Motus: A Unified Latent Action World Model
-
摘要
-
研究背景
-
现状: 目前的具身智能系统通常是由多个独立的模型拼凑而成的。
- 理解:用一个模型看懂环境(例如 VLM)。
- 世界模型:用另一个模型预测(如果我这样做,环境会变成什么样)。
- 控制:再用一个模型来输出具体的动作指令。
-
问题:这种碎片化方法有两个主要缺陷:
- 无法统一生成能力: 多模态(视觉、语言、动作)之间无法深度融合。
- 数据利用率低: 难以利用大规模的、异构的(来源不同的)数据进行联合学习。
-
-
核心方法:Motus
-
Motus 是一个 统一的潜在动作世界模型。它的目标是将上述所有功能(理解、生成、控制)整合进一个单一的系统中。
-
架构设计:MoT (Mixture-of-Transformer)
-
理解专家:负责感知环境。
-
视频生成专家:负责想象未来画面。
-
动作专家:负责决策和控制。
-
这种混合架构既保持了各领域的专业性,又实现了统一的计算流。
-
-
调度机制:UniDiffuser 风格
-
为了让这三个专家协同工作,Motus 采用了一种类似 UniDiffuser 的调度器,使Motus 可以根据任务需求灵活切换模式:
-
作为世界模型: 预测环境变化。
-
作为 VLA模型: 根据指令执行动作。
-
作为逆动力学模型: 观察前后状态,反推发生了什么动作。
-
作为视频生成器: 生成仿真视频。
-
视频-动作联合预测: 同时预测未来画面和动作。
-
-
-
关键创新点:实现高效训练
-
这是这篇论文最核心的技术突破,主要解决"动作数据稀缺"的问题。
-
利用光流学习潜在动作:
- 通常机器人训练需要真实的关节数据,这种数据很难获得。
- Motus 利用视频中的 光流(像素的移动轨迹)来代表动作。这意味着它利用了视频中丰富的运动信息。
- 意义: 这使得模型可以在没有具体机器人动作标签的大规模视频数据上进行预训练,极大地扩展了数据来源。
-
训练策略:
- 三阶段训练。
- 六层数据金字塔
-
-
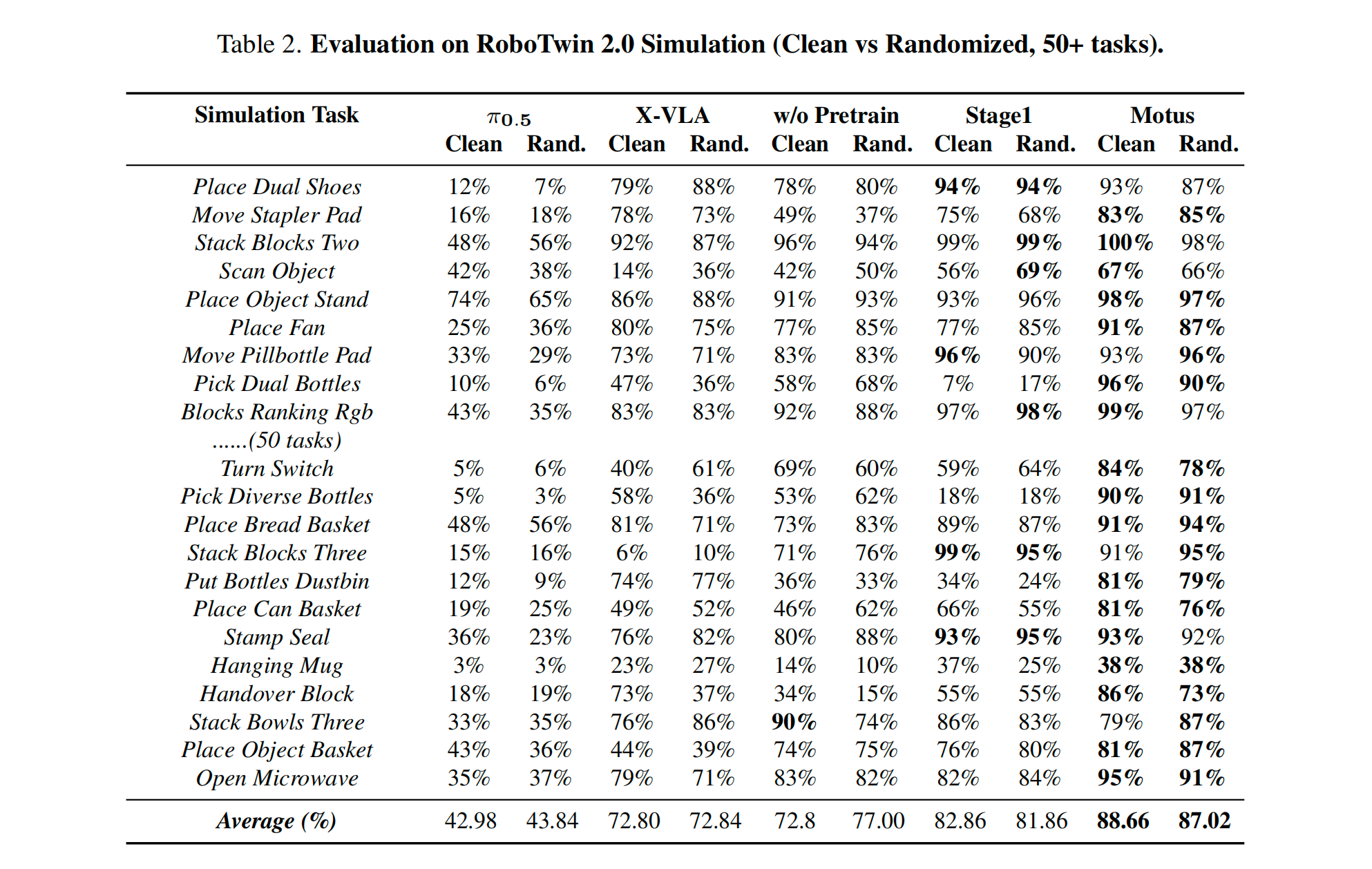
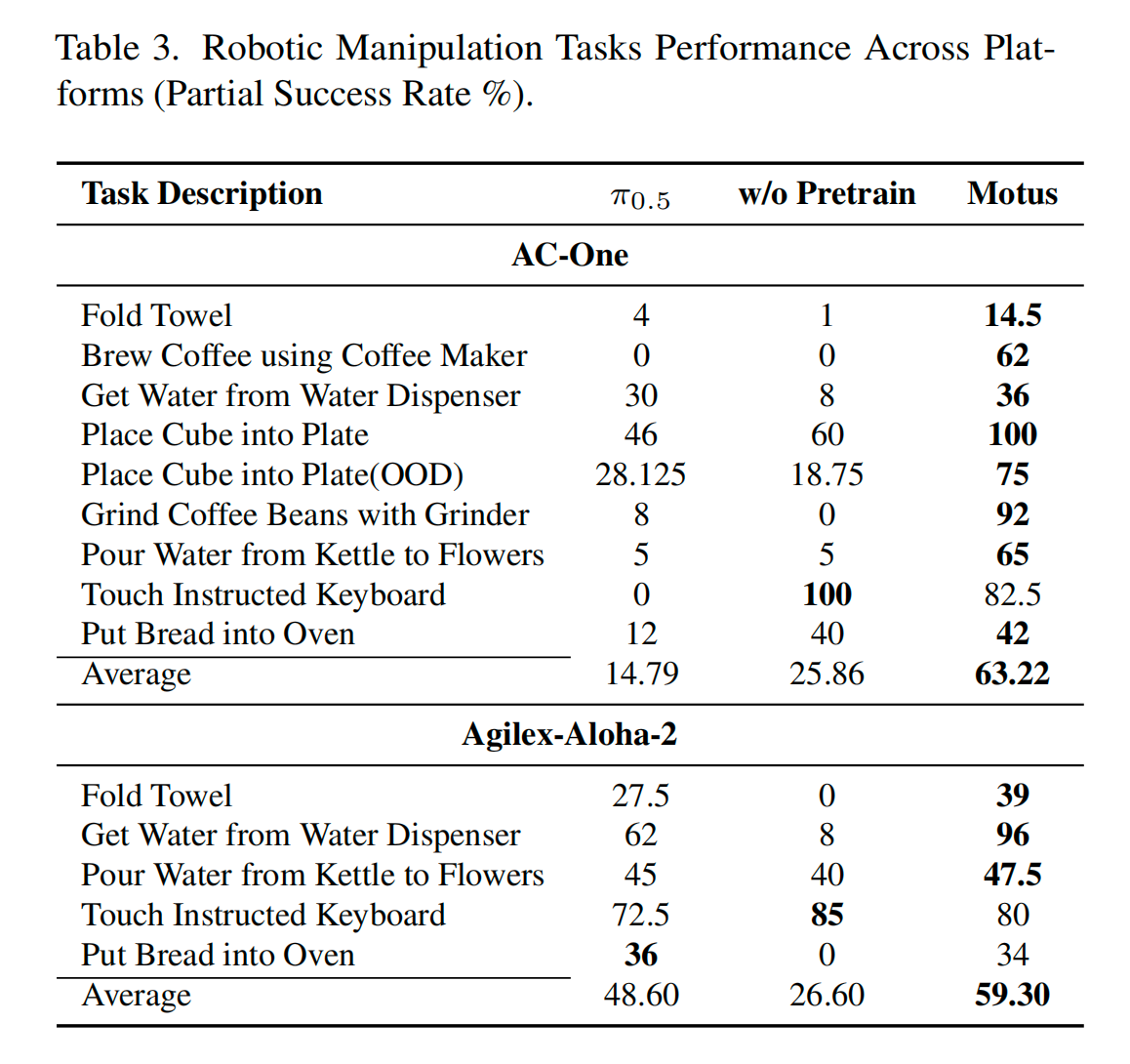
实验结果
-
仿真环境
- 比 X-VLA 提升了 15%。
- 比 π0\pi_0π0 (Pi-Zero,近期的一个强基线)提升了惊人的 45%。
-
真实世界
- 性能提升幅度在 11% ~ 48% 之间。
-
-
1. Introduction
-
现状与痛点
-
具身智能的终极目标是一个统一的系统。它不能只是看,也不能只是动,必须像人一样,把理解场景、想象未来、预测后果和执行动作结合在一起。
-
研究现状目前的模型是碎片化的:
- VLA (如 RT-2):也就是静态策略,只管"看到图 -> 输出动作",没有对未来的想象。
