Docker核心技术和实现原理第一部分-Docker镜像制作
- 一.镜像制作原因及方式
- 二.dockerfile制作镜像
-
- 2.1dockerfile的作用与基本写法规范
- 2.2为什么需要dockerfile
- 2.3dockerfile指令
-
- [Dockerfile 指令参考表](#Dockerfile 指令参考表)
- FROM
- MAINTAINER(已经废弃被LABEL替代)
- LABEL
- COPY
- ENV
- WORKDIR
- ADD
- RUN
- CMD
- 使用上述指令从nginx源码编译到制作镜像
- EXPOSE
- ENTRYPOINT
- ARG
- VOLUME
- USER
- HEALTHCHECK
- ONBUILD
- STOPSIGNAL
- [2.4制作命令docker build](#2.4制作命令docker build)
- 2.5dockerfile编写规范
- 三.综合实际案例
-
- 3.1通过实例来区别CMD与ENTRYPOINT
- 3.2使用dockerignore忽略冗余文件
- 3.3多阶段构建
- [3.4dockerfile结合docker compose实现mysql数据库主从同步](#3.4dockerfile结合docker compose实现mysql数据库主从同步)
-
- [docker compose build命令](#docker compose build命令)
- 什么是mysql主从同步
-
- 主从同步的主要目的:
- 主从同步架构图
- 什么是binlog
- 主从同步的方式
- [MySQL 主从形式](#MySQL 主从形式)
- 进行mysql主从同步的搭建
- [3.5dockerfile结合docker compose构建 Redis 集群](#3.5dockerfile结合docker compose构建 Redis 集群)
- 补充:自主实践案例:dockerfile结合dockercompose搭建C++微服务
- 补充:常见问题陈述
一.镜像制作原因及方式
镜像制作是因为某种需求,官方的镜像无法满足需求,需要我们通过一定手段来自定
义镜像来满足要求。
制作镜像往往因为以下原因
- 编写的代码如何打包到镜像中直接跟随镜像发布
- 第三方制作的内容安全性未知,如含有安全漏洞
- 特定的需求或者功能无法满足,如需要给数据库添加审计功能
- 公司内部要求基于公司内部的系统制作镜像,如公司内部要求使用自己的操作系统作为基础镜像
制作容器镜像,主要有两种方法:
- 制作快照方式获得镜像(偶尔制作的镜像):在基础镜像上(比如 Ubuntu),先登录容器中,然后安装镜像需要的所有软件,最后整体制作快照。(这个我们前面也使用过commit命令演示过)
- Dockerfile 方式构建镜像(经常更新的镜像):将软件安装的流程写成 Dockerfile,使用 docker build 构建成容器镜像。
为什么要认识使用dockerfile 制作镜像呢,因为快照方式制作镜像会造成以下几个问题:
-
缺乏可重复性
构建过程依赖容器的实时状态。
无法保证在不同环境或时间构建出完全一致的镜像。
每次构建都可能因为基础镜像更新、网络状态等因素产生差异。
-
构建过程不透明
无法追溯镜像是如何构建的。
缺少清晰的变更历史记录。
团队成员难以理解镜像包含的内容和步骤。
-
不可审计
没有明确的构建指令记录。
难以审查安全实践(如下载来源、用户权限设置等)。
不符合DevOps和CI/CD的最佳实践。
-
镜像臃肿
容易将不必要的中间文件、缓存等打包进镜像。
缺少分层优化的机会。
无法利用Docker的构建缓存机制。
-
维护困难
无法轻松修改或更新特定步骤。
需要重新运行整个容器并提交,而不是只修改特定指令。
难以创建基础镜像的变体。
-
版本控制不友好
Dockerfile是文本文件,适合Git等版本控制系统。
快照方式生成的镜像二进制文件难以进行版本差异比较。
-
安全问题
可能意外包含敏感信息(如密钥、密码)。
缺乏清晰的构建步骤来验证安全实践。
难以实施安全扫描和合规检查。
所以下面我们就来认识下使用dockerfile制作镜像的方式。
二.dockerfile制作镜像
2.1dockerfile的作用与基本写法规范
镜像的定制实际上就是定制每一层所添加的配置、文件 。如果我们可以把每一层修改、安装、构建、操作的命令都写入一个脚本,用这个脚本 来构建、定制镜像,这个脚本就是 Dockerfile。
Dockerfile 是一个文本文件,其内包含了一条条的指令(Instruction), 每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。
dockerfile中的命令格式如下:
bash
# Comment
INSTRUCTION arguments该指令不区分大小写。然而,约定是它们是大写的 ,以便更容易 地将它们与参数区分
开来。Docker 按顺序运行指令 Dockerfile。
Docker 将以开头的行视为#注释,行中其他任何地方的标记#都被视为参数。这允许像这样的语句:
bash
# Comment
RUN echo 'we are running some # of cool things'2.2为什么需要dockerfile
- 可以按照需求自定义镜像
和 docker commit 一样能够自定义镜像,官方的镜像可以说很少能直接满足我们应用的,都需要我们自己打包自己的代码进去然后做成对应的应用镜像对外使用。 - 很方便的自动化构建,重复执行
通过 dockerfile 可以自动化的完成镜像构建,而不是像 docker commit 一样,手动一个命令一个命令执行,而且可以重复执行, docker commit 的话很容易忘记执行了哪个命令,哪个命令没有执行。 - 维护修改方便,不再是黑箱操作
使用 docker commit 意味着所有对镜像的操作都是黑箱操作,生成的镜像也被称为黑箱镜像,dockerfile 很容易二次开发。 - 更加标准化,体积可以做的更小
docker 容器启动后,系统运行会生成很多运行时的文件,如果使用 commit 会导致这些文件也存储到镜像里面,而且 commit 的时候安装了很多的依赖文件,没有有效的清理机制的话会导致镜像非常的臃肿。使用 Dockerfile 则会更加标准化,而且提供多级构建,将编译和构建分开,不会有运行时的多余文件,更加的标准化。
2.3dockerfile指令
Dockerfile 指令参考表
| 指令 | 功能 | 备注 |
|---|---|---|
| FROM | 构建镜像基于哪个镜像(基础镜像) | 必须掌握 |
| RUN | 指定 docker build 过程中运行的程序 | 必须掌握 |
| COPY | 拷贝文件或目录到镜像中,不具备自动下载或解压功能 | 必须掌握 |
| ADD | 拷贝文件或目录到镜像中,支持 URL 自动下载和压缩包自动解压 | 必须掌握 |
| WORKDIR | 指定工作目录(后续命令的当前目录) | 必须掌握 |
| ENV | 设置环境变量 | 必须掌握 |
| CMD | 运行容器时执行的命令(可被覆盖) | 必须掌握 |
| ENTRYPOINT | 运行容器时的程序入口(不易被覆盖) | 必须掌握 |
| LABEL | 为镜像添加元数据(如作者、版本等) | 已替代 MAINTAINER |
| VOLUME | 指定容器挂载点(数据卷) | |
| EXPOSE | 声明容器的服务端口(仅是声明) | |
| ARG | 指定构建时的参数(构建期间有效) | |
| USER | 指定运行命令的用户身份 | |
| HEALTHCHECK | 容器健康检查指令 | |
| MAINTAINER | 镜像维护者姓名或邮箱地址 | 已废弃(使用 LABEL 替代) |
| ONBUILD | 当前镜像作为基础镜像时触发的指令 | 使用较少 |
| SHELL | 指定 RUN、CMD、ENTRYPOINT 使用的 shell | 使用较少 |
| STOPSIGNAL | 覆盖发送到容器的默认停止信号 | 使用较少 |
下面我们来一个一个认识这些指令:
FROM
功能
- FROM 指令用于为镜像文件构建过程指定基础镜像,后续的指令运行于此基础镜像所提供的运行环境;
注意事项 - FROM 指令必须是 Dockerfile 中非注释行或者 ARG 之后的第一个指令;
- 实践中,基准镜像可以是任何可用镜像文件 ,默认情况下 , docker build 会在docker 主机上查找指定的镜像文件,在其不存在时 ,则会自动从 Docker 的公共库 pull 镜像下来。如果找不到指定的镜像文件, docker build 会返回一个错误信息;
- FROM 可以在一个 Dockerfile 中出现多次,如果有需求在一个 Dockerfile 中创建多个镜像,或将一个构建阶段作为另一个的依赖。
- 如果 FROM 语句没有指定镜像标签 ,则默认使用 latest 标签。
语法
bash
FROM [--platform=<platform>] <image> [AS <name>]
FROM [--platform=<platform>] <image>[:<tag>] [AS <name>]
FROM [--platform=<platform>] <image>[@<digest>] [AS <name>]参数
- :构建的 cpu 架构,如 linux/amd64, linux/arm64,windows/amd64
- :指定作为 base image 的名称;
- : base image 的标签,省略时默认 latest;
- :是镜像的哈希码;
- AS : 指定构建步骤的名称,配合 COPY --from=可以完成多级构建
我们先来写一个简单的dockerfile,仅仅只使用FROM:
bash
#dockerfile
FROM nginx:1.29.4这里我们先介绍下docker build命令,一般我们使用时是这样用的:
bash
docker build -t 目标镜像名称:tag标签 上下文所在目录也就是说如果我们的dockerfile在当前目录下,我想使用此文件创建一个名为mytest,标签为v1.0的镜像可以这么用:
bash
docker build -t mytest:v1.0 .先认识这么多,我们下面会在细说这个docker build命令。
现在我们把上面的dockerfile示例喂给docker build看看效果:
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker build -t mynginx:v0.1 .
...
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker images
mynginx:v0.1 3855365a2781 225MB 59.8MB 可以看到我们的镜像已经做出来了。如果我们想要制作一个别的系统的镜像直接加上platform即可,大家可以自己尝试下,做好之后如果想以此镜像为容器运行会报错,因为平台不同。
MAINTAINER(已经废弃被LABEL替代)
功能
- 用于让 dockerfile 制作者提供本人的详细信息
- 该功能已经废弃,由 label 替代
语法
bash
MAINTAINER <authtor's detail>参数
- <authtor's detail>:作者信息
因为已经废弃了,所以我们这里就只做一个简单的演示:
bash
FROM nginx:1.29.4
MAINTAINER "knd <knd@25.com>"当我们查看此dockerfile做出来的镜像时会发现有作者与邮箱的信息:
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker inspect mynginx:v1.1
...
"Author": "\"knd <knd@25.com>\"",
...LABEL
功能
为镜像添加元数据,元数据是 kv 对形式
语法
bash
LABEL <key>=<value> <key>=<value> <key>=<value>这其实就是我们之前提到过的镜像中的元数据,我们截取上面inspect中的label看下:
bash
Labels": {
"maintainer": "NGINX Docker Maintainers <docker-maint@nginx.com>"
},那么我们以这种方式来向镜像中添加作者及作者信息看看:
bash
#dockerfile
FROM nginx:1.29.4
LABEL auther="knd" email="knd@example.com"可以看到被成功添加进去了:
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker inspect mnginx:1.0
...
"Labels": {
"auther": "knd",
"email": "knd@example.com",
"maintainer": "NGINX Docker Maintainers <docker-maint@nginx.com>"
},
...COPY
功能
用于从 docker 主机复制新文件或者目录至创建的新镜像指定路径中 。
语法
bash
COPY [--chown=<user>:<group>] <src>... <dest>
COPY [--chown=<user>:<group>] ["<src>",... "<dest>"]参数
<src>:要复制的源文件或目录, 支持使用通配符;<dest>:目标路径,即正在创建的 image 的文件系统路径; 建议<dest>使用绝对路径,否则, COPY 指定以 WORKDIR 为当前路径在路径中有空白字符时,通常使用第 2 种格式;- --chown:修改用户和组
- --from
<name>可选项 :
可以从之前构建的步骤中拷贝内容,结合 FROM ... AS 往往用作多级构建,后面我们有具体的案例。
注意事项
<src>必须是 build 上下文中的路径, 不能是其父目录中的文件;- 如果
<src>是目录,则其内部文件或子目录会被递归复制 ,但<src>目录自身不会被复制; - 如果指定了多个
<src>,或在<src>中使用了通配符,则<dest>必须是一个目录,且必须以 / 结尾; - 如果
<dest>事先不存在,它将会被自动创建,这包括父目录路径。
这里就使用COPY来向ubuntu:24.04的源镜像内拷贝进去个文件看看,注意这里我们用一个镜像本身并没有的目录:
bash
#dockerfile
FROM ubuntu:24.04
COPY ./dockerfile /data/knd/tar/dockerfile可以在新镜像制作的容器内确切的看到我们拷贝进去的文件:
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker run -it --rm mubuntu:1.0 cat /data/knd/tar/dockerfile
#dockerfile
FROM ubuntu:24.04
COPY ./dockerfile /data/knd/tar/dockerfile当然如果你加上了--chown,就是将此拷贝的文件归属于某个组的某个用户,如果不加上,默认此拷贝的文件用户与组均为root。
ENV
功能
- 用于为镜像定义所需的环境变量,并可被 Dockerfile 文件中位于其后的其它指令 (如 ENV、 ADD、 COPY 等)所调用
- 调用格式 为
$variable_name 或 ${variable_name}
语法
bash
ENV <key>=<value> ...我们这里可以试试用ENV同时为LABEL提供键值对参数和设置镜像内部的环境变量:
bash
#dockerfile
FROM ubuntu:24.04
ENV AUTHOR="knd" EMAIL="knd@example.com"
LABEL author=${AUTHOR} email=${EMAIL}可以看到label信息成功设置,环境变量也被成功设置:
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker inspect mubuntu:1.0
...
