holoClient.flush()
代码如下:
arduino
```
@Value("${spring.datasource.hologres.jdbc-url:jdbc:postgresql://hgprecn-cn-nwy3e73kt001-cn-shanghai.hologres.aliyuncs.com:80/rjhy_dc_cdp}")
private String jdbcUrl;
@Value("${spring.datasource.hologres.username:BASIC$dc_cdp_test}")
private String username;
@Value("${spring.datasource.hologres.password:KUnRu5XCE2V9z_i5}")
private String password;
@Bean
public HoloClient generateHoloClient() {
HoloConfig config = new HoloConfig();
config.setJdbcUrl(jdbcUrl);
config.setUsername(username);
config.setPassword(password);
config.setOnConflictAction(OnConflictAction.fromWriteMode(INSERT_OR_UPDATE));
try {
return new HoloClient(config);
} catch (HoloClientException e) {
log.error("HoloDataSourceConfig.generateHoloClient, errorMsg:", e);
throw new RuntimeException(e);
}
}
```
ini
@Resource
private HoloClient holoClient;
TableSchema tableSchema = holoClient.getTableSchema(keyTypeEnums.getTableName());
batchData.forEach(listableBeanFactory -> {
Put put = new Put(tableSchema);
listableBeanFactory.forEach(put::setObject);
try {
holoClient.put(put);
} catch (HoloClientException e) {
log.error("holoClient.put(put), errorMsg:", e);
}
});
holoClient.flush();holoClient.flush() 的批处理是Hologres写入性能的核心,其底层是一个分阶段、高度并行化的数据管道。为了让你直观地理解这个复杂过程,下图描绘了数据从你的Java堆内存出发,直到安全写入Hologres存储引擎的完整旅程:
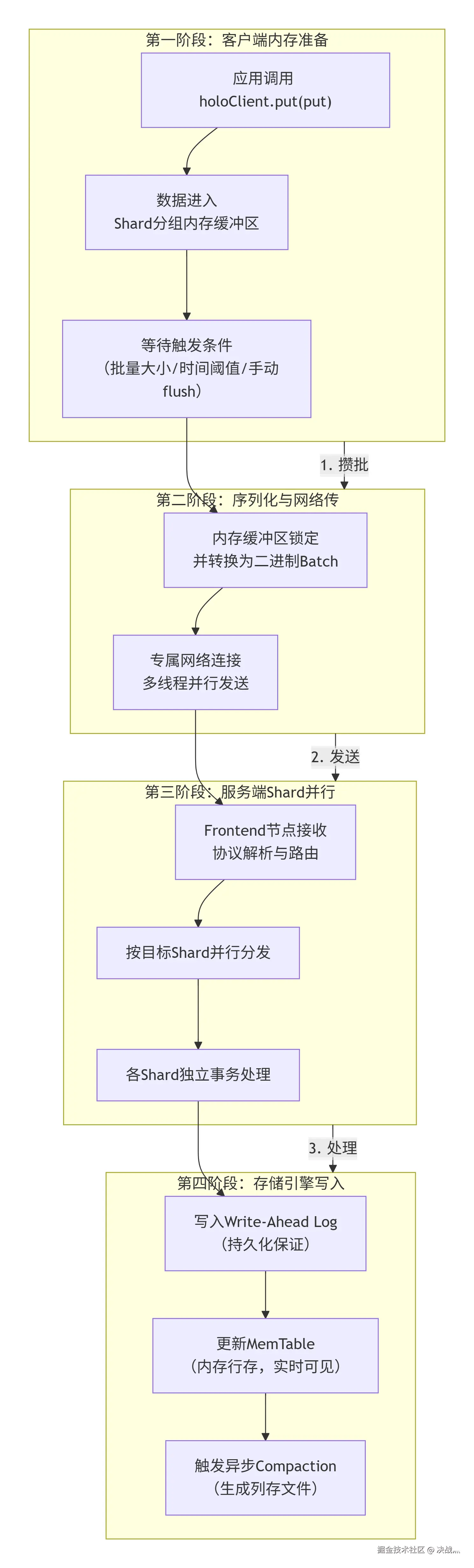
下面,我们来详解每个阶段的关键设计:
🔍 第一阶段:客户端内存准备与攒批
-
Shard分组缓冲区 :
HoloClient在内存中为每个目标表的每个Shard 维护了一个独立的缓冲区(RecordBuffer)。当你调用put(put)时,客户端会根据表的分布键(如主键)计算该行数据所属的Shard,并将其放入对应的缓冲区。 -
触发条件 :
flush()被调用时,会立即锁定 所有缓冲区,准备发送。此外,系统也会在以下条件满足时自动触发类似flush()的操作:- 批量大小 :单个缓冲区数据达到
writeBatchSize(默认256)。 - 数据体积 :缓冲区数据总字节数达到
writeBatchByteSize。 - 时间阈值 :距离上次发送间隔达到
writeMaxIntervalMs。
- 批量大小 :单个缓冲区数据达到
⚙️ 第二阶段:序列化与网络传输
- 高效序列化 :锁定的缓冲区数据会被高效地序列化成紧凑的二进制格式(如Protobuf)。与逐条发送SQL或JSON相比,这极大地减少了网络传输量。
- 多路复用与并行 :客户端会为每个目标Shard复用或创建独立的网络连接 ,并由专门的写入线程(
writeThreadSize控制)并行发送这些二进制Batch,充分利用网络带宽。
🚀 第三阶段:服务端Shard并行处理
- 前端路由 :Hologres的
Frontend节点接收请求后,会快速解析协议,并根据请求中的Shard信息,将Batch直接路由到对应的存储节点(Worker Node) 。 - 并行事务 :每个Shard的处理完全独立 。每个Shard收到自己的Batch后,会在一个轻量级的事务中处理这批数据。由于Shard间无锁,这是写入能线性扩展的关键。
💾 第四阶段:存储引擎写入与持久化
这是最核心的阶段,确保数据既快又稳:
- Write-Ahead Log :数据写入Shard后,首先被顺序、同步地追加 到该Shard的WAL中。WAL是预写式日志 ,写入操作一旦成功落盘,数据持久性就已得到保证,即使后续系统崩溃,也能从WAL恢复。这是
flush()操作原子性和持久性的基石。 - MemTable更新 :在WAL写入成功后,数据被应用到内存中的
MemTable。MemTable是一个行式存储 的数据结构,数据写入此处后,对读请求就立即可见。这也是Hologres写入低延迟的重要原因。 - 后台异步Compaction :当
MemTable增长到一定大小,它会被标记为只读(Immutable MemTable),并由后台线程异步地 与磁盘上的旧数据进行合并(Compaction),最终转换成高效的列式存储文件(SSTable) 。这个过程不影响前台写入的吞吐和延迟。
⚡ 性能关键总结
- 批处理:客户端攒批极大地减少了网络RPC和事务开销。
- Shard并行:数据分片实现了真正的并行写入,无共享资源竞争。
- 高效的二进制协议:紧凑的序列化节省了网络和解析成本。
- WAL + MemTable:顺序写WAL保证持久性,内存写MemTable保证低延迟可见。
- 读写分离的存储格式:行存优化写,列存优化读,后台转换互不干扰。
因此,当你调用 holoClient.flush() 时,你触发的是一台设计精密的"数据高速列车",它将离散的数据包在客户端打包成集装箱,通过多条并行轨道(Shard)高速运输,并在目的地(存储节点)经过一个高效的标准化入库流程(WAL -> MemTable),最终安全入库。理解了这一点,你就能更好地通过调整 writeBatchSize、writeThreadSize 等参数来优化你的写入吞吐和延迟。