- World Models:只管"预测未来画面",不管怎么控制。
- F1 (近期工作):虽然结合了 VLA 和逆动力学,但缺了世界模型和视频生成,不算真正的统一。
-
作者将这种碎片化总结为 5 个独立的数学建模任务:
- VLA (策略): p(at+1:t+k∣ot,ℓ)p(a_{t+1:t+k} | o_t, \ell)p(at+1:t+k∣ot,ℓ)
- 输入:当前观测 oto_tot + 语言指令 ℓ\ellℓ;输出:未来动作 aaa。
- WM (世界模型): p(ot+1:t+k∣ot,at+1:t+k)p(o_{t+1:t+k} | o_t, a_{t+1:t+k})p(ot+1:t+k∣ot,at+1:t+k)
- 输入:当前观测 oto_tot + 动作 aaa;输出:未来观测 ooo(预测环境变化)。
- IDM (逆动力学): p(at+1:t+k∣ot:t+k)p(a_{t+1:t+k} | o_{t:t+k})p(at+1:t+k∣ot:t+k)
- 输入:一连串观测(视频);输出:这中间发生了什么动作 aaa。
- VGM (视频生成): p(ot+1:t+k∣ot,ℓ)p(o_{t+1:t+k} | o_t, \ell)p(ot+1:t+k∣ot,ℓ)
- 输入:当前图 + 指令;输出:未来视频(不基于具体动作,只基于指令)。
- Joint Prediction (联合预测): p(ot+1:t+k,at+1:t+k∣ot,ℓ)p(o_{t+1:t+k}, a_{t+1:t+k} | o_t, \ell)p(ot+1:t+k,at+1:t+k∣ot,ℓ)
- 同时预测未来画面和动作。
- VLA (策略): p(at+1:t+k∣ot,ℓ)p(a_{t+1:t+k} | o_t, \ell)p(at+1:t+k∣ot,ℓ)
-
核心痛点: 需要一个统一的模型能同时承担五个模型的功能
-
-
统一模型的两大挑战
-
难点一:架构与先验融合难。
- 如果从头训练一个大模型,它既没有 VLM 这种看过几亿张图的"理解能力",也没有视频生成模型那种懂物理规律的"生成能力"。
- 我们需要一种架构,能直接利用现有的、已经很强的预训练模型(专家),而不是重头练。
-
难点二:数据异构与动作缺失。
- 数据很多(互联网视频),但这些视频没有动作标签(没有记录机器人关节角度或手柄操作)。
- 不同机器人的身体构造(Embodiment)不同,动作空间不通用。
- 核心问题: 怎么利用海量的 YouTube 视频来训练一个控制机器人的模型?
-
-
Motus 的架构解决方案------The MoT Architecture
-
Motus 是一个基于 MoT 的架构。这不仅是 MoE,而是混合了不同模态的 Transformer 专家。