"Labels": {
"author": "knd",
"email": "knd@example.com",
"org.opencontainers.image.ref.name": "ubuntu",
"org.opencontainers.image.version": "24.04"
}
...
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker run -it --rm mubuntu:1.0 bash
root@faeed64dd6b3:/# env | grep AUTHOR
AUTHOR=knd
root@faeed64dd6b3:/# env | grep EMAIL
EMAIL=knd@example.comWORKDIR
功能
为 Dockerfile 中所有的 RUN、 CMD、 ENTRYPOINT、 COPY 和 ADD 指定设定工作目录
语法
bash
WORKDIR /path/to/workdir注意事项
- 默认的工作目录是/
- 如果提供了相对路径,它将相对于前一条 WORKDIR 指令的路径。
- WORKDIR 指令可以解析先前使用设置的环境变量 ENV
我们来做个样例:
bash
#dockerfile
FROM ubuntu:24.04
ENV APP_HOME=/app
WORKDIR ${APP_HOME}
COPY ./dockerfile ./dockerfile可以看到,当我们执行bash进入容器时,发现初始所处的路径即为我们刚刚workdir指定的路径,同时,在指定了工作路径后,当我们后面使用了相对路径时它也会自动解析。
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker run -it --rm mub:1.0 bash
root@64d8e960c8d2:/app# ls
dockerfileADD
功能
ADD 指令类似于 COPY 指令, ADD 支持使用 TAR 文件和 URL 路径,会自动完成解压和下载
语法
bash
ADD [--chown=<user>:<group>] <src>... <dest>
ADD [--chown=<user>:<group>] ["<src>",... "<dest>"]参数
<src>:要复制的源文件或目录, 支持使用通配符;<dest>:目标路径,即正在创建的 image 的文件系统路径; 建议<dest>使用绝对路径,否则, ADD 指定以 WORKDIR 为其实路径;在路径中有空白字符时,通常使用第 2 种格式;- --chown:修改用户和组
它的功能和COPY是类似的,但不同的是,如果你给我的是一个tar包 ,那么我添加进去之后会自动对其进行解压 ,比如我们从nginx官网下载它的1.29.4源码包:
https://nginx.org/download/nginx-1.29.4.tar.gz
bash
knd@NightCode:~/dockertest/dockerfile_test$ wget https://nginx.org/download/nginx-1.29.4.tar.gz
...
knd@NightCode:~/dockertest/dockerfile_test$ ls
dockerfile nginx-1.29.4.tar.gz然后我们编写dockerfile:
bash
#dockerfile
FROM ubuntu:24.04
WORKDIR /web
ADD ./nginx-1.29.4.tar.gz /web/可以看到它已经被解压了:
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker run -it mub:1.0 bash
root@02aa9854e99a:/web# ls
nginx-1.29.4但是如果我们直接给它一个url ,它会把文件下到指定目录下,如果是tar包它不会进行解压:
bash
#dockerfile
FROM ubuntu:24.04
WORKDIR /web
ADD https://nginx.org/download/nginx-1.29.4.tar.gz /web/当然此过程因为它要下载,会build的时间稍微长些:
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker run -it --rm mub:1.0 bash
root@bca256bcd71b:/web# ls
nginx-1.29.4.tar.gz可以看到它并没有对下载下来的文件进行解压。
RUN
功能
用于指定 docker build 过程中运行的程序,其可以是任何命令
语法
bash
#shell form
RUN <command>
#exec form
RUN ["executable", "param1", "param2"]参数
第一种格式中 , <command>通常是一个 shell 命令, 且以/bin/sh -c来运行它,Windows 默认为 cmd /S /C。如果一个脚本 test.sh 不能自己执行,必须要/bin/sh -c test.sh 的方式来执行,那么,如果使用 RUN 的 shell 形式,最后得到的命令相当于:
bash
/bin/sh -c "/bin/sh -c 'test.sh'"第二种语法格式 中的参数是一个 JSON 格式的数组 ,其中<executable>为要运行的命令,后面的 <paramN>为传递给命令的选项或参数;然而,此种格式指定的命令不会以/bin/sh -c来发起,因此常见的 shell 操作如变量替换以及通配符(?,*等)替换将不会进行;不过,如果要运行的命令依赖于此 shell 特性的话,可以将其替换为类似下面的格式。
bash
RUN ["/bin/bash", "-c", "<executable>","<param1>"]我们来看下这两种使用方式的区别:
bash
#dockerfile
FROM ubuntu:24.04
WORKDIR /web
RUN ls -l
RUN ["/bin/bash", "-c", "echo 'hello world'"]当你不加"/bin/bash", "-c"对于第二种方式是错误的:
bash
=> ERROR [4/4] RUN ["echo 'hello world'"] 0.2s
------
> [4/4] RUN ["echo 'hello world'"]:
0.156 runc run failed: unable to start container process: error during container init: exec: "echo 'hello world'": executable file not found in $PATH这里我们加上一个选项能看到build过程中终端打印出来的信息:
bash
docker build --progress=plain -t myimage .可以看到如下结果:
bash
#6 [3/4] RUN ls -l
#6 CACHED
#7 [4/4] RUN ["/bin/bash", "-c", "echo 'hello world'"]
#7 0.135 hello world
#7 DONE 0.1sCMD
功能
- 类似于 RUN 指令, CMD 指令也可用于运行任何命令或应用程序,不过,二者的运行时间点不同
- RUN 指令运行于映像文件构建过程中 ,而 CMD 指令运行于基于 Dockerfile构建出的新映像文件启动一个容器时 ○ CMD 指令的首要目的 在于为启动的容器指定默认要运行的程序 ,且其运行结束后,容器也将终止 ;不过, CMD 指定的命令其可以被 docker run 的命令行选项所覆盖
- 在 Dockerfile 中可以存在多个 CMD 指令,但仅最后一个会生效
语法
bash
CMD ["executable","param1","param2"] (exec form, this is thepreferred form)
CMD ["param1","param2"] (as default parameters to ENTRYPOINT)
CMD command param1 param2 (shell form)注意事项
- 第二种则用于为 ENTRYPOINT 指令提供默认参数,也是官方推荐的使用方式
- json 数组中,要使用双引号,单引号会出错
使用上述指令从nginx源码编译到制作镜像
说了这么多,我们来个较为综合的例子。首先我们的源代码已经拉取下来了,就是刚刚的tar包,然后我们参照nginx在github提供的构建提示来进行源码编译指令的编写:
首先是设置基准镜像,工作目录以及添加源码文件:
bash
#dockerfile
FROM ubuntu:24.04
ENV WEBDIR="/web"
WORKDIR ${WEBDIR}
ADD ./nginx-1.29.4.tar.gz ${WEBDIR}然后我们来看看官方提示的构建步骤:
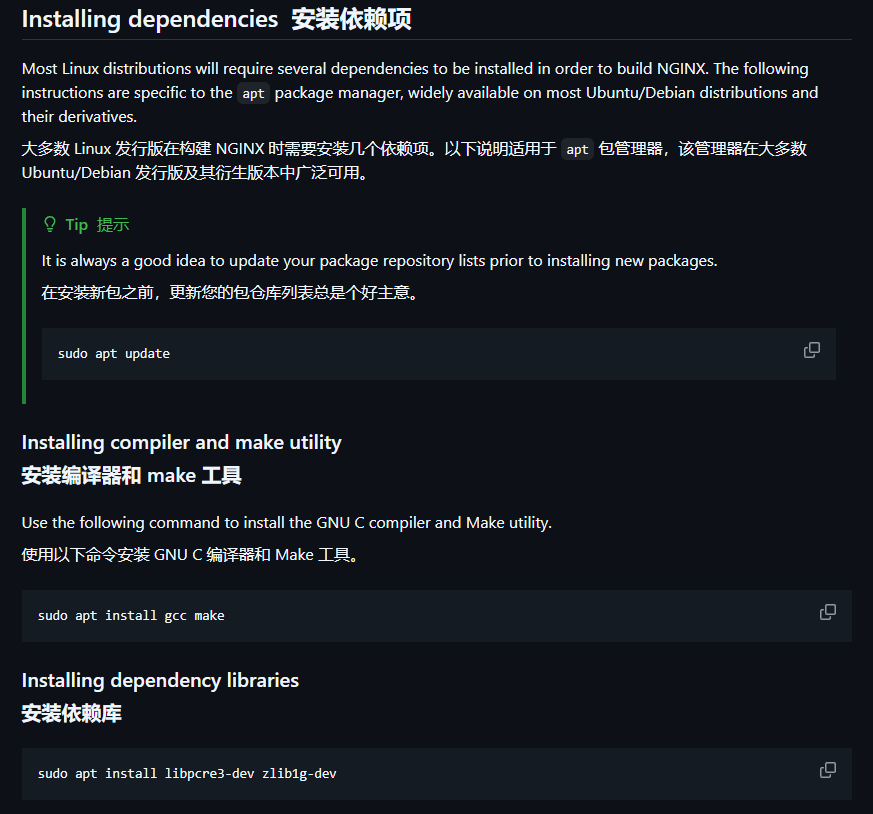
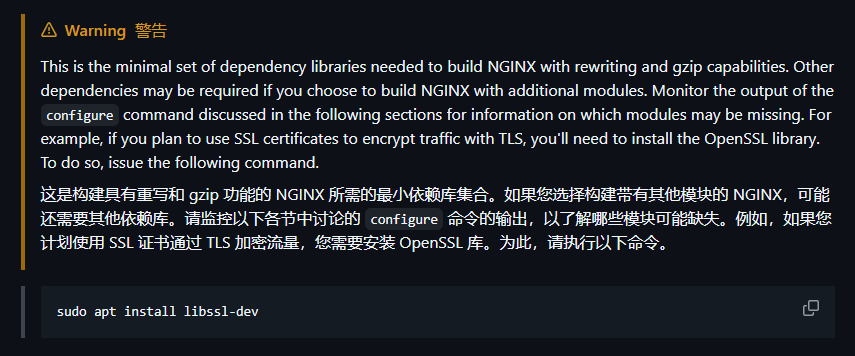
我们按照图中给的步骤添加相关RUN命令,因为我这里使用的是国内服务器,所以我们最好是再配置一个加速,记得install后面加上个-y标识不确认,否则会报错:
bash
# 更换apt源为中科大
RUN sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list && \
apt update && \
apt install -y gcc make && \
apt install -y libpcre3-dev zlib1g-dev libssl-dev然后让我们再来看看文档:
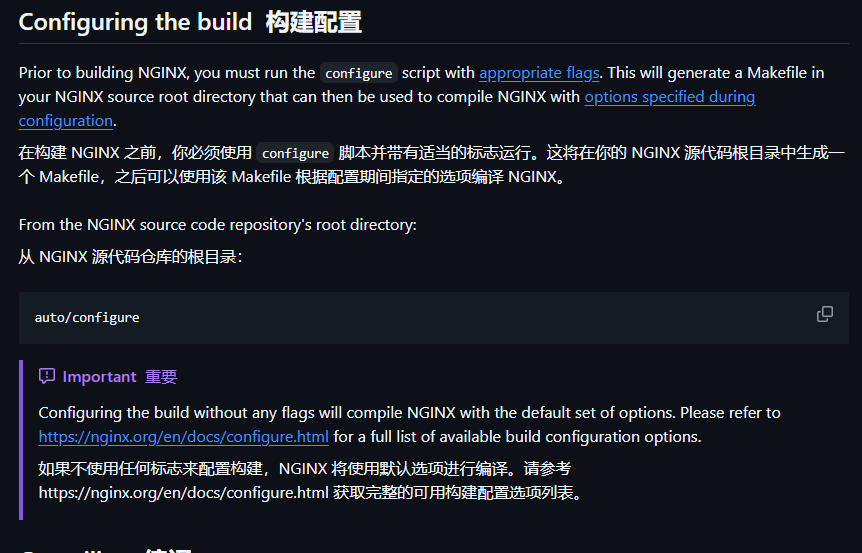
这里需要进行下配置,如果想要详细更改配置的读者可以到下面的网站进行查阅:
nginx配置文档
这里我们就只修改下它的首页所在目录了,它的tar包的conf目录下有个名为nginx.conf的文件:
找到这部分:
bash
location / {
root html;
index index.html index.htm;
}把root部分修正为我们想要它首页默认的存放目录,我这里就给它换成/web/nginxhtml了:
bash
location / {
root /web/nginxhtml/;
index index.html index.htm;
}然后把此文件也放到dokcerfile同目录下。加上这么一条指令:
bash
COPY ./nginx.conf ${WEBDIR}/nginx-1.29.4/conf/nginx.conf这样做也是为了替换它默认的配置文件。
接着往下看官方文档:

所以我们需要天加如下指令:
bash
RUN cd ${WEBDIR}/nginx-1.29.4/ && \
./configure && \
make && \
make install第一个是让配置文件生效,上上幅图中已经体现,下面两条是编译并安装nginx。到这里编译源码的部分已经结束,我们先让它运行构建出镜像来。构建镜像完毕之后我们在那里找到可运行的nginx二进制文件呢?
