Thread.run(Thread.java:842)
Caused by: java.net.SocketException: Connection reset
at java.base/sun.nio.ch.SocketChannelImpl.throwConnectionReset(SocketChannelImpl.java:394)
at java.base/sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:426)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.reactor.SessionInputBufferImpl.fill(SessionInputBufferImpl.java:231)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.codecs.AbstractMessageParser.fillBuffer(AbstractMessageParser.java:136)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.DefaultNHttpClientConnection.consumeInput(DefaultNHttpClientConnection.java:241)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.client.InternalIODispatch.onInputReady(InternalIODispatch.java:81)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.client.InternalIODispatch.onInputReady(InternalIODispatch.java:39)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.reactor.AbstractIODispatch.inputReady(AbstractIODispatch.java:114)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.reactor.BaseIOReactor.readable(BaseIOReactor.java:162)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.reactor.AbstractIOReactor.processEvent(AbstractIOReactor.java:337)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.reactor.AbstractIOReactor.processEvents(AbstractIOReactor.java:315)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.reactor.AbstractIOReactor.execute(AbstractIOReactor.java:276)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.reactor.BaseIOReactor.execute(BaseIOReactor.java:104)
at org.apache.flink.elasticsearch7.shaded.org.apache.http.impl.nio.reactor.AbstractMultiworkerIOReactor$Worker.run(AbstractMultiworkerIOReactor.java:591)
... 1 more- 我遇到的问题是ES服务器与客户端服务器网络不互通导致的,部署如下。
| 程序名称 | IP |
|---|---|
| ES | 192.168.0.111 |
| Java 程序(业务代码) | 192.168.10.232 |
-
192.168.0.x是主网络,192.168.10.x是桥接。192.168.10.232 能访问192.168.0.111,但是 192.168.0.111 无法访问 192.168.10.232 。 -
客户端访问ES服务器会建立一个
KeepAlive连接,Linux 服务器 TCP 的 Keepalive 有着自己的超时机制, 超时时间一般是7200秒(2小时)。若超过这个时间,且中间客户端没有操作。服务器就发送一个心跳包,探测下当前连接是否有效。但是 192.168.0.111 无法访问 192.168.10.232。就会断开并清除 TCP 连接。然而 192.168.10.232客户端并不知道连接被断开了。所以依旧用旧连接请求ES,所以报Connection reset。 -
解决方案就是让2个服务器可以相互访问。
-
如果无法做到互通,临时的方案就是配置job重启策略,以免报
Connection resetjob直接挂掉。
这个方案有一点弊端,实测会丢失一次变更。
- conf/config.yaml
yaml
restart-strategy:
type: fixed-delay
fixed-delay:
attempts: 3
delay: 3s索引状态yellow
- Elasticsearch 默认会为索引创建副本分片(默认副本数 = 1),但副本分片的设计原则是「不能和主分片在同一个节点」(否则失去副本的容错意义)
- 单机节点不需要副本,所以可以设置为0
- 在kibana执行
shell
PUT /索引名称/_settings
{
"number_of_replicas" : 0
}参考
- http://www.javacui.com/tool/669.html
- https://www.ververica.com/blog/how-to-guide-build-streaming-etl-for-mysql-and-postgres-based-on-flink-cdc
- https://github.com/infinilabs/analysis-ik
- https://segmentfault.com/a/1190000023478720
- https://blog.csdn.net/tansenc/article/details/141188935
- https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/
- https://juejin.cn/post/7323031996864331817