-
核心设计 1:三模态联合注意力(Tri-model Joint Attention)。
- 它把三个专家(视频生成、动作、视觉语言理解)通过共享的 Attention 层连起来。
- 视觉专家看到的特征,动作专家可以直接用;动作专家想干的事,视频专家可以直接生成对应后果。
-
核心设计 2:UniDiffuser 风格的调度器。
- UniDiffuser 是一种扩散模型策略,可以灵活决定先生成谁、后生成谁,或者一起生成。
- ++通过给视频和动作分配不同的噪声和时间步++ ,Motus 可以在推理时动态切换模式(比如这一步是 VLA,下一步是 World Model)。
-
-
数据与动作表征解决方案
-
核心创新:潜在动作(Latent Action)。
-
为了解决"视频没动作标签"的问题,作者用 光流 作为动作的替代品。
-
视频里像素的移动(光流)就是一种通用的"动作"。
- 不管是人手还是机械臂,向左移就是向左移。这被称为 Pixel-level "delta action"。
-
具体实现:
- 用一个 DC-AE(深度压缩自编码器) 把光流压缩成latent。
- 用少量的真实动作标签来监督这个 Latent,强迫模型关注那些"跟机器人操作有关的运动",忽略背景里的无关运动。
-
-
训练策略:
- 三阶段训练: 视频预训练 -> 潜在动作预训练 -> 特定机器人微调。
- 六层数据金字塔: 数据从最泛化的(网络视频)到最具体的(目标机器人数据)层层递进。
- 这使得模型先学会"什么是运动",再学会"什么是动作",最后学会"怎么控制这个机器人"。
-
-
贡献与实验
- 统一了 5 种主流范式(WM, IDM, VLA, VGM, Joint)。
- 提出了基于光流的可扩展训练策略。
- SOTA
- 仿真环境:比 X-VLA 强 15% ,比 π0\pi_0π0 强 45%
- 真机环境:提升 11%~48%。
2. Problem Formulation and Challenges
2.1 Embodied Policies
这部分定义了基本的符号和训练目标,标准的 Imitation Learning 设定。
-
任务场景: 语言条件下的机器人操控(听指令干活)。
-
核心变量:
- aaa: 动作。
- ooo: 视觉观测。
- ℓ\ellℓ: 语言指令。
- ppp: 本体感知(比如关节角度、末端位置)。
- 注意: 这里的 AAA(动作空间)和 OOO(观测空间)对于不同的机器人是不同的。
-
数据:Dexpert={ℓ,p1,o1,a1,...,pN,oN,aN}...D_{expert} = \{ \ell, p_1, o_1, a_1, ..., p_N, o_N, a_N \}...Dexpert={ℓ,p1,o1,a1,...,pN,oN,aN}...