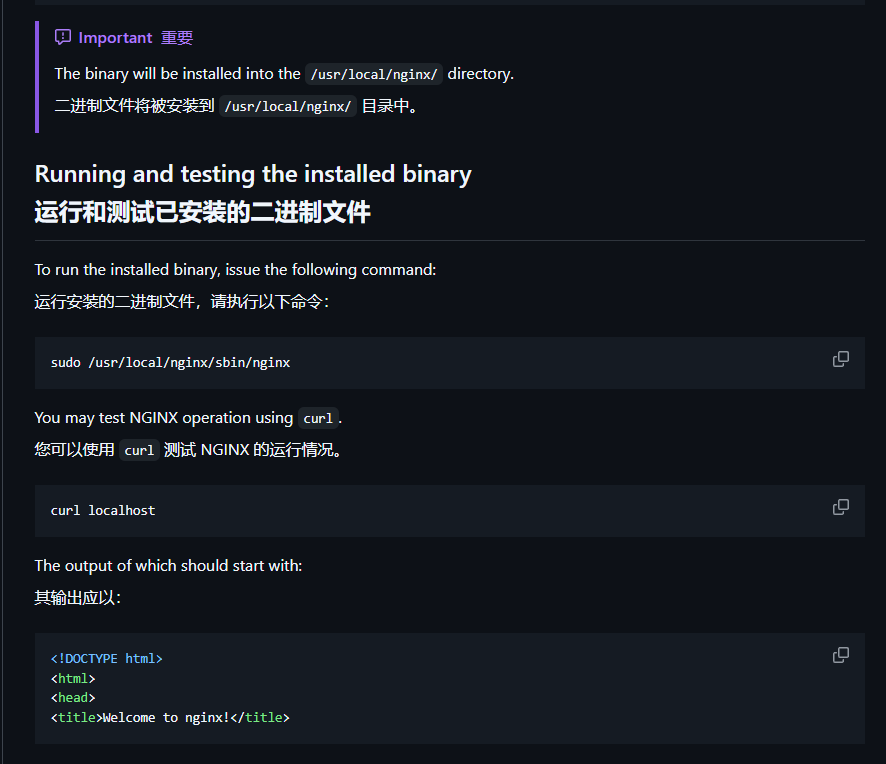
所以,为了接下来能够让镜像启动时自动执行nginx的启动命令,我们还需要加上一句CMD指令:
bash
CMD ["/usr/local/nginx/sbin/nginx", "-g", "daemon off;"]完整的dockerfile如下:
bash
#dockerfile
FROM ubuntu:24.04
ENV WEBDIR="/web"
WORKDIR ${WEBDIR}
ADD ./nginx-1.29.4.tar.gz ${WEBDIR}
# 更换apt源为中科大
RUN sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list && \
apt update && \
apt install -y gcc make && \
apt install -y libpcre3-dev zlib1g-dev libssl-dev
COPY ./nginx.conf ${WEBDIR}/nginx-1.29.4/conf/
COPY ./index.html ${WEBDIR}/nginxhtml/
RUN cd ${WEBDIR}/nginx-1.29.4/ && \
./configure --prefix=/usr/local/nginx && \
make && \
make install
CMD ["/usr/local/nginx/sbin/nginx", "-g", "daemon off;"]接下来我们等待一会让其构建出镜像然后我们运行下跑下试试(注意配置文件的拷贝放到RUN .configure之后,否则nginx找不到首页会爆404):
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker run -d --name nginx -p 8080:80 mynginx:1.0
774e375396626ececb8d4871334c7bed36991966cf217606d5f109c3f52edc3c成功跑起来了,我们访问下试试:
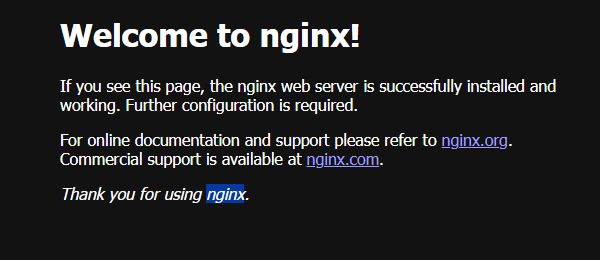
我们通过源码编译的nginx服务成功运行!
EXPOSE
功能
- 用于为容器声明打开指定要监听的端口以实现与外部通信
- 该 EXPOSE 指令实际上并不发布端口。它充当构建图像的人和运行容器的人之间的一种文档,关于要发布哪些端口。要在运行容器时实际发布端口,使用-p 参数发布和映射一个或多个端口,或者使用-Pflag 发布所有暴露的端口并将它们映射宿主机端口。
语法
bash
EXPOSE <port> [<port>/<protocol>...]参数
<protocol>: tcp/udp 协议<port>:端口
我们以上面的案例为例子,上面我们通过源码编译整出来的镜像,因为没有加expose,它相比官方镜像实例化的容器有些许区别当我们不指定端口映射时:
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker run -d --name mynginx mynginx:1.0
da58386413e762dc69530467e2f385b5d086fb98095c922b80480ded5c1205cb
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker run -d --name officalnginx nginx:1.29.4
e13249749da5be757ac9479fced5de60592368bfec13802b88990b08b73f397f
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e13249749da5 nginx:1.29.4 "/docker-entrypoint...." 3 seconds ago Up 3 seconds 80/tcp officalnginx
da58386413e7 mynginx:1.0 "/usr/local/nginx/sb..." 54 seconds ago Up 54 seconds mynginx可以看到我们的ports位置是没东西的。但我们上面的dockerfile加上EXPOSE 80/tcp就能达到和官方镜像一样的效果了:
bash
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
823535baf958 mynginx:1.1 "/usr/local/nginx/sb..." 4 seconds ago Up 4 seconds 80/tcp mynginx1
e13249749da5 nginx:1.29.4 "/docker-entrypoint...." 2 minutes ago Up 2 minutes 80/tcp officalnginxENTRYPOINT
功能
用于指定容器的启动入口
语法
bash
#exec from
ENTRYPOINT ["executable", "param1", "param2"]
#shell form
ENTRYPOINT command param1 param2参数
- json 数组中,要使用双引号,单引号会出错
这里可以把ENTRYPOINT与上面的CMD进行下替换,构建出来的镜像效果是一模一样的。不过ENTRYPOINT并不只有这些作用,它是和CMD搭配使用的,通常CMD作为参数传入ENTRYPOINT,这个下面综合案例中我们会有体现。
ARG
功能
ARG 指令类似 ENV,定义了一个变量;区别于 ENV:用户可以在构建时docker build --build-arg <varname> = <value> 进行对变量的修改; ENV 不可以;
- 如果用户指定了未在 Dockerfile 中定义的构建参数,那么构建输出警告。
语法
bash
ARG <name>[=<default value>]注意事项
- Dockerfile 可以包含一个或多个 ARG 指令
- ARG 支持指定默认值
- 使用范围:定义之后才能使用,定义之前为空 ,如下面的案例,执行命令
docker build --build-arg username=what_user.第二行计算结果为some_user ,不是我们指定的 build-arg 中的参数值 what_user
bash
FROM busybox
USER ${username:-some_user}
ARG username
USER $username
# ...- ENV 和 ARG 同时存在, ENV 会覆盖 ARG
bash
FROM ubuntu
ARG CONT_IMG_VER
ENV CONT_IMG_VER=v1.0.0
RUN echo $CONT_IMG_VER执行下面指令输出 v1.0.0
bash
docker build --build-arg CONT_IMG_VER=v2.0.1 .我们可以优化写法为
bash
FROM ubuntu
ARG CONT_IMG_VER
ENV CONT_IMG_VER=${CONT_IMG_VER:-v1.0.0}
RUN echo $CONT_IMG_VER- 系统内置了一些 ARG 变量
▪ HTTP_PROXY
▪ http_proxy
▪ HTTPS_PROXY
▪ https_proxy
▪ FTP_PROXY
▪ ftp_proxy
▪ NO_PROXY
▪ no_proxy
▪ ALL_PROXY
▪ all_proxy
这里我感觉吧,虽然ENV具有ARG的功能,但是它如果用了是会被设置到镜像的环境变量里面的,有的时候使用不好反而会污染镜像的环境变量,而ARG与ENV配合使用就可以解决这个问题。
VOLUME
功能
- 用于在 image 中创建一个挂载点目录
- 通过 VOLUME 指令创建的挂载点,无法指定主机上对应的目录,是自动生成的。
语法
bash
VOLUME <mountpoint>
VOLUME ["<mountpoint>"]参数
- mountpoint:挂载点目录
注意事项
▪ 如果挂载点目录路径下此前有文件存在 , docker run 命令会在卷挂载完成后将此前的所有文件复到新挂载的卷中
▪ 其实 VOLUME 指令只是起到了声明了容器中的目录作为匿名卷 ,但是并没有将匿名卷绑定到宿主机指定目录的功能。
▪ volume 只是指定了一个目录,用以在用户忘记启动时指定-v 参数也可以保证容器的正常运行。比如 mysql,你不能说用户启动时没有指定-v,然后删了容器,就把 mysql 的数据文件都删了,那样生产上是会出大事故的,所以 mysql 的 dockerfile 里面就需要配置 volume,这样即使用户没有指定-v,容器被删后也不会导致数据文件都不在了。还是可以恢复的。
▪ volume 与-v 指令一样,容器被删除以后映射在主机上的文件不会被删除。
▪ 如果-v 和 volume 指定了同一个位置,会以-v 设定的目录为准 ,其实volume 指令的设定的目的就是为了避免用户忘记指定-v 的时候导致的数据丢失,那么如果用户指定了-v,自然而然就不需要 volume 指定的位置了。
本质上就是容器run命令那里的-v但是无法指定卷名称。也就是说它创建的存储卷是管理卷中的匿名卷,主要是为了防止使用镜像的用户粗心存在的,这里就不再演示了,大家可以自行进行尝试。
SHELL
功能
- SHELL 指令允许覆盖用于 shell 命令形式的默认 shell。
- Linux 上的默认 shell 是"/bin/sh", "-c",在 Windows 上是"cmd", "/S","/C"
- SHELL 指令必须以 JSON 格式写入 Dockerfile。
语法
bash
SHELL ["executable", "parameters"]参数
- executable: shell 可执行文件的位置
- parameters: shell 执行的参数
- 注意事项
▪ SHELL 指令可以多次出现。
▪ 每个 SHELL 指令都会覆盖所有先前的 SHELL 指令,并影响所有后续指令。
▪ 该 SHELL 指令在 Windows 上特别有用,因为 windows 行有两种不同的shell: cmd 和 powershell
这个如果在linux上使用,主要是sh与bash的切换,我们看下面一个例子:
bash
# 使用默认 /bin/sh (dash)
RUN [ -f /etc/passwd ] && [ -r /etc/passwd ] && echo "文件可读"
# 使用 /bin/bash (更简洁)
SHELL ["/bin/bash", "-c"]
RUN [[ -f /etc/passwd && -r /etc/passwd ]] && echo "文件可读"| Shell | 特点 | Docker 中的影响 |
|---|---|---|
| /bin/sh (dash) | POSIX 兼容,轻量快速 | 默认,功能有限 |
| /bin/bash | 功能丰富,扩展多 | 支持数组、正则等 |
| /bin/zsh | 交互式功能强 | 高级补全、主题 |
这个我们就不深入了,有兴趣的读者可自行进行了解。
USER
功能
- 用于指定运行 image 时的或运行 Dockerfile 中任何 RUN、 CMD 或ENTRYPOINT 指令定的程序时的用户名或 UID
- 默认情况下, container 的运行身份为 root 用户
语法
bash
USER <user>[:<group>]
USER <UID>[:<GID>]参数
- user:用户
- group:用户组
- uid:用户 id
- gid:组 id
注意事项
<UID>可以为任意数字,但实践中其必须为/etc/passwd 中某用户的有效UID,否则将运行失败
- user 用于指定后续命令的运行用户,通常我们的程序建议不要直接用 root 用户操作
- 我们创建一个目录
bash
mkdir -p /data/myworkdir/dockerfile/user- 创建 Dockerfile,添加以下内容
bash
FROM ubuntu:22.04 as buildbase
RUN groupadd nginx
RUN useradd nginx -g nginx
USER nginx:nginx
RUN whoami > /tmp/user1.txt
USER root:root
RUN groupadd mysql
RUN useradd mysql -g mysql
USER mysql:mysql
RUN whoami > /tmp/user2.txt- 执行编译
bash
docker build -t user:v0.1 .- 运行查看我们的用户
bash
root@139-159-150-152:/data/myworkdir/dockerfile/user# docker run -
-name user1 --rm -it user:v0.1 cat /tmp/user1.txt /tmp/user2.txt
nginx
mysqlHEALTHCHECK
功能
- HEALTHCHECK 指令告诉 Docker 如何测试容器以检查它是否仍在工作。
- 即使服务器进程仍在运行,这也可以检测出陷入无限循环且无法处理新连接的 Web 服务器等情况。
语法
bash
HEALTHCHECK [OPTIONS] CMD command (check container health byrunning a command inside the container)