-
典型的专家演示数据。包含 N 个时间步的轨迹。
-
Action Chunking (动作分块): 这是一个关键细节。模型不是预测 1 个动作,而是预测未来 kkk 个动作序列 (at+1:t+ka_{t+1:t+k}at+1:t+k)。这在 Diffusion Policy 和 ACT 等现代方法中很常见,能增加动作的连贯性。
maxθE(ot,pt,at+1:t+k,ℓ)∼Dexpertlogpθ(at+1:t+k∣ot,pt,ℓ) \max_{\theta} E_{(o_t, p_t, a_{t+1:t+k}, \ell) \sim D_{expert}} \log p_\theta(a_{t+1:t+k} | o_t, p_t, \ell) θmaxE(ot,pt,at+1:t+k,ℓ)∼Dexpertlogpθ(at+1:t+k∣ot,pt,ℓ)- 标准的 Behavior Cloning (BC) 损失函数。即最大化专家动作在给定状态下的对数概率。
-
核心:重新定义 5 种建模任务
-
VLA (策略): p(at+1:t+k∣ot,ℓ)p(a_{t+1:t+k} | o_t, \ell)p(at+1:t+k∣ot,ℓ)
- 看图听话 -> 做动作。
-
WM (世界模型): p(ot+1:t+k∣ot,at+1:t+k)p(o_{t+1:t+k} | o_t, a_{t+1:t+k})p(ot+1:t+k∣ot,at+1:t+k)
- 看图 + 知道要做什么动作 -> 预测未来画面。
-
IDM (逆动力学): p(at+1:t+k∣ot:t+k)p(a_{t+1:t+k} | o_{t:t+k})p(at+1:t+k∣ot:t+k)
- 看一连串视频 -> 反推中间做了什么动作。
-
VGM (视频生成): p(ot+1:t+k∣ot,ℓ)p(o_{t+1:t+k} | o_t, \ell)p(ot+1:t+k∣ot,ℓ)
- 看图听话 -> 想象未来视频 (不涉及具体动作控制)。
-
Joint Prediction (联合预测): p(ot+1:t+k,at+1:t+k∣ot,ℓ)p(o_{t+1:t+k}, a_{t+1:t+k} | o_t, \ell)p(ot+1:t+k,at+1:t+k∣ot,ℓ)
- 看图听话 -> 同时输出未来画面和动作。
-
2.2 统一多模态生成能力的挑战
-
研究目标: 打造一个像人一样的统一系统。
-
现状: 碎片化。
-
UWM分析: 之前的 UWM 虽然架构上统一了,但有两个致命伤:
- 从头训练:没有继承 VLM 的常识。
- 缺乏物理先验:没有继承视频生成模型对物理世界的理解。
-
Motus 的目标: 不仅要架构统一,还要把现有的 Pretrained Experts 的知识融合进来。
-
2.3 异构数据利用的挑战
-
问题: 数据很大,但很杂。
-
Cross-Embodiment Gap:
- 狗的动作是"四个关节角度",机械臂的动作是"末端坐标+夹爪开合"。
- 这两个数据在数学上完全不同,没法直接混在一起训练。
-
现有方法的局限: 以前的方法(如 OpenVLA, Octo)虽然能处理不同机器人,但前提是必须有动作标签
- 数据浪费: 互联网上有丰富的视频,里面包含了丰富的物理规律(杯子怎么掉下来、门怎么推开)。
- 核心矛盾: 这些视频没有 aaa (动作标签)。
- 后果: 传统的 VLA 模型看着这些视频干瞪眼,没法用它们来预训练"动作专家"。
- **Motus 的motivation:**提出 Latent Action------ 为了把无标签视频里的"运动线索"提取出来,当作通用的动作来训练。
3. Methodology
3.1 Motus
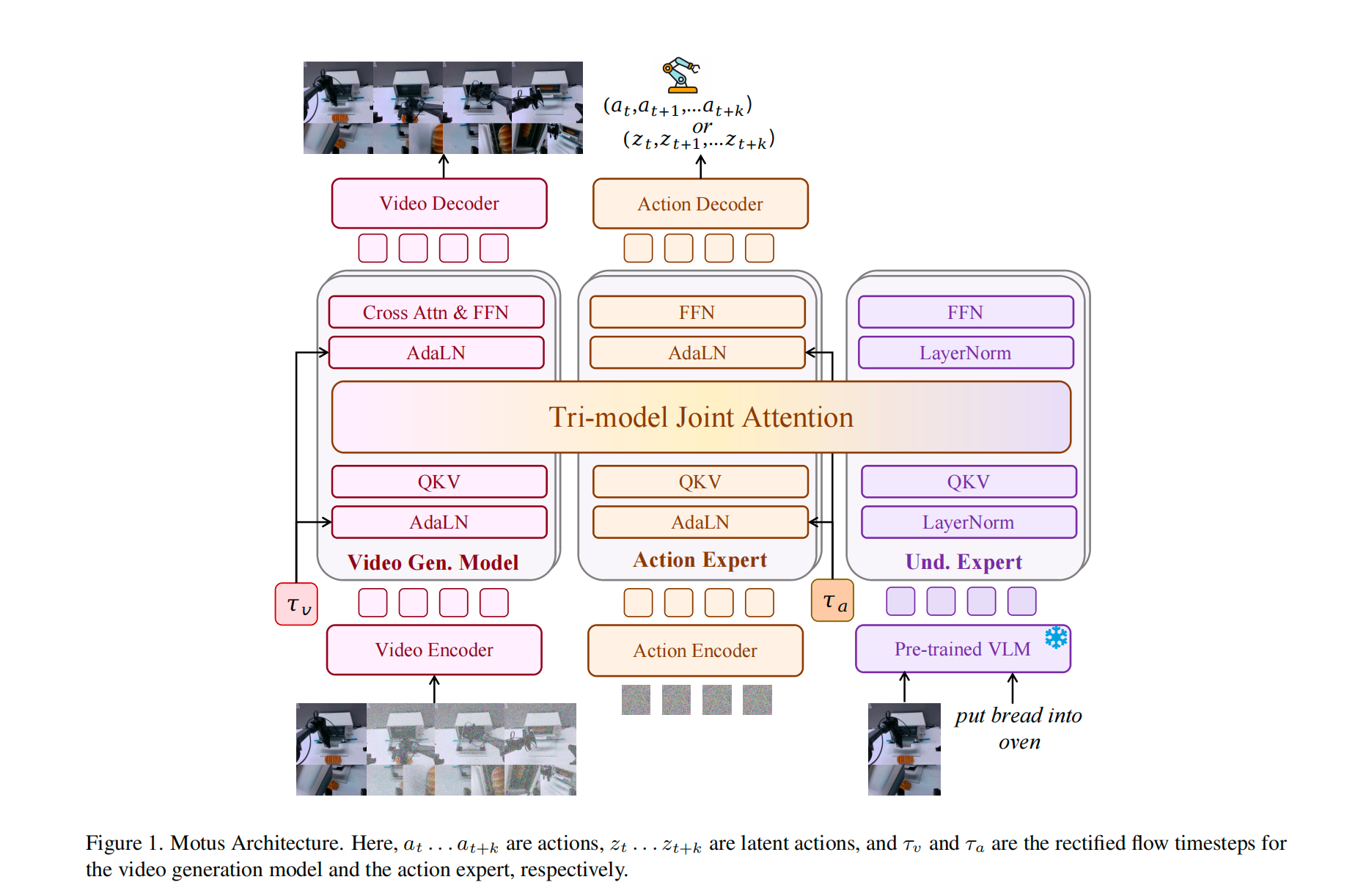
-
总体设计理念:利用已有专家的先验知识实现Unified
-
核心架构:MoT 与 Tri-model Joint Attention
-
MoT (Mixture-of-Transformers): 这是一个混合架构,包含三个"专家":
- VGM Expert: 视频生成专家(负责想画面)。
- VLM Expert: 理解专家(负责看图、读指令)。
- Action Expert: 动作专家(负责控制)。
-
优势: 这种设计不用从头训练,保留了各家的特长。
-
-
对比
- UWM:把图片 Token 和动作 Token 拼在一起,扔进同一个 Transformer 里硬算。
- Motus 的做法:更加精致。不仅区分专家,还采用了特殊的连接方式。
-
技术核心:Tri-model Joint Attention (三模态联合注意力)。
- 每个专家有自己的 FFN(前馈网络)和 LayerNorm。
- 在 Attention 层,它们是打通的。
- *动作专家在做决策时,可以通过 Attention 机制直接"查询"视频专家的画面预测和 VLM 的语义理解------Cross-modal feature fusion (跨模态特征融合)。
-
训练目标
lactionθ=E...∥vaθ−(ϵa−at+1:t+k)∥22lobsθ=E...∥voθ−(ϵo−ot+1:t+k)∥22lθ=lactionθ+lobsθ l^\theta_{action} = \mathbb{E}{\dots} \| v^\theta_a - (\epsilon_a - a{t+1:t+k}) \|^2_2\\ l^\theta_{obs} = \mathbb{E}{\dots} \| v^\theta_o - (\epsilon_o - o{t+1:t+k}) \|^2_2\\ l^\theta = l^\theta_{action} + l^\theta_{obs} lactionθ=E...