HEALTHCHECK NONE (disable any healthcheck inherited from the base image)参数
- OPTIONS 选项有:
▪ --interval=DURATION (default: 30s):每隔多长时间探测一次,默认 30秒
▪-- timeout= DURATION (default: 30s):服务响应超时时长,默认 30 秒
▪ --start-period= DURATION (default: 0s):服务启动多久后开始探测,默认 0 秒
▪ --retries=N (default: 3):认为检测失败几次为宕机,默认 3 次 - 返回值
▪ 0:容器成功是健康的,随时可以使用
▪ 1:不健康的容器无法正常工作
▪ 2:保留不使用此退出代码
我们来为我们前面的那个大实操在给他添加一个健康检查:
bash
HEALTHCHECK --interval=30s --timeout=30s --start-period=5s --retries=3 CMD [ "curl", "127.0.0.1:80" ] || exit 1看下效果:
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e0969e06095a mynginx:1.3 "/usr/local/nginx/sb..." 46 seconds ago Up 46 seconds (health: starting) 0.0.0.0:8080->80/tcp, [::]:8080->80/tcp nginx
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e0969e06095a mynginx:1.3 "/usr/local/nginx/sb..." About a minute ago Up About a minute (unhealthy) 0.0.0.0:8080->80/tcp, [::]:8080->80/tcp nginx唉,怎么能不健康呢?哦,CMD使用方式出错了,应该是这样,但是我的ubuntu镜像中还没有curl命令,我还要给他安装一个,你们要是有了就不用第一条指令的添加了:
bash
RUN apt install -y curl
HEALTHCHECK --interval=30s --timeout=30s --start-period=5s --retries=3 CMD curl -f http://localhost/ || exit 1我们在来看看:
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a72af7ff6bf5 mynginx:1.5 "/usr/local/nginx/sb..." 4 seconds ago Up 3 seconds (health: starting) 0.0.0.0:8080->80/tcp, [::]:8080->80/tcp nginx
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a72af7ff6bf5 mynginx:1.5 "/usr/local/nginx/sb..." 7 seconds ago Up 7 seconds (healthy) 0.0.0.0:8080->80/tcp, [::]:8080->80/tcp nginx现在它显示我们的nginx服务是健康的了。
ONBUILD
功能
- 用于在 Dockerfile 中定义一个触发器
- 以该 Dockerfile 中的作为基础镜像由 FROM 指令在 build 过程中被执行时,将会"触发"创建其 base image 的 Dockerfile 文件中的 ONBUILD 指令定义的触发器
语法
bash
ONBUILD <INSTRUCTION>参数
- INSTRUCTION: dockerfile 的一条指令
比如我们这里在原来的dockerfile中添加一个RUN echo "hello world"
bash
ONBUILD RUN echo "hello world"当我们以此dockerfile构建出来一个镜像时,使用下面命令构建看不到输出helloworld:
bash
sudo docker build -t --progress=plain mynginx:1.6 .但是如果我现在有这样一个dockerfile:
bash
FROM mynginx:1.6
RUN echo "1145141919180"我也加上--progress选项去看,它会触发上面打印hello world命令,打印出hello world:
bash
#4 [1/2] FROM docker.io/library/mynginx:1.6@sha256:8ab4ef44f25ab1c3cc5c214aa91f7d3f1c79868e869861d9eed98b78520aa39f
#4 resolve docker.io/library/mynginx:1.6@sha256:8ab4ef44f25ab1c3cc5c214aa91f7d3f1c79868e869861d9eed98b78520aa39f 0.0s done
#4 DONE 0.0s
#5 [2/3] ONBUILD RUN echo "hello world"
#5 0.158 hello world
#5 DONE 0.2s
#6 [3/3] RUN echo "1145141919180"
#6 0.166 1145141919180
#6 DONE 0.2sSTOPSIGNAL
功能
- STOPSIGNAL 指令设置将发送到容器的系统调用信号。
- 此信号可以是与内核的系统调用表中的位置匹配的有效无符号数,例如 9,或者 SIGNAME 格式的信号名,例如 SIGKILL。
语法
bash
STOPSIGNAL signal参数
STOPSIGNAL 指令设置将发送到容器出口的系统调用信号。 此信号可以是与内核的系统调用表中的位置匹配的有效无符号数,例如 9,或者 SIGNAME 格式的信号名,例如 SIGKILL。常见的信号如下:
| 代号 | 名称 | 内容 | 快捷键 |
|---|---|---|---|
| 1 | SIGHUP | 启动被终止的程序,可让该进程重新读取自己的配置文件,类似重新启动。 | - |
| 2 | SIGINT | 中断一个程序的进行。 | [Ctrl] + C |
| 9 | SIGKILL | 强制中断一个程序的进行。如果该程序进行到一半,那么尚未完成的部分可能会有"半产品"产生(如 vim 的 .filename.swp 文件保留下来)。 |
- |
| 15 | SIGTERM | 以正常的方式来终止该程序。由于是正常的终止,所以后续的动作会将他完成。不过,如果该程序已经发生问题,就是无法使用正常的方法终止时,输入这个信号也是没有用的。 | - |
| 19 | SIGSTOP | 暂停一个程序的进行。 | [Ctrl] + Z |
说白了,平时我们stop容器时不是默认向容器发送一个15信号吗,如果我们想要改变用户执行stop命令时不发送15号终止信号而是发送其他的停止信号,那就可以使用STOPSIGNAL指令进行改变。
但是,需要注意的是,docker stop 命令会先发送 STOPSIGNAL 指定的信号,然后等待一段时间,如果容器没有停止,还是会发送 SIGKILL 信号。这个行为没有改变,只是改变了第一个信号 。
比较简单,我们就不再进行演示了。
2.4制作命令docker build
docker build
功能
docker build 命令用于使用 Dockerfile 创建镜像。
语法
bash
docker build [OPTIONS] PATH | URL | -关键参数
- --build-arg=\[\] :设置镜像创建时的变量;举例
docker build --build-arg username=what_user - -f :指定要使用的 Dockerfile 路径;
- --label=\[\] :设置镜像使用的元数据;
- --no-cache :创建镜像的过程不使用缓存;
- --pull :尝试去更新镜像的新版本;
- --quiet, -q :安静模式,成功后只输出镜像 ID;
- --tag, -t: 镜像的名字及标签,通常 name:tag 或者 name 格式;可以在一次构建中为一个镜像设置多个标签。
- --network: 默认 default。在构建期间设置 RUN 指令的网络模式
我们先来看下语法中后面的PATH | URL | -,注意这三者存在一个即可,第一个我们前面也说过了,是指定构建的上下文路径。第二个URL主要是当我们的dockerfile不在本地的时候用的:
bash
# Git 仓库
docker build -t myapp https://github.com/user/repo.git
# 指定分支
docker build -t myapp https://github.com/user/repo.git#develop
# 指定子目录
docker build -t myapp https://github.com/user/repo.git#branch:subdir
# 私有仓库(需要认证)
docker build -t myapp https://username:password@github.com/user/repo.git第三个标准输入- 主要用于以下场景:
bash
# 从文件读取 Dockerfile
docker build -t myapp - < Dockerfile
# 通过管道传递
cat Dockerfile | docker build -t myapp -
# 使用 heredoc
docker build -t myapp - <<EOF
FROM ubuntu:22.04
RUN apt update && apt install -y curl
EOF
# 结合 curl 从网络获取 Dockerfile
curl -s https://raw.githubusercontent.com/user/repo/main/Dockerfile | \
docker build -t myapp -注意这是一个三选一 的互斥关系,不能同时提供多个构建上下文源。
我们在来说build的参数选项,其他选项就不多说了,我们主要来说下--no-cache,--pull,--network这几个选项,先从--pull说起,简单来说,即使你本地有我的基准镜像,但我加上--pull表明我不管你有没有,我都会从远端拉取基准镜像,我们系统上已经有nginx:1.29.4了,但是以下面这段dockerfile构建镜像:
bash
FROM nginx:1.29.4以下面的命令去构建
bash
sudo docker build --pull -t officallnginx:1.29.4 .
[+] Building 15.6s (5/5) FINISHED docker:default
=> [internal] load build definition from dockerfile 0.0s
=> => transferring dockerfile: 55B 0.0s
=> [internal] load metadata for docker.io/library/nginx:1.29.4 2.3s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [1/1] FROM docker.io/library/nginx:1.29.4@sha256:ca871a86d45a3ec6864dc45f014b11fe626145569ef0e74deaffc95a3b15b430 12.4s
=> => resolve docker.io/library/nginx:1.29.4@sha256:ca871a86d45a3ec6864dc45f014b11fe626145569ef0e74deaffc95a3b15b430 0.0s
=> => sha256:d03ca78f31febb8f2ba285ba9c2547eb66dbbbc8cc3f8bd76305d67fbafcbe9b 1.21kB / 1.21kB 1.6s
=> => sha256:35df28ad102658dd2661f97d891342916a766b37d638ef196d7e10f953065fc7 627B / 627B 可以看到它还是自动去拉取了。那--network从字面意思上是build时使用默认的default网络,如果我加上--pull选项后又给他指定了一个none网络那么就会失败,没网怎么拉取(当然如果你给它指定的网络用不了,那它还是会去用默认的,所以这里没办法演示就不演示了)。
那--no-cache这个选项是干什么的,有没有注意到,我们多次使用同一dockerfile去构建镜像时,即使我们后面在dockerfile中新增了一些并不耗时的命令,我们都发现,它比第一次构建镜像都会快的多。
这是因为当我们多次使用同一Dockerfile构建镜像时,Docker会利用层缓存机制。如果Dockerfile没有变化,所有层都使用缓存,构建极快。如果在中间新增命令,从该命令开始,后续所有层的缓存都会失效,需要重新构建。但由于前面的层仍然可以使用缓存,所以总体时间仍比第一次完整构建要快。--no-cache选项可以强制忽略所有缓存,从头开始构建每一层。如果我们加上这个选项可以发现构建我们上面那个大案例时就又回到第一次那样慢吞吞的速度了:
bash
knd@NightCode:~/dockertest/dockerfile_test$ sudo docker build --no-cache -t mynginx:1.8 .