∥vaθ−(ϵa−at+1:t+k)∥22lobsθ=E...∥voθ−(ϵo−ot+1:t+k)∥22lθ=lactionθ+lobsθ- 核心算法:Rectified Flow。 这是一种比传统 Diffusion Model 更快、更稳定的生成模型训练方法。
- Loss Function: 预测一个"速度场" vvv,让噪音 ϵ\epsilonϵ 能够顺滑地变成真实的动作 aaa 或观测 ooo。
- Joint Prediction: 动作的 Loss 和 观测(视频)的 Loss 是加在一起同时优化的。
-
UniDiffuser 调度器:
- 虽然是联合训练,但在推理时,你可以控制输入给视频和动作的 Timestep 和 Noise Scale。
- 举例:
- 如果你想做 VLA:给视频部分加满噪,只让动作部分去噪生成。
- 如果你想做 Video Generation:给动作部分加满噪,只让视频部分生成。
-
优化策略:Action-Dense Video-Sparse Prediction
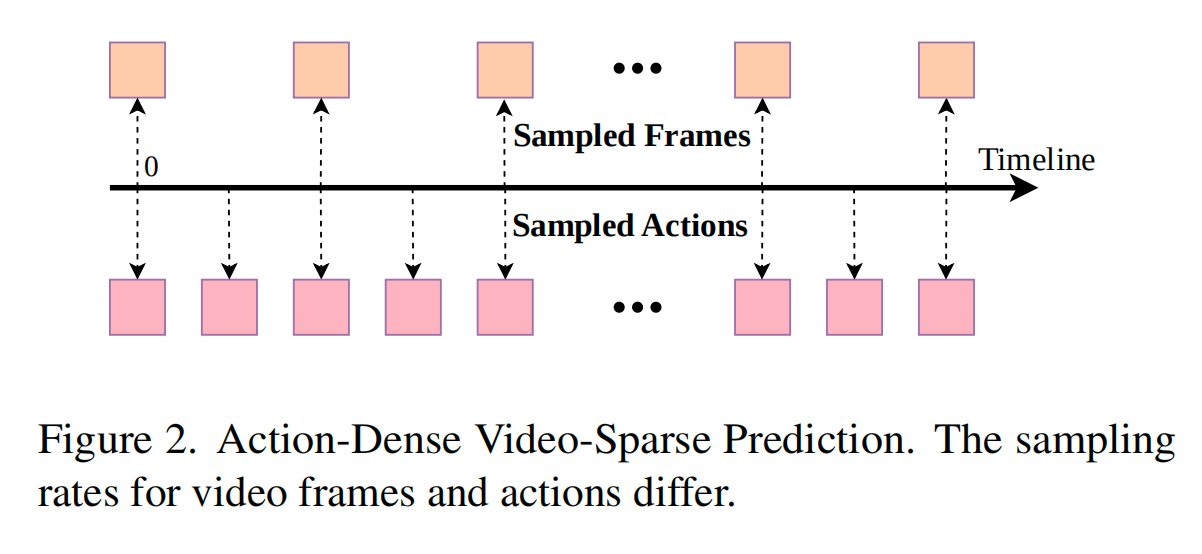
-
背景: 模型需要同时预测未来 kkk 步的动作和视频帧。
-
问题:Token 不平衡。
- 一张图片(即使压缩后)可能有几百个 Token。一段视频就是几千个。
- 而一个动作(关节角度向量)可能只有几十个 Token。
- 后果: Attention 机制会被海量的视频 Token 淹没,导致模型只顾着生成好看的视频,忽略了那一小撮动作 Token,导致控制变差。
-
解决方案:动作密、视频疏。
- 具体操作: 比如动作是 10Hz,视频就设成 2Hz。保持视频 Token 和动作 Token 的数量级大致平衡。
-
-
专家配置 (Experts Details)
- 视频生成: 使用了 Wan 2.2 5B(国内阿里的万相模型)
- 理解专家: 使用了 Qwen3-VL-2B(阿里的通义千问 VL)
- 动作专家: 自己搭了一个跟 Wan 层数一样的 Transformer。
3.2 Latent Actions

-
核心动机:用视觉动态替代真实动作
- 目标: 利用大规模异构数据
- 方法: 直接从视觉动态里学动作模式。
-
Latent Actions:作者定义了一种新的动作概念,它不是关节角度,而是从像素变化里提炼出来的。
- 数据源: 互联网视频、人类第一视角视频、不同机器人的轨迹。这些数据本来因为没标签是废的,现在都能用了。
-
技术实现:基于光流的表征