[+] Building 1.7s (8/11) docker:default
=> [internal] load build definition from dockerfile 0.0s
=> => transferring dockerfile: 823B 0.0s
=> [internal] load metadata for docker.io/library/ubuntu:24.04 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [1/7] FROM docker.io/library/ubuntu:24.04@sha256:c35e29c9450151419d9448b0fd75374fec4fff364a27f176fb458d472dfc9e54 0.0s
=> => resolve docker.io/library/ubuntu:24.04@sha256:c35e29c9450151419d9448b0fd75374fec4fff364a27f176fb458d472dfc9e54 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 72B 0.0s
=> CACHED [2/7] WORKDIR /web 0.0s
=> [3/7] ADD ./nginx-1.29.4.tar.gz /web 0.2s
=> CANCELED [4/7] RUN sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list && apt update && apt ins 1.5s因为要等的时间实在是太长,我就取消了,大家可以自行尝试下。
2.5dockerfile编写规范
- 善用.dockerignore 文件 类似于代码仓库的ignore文件
使用它可以标记在执行 docker build 时忽略的路径和文件, 避免发送不必要的数据内容,从而加快整个镜像创建过程。 - 镜像的多阶段构建
通过多步骤创建,可以将编译和运行等过程分开,保证最终生成的镜像只包括运行应用所需要的最小化环境。当然,用户也可以通过分别构造编译镜像和运行镜像来达到类似的结果,但这种方式需要维护多个 Dockerfile。 - 合理使用缓存
如合理使用 cache,减少内容目录下的文件, 内容不变的指令尽量放在前面,这样可以尽量复用; - 基础镜像尽量使用官方镜像,并选择体积较小镜像
容器的核心是应用,大的平台微服务可能几十上百个。选择过大的父镜像(如 Ubuntu系统镜像)会造成最终生成应用镜像的臃肿, 推荐选用瘦身过的应用镜像(如node:slim),或者较为小巧的系统镜像(如 alpine、 busybox 或 debian) ; - 减少镜像层数
如果希望所生成镜像的层数尽量少,则要尽量合并 RUN、 ADD 和 COPY 指令。通常情况下,多个 RUN 指令可以合并为一条 RUN 指令;如 apt get update&&apt install 尽量写到一行 - 精简镜像用途
尽量让每个镜像的用途都比较集中单一,避免构造大而复杂、多功能的镜像; - 减少外部源的干扰
如果确实要从外部引入数据,需要指定持久的地址,并带版本信息等,让他人可以复用而不出错。 - 减少不必要的包安装
只安装需要的包,不要安装无用的包,减少镜像体积。
三.综合实际案例
3.1通过实例来区别CMD与ENTRYPOINT
ENTRYPOINT 和 CMD 都是在 docker image 里执行一条命令, 但是他们有一些微妙的区别.一般来说两个大部分功能是相似的都能满足。
比如执行运行一个没有调用 ENTRYPOINT 或者 CMD 的 docker 镜像, 返回错误,一般的镜像最后都提供了 CMD 或者 EntryPoint 作为入口。
启动命令覆盖问题
在写 Dockerfile 时, ENTRYPOINT 或者 CMD 命令会自动覆盖之前的 ENTRYPOINT或者 CMD 命令.
在 docker 镜像运行时, 用户也可以在命令指定具体命令, 覆盖在 Dockerfile 里的命令.如果你希望你的 docker 镜像只执行一个具体程序, 不希望用户在执行 docker run 的时候随意覆盖默认程序. 建议用 ENTRYPOINT.
比如我们看下面的例子:
bash
FROM busybox
CMD echo "hello world"
bash
FROM busybox
ENTRYPOINT echo "hello world"执行docker run并覆盖启动命令后者不会被覆盖而前者会:
bash
knd@NightCode:~/dockertest/dockerfile_test/test2$ sudo docker run -it --rm mybusybox:1.0 echo "hello knd"
hello knd
knd@NightCode:~/dockertest/dockerfile_test/test2$ sudo docker run -it --rm mybusybox:1.1 echo "hello knd"
hello world如果你实在想去覆盖entrypoint,那么可以加上--entrypoint选项:
bash
knd@NightCode:~/dockertest/dockerfile_test/test2$ sudo docker run -it --entrypoint "/bin/sh" --rm mybusybox:1.1 -c "echo hello knd"
hello kndshell与exec模式
ENTRYPOINT 和 CMD 指令支持 2 种不同的写法: shell 表示法和 exec 表示法,就是我们之前说的默认命令格式与json数组模式。
当使用 shell 表示法时 , 命令行程序作为 sh 程序的子程序运行, docker 用/bin/sh -c 的语法调用. 如果我们用 docker ps 命令查看运行的 docker, 就可以看出实际运行的是/bin/sh -c 命令 。这样运行 的结果就是我们启动的程序的 PID 不是 1 ,如果从外部发送任何 POSIX 信号到 docker 容器, 由于/bin/sh 命令不会转发消息给实际运行的命令, 则不能安全得关闭 docker 容器。
EXEC 语法没有启动/bin/sh 命令, 而是直接运行提供的命令, 命令的 PID 是 1. 无论你用的是 ENTRYPOINT 还是 CMD 命令, 都强烈建议采用 exec 表示法。
我们来验证下这段话,我们用下面的dockerfile进行验证:
bash
FROM nginx:1.29.4
EXPOSE 80/tcp
ENTRYPOINT [ "nginx", "-g", "daemon off;" ]当我们以此dockefile制作的镜像启动nginx后,开启新终端能发现nginx的pid为1,而且使用docker stop也能够优雅的退出:
bash
#B终端
root@39c8fc7cc50d:/# ls -l /proc/1/exe
lrwxrwxrwx 1 root root 0 Jan 3 05:55 /proc/1/exe -> /usr/sbin/nginx
knd@NightCode:~$ sudo docker stop nginx
nginx
#A终端
...
2026/01/03 05:57:45 [notice] 10#10: exit
2026/01/03 05:57:45 [notice] 8#8: gracefully shutting down
...但是如果是shell模式运行nginx,那么pid为1的进程就不是我们指定的nginx了而是/bin/sh,而且stop发送的信号是给到/bin/dash上了,会导致nginx并不是优雅退出的(此时我们会发现停止容器等待了10s左右,这时因为docker发现10s你还没有停止就给我们的nginx发送了一个9号信号强制杀死了进程):
bash
FROM nginx:1.29.4
EXPOSE 80/tcp
ENTRYPOINT nginx -g "daemon off;"
bash
#B终端
knd@NightCode:~$ sudo docker exec -it nginx bash
root@389affecf069:/# ls -l /proc/1/exe
lrwxrwxrwx 1 root root 0 Jan 3 06:01 /proc/1/exe -> /usr/bin/dash
knd@NightCode:~$ sudo docker stop nginx
nginx
#A终端
knd@NightCode:~$ sudo docker run -it --name nginx --rm mynginx:1.1
2026/01/03 06:01:21 [notice] 7#7: using the "epoll" event method
2026/01/03 06:01:21 [notice] 7#7: nginx/1.29.4
2026/01/03 06:01:21 [notice] 7#7: built by gcc 14.2.0 (Debian 14.2.0-19)
2026/01/03 06:01:21 [notice] 7#7: OS: Linux 6.8.0-71-generic
2026/01/03 06:01:21 [notice] 7#7: getrlimit(RLIMIT_NOFILE): 1024:524288
2026/01/03 06:01:21 [notice] 7#7: start worker processes
2026/01/03 06:01:21 [notice] 7#7: start worker process 8
2026/01/03 06:01:21 [notice] 7#7: start worker process 9
2026/01/03 06:01:21 [notice] 7#7: start worker process 10
2026/01/03 06:01:21 [notice] 7#7: start worker process 11
knd@NightCode:~$ 可以看到此时nginx也没有优雅的退出。所以我们一般使用CMD或ENTRYPOINT时,最好是使用exec模式,不要使用SHELL模式(细心的读者可能也发现了我们使用shell模式时docker会给我们弹出一行黄色警告建议我们不要使用shell)。
组合模式
组合使用 ENTRYPOINT 和 CMD, ENTRYPOINT 指定默认的运行命令, CMD 指定默认的运行参数.ENTRYPOINT 和 CMD 同时存在时, docker 把 CMD 的命令拼接到ENTRYPOINT 命令之后, 拼接后的命令才是最终执行的命令.
比如下面的一个dockerfile:
bash
FROM busybox
ENTRYPOINT [ "ping", "-c", "4"]
CMD [ "localhost" ]也就是说,我们一般使用组合模式是将命令及命令选项放在一起,然后参数放到CMD位置,我们运行下看看:
bash
knd@NightCode:~/dockertest/dockerfile_test/test3$ sudo docker run -it --rm cmd:1.0
PING localhost (127.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: seq=0 ttl=64 time=0.042 ms
64 bytes from 127.0.0.1: seq=1 ttl=64 time=0.052 ms
64 bytes from 127.0.0.1: seq=2 ttl=64 time=0.046 ms
64 bytes from 127.0.0.1: seq=3 ttl=64 time=0.069 ms
--- localhost ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.042/0.052/0.069 ms
knd@NightCode:~/dockertest/dockerfile_test/test3$ 组合模式有一个比较爽的地方,就是我们可以动态调整ENTRYPOINT的运行参数,比如我现在不想去ping本地了,我想要去ping下www.qq.com,就可以利用CMD的可覆盖性来玩:
bash
knd@NightCode:~/dockertest/dockerfile_test/test3$ sudo docker run -it --rm cmd:1.0 www.qq.com
PING www.qq.com (109.244.211.81): 56 data bytes
64 bytes from 109.244.211.81: seq=0 ttl=56 time=1.618 ms
64 bytes from 109.244.211.81: seq=1 ttl=56 time=1.628 ms
64 bytes from 109.244.211.81: seq=2 ttl=56 time=1.600 ms
64 bytes from 109.244.211.81: seq=3 ttl=56 time=1.629 ms
--- www.qq.com ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 1.600/1.618/1.629 ms
knd@NightCode:~/dockertest/dockerfile_test/test3$其实当我们使用ENTRYPOINT的exec模式时,我们run后面的命令是被附加到ENTRYPOINT原来执行的命令之后的,相当于源目标执行的命令的一个参数了,比如我们看下面的这个例子:
bash
FROM busybox
ENTRYPOINT [ "echo", "hello world"]当我们这样用时,它直接把我们的run后面的命令给当成附加参数喂给echo命令了:
bash
knd@NightCode:~/dockertest/dockerfile_test/test3$ sudo docker run -it --rm cmd:1.1 echo "hello knd"
hello world echo hello knd3.2使用dockerignore忽略冗余文件
Docker 是 C-S 架构,理论上 Client 和 Server 可以不在一台机器上。在构建 docker 镜像的时候,需要把所需要的文件由 Client 发送给 Server,这些要发送的文件叫做build context。
如果想忽略掉一些传送给 Sever 端的文件, 这就会用到.dockerignore 文件。它会将记录的所有文件都忽略掉, 不会传送给 Server 端, 有效的避免一些和容器内应用运行无关的文件不会被复制到 Server 端, 即不会将无关的文件打入生成的镜像中。
比如说我有如下的dockerfile:
bash
FROM busybox
COPY ./* /同时我当前目录下有如下内容:
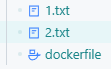
我想让它拷贝的时候忽略txt文件就可以这样写.dockerignore文件:
bash
*.txt此时我们构建容器就会发现1.txt与2.txt并没有被拷贝到镜像的根目录下:
bash
knd@NightCode:~/dockertest/dockerfile_test/test3$ sudo docker run -it --rm cmd:1.0 ls /
bin dockerfile home lib64 root tmp var
dev etc lib proc sys usr3.3多阶段构建
构建 docker 镜像可以有下面两种方式
- 将全部组件及其依赖库的编译、测试、打包等流程封装进一个 docker 镜像中。但是这种方式存在一些问题, 比如 Dockefile 特别长,可维护性降低;镜像的层次多,体积大,部署时间长等问题
- 将每个阶段分散到多个 Dockerfile。一个 Dockerfile 负责将项目及其依赖库编译测试打包好后,然后将运行文件拷贝到运行环境中,这种方式需要我们编写多个Dockerfile 以及一些自动化脚本才能将其两个阶段自动整合起来
- 为了解决以上的两个问题, Docker 17.05 版本开始支持多镜像阶段构建。只需要编写一个 Dockerfile 即可解决上述问题。
我们上面从源码编译nginx时,其实有很多的冗余部分,我们的镜像中除了目标的nginx还有一个比较重的gcc和make这些编译工具。如果想要移除这些编译工具就需要多阶段构建,下面是我写好的一个多阶段构建样例基于上面的那个例子:
bash
#dockerfile
FROM ubuntu:24.04 AS builder
ENV WEBDIR="/web"
WORKDIR ${WEBDIR}
ADD ./nginx-1.29.4.tar.gz ${WEBDIR}
# 更换apt源为中科大
RUN sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list && \
apt update && \
apt install -y gcc make && \
apt install -y libpcre3-dev zlib1g-dev libssl-dev
COPY ./nginx.conf ${WEBDIR}/nginx-1.29.4/conf/
COPY ./index.html ${WEBDIR}/nginxhtml/
RUN cd ${WEBDIR}/nginx-1.29.4/ && \
./configure --prefix=/usr/local/nginx && \
make && \
make install
#2.构建最终镜像
FROM ubuntu:24.04
ENV WEBDIR="/web"
WORKDIR ${WEBDIR}
COPY --from=builder /usr/local/nginx /usr/local/nginx
COPY --from=builder ${WEBDIR}/nginxhtml/ ${WEBDIR}/nginxhtml/
EXPOSE 80/tcp
ENTRYPOINT ["/usr/local/nginx/sbin/nginx", "-g", "daemon off;"]
RUN sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list && \
apt update && \
apt install -y libpcre3-dev zlib1g-dev libssl-dev &&\
apt install -y curl
HEALTHCHECK --interval=30s --timeout=30s --start-period=5s --retries=3 CMD curl http://localhost/ || exit 1这里就体现出AS与--from选项的作用了,一看就明白了。这里我们最终镜像是不需要gcc与make的,但是仍然需要运行时的动态库,那么就需要对这些动态库的文件予以保留,同时首页文件也需要拷贝。我们来看下这样多阶段构建出来的镜像有多大:
bash
mynginx:1.0 5fec4deac6f1 580MB 166MB
mynginx:1.1 33e2be0649e3 317MB 93.6MB 可以看到相比于1.0版本,它小了近1倍左右的大小。运行起来也是没有问题的:
需要注意,*-dev 包是"给编译用的",不是"给运行用的",在 final 镜像里用它是错误且浪费的。所以我们这里可以吧-dev给去掉(这里我偷了个懒libssl-dev去掉dev之后不是它的运行时包,啊不想再去找它的运行时包的名称了,为了省事就给他用上编译时包了):
bash
#dockerfile
FROM ubuntu:24.04 AS builder
ENV WEBDIR="/web"
WORKDIR ${WEBDIR}
ADD ./nginx-1.29.4.tar.gz ${WEBDIR}
# 更换apt源为中科大
RUN sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list && \
apt update && \
apt install -y gcc make && \
apt install -y libpcre3-dev zlib1g-dev libssl-dev
COPY ./nginx.conf ${WEBDIR}/nginx-1.29.4/conf/
COPY ./index.html ${WEBDIR}/nginxhtml/
RUN cd ${WEBDIR}/nginx-1.29.4/ && \
./configure --prefix=/usr/local/nginx && \
make && \
make install
#2.构建最终镜像
FROM ubuntu:24.04
ENV WEBDIR="/web"
WORKDIR ${WEBDIR}
COPY --from=builder /usr/local/nginx /usr/local/nginx
COPY --from=builder ${WEBDIR}/nginxhtml/ ${WEBDIR}/nginxhtml/
EXPOSE 80/tcp
ENTRYPOINT ["/usr/local/nginx/sbin/nginx", "-g", "daemon off;"]
#最后的rm -rf是清理缓存,保持镜像小,--no-install-recommends 的作用是:只安装"必须依赖",不安装"推荐但非必须"的附加包
RUN sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list && \
apt update && \
apt install --no-install-recommends -y libpcre3 zlib1g libssl-dev &&\
apt install -y curl && \
rm -rf /var/lib/apt/lists/*
HEALTHCHECK --interval=30s --timeout=30s --start-period=5s --retries=3 CMD curl http://localhost/ || exit 1来看下1.2版本的大小体积:
bash
mynginx:1.0 5fec4deac6f1 580MB 166MB
mynginx:1.1 33e2be0649e3 317MB 93.6MB
mynginx:1.2 f8ba4611de2a 156MB 38.8MB 直接给干到156mb了,而且能够正常运行我试过了,此时我们整出来的镜像就又小了很多,当然如果想要更小可以让最终的基准系统镜像为apline或debian这些小系统镜像,但是虽然可以小很多,配置起来会比较麻烦,最好编译时基准镜像也换用这些小系统,否则会引发一系列奇怪的找不到包,环境不适合等一堆问题。这里我们就不再展示了大家可以自己折腾折腾。
3.4dockerfile结合docker compose实现mysql数据库主从同步
docker compose build命令
功能
在 docker-compose.yml 文件中使用 build 选项编译镜像。
格式
yaml
services:
# 格式一
frontend:
image: awesome/webapp
build: ./webapp
# 格式二
backend:
image: awesome/database
build:
#构建上下文目录
context: ./backend
dockerfile: ./backend.Dockerfileimage的位置如果我们使用了build,那么它就相当于我们使用docker build -t给它指定了一个镜像名称。然后build位置如果只给了一个目录,意思就是你的dockerfile与上下文路径均为此目录。否则你就分开给。
什么是mysql主从同步
MySQL 主从复制是指数据可以从一个 MySQL 数据库服务器主节点复制到一个或多个从节点。 MySQL 默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库,或者特定的表。
主从同步的主要目的:
- 读写分离,性能提升:让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运作。扩展架构提升读写能力。
- 数据实时备份:主库数据实时保存到存库,万一主库故障也有从库的数据备份
- 高可用 HA:当系统中某个节点发生故障时,可以方便的故障切换
比如说我主的负责写的结点挂掉了,那么可以让从库提升为主节点然后保证服务的正常运行,给主节点的抢救提供时间。
主从同步架构图
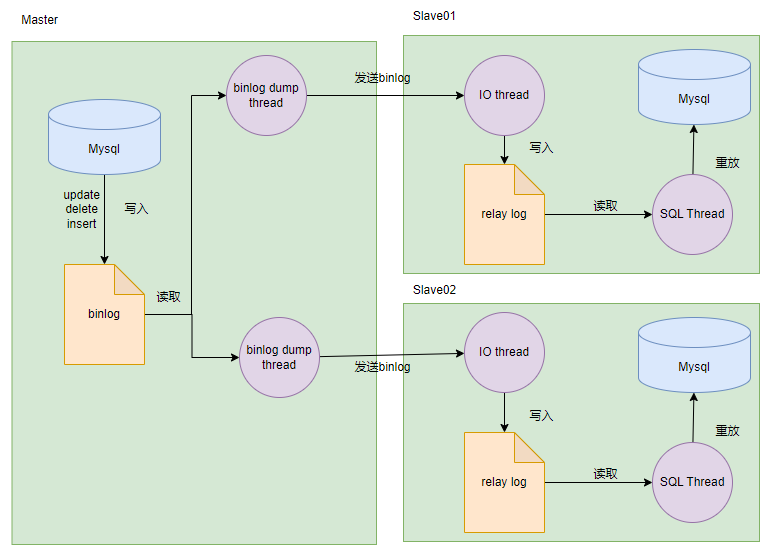
在主从复制的过程中,会基于三个线程来操作,一个是 binlog dump 线程,位于master 节点上,另外两个线程分别是 I/O 线程和 SQL 线程,它们都分别位于 slave 节点上。
此时如果客户端进行了数据的更新请求 ,比如update,delete等会修改数据的事务请求,那么此时会将此请求写入到主数据库的binlog,binlog dump 线程会读取 master 节点上的 binlog 日志,然后将 binlog 日志发送给slave 节点上的 I/O 线程。如果主库有读取事件的时候,会在 Binglog 上加锁,读取完成之后,再将锁释放掉。
slave 节点上的 I/O 线程接收到 binlog 日志后,会将 binlog 日志先写入到本地的relaylog 中, relaylog 中就保存了 binlog 日志。
slave 节点上的 SQL 线程,会来读取 relaylog 中的 binlog 日志,将其解析成具体的增删改操作,把这些在 master 节点上进行过的操作,重新在 slave 节点上也重做一遍,达到数据还原的效果,这样就可以保证 master 节点和 slave 节点的数据一致性了。
主从同步的数据内容其实是二进制日志(Binlog),它虽然叫二进制日志,实际上存储的是一个又一个的事件(Event),这些事件分别对应着数据库的更新操作,比如INSERT、 UPDATE、 DELETE 等。
什么是binlog
主库每提交一次事务,都会把数据变更,记录到一个二进制文件中,这个二进制文件就叫 binlog。需注意:只有写操作才会记录至 binlog,只读操作是不会的(如 select、show 语句)。
Bin Log 共有三种日志格式,可以 binlog_format 配置参数指定。
Statement:直接记录原始 SQL 语句,但是问题是会导致更新时间与原库不一致。比如说一个用户提交的事务在主库操作后,一段时间后传到我从库,但是这之间的时间可能很长,就会导致主库和从库对此数据的更新时间不一致。Row:记录每行数据的变化,保证了数据与原库一致,缺点是数据量较大。Mixed:Statement 和 Row 的混合模式,默认采用 Statement 模式,涉及日期、函数相关的时候采用 Row 模式,既减少了数据量,又保证了数据一致性。
主从同步的方式
全同步方式
最简单暴力的同步方式,就是只有当所有的从库都提交完毕事务之后,再返回相应给客户端:
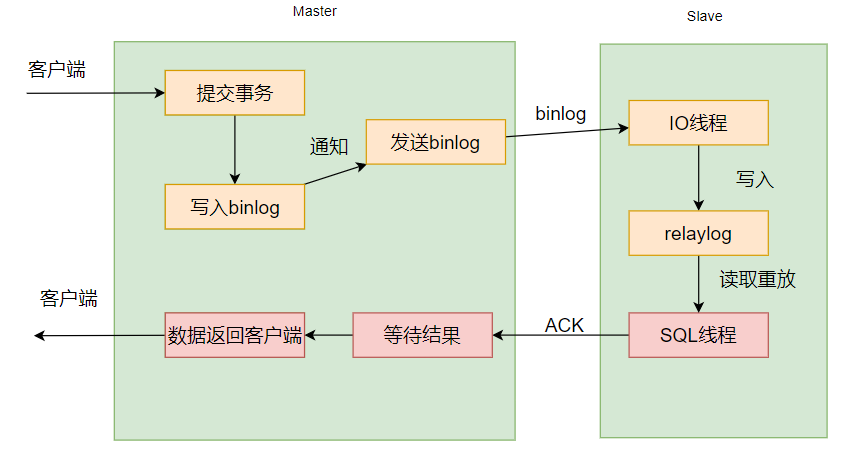
这样就会有很大的问题,就跟数据库的事务串行化一样,最为严格,但是一旦从库比较多,全部去等待时间上会很长,性能上会大打折扣。而且从库挂了主库也会受影响。
那么我们想,可不可以直接把binlog发给从库之后然后不等待立马返回响应给客户端呢,这就是下面的异步同步方式。
异步同步方式
默认方式,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理。
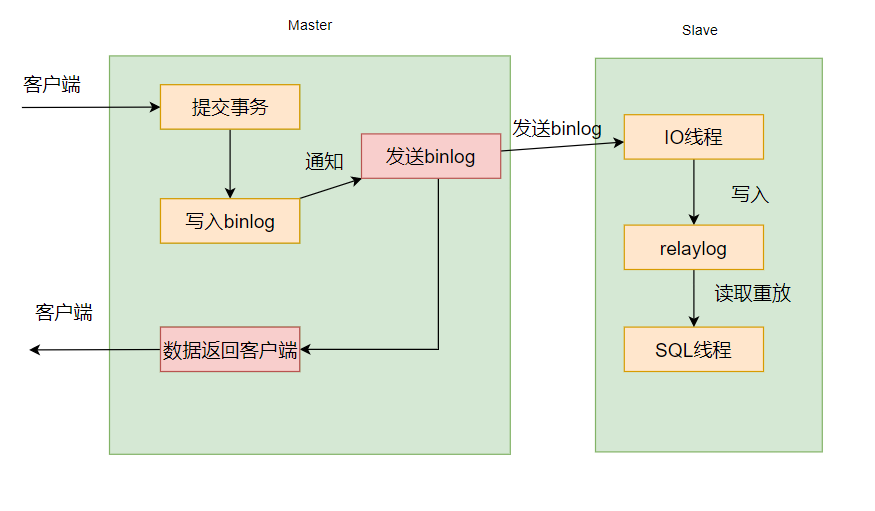
但是,这样会有两个问题,第一个就是幻读问题,如果我主数据库刚把binlog发给slave节点。此时我有客户端先前已经在master结点查到了对应的数据,然后又查了一次数据以负载均衡策略来查我从节点。可是主库给我的binlog我还没有消化啊,我查不到先前你在主库中查到的数据,此时就只能返回个空给你了。这就导致了幻读问题。
还有数据一致性的问题,比如我master结点刚提交完事务,因为一些原因我主库挂掉了。此时没有给从库发binlog。然后从库替代主库成为新的主库,此时又更新了一些数据。等到我原来的主库起来了,我一看现在的主库,原本我看到你比我多了些数据我准备去更新,但是我更新完后发现我的数据结果又比现在的主库多了,这就成了一个问题。
那么我们可以先从sql线程读取relaylog这步开始优化,为什么,因为此时主库的binlog已经完全写入了我从库的relaylog,剩下的数据更新执行sql语句的过程你从库慢慢更新,主库不等了就行了吗。也就是当所有的从库relaylog写入完毕之后,我主库再返回响应给客户端,这种同步方式被称为半同步方式:
半同步方式
半同步:基于传统异步存在的缺陷, mysql 在 5.5 版本推出半同步复制。可以说半同步复制是传统异步复制的改进,在 master 事务的 commit 之前,必须确保一个slave 收到 relay log 并且响应给 master 以后,才能进行事务的 commit。相当于添加多了一个从库反馈机制。
在 MySQL5.7 版本中还增加了一个rpl_semi_sync_master_wait_for_slave_count 参数,我们可以对需要响应的从库数量进行设置 ,默认为 1,也就是说只要有一个从库进行了响应,就可以返回给客户端。如果将这个参数调大,可以提升数据一致性的强度,但也会增加主库等待从库响应的时间。对应配置参数为 rpl_semi_sync_master_wait_point=after_commit。核心流程为,主库执行完事务后,主库提交 commit ,同步 binlog 给从库,从库 ack 反馈接收到binlog,反馈给客户端,释放会话; (主库生成 binlog,主库提交,再同步 binlog,等ACK 反馈,返回客户端)
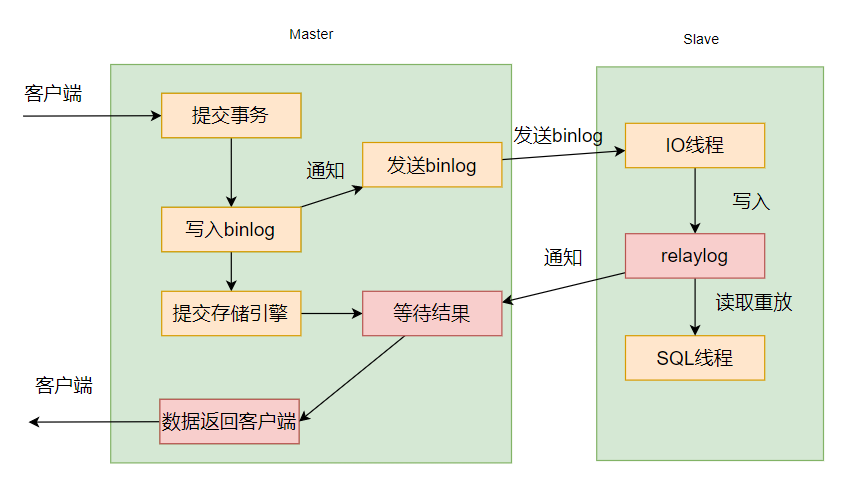
但是也导致了几个问题,首当其冲的就是半同步复制的性能,相比异步复制而言有所下降,相比于异步复制是不需要等待任何从库是否接收到数据的响应,而半同步复制则需要等待至少一个从库确认接收到 binlog 日志的响应,性能上是损耗更大的。
第二个问题,主库等待从库响应的最大时长是可以配置的,如果超过了配置的时间,半同步复制就会退化为异步复制,那么,异步复制的问题同样也就会出现了。而且如果主库挂掉了,又会导致数据的不一致,这种同步方式只是一定程度上减小了不一致的可能性。