- pipeline:视频 -> 光流 -> 压缩 -> 低维向量 。
- 光流:本质上就是像素的位移场。
- 优势:它剥离了纹理、颜色、光照,只剩下"运动"。对于机器人来说,手向左移,无论穿什么颜色的袖子,光流都是向左的。这是跨域对齐的关键。
-
预处理: 使用现成的 DPFlow 算法把两帧视频算成光流图。
-
第一步压缩 (DC-AE):
-
输入:高维的光流图(比如 256x256)。
-
编码器:一个卷积 VAE。
-
中间产物:4 个 Token,每个 512 维(4×5124 \times 5124×512)。
-
目的: 提取视觉特征,去噪。
-
-
第二步压缩 (Lightweight Encoder):
- 输入:4×512=20484 \times 512 = 20484×512=2048 维特征。
- 输出:14 维向量 。
- 典型的双臂机器人通常是 7自由度 x 2 = 14,或者 6自由度 x 2 + 2夹爪 = 14。
- pipeline:视频 -> 光流 -> 压缩 -> 低维向量 。
-
训练与分布对齐
-
光把光流压成 14 维向量还不够,得保证这 14 个数像真正的机器人动作,而不是随机的噪声。
- 引入 AnyPos 数据: 这是一种"无脑乱动"的数据。
- 方法: 用仿真器随机采样机器人的动作空间,生成对应的画面。
- 作用: 这提供了"这是真的机器人动作"的基准锚点(Anchor)。
-
混合训练策略
- 90% 无标签数据(视频): 只能用来做重构任务。即:
- Encoder(Flow)→Latent→Decoder(Flow)Encoder(Flow) \rightarrow Latent \rightarrow Decoder(Flow)Encoder(Flow)→Latent→Decoder(Flow)。这让模型学会压缩光流。
- 10% 有标签数据(机器人数据): 既做重构,也做对齐 。即:Latent≈Real_ActionLatent \approx Real\_ActionLatent≈Real_Action。
- 90% 无标签数据(视频): 只能用来做重构任务。即:
-
核心逻辑:
- 90% 的数据教模型"如何提取运动特征"。
- 10% 的数据教模型"这些特征对应哪个关节"。
- 结果:模型学会了把视频里的运动翻译成关节动作。
-
-
损失函数
L=Lrecon+λa∣∣areal−apred∣∣2+βLKL L = L_{recon} + \lambda_a || a_{real} - a_{pred} ||^2 + \beta L_{KL} L=Lrecon+λa∣∣areal−apred∣∣2+βLKL- LreconL_{recon}Lrecon (重构损失): 保证 Latent 能还原回光流图。这是为了不丢失运动信息。