第三个问题,幻读问题依旧没有解决。当主库成功提交事物并处于等待从库确认的过程中,这个时候,从库都还没来得及返回处理结果给客户端,但因为主库存储引擎内部已经提交事务了,所以,其他客户端是可以到从主库中读到数据的。但是,如果下一秒主库突然挂了,此时正好下一次请求过来,就只能把请求切换到从库中,因为从库还没从主库同步完数据,所以,从库中当然就读不到这条数据了,和上一秒读取数据的结果对比,就造成了幻读的现象了。
既然这样,那我就再损耗一些性能,我也不写入binlog之后提交存储引擎了,我就等指定的最小从库数都写入完毕relaylog之后,再去提交我的存储引擎。最后在给客户端响应,这就是增强半同步机制:
增强半同步方式
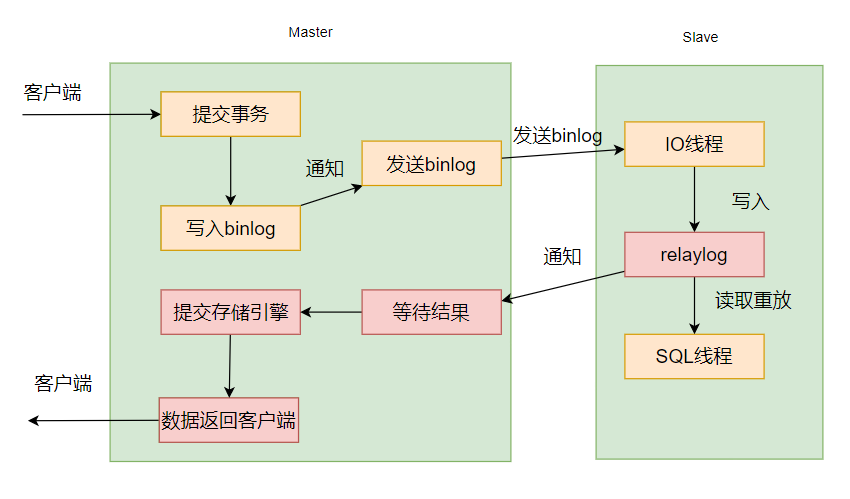
增强半同步复制,是 对半同步复制做的一个改进,原理上几乎是一样的,主要是解决幻读的问题。
主库配置了参数 rpl_semi_sync_master_wait_point = AFTER_SYNC 后,主库在存储引擎提交事务前,必须先收到从库数据同步完成的确认信息后,才能提交事务,以此来解决幻读问题。
核心流程为主库执行完事务后,同步 binlog 给从库,从库 ack 反馈接收到 binlog,主库提交 commit,反馈给客户端,释放会话; (主库生成 binlog,再同步 binlog,等ACK 反馈,主库提交,返回客户端)
但是 slave 对于 relaylog 的应用仍然是异步进行的,幻读和数据不一致性依然只是减轻了并没有得到最大限度的降低。我们会发现啊,是否响应给客户端,上面的同步方式怎么都是一个库来决定啊,是不是有些不太合理,半数以上的库都同意了再提交是不是更好些,也就是实行民主化决策。
还有,既然写入binlog时有可能挂掉,那我不在这里再去给从库通知了。我直接收到客户端的事务时,我先将语句执行完毕,然后将事务再直接给所有的slave结点发一个,让他们也去执行这个事务。这就是接下来要说的组复制方式。
组复制
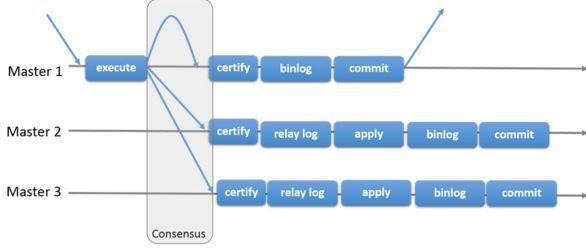
MySQL 官方在 5.7.17 版本正式推出组复制(MySQL Group Replication,简称MGR)
由若干个节点共同组成一个复制组,一个事务的提交,必须经过组内大多数节点(N / 2 + 1)决议并通过,才能得以提交。 如上图所示,由 3 个节点组成一个复制组,Consensus 层为一致性协议层,在事务提交过程中,发生组间通讯,由 2 个节点决议(certify)通过这个事务,事务才能够最终得以提交并响应。
同时,当事务到达主库时,并不是我主库执行完毕所有对应sql语句之后就ok了,流程替换成了如下方式:
客户端 → 任意节点:
- 执行事务(本地)
- 不提交!❌
- 提取"写集"(事务的核心内容)
- 广播给所有成员投票
- 多数同意 → 提交事务 ✅
- 所有节点同时写入binlog
引入组复制,主要是为了解决传统异步复制和半同步复制可能产生数据不一致的问题。组复制依靠分布式一致性协议(Paxos 协议的变体),实现了分布式下数据的最终一致性,提供了真正的数据高可用方案(是否真正高可用还有待商榷)。其提供的多写方案,给我们实现多活方案带来了希望。
MGR 的解决方案有一定的局限性,如仅支持 InnoDB 表,并且每张表一定要有一个主键,用于做write set 的冲突检测;开启 GTID 特性等等。
MySQL 主从形式
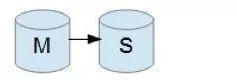
一主一从形式
一主多从 ,以便提高数据库的读性能
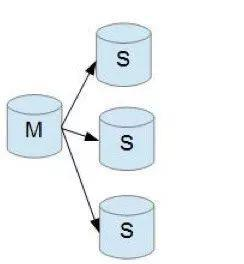
一主一从和一主多从是最常见的主从架构,实施起来简单并且有效,不仅可以实现 HA,而且还能读写分离,进而提升集群的并发能力。
多主一从 ,提高服务的写能力
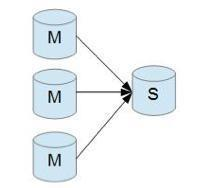
多主一从可以将多个 mysql 数据库备份到一台存储性能比较好的服务器上。
双主复制
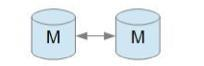
双主复制,也就是互做主从复制,每个 master 既是 master,又是另外一台服务器的slave。这样任何一方所做的变更,都会通过复制应用到另外一方的数据库中。
级联复制
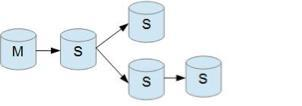
级联复制模式下,部分 slave 的数据同步不连接主节点,而是连接从节点。因为如果主节点有太多的从节点,就会损耗一部分性能用于 replication,那么我们可以让 3~5个从节点连接主节点,其它从节点作为二级或者三级与从节点连接,这样不仅可以缓解主节点的压力,并且对数据一致性没有负面影响。
进行mysql主从同步的搭建
步骤:
- 创建主库,并在主库中创建单独的 mysql 用户用于同步数据,授予该用户数据同步权限
- 创建从库,配置从库的数据同步的主库信息
- 启动从库,开始同步
我们这里简单些,创建一个一主二从的 mysql 集群,使用5.7版本的mysql作为基准镜像,用8.0的有一个认证问题,需要配置的比较麻烦:
因为从库的配置是一样的,所以我们只需要写两份配置,一份主库的,一份从库的:
bash
knd@NightCode:~/dockertest/mysql_cluster_test$ mkdir master
knd@NightCode:~/dockertest/mysql_cluster_test$ mkdir slave首先我们编写主库的dockerfile:
bash
FROM mysql:5.7.36
#设置系统的时区为上海时区
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime接下来是从库的:
bash
FROM mysql:5.7.36
#设置系统的时区为上海时区
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
#将数据库的默认需要执行的sql文件复制到容器中让数据库在启动时自动执行
COPY ./slave.sql /docker-entrypoint-initdb.d
sql
change master to master_host='mysql-master',
master_port=3306,
master_user='knd',
master_password='114514';
-- 启动从库复制,告诉从库开始同步主库的数据
start slave;然后是编写我们的docker-compose.yml,主要用到的选项配置如下:
mysql的数据库配置选项如下:
- log-bin:打开二进制日志功能,配置 binlog 文件名
- binlog-ignore-db: 配置忽略的数据库
- binlog_cache_size:在一个事务中 binlog 为了记录 SQL 状态所持有的 cache 大小,如果经常使用大事务,可以增加此值来获取更大的性能。
- binlog_format:ROW/STATEMENT/MIXED
- lower_case_table_names:表采用小写
- character-set-server:配置字符集
- collation-server:配置比较规则
编写的最终结果:
yaml
services:
mysql-master:
build: ./master
container_name: mysql-master
ports:
- 8080:3306
environment:
MYSQL_ROOT_PASSWORD: "xiu1919180"
volumes:
- ./master/varlib:/var/lib/mysql
privileged: true #设置容器为特权容器,可以访问宿主机的设备,相当于root用户
command: [
# 【核心标识】设置MySQL服务器ID,主从复制中必须唯一主库通常设为1,从库设为2、3等不同数字
'--server-id=1',
# 【二进制日志】开启二进制日志功能,开启后,所有数据库变更操作都会写入二进制日志文件
'--log-bin=master-bin',
# 【日志过滤】忽略系统数据库mysql的变更记录,避免复制不必要的系统表变更,减少日志大小
'--binlog-ignore-db=mysql',
# 【性能优化】设置二进制日志缓存大小为256MB,提高事务写入binlog的性能,大事务场景下尤为重要
'--binlog_cache_size=256M',
# 【日志格式】设置二进制日志binlog格式为混合模式
'--binlog_format=mixed',
# 【表名大小写】设置表名不区分大小写,1 = 不区分大小写(Windows/Linux兼容性)
# 0 = 区分大小写(Linux默认)
# 2 = 按创建时的大小写存储,比较时转为小写
'--lower_case_table_names=1',
# 【字符集】设置服务器默认字符集为utf8,注意:MySQL的utf8是utf8mb3(最大3字节),utf8mb4支持4字节(如emoji)
'--character-set-server=utf8',
# 【排序规则】设置服务器默认排序规则,utf8_general_ci:通用排序规则,不区分大小写
'--collation-server=utf8_general_ci'
]
healthcheck:
test: ["CMD" , "mysql", "-u", "root", "-pxiu1919180", "-e", "SELECT 1"]
interval: 10s
timeout: 5s
retries: 10
networks:
- mysql-cluster-network
mysql-slave1:
build: ./slave
container_name: mysql-slave1
ports:
- 8081:3306
environment:
- MYSQL_ROOT_PASSWORD=xiu1919180
volumes:
- ./slave/varlib1:/var/lib/mysql
privileged: true #设置容器为特权容器,可以访问宿主机的设备,相当于root用户
command: [
'--server-id=2',
'--relay_log=slave-relay', # 中继日志文件名前缀
'--lower_case_table_names=1',
'--character-set-server=utf8',
'--collation-server=utf8_general_ci'
]
healthcheck:
test: ["CMD" , "mysql", "-u", "root", "-pxiu1919180", "-e", "SELECT 1"]
interval: 10s
timeout: 5s
retries: 10
depends_on:
mysql-master:
condition: service_healthy
networks:
- mysql-cluster-network
mysql-slave2:
build: ./slave
container_name: mysql-slave2
ports:
- 8082:3306
environment:
- MYSQL_ROOT_PASSWORD=xiu1919180
volumes:
- ./slave/varlib2:/var/lib/mysql
privileged: true #设置容器为特权容器,可以访问宿主机的设备,相当于root用户
command: [
'--server-id=3',
'--relay_log=slave-relay', # 中继日志文件名前缀
'--lower_case_table_names=1',
'--character-set-server=utf8',
'--collation-server=utf8_general_ci'
]
healthcheck:
test: ["CMD" , "mysql", "-u", "root", "-pxiu1919180", "-e", "SELECT 1"]
interval: 10s
timeout: 5s
retries: 10
depends_on:
mysql-master:
condition: service_healthy
networks:
- mysql-cluster-network
networks:
mysql-cluster-network:
driver: bridge目录结构如下:
先执行sudo docker compose build,镜像构建成功之后再进行sudo docker compose up -d。
可以看到所有数据库已经健康启动:
bash
knd@NightCode:~/dockertest/mysql_cluster_test$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a52f5408c483 mysql_cluster_test-mysql-slave1 "docker-entrypoint.s..." 10 minutes ago Up 54 seconds (healthy) 33060/tcp, 0.0.0.0:8081->3306/tcp, [::]:8081->3306/tcp mysql-slave1
bb9e5ae31e04 mysql_cluster_test-mysql-slave2 "docker-entrypoint.s..." 10 minutes ago Up 54 seconds (healthy) 33060/tcp, 0.0.0.0:8082->3306/tcp, [::]:8082->3306/tcp mysql-slave2
b039987e0c09 mysql_cluster_test-mysql-master "docker-entrypoint.s..." 10 minutes ago Up About a minute (healthy) 33060/tcp, 0.0.0.0:8080->3306/tcp, [::]:8080->3306/tcp mysql-master我们可以登上主库查看配置信息:
bash
mysql> SHOW MASTER STATUS\G
*************************** 1. row ***************************
File: master-bin.000003
Position: 154
Binlog_Do_DB:
Binlog_Ignore_DB: mysql
Executed_Gtid_Set:
1 row in set (0.00 sec)登上从库看从库信息:
bash
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: mysql-master
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master-bin.000003
Read_Master_Log_Pos: 154
Relay_Log_File: slave-relay.000006
Relay_Log_Pos: 369
Relay_Master_Log_File: master-bin.000003
...
#这四行如果是示例展示的情况才说明与主库连接成功了,否则没有成功
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
...然后我们在主库新增一些数据:
bash
mysql> create database mytest;
mysql> use mytest;
mysql> CREATE TABLE `user` (
-> `id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
-> `username` VARCHAR(64) NOT NULL,
-> PRIMARY KEY (`id`),
-> UNIQUE KEY `uk_username` (`username`)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
mysql> insert into user (username) values('knd');
mysql> select * from user;
+----+----------+
| id | username |
+----+----------+
| 1 | knd |
+----+----------+
1 row in set (0.00 sec)再来从库查询下有没有对应数据:
bash
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| mytest |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)是有对应数据库的:
bash
mysql> select * from user;
+----+----------+
| id | username |
+----+----------+
| 1 | knd |
+----+----------+
1 row in set (0.00 sec)另一个从库也是能够查到的。
3.5dockerfile结合docker compose构建 Redis 集群
这里我们也是采用源码编译的方式,使用redis7的版本进行构建,首先把7.0.11版本的redis源码包下载到我们自己的电脑上然后别急着上传到服务器,先改下配置以便于我们搭建redis集群:
要修改的配置如下(修改的是根目录下的redis.conf):
bash
#表示前台运行
daemonize no
#端口
port 6379
#持久化
dir /data/redis
#启用集群
cluster-enabled yes
#集群参数配置
cluster-config-file nodes.conf
#集群超时时间
cluster-node-timeout 5000
#密码配置
requirepass 123456
#主节点密码配置
masterauth 123456
#表示远端可以连接
bind * -::*主节点密码和其他结点密码配置一致能够减少运维量,找到redis.conf中的这些选项改为我们上面的选项即可。当然生产环境密码不能这么简单,我们这里只是测试下。
配置修改完毕之后再把它上传到服务器:
bash
knd@NightCode:~/dockertest/redis_cluster_test/redis$ ls
redis-7.0.11.tar.gz redis.conf这里我把压缩包和修改后的配置文件给上传上来了。后面COPY到镜像中就ok了。
放于redis目录下的dockerfile如下:
bash
FROM ubuntu:24.04 AS buildstage
RUN sed -i 's@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g' /etc/apt/sources.list && \
apt update && \
apt install -y build-essential
ADD redis-7.0.11.tar.gz /
ADD redis.conf /redis/
WORKDIR /redis-7.0.11
RUN make
RUN mv /redis-7.0.11/src/redis-server /redis/ && mv /redis-7.0.11/src/redis-cli /redis/
FROM ubuntu:24.04
RUN mkdir -p /data/redis && mkdir -p /redis
COPY --from=buildstage /redis /redis
EXPOSE 6379
ENTRYPOINT ["/redis/redis-server", "/redis/redis.conf"]构建根目下的docker-compose.yml如下:
yaml
services:
redis01:
image: myredis:1.0
build: ./redis
ports:
- 6379:6379
container_name: redis01
healthcheck:
test: /redis/redis-cli ping
interval: 10s
timeout: 5s
retries: 10
redis02:
image: myredis:1.0
container_name: redis02
healthcheck:
test: /redis/redis-cli ping
interval: 10s
timeout: 5s
retries: 10
redis03:
image: myredis:1.0
container_name: redis03
healthcheck:
test: /redis/redis-cli ping
interval: 10s
timeout: 5s
retries: 10
redis04:
image: myredis:1.0
container_name: redis04
healthcheck:
test: /redis/redis-cli ping
interval: 10s
timeout: 5s
retries: 10
redis05:
image: myredis:1.0
container_name: redis05
healthcheck:
test: /redis/redis-cli ping
interval: 10s
timeout: 5s
retries: 10
redis06:
image: myredis:1.0
container_name: redis06
healthcheck:
test: /redis/redis-cli ping
interval: 10s
timeout: 5s
retries: 10
# 此容器仅用于初始化集群,初始化完成后即可删除
redis07:
image: myredis:1.0
container_name: redis07
entrypoint: ["/redis/redis-cli","--cluster","create","redis01:6379","redis02:6379","redis03:6379","redis04:6379","redis05:6379","redis06:6379","--clusterreplicas","1","-a","123456","--cluster-yes"]
depends_on:
redis01:
condition: service_healthy
redis02:
condition: service_healthy
redis03:
condition: service_healthy
redis04:
condition: service_healthy
redis05:
condition: service_healthy
redis06:
condition: service_healthy容器已经全部成功运行
yaml
knd@NightCode:~/dockertest/redis_cluster_test$ sudo docker compose up -d
[+] up 8/8
✔ Network redis_cluster_test_default Created 0.0s
✔ Container redis04 Healthy 11.2s
✔ Container redis06 Healthy 11.2s
✔ Container redis02 Healthy 10.7s
✔ Container redis05 Healthy 11.2s
✔ Container redis03 Healthy 10.7s
✔ Container redis01 Healthy 11.2s
✔ Container redis07 Created 我们来看下集群的状态:
bash
knd@NightCode:~/dockertest/redis_cluster_test/redis$ sudo docker logs redis07
...
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.看到这些就说明我们的集群已经成功启动了。
再进容器看看:
bash
knd@NightCode:~/dockertest/redis_cluster_test/redis$ sudo docker exec -it redis01 bash
root@59ec39314dbd:/# /redis/redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:197
cluster_stats_messages_pong_sent:206
cluster_stats_messages_sent:403
cluster_stats_messages_ping_received:201
cluster_stats_messages_pong_received:197
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:403
total_cluster_links_buffer_limit_exceeded:0看到如上信息说明集群创建已经完全成功没有问题了。
补充:自主实践案例:dockerfile结合dockercompose搭建C++微服务
这里可以尝试使用dockerfile与dockercompose联合去编写下我们之前写过的一个微服务项目:基于脚手架的视频点播系统服务端。让他的服务端能成功运行通过我们自主编写的dockerfile与docker-compose.yml,可以参考我写的docker-compose.yml与dockerfile。
博主自己写的案例
注意在此之前先把其他中间件的容器给运行起来,也就是我们最开始写服务端配置环境那里拉取的容器,可以把dev那个开发环境给去了减少资源占用。
补充:常见问题陈述
- ADD 与 COPY 的区别
ADD:不仅能够将构建命令所在的主机本地的文件或目录,而且能够将远程 URL所对应的文件或目录,作为资源复制到镜像文件系统。所以,可以认为 ADD 是增强版的 COPY,支持将远程 URL 的资源加入到镜像的文件系统。
COPY: COPY 指令能够将构建命令所在的主机本地的文件或目录,复制到镜像文件系统。
有的时候就是只需要拷贝压缩包,那么我们就要用 COPY 指令了 - CMD 与 EntryPoint 的区别
ENTRYPOINT 容器启动后执行的命令,让容器执行表现的像一个可执行程序一样,与 CMD 的 区 别 是 不 可 以 被 docker run 覆 盖 , 会 把 docker run 后 面 的参 数 当 作 传 递 给 ENTRYPOINT 指令的参数。Dockerfile 中只能指定一个 ENTRYPOINT,如果指定了很多,只 有 最 后 一 个 有效 。 docker run 命 令 的 -entrypoint 参 数 可 以 把 指 定 的 参 数 继 续 传 递 给ENTRYPOINT
组合使用 ENTRYPOINT 和 CMD, ENTRYPOINT 指定默认的运行命令, CMD指定默认的运行参数 - 多个 From 指令如何使用
多个 FROM 指令并不是为了生成多根的层关系,最后生成的镜像,仍以最后一条FROM 为准,之前的 FROM 会被抛弃,那么之前的 FROM 又有什么意义呢?每一条 FROM 指令都是一个构建阶段,多条 FROM 就是多阶段构建,虽然最后生成的镜像只能是最后一个阶段的结果,但是,能够将前置阶段中的文件拷贝到后边的阶段中,这就是多阶段构建的最大意义。最大的使用场景是将编译环境和运行环境分离. - 快照和 dockerfile 制作镜像有什么区别?
等同于为什么要使用 Dockerfile。 - 什么是空悬镜像 (dangling )仓库名、标签均为 的镜像被称为虚悬镜像,一般来说,虚悬镜像已经失去了存在的价值,是可以随意删除的。造成虚悬镜像的原因:
原因一 :
原本有镜像名和标签的镜像,发布了新版本后,重新 docker pull *** 时,旧的镜像名被转移到了新下载的镜像身上,而旧的镜像上的这个名称则被取消;
原因二 :
docker build 同样可以导致这种现象。比如用 dockerfile1 构建了个镜像 tnone1:v1,又用另外一个 Dockerfile2 构建了一个镜像 tnone1:v1,这样之前的那个镜像就会变成空悬镜像。
可以用下面的命令专门显示这类镜像:
bash
docker image ls -f dangling=true- 中间层镜像是什么?
为了加速镜像构建、重复利用资源, Docker 会利用 中间层镜像。所以在使用一段时间后,可能会看到一些依赖的中间层镜像。默认的 docker image ls 列表中只会显示顶层镜像,如果希望显示包括中间层镜像在内的所有镜像的话,需要加 -a 参数。
bash
docker image ls -a**这样会看到很多无标签的镜像,与之前的虚悬镜像不同,这些无标签的镜像很多都是中间层镜像,是其它镜像所依赖的镜像。**这些无标签镜像不应该删除,否则会导致上层镜像因为依赖丢失而出错。实际上,这些镜像也没必要删除,因为之前说过,相同的层只会存一遍,而这些镜像是别的镜像的依赖,因此并不会因为它们被列出来而多存了一份,无论如何你也会需要它们。只要删除那些依赖它们的镜像后,这些依赖的中间层镜像也会被连带删除。