- ∣∣areal−apred∣∣2|| a_{real} - a_{pred} ||^2∣∣areal−apred∣∣2 (对齐损失): 保证 Latent 等于真实的动作 aaa。。
- LKLL_{KL}LKL (正则化): VAE的标准配置,防止 Latent 空间不连续。
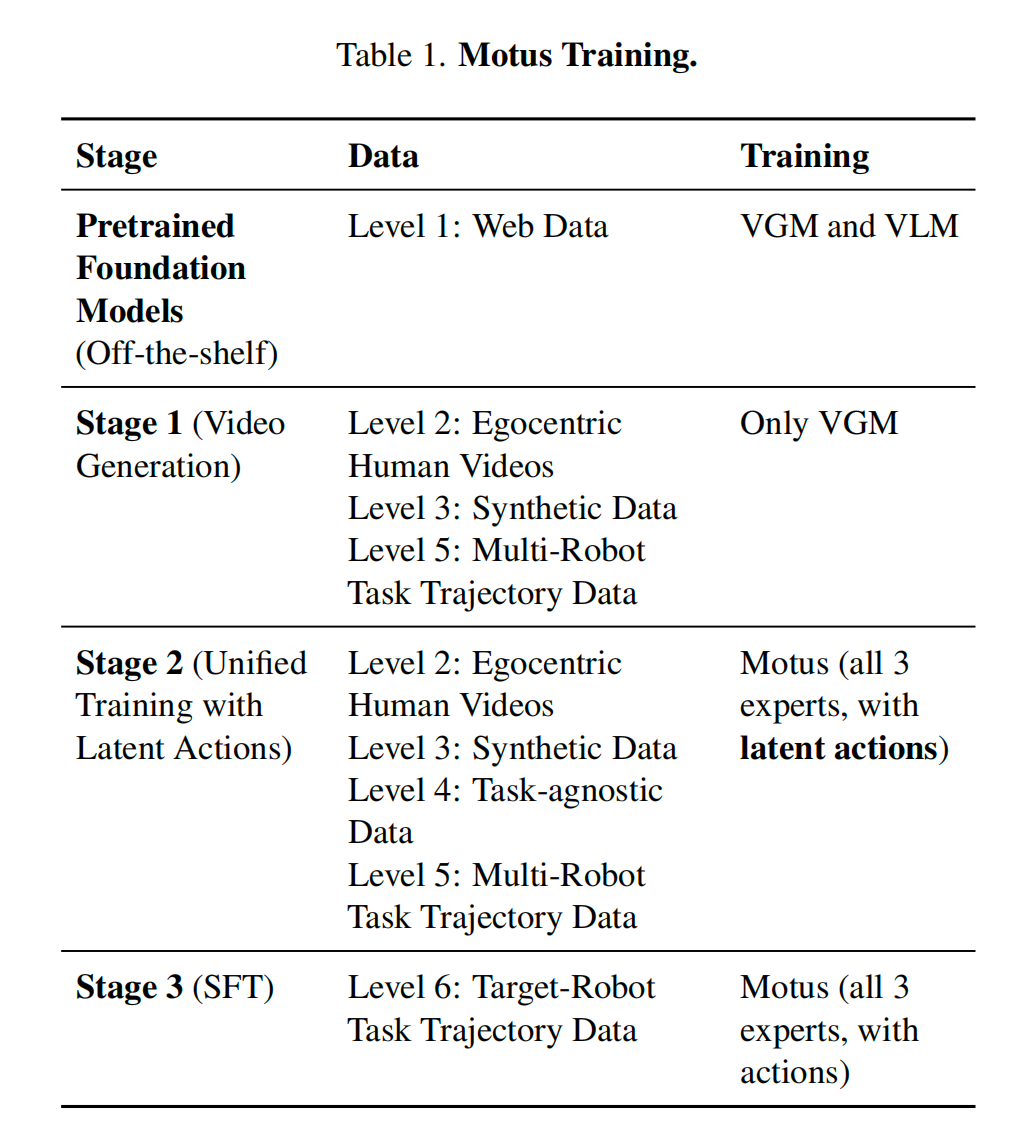
3.3 Model Training and Data
-
作者把训练分成了三个阶段,这是一个典型的 从通用到专用 的策略。
-
Stage 1: Learning Visual Dynamics
- 目标: 训练VGM。
- 任务: 视频生成。也就是给定一张图和一句话,预测未来会发生什么。
- 数据: 多种机器人的视频 + 人类视频。
- 关键点: 这一步不涉及动作控制。只是为了让模型学会物理常识。
-
Stage 2: Learning Action Representations
- 核心操作:
- VLM Frozen
- Latent Actions (潜在动作): 这里用到了 4.2 节提到的"光流转换出的 14 维向量"。
- 数据: 主要是无标签的视频。
- 逻辑: 模型看着视频,不仅要预测下一帧画面,还要预测那个 Latent Action。
- 核心操作:
-
Stage 3: Specializing for the Target Robot (针对目标机器人微调)
- 数据: 目标机器人的真实数据(包含真实的 aaa)。
- 逻辑: 之前模型学的是 Latent Action,现在要把它映射到 Real Action。因为模型已经懂得了动作的含义,所以这一步只需要少量数据微调即可。
-
-
Data
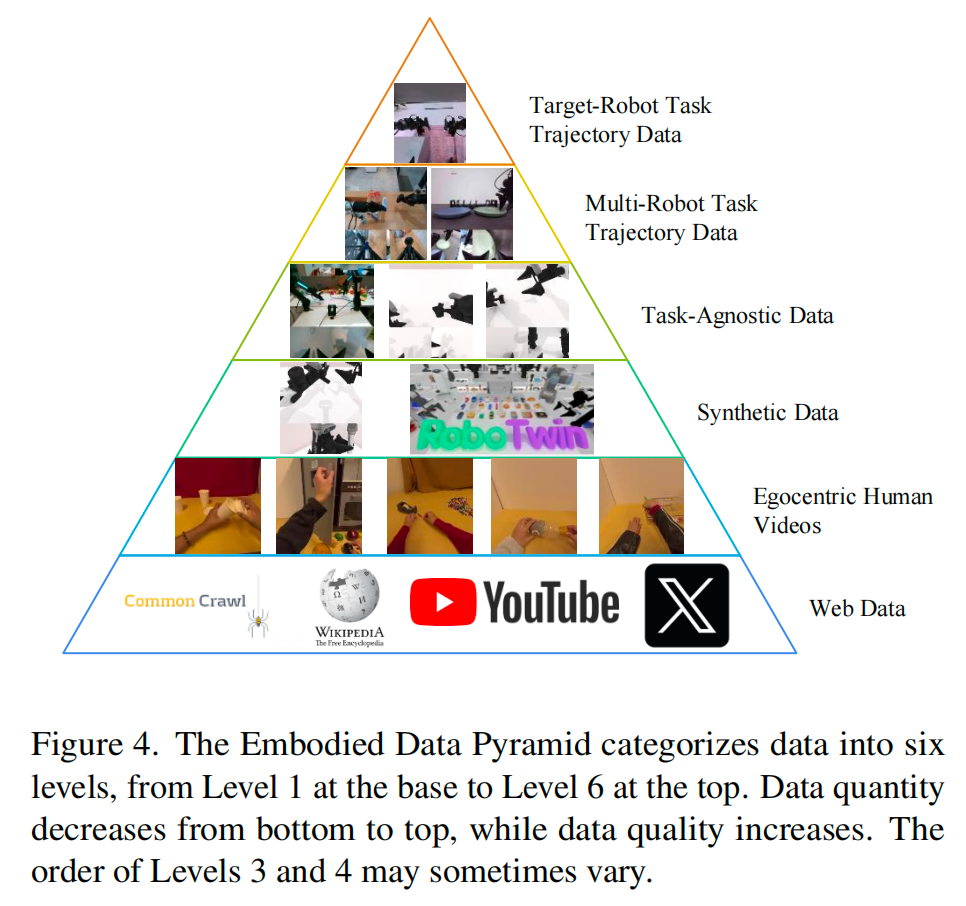
-
Language + Image + Action (L+I+A):
-
机器人轨迹数据(Robot Trajectories)。
-
特点: 质量最高,最直接,但最稀缺。这是传统 BC/RL 方法唯一能用的数据。
-
-
Language + Image (L+I):
-
视频序列或图文对。
-
特点: 数据量巨大,包含物理常识,但没有动作标签。
-
-
Image + Action (I+A):
-
任务无关的交互数据。
-
解释: 比如机器人瞎玩,或者是遥控车乱跑。有画面也有动作,但是没有语言指令告诉它在干嘛。
-
作用: 用来帮模型理解"动作 -> 画面变化"的因果关系。
-
-
Language-only (L-only):
-
纯文本(Textual corpora)。
-
作用: 提升 VLM 的语义理解能力。
-
-
4. Experiment